Aktualisiert Juni 2026 · 11 Minuten Lesezeit

Fragen Sie jeden Bereitschaftsingenieur nach seinem Monitoring, und er wird Ihnen dasselbe sagen: Die Alarme sind nicht das Problem. Es ist der Lärm. Ein typischer Stack löst bei jeder langsamen Stichprobe aus, bei jedem kurzen Aussetzer an einem einzelnen Standort, bei jeder abhängigen Überprüfung, die anspringt, wenn ein vorgelageter Dienst ausfällt. Nach ein paar Wochen lesen die Leute die Alarme nicht mehr. Und in der Nacht, in der ein echter Ausfall eintritt, landet dieser im selben stummgeschalteten Kanal wie 200 Fehlalarme.
So sorgt Alarmmüdigkeit für eine Erhöhung der mittleren Wiederherstellungszeit (Mean Time to Resolution). Die Erkennung war nie der Engpass. Das Signal wurde verschüttet. Dieser Leitfaden handelt davon, Website-Monitoring-Alarme zu erstellen, die nur dann ausgelöst werden, wenn die Benutzererfahrung tatsächlich beeinträchtigt ist, damit Ihr Team ihnen genug vertraut, um zu handeln, wenn sie auftreten. Wir behandeln Bestätigungslogik, Eskalationsstufen, abhängigkeitssensitive Unterdrückung und Schwellenwertmathematik, mit den genauen Einstellungen, die eine ruhige Bereitschaftsschicht von einem Pager unterscheiden, den niemand beantwortet.
Warum die meisten Alarme Lärm und kein Signal sind
Ein Monitoring-Alarm hat eine Aufgabe: einem Menschen mitzuteilen, dass etwas falsch ist, das er beheben muss. Die meisten Alarme scheitern an dieser Aufgabe durch drei gängige Muster, und jedes hat eine einfache Lösung.
Fehlalarme an einem einzelnen Standort sind die häufigsten. Ein Überwachungsagent in Frankfurt hat eine vorübergehende Netzwerkstörung, die Überprüfung schlägt fehl, der Alarm wird ausgelöst, und Ihre Seite war für keinen echten Nutzer jemals wirklich offline. Wenn Sie die Verfügbarkeit nur von einem Standort aus überwachen, sind viele Ihrer Seitenpakete wegen Paketverlust zwischen dem Monitor und Ihrem Ursprung nicht tatsächlich ausgefallen.
Als nächstes kommen schwankende Schwellenwerte. Sie setzen eine Antwortzeit-Warnung bei 2.000 ms, weil das langsam erschien. Aber Ihr p95 (die Antwortzeit, die Ihre langsamsten 5 % der Anfragen tatsächlich sehen) liegt bereits während der Spitzenzeit bei etwa 1.800 ms, sodass der Alarm jeden Nachmittag anspringt, von selbst wieder verschwindet und erneut ausgelöst wird. Niemand reagiert darauf, weil es nichts zum Reagieren gibt. Die Zahl war falsch, nicht die Seite.
Und dann gibt es den Alarmsturm. Die DNS-Auflösung für Ihre Domain schlägt fehl. Jetzt schlagen Ihre Homepage-, Login-, Checkout-, API- und SSL-Checks fehl, weil der Monitor den Host nicht erreichen kann. Eine Ursache, vierzig Alarme, alle innerhalb derselben Minute ausgelöst. Der Bereitschaftsingenieur muss alle vierzig lesen, um den einen zu finden, der zählt.
Beheben Sie diese drei Muster, und Sie entfernen den Großteil des Lärms. Der Rest dieses Leitfadens zeigt Ihnen, wie.
Bestätigen Sie einen Ausfall, bevor Sie jemanden pagern
Die wirkungsvollste Änderung, die Sie vornehmen können, ist, eine Bestätigung zu verlangen, bevor ein Alarm ausgelöst wird, und Dotcom-Monitor ist genau darauf ausgelegt. Anstatt beim ersten fehlgeschlagenen Check zu pagern, legen Sie die Bedingungen fest, die ein Fehler erfüllen muss, bevor jemand davon hört: Übereinstimmung von mehr als einem Standort und mehr als einem aufeinanderfolgenden Fehlcheck. Beides wird pro Monitor konfiguriert, sodass Sie entscheiden, wie viel Beweis jeder Check benötigt, bevor er läutet.
