更新于2026年6月 · 11分钟阅读

问任何一个值班工程师他们的监控情况,他们都会告诉你同样的事情:警报本身不是问题,噪声才是。一个典型的监控栈在每次响应变慢、每个单一地点的波动、以及上游服务故障导致的所有依赖检查异常时都会触发警报。经过几周如此,大家就不再阅读警报了。而真正的故障发生的那个夜晚,它落在了和200个误报相同的静音频道里。
这就是警报疲劳如何推高平均解决时间的原因。检测从来不是瓶颈,信号被埋没了。本指南将介绍如何构建只在用户体验真正受损时才触发的站点监控警报,让你的团队足够信任它们,从而及时响应。内容涵盖确认逻辑、升级层级、依赖感知抑制以及阈值计算,带来区分平稳值班与无人响应呼叫器的准确设置。
为什么大多数警报是噪声而非有效信号
监控警报的唯一任务是告诉人工哪里出现问题需要修复。大多数警报因三种常见模式未能完成这项工作,每种模式都有简洁的解决方案。
单点误报最为常见。法兰克福的一个监控代理遇到瞬时网络故障,检测失败,警报触发,而实际上并没有真实用户遭遇网站故障。从单点位置运行的正常运行时间监控会导致监控与源服务器之间的丢包被误判为停机。
接着是抖动阈值。你把响应时间警报设置为2000毫秒,因为感觉那速度慢。但你的第95百分位响应时间(最慢5%的请求实际响应时间)在峰值流量时就已经在1800毫秒左右,因此警报每天都会在下午触发,自动清除,然后再次触发。没人会采取行动,因为根本无事可做。数值错误,而非站点有故障。
之后是警报风暴。你的域名的DNS解析失败。于是首页检测失败、登录检测失败、结账检测失败、API检测失败,SSL检测失败,因为监控根本无法访问主机。一个根本原因,四十个警报,在一分钟内同时触发。值班工程师必须查看所有四十条才能找到关键警报。
修复这三种模式即可消除大部分噪声。剩下的内容将阐述如何做到。
确认故障后再通知任何人
你能做出的最大影响改动是要求警报触发前先确认,Dotcom-Monitor正是为此而设计。你不是在第一次检测失败时就通知,而是设置失败需满足的清除条件方才通知:多个地点达成一致,且连续多次检测失败。两者均针对每个监控配置,你可决定每个检测需要多少证据再触发通知。
多地点确认从源头消除误报。如果法兰克福检测失败,但达拉斯、伦敦、新加坡同时通过,则问题在于通往法兰克福的路径,而非你的网站。真正的故障则会在所有地点失败。这是Dotcom-Monitor全球监控网络的职责:当检测失败时,Dotcom-Monitor会自动从多个地点重新检测,再决定是否发送警报,因此一次地区性的瞬时故障不会影响你的值班安排。你只会收到多个视角都确认的失败通知。
连续失败逻辑处理瞬时故障。在Dotcom-Monitor警报系统中,你可以设置警报仅在连续两次或三次检测失败后触发,而不是第一次失败立即触发。在一分钟的检测间隔下,这相当于增加一至两分钟的检测延迟,以换取近乎零的瞬时噪声。对于大多数站点,这种权衡显然值得。因为过滤是按监控设置的,营销页面可以容忍较慢的确认而支付端点则需快速响应。
确认确实引入了小延迟。如果你的系统对一秒宕机非常敏感,你可能接受更多误报以获得更快检测速度。大多数团队并不处于这种情况,而确认策略带来的是安静的呼叫器。
构建匹配严重性的升级层级
