
Each time an error is detected by a remote Dotcom-Monitor agent location, it automatically executes a traceroute from that remote monitoring agent location to the target of the monitoring.
A traceroute can help determine if the error is an issue related to the network itself, such as Domain Name Server (DNS) resolution issue, packet loss, or a network latency, or possibly if the error is caused by the server itself.
There are two types of traceroute procedures: network traceroute and DNS traceroute.
Network Traceroute
A Network traceroute will help identify the network hop where the problem is occurring. This helps identify whether or not the issue is actually within the user’s organization or within the user’s direct control. If the network traceroute shows no packet loss and average latency, then the traceroute is helping to pinpoint that the issue is not network-related and likely an issue with the server itself.
Dotcom-Monitor attaches traceroute to each error, except DNS errors, with the visual traceroute tool.
Traceroute is being captured in four iterations with a 30-hop limit for each. The timeout threshold for each request is four seconds.
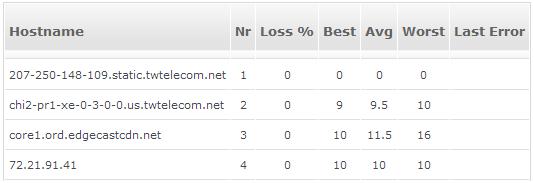
The summary table below contains the best, average, and worst latency values returned for each router along the path, based on all four iterations.
Here’s an example of final traceroute columns:
DNS Traceroute
A DNS traceroute is a great tool for identifying issues with DNS servers. It shows you how DNS requests go through all the steps of a DNS hierarchy, from ROOT servers to your local DNS server. If the DNS traceroute to one of the DNS servers doesn’t respond, or responds incorrectly, you can find it in the results of the DNS traceroute.
The following video shows how to troubleshoot DNS Errors via DNS Traceroute.
Dotcom-Monitor offers a powerful solution to visualize traceroute paths from a number of monitoring locations all over the globe. You can set up a traceroute monitoring device or configure web performance monitoring for web servers, web pages, or web applications. The Dotcom-Monitor platform automatically executes traceroute every time an error is detected by a remote monitoring agent.
Learn more about the Dotcom-Monitor visual traceroute tool here.