
稼働時間とダウンタイムとは何ですか?
一般に 、uptime 値は、指定された期間内で測定された時間の割合を反映し、その間、Dotcom-Monitor は 世界中に位置する監視エージェント
. d自身の時間の値は、指定された期間の範囲内で測定された時間の割合を反映し、その間にドットコムモニターは否定的な応答を受け取りました。
手動サーバのアップタイム/ダウンタイムチェック
多くの無料の商用およびオープンソースツールがあります Webサーバーの状態とパフォーマンスを確認するために使用できるソリューション. これらのツールはチェックするのに最適ですが、 ステータス、応答時間、およびパフォーマンスは、テストを手動で実行してスポットチェックを行う サーバーエラーの 場合は時間 とリソース が消費されます テストの時点で結果が得られるだけです。 エラーの検出 手動テストを実行している間、あなたのウェブサイトにアクセスするためにクライアントのabilityに影響を与えた可能性があります ビジネス.
稼働時間/ダウンタイム監視の自動化
サーバーの問題は特定が難しく、修復に時間がかかる可能性があるため、時間はen エラーが発生します。 私f サーバーの自動監視を設定しておらず、エラーが発生し、次に次の処理を続行します 意味icant の時間が発見される前に、損傷は既に行われている可能性があります。 サーバーの自動化 モニターイングと プロアクティブのセットアップ 卯ptime/ダウンタイムチェックを使用すると、継続的かつ自動的に セットモニートリング cヘックダウンタイムが発生したときに即時アラートを受け取るdをクリックすると、チームはエラーのトラブルシューティングとキーのトラブルシューティングを迅速に行うことができます。p あなたの顧客 frオム・持っている 否定的なユーザー 経験 またはリスク ヘへの無益損失 ザ バスのなさ。
サービス レベル 契約の遵守の監視
さらに、アップタイムの監視は、サービス プロバイダーが SLA (サービス レベル アグリーメント)に順応していることを確認するのに役立ちます。 コミットメント。 SLA レポートの詳細を表示するにはDotcom-Monitor ソリューション内で、SLA レポートの作成方法に関するサポート技術情報の記事をお読みください
。SLA レポートは、指定された時間間隔での SLA パフォーマンスの単一ビューを提供する特別なレポート グループです。
ビジネス要件のダウンタイムを定義する方法
エセと一緒に 考慮する要因 は、以下にはいくつかの例です いつ ダウンタイムの定義方法を考慮する。
- 毎週日曜日の夕方に Web サーバーで定期的にメンテナンスをスケジュールしている場合、Web サイトはダウンしていますか?
- シカゴに拠点を置くウェブサーバーはオーランドからアクセスできませんが、サービスプロバイダがオーランドで問題を抱えている原因ですが、米国の他の地域から入手可能です。
- チャットウィジェットなどのサードパーティのホストされた要素でサーバーエラーが発生しているが、ウェブサイトの残りの部分が利用可能な場合、ウェブサイトはダウンしていますか?
- あなたのウェブサイトが、サーバーのしゃっくりやその他のサーバーエラーのために、世界のどこからでも利用できない場合、最後のs 5秒以上、あなたのウェブサイトがダウンしていますか?
- 小売用の Web サイトを運営していて、ショッピング カートのプロセスが正常に動作していて、たとえば[私たちについて]ページのような別のページが読み込まれていない場合、ウェブサイトはダウンしていますか?
- DNS サーバーの 1 台がダウンしているのに、他の3 台が動作している場合、クライアントの25% が動作しない場合は、そのサーバーが停止している キャッシュされた存続時間(TTL)の有効期限が切れた後にウェブサイトにアクセスすると、ダウン状態と見なされますか?
- Web ファーム内の 3 つの Web サーバーのいずれかがダウンし、ページ応答時間が 10% 増加した場合、 25% 、あるいはページの読み込みが 50%遅い場合でも、ダウンタイムが発生した場合は、この点を考慮しますか?
