Home » Soluciones » Monitoreo Sintético
Software Automatizado de Monitoreo Sintético para Aplicaciones, APIs y Sitios Web
El software de monitoreo sintético de Dotcom-Monitor simula el comportamiento real del usuario 24/7 para detectar trayectorias de usuario rotas y fallos "silenciosos" antes de que afecten a tus clientes. Monitorea sitios web, APIs y aplicaciones web complejas en más de 30 ubicaciones globales con pruebas en navegadores reales, reproducciones de video detalladas, informes de gráficos de cascada y alertas proactivas de rendimiento.
Primeras Alertas
En 10 minutos
Prueba de 30 Días
Todas las funciones
Soporte 24/7
Equipo experto
- No se requiere tarjeta de crédito
- Todas las funciones premium incluidas
Más de 10,000
Organizaciones en todo el mundo
99.99%
SLA de tiempo de actividad de la plataforma
Más de 30
Ubicaciones globales de monitoreo
Desde 1998
Líder en monitoreo de sitios web
62%
reducción en MTTR
“Detectamos una regresión en la API de pagos en 90 segundos tras el despliegue. Antes de Dotcom-Monitor, eso hubiera sido un ticket P1 de un cliente tres horas después.”
Michael Reeves
Sr. SRE, Plataforma SaaS Empresarial
$140K
en pérdidas por tiempo de inactividad evitadas
“La supervisión sintética solo en nuestro flujo de pago pagó la plataforma en el primer mes. Ahora detectamos fallas de autenticación antes de que un solo usuario se vea afectado.”
Sarah Kim
VP de Ingeniería, Fintech B2B
4.5
Capterra
82 reseñas
4.5
G2 | Más fácil de usar
Los usuarios nos aman · 2025
4.5
Software Advice
Recomendado
Comienza en minutos
