- Surveillance API
- REST · SOAP · GraphQL · Postman
Logiciel de surveillance API qui détecte les API défaillantes avant qu'elles ne cassent votre produit
Dotcom-Monitor est un logiciel de surveillance API qui exécute des contrôles synthétiques sur chaque API dont votre équipe dépend — collections REST, SOAP, GraphQL, Postman et Insomnia — depuis plus de 30 emplacements mondiaux. Il enchaîne des workflows multi-étapes, valide chaque payload, et alerte les bonnes personnes au moment où quelque chose se casse.

- Aucune carte de crédit requise
- Toutes les fonctionnalités incluses
- En direct en moins de 5 minutes
- Annulez à tout moment · Pas de facturation automatique après l'essai
Choisissez votre protocole ou outil
Choisissez la surface API que vous devez surveiller
Chaque protocole possède sa propre page détaillée avec guides d’installation, exemples de code et cas d’usage. Ou commencez simplement un essai et nous détecterons automatiquement ce que vous utilisez.
REST
- Le plus courant
Surveillance d'API REST
Validation JSON, assertions de schéma, enchaînement multi-étapes, OAuth/JWT. La clé de voûte pour toute équipe utilisant des API REST HTTP.
SOAP
- Entreprise & legacy
Surveillance d'API SOAP
Importation WSDL, validation XPath, prise en charge SOAP 1.1/1.2, WS-Security. Conçu pour les API d’entreprise, financières et de santé.
GQL
- Moderne
Surveillance de l'API GraphQL
Surveillance consciente des requêtes. Inspecte le tableau errors et les données de réponse, puisque GraphQL renvoie 200 même en cas d’échec.
POSTMAN
- Importer des collections
Surveillance de la collection Postman
Importez directement la collection Postman v2.0/v2.1 JSON. Transformez les tests API que votre équipe maintient déjà en surveillances de production 24/7.
INSOMNIA
- Importer des collections
Surveillance de la collection Insomnia
Importer les exports Insomnia v4 avec tous les détails de requête, variables d’environnement et configurations d’authentification préservés.
Vous cherchez OAuth, JWT, mTLS ou d’autres schémas d’authentification ? Tous les protocoles ci-dessus les supportent — voir la matrice complète d’authentification →
Références externes : en savoir plus sur REST, SOAP, GraphQL, et le schéma API lui-même.
Pourquoi les équipes nous choisissent
Surveillance API conçue pour les ingénieurs qui répondent aux alertes
Six choses que les équipes nous disent qu’elles ne pouvaient pas faire aussi clairement avec Datadog, Pingdom, Uptrends ou les Moniteurs Postman.
Plus de 30 emplacements mondiaux
Exécutez des vérifications distribuées depuis l’Amérique du Nord, l’Europe, l’Asie-Pacifique et l’Amérique du Sud. Détectez le problème régional du CDN, le décalage de propagation DNS, la défaillance de géoroutage.
SLA de disponibilité 99,99 %
Disponibilité contractuelle soutenue par plus de 25 ans d’infrastructure de surveillance. Votre outil de surveillance lui-même ne devient jamais le point unique de défaillance.
Transactions multi-étapes
Chainez connexion → récupération → mutation → confirmation dans un seul moniteur. Passez les jetons entre les étapes, annulez à la première erreur, capturez les journaux au niveau des étapes.
Intégration native PagerDuty, Slack, Teams
Dirigez les alertes directement vers vos outils d’incident — avec contexte diagnostique, charges utiles de réponse et IDs de trace dans la première notification.
Agents privés (derrière un pare-feu)
Installez un agent léger dans votre VPC pour surveiller les microservices internes. Connexion sortante uniquement — pas de règles de pare-feu entrantes.
CI/CD & Moniteurs en tant que code
Déclenchez les exécutions de moniteur depuis GitHub Actions, Jenkins, Azure DevOps. Contrôlez les mises en production par les résultats d’assertion, la latence, ou la disponibilité.
