 Les flux OAuth 2.0 client credentials constituent un mécanisme fondamental pour l’authentification d’API de machine à machine. Ils permettent aux tâches en arrière-plan, aux microservices et aux intégrations système d’accéder aux API de manière sécurisée, sans interaction utilisateur.
Les flux OAuth 2.0 client credentials constituent un mécanisme fondamental pour l’authentification d’API de machine à machine. Ils permettent aux tâches en arrière-plan, aux microservices et aux intégrations système d’accéder aux API de manière sécurisée, sans interaction utilisateur.
Cependant, même si la plupart des équipes consacrent du temps à la configuration de ces flux, beaucoup moins s’assurent qu’ils sont surveillés en continu en production. Cela crée un angle mort critique : les défaillances OAuth ne se manifestent souvent qu’après que des services dépendants commencent à tomber en panne.
Cet article explique comment surveiller les flux OAuth 2.0 client credentials de bout en bout, depuis l’émission du jeton jusqu’aux appels d’API authentifiés, afin que les équipes DevOps puissent détecter les défaillances plus tôt, isoler les causes racines plus rapidement et maintenir des intégrations fiables. Pour disposer d’une base plus large au préalable, il est utile de comprendre le fonctionnement de la surveillance des API Web et pourquoi la surveillance externe est essentielle pour les systèmes distribués modernes.
Pourquoi les flux Client Credentials se cassent en production (même lorsqu’ils sont correctement configurés)
La plupart de la documentation OAuth traite le flux client credentials comme un exercice de configuration ponctuel : enregistrer le client, demander un jeton, appeler l’API. En réalité, OAuth est une dépendance vivante et, comme toute dépendance, elle peut et finit par tomber en panne en production.
Les scénarios de défaillance courants incluent :
- Des indisponibilités du serveur d’autorisation qui empêchent l’émission des jetons
- Des pics de latence sur l’endpoint de jeton qui ralentissent chaque requête en aval
- Des erreurs de rotation de secret client ou de certificat qui invalident l’authentification
- Des changements de périmètre ou de permissions qui cassent silencieusement des appels auparavant fonctionnels
- Des défaillances partielles où l’émission du jeton réussit, mais l’API protégée échoue
Ces problèmes sont particulièrement dangereux car ils sont souvent mal diagnostiqués. Un secret client expiré peut apparaître comme une erreur 401 générique. Un endpoint de jeton lent peut ressembler à une dégradation des performances de l’API. Sans visibilité sur l’étape d’authentification, les équipes perdent un temps précieux à rechercher la mauvaise cause racine.
Ce risque est encore plus élevé dans les flux de machine à machine, car il n’y a aucune boucle de retour utilisateur. Contrairement aux flux OAuth basés sur le navigateur — où les redirections, écrans de consentement et échecs de connexion sont immédiatement visibles — les défaillances client credentials se produisent généralement en arrière-plan. Elles peuvent se propager à travers des ordonnanceurs de tâches, des files d’attente ou des microservices avant que quelqu’un ne s’en rende compte.
Pour les équipes familières des flux OAuth orientés utilisateur, il est important de noter que ces risques opérationnels diffèrent de ceux observés dans les flux basés sur les redirections. Par exemple, des problèmes tels que les incohérences d’URI de redirection introduisent des modes de défaillance très différents, que nous avons traités séparément dans notre article sur la surveillance des incompatibilités d’URI de redirection dans le flux authorization code.
La conclusion est simple : un flux client credentials correctement configuré n’est pas nécessairement un flux qui fonctionne de manière fiable. La surveillance continue est le seul moyen de garantir qu’il continue de fonctionner comme prévu.
Ce qui doit être surveillé dans un flux Client Credentials
La surveillance d’un flux OAuth 2.0 client credentials nécessite plus que la simple confirmation qu’un endpoint d’API répond avec succès. Comme l’authentification se produit avant l’exécution de toute logique applicative, des défaillances à ce stade peuvent bloquer toute communication en aval. Pour détecter les problèmes tôt, la surveillance doit valider le flux tel qu’il s’exécute réellement en production.