警报和升级不是一回事。警报是检测失败的事实,升级是决定谁通过哪个频道接收通知以及无人响应时如何处理的规则。每次失败均等通知所有人的扁平警报,最容易让团队忽视呼叫器。
先把故障按严重性层级分类,并匹配对应渠道。原则很简单:频道越吵闹,使用门槛越高。
| 严重性 | 示例 | 频道 | 响应人员 |
|---|---|---|---|
| 关键 | 多地点确认的结账或登录故障 | 短信、电话、PagerDuty | 值班工程师,立即响应 |
| 高 | 主要页面响应超过p95阈值持续10分钟 | Slack或Teams,@on-call | 值班工程师,一小时内响应 |
| 低 | 营销页面响应变慢,单个资源404 | 邮件摘要,仪表盘 | 下一个工作日审核 |
接着在严重性基础上叠加基于时间的升级。关键警报同时通知Slack和值班工程师,若10分钟后仍未处理,则通过短信再次通知。20分钟后通知次级值班或团队负责人。无需凌晨三点手动升级,漏接页面不会变成漏接故障。
Dotcom-Monitor通过通知组和升级计划实现此功能。你定义谁值班,每层使用哪些渠道,警报等待多久才升级给下一个人。它集成团队常用渠道,Slack或Microsoft Teams通知送达工作时间人员,PagerDuty升级处理非工作时间路径。核心是按严重性路由,而非广播所有通知期待有人注意。
让依赖检查抑制症状警报
警报风暴是结构性问题,必须用结构性方法解决。你的监控检查有依赖顺序,大多数团队忽视这一点。访问结账页依赖DNS解析、TCP连接、TLS握手完成、HTTP返回内容,最后事务成功。当底层环节出错,上层环节全都失败。
因此,监控顺序应与请求流程一致,让根本原因屏蔽下游症状。Dotcom-Monitor的多协议监控让这变得可行:你分别监控DNS、TCP、TLS、HTTP及全事务,当出现失败时可查看是哪一层出错,针对该层报警,而非累积爆发的警报。
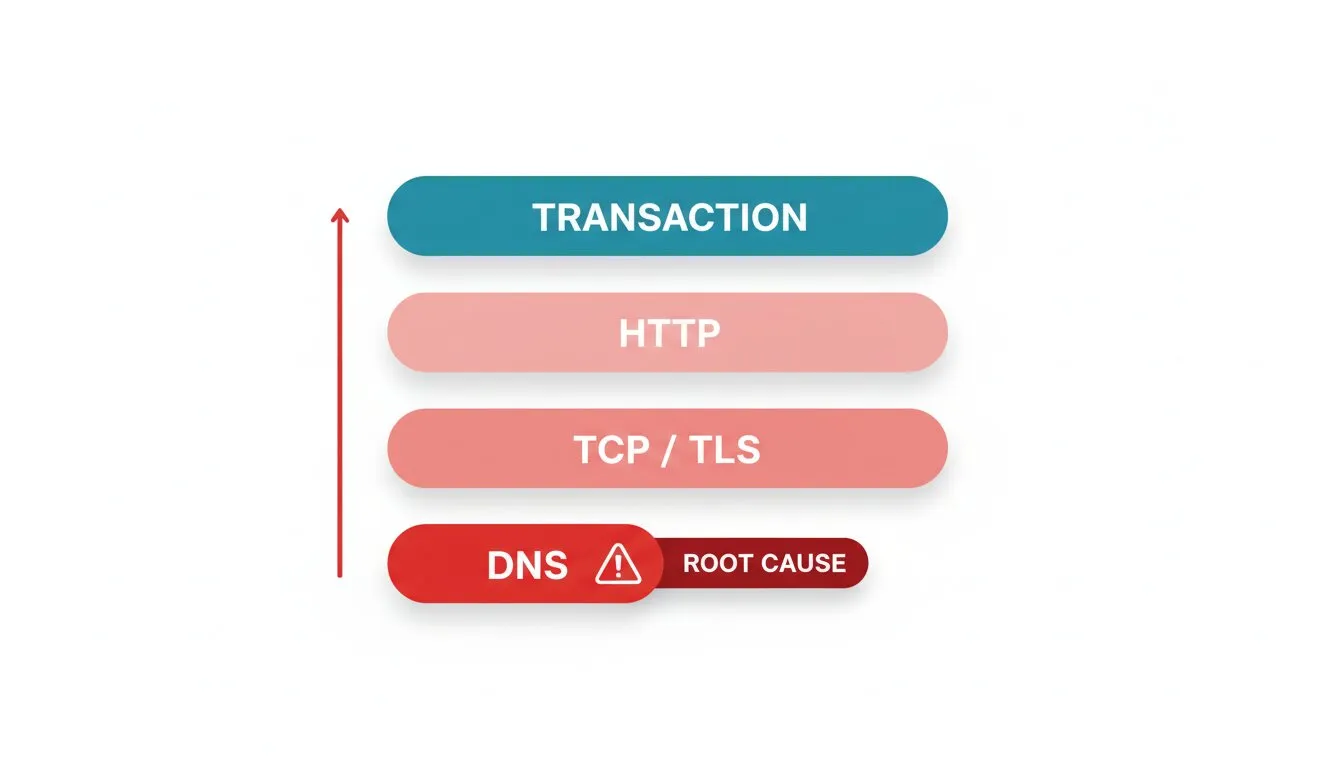
- 优先DNS。如果DNS监控显示解析失败,已知所有下游检测为红灯。针对DNS故障报警并屏蔽其余。
- 其次连接和证书。TLS握手失败或证书过期,会导致所有HTTPS检查失败。借助SSL证书监控在证书层捕获故障,获得单一明晰警报,避免泛泛的页面失败洪流。
- 最后应用层。如果DNS、TCP、TLS均健康,但页面或API监控失败,则触发真正的应用层事件,值得通知。
事务监控对此进一步细化。不要对每个单独资源报警,脚本化关键用户流程并针对流程报警。Dotcom-Monitor的EveryStep脚本记录真实浏览器路径,如搜索、添加购物车、开始结账,且当某步骤失败触发警报。如果第四步失败但首页正常,你只获得结账支付环节故障的一个警报,而非二十个资源错误。这是准确指出故障而非泛泛通知的关键。
按依赖关系分组监控,使父级故障静音子级。单一根因警报胜过四十个症状警报。
设定阈值让警报有意义
阈值承诺超过此线表明有问题。大多数阈值因静态设定一劳永逸,破坏了承诺。三个原则保持阈值有效。
使用百分位而非平均数
平均隐藏了真正影响用户的慢请求。页面可能平均900毫秒响应,但第95百分位可能达3秒,意味着20个访客中有1个等待3秒。针对p95报警,结账流程使用p99,因为那是最慢真实用户体验。Dotcom-Monitor的性能报告按百分位和地点划分响应时间,便于基于真实体验而非平均数字设定阈值。
