 OAuth 2.0 client credentials flows are a core mechanism for machine-to-machine API authentication. They enable background jobs, microservices, and system integrations to securely access APIs without user interaction.
OAuth 2.0 client credentials flows are a core mechanism for machine-to-machine API authentication. They enable background jobs, microservices, and system integrations to securely access APIs without user interaction.
However, while most teams spend time configuring these flows, far fewer ensure they are continuously monitored in production. This creates a critical blind spot: OAuth failures often surface only after dependent services begin failing.
This article focuses on how to monitor OAuth 2.0 client credentials flows end to end; from token issuance to authenticated API calls, so DevOps teams can detect failures early, isolate root causes faster, and maintain reliable integrations. If you want a broader foundation first, it helps to understand how Web API monitoring works and why external monitoring is essential for modern distributed systems.
Why Client Credentials Flows Break in Production (Even When Configured Correctly)
Most OAuth documentation treats the client credentials flow as a one-time setup exercise: register the client, request a token, call the API. In reality, OAuth is a live dependency, and like any dependency, it can and does fail in production.
Common failure scenarios include:
- Authorization server outages that prevent tokens from being issued
- Latency spikes at the token endpoint that slow every downstream request
- Client secret or certificate rotation errors that invalidate authentication
- Scope or permission changes that silently break previously working calls
- Partial failures where token issuance succeeds but the protected API fails
These issues are especially dangerous because they’re often misdiagnosed. An expired client secret may surface as a generic 401 error. A slow token endpoint may appear as degraded API performance. Without visibility into the authentication step, teams lose valuable time chasing the wrong root cause.
This risk is even higher in machine-to-machine flows because there is no user feedback loop. Unlike browser-based OAuth flows—where redirects, consent screens, and login failures are immediately visible—client credentials failures typically occur in the background. They can cascade through job schedulers, queues, or microservices before anyone notices.
For teams familiar with user-based OAuth flows, it’s worth noting that these operational risks differ from those seen in redirect-driven flows. For example, issues like redirect URI mismatches introduce very different failure modes, which we’ve covered separately in our article on authorization code flow redirect URI mismatch monitoring.
The takeaway is simple: a correctly configured client credentials flow is not a reliably operating one. Continuous monitoring is the only way to ensure it keeps working as intended.
What Needs to Be Monitored in a Client Credentials Flow
Monitoring an OAuth 2.0 client credentials flow requires more than confirming that an API endpoint responds successfully. Because authentication happens before any application logic is executed, failures at this stage can block all downstream communication. To detect problems early, monitoring must validate the flow as it actually runs in production.
Token Endpoint Availability and Response Validation
The token endpoint is the first and most critical dependency in a client credentials flow. If the authorization server is unavailable, slow, or returning malformed responses, no authenticated API call can succeed.
Effective monitoring at this stage confirms not only that the endpoint is reachable, but that it responds within acceptable time thresholds and returns a usable token. A successful HTTP status code alone is not sufficient. The response must include an access token, an expiration value, and the expected token type. When any of these elements are missing or invalid, the flow is already broken, even if the request technically “succeeds.”
This is where synthetic monitoring becomes essential. By simulating real token requests from external locations, teams can identify authentication issues before they impact production workloads or dependent services.
Authentication and Authorization Errors
Client credentials flows commonly fail due to authentication or authorization issues introduced by operational changes rather than code deployments. Credential rotation, scope updates, or policy changes at the authorization server can all invalidate previously working requests.
Errors such as invalid_client, invalid_scope, or insufficient_scope often surface only as generic failures unless responses are explicitly inspected. Without targeted monitoring, these errors are frequently mistaken for API outages, delaying root cause identification. Monitoring that differentiates authentication failures from application-level errors allows teams to respond faster and more accurately.
Token-Authenticated API Requests
Successfully obtaining a token does not guarantee that the protected API will accept it. Tokens may be rejected due to scope mismatches, expiration timing issues, or authorization logic within the resource server.
For this reason, monitoring must validate the full sequence: requesting the token, extracting it, and using it in an authenticated API call. Only by observing the complete flow can teams determine whether failures originate at the authorization server or the API itself.
This end-to-end visibility is a core capability of Web API monitoring software, which is designed to validate authentication, availability, and response correctness across multi-step API workflows.
