Mise à jour juin 2026 · lecture de 11 minutes

Demandez à tout ingénieur de garde ce qu’il pense de sa surveillance et il vous dira la même chose : les alertes ne sont pas le problème. C’est le bruit. Une pile typique déclenche une alerte à chaque échantillon lent, à chaque brève perte locale, à chaque vérification dépendante qui échoue quand un service en amont tombe en panne. Après quelques semaines, les gens arrêtent de lire les alertes. Et la nuit où une panne réelle survient, elle se retrouve dans le même canal muet que 200 faux positifs.
C’est ainsi que la fatigue liée aux alertes augmente le temps moyen de résolution. La détection n’a jamais été le goulot d’étranglement. Le signal a été enterré. Ce guide explique comment créer des alertes de surveillance de site web qui ne se déclenchent que lorsque l’expérience utilisateur est réellement compromise, pour que votre équipe leur fasse suffisamment confiance pour agir lorsqu’elles se produisent. Nous aborderons la logique de confirmation, les niveaux d’escalade, la suppression consciente des dépendances et les calculs de seuil, avec les réglages exacts qui distinguent une rotation de garde calme d’un pager que personne ne répond.
Pourquoi la majorité des alertes sont du bruit et non du signal
Une alerte de surveillance a un seul but : informer un humain qu’il y a un problème à résoudre. La plupart des alertes échouent à cette tâche selon trois schémas communs, chacun ayant une solution simple.
Les faux positifs sur un seul emplacement sont les plus fréquents. Un agent de surveillance à Francfort rencontre un accroc réseau temporaire, le contrôle échoue, l’alerte se déclenche, et votre site n’a jamais été en panne pour un utilisateur réel. Surveiller la disponibilité depuis un seul emplacement fait que certains de vos pages affichent des pertes de paquets entre votre moniteur et votre origine, pas de vraies pannes.
Ensuite viennent les seuils instables (flapping). Vous réglez une alerte de temps de réponse à 2 000 ms parce que cela semblait lent. Mais votre p95 (temps de réponse que vos 5 % de requêtes les plus lentes rencontrent réellement) se situe déjà autour de 1 800 ms lors des pics de trafic, donc l’alerte se déclenche chaque après-midi, se résout d’elle-même, et se déclenche à nouveau. Personne n’agit dessus parce qu’il n’y a rien à faire. Le chiffre était mauvais, pas le site.
Et puis il y a la tempête d’alertes. La résolution DNS échoue pour votre domaine. Maintenant, votre contrôle de page d’accueil échoue, votre contrôle de connexion échoue, votre contrôle de panier échoue, vos contrôles API échouent, et votre contrôle SSL échoue car le moniteur ne peut même pas atteindre l’hôte. Une cause racine, quarante alertes, toutes déclenchées dans la même minute. L’ingénieur de garde doit lire les quarante alertes pour trouver celle qui compte.
Corrigez ces trois schémas et vous éliminez la majeure partie du bruit. La suite de ce guide explique comment.
Confirmer une panne avant de prévenir quelqu’un
Le changement à plus fort impact que vous pouvez faire est d’exiger une confirmation avant qu’une alerte ne soit déclenchée, et Dotcom-Monitor est conçu pour appliquer exactement cela. Plutôt que de contacter dès la première vérification échouée, vous configurez les conditions que l’échec doit respecter avant qu’on n’en parle : accord venant de plusieurs emplacements, et plusieurs échecs consécutifs. Les deux sont configurés par moniteur, vous décidez donc combien de preuves chaque contrôle doit fournir avant de lancer une alerte.
La confirmation multi-emplacements élimine le faux positif à la source. Si une vérification échoue depuis Francfort mais réussit simultanément depuis Dallas, Londres et Singapour, le problème vient de la route vers Francfort, pas de votre site. Une vraie panne échoue partout. C’est le rôle du réseau mondial de surveillance de Dotcom-Monitor : quand un contrôle échoue, Dotcom-Monitor le reteste automatiquement depuis plusieurs sites avant d’envoyer une alerte, ainsi un simple incident régional ne dérange jamais votre rotation de garde. Vous entendez seulement parler des pannes confirmées par plusieurs points de vue.