Surveillance multi-étape
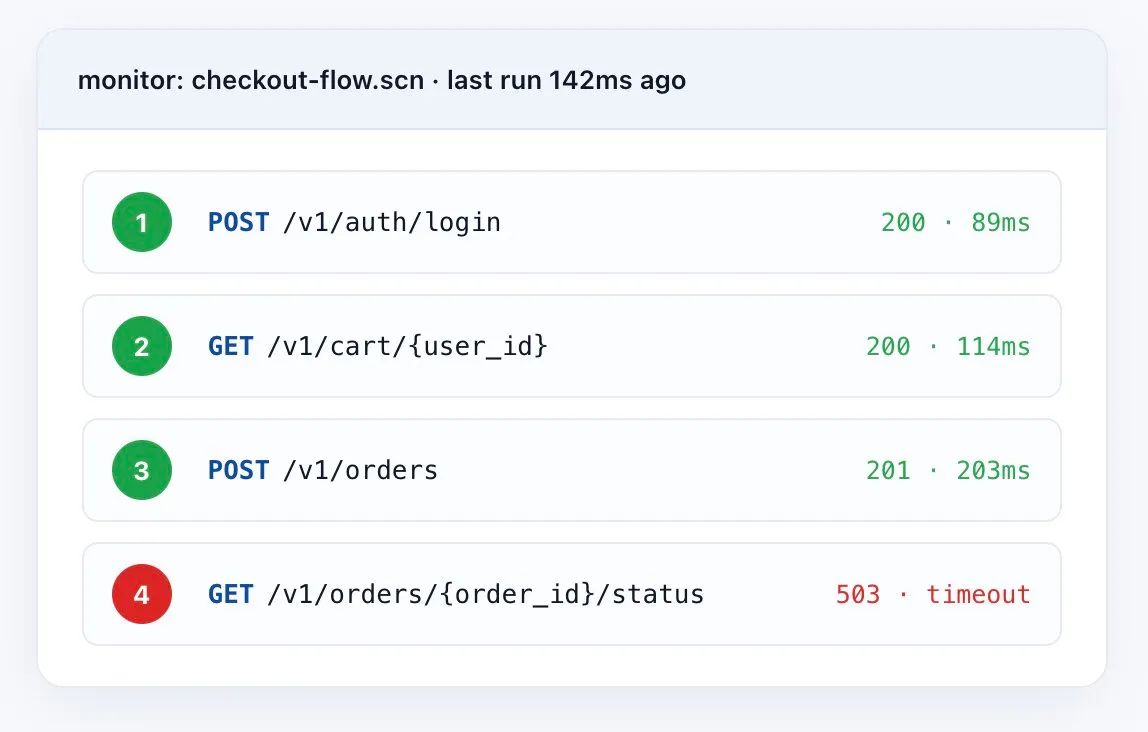
Validez de vrais workflows, pas seulement des points de terminaison isolés
Un simple contrôle /health fonctionnel ne prouve pas que votre logique métier fonctionne toujours. Enchaînez de vraies séquences — auth → fetch → mutate → verify — et validez chaque étape. Dès que la chaîne se brise, vous savez exactement où, pourquoi, et quel était le contenu de la réponse.
- Transférez des variables entre les appels — les jetons, IDs, et valeurs dynamiques circulent automatiquement.
- Assertions par étape — statut, en-têtes, schéma, contenu du payload sur chaque requête.
- Arrêt à la première erreur — journaux complets requête/réponse par étape capturés.
- Fonctionne sur plusieurs protocoles — REST, SOAP, GraphQL, chaînes mixtes.
