 良いモニタリングは、お客様に気づかれる前に、何が壊れたのか、どこで、なぜそうなったのかを教えてくれます。
良いモニタリングは、お客様に気づかれる前に、何が壊れたのか、どこで、なぜそうなったのかを教えてくれます。
ほとんどのチームはウェブサイトのモニタリングをしています。しかし、お客様、営業、サポートが問題に気づく前に実際に問題を検知できるウェブサイトモニタリングを持っているチームははるかに少ないです。その差はツールにあることはまれで、多くはそれを取り巻く運用方法、つまり何をどこからどの頻度でチェックするのか、どんな条件でページをトリガーし、誰がチェックの失敗とサイトの故障を判断するかにあります。
このプレイブックは、SREやDevOpsチームが信頼する設定と、静かにノイズと化す設定を分ける8つのウェブサイトモニタリングベストプラクティスをまとめました。すべて具体的で、閾値、間隔、アンチパターン、うまく機能した後も続けるべきことが含まれます。これらのプラクティスは、マーケティングサイトの稼働監視でも、SaaSのチェックアウト全体で実行する合成トランザクション監視でも同様に適用されます。
「良い」とは何か(そしてなぜ多くの設定がそれを逃すのか)
動作定義:お客様が問題を知るより前に、モニターからすべての顧客向け問題を知り受け取るページがほぼ常にアクション可能であれば、モニタリングは良いと言えます。それが唯一の基準です。
3つの数字で追跡します。平均検出時間(MTTD)は監視が十分に速いかを示し、平均解決時間(MTTR)はモニターが表面化するデータが問題を修正するのに十分かを示します。アラートの精度(リアルで即時対応が必要なページの割合)は、チームが6ヶ月後もアラートを信頼し続けられるかどうかを示します。ほとんどのSREチームはMTTDとMTTRを測定しますが、多くのチームは精度を測定していないため、オンコール体制が無言の承認や学習した無力感に陥りがちです。
このプレイブックの残りは、同時に両方の数値を正方向に押し上げることについて説明します。
リクエスト全体パスにまたがるレイヤーチェックを実施する
単一のHTTPSチェックは1つのセンサーを持つ煙感知器です。それは何かが間違っていることを伝えますが、どこが原因かは示しません。ユーザーがURLを入力し、ページが表示されるまでにリクエストは少なくとも6つのレイヤーを通過します:DNS解決、TCPハンドシェイク、TLS交渉、HTTPレスポンス、アセット読み込み、最終ビューのクライアント側レンダリングです。各レイヤーは異なる方法で失敗し、それぞれに固有の原因があります。
 レイヤー毎に1つチェック。各レイヤーは異なる障害面と独自の修正方法があります。
レイヤー毎に1つチェック。各レイヤーは異なる障害面と独自の修正方法があります。
実用的なセットアップは以下の通りです:
- DNS: A、AAAA、CNAME、MXレコードが複数のリゾルバーから期待通り解決されるかを確認。DNSの問題は最も見落とされやすく、後からデバッグするのが最も手間がかかります。最高のDNS監視ツールは、不正なレコード変更、伝播遅延、リゾルバー固有の障害を監視します。
- TCPとICMP: ポートが開いており、ネットワークパスが正常か確認。ファイアウォールの変更で443が遮断されても同じネットワークセグメントからのHTTPチェックでは検出されません。
