2026年6月更新 · 読了時間11分

オンコールエンジニアに監視について尋ねると、彼らは同じことを言います:問題はアラートではなくノイズです。典型的なスタックは、すべての遅延サンプル、単一ロケーションのわずかな異常、1つの上流サービスが壊れたときに発生する依存チェックのすべてでアラートを発します。数週間も続くと、人々はアラートを読み飛ばし始めます。そして、本当の障害が起こった夜、そのアラートは200の誤検知と同じミュートチャネルに届くのです。
これがアラート疲労によって平均対応時間(MTTR)が上がる仕組みです。検出自体がボトルネックではありません。信号が埋もれてしまったのです。このガイドは、ユーザー体験が実際に損なわれた時だけアラートを発し、チームが動く信頼を得るためのウェブサイト監視アラート構築についてです。確認ロジック、エスカレーション階層、依存性を考慮した抑制、しきい値の数学を取り上げます。落ち着いたオンコールローテーションと誰も応答しないページャーを分ける正確な設定を紹介します。
ほとんどのアラートはノイズであって信号ではない理由
監視アラートの仕事は1つ:人間に修正が必要な問題があることを伝えることです。ほとんどのアラートは3つの共通パターンのどれかでその仕事に失敗し、それぞれに明確な解決策があります。
最も頻繁なのは単一ロケーションの誤検知です。フランクフルトの1つの監視エージェントが一時的なネットワーク障害に遭い、チェックが失敗してアラートが発生しても、実際にはユーザーは一人もサイトダウンを経験していません。単一ロケーションから監視すると、監視地点とオリジン間のパケットロスが原因で、実際の障害でないページが多数検出されてしまいます。
次にしきい値の変動(フラッピング)です。レスポンスタイムのアラートを2000msに設定したのは遅く感じたからです。しかし、ピーク時のP95(最も遅い5%のリクエストの応答時間)がすでに1800ms前後なので、午後ごとにアラートが発生し、自動的に解除され、再び発生します。何も対応すべき問題はないため誰も対応しません。数字が間違っているだけで、サイト自体は正常です。
そして最後にアラートストーム。あなたのドメインのDNS解決が壊れると、ホームページのチェックが失敗し、ログイン、チェックアウト、API、SSLチェックも次々に失敗します。1つの根本原因に対して40のアラートが同時に発生し、オンコールエンジニアは重要なものを見つけるために40件すべてを読み解かなければなりません。
これら3パターンを解消すると、ほとんどのノイズが取り除かれます。このガイドの残りはその方法です。
誰かにページを送る前に障害を確認する
最も効果的な改善は、アラートを発する前に確認を必須にすることです。Dotcom-Monitorはまさにそれを実現しています。最初のチェック失敗でページを送るのではなく、複数のロケーションでの合意と複数連続失敗という条件を設定しなければ通知されません。いずれもモニターごとに設定可能で、ページ送信前に各チェックにどれだけの証拠が必要かを決められます。
多地点での確認は誤検知を根本から排除します。フランクフルトだけが失敗し、同時刻のダラス、ロンドン、シンガポールが成功していれば、問題はフランクフルトへの経路でありサイトではありません。本当の障害はすべての地点で失敗します。これはDotcom-Monitorのグローバル監視ネットワークの役割であり、チェック失敗時に追加のロケーションで再検査を行い、単一地域の異常がオンコールに届かないようにします。複数地点で一致する障害のみを通知します。