要求持续违背
单一慢响应不是事件。Dotcom-Monitor同样给性能应用连续失败过滤器,响应时间警报只有连续多次检测迟缓才触发,不因首次样本迟缓报警。它减少了下午拥堵造成的抖动,避免用户忽视延迟警报。
针对任何过期项报警预警期
证书和域名不会渐变损坏,只有正常与失效。阈值不是表现数值,而是时钟。提前30天触发SSL过期警报,7天再次提醒,能将午夜故障转为例行工单。正确的证书报警意味着续约在工作时间完成,而非故障时紧急处理。
若需将性能阈值关联业务指标,错误预算计算器帮助估算SLA可接受的性能下降幅度,从而判断何时触发唤醒警报。
凌晨2点结账故障,步骤详解
结合大多数运维团队经历过的实际模式。时间是凌晨2:14,你支付网关中间域名的一个证书过期了。
无警报工程:所有HTTPS检测同时失败。值班工程师手机30条短信爆炸:首页、结账、账号页面、三个API接口以及多个资源出错。工程师醒来,面对一堆相似警报,花15分钟才弄清这不是30个问题。MTTR已经被拖长,在动手修复前已大打折扣。
有警报工程:SSL证书监控检测到过期证书为根因。依赖分组抑制下游页面和API警报,因其父级已失败。工程师接到一条关键短信:支付中间证书过期,多地点确认。他们准确知道故障及位置,正更新证书时老设置尚在继续计数警报。
故障与检测速度两个版本相同。不同的是警报构建方式。而应该在30天前触发的证书警报,则是防止此事件发生的关键版本。
部署和维护期间静音噪声
自导警报占总警报量很大且易移除。你部署、迁移或计划停机维护时检测会失败,若这些失败都呼叫值班工程师,就是训导团队期望在应高度关注时段接受误报。
设置维护窗口,监控在计划工作期间抑制警报,然后自动恢复。Dotcom-Monitor允许针对设备或设备组安排,部署结账服务时可静音结账相关警报,不影响其他站点。结合CI/CD流水线,可使抑制窗口围绕部署自动开启与关闭。
设置维护窗口必须成习惯,忘记设置等同于无窗口。将抑制写入部署流程,避免发布夜11点匆忙时忘记。如果频繁部署,将监控集成入CI/CD流水线,使抑制自动发生,成为发布环节自然一部分。
每月审查警报配置
警报配置非一劳永逸。站点变化、流量模式波动,半年以前合理的警报可能变成人人静音的噪声。开展简短月度审查,问三个问题。
首先,哪些警报触发但无人响应?拉取无人工干预自动解决的警报清单。任何多次触发未被处理的规则,都可考虑淘汰或调优,其本质是噪声。
其次,哪些事件却无警报?更具启发性。回溯客户或团队先于监控发现的故障或性能下降,添加可捕获这些异常的检查。漏警比误警风险更大,因其保持沉默。
第三,阈值仍匹配现实吗?流量增长导致p95上升,旧阈值可能太严或太松。基于当前运行时间和SLA报告中的数字重新基准,而非设置初期数据。
这种方法是更广泛网站监控最佳实践的一部分,但警报环节是日常痛点重灾区。警报配置得当,整个监控栈会自然趋于安静。
构建团队真正信任的警报
Dotcom-Monitor在全球多地点确认失败后通知,按严重性通过Slack、Teams、短信和PagerDuty路由,定位DNS、TLS、API及事务失败的具体层。了解Dotcom-Monitor警报系统工作原理,或从运行时间监控开始并逐步优化。