Die Bestätigung an mehreren Standorten eliminiert den Fehlalarm an der Quelle. Wenn ein Check von Frankfurt fehlschlägt, aber gleichzeitig in Dallas, London und Singapur bestanden wird, liegt das Problem beim Pfad nach Frankfurt, nicht bei Ihrer Seite. Ein echter Ausfall schlägt überall fehl. Das ist die Aufgabe des Dotcom-Monitor globalen Monitoring-Netzwerks: Wenn ein Check fehlschlägt, testet Dotcom-Monitor ihn automatisch von weiteren Standorten aus erneut, bevor er einen Alarm sendet, sodass ein einzelner regionaler Ausrutscher nie Ihre Bereitschaftsschicht erreicht. Sie hören nur von Ausfällen, denen mehr als ein Standort zustimmt.
Die Logik für aufeinanderfolgende Fehler behandelt den Momentanfehler. Im Dotcom-Monitor Alarmierungssystem stellen Sie ein, dass ein Alarm erst nach zwei oder drei aufeinanderfolgenden fehlgeschlagenen Checks ausgelöst wird, nicht beim ersten. Bei einem Intervall von einer Minute bedeutet das eine Verzögerung von ein oder zwei Minuten bei der Erkennung, im Austausch dafür wird der transiente Lärm nahezu komplett beseitigt. Für die meisten Seiten ist dieser Kompromiss offensichtlich sinnvoll, und da der Filter pro Monitor eingestellt wird, kann eine Marketingseite eine langsamere Bestätigung tolerieren als eine Zahlungs-Endpunkt.
Die Bestätigung fügt eine kleine Verzögerung hinzu. Wenn Sie ein System betreiben, bei dem eine Sekunde Ausfallzeit wirklich katastrophal ist, akzeptieren Sie möglicherweise mehr Fehlalarme zugunsten einer schnelleren Erkennung. Die meisten Teams sind nicht in dieser Situation, und der Kompromiss mit Bestätigung sorgt für ruhige Pager.
Bauen Sie Eskalationsstufen, die der Schwere entsprechen
Ein Alarm und eine Eskalation sind nicht dasselbe. Der Alarm ist die Tatsache, dass ein Check fehlgeschlagen ist. Die Eskalation ist die Regel, die bestimmt, wer davon erfährt, über welchen Kanal, und was passiert, wenn niemand reagiert. Flaches Alarmieren, bei dem jeder Fehler alle auf dieselbe Weise alarmiert, ist der schnellste Weg zu einem Team, das seinen Pager ignoriert.
Beginnen Sie damit, Fehler in Schweregrade zu sortieren und jedem einen Kanal zuzuordnen. Das Prinzip ist einfach: Je lauter der Kanal, desto höher die Hürde, ihn zu verwenden.
| Schwere | Beispiel | Kanal | Wer reagiert |
|---|---|---|---|
| Kritisch | Checkout oder Login ausgefallen, von mehreren Standorten bestätigt | SMS, Telefon, PagerDuty | Bereitschaft, sofort |
| Hoch | Kernseite länger als 10 Minuten langsamer als p95 | Slack oder Teams, @on-call | Bereitschaft, innerhalb einer Stunde |
| Niedrig | Marketing-Seite langsam, einzelne Ressource 404 | E-Mail-Digest, Dashboard | Am nächsten Werktag geprüft |
Dann fügen Sie zeitbasierte Eskalation zusätzlich zur Schwere hinzu. Ein kritischer Alarm trifft Slack und den Bereitschaftsingenieur gleichzeitig. Wenn er nach zehn Minuten noch offen ist, wird ein zweiter Alarm per SMS gesendet. Nach zwanzig Minuten wird die sekundäre Bereitschaft oder der Teamleiter benachrichtigt. Niemand muss sich daran erinnern, um 3 Uhr morgens manuell zu eskalieren, und ein verpasster Pager wird nicht zum verpassten Ausfall.
