Atualizado em junho de 2026 · Leitura de 11 minutos

Pergunte a qualquer engenheiro de plantão sobre seu monitoramento e eles dirão a mesma coisa: os alertas não são o problema. O problema é o ruído. Um stack típico dispara em toda amostra lenta, em toda falha de localização única, em toda verificação dependente que falha quando um serviço upstream quebra. Depois de algumas semanas disso, as pessoas param de ler os alertas. E na noite que ocorre uma falha real, ela cai no mesmo canal silenciado que 200 falsos positivos.
É assim que a fadiga de alertas aumenta o Tempo Médio para Resolução. A detecção nunca foi o gargalo. O sinal foi enterrado. Este guia é sobre como criar alertas de monitoramento de sites que disparam apenas quando a experiência do usuário está realmente comprometida, para que sua equipe confie neles o suficiente para agir quando isso acontecer. Vamos abordar lógica de confirmação, camadas de escalonamento, supressão consciente de dependências e matemática de limiares, com as configurações exatas que separam uma rotação calma de plantão de um pager que ninguém atende.
Por que a Maioria dos Alertas é Ruído, Não Sinal
Um alerta de monitoramento tem um trabalho: avisar um humano que algo está errado e precisa ser consertado. A maioria dos alertas falha nessa tarefa por três padrões comuns, e cada um tem uma solução clara.
Falsos positivos de localização única são os mais frequentes. Um agente de monitoramento em Frankfurt sofre uma falha transitória de rede, a verificação falha, o alerta dispara, e seu site nunca esteve indisponível para um usuário real. Execute monitoramento de uptime de uma única localização e boa parte das suas páginas será perda de pacotes entre seu monitor e sua origem, não interrupções reais.
Limiares instáveis vêm em seguida. Você configura um alerta de tempo de resposta em 2.000 ms porque parecia lento. Mas seu p95 (o tempo de resposta que os 5% mais lentos dos pedidos realmente experimentam) já fica em torno de 1.800 ms durante pico de tráfego, então o alerta dispara toda tarde, se limpa sozinho e dispara de novo. Ninguém age porque não há motivo para agir. O número estava errado, não o site.
E então vem a tempestade de alertas. A resolução DNS falha para seu domínio. Agora sua verificação da homepage falha, seu login falha, o checkout falha, as verificações da API falham e a verificação SSL falha porque o monitor não consegue alcançar o host. Uma causa raiz, quarenta alertas, todos disparando no mesmo minuto. O engenheiro de plantão precisa ler todos os quarenta para encontrar o que importa.
Corrija esses três padrões e você reduz a maior parte do ruído. O resto deste guia é como fazer isso.
Confirme uma Interrupção Antes de Acionar Alguém
A mudança de maior impacto que você pode fazer é exigir confirmação antes que um alerta dispare, e o Dotcom-Monitor é construído exatamente para isso. Em vez de disparar no primeiro teste falho, você configura as condições que uma falha precisa cumprir antes que alguém seja avisado: concordância de mais de uma localização e mais de uma verificação consecutiva falha. Ambos são configurados por monitor, assim você decide quanta prova cada teste precisa antes de disparar o alerta.
A confirmação multi-localização elimina o falso positivo na origem. Se uma verificação falha em Frankfurt mas passa simultaneamente em Dallas, Londres e Singapura, o problema está no caminho até Frankfurt, não no seu site. Uma falha real ocorre em todos. Essa é a função da rede global de monitoramento do Dotcom-Monitor: quando uma verificação falha, o Dotcom-Monitor automaticamente refaz o teste de outras localidades antes de enviar um alerta, para que um pico regional único nunca chegue à sua rotação de plantão. Você só ouve os alertas em que mais de um ponto de vista concorda.
A lógica de falha consecutiva lida com a falha momentânea. No sistema de alertas do Dotcom-Monitor, você configura um alerta para disparar somente após duas ou três verificações falharem seguidas, não na primeira. Em intervalo de um minuto, isso adiciona um ou dois minutos de latência na detecção em troca de cortar quase totalmente o ruído transitório. Para a maioria dos sites, essa troca vale a pena, e como o filtro é por monitor, uma página de marketing pode tolerar uma confirmação mais lenta que um endpoint de pagamento.
A confirmação realmente adiciona um pequeno atraso. Se você roda um sistema onde um segundo de downtime é realmente catastrófico, pode aceitar mais falsos positivos em troca de detecção mais rápida. A maioria das equipes não está nessa posição, e o trade-off da confirmação lhes garante pagers silenciosos.