Configura tu software de supervisión sintética en solo 3 pasos
No hay agentes que instalar. No se requieren cambios de código. Configura tu primera supervisión sintética y recibe alertas antes de que tus usuarios noten que algo está mal.
Grabar
Abre el EveryStep Recorder y navega por tu sitio.
Desplegar
Elige entre más de 30 puntos de control globales.
Resolver
Reciba una notificación en el momento en que un recorrido falla, con un video.
Paso 01
Paso 02
Paso 03

Grabe Recorridos Reales de Usuarios con EveryStep
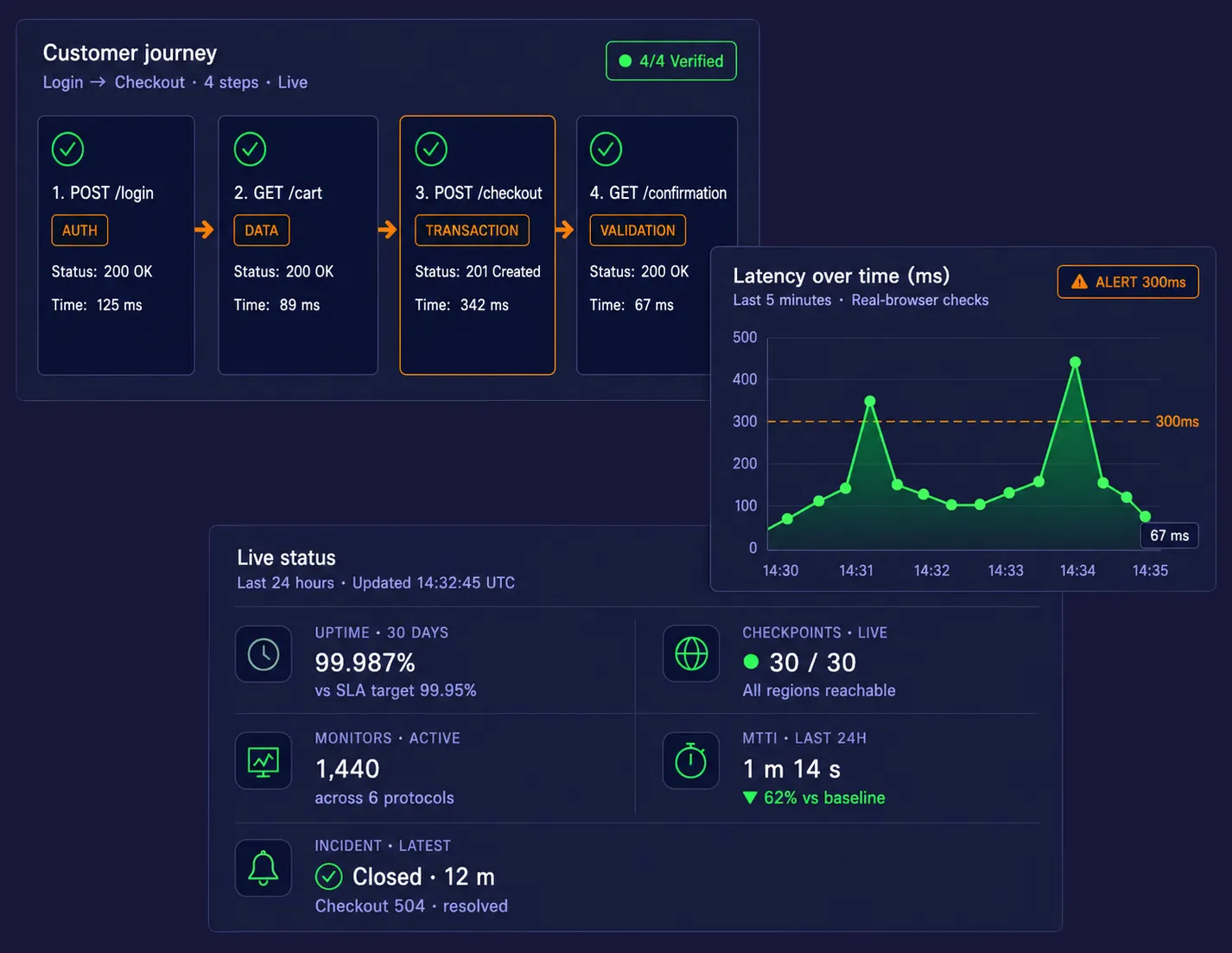
Use el Grabador Web EveryStep para crear scripts de monitoreo sintético simplemente interactuando con su sitio o aplicación. Grabe flujos de trabajo complejos como el pago en varias páginas, inicio de sesión SSO, registro de cuenta, acceso restringido al panel y acciones en el carrito sin necesidad de scripting manual. Este enfoque sin código facilita la implementación de monitoreo de aplicaciones web rápidamente mientras protege las rutas que generan ingresos y son más importantes.
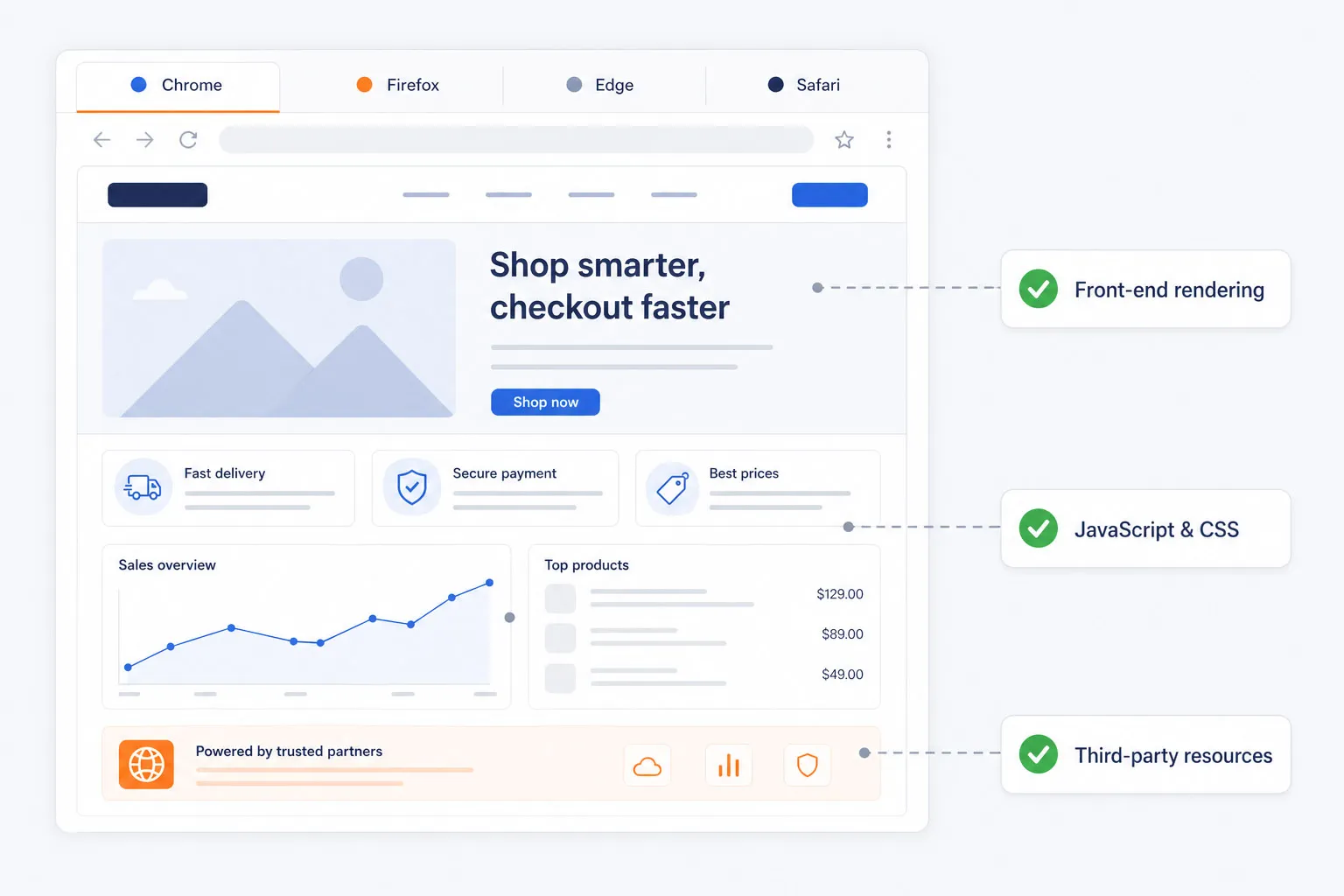
Pruebe en Navegadores Reales, No Simulaciones Simplificadas
Las comprobaciones básicas de disponibilidad no pueden detectar problemas en el renderizado del front-end, errores de JavaScript, problemas de CSS o recursos de terceros lentos. Dotcom-Monitor ejecuta pruebas sintéticas en navegadores reales Chrome, Firefox, Edge y Safari para que los equipos puedan validar el rendimiento y la funcionalidad exactamente como los usuarios las experimentan.
Esto brinda a ingeniería, QA y equipos digitales una visión más precisa de la salud real de la aplicación web.