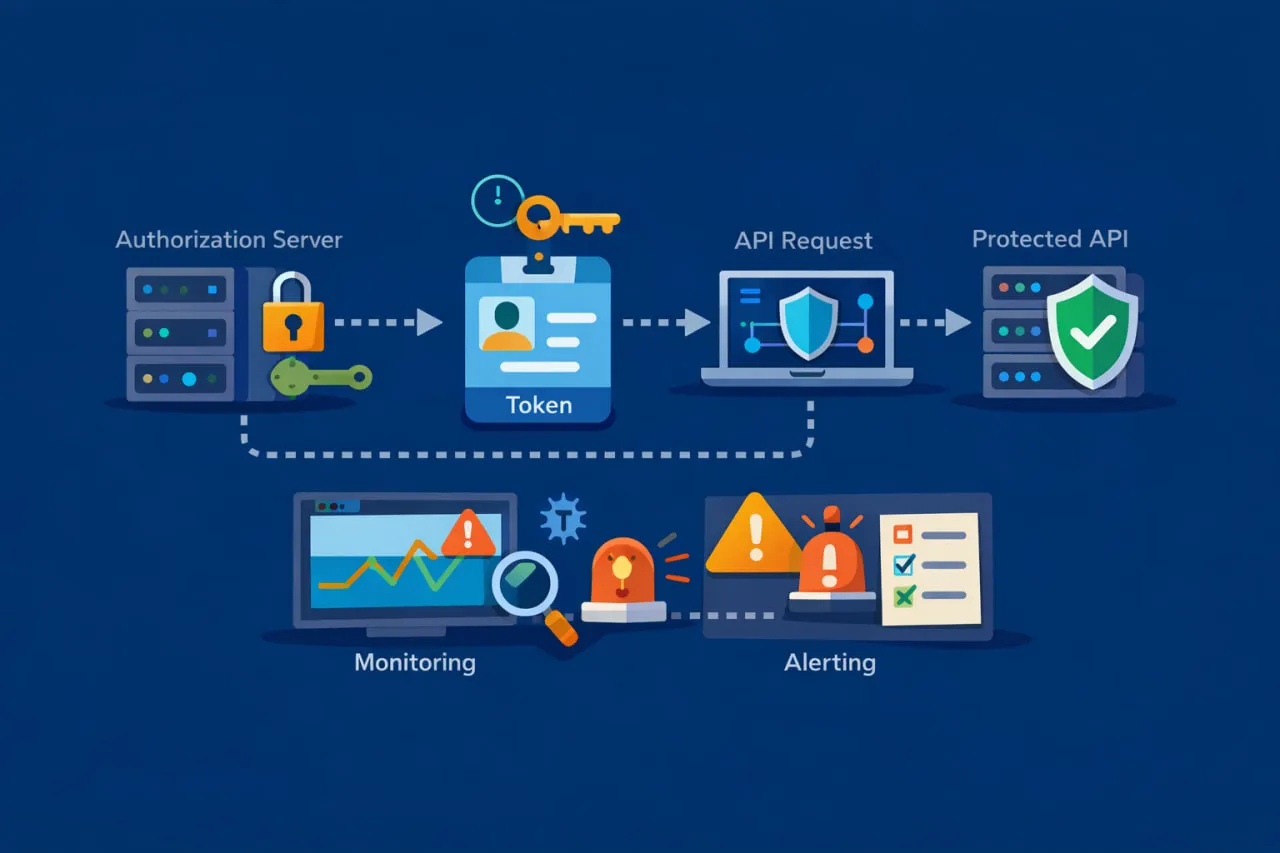
End-to-End Monitoring Pattern for Client Credentials OAuth
To monitor OAuth 2.0 client credentials flows reliably, it helps to think in terms of behavior, not endpoints. Checking a token endpoint in isolation or validating a protected API on its own doesn’t show where authentication actually breaks.
In production, the client credentials flow behaves as a sequence of dependent actions. Monitoring should reflect that reality.
At a high level, an effective pattern looks like this:
- Request an access token from the authorization server
- Validate the token response and extract the token
- Use the token immediately in a request to the protected API
Each step depends on the success of the one before it. When monitoring is structured this way, failures become self-explanatory. If the token request fails, the issue is clearly authentication-related. If the token is issued but the API call fails, the problem lies with authorization or the resource server.