連続失敗ロジックは一時的なグリッチを扱います。Dotcom-Monitorのアラートシステムでは、2回か3回連続で失敗して初めてアラートを発します(一度目の失敗では発しません)。1分間隔のため、検出遅延は1~2分増えますが、一時的なノイズをほぼゼロにできます。ほとんどのサイトではこのトレードオフは明らかに価値があり、モニターごとに設定可能なため、マーケティングページは決済エンドポイントより遅くてもよい確認が可能です。
確認には遅延が加わります。1秒のダウンタイムが致命的なシステムなら、より速い検出のために誤検知を増やす選択もありますが、ほとんどのチームはそうではありません。確認設定を選ぶことで静かなページャーを実現します。
重大度に応じたエスカレーション階層を作る
アラートとエスカレーションは同じではありません。アラートはチェック失敗の事実、エスカレーションは誰がどのチャネルで通知を受けるか、応答しなければどう扱うかを決めるルールです。同じように全員にページ送信すると、ページャーを無視するチームになります。
 重大度がチャネルを決め、応答なし時間がエスカレーションを決める。
重大度がチャネルを決め、応答なし時間がエスカレーションを決める。
まず失敗を重大度に分類し、それぞれにチャネルを割り当てます。原則は簡単:声の大きいチャネルほど、使用する基準が高い。
| 重大度 | 例 | チャネル | 対応者 |
|---|---|---|---|
| クリティカル | 複数ロケーションで確認されたチェックアウトまたはログインの停止 | SMS、電話、PagerDuty | オンコール、即時 |
| 高 | コアページが10分間p95超過の遅延 | SlackまたはTeamsの@on-call | オンコール、1時間以内 |
| 低 | マーケティングページの遅延、単一資産の404 | メールダイジェスト、ダッシュボード | 翌営業日にレビュー |
さらに重大度に時間ベースのエスカレーションを追加します。クリティカルアラートはSlackとオンコールエンジニアに同時に通知されます。10分以上解決しなければSMSでも再通知。20分経過すると二次オンコールやチームリードにも通知されます。朝3時に手動エスカレーションし忘れることはなく、ページを見逃しても障害を見逃すことはありません。
Dotcom-Monitorは通知グループとエスカレーションスケジュールでこれを管理します。誰がオンコールか、各階層がどのチャネルを使うか、通知が次の担当者に上がるまでの時間を設定できます。チームが普段使うSlackやMicrosoft Teamsに通知が届き、PagerDutyが時間外対応の経路を担います。重要なのは重大度によるルーティングであって、すべてを同時に放送し誰かに気づいてもらうことではありません。
依存チェックで症状を抑制する
アラートストームは構造的問題で、構造的に解決します。チェックには依存順序があり、多くのチームは無視しています。チェックアウトページへのリクエストはDNS解決、TCP接続、TLSハンドシェイク完了、HTTPコンテンツの返却、トランザクションの成功へと依存しています。スタックの下層で問題が起これば、それより上のすべても失敗します。
監視をリクエストの流れに合わせて順序付け、根本原因が症状をミュートするようにします。Dotcom-Monitorのマルチプロトコル監視により、DNS、TCP、TLS、HTTP、およびトランザクションを個別に監視できるため、どのレイヤーが壊れたかを特定し、それに対してアラートを出します。