- TLS: 証明書チェーン、有効期限、ホスト名一致、暗号サポートを検証。多くの証明書障害は防げます—単に日曜日に証明書が期限切れになっただけです。60日、30日、14日、3日前に明確な期限切れアラートを取得してください。詳細はSSL証明書期限監視方法を参照。
- HTTP: ステータスコード、レスポンスタイム、コンテンツの検証。ステータス200で空のボディは成功ではなく失敗と見なします。
- レンダーとトランザクション: 実際のブラウザーでユーザージャーニーをドライブし、最終状態の既知の要素を検証し、インタラクティブになるまでの時間を計測。合成監視はプロトコルチェックで検出できない破損したJavaScript、ハングするサードパーティスクリプト、不足してカートボタンを不可視にするCSSファイルなどを捕捉します。
- API: APIを一級のエンドポイントとして扱います。サイトは読み込めても、決済APIがタイムアウトしてチェックアウトが完了しないならサイトは壊れています。API監視は依存するページとは別のスケジュールでチェックすべきです。
何かが壊れたら、最初にアラートを出したレイヤーが根本原因調査の出発点です。HTTPだけを監視するチームは「ダウン」という情報しか得られませんが、全6レイヤーを監視するチームは障害ツリーが得られます。
合成監視とRUMを並行運用し、置き換えない
2つの方法は異なる質問に答え、代替ではありません。以下の表は両方を四半期運用後に多くのチームがたどり着く分割をまとめています。
| 能力 | 合成監視 | 実ユーザーモニタリング(RUM) |
|---|---|---|
| データソース | 制御された場所からのスクリプト化されたチェック | 実際の訪問者のブラウザ |
| トラフィックゼロでも動作 | はい | いいえ |
| 一貫したベースライン | はい―同じスクリプト、同じ場所 | いいえ―トラフィックの混合により変動 |
| ユーザーが気づく前にリグレッションを検知 | はい | いいえ |
| 実際のデバイスとネットワークの多様性を反映 | 限定的 | はい |
| 最適な用途 | SLAレポート、積極的アラート、稼働監視 | 実ユーザー体験分析、修正優先順位付け |
| よくある失敗モード | スクリプト化されていないエッジケースの見逃し | Twitterから障害を知る |
合成監視は固定スケジュールで決まった場所からスクリプト化されたチェックを実行します。データは時間を通じて一貫しており、トラフィックの途絶に左右されません。また、午前3時のように実際のユーザーがいない時間でも動作し、たとえばログインページを壊したデプロイに誰も気づかないときにも検知します。だからこそ、合成監視はSLAレポート、リグレッション検知、積極的アラートに適したツールです。
RUMは実際のブラウザからパフォーマンスとエラーデータを収集し、ユーザーが実際に使うデバイス、ネットワーク、地域の分布を反映します。特定のキャリアの2%のAndroidユーザーが最初のバイトまでに9秒かかっていることを伝えられる唯一のソースです。RUMは実際のユーザー体験を理解し、エンジニアリング作業の優先順位を付けるのに適しています。
合成監視はサイトが稼働して正常に動作していることを知るために使い、RUMはその動作が実際にサービスを支払っている人にどう影響するかを把握するために使います。どちらか一方を選び、もう一方をスキップするチームは、エッジケース(合成のみ)に不意を突かれたり、障害をTwitterで知ったり(RUMのみ)します。