夜中に呼ばれたり警告されたりするのが好きな人はいない 真面目 ダウンタイムの問題が発生します。 最初の答え ニ自分の時間は2で目を覚ます意味.m. 問題に対処する, だろう 上記の質問に対する回答のいずれかが、監視を変更します アプローチまたは応答 に関連する 卯ptime と ニ自分の時間?
稼働時間/ダウンタイム計算アプローチ
アップタイムまたはダウンタイムを計算することで、Dotcom-Monitor プラットフォームが応答を「アップ」または「ダウン」応答として解釈する方法を慎重に定義できます。 これは、フィルターを使用して行います。フィルタを使用すると、監視デバイスの特定の条件とパラメータを設定できます。 監視期間、タスクの失敗、エラーコードなどをクリックして、エージェントを監視します。フィルタを使用して、アラートの送受信方法を定義することもできます。 ビジネスや監視環境のニーズを満たすために、誤ったアラートの数を制限または無視する 、意図せずにトリガーされる可能性があります。
ちなみに、フィルタはデバイス(偽トリガの切断)とあらゆるタイプのレポートに適用することもできます。
- error は、指定された時間分で報告されます。
- error は、指定された数の A紳士によって確認されます。
- error は、指定された数のタスクで検出されます。
すべてのフィルタとその設定は、アクセスして利用可能です。 フィルタの設定 > . 監視デバイスにフィルタを適用すると、すべての監視デバイスが 通知は、フィルタの基準に基づいています。
A default filter は、すべての新しい監視に割り当てられます。 デバイスs. デフォルトのフィルタはバランスの取れた構成で、ほとんどのモニタリングに適しています デバイスs.
稼働時間/ダウンタイム計算
ダウンタイム計算の数式を以下に示します。

ダウンタイムの期間
ダウンタイム期間 は、フィルタ内の構成に直接関連付けられています。
- ダウンタイム 期間は、フィルターの条件が満たされたときに開始されます。 たとえば、次の 失敗を報告する紳士は、フィルターで指定された A の数に等しく、指定された条件も分数とタスクに合致し、ダウンタイムアラートが送信されます。
- アップタイム 期間は、フィルターの条件が満たされなくなった時点から開始されます。 具体的には 稼働時間
は、”u p”の成功を報告したA の紳士、分、またはタスクの数が開始されます。 フィルター処理された”ダウン”条件に必要な条件を満たさない。 たとえば、up” 状態は、エラー数がs の場合に示されます。 監視によって受信された“ダウン”応答 ジェントはエラー数より少なくなります。 “down” 応答は、Aがフィルタで設定されているとおりに、”down” 状態を示すために必要です。
未定義状態の継続時間
未定義の状態は、各Aのステータス時に設定できます監視に関与するジェントは未定義になります。 エージェントのステータスは未定義と見なされます Agent が、指定された時間の間、エラー応答または成功した応答のいずれかの応答を提供しない場合は、未定義です。
応答時間時間 = (すべてのエージェントの数+1) ×監視周波数 + 15 分たとえば、3つのモニタリングを使用する状況を考える場合5分毎の紳士およびモニタリング頻度、eagentは35分間応答を待ちます。 [応答時間の待機時間] の計算は、次のように:応答時間時間 = (3+1)×5 +15 分= 35 分時間の期限が切れて応答が受信されなくなったら、Agentは未定義です。延期状態の期間監視の延期 デバイス は、いつでも、再び有効になるまで、監視アクティビティを停止します。
