Home » Produits » Surveillance API » Surveillance REST API
- Surveillance REST API
- Contrôles synthétiques · 30+ régions
Ne soyez jamais dérangé par une panne d’API inattendue avec Dotcom-Monitor Surveillance REST API
Dotcom-Monitor exécute de véritables flux REST contre vos points de terminaison depuis plus de 30 emplacements mondiaux — enchaîne des appels multi-étapes, valide chaque champ de chaque réponse, et alerte votre équipe dès qu’un problème survient. Détectez les pannes partielles, la dérive du schéma et les pics de latence avant vos utilisateurs.

- Aucune carte de crédit requise
- Toutes les fonctionnalités incluses
- En service en moins de 5 minutes
- Annulez à tout moment · Pas de facturation automatique après l’essai
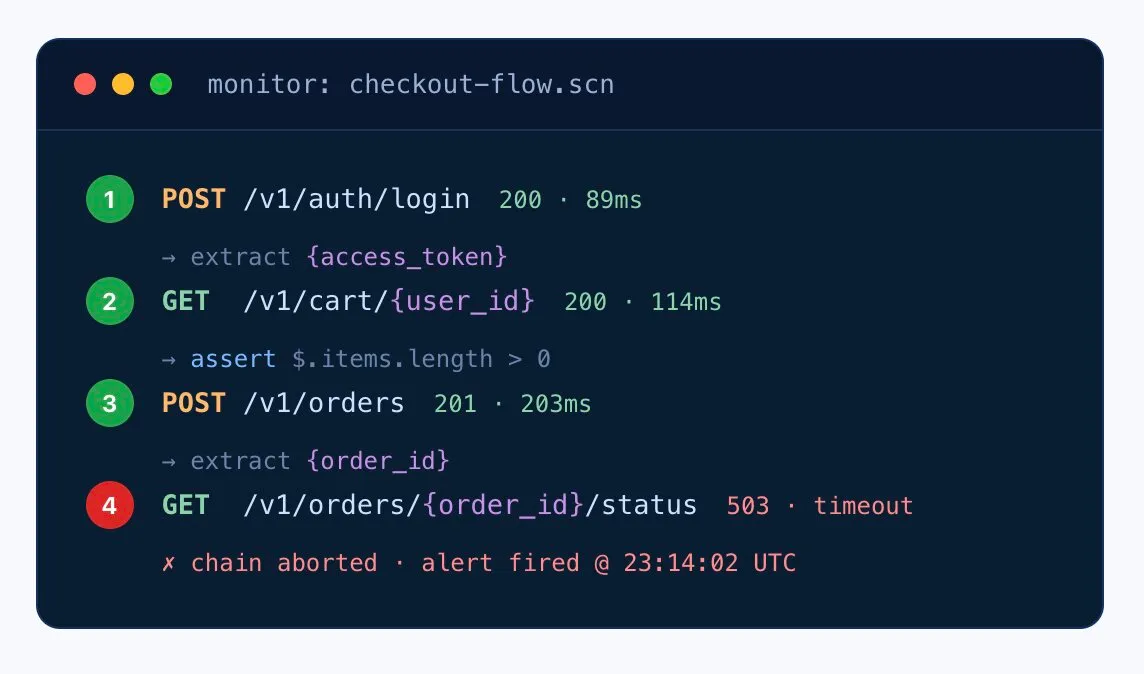
Scénarios multi-étapes
Surveillez de véritables flux API, pas des points de terminaison isolés
Un contrôle /health fonctionnel ne prouve pas que votre logique métier fonctionne toujours. Dotcom-Monitor enchaîne de vraies séquences — auth → fetch → mutate → verify — et valide chaque étape. Dès que la chaîne se casse, vous savez exactement où, pourquoi, et à quoi ressemblait la charge utile de la réponse.
- Transférez les variables entre les appels — les tokens, IDs et valeurs dynamiques circulent automatiquement d'une étape à l'autre.
- Assertions par étape — validez le statut, les en-têtes, le schéma et le contenu de la charge utile à chaque requête, pas seulement la dernière.
- Abandon à la première erreur — arrêtez la chaîne dès qu'une erreur survient, capturez les logs complets requête/réponse pour chaque étape.
- Conçu pour OAuth 2.0 + JWT — actualisez automatiquement les tokens, masquez les secrets dans le Coffre-fort sécurisé.