Authentification
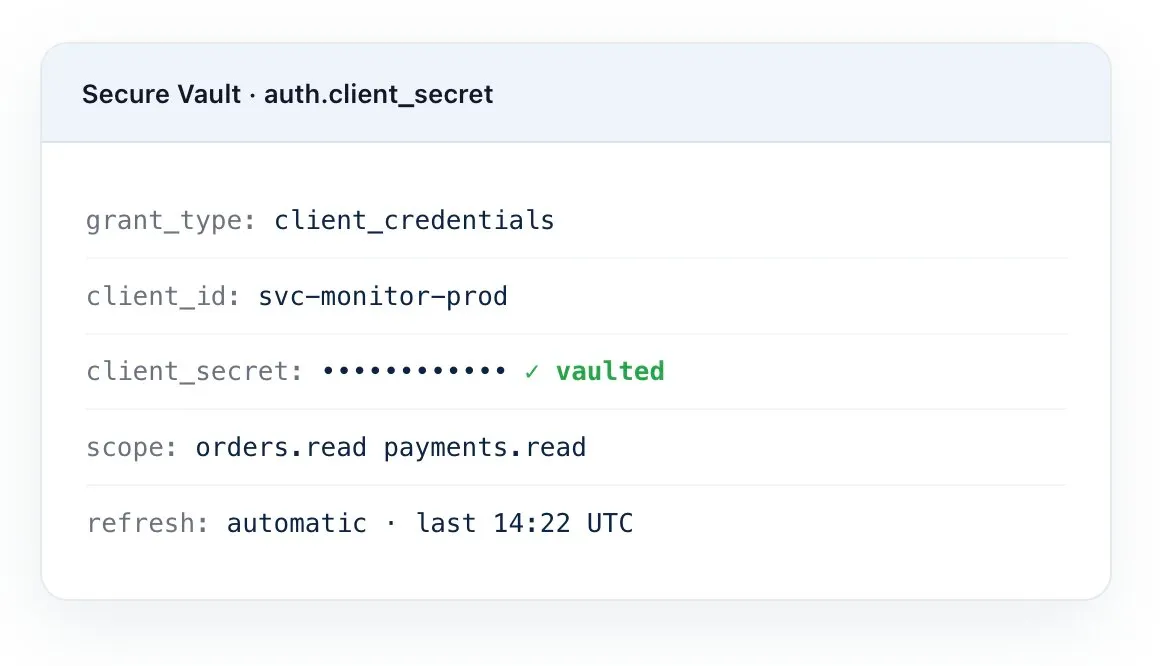
Tous les schémas d'authentification réellement utilisés par vos API
Les API de production ne vivent pas derrière une seule méthode d’authentification. Dotcom-Monitor prend en charge nativement toute la gamme — et masque tous les secrets dans Secure Vault, afin que les identifiants ne fuient jamais dans les logs ou les scripts exportés.
- OAuth 2.0 — flux Client Credentials, Authorization Code, Refresh Token.
- JWT avec actualisation automatique, plus API Key, Basic et Bearer Token.
- Entreprise : NTLM, Kerberos, mTLS (Certificat Client), AWS Signature v4.
- En-têtes personnalisés pour tout schéma d'authentification propriétaire.
Réseau de surveillance global
Contrôles qui s'exécutent là où vivent vos utilisateurs
Dotcom-Monitor exploite sa propre infrastructure de surveillance dans plus de 30 emplacements sur six continents — ainsi que des agents privés que vous pouvez déployer dans votre VPC, derrière des pare-feu, ou sur site pour surveiller les microservices internes.
Cela signifie que vous détectez la panne régionale, le délai de propagation DNS, la mauvaise redirection CDN — pas seulement les problèmes globaux.
30+
Emplacements mondiaux
6
Continents couverts
1 min
Intervalle minimum entre les contrôles
Agents privés
Pour derrière le pare-feu

Premiers pas
De l'inscription à la première alerte en moins de cinq minutes
1
Définir les Endpoints & Assertions
Configurez les endpoints REST, SOAP ou GraphQL, les en-têtes, les assertions JSONPath/XPath, et l’authentification. Ou importez directement une collection Postman ou Insomnia.
2
Planifier les Contrôles Synthétiques
Exécutez des contrôles aux intervalles de 1, 3, 5 ou 15 minutes depuis plus de 30 emplacements mondiaux en Amérique du Nord, Europe, Asie-Pacifique et Amérique du Sud.
3
Suivre la Disponibilité & la Performance
Suivez le pourcentage de disponibilité, les temps de réponse P95/P99, TTFB, le temps DNS et les taux d’erreur par code HTTP sur chaque endpoint surveillé.
4
Recevoir des Alertes en Temps Réel
Recevez des alertes par e-mail, SMS, Slack, PagerDuty ou Teams en quelques secondes — avec le temps de réponse, le code d’état et les échecs de validation joints.
Pourquoi c’est important
Le Coût Caché des Pannes d’API
Les APIs alimentent les paiements, l’authentification, l’inventaire, les transactions financières et les intégrations SaaS. Lorsqu’elles échouent — même brièvement — l’impact est immédiat.