Disponibilité de l’endpoint de jeton et validation de la réponse
L’endpoint de jeton est la première et la plus critique des dépendances dans un flux client credentials. Si le serveur d’autorisation est indisponible, lent ou renvoie des réponses mal formées, aucun appel d’API authentifié ne peut aboutir.
Une surveillance efficace à ce stade confirme non seulement que l’endpoint est accessible, mais aussi qu’il répond dans des délais acceptables et renvoie un jeton exploitable. Un code de statut HTTP réussi, à lui seul, n’est pas suffisant. La réponse doit inclure un jeton d’accès, une valeur d’expiration et le type de jeton attendu. Lorsque l’un de ces éléments est manquant ou invalide, le flux est déjà rompu, même si la requête « réussit » techniquement.
C’est là que la surveillance synthétique devient essentielle. En simulant de véritables requêtes de jeton depuis des emplacements externes, les équipes peuvent identifier les problèmes d’authentification avant qu’ils n’affectent les charges de travail en production ou les services dépendants.
Erreurs d’authentification et d’autorisation
Les flux client credentials échouent fréquemment en raison de problèmes d’authentification ou d’autorisation introduits par des changements opérationnels plutôt que par des déploiements de code. La rotation des identifiants, les mises à jour de périmètre ou les changements de politique sur le serveur d’autorisation peuvent tous invalider des requêtes auparavant fonctionnelles.
Des erreurs telles que invalid_client, invalid_scope ou insufficient_scope apparaissent souvent uniquement comme des échecs génériques, à moins que les réponses ne soient explicitement inspectées. Sans surveillance ciblée, ces erreurs sont fréquemment confondues avec des pannes d’API, ce qui retarde l’identification de la cause racine. Une surveillance qui distingue les échecs d’authentification des erreurs applicatives permet aux équipes de réagir plus rapidement et plus précisément.
Requêtes d’API authentifiées par jeton
Obtenir un jeton avec succès ne garantit pas que l’API protégée l’acceptera. Les jetons peuvent être rejetés en raison d’incohérences de périmètre, de problèmes de synchronisation d’expiration ou de logique d’autorisation au sein du serveur de ressources.
Pour cette raison, la surveillance doit valider la séquence complète : demander le jeton, l’extraire et l’utiliser dans un appel d’API authentifié. Ce n’est qu’en observant l’ensemble du flux que les équipes peuvent déterminer si les défaillances proviennent du serveur d’autorisation ou de l’API elle-même.