Crie Camadas de Escalonamento que Combinem com a Gravidade
Um alerta e um escalonamento não são a mesma coisa. O alerta é o fato de uma verificação ter falhado. O escalonamento é a regra que decide quem recebe a notificação, por qual canal e o que acontece se ninguém responde. Alertas achatados, onde toda falha avisa todo mundo do mesmo jeito, são o caminho mais rápido para uma equipe que ignora seu pager.
Comece classificando as falhas em camadas de severidade e associando cada uma a um canal. O princípio é simples: quanto mais barulhento o canal, maior o patamar para usá-lo.
| Gravidade | Exemplo | Canal | Quem responde |
|---|---|---|---|
| Crítico | Checkout ou login indisponível, confirmado de múltiplas localidades | SMS, telefone, PagerDuty | Plantão, imediatamente |
| Alto | Página principal lenta além do p95 por 10 minutos | Slack ou Teams, @plantão | Plantão, em até uma hora |
| Baixo | Página de marketing lenta, único ativo com erro 404 | Resumo por e-mail, painel | Revisado no próximo dia útil |
Depois, adicione escalonamento baseado em tempo sobre a severidade. Um alerta crítico alcança Slack e o engenheiro de plantão simultaneamente. Se ele permanecer aberto após dez minutos, dispara novamente por SMS. Depois de vinte minutos, notifica o plantão secundário ou o líder da equipe. Ninguém precisa lembrar de escalar manualmente às 3 da manhã, e um alerta perdido não vira uma falha não resolvida.
O Dotcom-Monitor gerencia isso com grupos de notificação e agendas de escalonamento. Você define quem está de plantão, quais canais cada nível usa, e quanto tempo o alerta espera antes de subir para a próxima pessoa. Ele se integra aos canais que as equipes já usam, assim uma notificação no Slack ou Microsoft Teams alcança as pessoas trabalhando e um escalonamento no PagerDuty cuida do caminho fora do horário. O objetivo é rotear por severidade, não transmitir tudo e esperar que alguém perceba.
Permita que Verificações de Dependência Supprimam os Sintomas
A tempestade de alertas é um problema estrutural, e você resolve estruturalmente. Suas verificações têm uma ordem de dependência, e a maioria das equipes a ignora. Uma requisição para sua página de checkout depende da resolução DNS, depois da conexão TCP, depois da conclusão do handshake TLS, depois do retorno de conteúdo HTTP e, finalmente, o sucesso da transação. Quando algo baixo nessa pilha falha, tudo acima também falha.
Portanto, organize seu monitoramento da mesma forma que a requisição flui, e deixe a causa raiz silenciar os sintomas. O monitoramento multi-protocolo do Dotcom-Monitor torna isso prático: você monitora DNS, TCP, TLS, HTTP e a transação completa como verificações separadas, então quando algo falha você sabe qual camada quebrou e alerta nessa camada em vez da avalanche das camadas acima.
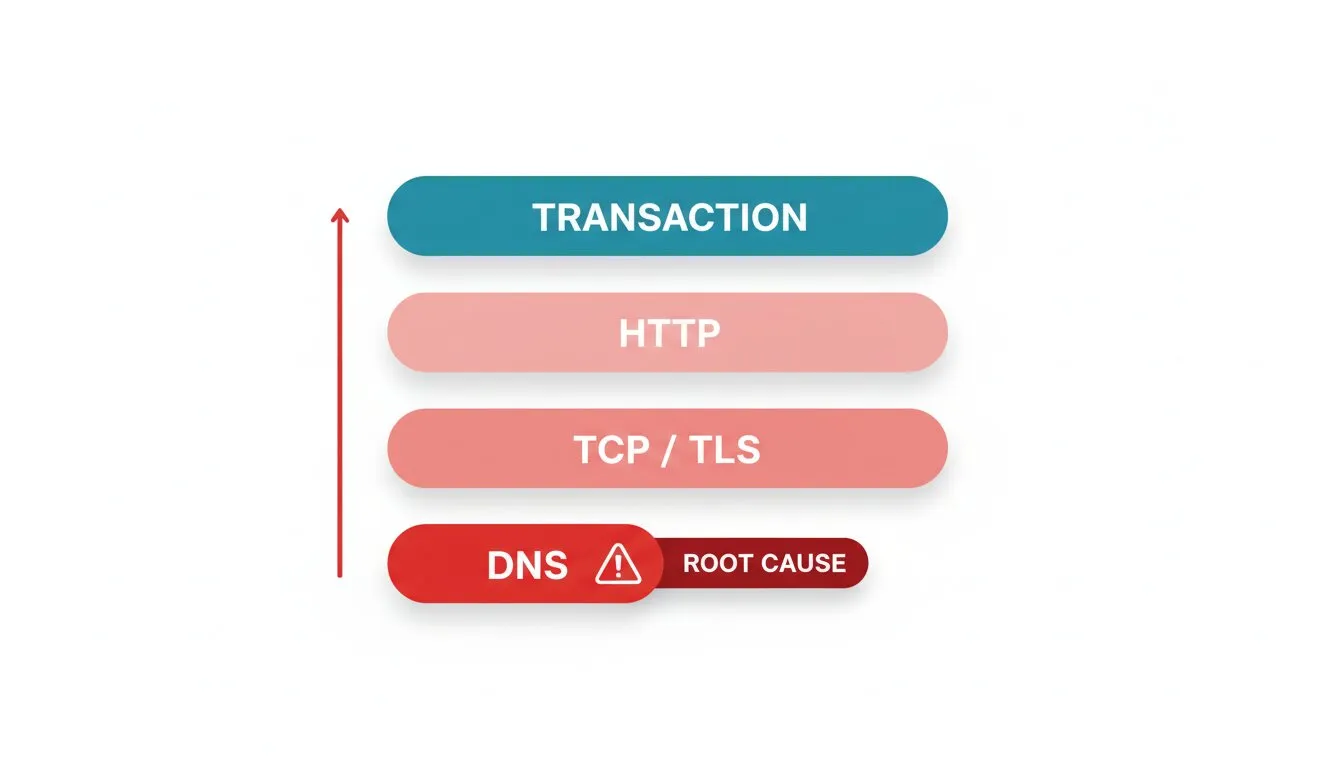
- DNS primeiro. Se o monitoramento DNS mostra falha na resolução, você já sabe porque todas as verificações abaixo estão vermelhas. Alerta na falha DNS e suprima o resto.