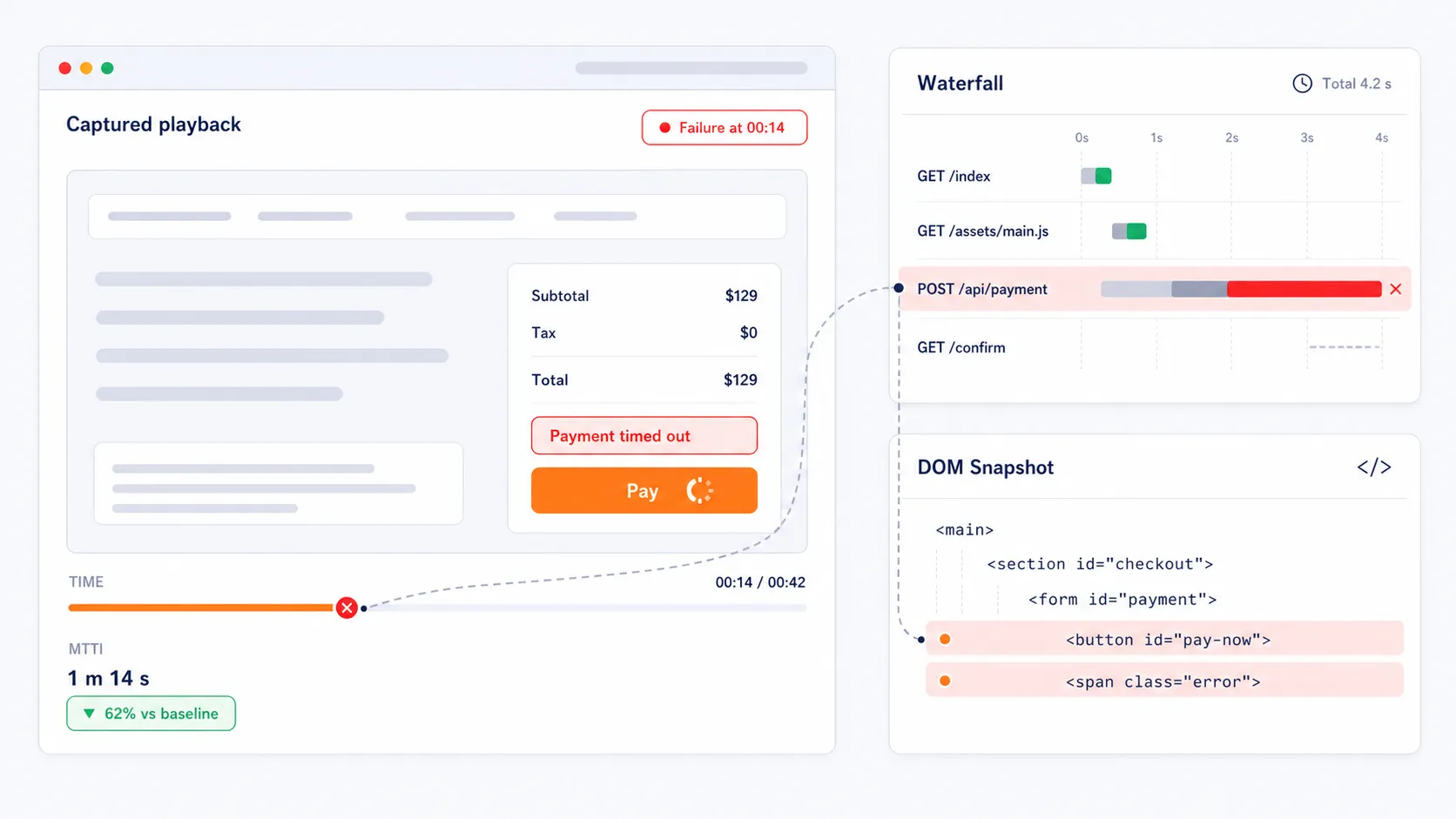
Capture Evidencia Visual para una Resolución más Rápida de Problemas
Cuando una transacción falla, la plataforma captura reproducción en video de la prueba fallida, gráficos de cascada y capturas completas del DOM. Estos diagnósticos visuales ayudan a los equipos a acelerar el análisis de la causa raíz mostrando la llamada API exacta, elemento de página, redireccionamiento o script que causó la falla del recorrido. En lugar de adivinar dónde está el problema, los equipos obtienen evidencia inmediata que reduce el Tiempo Medio de Identificación.
Detecte Fallos Silenciosos en la Conversión Antes de Perder Ingresos
Un sitio puede parecer disponible mientras acciones críticas como inicio de sesión, pago, búsqueda o acceso a cuenta fallan silenciosamente tras bambalinas. Estas fallas silenciosas pueden disminuir las tasas de conversión, desperdiciar tráfico pagado y dañar la confianza del cliente. Dotcom-Monitor ayuda a los equipos a detectar estos problemas con comprobaciones sintéticas que pueden ejecutarse tan frecuente como cada 60 segundos, dando a los equipos digitales una manera proactiva de proteger la experiencia del cliente y los ingresos en línea.


Implemente con Confianza de Staging a Producción
El monitoreo sintético no es solo para alertas en producción. Los equipos pueden dirigir los monitores a entornos de staging o integrarlos en flujos CI/CD para ejecutar pruebas rápidas en rutas críticas antes y después del lanzamiento. Esto ayuda a prevenir errores en el Día 1, protege los recorridos de usuario clave y da más confianza a los equipos para desplegar rápidamente sin romper funcionalidades existentes.