Cette visibilité de bout en bout est une capacité clé des logiciels de surveillance des API Web, conçus pour valider l’authentification, la disponibilité et la conformité des réponses dans des workflows d’API en plusieurs étapes.
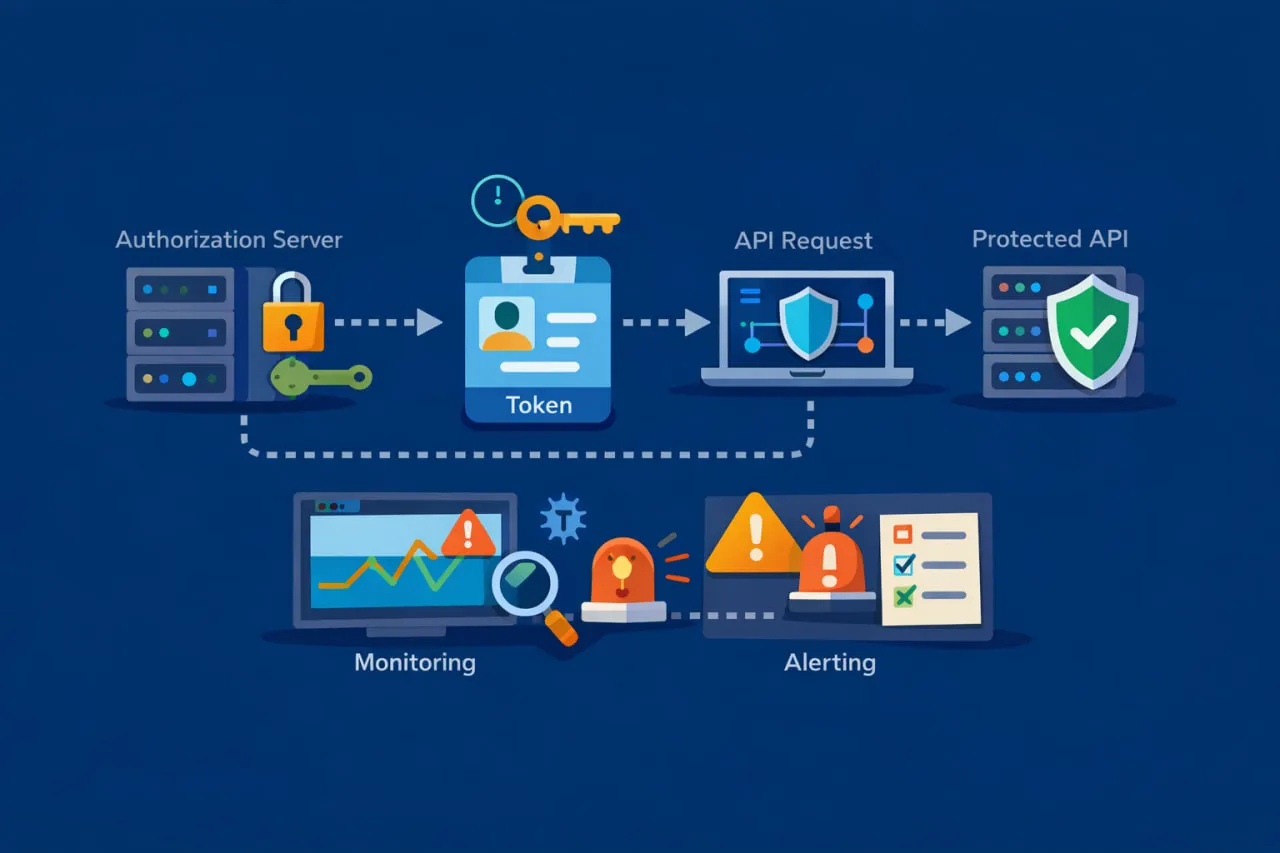
Schéma de surveillance de bout en bout pour OAuth Client Credentials
Pour surveiller de manière fiable les flux OAuth 2.0 client credentials, il est utile de raisonner en termes de comportement, et non d’endpoints. Vérifier un endpoint de jeton isolément ou valider une API protégée seule ne montre pas où l’authentification se rompt réellement.
En production, le flux client credentials se comporte comme une séquence d’actions dépendantes. La surveillance doit refléter cette réalité.
À haut niveau, un schéma efficace ressemble à ceci :
- Demander un jeton d’accès au serveur d’autorisation
- Valider la réponse du jeton et extraire le jeton
- Utiliser immédiatement le jeton dans une requête vers l’API protégée
Chaque étape dépend du succès de la précédente. Lorsque la surveillance est structurée de cette manière, les défaillances deviennent explicites. Si la requête de jeton échoue, le problème est clairement lié à l’authentification. Si le jeton est émis mais que l’appel API échoue, le problème se situe au niveau de l’autorisation ou du serveur de ressources.
Cette approche élimine également les suppositions lors des incidents. Au lieu de constater une défaillance API générique, les équipes peuvent identifier précisément si la rupture s’est produite lors de l’émission du jeton, de son utilisation ou de l’exécution de l’API.
Parce que ce schéma de surveillance est externe et basé sur les résultats, il reste neutre vis-à-vis des fournisseurs. Il fonctionne avec n’importe quel serveur d’autorisation OAuth 2.0, qu’il s’agisse d’une plateforme d’identité managée ou d’une implémentation personnalisée. L’accent reste mis sur le comportement observable plutôt que sur les détails internes de configuration.
Avec le temps, cette vue de bout en bout met également en évidence des signaux de performance que des vérifications isolées ne détectent pas. Des augmentations progressives de la latence des requêtes de jeton, par exemple, peuvent indiquer une dégradation du serveur d’autorisation bien avant qu’il ne devienne indisponible. Combinées à des tableaux de bord et rapports historiques, ces tendances offrent une alerte précoce et un contexte précieux lors du dépannage.
