Actualizado en junio de 2026 · Lectura de 11 minutos

Pregunta a cualquier ingeniero de guardia sobre su monitoreo y te dirá lo mismo: las alertas no son el problema. El ruido sí lo es. Un stack típico dispara en cada muestra lenta, cada pico en una sola ubicación, cada chequeo dependiente que falla cuando un servicio upstream se rompe. Después de unas semanas de eso, la gente deja de leer las alertas. Y la noche que ocurre una falla real, cae en el mismo canal silenciado que 200 falsos positivos.
Así es como la fatiga de alertas incrementa el Tiempo Promedio para la Resolución. La detección nunca fue el cuello de botella. La señal quedó enterrada. Esta guía trata sobre construir alertas de monitoreo para sitios web que solo se activen cuando la experiencia del usuario esté realmente comprometida, para que tu equipo confíe lo suficiente en ellas para actuar cuando lo hacen. Cubriremos lógica de confirmación, niveles de escalada, supresión consciente de dependencias y matemáticas de umbrales, con los ajustes exactos que separan una rotación de guardia tranquila de un pager que nadie atiende.
Por qué la mayoría de las alertas son ruido, no señal
Una alerta de monitoreo tiene un solo trabajo: decirle a un humano que algo está mal y necesita arreglarlo. La mayoría de las alertas fallan en esa tarea mediante tres patrones comunes, y cada uno tiene una solución clara.
Los falsos positivos en una sola ubicación son los más frecuentes. Un agente de monitoreo en Frankfurt sufre un pequeño problema de red transitorio, la verificación falla, la alerta se dispara, y tu sitio nunca estuvo caído para un solo usuario real. Ejecutar monitoreo de disponibilidad desde un solo lugar hace que un porcentaje de tus páginas fallen por pérdida de paquetes entre tu monitor y tu origen, no por cortes reales.
Los umbrales variables (flapping) vienen después. Configuras una alerta de tiempo de respuesta en 2,000 ms porque parecía lento. Pero tu p95 (el tiempo de respuesta que ve el 5 % más lento de tus solicitudes) ya ronda los 1,800 ms durante tráfico pico, así que la alerta se dispara cada tarde, se limpia sola y se dispara de nuevo. Nadie actúa porque no hay nada que hacer. El número estaba mal, no el sitio.
Y luego está la tormenta de alertas. La resolución DNS falla para tu dominio. Ahora los chequeos de la página principal fallan, los de inicio de sesión fallan, los del checkout fallan, los checks de API fallan y el del SSL también porque el monitor ni siquiera puede alcanzar el host. Una causa raíz, cuarenta alertas, todas disparándose en el mismo minuto. El ingeniero de guardia tiene que leer las cuarenta para encontrar la que importa.
Arregla esos tres patrones y eliminas la mayor parte del ruido. El resto de esta guía explica cómo hacerlo.
Confirma un corte antes de avisar a alguien
El cambio con mayor impacto que puedes hacer es exigir confirmación antes de que una alerta se dispare, y Dotcom-Monitor está diseñado para aplicar exactamente eso. En lugar de enviar un aviso en la primera verificación fallida, configuras las condiciones que una falla debe cumplir antes de que alguien se entere: acuerdo de más de una ubicación y más de un chequeo fallido consecutivo. Ambos se configuran por monitor, así decides cuánta evidencia necesita cada chequeo antes de alertar.
La confirmación desde múltiples ubicaciones elimina el falso positivo en la fuente. Si un chequeo falla desde Frankfurt pero pasa desde Dallas, Londres y Singapur al mismo tiempo, el problema es la ruta a Frankfurt, no tu sitio. Una falla real ocurre en todas partes. Esa es la función de la red global de monitoreo de Dotcom-Monitor: cuando un chequeo falla, Dotcom-Monitor lo vuelve a verificar automáticamente desde más ubicaciones antes de enviar una alerta, así que un pico regional único nunca llega a tu rotación de guardia. Solo escuchas fallos que coinciden en más de un punto de vista.
La lógica de fallos consecutivos maneja el glitch momentáneo. En el sistema de alertas de Dotcom-Monitor configuras una alerta para que se active solo después de que fallen dos o tres chequeos consecutivos, no el primero. A intervalos de un minuto, eso agrega uno o dos minutos de latencia en la detección a cambio de reducir el ruido transitorio casi a cero. Para la mayoría de sitios ese intercambio vale la pena, y porque el filtro se configura por monitor, una página de marketing puede tolerar una confirmación más lenta que un endpoint de pago.
La confirmación agrega un pequeño retraso. Si manejas un sistema donde un segundo de caída es verdaderamente catastrófico, puedes aceptar más falsos positivos a cambio de detección más rápida. La mayoría de equipos no están en esa posición, y ese intercambio les da pagers tranquilos.
