La surveillance des API est la pratique continue et automatisée de validation des points de terminaison API pour la disponibilité, le temps de réponse et la précision des données — confirmant non seulement qu’un point de terminaison répond, mais qu’il renvoie les bonnes données, dans le bon format, dans une latence acceptable, du point de vue des utilisateurs et des systèmes dépendants.

Les API sont le tissu conjonctif des logiciels modernes. Chaque fois qu’un utilisateur se connecte, effectue un paiement ou reçoit une notification en temps réel, plusieurs appels d’API s’exécutent en coulisses — souvent à travers des microservices, des fournisseurs cloud et des vendeurs tiers. Quand ces appels échouent ou ralentissent, l’impact est immédiat : processus de paiement interrompus, utilisateurs bloqués, revenus perdus.
Pourtant, la plupart des équipes découvrent les défaillances des API uniquement lorsque les clients les signalent. Sans surveillance proactive, le délai entre l’échec et l’investigation est généralement de plusieurs dizaines de minutes — assez longtemps pour exposer des risques réels de revenus et de SLA avant qu’une alerte ne soit déclenchée.
Ce guide explique ce qu’est la surveillance des API, son fonctionnement, les métriques à suivre, ses différences avec les tests d’API et l’APM, et comment la mettre en œuvre — avec la précision nécessaire aux ingénieurs DevOps, SRE et équipes QA pour prendre des décisions éclairées en production.
Qu’est-ce que la surveillance des API ?
La surveillance des API couvre trois couches distinctes de validation, par ordre de spécificité croissante :
- Surveillance de la disponibilité — Le point de terminaison est-il accessible ? Renvoie-t-il une réponse HTTP sans délai d’attente ?
- Surveillance des performances — Combien de temps prend la réponse ? Le TTFB, la résolution DNS ou la négociation TLS introduisent-ils de la latence ?
- Validation des charges utiles — Le corps de réponse contient-il la structure de données attendue ? Les assertions JSONPath ou XPath sont-elles validées ?
Qu’est-ce qu’un point de terminaison API ?
Une interface de programmation d’applications (API) est un ensemble de protocoles et de définitions permettant aux systèmes logiciels de communiquer. Un point de terminaison API est l’URL spécifique où une API reçoit les requêtes et renvoie des réponses — l’unité d’observation pour la surveillance des API. Par exemple :
POST /v2/auth/token— point de délivrance de jetonsGET /v2/orders/{id}— point de récupération de commandePOST /v2/payments/charge— point de traitement des paiements
Les applications modernes dépendent simultanément de dizaines, voire de centaines, de tels points de terminaison — microservices internes, passerelles de paiement tiers, fournisseurs d’identité, API de livraison, et systèmes CRM. La surveillance des API maintient la visibilité sur tous ces points.
Types de surveillance des API
Toutes les surveillances d’API ne se valent pas. Comprendre les catégories aide les équipes à construire une couverture adaptée à leur architecture et à leurs besoins métier. Les cinq types principaux s’appliquent à presque toutes les équipes ; les types spécialisés importent lorsque leurs conditions spécifiques s’appliquent.