Impact Mttr
Temps Moyen de Résolution
Sans surveillance proactive, les équipes comptent sur les rapports clients pour détecter les défaillances — ajoutant 30 à 60 minutes rien que pour la détection. La surveillance synthétique continue réduit la détection à moins de 60 secondes, ce qui permet d’isoler plus rapidement la cause première.
Exposition SLA & Conformité
Risque contractuel et réglementaire
Pour les SaaS B2B, FinTech et la santé, une interruption d’API déclenche des pénalités SLA, des violations de conformité et des constats d’audit. Les preuves documentées de la disponibilité sont ce qui défend le respect des SLA lors des discussions de renouvellement.
Exposition au revenu par minute
Impact financier direct
Une plateforme e-commerce traitant 100 commandes/min à 50 $/commande perd 25 000 $ par interruption de 5 minutes. Une erreur lors du passage en caisse, de l’autorisation de paiement ou de l’appel d’authentification interrompt immédiatement la conversion.
Angles morts des API tierces
Responsabilité des fournisseurs
Les applications modernes dépendent de Stripe, Auth0, Okta, Twilio. Même lorsque votre infrastructure est saine, une dégradation en amont peut casser le passage en caisse, la connexion et la synchronisation des données. Surveillez les points de terminaison tiers pour isoler l’origine des pannes.
Pas prêt pour un essai ?
Vous voulez d'abord une démonstration de 15 minutes ?
Un ingénieur performance vous montrera comment configurer votre premier moniteur dans votre environnement — pas de discours commercial, juste un moniteur fonctionnel à la fin de l’appel. Réservation directe sur le calendrier, sans intermédiaire.
Comparé aux alternatives
Où les outils de surveillance d’API gagnent et perdent
Une référence pour les acheteurs qui comparent les options. Nous essayons d’être justes — chaque outil a son rôle ; voici où nous nous positionnons.
Capacité | Dotcom-Monitor | Postman Monitors | Pingdom / uniquement disponibilité | Datadog Synthetics |
|---|---|---|---|---|
Chaînes API multi-étapes avec passage de variables | Complet | Partiel | ||
Assertions de charge utile JSON / XML / XPath | Limité | |||
OAuth 2.0 + JWT actualisation automatique | Manuel | Limité | ||
SOAP / WSDL / WS-Security | Partiel | |||
Agents privés (derrière un pare-feu) | ||||
30+ emplacements de surveillance globaux | Limité | |||
Importer des collections Postman / Insomnia | (Postman) | |||
Blocage de porte CI/CD via API | Partiel | |||
Essai gratuit | 30 jours, toutes fonctionnalités | Plans payants | 14 jours | 14 jours |
- Les moniteurs Postman à profondeur multi-étapes sont inégalés
- La validation de charge utile que Pingdom ne peut égaler
- Capacités de niveau Datadog à une fraction du coût
En production
Ce que les équipes détectent avec nous qu'elles ne pouvaient pas détecter avant
- E-commerce
Malcolm Group
A construit un moniteur complet du processus de paiement avec EveryStep Recorder qui fonctionne toutes les 15 minutes — ajoute des articles, applique des coupons, valide les prix, soumet avec une carte refusée pour tester la logique de paiement de bout en bout.
- Les alertes pointent maintenant vers le composant défaillant (panier, coupon, paiement, lot) — pas juste "site hors service"
- Détecte des problèmes que les vérifications de disponibilité manquent parce que le site semble en ligne
- Le moniteur de soumission par lot nocturne s'exécute toutes les 3 heures, détectant les régressions backend
- Commerce mondial
LuckyVitamin
Des millions de visiteurs mensuels dans plus de 50 pays. Mise en place des tests synthétiques et de performance Dotcom-Monitor pour sécuriser le paiement sous forte charge.
- Les alertes en temps réel et les analyses de tendances ont révélé des goulets d'étranglement cachés
- A économisé des centaines d'heures d'ingénierie, protégé les revenus pendant des pics de demande 3–4×
- A renforcé la confiance dans le monitoring à mesure que la présence internationale a grandi
Ce que disent les clients
Les équipes qui exploitent les APIs de production le disent mieux
"J'adore absolument les services complets de surveillance fournis par Dotcom-Monitor. Les alertes en temps réel et les analyses détaillées des performances ont changé la donne pour la disponibilité et la rapidité de notre site web. La fonction de surveillance globale garantit que notre site est optimisé partout, et le tableau de bord intuitif facilite le suivi des performances. Leur support client est exceptionnel — toujours réactif et efficace."