La logique d’échecs consécutifs gère les glitches momentanés. Dans le système d’alertes de Dotcom-Monitor, vous configurez une alerte pour qu’elle ne se déclenche qu’après deux ou trois échecs de suite, pas au premier. À intervalle d’une minute, cela ajoute un ou deux minutes de latence de détection en échange de la réduction du bruit transitoire quasi à zéro. Pour la plupart des sites, ce compromis vaut clairement la peine, et comme le filtre est défini par moniteur, une page marketing peut tolérer une confirmation plus lente qu’un point de terminaison de paiement.
La confirmation ajoute un léger délai. Si vous gérez un système où une seconde de panne est véritablement catastrophique, vous pourriez accepter plus de faux positifs pour une détection plus rapide. La majorité des équipes ne sont pas dans ce cas, et ce compromis apporte des pagers plus calmes.
Construisez des niveaux d’escalade adaptés à la gravité
Une alerte et une escalade ne sont pas la même chose. L’alerte signale qu’une vérification a échoué. L’escalade règle qui en est informé, par quel canal, et ce qui se passe si personne ne répond. Une alerte uniforme, où chaque échec alerte tout le monde de la même manière, mène rapidement à ce que l’équipe ignore ses pagers.
Commencez par trier les échecs selon des niveaux de gravité et associer chacun à un canal. Le principe est simple : plus le canal est bruyant, plus la barre à franchir pour l’utiliser est haute.
| Gravité | Exemple | Canal | Répondants |
|---|---|---|---|
| Critique | Paiement ou connexion hors service, confirmé depuis plusieurs emplacements | SMS, téléphone, PagerDuty | Assistance de garde, immédiatement |
| Élevée | Page principale lente au-delà du p95 pendant 10 minutes | Slack ou Teams, @on-call | Assistance de garde, dans l’heure |
| Faible | Page marketing lente, un seul actif en 404 | Résumé par email, tableau de bord | Révision le jour ouvrable suivant |
Puis ajoutez une escalade temporelle au-dessus de la gravité. Une alerte critique arrive sur Slack et au technicien de garde en même temps. Si elle est toujours active après dix minutes, elle se répète par SMS. Après vingt minutes, elle notifie la garde secondaire ou le responsable d’équipe. Personne n’a à se souvenir d’escalader manuellement à 3 heures du matin, et une alerte manquée ne devient pas une panne ignorée.
Dotcom-Monitor gère cela avec des groupes de notifications et des horaires d’escalade. Vous définissez qui est de garde, quels canaux chaque niveau utilise, et combien de temps une alerte attend avant de passer au responsable suivant. Il s’intègre aux canaux utilisés par les équipes, ainsi une notification Slack ou Microsoft Teams atteint les personnes actives et une escalade PagerDuty gère les alertes hors heures. Le but est d’orienter selon la gravité, pas de diffuser tout partout en espérant qu’on remarque quelque chose.
Laissez les vérifications de dépendance supprimer les symptômes
La tempête d’alertes est un problème structurel, et vous le résolvez de façon structurelle. Vos contrôles ont un ordre de dépendance, que la plupart des équipes ignore. Une requête vers votre page de panier dépend d’abord de la résolution DNS, puis de la connexion TCP, puis de la réussite de la poignée de main TLS, puis du retour HTTP de contenu, puis du succès même de la transaction. Quand quelque chose en bas de cette chaîne casse, tout ce qui est au-dessus échoue aussi.
Classez donc votre surveillance dans l’ordre dans lequel la requête s’exécute, et laissez la cause racine réduire le bruit des symptômes. La surveillance multi-protocole de Dotcom-Monitor rend cela pratique : vous surveillez DNS, TCP, TLS, HTTP et la transaction complète comme contrôles séparés, ainsi quand un contrôle échoue vous voyez quelle couche a cassé et alertez sur cette couche au lieu de la cascade derrière.