期間をスケジュールで除外
アップタイム/ダウンタイムの計算に大きな影響を与える可能性のある別のエンティティは、
スケジュール. スケジュール として機能します。 監視を管理するためのオプション エージェント 中 の期間 ルーチン またはシッシュニ潰瘍 メンテナンス。 監視は、特定の曜日に対して延期できます。, 一日の特定の時間と分だけでなく、 スケジュールを設定するには、スケジュールに記載されている手順に従い、以下の手順に従ってください。 スケジュールナレッジベース記事を設定する。
の変更 モニタリング デバイス‘s 設定s, 含む を再起動する モニタリング デバイス, の間に 下 状態はリセットされるため、アップタイムアラートは送信されません。
サーバーの稼働時間/ダウンタイムの例
監視エージェントが稼働時間またはダウンタイムの状態で処理および応答する方法の例として、7 つの場所から監視されている監視デバイスがあり、ダウンタイム条件が満たされたときに 3 つの場所でエラーを報告する必要があるフィルター セットがあるとします。 このシナリオは、下の図に示されています。
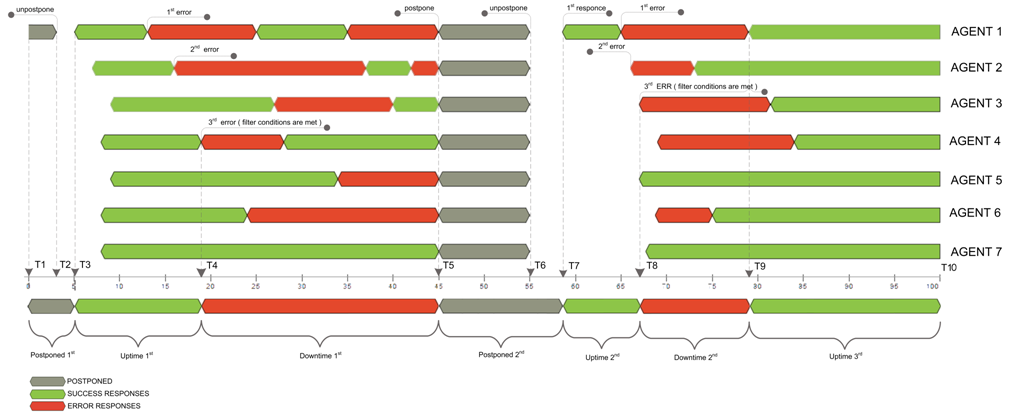
上の図から見ると、 a モニタリング ノード (Agent 1)は残りの部分の間にエラーを検出する エージェントの まだ成功を報告しているフルレスポンス. 次に、2 番目の監視ノード、エージェント 2, エラーを検出する, 次に、エラー応答が 3番目と最後 監視ノード、 エージェント 4. この最終的なエラー応答 図のT4 ポイントで、この瞬間から停止時間
を設定するフィルターがトリガーされます。
ダウン
状態は、あなたがpostポンe期間を設定するまで残ります. この図では、仮定の延期を設定しました。 Aの優れた報告エラーの数は、監視の間に 3 つの監視デバイスの定義済みのしきい値を満たしています セッション.
グラフ上のポイントT6とT7の間の時間ギャップは、最初の応答に遅延が含まれていることを示しています (セッションの処理時間の監視には、ネットワーク転送の遅延と実行自体が含まれます)、”延期された” 時間が∆ (T7–T5) として計算されます(グラフ上に延期 2ndと示されています)。
ここでの利益は、エージェント3からの3番目のエラーでのみダウンタイム
に陥り、Uptime
状態のみを再開します。 ポイント T9応答は、失敗したエージェントの数がフィルタで調整されたよりも少なくなる場合。 この例の最終的なダウンタイムの割合の計算式を次に示します。
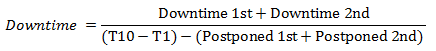
ドットコムモニターによる稼働時間とダウンタイムのモニタリング
のプロセスを自動化するには 稼働時間とダウンタイムの監視 インフラストラクチャの詳細な可視性とパフォーマンスを提供するソリューションを利用する必要があるだけでなく、複数のグローバルな場所から監視する機能、特定のスケジュール、フィルタ、即時アラートの構成、および レポートs とメトリック、 その他の .これらの機能はすべて、ユーザーに ビジネスの要件とニーズに合致する. T彼のドットコムモニタープラットフォームは、これらすべての基本的な機能に加えて、より高度な構成設定とサードパーティの統合を、すべて単一のダッシュボードから提供します。ウェブサイト、API、Webアプリケーションの24時間365日の稼働時間を確保するために、Dotcom-Monitorから利用可能なすべての監視ソリューション
をご覧ください。