Types principaux
| Type | Ce qu’il valide | Idéal pour |
|---|---|---|
| Surveillance d’uptime | Accessibilité du point de terminaison ; codes de réponse HTTP ; réponse dans le délai imparti | SLA de disponibilité basique ; détection immédiate des pannes |
| Surveillance des performances | Temps de réponse, TTFB, résolution DNS, poignée de main TCP, temps TLS, débit | SLA de latence, cibles P95 / P99, planification de capacité |
| Surveillance de la charge utile / validation | Corps de réponse via assertions JSONPath / XPath ; exactitude du schéma ; valeurs des champs | Détection des échecs silencieux quand HTTP 200 ≠ données correctes |
| Surveillance synthétique | Appels API simulés depuis des emplacements globaux à intervalles programmés, indépendants du trafic réel | Détection proactive ; couverture géographique ; périodes sans trafic |
| Surveillance de transactions multi-étapes | Séquences chaînées d’appels API (ex. : authentification → requête → soumission → confirmation) ; passage de données entre étapes | Flux e-commerce, parcours de connexion, workflows de commande |
Types spécialisés
| Type | Ce qu’il valide | Idéal pour |
|---|---|---|
| Surveillance de sécurité | Échecs d’authentification, schémas de requêtes anormales, expiration de certificats, abus de limites de taux, rejouage de jetons | FinTech, santé ; API manipulant des PII/PHI |
| Vérifications de conformité | Validation de version/cipher TLS, expiration de certificats, présence d’en-têtes de sécurité, tests d’application d’authentification | Santé, services financiers, industries réglementées |
| Surveillance des utilisateurs réels (RUM) | Interactions API réelles des utilisateurs ; visibilité des sessions complètes ; variances géographiques et d’appareils réelles | Compréhension de l’impact utilisateur réel ; validation des résultats synthétiques |
| Surveillance des versions et dépréciations | Taux d’adoption des versions API ; pics d’erreur après changement de version ; compatibilité rétroactive | Équipes gérant plusieurs versions API simultanément |
| Surveillance de tierces parties / intégrations | Dépendances API externes (Stripe, Okta, Salesforce, Twilio) ; isolement des échecs externes vs internes | Toute application dépendant d’API tierces pour des workflows critiques |