Comience a Monitorear sus Aplicaciones Web en Menos de 10 Minutos
Reduzca el tiempo de inactividad, detecte problemas antes que sus clientes y demuestre el cumplimiento de SLA. Todas las funciones incluidas en la prueba. Sin tarjeta de crédito. Cancele en cualquier momento.
- No se requiere tarjeta de crédito
- Todas las funciones incluidas
- Configuración en 5 minutos
- Soporte 24x7
Software de Monitoreo Sintético para APIs y Microservicios

Validar Disponibilidad, Precisión y Latencia de la API
Dotcom-Monitor supervisa las APIs REST y SOAP para rendimiento y corrección, ayudando a los equipos a verificar que los endpoints devuelvan las cargas útiles, los códigos de estado y los tiempos de respuesta esperados. Al verificar el comportamiento del servicio de manera continua, los equipos pueden detectar problemas antes y mantener operaciones backend más confiables.
Detectar Tiempos de Espera, Cargas Útiles Incorrectas y Fallos de Autenticación Más Temprano
Los problemas de API y microservicios a menudo surgen primero como funcionalidades degradadas, transacciones lentas o errores intermitentes. Las comprobaciones sintéticas de API ayudan a los equipos a detectar tiempos de espera, autenticaciones fallidas, respuestas incorrectas e interrupciones de servicio antes de que se conviertan en problemas visibles para los clientes.
Esto es especialmente valioso en arquitecturas distribuidas donde múltiples servicios backend influyen en una única experiencia de usuario.