Tomer C.
Directeur Général · Services aux installations
Avis vérifié Capterra · Mars 2025
"L'une des meilleures fonctionnalités de Dotcom est la capacité API push/pull qui nous fournit des données de performance réseau. Nous l'utilisons pour surveiller les problèmes de performance ainsi que les statistiques de chargement des pages. Dotcom-Monitor nous permet de surveiller plusieurs services au sein d'une seule interface et plateforme. Cela nous a permis d'opérer plus efficacement."
Gregory S.
Manager · Médias de diffusion
Avis vérifié Capterra · Mai 2020
"J'ai été profondément impressionné par le niveau de détail et l'exhaustivité des rapports générés par le logiciel. De plus, l'équipe de support de Dotcom-Monitor a dépassé mes attentes. Presque quotidiennement, je les contacte avec diverses questions et ils ont toujours fait preuve d'une patience inébranlable, fournissant des réponses détaillées et perspicaces."
Shirin R.
Ingénieur Test Logiciel · Logiciel informatique
Avis vérifié Capterra · Février 2023
"Je suis analyste réseau et j'utilise les outils Dotcom au sein du FAI où je travaille, c'est un outil vraiment bon et fiable pour surveiller les éléments du réseau et tester les composants réseau, je l'utilise habituellement pour diagnostiquer la latence des serveurs et le temps de résolution DNS."
Leonardo J.
Analyste infrastructure réseau et informatique Internet
Avis vérifié Capterra · Octobre 2022
4.5
Capterra
80 avis
4.6
Facilité d'utilisation
Score Capterra avis
4.6
Service Client
Score Capterra avis
Tous les avis proviennent de avis vérifiés Capterra. Évaluations en date de janvier 2026.
Tarification
Commencez Gratuitement. Évoluez avec la Croissance de Vos APIs.
Chaque plan inclut la surveillance REST API, des contrôles synthétiques, des transactions multi-étapes et des rapports de disponibilité. Aucuns frais cachés.
Gratuit
Gratuit Pour Toujours
0 $
- Jusqu'à 25 Cibles
- Fréquence de Surveillance Jusqu'à 5 min
- 2 Emplacements Globaux
- Rétention des Données Pendant 7 Jours
- Alertes Email
- Tableaux de Bord Publics
Le plus populaire
Abonnements
À partir de
19 $
.99 /mo
- Jusqu'à 100 cibles
- Fréquence de surveillance jusqu'à 1 min
- 25 emplacements mondiaux
- Rétention des données 1 an
- Plus de 20 intégrations d'alerte
- Agents privés & configuration API
Entreprise
Tarification personnalisée
Parlons-en
- Cibles illimitées
- Fréquence de surveillance jusqu'à 1 min
- Plus de 30 emplacements mondiaux
- Rétention des données 3 ans
- Support prioritaire 24/7
- SSO, MFA & facturation PO
Par industrie
Surveillance API dans tous les secteurs qui dépendent de la disponibilité
Surveillez les dépendances API internes et tierces pour garantir que les intégrations renvoient des données correctes à temps. Détectez la dégradation des API partenaires avant qu’elle ne se propage.
Suivez les passerelles de paiement (Stripe, PayPal), les systèmes d’inventaire et les points de terminaison d’expédition. Une panne de 5 minutes à la caisse peut coûter des dizaines de milliers lors des pics.
FinTech
Assurez-vous que les API financières respectent les normes de sécurité réglementaires et la latence inférieure à la seconde. Surveillez le traitement des transactions, KYC, et les intégrations bancaires pour éviter les transactions échouées.
Santé
Surveillez les API EHR, les portails d’assurance et les plateformes de télémédecine. Maintenez disponibles et réactifs les points de terminaison d’échange de données conformes à la HIPAA.
Informatique d'entreprise
Validez les intégrations API inter-départements — CRM, ERP, RH, communications. Détectez les défaillances inter-systèmes avant qu’elles ne perturbent les flux de travail internes.