Une note sur les vérifications de conformité : elles fournissent des preuves à l’appui de contrôles techniques spécifiques. La conformité aux cadres (HIPAA, PCI DSS, SOC 2) requiert une gouvernance organisationnelle plus large que ce que la seule surveillance peut offrir.
Surveillance synthétique vs Surveillances des utilisateurs réels (RUM)
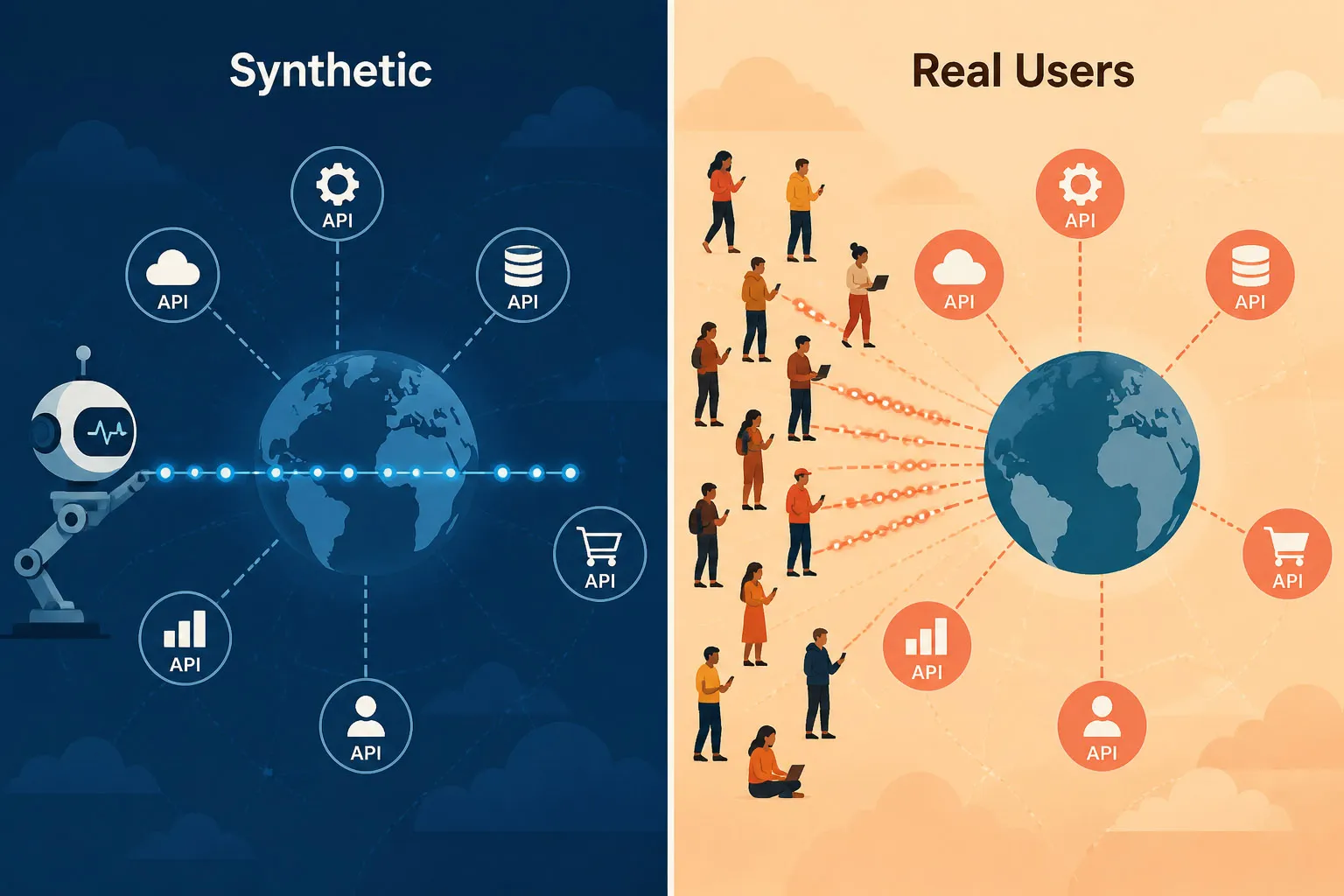
Les deux approches fournissent des données de performance API, mais selon des perspectives fondamentalement différentes :
| Surveillance synthétique | Surveillance des utilisateurs réels (RUM) | |
|---|---|---|
| Déclencheur | Contrôles scriptés sur un calendrier (ex. toutes les 1 minute) | Requêtes utilisateur réelles en production |
| Couverture | Fonctionne 24h/24 même en absence d’utilisateurs réels | Génère des données uniquement quand les utilisateurs effectuent des requêtes |
| Détection | Proactive — détecte les échecs avant impact utilisateur | Réactive — révèle les problèmes une fois les utilisateurs affectés |
| Portée | API publiques et privées/internes (via Agent Privé) | API atteintes par de vrais utilisateurs/clients — surtout publiques, mais RUM entreprise peut aussi capturer des appels API internes issues d’applications instrumentées |
| Cas d’usage | Validation continue de la disponibilité et performance | Compréhension du rayon d’impact réel et expérience utilisateur |
Principales métriques de surveillance API
Suivre les bonnes métriques fait la différence entre une réponse aux incidents informée et la fatigue des alertes. Voici les métriques les plus importantes, avec les benchmarks précis et ce que chacune indique.
| Métrique | Objectif / Benchmark | Ce qu’elle détecte |
|---|---|---|
| Disponibilité (taux d’uptime %) | ≥ 99,9 % (trois neuf) ; 99,99 % pour les APIs critiques en termes de revenus | Panne totale, panne partielle, délai d’attente |
| Temps de réponse total | < 200 ms pour points simples ; < 1 s pour opérations complexes | Lenteurs serveur, surcharge, régressions de déploiement |