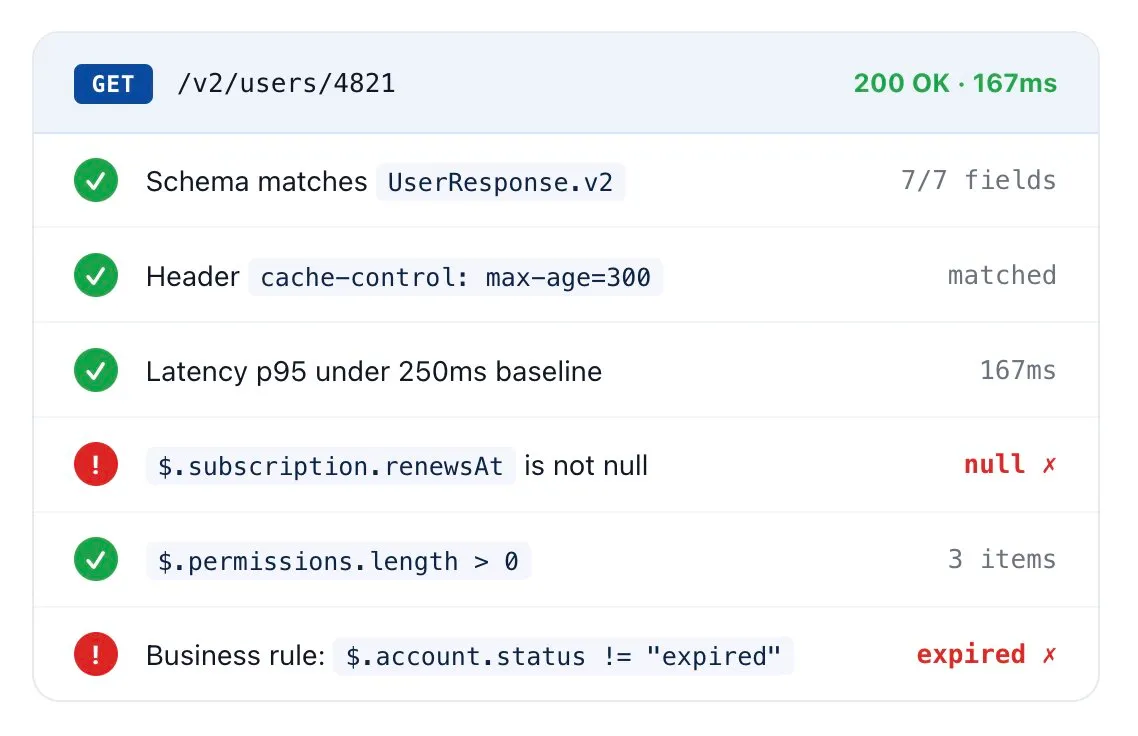
Validation et alertes granulaires
200 OK ne suffit pas. Validez chaque champ.
La moitié des échecs d’API retournent un 200. Dotcom-Monitor inspecte le statut, les en-têtes, le schéma JSON, les nœuds XML, et les champs individuels de réponse — puis escalade uniquement ce qui compte vraiment, pour que votre astreinte n’apprenne pas à ignorer les alertes.
- Validation de schéma JSON / XML — détectez les clés manquantes, types erronés, champs nuls, et valeurs périmées.
-
Assertions de règles métier — exprimez des vérifications comme
$.order.total > 0ou$.status == "success". - Seuils de percentiles de latence — ne déclenchez une alerte qu’en cas de déviation p95/p99 par rapport à la base, pas pour des échantillons bruités isolés.
- Alerte par assertion — orientez les échecs de schéma et violations SLA vers différents canaux et parcours d’escalade.
Cas d’usage
Ce que les équipes DevOps surveillent réellement avec nous
Scénarios réels d’équipes gérant des API REST de production à grande échelle. Chacun peut être actif dans votre compte en moins d’une heure.
Login → Processus de finalisation
Enchaînez l’authentification, la récupération du panier, la commande, le sondage de confirmation. Détectez la panne partielle où la connexion fonctionne mais la commande retourne silencieusement un 503.
Livraison Webhook
Validez que les webhooks de votre fournisseur arrivent au bon endpoint avec le bon schéma — et que les vôtres se déclenchent en aval lorsqu’ils sont activés.
SLA des API tierces
Tenez Stripe, Twilio, Auth0 ou tout fournisseur en amont responsable. Suivez la latence et le taux d’erreur par rapport au SLA qu’ils vous ont vendu.
Détection des goulets d'étranglement régionaux
Effectuez les mêmes contrôles depuis plus de 30 emplacements. Découvrez la mauvaise configuration du CDN qui n’apparaît qu’en APAC, ou le déploiement DNS qui ne s’est pas propagé en EU-West.