Ce type de validation chaînée est une capacité fondamentale des logiciels de surveillance des API Web, conçus pour exécuter des workflows d’API multi-étapes, appliquer des assertions à chaque étape et alerter les équipes dès qu’une partie du flux échoue.
Surveiller OAuth Client Credentials avec des contrôles d’API multi-étapes
Surveiller des API protégées par OAuth à l’aide de contrôles uniques et autonomes crée souvent un faux sentiment de confiance. Un endpoint de jeton peut être sain alors que l’API protégée échoue, ou une API peut répondre alors que l’authentification est déjà rompue.
Les flux client credentials ne fonctionnent pas comme des requêtes isolées. Ils opèrent comme une séquence dépendante, et la surveillance doit refléter cette réalité.
Avec des contrôles d’API multi-étapes, le flux est validé exactement tel qu’il s’exécute en production :
- D’abord, un jeton d’accès est demandé au serveur d’autorisation
- Ensuite, le jeton est extrait et utilisé pour appeler l’API protégée
Parce que les deux étapes sont évaluées ensemble, les défaillances sont plus faciles à interpréter et plus rapides à résoudre. Si la requête de jeton échoue, le problème est clairement lié à l’authentification. Si le jeton est émis mais que l’appel API échoue, le problème se situe au niveau de l’autorisation ou du serveur de ressources.
Cette approche est particulièrement utile lorsqu’il s’agit de l’expiration des jetons et de la rotation des identifiants. Les jetons client credentials sont volontairement de courte durée. Des problèmes tels qu’un mauvais alignement des délais d’expiration, des comportements de cache ou des secrets rotés peuvent casser des intégrations même lorsque l’endpoint de jeton reste disponible. La surveillance multi-étapes met ces problèmes en évidence car elle exerce en continu l’ensemble du chemin d’authentification.
Elle améliore également la visibilité sur les pannes partielles, telles que :
- Le serveur d’autorisation émettant des jetons alors que l’API est indisponible
- L’API répondant avec succès alors que les requêtes de jeton échouent
En validant chaque étape dans l’ordre, les équipes peuvent voir immédiatement où la rupture se produit, au lieu de supposer.
Pour un aperçu plus détaillé de cette approche, notre guide sur la surveillance des API Web OAuth explique comment les configurations de surveillance multi-tâches valident conjointement l’authentification et la disponibilité des API, plutôt que comme des contrôles déconnectés.
Erreurs courantes OAuth Client Credentials sur lesquelles vous devez alerter
Les défaillances OAuth client credentials se présentent rarement de manière évidente. Dans de nombreux cas, elles apparaissent comme des erreurs API génériques, ce qui ralentit le dépannage à moins que des conditions spécifiques à l’authentification ne soient explicitement surveillées.
Pour éviter de diagnostiquer le mauvais problème, les équipes doivent alerter sur les signaux de défaillance liés à OAuth, et pas uniquement sur la disponibilité globale de l’API.
Erreurs Invalid Client
Les erreurs invalid_client indiquent presque toujours un problème du côté de l’autorisation plutôt que dans le code applicatif. Elles surviennent fréquemment après la rotation, la révocation ou l’expiration des identifiants.
Lorsque cela se produit, les requêtes API échouent immédiatement, même si l’API elle-même reste saine. Sans surveillance directe de la requête de jeton, ces défaillances sont souvent prises pour des pannes applicatives plutôt que pour des problèmes d’authentification.
Échecs de périmètre et d’autorisation
Les erreurs liées à l’autorisation constituent une autre source fréquente de rupture dans les flux client credentials.
Une erreur invalid_scope apparaît généralement après des modifications des définitions de permissions ou de périmètres sur le serveur d’autorisation. Une erreur insufficient_scope signifie que le jeton est valide, mais qu’il n’accorde pas l’accès à la ressource demandée. Dans les deux cas, l’authentification réussit, mais l’autorisation échoue.
Comme ces erreurs se produisent après l’émission du jeton, elles sont faciles à mal interpréter à moins que la surveillance ne valide à la fois la réponse du jeton et l’appel d’API authentifié.