| Temps jusqu’au premier octet (TTFB) | < 100 ms idéal ; < 300 ms acceptable | Retard de traitement serveur avant début de réponse |
| Temps de réponse P95 / P99 | Alerte à 2× votre P95 de référence par point ; ajuster selon comportement | Latence extrême affectant les 1-5 % les plus lents des requêtes |
| Taux d’erreur (4xx / 5xx) | < 0,1 % pour APIs en production | Échecs d’authentification, mauvaise gestion des entrées, erreurs serveur |
| Temps de résolution DNS | < 50 ms pour recherches en cache dans la même région ; plus de 100 ms possibles inter-régions | Problèmes de propagation DNS, échecs de résolveur |
| Temps de poignée de main TLS | < 100 ms | Mauvaise configuration certifiée, problèmes de négociation TLS |
| Taux de réussite des assertions de charge utile | 100 % (alerte dès la moindre défaillance) | Échecs silencieux : réponses HTTP 200 avec données erronées ou manquantes |
| Débit (req/sec) | Comparer à la base historique | Baisse inattendue ou pics anormaux de trafic |
| Expiration des certificats (jours restants) | Alerte à 30 jours ; critique à 7 jours | Expiration imminente des certificats TLS |
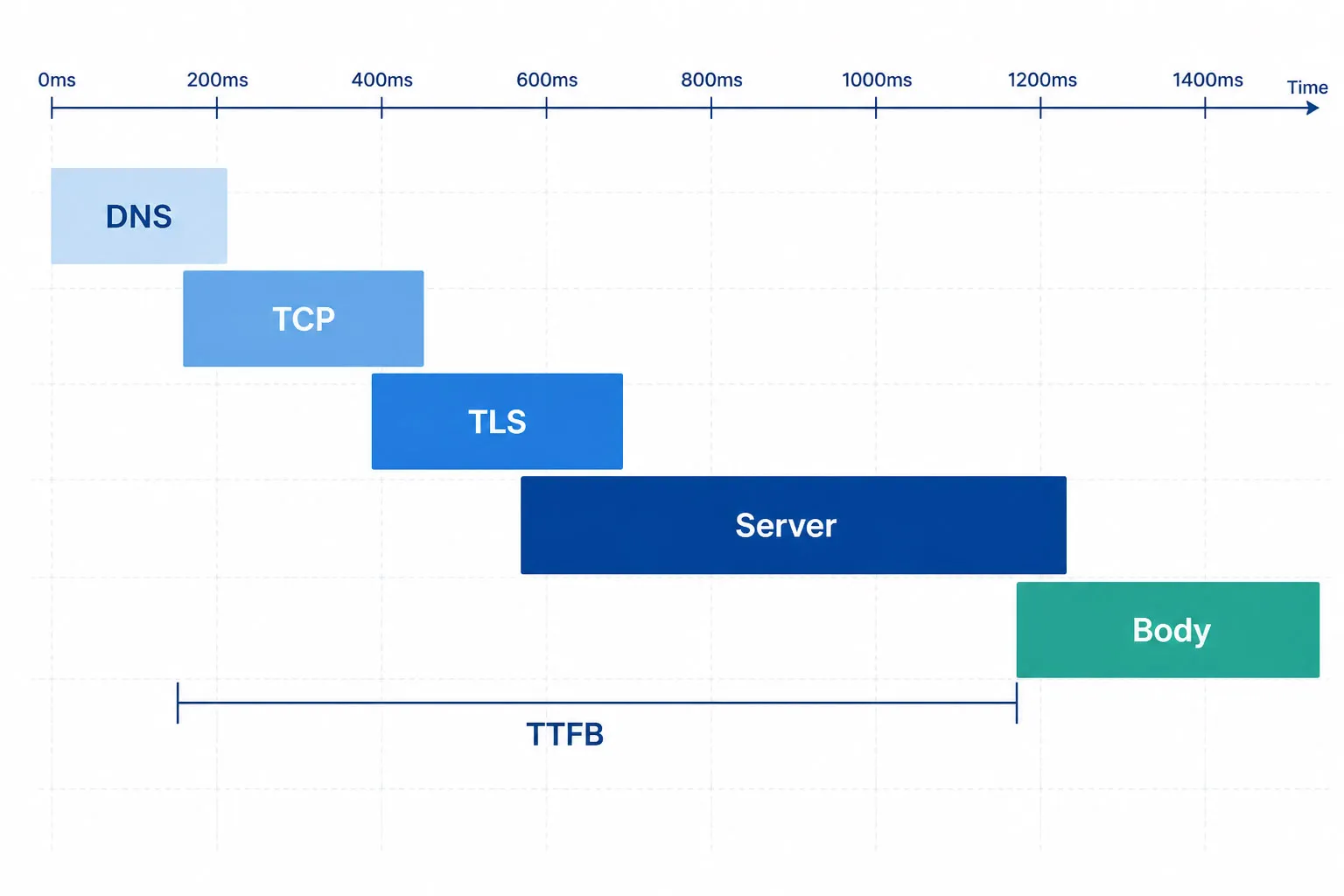
Référentiels de temps de réponse
Comment fonctionne la surveillance des API ?
Comprendre les mécanismes techniques aide les équipes à configurer correctement la surveillance et interpréter précisément les résultats.
La boucle de surveillance centrale
- Planification. Un contrôle synthétique s’exécute à un intervalle configuré (ex. : toutes les 1 minute) depuis un emplacement de surveillance global sélectionné.
- Envoi de requête. L’agent de surveillance envoie une requête HTTP au point de terminaison cible — incluant la méthode HTTP (GET, POST, PUT, PATCH, DELETE), les en-têtes, les identifiants d’authentification et le corps de la requête.
- Mesure des temps. L’agent enregistre le temps de résolution DNS, le temps de connexion TCP, le temps de poignée de main TLS, le temps jusqu’au premier octet (TTFB), et le temps de réponse total comme composants distincts.
- Assertion. La réponse est évaluée selon les assertions configurées — code HTTP, seuils de temps de réponse, en-têtes et contenu de charge utile via JSONPath (REST) ou XPath (SOAP).