サイトの両側面を見てみよう
Dotcom-Monitorはグローバルチェックポイントネットワークからの実ブラウザー合成監視を実行し、フロントエンドチームがすでに収集しているRUMデータと統合します。1つのプラットフォームで両方の視点を実現。
収益を生む地域から監視を行う
隣のデータセンターからのチェックは、データセンターがオンラインかどうかは教えてくれますが、サンパウロのユーザーが快適かどうかは教えてくれません。
ルールはシンプルです:収益に意味のある貢献をするすべての地域にチェックポイントを置き、加えて1~2の対照地域を設けます。売上の35%がEMEAなら、最低でも2つのEMEAチェックポイントが必要です―フランクフルトやロンドンなどの主要市場に1つ、マドリードやストックホルムなどの二次市場に1つ。単一チェックポイントのEMEAは地域のISP障害やCDNエッジの障害を隠します。
設定すべき3つのパターン:
- 複数地域からのページング確認。 異なる少なくとも2つの地域で60秒以内に失敗が繰り返されてからページング。単一地域の失敗は通常地域キャリアの問題か単一チェックポイントの問題でサイト障害ではありません。
- 地域別ベースライン。 東京とアイオワは同じ速度でサイトを読み込まないし、閾値も共有すべきではありません。地域ごとのp95レイテンシーを追跡し、地域偏差でアラートしグローバル平均にはしない。
- 企業ネットワーク内のプライベートエージェント。 ファイアウォールの背後からのアクセスがある企業向けなら、その環境内にチェックポイントを設置。プライベートエージェントは顧客のネットワークに起因する問題を捕捉し、顧客にとっては自社の問題のように感じられる。
Dotcom-Monitorのチェックポイントネットワークは30以上の国に広がり、どの地域を有効化するかはデータセンターの場所ではなく、収益がどこから来るかに依存します。
閾値は丸数字ではなくベースラインから設定する
最もよくあるモニタリング上の過ちが「応答時間 > 3秒ならアラート」です。3秒は丸数字ですがサイトは丸数字を気にしません。p95が安定して4.2秒なら、通常動作で一日に24回もページングされます。p95が0.8秒から2.5秒に低下しても、2.5秒は3秒以下なので何も起こりません。
修正はベースラインに相対した閾値:
10分間のウィンドウで持続的にp95が(ベースラインp95 × 1.5)または(ベースラインp95 + 2σ)のいずれか大きい方を超え、2つの連続した評価ウィンドウで条件が続く場合にアラート。
この式は3つの役割を担います。1.5倍乗数はページごとにスケールし、速いページも遅いページも同じルールを共有可能にします。2σ項は通常の変動を抑制します。2連続のウィンドウ条件はスパイクして回復する偽陽性のほとんどを排除し、ページングのノイズを減らします。
多くのチームが飛ばすのがベースライン算出です。過去14日間のデータから週次でベースラインを再計算し、デプロイ時間帯と既知のインシデント期間を除外します。自動ベースライン作成の異常検出製品は手動管理したくない場合のショートカットとして良いですが、除外内容を検証してください。前週のインシデントが含まれるベースラインは無いのと同じです。