Médias & Diffusion
Surveillez les API de diffusion de contenu, les points de terminaison de streaming et les services de gestion des droits. Vérifiez que les consommateurs en aval voient les bonnes données à l’échelle mondiale.
Une question courante
Surveillance synthétique des API vs. Logs & Traces — Lequel devez-vous choisir ?
La réponse honnête est les deux. Ils répondent à des questions différentes. Voici à quoi sert chacun réellement.
Surveillance synthétique des API
- Tests externes — la façon dont vos clients expérimentent votre API
- Attrape les échecs DNS, les erreurs TLS, les mauvais routages CDN, les délais d’attente réseau
- Fonctionne 24h/24 et 7j/7 à partir de plus de 30 emplacements globaux, même pendant les périodes sans trafic
- Détecte les défaillances avant les clients — proactif, pas réactif
Logs, Traces, APM
- Observe de l'intérieur — ce que vos serveurs et votre code voient
- Identifie les erreurs au niveau de l'application, les requêtes lentes, les exceptions
- Ne génère des données que lorsque de vrais utilisateurs effectuent activement des requêtes
- Signale les problèmes après qu'ils ont affecté les utilisateurs
À retenir : Les logs répondent à « qu’est-ce qui n’a pas fonctionné dans notre code ? » Le synthétique répond à « nos clients peuvent-ils réellement utiliser cette API maintenant ? » Les équipes avec le MTTR le plus bas utilisent les deux.
Bonnes pratiques
À quoi ressemble un bon monitoring d'API
Sept choses que toute équipe exploitant des API en production devrait faire — indépendamment de l’outil choisi.
01
Surveillez depuis plusieurs emplacements géographiques
Un seul emplacement ne peut pas détecter les pannes DNS régionales, les mauvaises configurations CDN ou les problèmes de routage géographique. Utilisez au moins 5 emplacements répartis.
02
Validez les charges utiles — pas seulement les codes de statut
Un HTTP 200 ne garantit pas la correction. Utilisez des assertions JSONPath ou XPath pour vérifier que les corps de réponse ont la structure et le contenu attendus.
03
Définissez des seuils d'alerte basés sur la ligne de base
Les seuils statiques déclenchent des faux positifs. Établissez des lignes de base par point de terminaison, puis alertez à 2× le temps de réponse P95.
04
Surveillez les flux d'authentification de bout en bout
L’expiration des jetons, les échecs de rafraîchissement OAuth et la rotation des certificats sont des causes courantes de panne. Incluez les étapes d’authentification pour détecter rapidement les problèmes d’identifiants.
05
Tester les transactions multi-étapes
Un seul point de terminaison peut réussir alors que la transaction complète échoue. Les moniteurs multi-étapes détectent les échecs de session, de séquençage et de dépendance des données.
06
Surveiller séparément les dépendances tierces
Les passerelles de paiement, les fournisseurs d’identité et les API d’expédition se dégradent indépendamment. Des moniteurs dédiés isolent si les pannes sont internes ou externes.
07
Inclure la surveillance API dans le CI/CD
Exécutez des vérifications synthétiques post-déploiement. Les tests automatisés détectent les changements de schéma, les champs manquants et les régressions avant qu’ils n’atteignent les utilisateurs.
Questions fréquemment posées
Réponses que les équipes DevOps veulent avant de s'inscrire
Qu'est-ce que la surveillance API ?
La surveillance API est la pratique continue et automatisée de validation des points de terminaison API en termes de disponibilité, temps de réponse et exactitude des données depuis l’extérieur de votre infrastructure. Contrairement aux tests ponctuels, la surveillance fonctionne 24/7 depuis plusieurs emplacements mondiaux à un rythme fixe — et vous alerte dès qu’une de ces connexions échoue.
Quels modes d'authentification sont pris en charge ?
Clé API, Authentification basique, OAuth 2.0 (Client Credentials, Authorization Code, Refresh Token), JWT avec rafraîchissement automatique, Bearer Token, AWS Signature v4, NTLM, Kerberos, mTLS, et en-têtes personnalisés. Les secrets sont masqués via le Secure Vault.
Puis-je enchaîner plusieurs appels API dans un seul moniteur ?
Oui. Les moniteurs multi-étapes transmettent les tokens, IDs et valeurs dynamiques entre les étapes, valident chaque étape indépendamment, et interrompent la chaîne dès la première erreur avec des journaux complets de requête/réponse par étape.