- Alerte ou réussite. En cas d’échec d’une assertion ou de délai d’attente dépassé, un incident est créé et les alertes sont envoyées selon les règles de notification configurées.
- Enregistrement. Tous les résultats — succès et échecs — sont stockés avec horodatages, données de réponse et résultats d’assertion pour analyse historique et rapports SLA.
Surveillance de transactions API multi-étapes

La surveillance d’un point de terminaison unique confirme que les points d’API répondent individuellement. Mais les parcours utilisateur réels sont des séquences chaînées où chaque étape dépend de la sortie de la précédente.
Considérons un flux de paiement e-commerce :
- Étape 1 —
POST /auth/token: authentification de l’utilisateur ; extraction deaccess_tokendu corps de réponse - Étape 2 —
GET /products/{id}: récupération des détails produit ; injection du jeton dans l’en-têteAuthorization - Étape 3 —
POST /cart/add: ajout d’article ; extraction decart_idde la réponse - Étape 4 —
POST /checkout/initiate: lancement du paiement aveccart_id; extraction decheckout_session_id - Étape 5 —
POST /payments/charge: traitement du paiement ; assertion que le champorder_statusvaut'confirmed'
Avec une surveillance point par point, les cinq étapes peuvent réussir individuellement alors que la transaction complète échoue — parce que les données de session ne sont pas correctement transférées, un jeton expire en cours de route ou l’API paiement renvoie un HTTP 200 avec une erreur dans la charge utile. La surveillance multi-étapes exécute la chaîne entière comme un seul moniteur, valide chaque étape indépendamment, et transmet automatiquement les valeurs dynamiques entre étapes.
Dotcom-Monitor permet la surveillance des transactions multi-étapes en chaînant des appels API séquentiels dans une seule tâche de surveillance. L’extraction et l’injection des variables sont automatiques. Chaque étape est validée indépendamment, ce qui permet de localiser précisément l’étape qui provoque l’échec.
Validation de charge utile : assertions JSONPath et XPath
La validation de charge utile distingue la surveillance d’un simple ping de disponibilité. La manière d’exprimer les assertions dépend de l’outil, mais la logique est constante :
- Accès aux champs JSONPath (REST) : accéder à
$.data.status— puis vérifier que la valeur retourne'active' - Vérification des tableaux JSONPath : accéder à
$.items— vérifier que la longueur du tableau est supérieure à 0 - Assertion XPath (SOAP) :
//order/status/text()— vérifier que la valeur du nœud est'confirmed' - Assertion sur les en-têtes : vérifier que la valeur de l’en-tête
Content-Typeest'application/json' - Assertion de temps de réponse : vérifier que le temps total de réponse est inférieur à 500 ms
Surveillance d’authentification
Les APIs en production requièrent une authentification. Un outil de surveillance doit gérer les mêmes méthodes d’authentification que vos clients API réels. Les schémas qu’une plateforme de surveillance prête pour la production doit supporter :
| Méthode d’authentification | Description | Notes |
|---|---|---|
| OAuth 2.0 — Client Credentials | Machine-à-machine ; échange direct d’identifiants contre un jeton | Le plus courant pour la surveillance API serveur-à-serveur |
| OAuth 2.0 — Code d’autorisation | Autorisation déléguée par l’utilisateur ; utilisé avec PKCE pour SPA/apps mobiles | Demande une gestion automatique du rafraîchissement des jetons |
| OAuth 2.0 — Mot de passe propriétaire de ressource (ROPC) | Échange direct utilisateur/mot de passe — flux legacy | À utiliser seulement si le Code d’autorisation n’est pas possible |
| Jeton Bearer (JWT) | Jeton statique ou rafraîchi dynamiquement dans l’en-tête Authorization |
JWT à durée de vie courte nécessitent un rafraîchissement automatique |
| Clé API | Clé statique en en-tête, paramètre de requête ou cookie | La plus simple à surveiller ; surveiller les événements de rotation |
| Authentification basique | username:password codé en base64 dans l’en-tête Authorization |
Legacy — encore commune en entreprise et API internes |
| Signature AWS v4 | Requête signée HMAC avec identifiants AWS | Requise pour les points API Gateway AWS |
| mTLS / certificat client | Mutual TLS — les deux parties présentent des certificats | Environnements zero trust ; surveillance critique de l’expiration des certificats |
| NTLM / Kerberos | Authentification intégrée Windows/Active Directory | API internes d’entreprise ; moins courant dans les stacks cloud natives |
| En-têtes personnalisés | Schémas d’authentification propriétaires via en-têtes de requête personnalisés | Catch-all pour implémentations d’authentification non standard |
L’expiration des jetons est une cause principale de faux positifs en surveillance. La durée de vie des jetons OAuth 2.0 varie largement selon l’implémentation et le type de grant. Les jetons délégués par les utilisateurs (flux Code d’autorisation) durent typiquement de 15 minutes à 1 heure. Les jetons machine-à-machine (flux Client Credentials) sont souvent configurés sur des fenêtres plus longues — de 1 à 24 heures — pour réduire la charge de rafraîchissement. Les environnements hautement sécurisés peuvent imposer des durées aussi courtes que 5 minutes. Quel que soit le délai, un outil de surveillance ne gérant pas le rafraîchissement automatique des jetons génèrera des faux positifs ou exigera une rotation manuelle des identifiants, créant à la fois une surcharge opérationnelle et un risque de panne.