Réponses 401 ou 403 répétées
Des réponses 401 et 403 intermittentes sont souvent écartées comme des problèmes API transitoires. En pratique, elles peuvent signaler des problèmes OAuth plus profonds, tels que l’instabilité du serveur d’autorisation, des changements dans l’application des politiques ou des échecs de validation des jetons au niveau du serveur de ressources.
Alerter sur ces réponses dans le contexte du flux OAuth complet aide les équipes à comprendre si les défaillances proviennent de l’authentification ou de l’autorisation.
Timeouts de l’endpoint de jeton et réponses inattendues
Toutes les défaillances OAuth ne sont pas explicites. Les timeouts de l’endpoint de jeton ou des structures de réponse inattendues indiquent souvent une dégradation du serveur d’autorisation, des problèmes réseau ou une mauvaise configuration.
Une surveillance qui valide à la fois le temps de réponse et la structure de la réponse garantit que ces problèmes sont détectés tôt, avant qu’ils ne se transforment en défaillances d’intégration plus larges.
Pour des conseils plus approfondis sur la validation au niveau du jeton, notre article sur la surveillance des jetons JWT et des endpoints de jeton OAuth explique comment l’inspection des réponses de jeton aide à distinguer les échecs d’authentification des problèmes au niveau de l’API.
Mise en œuvre de la surveillance OAuth Client Credentials (configuration pratique)
Une fois que vous savez quoi surveiller, l’étape suivante consiste à mettre en œuvre la surveillance OAuth client credentials d’une manière sûre, reproductible et alignée sur le comportement réel en production. L’objectif n’est pas de reproduire votre configuration OAuth en détail, mais de la valider de manière externe, de la même façon qu’un service dépendant l’expérimenterait.
Commencer par un contrôle de requête de jeton
La mise en œuvre commence par la création d’une tâche de surveillance qui demande un jeton d’accès au serveur d’autorisation en utilisant les mêmes paramètres que ceux sur lesquels reposent vos applications. Ce contrôle doit confirmer que l’endpoint de jeton est accessible et répond comme attendu.
Plus important encore, il doit valider que la réponse contient réellement un jeton d’accès exploitable et les métadonnées attendues. Une réponse HTTP réussie sans jeton valide représente toujours un flux d’authentification défaillant.
Si vous mettez cela en place pour la première fois, le guide expliquant comment configurer des tâches de surveillance d’API REST détaille la structuration et la validation correctes de ces requêtes de jeton.
Chaîner le jeton dans un appel d’API authentifié
Une fois la requête de jeton validée, l’étape suivante consiste à utiliser immédiatement ce jeton dans une requête vers l’API protégée. Cela confirme que le serveur de ressources accepte le jeton et que l’autorisation est alignée avec les périmètres et permissions requis.
Ensemble, ces deux étapes forment un flux unique surveillé qui reflète le fonctionnement de l’authentification client credentials en production. Si l’une ou l’autre étape échoue, le problème peut être isolé rapidement à l’authentification ou à l’autorisation, plutôt que d’être traité comme une panne d’API générique.
À mesure que votre surveillance évolue, vous devrez peut-être affiner les assertions, ajuster les timeouts ou étendre la logique de validation. La documentation expliquant comment ajouter ou modifier des tâches de surveillance d’API REST détaille la manière de mettre à jour en toute sécurité des contrôles existants sans interrompre la couverture.
Gérer les identifiants de manière sécurisée et alerter tôt
Étant donné que les flux client credentials reposent sur des secrets ou des certificats, les configurations de surveillance ne doivent jamais coder en dur des valeurs sensibles. Les identifiants doivent être stockés de manière sécurisée et référencés dynamiquement afin que la surveillance continue de fonctionner lors des rotations et des mises à jour.
Les alertes doivent se déclencher dès qu’une étape du flux échoue. La notification précoce permet aux équipes de traiter les problèmes OAuth avant que les intégrations, les tâches ou les services dépendants ne commencent à tomber en panne à grande échelle.
Pour une vue d’ensemble reliant ces éléments, le guide de configuration de la surveillance des API Web montre comment structurer une surveillance d’API multi-étapes avec une validation et des alertes appropriées.