Construye niveles de escalada que coincidan con la gravedad
Una alerta y una escalada no son lo mismo. La alerta es el hecho de que un chequeo falló. La escalada es la regla que decide quién la recibe, por qué canal y qué pasa si nadie responde. El alertamiento plano, donde cada falla avisa a todos de la misma forma, es la ruta más rápida hacia un equipo que ignora su pager.
Comienza clasificando las fallas por niveles de gravedad y asignando cada uno a un canal. El principio es simple: mientras más ruidoso el canal, mayor la barrera para usarlo.
| Gravedad | Ejemplo | Canal | Quién responde |
|---|---|---|---|
| Crítica | Checkout o inicio de sesión caídos, confirmado desde múltiples ubicaciones | SMS, teléfono, PagerDuty | Guardia, inmediatamente |
| Alta | Página principal lenta más allá del p95 durante 10 minutos | Slack o Teams, @on-call | Guardia, en menos de una hora |
| Baja | Página de marketing lenta, un activo con error 404 | Correo electrónico resumen, panel de control | Revisado al siguiente día hábil |
Luego agrega escalada basada en el tiempo sobre la gravedad. Una alerta crítica llega por Slack y al ingeniero de guardia al mismo tiempo. Si sigue abierta después de diez minutos, se envía un segundo aviso por SMS. Después de veinte, notifica al guardia secundario o al líder del equipo. Nadie tiene que recordar escalar a mano a las 3 AM, y una página no respondida no se convierte en una falla ignorada.
Dotcom-Monitor maneja esto con grupos de notificación y horarios de escalada. Defines quién está de guardia, qué canales usa cada nivel y cuánto tiempo espera una alerta antes de escalar a la siguiente persona. Se integra con los canales donde los equipos ya trabajan, así una notificación en Slack o Microsoft Teams llega a las personas activas y una escalada por PagerDuty cubre el camino fuera de horario. La idea es enrutar por gravedad, no enviar todo esperando que alguien lo note.
Deja que los chequeos de dependencia supriman los síntomas
La tormenta de alertas es un problema estructural y lo resuelves estructuralmente. Tus chequeos tienen un orden de dependencia y la mayoría de los equipos lo ignora. Una petición a tu página de checkout depende de que DNS resuelva, luego que TCP conecte, luego que termine el handshake TLS, luego que HTTP devuelva contenido, y finalmente que la transacción tenga éxito. Cuando algo abajo en esa pila falla, todo lo que está arriba también falla.
Así que ordena tu monitoreo igual que el flujo de la petición y deja que la causa raíz silencie los síntomas. El monitoreo multiprotocolo de Dotcom-Monitor hace esto práctico: observas DNS, TCP, TLS, HTTP y la transacción completa como chequeos separados, así cuando algo falla puedes ver qué capa se rompió y alertar sobre esa en vez del efecto dominó detrás.
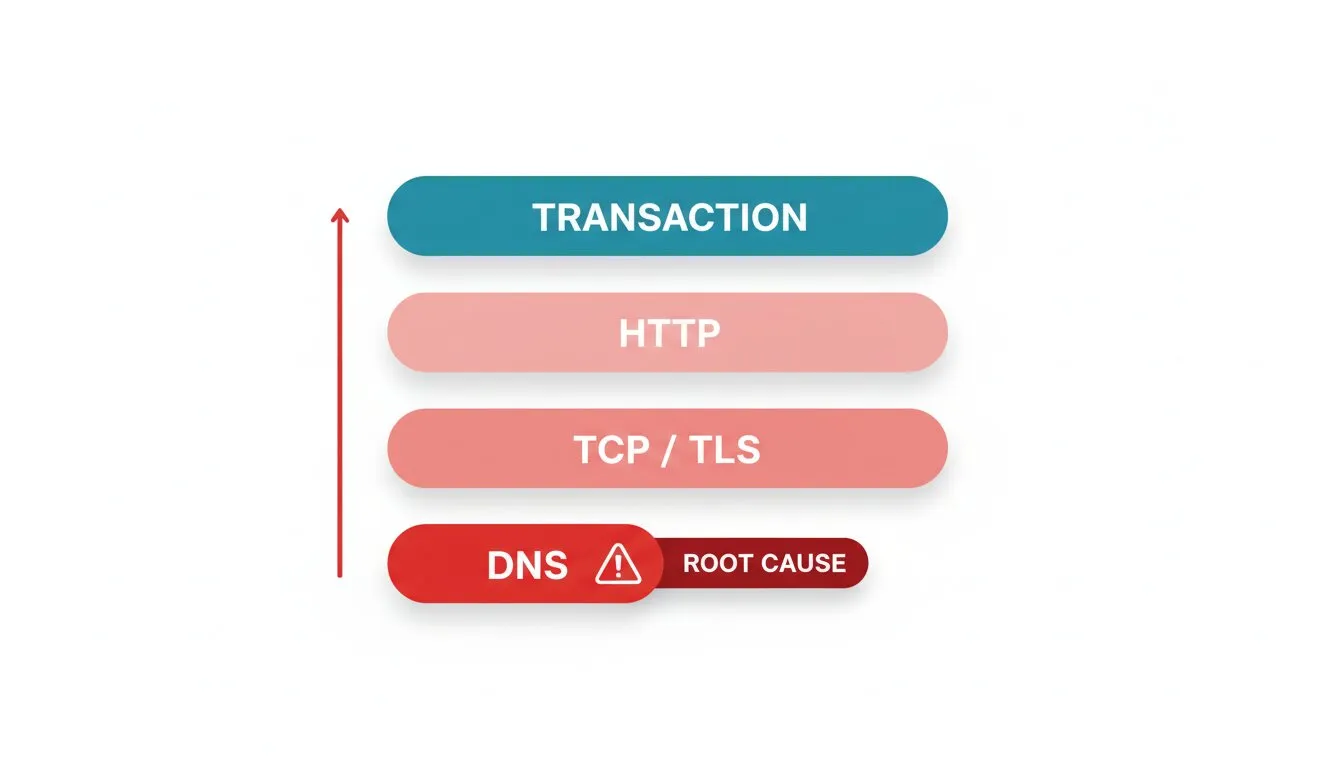
- DNS primero. Si el monitoreo DNS muestra que la resolución falla, ya sabes por qué todos los chequeos posteriores están en rojo. Alerta en la falla de DNS y suprime el resto.