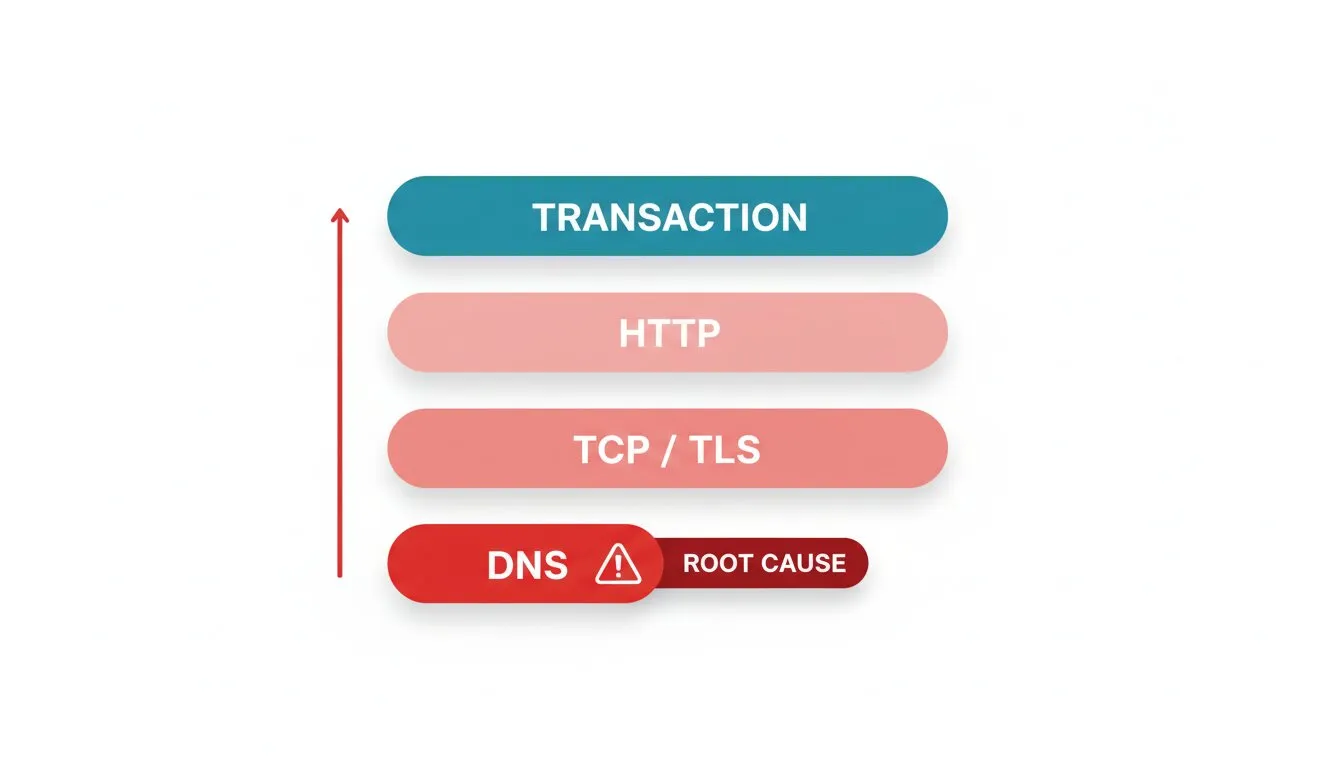
- DNS d’abord. Si la surveillance DNS montre un échec de résolution, vous savez déjà pourquoi tous les contrôles en aval sont rouges. Alertez sur l’échec DNS et supprimez le reste.
- Puis la connexion et le certificat. Une poignée de main TLS ratée ou un certificat expiré provoque l’échec de tous les contrôles HTTPS derrière. Attrapez-le au niveau du certificat avec la surveillance de certificat SSL et obtenez une alerte claire unique au lieu d’une inondation d’erreurs génériques sur vos pages.