Dotcom-Monitor verwaltet dies mit Benachrichtigungsgruppen und Eskalationsplänen. Sie definieren, wer Bereitschaft hat, welche Kanäle jede Stufe nutzt und wie lange ein Alarm wartet, bevor er zur nächsten Person weitergeleitet wird. Es integriert sich in die Kanäle, in denen Teams bereits aktiv sind, sodass eine Slack- oder Microsoft Teams-Benachrichtigung die Mitarbeitenden erreicht und eine PagerDuty-Eskalation den Nachtschichtweg übernimmt. Ziel ist es, nach Schwere zu routen, nicht alles zu senden und darauf zu hoffen, dass es jemand bemerkt.
Lassen Sie Abhängigkeitsprüfungen Symptome unterdrücken
Der Alarmsturm ist ein strukturelles Problem, das Sie strukturell lösen. Ihre Checks haben eine Abhängigkeitsreihenfolge, und die meisten Teams ignorieren diese. Eine Anfrage an Ihre Checkout-Seite hängt davon ab, dass DNS auflöst, dann TCP verbindet, dann der TLS-Handshake abgeschlossen wird, dann HTTP Inhalt zurückgibt und schließlich die Transaktion selbst erfolgreich ist. Wenn etwas weiter unten in diesem Stack fehlschlägt, schlagen alle darüber liegenden Prüfungen ebenfalls fehl.
Ordnen Sie Ihr Monitoring also so an, wie die Anfrage fließt, und lassen Sie die Ursache die Symptome stummschalten. Das multi-protokollbasierte Monitoring von Dotcom-Monitor macht dies praktikabel: Sie überwachen DNS, TCP, TLS, HTTP und die vollständige Transaktion als separate Checks, sodass Sie im Fehlerfall sehen können, welche Ebene ausgefallen ist, und nur auf diese alarmieren, anstatt die gesamte Flut dahinter.
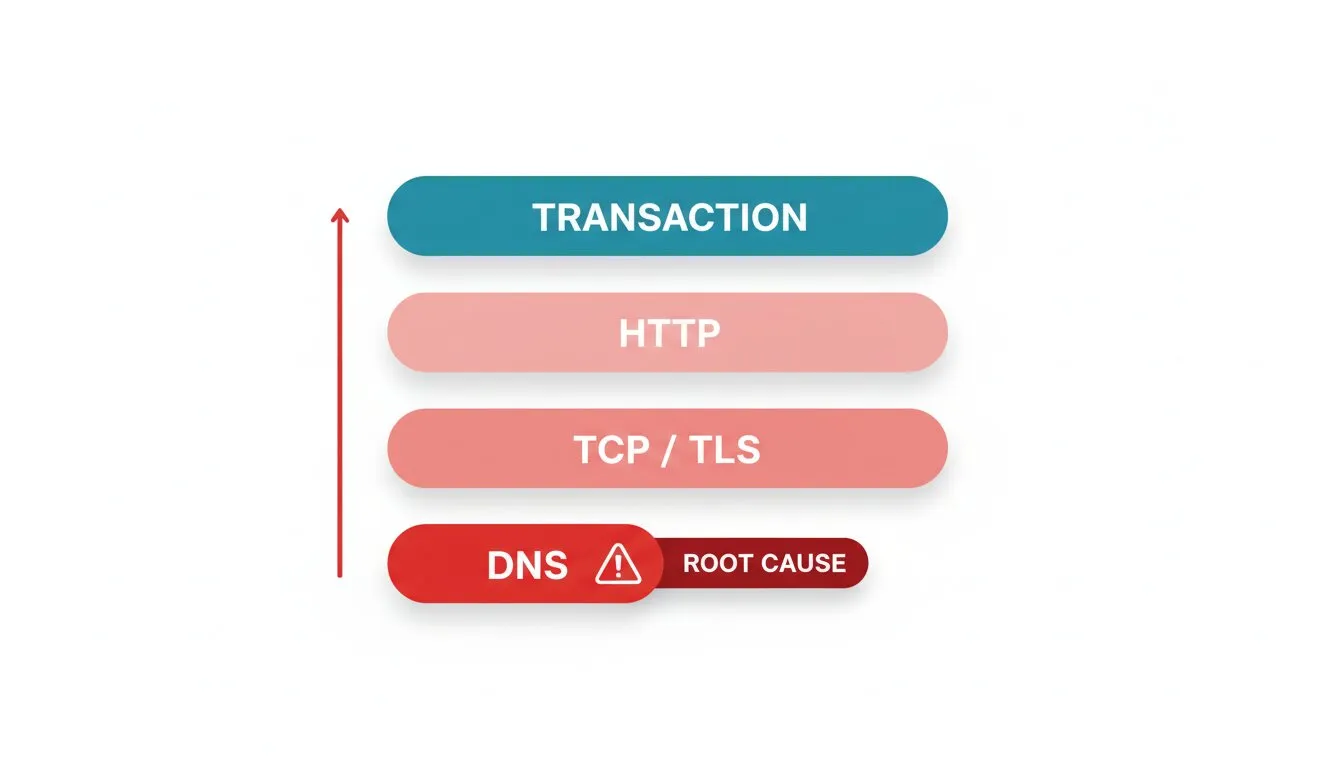
- DNS zuerst. Wenn DNS-Monitoring eine Auflösungsstörung zeigt, wissen Sie bereits, warum alle nachgelagerten Checks rot sind. Alarmieren Sie den DNS-Ausfall und unterdrücken Sie den Rest.