- Depois conexão e certificado. Um handshake TLS falho ou certificado expirado quebra todas as verificações HTTPS relacionadas. Detecte isso na camada de certificado com monitoramento de certificado SSL e você receberá um alerta único e claro em vez de uma enxurrada de falhas genéricas de páginas.
- Depois a aplicação. Se DNS, TCP e TLS estiverem saudáveis, mas a página ou a verificação API falharem, aí você tem um incidente genuíno na camada de aplicação que justifica o alerta.
O monitoramento de transação melhora ainda mais isso. Em vez de alertar sobre cada ativo individual, crie scripts do fluxo do usuário real que importa e alerte no fluxo. O EveryStep scripting do Dotcom-Monitor grava o caminho em navegador real, como buscar, adicionar ao carrinho e iniciar checkout, e alerta quando uma etapa específica falha. Se a etapa quatro quebra mas a homepage está ok, você recebe um alerta dizendo que o checkout está fora na etapa de pagamento, não vinte alertas dizendo que vários ativos retornaram erros. Essa é a diferença entre um alerta que explica o que quebrou e um que diz só que algo quebrou.
Agrupe monitores por dependência para que a falha principal silencie suas dependentes. Um alerta de causa raiz vence quarenta alertas de sintomas toda vez.
Formate Limiares Para Que Alertas Signifiquem Algo
Um limiar é uma promessa de que cruzar essa linha indica algo errado. A maioria dos limiares quebra essa promessa porque são números estáticos escolhidos uma vez e nunca revisados. Três regras os mantém honestos.
Use Percentis, Não Médias
Médias escondem as requisições lentas que realmente prejudicam os usuários. Uma página pode ter média de 900 ms enquanto o p95 fica em 3 segundos, o que significa que um em cada vinte visitantes espera 3 segundos. Alerta no p95, ou p99 para fluxos de checkout, porque essa é a experiência dos usuários reais mais lentos. Os relatórios de desempenho do Dotcom-Monitor detalham tempo de resposta por percentil e por localização, para que você configure limiares refletindo a experiência real, não uma média favorável.
Exija uma Violação Sustentada
Uma única amostra lenta não é um incidente. No Dotcom-Monitor você aplica o mesmo filtro de falha consecutiva para desempenho que usa para disponibilidade, fazendo com que o alerta de tempo de resposta só dispare após várias verificações lentas consecutivas, não na primeira que ultrapassa o limite. Isso reduz as oscilações de tráfego da tarde que treinam as pessoas a ignorar alertas de latência.
Alerta Antecipado para Tudo Que Expira
Certificados e domínios não degradam. Funcionam e um dia param. Então o limiar não é um número de desempenho, é uma data no calendário. Dispare um alerta SSL 30 dias antes da expiração e novamente 7 dias antes, transformando uma indisponibilidade de madrugada em um ticket de rotina. O alerta correto para certificado faz a renovação acontecer em horário comercial, não durante um incidente.