稼働チェックの同等ルール:2つの異なる地域で連続して2回失敗が発生しない限り、ページングしない。1地点の単一の失敗はほぼ必ずチェックポイントの小障害です。2地点2回は本当の障害。
チェックだけでなくアラートも設計する
チェックは何かが起こったことを告げます。アラートは人に何か対応させます。この2つは別の問題で、多くのチームは前者だけを設計します。
アラート設計の仕事は、適切な情報を適切な人に60秒以内に対応できるフォーマットで届けること。阻害要因は普通以下です:
- アラートが多すぎる。 平均で1回のシフトに3回以上呼び出されると、次のページは注意が薄れてトリアージされます。これは道徳的失敗ではなく人間の注意の仕組みです。
- 文脈の無いアラート。 「チェックアウト遅延」は対応不能。「EU地域のチェックアウトp95が4.8秒(ベースライン1.1秒)、14:32 UTC開始、デプロイabc123と14:30に相関」は対応可能。
- 誤ったチャネル。 Slackやメールはページングではない。SMS、プッシュ通知、電話がページング。混ぜると信号が希釈される。
成功するパターン:
- 重要度3層、チャネル3種。 致命的(サイトダウン、決済障害)→ SMS/電話。警告(持続的劣化)→ プッシュまたはオンコール言及ありチャット。情報(単一チェック失敗、ベースラインドリフト)→ ダッシュボードまたは日次要約。情報でページングはしない。
- 依存性抑制。 DNSが失敗したら、それに依存する14のHTTPチェックでページングしない。アラートグループ化と依存性抑制は必須。未対応だと睡眠時間で支払うことになる。
- エスカレーションは連鎖でなく格子状に。 プライマリオンコールが5分以内に応答しなければセカンダリにページし、同時にチャネル通知。直列エスカレーションはサイトダウン中に1段で5分の遅れを生む。
- 非致命的な時間帯は静かに。 日曜午前2時の性能低下には通常起こす必要なし。致命的は除く。ルール設定時に正直であること。
そして精度を測定。毎月、発動したページングを数え、それぞれに「実インシデント」「偽陽性」「対応不要」をタグ付け。精度が80%未満なら、新規追加前に最も騒がしいアラートを修正せよ。
制御できない要素もカバーする
サイトはコードだけではありません。現代のチェックアウトページは決済プロセッサー、タグマネージャー、分析プロバイダー、チャットウィジェット、A/Bテストツール、CDN、時には不正検知サービスからスクリプトをロードします。どれかが失敗すればページ全体が落ちます。
サードパーティ依存はそれぞれ独自のモニターが必要:
- 地域別CDNエッジの応答時間。 CDNは特に地域イベント中に障害を起こすことがある。
- 決済ゲートウェイの往復時間を状態エンドポイントやサンドボックスに対する合成APIチェックとして。
- タグマネージャーや分析スクリプトの読み込み時間を合成トランザクションの一部として計測。ブロッキング分析タグはすべてのページに2秒追加するので検知したい。
- 外部認証プロバイダー(OAuth、SSO)。「Googleでログイン」ボタンが機能しなくなったらサポートより先に知る必要がある。
- DNSプロバイダー。 複数のリゾルバーからのDNS監視を実施し、伝播遅延やプロバイダーの部分的な障害を捕捉。