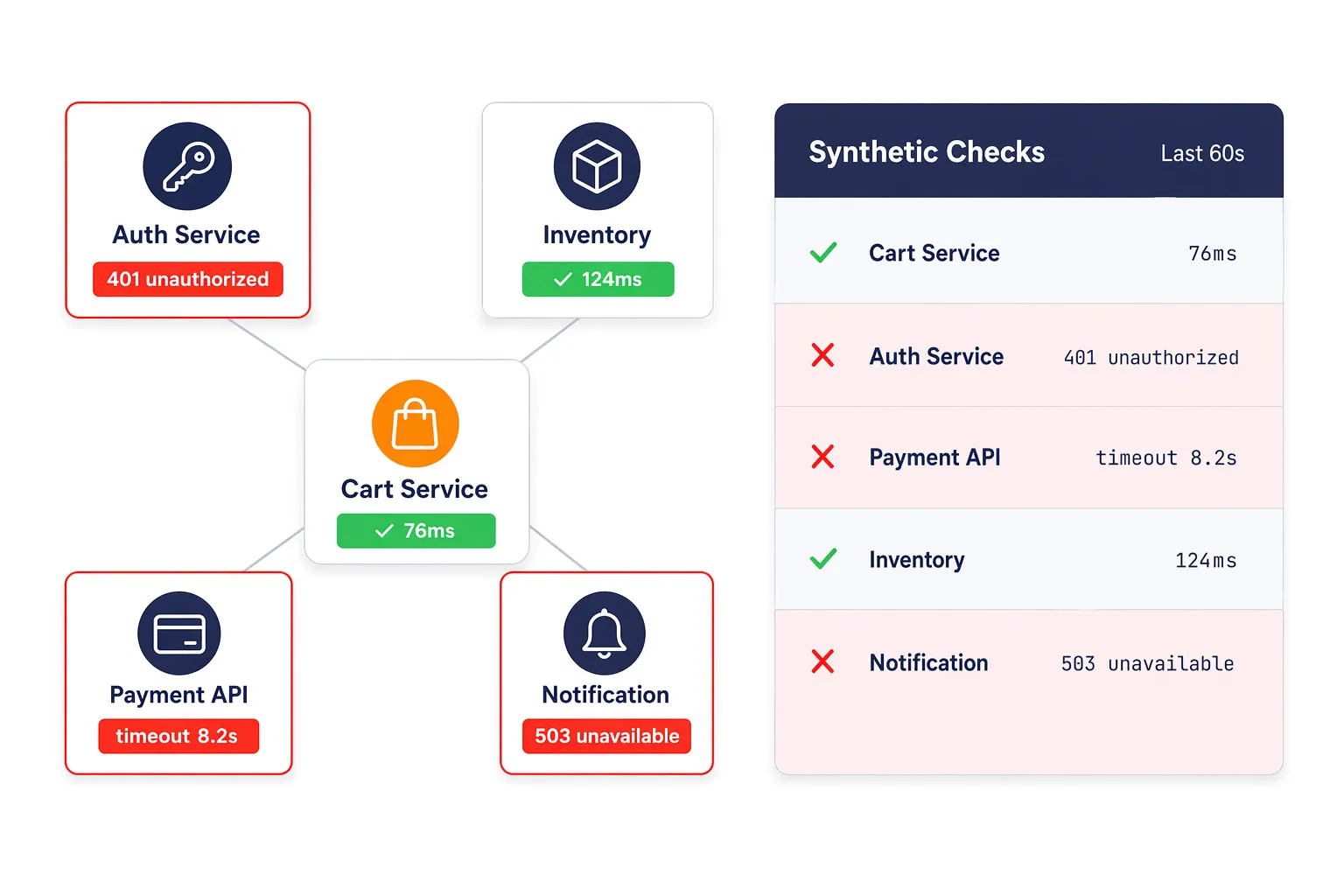

Soportar Validación de Autenticación y Nivel de Servicio
La confiabilidad del backend no solo se trata de tiempo de actividad. Los equipos también necesitan validar el comportamiento de autenticación, los intercambios de tokens y las respuestas de servicios críticos para el negocio. Dotcom-Monitor ayuda a verificar estas condiciones proactivamente para que las fallas se puedan resolver antes de afectar las aplicaciones dependientes o los flujos de trabajo de los clientes.
Acelerar el Análisis de Causa Raíz para Incidentes de Servicio
Cuando se detecta una falla, los equipos pueden revisar los detalles diagnósticos necesarios para identificar el servicio fallido más rápidamente. Esto proporciona a los equipos de DevOps, SRE y plataforma un punto de inicio más sólido para la solución y ayuda a reducir el tiempo dedicado a buscar la fuente de un incidente backend.