- Dann Verbindung und Zertifikat. Ein fehlgeschlagener TLS-Handshake oder ein abgelaufenes Zertifikat unterbricht alle dahinter liegenden HTTPS-Checks. Fangen Sie es auf der Zertifikatebene mit SSL-Zertifikat-Monitoring ab, und Sie erhalten einen einzigen, klaren Alarm statt einer Flut generischer Seitenfehler.
- Dann die Anwendung. Wenn DNS, TCP und TLS gesund sind, aber die Seiten- oder API-Überprüfung fehlschlägt, liegt nun ein echter Vorfall auf Anwendungsebene vor, der das Pagern wert ist.
Die Transaktionsüberwachung schärft dies weiter. Statt jeden einzelnen Vermögenswert zu alarmieren, skripten Sie den Benutzerfluss, der tatsächlich wichtig ist, und alarmieren den gesamten Ablauf. Das EveryStep-Scripting von Dotcom-Monitor zeichnet einen echten Browserpfad auf, z. B. Suche, Warenkorb hinzufügen und Checkout beginnen, und alarmiert, wenn ein bestimmter Schritt fehlschlägt. Wenn Schritt vier ausfällt, die Startseite aber funktioniert, erhalten Sie einen Alarm, der sagt, dass der Checkout beim Zahlungsschritt ausgefallen ist, und nicht zwanzig Alarme, die verschiedene Assets mit Fehlern melden. Das ist der Unterschied zwischen einem Alarm, der Ihnen sagt, was kaputt ist, und einem Alarm, der Ihnen nur sagt, dass etwas kaputt ist.
Gruppieren Sie Monitore nach Abhängigkeiten, damit ein übergeordneter Ausfall seine untergeordneten stummschaltet. Ein Ursachenalarm schlägt immer vierzig Symptomalarme.
Gestalten Sie Schwellenwerte so, dass Alarme etwas bedeuten
Ein Schwellenwert ist ein Versprechen, dass das Überschreiten dieser Linie bedeutet, dass etwas nicht stimmt. Die meisten Schwellenwerte brechen dieses Versprechen, weil es statische Zahlen sind, die einmal gewählt und nie wieder überprüft werden. Drei Regeln halten sie zuverlässig.