- Luego conexión y certificado. Un handshake TLS fallido o un certificado expirado rompe todos los chequeos HTTPS detrás. Detecta eso en la capa del certificado con monitoreo de certificados SSL y obtendrás una alerta única y clara en lugar de una avalancha de fallos genéricos de página.
- Después la aplicación. Si DNS, TCP y TLS están saludables pero falla el chequeo de página o monitoreo de API, tienes un incidente genuino a nivel de aplicación que vale la pena que dispare una alerta.
El monitoreo de transacciones afina esto aún más. En lugar de alertar por cada activo individual, scriptéa el flujo de usuario que realmente importa y alerta por ese flujo. El scripting EveryStep de Dotcom-Monitor graba un camino real en navegador, como buscar, agregar al carrito y comenzar el checkout, y alerta cuando un paso específico falla. Si falla el paso cuatro pero la página principal está bien, recibes una alerta que dice el checkout falla en el paso de pago, no veinte que indican errores en varios activos. Esa es la diferencia entre una alerta que te dice qué se rompió y otra que solo dice que algo se rompió.
Agrupa los monitores por dependencia para que una falla padre silencie a sus hijos. Una alerta de causa raíz vence a cuarenta alertas de síntomas siempre.
Configura umbrales para que las alertas signifiquen algo
Un umbral es una promesa que cruzar esa línea significa que algo está mal. La mayoría de umbrales rompen esa promesa porque son números estáticos elegidos una vez y olvidados. Tres reglas los mantienen honestos.
Usa percentiles, no promedios
Los promedios ocultan las solicitudes lentas que realmente afectan a los usuarios. Una página puede promediar 900 ms mientras su p95 está en 3 segundos, lo que significa que uno de cada veinte visitantes espera tres segundos. Alerta en el p95, o p99 para flujos de checkout, porque esa es la experiencia que obtienen tus usuarios reales más lentos. Los informes de rendimiento de Dotcom-Monitor separan el tiempo de respuesta por percentil y ubicación, para que puedas configurar un umbral contra el número que refleja experiencia real y no un promedio favorecedor.
Exige un incumplimiento sostenido
Una muestra lenta no es un incidente. En Dotcom-Monitor aplicas el mismo filtro de fallos consecutivos al rendimiento que para la disponibilidad, así una alerta de tiempo de respuesta solo se dispara después de varios chequeos lentos seguidos, no en la primera muestra que cruza tu línea. Esto reduce el flapping en tráfico de la tarde que entrena a la gente a ignorar alertas de latencia.
Alerta sobre el tiempo restante para todo lo que expire
Los certificados y dominios no se degradan. Funcionan y un día dejan de funcionar. Así que el umbral no es un número de rendimiento, es un calendario. Dispara una alerta SSL 30 días antes de la expiración y otra a los 7 días, y conviertes una caída a medianoche en un ticket rutinario. La alerta correcta de certificados significa que la renovación ocurre en horario laboral, no durante un incidente.