Valida Tus APIs Antes de Que Los Usuarios Perciban La Falla
- No se requiere tarjeta de crédito
- REST, SOAP, multi-paso y alertas incluidos
- Soporte 24x7
Monitoreo Sintético Web para Sitios Web y Experiencias Digitales Públicas

Monitorear la Disponibilidad del Sitio Web desde Más de 30 Ubicaciones Globales
Dotcom-Monitor ofrece monitoreo sintético desde más de 30 puntos de control globales, ayudando a los equipos a entender cómo funcionan los sitios web en las principales regiones de clientes. Esto facilita identificar latencia regional, cortes localizados y zonas ciegas que serían pasadas por alto con monitoreo desde una sola ubicación.
Ir Más Allá del Tiempo de Actividad con Visibilidad de Rendimiento
El monitoreo sintético de sitios web no debe limitarse a determinar si una página responde. Dotcom-Monitor ayuda a los equipos a analizar cuellos de botella de rendimiento con informes de gráficos de cascada y diagnósticos basados en navegador que revelan scripts lentos, recursos pesados y otros problemas que degradan la velocidad de carga y la experiencia del usuario.


Mejorar Core Web Vitals y Visibilidad en Buscadores
El rendimiento en buscadores y la experiencia digital están estrechamente conectados. Dotcom-Monitor ayuda a los equipos a monitorear las condiciones que influyen en métricas como Largest Contentful Paint y Cumulative Layout Shift en entornos controlados. Al identificar recursos de terceros lentos y el rendimiento de CDN tempranamente, los equipos pueden mejorar la estabilidad del sitio, proteger el rendimiento SEO y ofrecer experiencias más rápidas.
Convertir Datos de Confiabilidad en Informes Útiles
Para organizaciones empresariales y proveedores de servicios, la confiabilidad a menudo debe ser documentada, no solo observada. Dotcom-Monitor soporta paneles automatizados e informes orientados a SLA que ayudan a los equipos a demostrar compromisos de tiempo de actividad y rendimiento con datos recogidos de una red de monitoreo global.
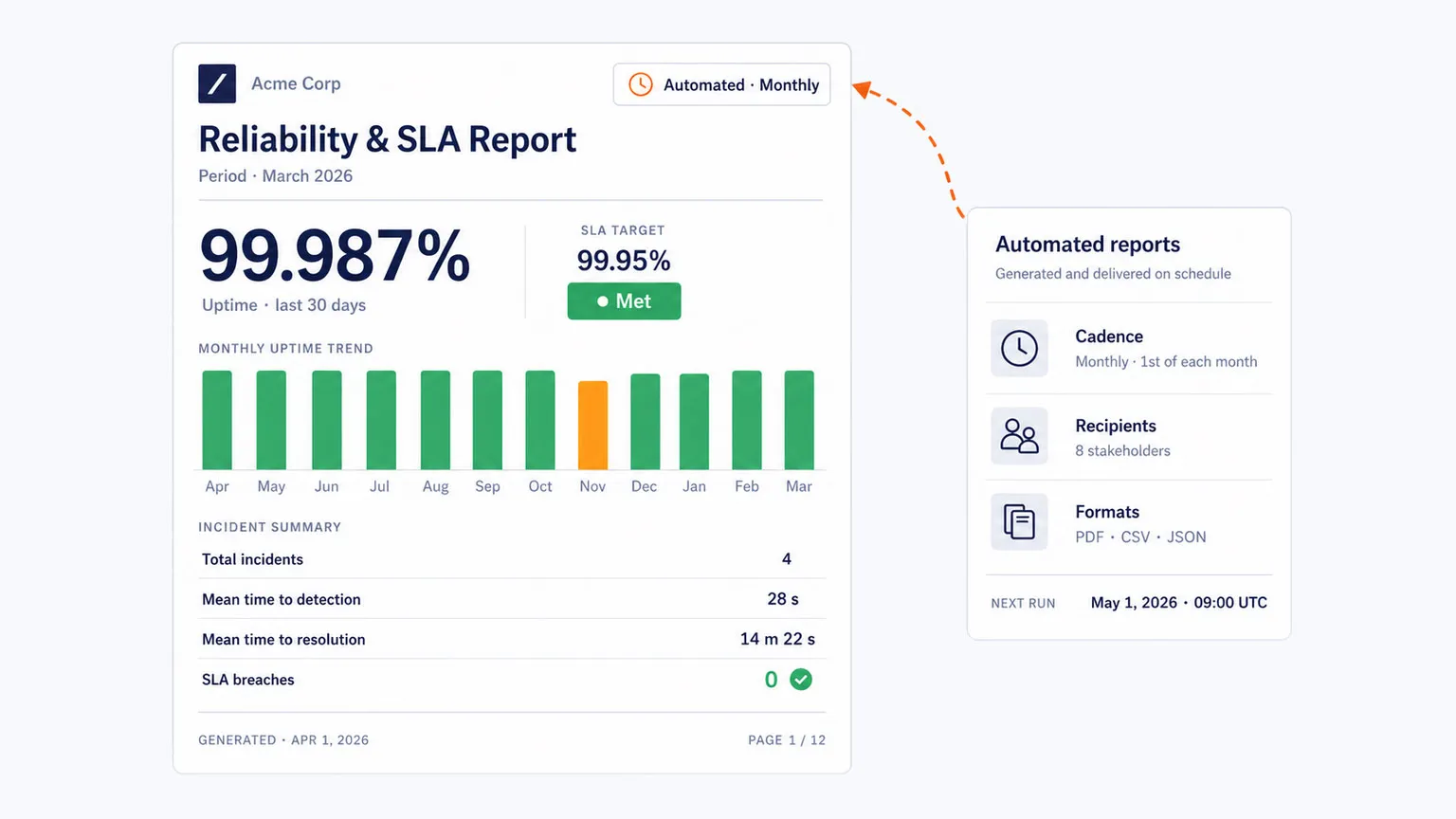
Comience a monitorear la disponibilidad del sitio web a nivel global
- No se requiere tarjeta de crédito
- Todas las funciones incluidas
- Configuración en 5 minutos
- Soporte 24x7
Monitoreo sintético para autenticación, aplicaciones internas y empresas avanzadas

Monitorear flujos de autenticación SSO y MFA
Los flujos de trabajo de inicio de sesión único y autenticación multifactor suelen depender de redireccionamientos encadenados, proveedores de identidad, intercambios de tokens y sesiones protegidas que pueden fallar de formas difíciles de diagnosticar. Dotcom-Monitor puede simular estos procesos de autenticación de varios pasos para que los equipos puedan identificar interrupciones en el handshake, problemas de redireccionamiento y fallos de acceso antes de que los usuarios sean bloqueados de sistemas críticos.