This approach also eliminates guesswork during incidents. Instead of seeing a generic API failure, teams can pinpoint whether the breakdown occurred during token issuance, token usage, or API execution.
Because this monitoring pattern is external and outcome-based, it remains vendor-neutral. It works with any OAuth 2.0 authorization server, whether that’s a managed identity platform or a custom implementation. The focus stays on observable behavior rather than internal configuration details.
Over time, this end-to-end view also surfaces performance signals that single checks miss. Gradual increases in token request latency, for example, can indicate authorization server degradation long before it becomes unavailable. When combined with historical dashboards and reports, these trends give teams early warning and valuable context during troubleshooting.
This type of chained validation is a core capability of Web API monitoring software, which is built to execute multi-step API workflows, apply assertions at each stage, and alert teams as soon as any part of the flow fails.
Monitoring OAuth Client Credentials with Multi-Step API Checks
Monitoring OAuth-protected APIs using single, standalone checks often creates a false sense of confidence. A token endpoint can be healthy while the protected API is failing, or an API can be responsive while authentication is already broken.
Client credentials flows don’t operate as isolated requests. They work as a dependent sequence, and monitoring needs to reflect that reality.
With multi-step API checks, the flow is validated exactly as it runs in production:
- First, an access token is requested from the authorization server
- Next, the token is extracted and used to call the protected API
Because both steps are evaluated together, failures are easier to interpret and faster to resolve. If the token request fails, the issue is clearly authentication-related. If the token is issued but the API call fails, the problem lies with authorization or the resource server.
This approach is especially valuable when dealing with token expiration and credential rotation. Client credentials tokens are intentionally short-lived. Issues such as misaligned expiration timing, caching behavior, or rotated secrets can break integrations even though the token endpoint itself remains available. Multi-step monitoring surfaces these problems because it continuously exercises the full authentication path.
It also improves visibility into partial outages, such as:
- The authorization server issuing tokens while the API is unavailable
- The API responding successfully while token requests fail
By validating each step in sequence, teams can immediately see where the breakdown occurs instead of guessing.
For a deeper walkthrough of this approach, our guide on OAuth web API monitoring explains how multi-task monitoring setups validate authentication and API availability together rather than as disconnected checks.
Common OAuth Client Credentials Errors You Should Alert On
OAuth client credentials failures rarely present themselves clearly. In many cases, they appear as generic API errors, which slows down troubleshooting unless authentication-specific conditions are monitored explicitly.
To avoid diagnosing the wrong problem, teams should alert on OAuth-related failure signals, not just overall API availability.
Invalid Client Errors
invalid_client errors almost always indicate a problem on the authorization side rather than in application code. They commonly occur after credentials are rotated, revoked, or expired.
When this happens, API requests fail immediately, even though the API itself may still be healthy. Without monitoring the token request directly, these failures are often mistaken for application outages instead of authentication issues.
Scope and Authorization Failures
Authorization-related errors are another frequent source of breakage in client credentials flows.
An invalid_scope error typically appears after permission or scope definitions change at the authorization server. An insufficient_scope error means the token is valid but does not grant access to the requested resource. In both cases, authentication succeeds, but authorization fails.
Because these errors occur after token issuance, they are easy to misinterpret unless monitoring validates both the token response and the authenticated API call.
Repeated 401 or 403 Responses
Intermittent 401 and 403 responses are often dismissed as transient API issues. In practice, they can signal deeper OAuth-related problems, such as authorization server instability, policy enforcement changes, or token validation failures at the resource server.
Alerting on these responses in the context of the full OAuth flow helps teams understand whether failures originate during authentication or authorization.
Token Endpoint Timeouts and Unexpected Responses
Not all OAuth failures are explicit. Token endpoint timeouts or unexpected response structures often point to authorization server degradation, network issues, or misconfiguration.
Monitoring that validates both response timing and response structure ensures these issues are detected early, before they cascade into broader integration failures.
For deeper guidance on token-level validation, our article on monitoring JWT tokens and OAuth token endpoints explains how inspecting token responses helps distinguish authentication failures from API-level issues.
Implementing OAuth Client Credentials Monitoring (Practical Setup)
Once you know what to monitor, the next step is implementing OAuth client credentials monitoring in a way that’s safe, repeatable, and aligned with real production behavior. The objective isn’t to replicate your OAuth configuration in detail, but to validate it externally, the same way a dependent service would experience it.