どのサードパーティがどのユーザージャーニーを阻害するか記録し、その障害時の対応が「フォールバック」「様子を見る」「ベンダーのオンコールにページ」なのかをルンブックに書く。これがないとすべてのサードパーティ障害が即興対応になる。
すべてのモニターにルンブックを紐づける
インシデントの最も時間のかかる最初の5分はオンコールエンジニアがアラートの意味を理解しようとする時間です。
これを一度直す:すべてのモニターがルンブックのエントリーにつながる。ルンブックは大げさである必要はなく、3つのセクションで十分:
- このチェックがカバーする範囲を1文で(「フランクフルトとアムステルダムからEUのチェックアウト取引が5秒以内に完了することを検証」など)
- 発動時に最初に確認すべき5つ:ステータスページリンク、ダッシュボード、最近のデプロイ、関連アラート、ベンダーのステータスページ。
- 既知の偽陽性パターン、あれば(「フランクフルトのチェックポイントはベンダー保守時間の土曜02:00-02:30 UTCにタイムアウトすることがあり抑制済み」など)
ルンブックを書くのは初回は15分、以降は該当モニターのインシデント毎に15分短縮。効果は明白で大半のチームはまだこれを実施していません。
モニターの検証とカバレッジの四半期監査
未検証のモニターは願望であって保証ではありません。ギャップを発見するために2つの方法があります。
アラートのカオスドリル。 四半期に一度、故意にチェックを壊します―テストエンドポイントをシャットダウン、ステージング環境で証明書期限切れ、応答時間閾値を0に下げる―そしてアラートが発動し、エスカレーションし、適切な人物に届くことを確認します。約3割のアラートは最初のドリルに失敗します。主な原因はオンコールのローテーションが古い、統合トークンの期限切れ、誰も見なくなったSlackチャンネルなど。
カバレッジマップの四半期監査。 すべてのユーザージャーニー、外部依存、URLカテゴリを列挙した単一ドキュメントを管理し、各行にそれをカバーするモニターをリスト化。空行はギャップ。直近四半期に追加された新機能は通常空行に存在。
監査は逆の発見も生みます:もう存在しないURLを監視しているモニター。削除せよ。410エンドポイントのモニターは永遠にノイズを発生させ、何も守りません。
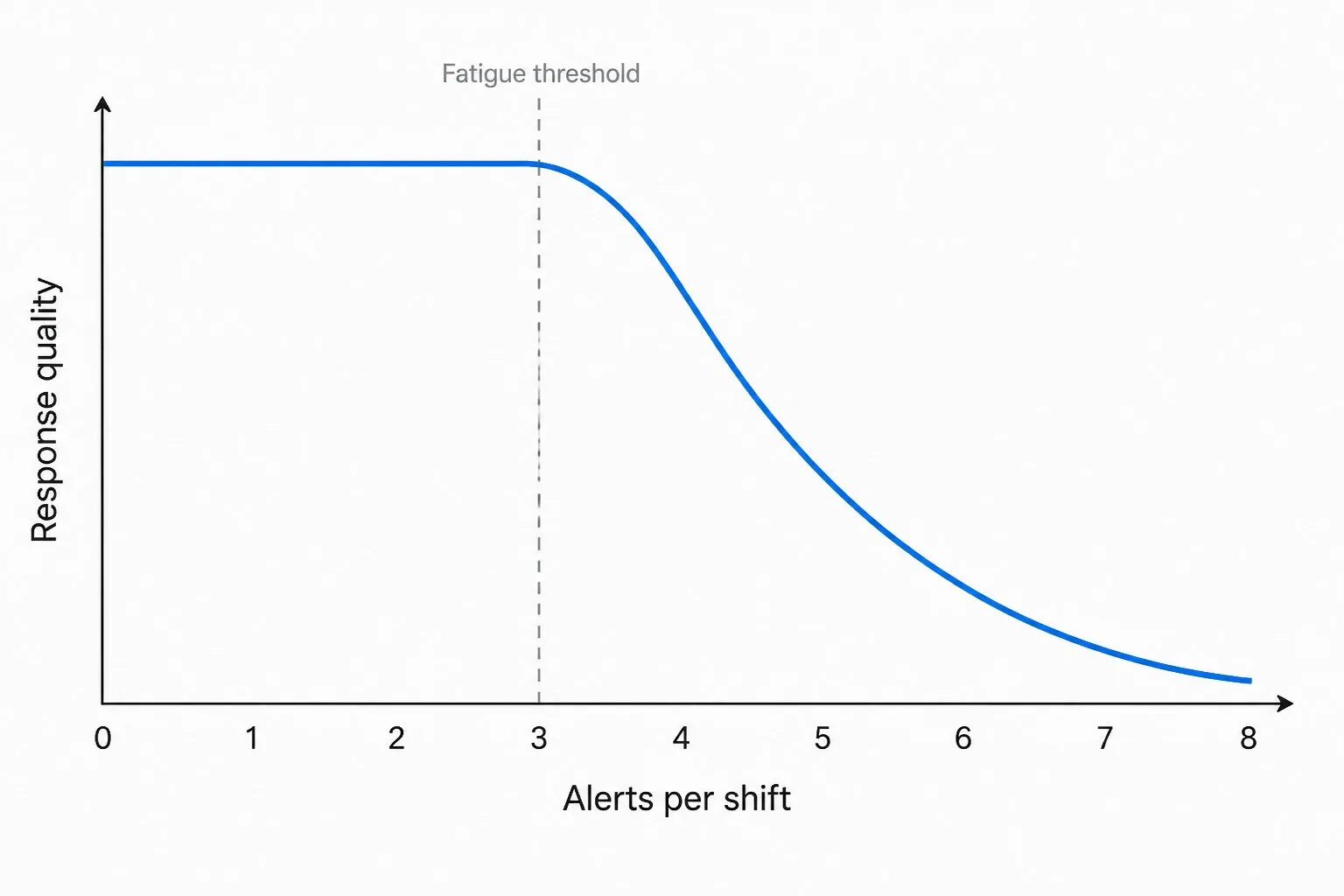 1シフトあたり3ページを超えると、応答品質はアラート量の増加より速く低下する。
1シフトあたり3ページを超えると、応答品質はアラート量の増加より速く低下する。
モニタリングプラットフォーム選定時の確認ポイント
ほとんどのプラットフォームはURLをpingできます。違いは難しいケースで現れます。ツール評価時はダッシュボードデモだけでなく以下を尋ねてください:
- 条件分岐を含む実ブラウザトランザクションをスクリプト化できるか? 静的な録画はページが変われば壊れます。スクリプト化されたトランザクション監視(Selenium風や独自)は通常の製品進化に耐えます。
- ネイティブプロトコルの対応数は? HTTP, HTTPS, DNS, FTP, SMTP, IMAP, POP3, TCP, UDP, ICMP。ひとつひとつ別ツールに外注するとベンダー付き合いとログインが増えます。
- グローバルチェックポイントの実際のフットプリントは? 200「チェックポイント」が3つのクラウドリージョンにあるだけならグローバルではありません。都市リストを要求せよ。