Despliegue agentes privados detrás del firewall
Muchas aplicaciones empresariales, incluidos portales internos para empleados, herramientas propietarias, intranets y sistemas ERP, están detrás de los firewalls corporativos. Dotcom-Monitor soporta agentes sintéticos privados, también llamados Nodos Privados, que pueden desplegarse dentro de su propio entorno para monitorear aplicaciones internas desde un punto interno seguro.


Aislar el impacto de scripts de terceros y la inestabilidad del DOM
Las experiencias digitales modernas dependen de etiquetas analíticas, widgets de chat, scripts externos y otros elementos de terceros que pueden bloquear la renderización e introducir inestabilidad en el diseño. El monitoreo sintético en navegador real ayuda a los equipos a aislar qué recurso externo está ralentizando la experiencia o afectando la estabilidad de la página para que puedan optimizar la estrategia de carga y reducir la fricción del usuario.
Reproducir fallos intermitentes durante eventos de alto tráfico
Los problemas intermitentes de aplicaciones de comercio electrónico y SaaS pueden ser difíciles de capturar durante las ventanas de tráfico pico. El monitoreo sintético ayuda a reproducir los fallos visibles para el usuario ejecutando repetidamente toda la lógica de la transacción, facilitando la captura de evidencias de lentitud en APIs, errores en frontend o problemas de rendimiento en backend que solo aparecen bajo presión.

Asegure que la infraestructura de su negocio esté activa y funcionando
- No se requiere tarjeta de crédito
- Todas las funciones incluidas
- Configuración en 5 minutos
- Soporte 24x7
Por qué los equipos eligen Dotcom-Monitor para el Monitoreo Sintético

Reducir el Tiempo Medio de Identificación
Las interrupciones se vuelven más costosas cuanto más tiempo pasan los equipos buscando el problema. Con diagnósticos visuales, reproducción sincronizada, datos en cascada y alertas contextuales, Dotcom-Monitor ofrece a los equipos un punto de partida rápido para la resolución de problemas.
Monitoreo de Transacciones Sintéticas Sin Código
Los equipos pueden grabar flujos de trabajo complejos sin escribir scripts manualmente, facilitando el lanzamiento rápido del monitoreo y manteniendo la cobertura alineada con la manera en que un usuario real navega por su sitio web.


Reciba Alertas Proactivas en las Herramientas que su Equipo Ya Usa
Dotcom-Monitor integra alertas proactivas en flujos de trabajo existentes a través de Slack, PagerDuty, Microsoft Teams y ServiceNow, ayudando a los equipos a responder más rápido cuando se detectan problemas de rendimiento o disponibilidad.