- Puis l’application. Si DNS, TCP, et TLS sont sains mais que le contrôle de page ou la surveillance API échoue, vous avez un incident d’application valable qui mérite une alerte.
La surveillance des transactions affine cela davantage. Plutôt que d’alerter sur chaque actif individuel, scendez un script du parcours utilisateur qui compte vraiment puis alertez sur ce parcours. Le script EveryStep de Dotcom-Monitor enregistre un chemin en vrai navigateur, comme recherche, ajout au panier, et début de paiement, puis alerte quand une étape précise échoue. Si l’étape quatre casse mais que la page d’accueil va bien, vous avez une alerte unique qui dit que le paiement est en panne à l’étape de paiement, pas vingt alertes qui disent que divers actifs sont en erreur. C’est la différence entre une alerte qui dit ce qui a cassé et une qui dit juste qu’il y a eu une panne.
Groupez les moniteurs par dépendance pour que la panne parente réduise le bruit de ses enfants. Une alerte cause racine bat quarante alertes symptômes à chaque fois.
Formatez les seuils pour que les alertes aient un sens
Un seuil est une promesse : franchir cette ligne signifie qu’il y a un problème. La plupart des seuils trahissent cette promesse parce qu’ils sont des nombres statiques choisis une fois pour toutes. Trois règles les maintiennent intègres.
Utilisez des percentiles, pas des moyennes
Les moyennes cachent les requêtes lentes qui pénalisent vraiment les utilisateurs. Une page peut avoir une moyenne de 900 ms alors que son p95 est à 3 secondes, ce qui signifie qu’un visiteur sur vingt attend trois secondes. Alertez sur le p95, ou le p99 pour les parcours de paiement, car c’est l’expérience de vos utilisateurs les plus lents. Les rapports de performance de Dotcom-Monitor détaillent les temps de réponse par percentile et par localisation, vous permettant de configurer un seuil basé sur une mesure d’expérience réelle plutôt qu’une moyenne flatteuse.
Exigez une violation soutenue
Un seul échantillon lent n’est pas incident. Avec Dotcom-Monitor, appliquez le même filtre d’échecs consécutifs pour la performance que pour la disponibilité, ainsi une alerte temps de réponse se déclenche seulement après que le ralentissement se répète plusieurs fois d’affilée, pas au premier dépassement. Cela coupe les fluctuations dues au trafic de l’après-midi qui entraînent la désactivation des alertes latence.
Alertez sur le temps restant avant expiration pour tout ce qui expire
Les certificats et domaines ne se dégradent pas. Ils fonctionnent, puis un jour, ils ne fonctionnent plus. Donc, le seuil n’est pas un nombre de performance, c’est un calendrier. Lancez une alerte SSL 30 jours avant l’expiration puis de nouveau à 7 jours, et vous transformez une panne nocturne en ticket routinier. La bonne alerte de certificat garantit que le renouvellement se fait pendant les heures ouvrables, pas pendant un incident.
Si vous souhaitez relier vos seuils de performance à une valeur métier, un calculateur de budget d’erreur vous aide à déterminer combien de dégradation votre SLA peut vraiment absorber avant qu’une alerte mérite de réveiller quelqu’un.
Une panne du paiement à 2 h du matin, étape par étape
Assemblez les pièces avec un scénario réel que la plupart des équipes opérationnelles ont connu. Il est 2:14 du matin. Un certificat sur le domaine intermédiaire de votre passerelle de paiement expire.
Sans ingénierie des alertes : Tous les contrôles HTTPS derrière ce certificat échouent en même temps. Le téléphone de l’ingénieur de garde s’enflamme avec 30 SMS : page d’accueil hors service, paiement hors service, page compte hors service, trois points d’API hors service, diverses erreurs d’actifs. Il se réveille, plisse les yeux devant une muraille d’alertes identiques, et met quinze minutes à comprendre qu’il ne s’agit pas de trente problèmes séparés. Le MTTR est déjà compromis avant même qu’on touche à la vraie correction.