Start With a Token Request Check
Implementation begins by creating a monitoring task that requests an access token from the authorization server using the same parameters your applications rely on. This check should confirm that the token endpoint is reachable and responding as expected.
More importantly, it should validate that the response actually contains a usable access token and the expected metadata. A successful HTTP response without a valid token still represents a broken authentication flow.
If you’re setting this up for the first time, the guide on how to configure REST API monitoring tasks walks through how to structure and validate these token requests correctly.
Chain the Token Into an Authenticated API Call
Once the token request is validated, the next step is to use that token immediately in a request to the protected API. This confirms that the resource server accepts the token and that authorization is aligned with the required scopes and permissions.
Together, these two steps form a single monitored flow that reflects how client credentials authentication works in production. If either step fails, the issue can be isolated quickly to authentication or authorization rather than treated as a generic API outage.
As your monitoring evolves, you may need to refine assertions, adjust timeouts, or extend validation logic. The documentation on how to add or edit REST API monitoring tasks explains how to safely update existing checks without disrupting coverage.
Handle Credentials Securely and Alert Early
Because client credentials flows rely on secrets or certificates, monitoring configurations should never hard-code sensitive values. Credentials should be stored securely and referenced dynamically so monitoring continues to work through rotations and updates.
Alerts should trigger as soon as any step in the flow fails. Early notification is what allows teams to address OAuth issues before integrations, jobs, or dependent services begin failing at scale.
For a broader walkthrough that ties these pieces together, the web API monitoring setup guide shows how to structure multi-step API monitoring with proper validation and alerting.
Why OAuth Monitoring Is a Reliability Requirement (Not a Security Nice-to-Have)
OAuth is often discussed primarily in the context of security. While secure authentication is essential, treating OAuth purely as a security concern overlooks its role as a critical runtime dependency. When OAuth fails, integrations fail, regardless of how healthy the underlying API may be.
In client credentials flows, every background job, service-to-service call, or automated integration depends on successful token issuance. If the authorization server becomes unavailable or starts responding slowly, those failures propagate immediately across dependent systems.
OAuth as a Production Dependency
From an operational standpoint, OAuth behaves like any other external dependency. It has availability characteristics, performance thresholds, and failure modes that directly affect system reliability.
When OAuth is not monitored, teams often discover issues only after:
- Scheduled jobs stop running
- Queues begin backing up
- Downstream services start returning errors
By contrast, monitoring OAuth flows allows teams to detect problems at the authentication layer before business logic is impacted.
Reliability Signals Hidden in Authentication
OAuth failures don’t always show up as clear outages. Subtle issues, such as increasing token request latency or intermittent authorization errors, can signal degradation long before a full failure occurs.
By monitoring authentication as part of the API workflow, teams gain visibility into:
- Token issuance latency trends
- Authentication error frequency
- Authorization failures tied to scope or policy changes
When these signals are surfaced in dashboards and reports, they provide valuable historical context during incident response and capacity planning.
Reducing MTTR With External Validation
One of the biggest operational benefits of OAuth monitoring is faster root cause identification. Instead of debating whether an outage is caused by the API, the identity provider, or the network, teams can see exactly where the failure occurs.
External monitoring validates OAuth behavior from the outside, using the same perspective as real consumers. This reduces guesswork, shortens mean time to resolution, and helps teams focus on fixing the right component.
For teams responsible for production reliability, OAuth monitoring is not optional. It is part of maintaining predictable, dependable API integrations.
Get Proactive Visibility Into OAuth Client Credentials Flows
OAuth 2.0 client credentials flows are easy to take for granted because they run silently in the background. When they fail, however, they tend to fail fast and take critical integrations with them.
By monitoring the full client credentials flow end to end, teams gain visibility into authentication and authorization issues before they cascade into larger incidents. Instead of reacting to broken jobs or failing services, you can detect token issuance problems, authorization errors, and performance degradation at the point where they actually begin.
This kind of proactive insight is especially important in distributed systems, where a single OAuth dependency may support dozens of services or integrations. External monitoring helps ensure those dependencies remain available, performant, and predictable over time.
If you want to see how this works in practice, you can see how Dotcom-Monitor monitors OAuth-protected APIs using multi-step Web API monitoring with assertions, alerting, and historical reporting built in.