- 自社ネットワーク内で動かせるか? プライベートエージェントはステージング環境や内部アプリ、顧客限定デプロイ監視に必要。
- アラートの依存関係やグループ化はどう処理する? DNS障害で14回ページングするプラットフォームはストレスを買っています。
- データエクスポートの形式は? 生のチェック結果を自社アナリティクスに取り込めなければ、厄介なインシデントを調査できません。
- インシデントツールとの統合は? PagerDuty、Opsgenie、Slack、Microsoft Teams、ServiceNow、Jira。ネイティブ統合はWebhookより優れます。
詳しい購入者チェックリストと評価基準は最高のウェブサイト監視ツールの選び方とDatadogの競合と代替案を参照ください。
よくある障害モード
以下のパターンはほぼすべての監査で登場します。修正には新しいツールは不要です。
- 多地域サイトに対してグローバル1閾値のみ。 速い地域が遅くなり、遅い地域が悪化し、グローバル平均は正常に見えてアラートが発動しない。
- コンテンツ検証のないステータス200チェック。 CDNエラーページの空白200がチェックに合格し、本番で破綻。
- 実顧客アカウントに依存する合成トランザクション。 パスワード期限切れ、MFA登録、アカウントロック。明示的監視スコープを持つサービスアカウントを使うべし。
- 7日の証明書アラートのみ。 7日は期限切れのデッドラインで警告ではない。その時点で誰かが対応に追われている。60、30、14、3日前にアラートを。SSL証明書モニタリングは段階的に設定すべき。
- デプロイとの相関なし。 「このアラートはデプロイabc123の3分後に発動」の表示がなければ、すべてのインシデントは手動gitログレビューから始まる。CIを監視注釈と連携せよ。
- 閾値が永久に調整されない。 2年前に「> 5秒」と設定し、今はサイトが倍速なら、その閾値は実質無効化している。
- ホームページを監視し、重要パスを監視しない。 ホームページの可用性は見かけだけ。チェックアウト、サインアップ、ログインの可用性がビジネス。
API、スクリプト化ジャーニー、マイクロサービストポロジー周りの詳細はウェブアプリケーションモニタリング ベストプラクティスを参照。レイテンシ予算の重要性のSEO側面はウェブサイト速度がSEOに与える影響にて。
プレイブックを実践に活かす
現状のセットアップでカバーしていないプラクティスをこのリストから3つ選び、今スプリントで実装。新モニターはカオスドリルを実行してから完成と呼ぶ。30日後に精度監査。
プラットフォームにボトルネックがあるなら、Dotcom-Monitorは全スタックを1箇所でカバー:実ブラウザー合成監視、マルチプロトコルチェック、グローバルチェックポイントネットワーク+プライベートエージェント、そして上記パターンに適したアラート設計機能。ウェブアプリケーションモニタリング、API監視、DNS監視、SSL証明書監視をご確認、または大規模環境向けのエンタープライズ監視概要へ直接。
このプレイブックが書かれたプラットフォームをお試しあれ
30以上の国からの実ブラウザ監視、マルチプロトコルチェック、スクリプト化トランザクション、睡眠を尊重するアラート設計。
無料のDotcom-Monitorトライアルを開始 → クレジットカード不要。あるいは料金プランを見る。