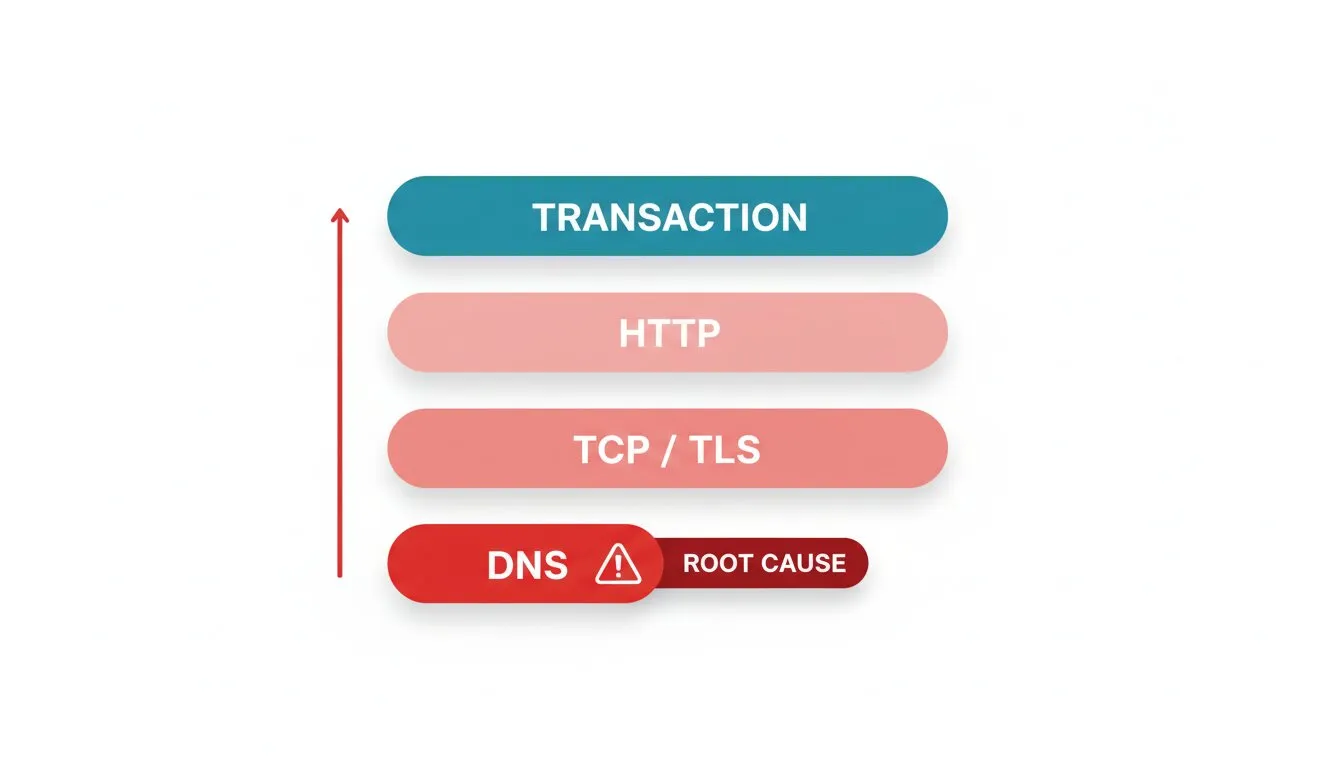 低レイヤーが壊れると上層もすべて失敗します。まず壊れたレイヤーにアラートを出しましょう。
低レイヤーが壊れると上層もすべて失敗します。まず壊れたレイヤーにアラートを出しましょう。
- DNSを最初に。 DNS監視で解決失敗が示されれば、すべての下流チェックが赤になる理由がわかります。DNS故障にアラートを出して他を抑制しましょう。
- 次に接続と証明書。 TLSハンドシェイク失敗や証明書期限切れは背後のすべてのHTTPSチェックを壊します。SSL証明書監視で証明書レイヤーで捕捉すれば、一般的なページ失敗の洪水ではなく単一明確なアラートを得られます。
- 次にアプリケーション。 DNS、TCP、TLSが正常でページやAPI監視チェックが失敗した場合、真のアプリケーション層障害としてページできます。
トランザクション監視はこれをさらに鋭敏にします。個々の資産でなく、実際に重要なユーザーフローをスクリプト化し、そのフローでアラートします。Dotcom-MonitorのEveryStepスクリプティングは、検索、カート追加、チェックアウト開始などのリアルブラウザパスを記録し、特定ステップ失敗時にアラート。4ステップ目が壊れてもホームページは問題ない場合、20件ではなく1件のアラートで「決済ステップのチェックアウト障害」を伝えます。これが、何が壊れたかを正確に告げるページと、何か壊れたとだけ告げるページの違いです。
モニターは依存でグループ化し、親障害で子をミュート。一つの根本原因アラートが40の症状アラートに勝る。
アラートが意味を持つようにしきい値を設定する
しきい値は、このラインを越えれば問題があるという約束です。多くのしきい値は静的な数値で一度設定すると見直されませんが、その約束を破っています。三つのルールで誠実さを保ちます。
平均ではなくパーセンタイルを使う
平均値は実際にユーザーを苦しめる遅いリクエストを隠します。ページ平均900msでもP95は3秒と、20人に1人は3秒待たされる場合があります。P95、決済フローならP99でアラートし、最も遅い実ユーザーの体験を反映しましょう。Dotcom-Monitorのパフォーマンスレポートはパーセンタイルおよび場所別応答時間を示し、実体験を反映する数字でしきい値を設定できます。
継続的な違反を条件にする
単一の遅延サンプルはインシデントではありません。Dotcom-Monitorでは可用性と同様に連続失敗フィルターをパフォーマンスにも適用し、遅延アラートは複数回連続で遅延が続いた時だけ発します。午後の通信量変動によるフラッピングをカットし、レイテンシアラートを無視する習慣をつけません。
期限切れがあるものはリードタイムでアラートする
証明書やドメインは徐々に悪化しません。動作し、突然動作しなくなります。なのでしきい値は性能ではなくカレンダーです。SSLアラートは期限30日前と7日前に発し、真夜中の障害を通常のチケット対応に変えます。適切な証明書アラートは更新を業務時間内にし、障害対応時間外を避けます。
パフォーマンスしきい値をビジネス数値に結び付けたい場合、エラーバジェット計算機が、SLAで許容できる劣化とページを起こすべきレベルを算出します。
午前2時のチェックアウト障害をステップごとに解説
多くの運用チームが経験した実例で組み立てます。午前2時14分に決済ゲートウェイの中間ドメイン証明書が期限切れ。