Verwenden Sie Perzentile, keine Durchschnitte
Durchschnittswerte verbergen die langsamen Anfragen, die tatsächlichen Schaden für die Nutzer verursachen. Eine Seite kann im Mittel 900 ms laden, während ihr p95 bei 3 Sekunden liegt, was bedeutet, dass einer von zwanzig Besuchern drei Sekunden wartet. Alarmieren Sie bei p95 oder p99 für Checkout-Flows, weil das die Erfahrung Ihrer langsamsten echten Nutzer widerspiegelt. Die Leistungsberichte von Dotcom-Monitor zeigen die Antwortzeit nach Perzentilen und Standorten auf, sodass Sie einen Schwellenwert gegen die Zahl setzen können, die die echte Erfahrung widerspiegelt, statt eines schmeichelhaften Mittels.
Erfordern Sie einen anhaltenden Verstoß
Eine einzelne langsame Stichprobe ist kein Vorfall. In Dotcom-Monitor wenden Sie denselben Filter für aufeinanderfolgende Fehler auf Leistung an, den Sie für Verfügbarkeit nutzen, sodass ein Antwortzeit-Alarm erst nach mehreren aufeinanderfolgenden langsamen Ergebnissen ausgelöst wird, nicht bei der ersten Überschreitung. Das unterbindet das Nachmittagsflattern, das die Leute dazu bringt, Latenzalarme zu ignorieren.
Alarmieren Sie die Vorlaufzeit für alles, was abläuft
Zertifikate und Domains verschlechtern sich nicht. Sie funktionieren, und dann an einem Tag nicht mehr. Der Schwellenwert ist also keine Leistungszahl, sondern ein Kalender. Geben Sie 30 Tage vor Ablauf und nochmals 7 Tage vorher einen SSL-Alarm aus, und Sie verwandeln einen nächtlichen Ausfall in ein Routine-Ticket. Die richtige Zertifikatserkennung sorgt dafür, dass die Erneuerung während der Geschäftszeiten erfolgt, nicht während eines Vorfalls.
Wenn Sie Leistungsgrenzwerte an eine Geschäftskennzahl koppeln möchten, hilft Ihnen ein Fehlerbudgetrechner, zu ermitteln, wie viel Leistungseinbuße Ihr SLA tatsächlich verkraften kann, bevor sich ein Alarm zum Wecken lohnt.
Ein Ausfall des Checkouts um 2 Uhr morgens, Schritt für Schritt
Setzen Sie die Teile zusammen mit einem realen Muster, das die meisten Ops-Teams erlebt haben. Es ist 2:14 Uhr morgens. Ein Zertifikat für die Zwischen-Domain Ihres Zahlungs-Gateways läuft ab.
Ohne Alarmengineering: Jeder HTTPS-Check hinter diesem Zertifikat schlägt gleichzeitig fehl. Das Handy des Bereitschaftsingenieurs blinkt mit 30 SMS-Nachrichten auf: Homepage down, Checkout down, Account-Seite down, drei API-Endpunkte down, verschiedene Asset-Fehler. Er wacht auf, schaut auf eine Wand identisch aussehender Alarme und verbringt 15 Minuten damit, herauszufinden, dass es keine dreißig getrennten Probleme sind. Die MTTR ist bereits im Keller, bevor jemand an die eigentliche Behebung geht.
Mit Alarmengineering: Der SSL-Zertifikat-Check identifiziert das abgelaufene Zertifikat als Ursache. Die Abhängigkeitsgruppierung unterdrückt die nachgelagerten Seiten- und API-Alarme, da ihr Eltern-Check schon fehlgeschlagen ist. Der Ingenieur erhält eine kritische SMS: Zertifikat auf der Zahlungs-Intermediate ist abgelaufen, von fünf Standorten bestätigt. Er weiß genau, was wo kaputt ist, und erneuert das Zertifikat, während das alte Setup noch Alarme gezählt hätte.
Der Ausfall und die Erkennungsgeschwindigkeit sind in beiden Versionen identisch. Was die Nacht verändert, ist, wie die Alarme gestaltet wurden. Und der Zertifikatsalarm, der 30 Tage früher hätte ausgelöst werden sollen? Das ist die Version, bei der dieser Vorfall überhaupt nie passiert.