Puis-je surveiller des API derrière un pare-feu ?
Oui. Déployez des agents privés légers dans votre réseau — ils initient des connexions sortantes, donc aucune règle de pare-feu entrante n’est nécessaire.
En quoi cela diffère-t-il de la surveillance uniquement de la disponibilité ?
Les outils de disponibilité vous indiquent en vert lorsqu’un code 200 est renvoyé. Nous validons la réponse réelle — schéma JSON, en-têtes, contenu du payload, percentiles de latence, succès de la chaîne en aval — afin de détecter les pannes partielles (le type 200-mais-cassé).
En quoi la surveillance API diffère-t-elle de l'APM ?
La surveillance API teste de l’extérieur (du point de vue de l’utilisateur). L’APM suit le comportement interne — code, base de données, serveur. Les équipes matures utilisent les deux : synthétique pour les vérifications orientées client, APM pour le débogage de la cause racine.
Puis-je intégrer la surveillance API dans un pipeline CI/CD ?
Oui. Déclenchez les exécutions de surveillance via API depuis GitHub Actions, Jenkins, Azure DevOps. Bloquez le déploiement selon la disponibilité, la latence ou les résultats des assertions pour empêcher les mauvaises versions d’arriver en production.
À quelle fréquence les contrôles peuvent-ils être exécutés ?
Aussi souvent qu’une fois par minute par point de terminaison. Nous recommandons des intervalles d’une minute pour les chemins critiques (connexion, panier, paiement) et des intervalles de 5 ou 15 minutes pour les points de terminaison moins prioritaires.
Quelles métriques sont les plus importantes ?
% de disponibilité (objectif 99,9%+), temps de réponse (P95/P99), taux d’erreur (4xx + 5xx), TTFB, temps de résolution DNS, temps de poignée de main SSL, et débit. Plus la validation du payload — métrique totalement ignorée par les outils de disponibilité.
À quelle fréquence dois-je surveiller une API en production ?
Pour les API impactant le chiffre d’affaires (connexion, paiement, panier), chaque minute. Pour les points de terminaison moins critiques, tous les 5 ou 15 minutes conviennent. La cadence idéale équilibre le temps de détection et le coût lié au volume des contrôles.
Quelle est la différence entre la surveillance API et les tests API ?
Les tests ont lieu en développement et en CI pour vérifier que les points de terminaison fonctionnent correctement avant la mise en production. La surveillance s’exécute en continu en production, suivant la disponibilité réelle, la latence et la précision des réponses au fil du temps. Les tests détectent les bugs avant le déploiement ; la surveillance détecte les pannes, régressions et dégradations après le déploiement.
La surveillance API remplace-t-elle l’APM ?
Non. La surveillance API teste de l’extérieur (point de vue utilisateur). L’APM suit le comportement interne — exécution du code, requêtes base de données, ressources serveurs. Les équipes matures utilisent les deux : synthétique pour les contrôles orientés client, APM pour le débogage de la cause racine.
Qu’est-ce que le TTFB et pourquoi est-ce important pour les APIs ?
Le Time to First Byte mesure le temps écoulé entre l’envoi d’une requête et la réception du premier octet de réponse. Du point de vue d’un client synthétique, cela inclut DNS, TCP, TLS, et le traitement serveur — mais pas le temps de transfert du corps. Un temps de réponse élevé avec un TTFB faible indique un payload volumineux ; un TTFB élevé indique un traitement serveur lent.
Combien de lieux de surveillance me faut-il ?
Pour des applications globales, au moins 5 sites distribués couvrant vos principales régions utilisateurs. Base typique : Amérique du Nord Est, Amérique du Nord Ouest, Europe de l’Ouest, Asie-Pacifique, Amérique du Sud. Cela permet de détecter les problèmes régionaux de CDN, les lacunes de propagation DNS et les anomalies de routage géographique que la surveillance d’un seul site manquerait totalement.
Détectez la prochaine panne API avant vos utilisateurs
Essai gratuit de 30 jours. Pas de carte bancaire. Accès complet à la plateforme. En service en moins de cinq minutes.
- Plus de 10 000 organisations
- Leader du monitoring depuis 1998
- SLA de disponibilité de 99,99 %