アラート設計なし: その証明書背後のすべてのHTTPSチェックが同時に失敗。オンコールエンジニアの電話が30件のSMSで光ります:ホームページダウン、チェックアウトダウン、アカウントページダウン、3つのAPIエンドポイントダウン、各種資産障害。彼らは目をこすりながら目の前の同じようなアラート群を15分間読み解き、30個の問題ではなく一つの根本原因であることを理解します。MTTRはすでに悪化しています。
アラート設計あり: SSL証明書監視が、期限切れ証明書を根本原因として特定。依存性グループ化が下流のページ・APIアラートを抑制。エンジニアは5ロケーションで確認された重要な証明書期限切れのSMSを一つだけ受け取ります。何が壊れどこで壊れたかを即座に理解し、旧設定では鳴り続けるアラートの中で更新作業が進みます。
障害と検出速度はどちらも同じです。変わるのはアラートの設計方法のみです。そして30日前に発するはずだった証明書アラート?それがこのインシデントを根本的に防ぎます。
デプロイやメンテナンス時のノイズをミュートする
自己発生アラートは総アラートの大半であり、一番簡単に除去できます。デプロイ、マイグレーション、計画的メンテナンス時はチェックが失敗します。これらがオンコールエンジニアに通知されると、チームは注目すべきタイミングに偽アラームを期待するようになってしまいます。
計画作業中は監視を抑制し、自動で再開するメンテナンスウィンドウを設定しましょう。Dotcom-Monitorはデバイス、デバイスグループ単位でこれを設定可能で、たとえばチェックアウトサービスのデプロイ時にチェックアウトアラートだけをミュートし、サイト全体は静かにできます。CI/CDパイプラインと連携すれば、抑制ウィンドウをデプロイの前後で自動的に開閉できます。
ウィンドウ設定は習慣化必須です。忘れるとウィンドウなしと同じになります。デプロイランブックに組み込み、リリース夜の23時に思い出す必要をなくしましょう。頻繁なデプロイならCI/CDパイプラインとの統合で監視抑制を自動化可能です。
毎月アラートを監査する
アラート設定は設定して放置ではありません。サイトは変わり、トラフィックも変動し、6か月前は意味のあったアラートも今は全員が無視するものに変化します。毎月短い監査を行い次の3つを問います。
まず、誰も対応しなかったアラートはどれか? 人手対応なしで解決したアラートをリストアップ。何度もアクションなしで発したルールは引退または調整対象。定義上信号でなくノイズを発生させています。
次に、アラートがなかった障害は? 客や他チームが監視より先に見つけた障害や遅延を遡って洗い出し、それを検知するチェックを追加。ギャップはノイズより危険で静かに進むからです。
最後に、しきい値は現状に合っているか? P95がトラフィック増加で上昇していれば、古いしきい値は厳しすぎるか緩すぎるかに変化。設定時点からではなく、最新の稼働時間・SLAレポートの数字を基準に再評価します。
このアプローチはより広範なウェブサイト監視ベストプラクティスの中に位置しますが、日々の苦痛はアラートに集中します。アラートが適切なら、他も自ずと静かになります。
チームが本当に信頼できるアラートを作ろう
Dotcom-Monitorはグローバルネットワークで失敗を確認してからページを送信し、Slack、Teams、SMS、PagerDutyで重大度別に通知し、DNS、TLS、API、トランザクションの障害を壊れたレイヤーで捕捉します。Dotcom-Monitorのアラートシステムを見てみるか、稼働時間監視から始めて調整しましょう。