Dämpfen Sie den Lärm während Deployments und Wartungen
Selbstverschuldete Alarme machen einen großen Teil des gesamten Alarmvolumens aus, und sie sind am einfachsten zu entfernen. Wenn Sie deployen, eine Migration durchführen oder einen Dienst für planmäßige Wartung herunterfahren, schlagen Ihre Checks fehl. Wenn diese Fehler den Bereitschaftsingenieur alarmieren, trainieren Sie das Team darauf, während genau der Zeitfenster, in denen es aufmerksam sein sollte, Falschalarm zu erwarten.
Legen Sie Wartungsfenster fest, sodass das Monitoring während der geplanten Arbeiten Alarme unterdrückt und danach automatisch fortsetzt. Dotcom-Monitor erlaubt es, diese pro Gerät oder Gerätegruppe zu planen, sodass ein Deployment beim Checkout-Service Checkout-Alarme stummschaltet, ohne den Rest der Seite stillzulegen. Kombinieren Sie das mit Ihrer CI/CD-Pipeline, dann kann das Unterdrückungsfenster sich um das Deployment herum öffnen und schließen.
Das Festlegen des Fensters muss zur Gewohnheit werden, denn ein Wartungsfenster, das jemand vergisst, ist dasselbe wie kein Fenster. Bauen Sie die Unterdrückung in Ihr Deployment-Runbook ein, sodass sie nicht um 23 Uhr an Release-Abenden erinnert werden muss. Wenn Sie häufig deployen, ermöglicht die Integration des Monitorings in die CI/CD-Pipeline, dass die Unterdrückung automatisch als Teil des Releases erfolgt.
Überprüfen Sie Ihre Alarme jeden Monat
Die Alarmkonfiguration ist kein Set-and-Forget. Seiten ändern sich, Verkehrsmuster verschieben sich, und ein Alarm, der vor sechs Monaten Sinn machte, ist heute derjenige, den alle stummschalten. Führen Sie daher eine kurze monatliche Überprüfung mit drei Fragen durch.
Erstens: Welche Alarme wurden ausgelöst, ohne dass jemand reagierte? Listen Sie die Alarme auf, die sich selbst schlossen ohne menschliches Eingreifen. Jede Regel, die mehrmals ohne Aktion ansprang, ist ein Kandidat für die Abschaffung oder Anpassung. Sie erzeugt per Definition Lärm und kein Signal.
Zweitens: Welche Vorfälle hatten keinen Alarm? Die aufschlussreichere Frage. Analysieren Sie jeden Ausfall oder jeden langsamen Zeitraum, den ein Kunde oder ein anderes Team vor Ihrem Monitoring entdeckte, und fügen Sie die Überprüfung hinzu, die diesen hätte erkennen können. Lücken sind gefährlicher als Lärm, weil sie lautlos sind.
Drittens: Stimmen die Schwellenwerte noch mit der Realität überein? Wenn Ihr p95 mit dem Verkehrsanstieg gestiegen ist, ist Ihr alter Schwellenwert jetzt entweder zu streng oder zu lax. Neufestlegen Sie ihn basierend auf den aktuellen Zahlen in Ihren Uptime- und SLA-Berichten statt auf den Zahlen von damals.
Dieser gesamte Ansatz ist Teil einer umfassenderen Sammlung von Best Practices für Website-Monitoring, aber das Alerting ist dort, wo der meiste tägliche Schmerz sitzt. Setzen Sie die Alarme richtig, und der Rest des Stacks wird automatisch ruhiger.
Erstellen Sie Alarme, denen Ihr Team wirklich vertraut
Dotcom-Monitor bestätigt Ausfälle aus einem globalen Netzwerk, bevor es pagert, leitet nach Schwere über Slack, Teams, SMS und PagerDuty weiter und erkennt DNS-, TLS-, API- und Transaktionsausfälle auf der Ebene, die ausgefallen ist. Sehen Sie, wie das Dotcom-Monitor Alarmierungssystem funktioniert, oder starten Sie mit Uptime-Monitoring und passen Sie es nach Bedarf an.