Tests de fumée avant déploiement
Lancez des exécutions de surveillance depuis votre pipeline CI après le déploiement. Conditionnez la sortie sur les résultats des assertions — bloquez les builds défectueux avant qu’ils n’atteignent le trafic de production.
Microservices internes
Installez un agent privé dans votre VPC. Surveillez les appels REST service à service de la même manière que vous surveillez les API publiques — sans règles de pare-feu entrantes.
Pas prêt pour un essai ?
Vous voulez d'abord une présentation de 15 minutes ?
Un ingénieur performance vous guidera à travers votre premier moniteur REST multi-étapes — authentification en chaîne → récupération → assertion — pas de discours commercial, juste un moniteur fonctionnel à la fin de l’appel.
S'intègre à votre stack
S'intègre bien aux outils que votre équipe utilise déjà
Slack
PagerDuty
Microsoft Teams
Opsgenie
Webhook
Email / SMS
Grafana
Prometheus
GitHub Actions
Jenkins
Azure DevOps
Power BI
Réseau de surveillance mondial
Contrôles exécutés là où vivent vos utilisateurs
Dotcom-Monitor exploite sa propre infrastructure de surveillance dans plus de 30 emplacements sur six continents — y compris des agents privés que vous pouvez déployer dans votre VPC, derrière des pare-feu ou sur site.
Cela signifie que vous détectez la panne régionale, le décalage de propagation DNS, la mauvaise orientation du CDN — pas seulement la panne globale.
30+
Emplacements de surveillance mondiaux
6
Continents couverts
1 min
Intervalle minimum de contrôle
Agents privés
Pour derrière le pare-feu

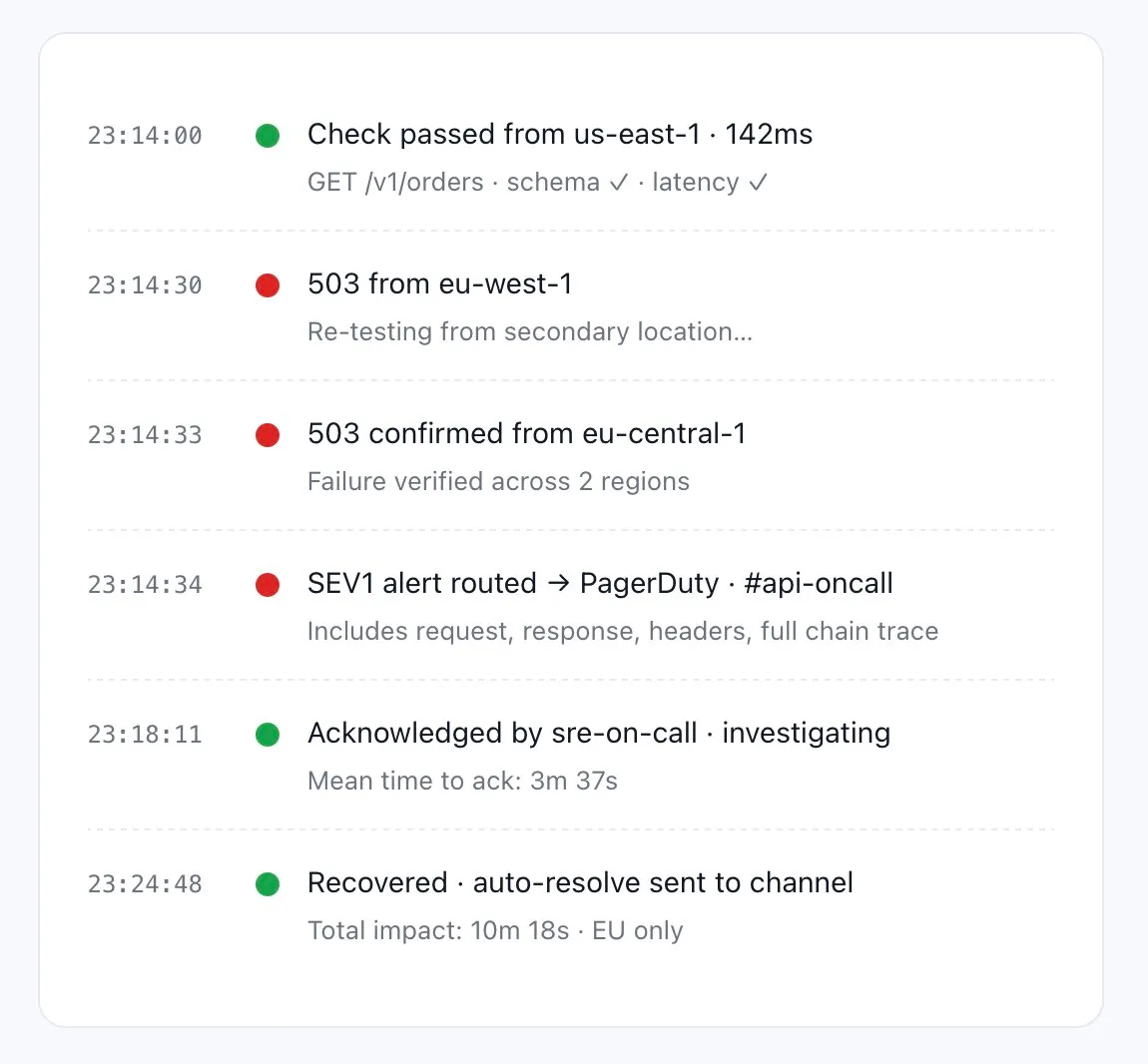
Alertes qui ne crient pas au loup
La bonne personne alertée. Avec le bon contexte. Du premier coup.