Pourquoi la surveillance OAuth est une exigence de fiabilité (et non un simple plus de sécurité)
OAuth est souvent abordé principalement sous l’angle de la sécurité. Bien que l’authentification sécurisée soit essentielle, traiter OAuth uniquement comme une préoccupation de sécurité occulte son rôle de dépendance critique à l’exécution. Lorsque OAuth échoue, les intégrations échouent, quelle que soit la santé de l’API sous-jacente.
Dans les flux client credentials, chaque tâche en arrière-plan, appel inter-services ou intégration automatisée dépend de l’émission réussie de jetons. Si le serveur d’autorisation devient indisponible ou commence à répondre lentement, ces défaillances se propagent immédiatement à l’ensemble des systèmes dépendants.
OAuth en tant que dépendance de production
D’un point de vue opérationnel, OAuth se comporte comme toute autre dépendance externe. Il possède des caractéristiques de disponibilité, des seuils de performance et des modes de défaillance qui affectent directement la fiabilité du système.
Lorsque OAuth n’est pas surveillé, les équipes découvrent souvent les problèmes seulement après que :
- Des tâches planifiées cessent de s’exécuter
- Des files d’attente commencent à s’accumuler
- Des services en aval commencent à renvoyer des erreurs
À l’inverse, la surveillance des flux OAuth permet aux équipes de détecter les problèmes au niveau de l’authentification avant que la logique métier ne soit impactée.
Signaux de fiabilité cachés dans l’authentification
Les défaillances OAuth ne se manifestent pas toujours par des pannes évidentes. Des problèmes subtils, tels qu’une augmentation progressive de la latence des requêtes de jeton ou des erreurs d’autorisation intermittentes, peuvent signaler une dégradation bien avant qu’une défaillance complète ne survienne.
En surveillant l’authentification dans le cadre du workflow d’API, les équipes gagnent en visibilité sur :
- Les tendances de latence d’émission des jetons
- La fréquence des erreurs d’authentification
- Les échecs d’autorisation liés à des changements de périmètre ou de politique
Lorsque ces signaux sont présentés dans des tableaux de bord et rapports, ils fournissent un contexte historique précieux lors de la réponse aux incidents et de la planification de capacité.
Réduction du MTTR grâce à la validation externe
L’un des principaux avantages opérationnels de la surveillance OAuth est l’identification plus rapide des causes racines. Au lieu de débattre pour savoir si une panne est causée par l’API, le fournisseur d’identité ou le réseau, les équipes peuvent voir exactement où la défaillance se produit.
La surveillance externe valide le comportement OAuth depuis l’extérieur, en utilisant la même perspective que les consommateurs réels. Cela réduit les suppositions, raccourcit le temps moyen de résolution et aide les équipes à se concentrer sur la correction du bon composant.
Pour les équipes responsables de la fiabilité en production, la surveillance OAuth n’est pas optionnelle. Elle fait partie du maintien d’intégrations d’API prévisibles et fiables.
Obtenir une visibilité proactive sur les flux OAuth Client Credentials
Les flux OAuth 2.0 client credentials sont faciles à tenir pour acquis car ils s’exécutent silencieusement en arrière-plan. Lorsqu’ils échouent, en revanche, ils ont tendance à échouer rapidement et à emporter avec eux des intégrations critiques.
En surveillant l’ensemble du flux client credentials de bout en bout, les équipes gagnent en visibilité sur les problèmes d’authentification et d’autorisation avant qu’ils ne se transforment en incidents plus importants. Au lieu de réagir à des tâches cassées ou à des services défaillants, il est possible de détecter les problèmes d’émission de jetons, les erreurs d’autorisation et la dégradation des performances au point précis où ils commencent réellement.
Ce type d’analyse proactive est particulièrement important dans les systèmes distribués, où une seule dépendance OAuth peut prendre en charge des dizaines de services ou d’intégrations. La surveillance externe permet de garantir que ces dépendances restent disponibles, performantes et prévisibles dans le temps.
Si vous souhaitez voir comment cela fonctionne en pratique, vous pouvez découvrir comment Dotcom-Monitor surveille les API protégées par OAuth à l’aide de la surveillance d’API Web multi-étapes avec assertions, alertes et rapports historiques intégrés.