Si quieres ligar los umbrales de rendimiento a un número de negocio, un calculador de presupuesto de error te ayuda a determinar cuánto deterioro tu SLA puede absorber antes de que valga la pena despertar a alguien.
Una falla en checkout a las 2 AM, paso a paso
Pon los elementos juntos con un patrón real que la mayoría de los equipos de operaciones ha vivido. Son las 2:14 AM. Un certificado del dominio intermedio de tu pasarela de pago expira.
Sin ingeniería de alertas: Todos los chequeos HTTPS detrás de ese certificado fallan al mismo tiempo. El teléfono del ingeniero de guardia se llena con 30 SMS: página principal caída, checkout caído, página de cuenta caída, tres endpoints API caídos, fallos de activos varios. Se despiertan, entrecierran los ojos ante un muro de alertas idénticas y dedican quince minutos a entender que no son treinta problemas separados. El MTTR ya está dañado antes de que alguien toque la solución real.
Con ingeniería de alertas: El chequeo de monitoreo de certificado SSL identifica el certificado expirado como causa raíz. La agrupación por dependencia suprime las alertas de páginas y API aguas abajo porque su padre ya falló. El ingeniero recibe un único SMS crítico: certificado expirado en el intermedio de pago, confirmado desde cinco ubicaciones. Saben exactamente qué se rompió y dónde, y están renovando el certificado mientras la versión antigua todavía contaba alertas.
La falla y la velocidad de detección son idénticas en ambas versiones. Lo que cambia la noche es cómo se construyeron las alertas. ¿Y la alerta de certificado que debió activarse 30 días antes? Esa es la versión donde este incidente nunca sucede.
Silencia el ruido durante despliegues y mantenimiento
Las alertas autoprovocadas son una gran parte del volumen total y las más fáciles de eliminar. Cuando despliegas, corres una migración o sacas un servicio para mantenimiento programado, tus chequeos fallarán. Si esas fallas alertan al ingeniero de guardia, estás entrenando al equipo para esperar falsas alarmas justo cuando deberían estar más atentos.
Configura ventanas de mantenimiento para que el monitoreo suprima alertas durante trabajo planeado y luego retome automáticamente. Dotcom-Monitor permite programarlas por dispositivo o grupo, así un despliegue al servicio de checkout silencia solo esas alertas sin callar todo el sitio. Combínalo con tu pipeline CI/CD y la ventana de supresión puede abrirse y cerrarse alrededor del despliegue.
Configurar la ventana debe ser un hábito porque una ventana de mantenimiento que alguien olvida establecer es igual a no tenerla. Incluye la supresión en tu runbook de despliegue para que no sea algo que recordar a las 11 PM en la noche de lanzamiento. Si haces despliegues frecuentes, integrar el monitoreo en el pipeline CI/CD permite que la supresión ocurra automáticamente como parte del release.
Audita tus alertas cada mes
Configurar alertas no es algo que se hace una vez y se olvida. Los sitios cambian, los patrones de tráfico varían y una alerta que tenía sentido hace seis meses ahora es la que todos silencian. Así que realiza una auditoría corta mensual con tres preguntas.
Primero, ¿qué alertas se dispararon sin que nadie actuara? Extrae la lista de alertas que se resolvieron solas sin respuesta humana. Cualquier regla que se disparó más de unas pocas veces sin acción es candidata a ser retirada o ajustada. Por definición está generando ruido, no señal.
Segundo, ¿qué incidentes no tuvieron alerta? La pregunta más reveladora. Revisa cualquier caída o período lento que un cliente u otro equipo detectó antes que tu monitoreo y añade el chequeo que lo hubiera detectado. Las brechas son más peligrosas que el ruido porque son silenciosas.
Tercero, ¿siguen los umbrales reflejando la realidad? Si tu p95 ha subido con el crecimiento del tráfico, tu antiguo umbral es ahora demasiado estricto o demasiado permisivo. Re-baséate con los números actuales en tus informes de disponibilidad y SLA en lugar de con los datos de cuando lo configuraste.
Este enfoque forma parte de un conjunto más amplio de mejores prácticas en monitoreo de sitios web, pero el alertamiento es donde vive la mayor parte del dolor diario. Configura las alertas correctamente y el resto del stack se tranquiliza por sí solo.
Construye alertas en las que tu equipo realmente confíe
Dotcom-Monitor confirma fallos desde una red global antes de alertar, enruta por gravedad a través de Slack, Teams, SMS y PagerDuty, y captura fallas de DNS, TLS, API y transacciones en la capa que se rompió. Mira cómo funciona el sistema de alertas de Dotcom-Monitor, o comienza con monitoreo de disponibilidad y ajusta desde ahí.