Les alertes à 3 heures du matin ne fonctionnent que lorsqu’elles sont fiables. Dotcom-Monitor trie selon la gravité, supprime le bruit, et fournit au répondeur tout ce dont il a besoin pour trier dans une seule notification — la requête échouée, le corps de la réponse, quelles assertions ont échoué, et quels emplacements l’ont vu.
- Routage multi-canaux — alerte Slack pour les avertissements, PagerDuty pour les SEV1, Teams pour les mises à jour de statut.
- Confirmation d’échec — nouveau test depuis un second emplacement avant d’alerter. Pas d’alertes sur des échantillons isolés bruyants.
- Escalade de gravité — escalade dans la chaîne d’astreinte si non reconnue dans votre fenêtre SLA.
- Charge utile médico-légale complète — chaque alerte inclut la requête, la réponse, les en-têtes, et les traces au niveau des étapes.
Slack
PagerDuty
Opsgenie
MS Teams
Webhook
SMS / Voix
Ce que disent les équipes
Les ingénieurs ne recommandent pas les outils à la légère. Ils recommandent celui-ci.
"J'adore absolument les services de surveillance complets que Dotcom-Monitor fournit. Les alertes en temps réel et les analyses de performance détaillées ont changé la donne pour le temps de disponibilité et la vitesse de notre site web. La fonction de surveillance mondiale garantit que notre site est optimisé partout, et le tableau de bord intuitif facilite le suivi des performances. Leur service client est exceptionnel — toujours réactif et efficace."
Tomer C.
Directeur général · Services aux installations
Avis Capterra vérifié · mars 2025
"L'une des meilleures fonctionnalités de Dotcom est la capacité d'API push/pull qui nous fournit des données de performance réseau. Nous l'utilisons pour surveiller les problèmes de performance ainsi que les statistiques de chargement des pages. Dotcom-Monitor nous permet de surveiller plusieurs services dans une seule interface et plateforme. Cela nous a permis de fonctionner plus efficacement."
Gregory S.
Responsable · Médias de diffusion
Avis Capterra vérifié · mai 2020
"J'ai été profondément impressionné par le niveau de détail et la exhaustivité des rapports générés par le logiciel. De plus, l'équipe de support de Dotcom-Monitor a dépassé mes attentes. Presque quotidiennement, je les contacte avec diverses questions et ils ont constamment fait preuve d'une patience inébranlable, fournissant des réponses détaillées et perspicaces."
Shirin R.
Ingénieur test logiciel · Logiciels informatiques
Avis Capterra vérifié · février 2023
"Je suis analyste réseau et j'utilise les outils Dotcom au sein de l'ISP pour lequel je travaille, c'est un outil vraiment bon et fiable pour surveiller les éléments le long du réseau, et tester les composants réseau. Je l'utilise habituellement pour diagnostiquer la latence des serveurs et le temps de résolution DNS."
Leonardo J.
Analyste infrastructure informatique et réseau Internet
Avis Capterra vérifié · octobre 2022
4.5
Capterra
82 avis
4.6
Facilité d'utilisation
Avis Score Capterra
4.6
Service Client
Avis Score Capterra
Tous les avis proviennent de avis vérifiés Capterra. Notes au juillet 2026.
Vous voulez tester sans vous engager ? Plan Free Forever disponible — jusqu’à 25 cibles, 2 emplacements de surveillance, 7 jours de conservation des données. Commencez gratuitement → ou Comparez les plans
Questions fréquemment posées
Réponses que cherchent les équipes DevOps avant de s'inscrire
Qu'est-ce que la surveillance REST API ?