Avec ingénierie des alertes : La vérification de surveillance de certificat SSL identifie le certificat expiré comme cause racine. Le groupement par dépendance supprime les alertes pages et API en aval, car leur parent a déjà échoué. L’ingénieur reçoit un seul SMS critique : certificat expiré sur le domaine intermédiaire de paiement, confirmé depuis cinq emplacements. Il sait exactement ce qui a cassé et où, et renouvelle le certificat pendant que l’ancienne configuration compterait encore les alertes.
La panne et la vitesse de détection sont identiques dans les deux cas. Ce qui change la nuit, c’est la manière dont les alertes ont été construites. Et l’alerte certificat qui aurait dû se déclencher 30 jours plus tôt ? C’est la version où cet incident n’arrive pas du tout.
Réduisez le bruit pendant les déploiements et maintenances
Les alertes auto-infligées représentent une grande part du volume total, et sont les plus faciles à éliminer. Quand vous déployez, migrez ou mettez un service en maintenance planifiée, vos contrôles échouent. Si ces échecs alertent le technicien de garde, vous habituez l’équipe à des fausses alertes pendant les fenêtres où ils doivent vraiment être attentifs.
Définissez des fenêtres de maintenance pour que la surveillance supprime les alertes pendant les travaux planifiés puis reprenne automatiquement. Dotcom-Monitor permet de planifier cela par appareil ou groupe d’appareils, ainsi un déploiement sur le service de paiement coupe les alertes liées au paiement sans muer le reste du site. Associer cela à votre pipeline CI/CD permet d’ouvrir et fermer la fenêtre de suppression autour du déploiement lui-même.
Programmer la fenêtre doit devenir une habitude, car une fenêtre de maintenance qu’on oublie de configurer vaut autant qu’une fenêtre inexistante. Intégrez la suppression à votre runbook de déploiement pour ne pas avoir à y penser à 23 h le soir de la mise en production. Si vous déployez fréquemment, intégrer la surveillance dans le pipeline CI/CD permet de gérer la suppression automatiquement dans le cadre de la livraison.
Auditez vos alertes chaque mois
La configuration d’alertes n’est pas une tâche à faire une seule fois. Les sites changent, les schémas de trafic évoluent, et une alerte qui avait du sens il y a six mois est aujourd’hui celle que tout le monde désactive. Faites donc un court audit mensuel avec trois questions.
D’abord, quelles alertes se sont déclenchées sans action humaine ? Récupérez la liste des alertes qui se sont résolues seules sans intervention. Toute règle qui s’est déclenchée plusieurs fois sans action est candidate à la suppression ou au réajustement. Par définition, elle génère du bruit et non du signal.
Ensuite, quels incidents n’avaient pas d’alerte ? La question la plus révélatrice. Revisitez toute panne ou ralentissement qu’un client ou une autre équipe a détecté avant votre surveillance, et ajoutez le contrôle qui l’aurait détecté. Les lacunes sont plus dangereuses que le bruit car elles sont silencieuses.
Enfin, les seuils correspondent-ils toujours à la réalité ? Si votre p95 a augmenté avec la croissance du trafic, votre ancien seuil est maintenant trop serré ou trop laxiste. Recalibrez-le selon les chiffres actuels de vos rapports de disponibilité et SLA plutôt que ceux de sa première mise en place.
Toute cette approche s’inscrit dans un ensemble plus large de bonnes pratiques de surveillance de sites web, mais l’alerte est la source majeure des douleurs quotidiennes. Réglez les alertes et le reste de la pile se calme automatiquement.
Créez des alertes en lesquelles votre équipe a réellement confiance
Dotcom-Monitor confirme les échecs depuis un réseau mondial avant d’alerter, route selon la gravité via Slack, Teams, SMS et PagerDuty, et détecte DNS, TLS, API et pannes transactionnelles à la couche où ça casse. Découvrez comment fonctionne le système d’alertes de Dotcom-Monitor, ou commencez par la surveillance de disponibilité et affinez à partir de là.