Correlacione la Experiencia de Front-End con Señales de Infraestructura
Dotcom-Monitor soporta visibilidad en sitios web, aplicaciones, APIs y chequeos a nivel de infraestructura como DNS, FTP y TCP. Esto ayuda a los equipos a conectar la salud del backend y el comportamiento de la red con la experiencia digital real que reciben los usuarios.

Obtenga respuestas
Preguntas Frecuentes
¿Puedo desplegar Agentes Privados detrás del firewall de mi empresa?
Sí, Dotcom-Monitor le permite desplegar Agentes Privados (también conocidos como Nodos Privados) específicamente para monitorear aplicaciones desde detrás del firewall corporativo. Esta capacidad es esencial para rastrear el desempeño y la disponibilidad de portales internos para empleados, intranets o herramientas de recursos humanos que no son accesibles por internet pública.
¿Qué es un agente sintético privado?
Un agente sintético privado es una instancia ligera de software instalada en su propio servidor local o nube privada que actúa como un punto de observación interno seguro. A diferencia de los nodos públicos que se encuentran en centros de datos globales, un agente privado simula la experiencia de un empleado real o sistema interno desde dentro de su propia infraestructura de red.
¿Cuál es la diferencia entre APM y monitoreo sintético?
La diferencia principal radica en la dirección de la observación: El Monitoreo de Rendimiento de Aplicaciones (APM) es una estrategia “de adentro hacia afuera” que utiliza agentes instalados en servidores para rastrear la ejecución interna del código, consultas a bases de datos y uso de recursos de hardware para identificar cuellos de botella en el backend. En contraste, el Monitoreo Sintético es un enfoque “de afuera hacia adentro” que usa scripts para simular el comportamiento del usuario final – como iniciar sesión o realizar un pago – para detectar proactivamente fallas en el front-end y tiempos de carga lentos antes de que los usuarios reales los experimenten.
¿Cuáles son los diferentes tipos de monitores sintéticos que existen?
Los monitores sintéticos se clasifican según la profundidad técnica de la verificación: Los monitores de disponibilidad web manejan chequeos básicos de protocolo como DNS, FTP y expiración de certificados SSL. Los monitores Web API validan la funcionalidad de respuestas REST, SOAP y WebSocket. Los monitores de aplicaciones web (UserView) utilizan un motor de navegador completo para simular transacciones multi-pasos. Finalmente, los monitores de transmisión multimedia verifican la disponibilidad y calidad de la reproducción de audio y video.
¿Desde cuántas ubicaciones debería monitorear?
Para una confiabilidad de nivel empresarial, debería monitorear desde 3 a 5 ubicaciones cubriendo cada región geográfica importante donde se encuentran sus clientes. Este enfoque multinodo es crítico porque permite la lógica de “Doble Chequeo”, donde una falla reportada por un nodo es inmediatamente verificada por otros.
Lo que dicen nuestros clientes
"I absolutely love the comprehensive monitoring services Dotcom-Monitor provides. The real-time alerts and detailed performance analytics have been a game-changer for our website's uptime and speed. The global monitoring feature ensures that our site is optimized everywhere, and the intuitive dashboard makes it easy to track performance. Their customer support is exceptional — always responsive and efficient."
Tomer C.
Managing Director · Facilities Services
Verified Capterra review · March 2025
"One of Dotcom's best features is the push/pull API capabilities that provide us with network performance data. We use this to monitor for performance issues as well as page loading stats. Dotcom-Monitor allows us to monitor multiple services within one interface and platform. It's allowed us to operate more efficiently."
Gregory S.
Manager · Broadcast Media
Verified Capterra review · May 2020
"I have been thoroughly impressed with the level of detail and comprehensiveness of the reports generated by the software. Moreover, the support team at Dotcom-Monitor has exceeded my expectations. On almost a daily basis, I reach out with various questions and they have consistently demonstrated unwavering patience, providing detailed and insightful answers."
Shirin R.
Software Test Engineer · Computer Software
Verified Capterra review · February 2023
"I'm a network analyst and use Dotcom tools inside the ISP I work, it's a really good and reliable tool for monitoring things along the network, and testing network components, I usually use it to make diagnostics of servers latency, and dns resolve time."
Leonardo J.
IT & Network Infrastructure Analyst Internet
Verified Capterra review · October 2022
Un Software de Monitoreo Sintético | Cero Puntos Ciegos
No se requiere tarjeta de crédito. Todas las funciones premium incluidas. Soporte experto 24×7.