Tests continus et automatisés des endpoints REST depuis l’extérieur de votre infrastructure — vérification de la disponibilité, du temps de réponse et de la justesse des données, puis alerte dès qu’un problème survient. Contrairement aux tests ponctuels, la surveillance s’exécute 24h/24 et 7j/7 depuis plusieurs emplacements mondiaux à intervalles réguliers.
Prend-il en charge OAuth, JWT et d'autres schémas d'authentification ?
Oui. Clé API, Auth Basic, OAuth 2.0 (client credentials et code d’autorisation), JWT avec actualisation automatique, en-têtes personnalisés, mTLS et AWS Signature v4. Les secrets sont masqués grâce au Secure Vault.
Puis-je enchaîner plusieurs appels API dans un seul moniteur ?
Oui — c’est le cœur de la surveillance multi-étapes. Transmettez jetons, IDs et valeurs dynamiques entre les étapes, validez chaque étape indépendamment, et arrêtez l’enchaînement dès la première erreur avec des logs complets par étape des requêtes/réponses.
Puis-je bloquer une mise en production si les seuils de surveillance ne sont pas respectés ?
Oui. Déclenchez des exécutions de moniteurs via API depuis GitHub Actions, Jenkins, Azure DevOps ou tout outil CI/CD. Conditionnez le déploiement sur la disponibilité, la latence ou les résultats d’assertion pour empêcher les mauvaises versions d’atteindre la production.
À quelle fréquence les contrôles peuvent-ils s’exécuter ?
Aussi souvent qu’une fois par minute par endpoint, avec des intervalles personnalisés possibles par moniteur. Pour les chemins critiques comme la connexion ou le paiement, nous recommandons des contrôles à 1 minute ; pour les endpoints moins critiques, des intervalles de 5 ou 15 minutes.
Puis-je surveiller des API derrière un pare-feu ?
Oui. Déployez des agents privés légers dans votre réseau — ils initient des connexions sortantes vers la plateforme, donc aucune règle de pare-feu entrante n’est requise. Vous bénéficiez de la même profondeur de surveillance pour les microservices internes que pour les API publiques.
En quoi cela diffère-t-il de la simple surveillance de disponibilité ?
Les outils de disponibilité vous affichent en vert quand un 200 est reçu. Nous validons la réponse réelle — schéma JSON, en-têtes, contenu des données, percentiles de latence, succès de la chaîne aval — ainsi les échecs partiels (le « 200 mais cassé ») sont détectés avant que les utilisateurs ne s’en aperçoivent.
Puis-je exporter les données de performance vers Grafana ou un BI ?
Oui. Diffusez les métriques de disponibilité du flux, de latence et d’erreurs via un flux XML vers Grafana, Prometheus, Power BI ou votre propre stack BI. L’API expose également des données historiques pour des tableaux de bord et rapports personnalisés.
Sur quels codes de statut HTTP dois-je alerter ?
Toujours les erreurs 5xx (problèmes serveur). Les erreurs 4xx de manière sélective — alerter sur les pics 401/403 (rupture d’authentification) mais généralement pas sur les 404 (erreurs client). Le 429 (limite de débit) mérite une alerte si votre moniteur est lui-même limité. Combinez avec des assertions sur le contenu pour détecter le cas 200-mais-cassé.
Comment surveiller une API REST qui retourne des données paginées ?
Configurez le moniteur pour demander la page 1 et vérifiez le champ total-count ainsi que la présence des métadonnées next-page. Pour une validation complète sur toutes les pages, construisez une chaîne multi-étapes qui suit le lien next et valide chaque page via le curseur.
Qu'est-ce que JSONPath et pourquoi l'utiliser pour la surveillance REST ?
JSONPath est un langage de requête pour JSON, analogue à XPath pour XML. Il vous permet d’affirmer sur des champs spécifiques profondément dans la charge utile de la réponse sans analyser tout le corps. Exemple : $.order.status == “confirmed” ou $.items.length > 0.
Puis-je surveiller une API REST protégée par AWS Signature v4 ?
Oui. Configurez la clé d’accès et le secret AWS dans le Coffre Sécurisé ; Dotcom-Monitor s’occupe automatiquement de la signature des requêtes SigV4 selon les spécifications AWS.
Vous surveillez plus que REST ? Découvrez la plateforme complète de surveillance API →
Détectez la prochaine panne d'API avant vos utilisateurs
Essai gratuit de 30 jours. Aucun carte de crédit. Accès complet à la plateforme. En ligne en moins de cinq minutes.
- Plus de 10 000 organisations
- Leader en surveillance depuis 1998
- SLA de disponibilité à 99,99%