Se quiser vincular limiares de desempenho a números de negócio, uma calculadora de orçamento de erros ajuda a calcular quanta degradação seu SLA pode absorver antes de valer a pena acordar alguém por um alerta.
Uma Falha no Checkout às 2 da Manhã, Passo a Passo
Junte as peças com um padrão real que a maioria das equipes de ops já viveu. São 2:14 AM. Um certificado no domínio intermediário do seu gateway de pagamento expira.
Sem engenharia de alertas: Todas as verificações HTTPS relacionadas a esse certificado falham de uma vez. O telefone do engenheiro de plantão se acende com 30 SMS: página principal caída, checkout indisponível, página de conta fora, três endpoints de API inacessíveis, falhas variadas em ativos. Ele acorda, encara um muro de alertas idênticos e passa quinze minutos descobrindo que não são trinta problemas diferentes. O MTTR já está comprometido antes de qualquer conserto.
Com engenharia de alertas: A verificação de monitoramento de certificado SSL identifica o certificado expirado como causa raiz. O agrupamento por dependência suprime os alertas de página e API abaixo, porque o pai já falhou. O engenheiro recebe um SMS crítico: certificado expirado no intermediário de pagamento, confirmado de cinco locais. Ele sabe exatamente o que quebrou e onde, e já está renovando o certificado enquanto o velho sistema ainda contaria alertas.
A falha e a velocidade de detecção são idênticas em ambas versões. O que muda a noite é como os alertas foram construídos. E aquele alerta de certificado que deveria ter disparado 30 dias antes? Essa é a versão onde o incidente nem acontece.
Silencie o Ruído Durante Deploys e Manutenção
Alertas autoinduzidos representam grande parte do volume total e são os mais fáceis de eliminar. Quando você faz deploy, roda migração ou tira um serviço para manutenção planejada, suas verificações falharão. Se essas falhas notificarem o engenheiro de plantão, você treina a equipe para esperar falsos alarmes nos momentos em que deveriam estar mais atentos.
Configure janelas de manutenção para que o monitoramento suprima alertas durante trabalhos planejados e retome automaticamente depois. O Dotcom-Monitor permite agendar isso por dispositivo ou grupo, assim um deploy no serviço de checkout silencia só os alertas do checkout sem calar o resto do site. Combine com seu pipeline CI/CD e a janela de supressão pode abrir e fechar junto ao deploy.
Configurar a janela tem que ser um hábito, porque esquecer de definir uma janela é como não ter janela nenhuma. Inclua a supressão no runbook do deploy para não ser algo a lembrar às 23h na noite de lançamento. Se fizer deploys frequentes, integrar monitoramento no pipeline CI/CD permite a supressão automática como parte do release.
Audite Seus Alertas Todo Mês
A configuração de alertas não é para definir e esquecer. Sites mudam, padrões de tráfego se alteram, e um alerta que fazia sentido há seis meses é hoje aquele que todo mundo silencia. Então faça uma rápida auditoria mensal com três perguntas.
Primeiro, quais alertas dispararam sem que ninguém agisse? Puxe a lista de alertas que se resolveram sozinhos sem resposta humana. Qualquer regra que disparou muitas vezes sem ação é candidata à aposentadoria ou ajuste. Por definição, gera ruído e não sinal.
Segundo, quais incidentes não tiveram alerta? A pergunta mais reveladora. Revise qualquer queda ou período lento que um cliente ou outra equipe tenha detectado antes do seu monitoramento, e adicione a verificação que teria detectado. Lacunas são mais perigosas que ruído porque são silenciosas.
Terceiro, os limiares ainda refletem a realidade? Se seu p95 subiu com o crescimento do tráfego, seu limiar antigo está apertado demais ou frouxo demais. Reajuste com base nos dados atuais nos relatórios de uptime e SLA em vez dos números de quando configurou.
Essa abordagem fica dentro de um conjunto maior de melhores práticas de monitoramento de sites, mas onde a maior parte da dor diária está é em alertas. Configure os alertas corretamente e o restante do stack fica mais silencioso sozinho.
Construa Alertas em Que Sua Equipe Realmente Confie
O Dotcom-Monitor confirma falhas a partir de uma rede global antes de avisar, roteia por severidade pelo Slack, Teams, SMS e PagerDuty, e detecta falhas de DNS, TLS, API e transação na camada que quebrou. Veja como funciona o sistema de alertas do Dotcom-Monitor, ou comece com monitoramento de uptime e ajuste a partir daí.