Note sur le grant implicite OAuth 2.0 : il est déprécié dans les meilleures pratiques de sécurité actuelles OAuth 2.0 (RFC 9700) et ne doit pas être utilisé dans les nouveaux systèmes. Si vos APIs existantes utilisent ce flux, la migration vers Code d’autorisation + PKCE est fortement recommandée.
Pourquoi la surveillance des API est importante : impact métier
Les APIs ne sont pas de simples abstractions d’infrastructure — elles sont des chemins de revenus. Lorsqu’elles échouent, les conséquences sont financières, opérationnelles et contractuelles.
Coût des défaillances d’API non détectées
Sans surveillance proactive, les équipes dépendent des rapports clients pour détecter les échecs. Les enquêtes industrielles placent constamment le MTTD (temps moyen jusqu’à détection) rapporté par les clients bien au-delà de 30 minutes — au moment où une plainte est déposée, investiguée, triée et escaladée, le temps est déjà écoulé. La surveillance synthétique continue à intervalles d’une minute réduit la détection à moins de 60 secondes, permettant d’isoler la cause racine avant que le problème ne s’aggrave.
La formule des revenus est simple : commandes/min × valeur moyenne de commande × durée de panne en minutes. Une plateforme traitant 100 commandes/min à 50 $ de valeur moyenne perd 25 000 $ de revenus potentiels lors d’une panne API paiement de 5 minutes. Calculez votre exposition avec vos propres taux et valeurs.
Scénarios spécifiques par secteur
- E-commerce. Une défaillance de l’API de paiement en pointe bloque toutes les conversions. Une API d’autorisation de paiement renvoyant HTTP 200 avec un statut refusé — mais sans alerte — bloque silencieusement les transactions pendant des minutes avant qu’on ne s’en rende compte.
- FinTech. Les API de traitement des transactions doivent respecter des latences sous la seconde. Une dégradation persistante au-delà des seuils SLA peut déclencher des pénalités contractuelles et des audits sous PCI DSS.
- Santé. Les API d’intégration EHR et les endpoints télémédecine doivent maintenir un échange de données conforme HIPAA. Une API renvoyant HTTP 200 avec des données patient incomplètes est un cas de non-conformité — pas seulement une question de performance.
- SaaS / API en tant que produit. Quand votre API est un produit facturable, l’indisponibilité entraîne des pénalités SLA contractuelles et la perte de clients. La surveillance fournit les preuves documentées nécessaires.
- IT d’entreprise. Intégrations CRM, ERP, RH inter-départements. Une dégradation de l’API Salesforce peut casser silencieusement les workflows commerciaux à l’échelle de l’entreprise sans générer aucune erreur 500 dans vos logs.
Risques liés aux API tierces
Les applications modernes dépendent d’API externes hors de leur contrôle : passerelles de paiement (Stripe, PayPal, Braintree), fournisseurs d’identité (Okta, Auth0, AWS Cognito), APIs d’expédition, et systèmes CRM. Lorsqu’elles se dégradent, votre application semble cassée pour les utilisateurs malgré une infrastructure saine.
La surveillance des points de terminaison tiers permet aux équipes d’isoler immédiatement si un échec est interne ou externe — distinction nécessitant souvent des investigations longues sans données préalables. Elle fournit également les preuves documentées pour tenir les fournisseurs responsables de leurs SLA publiés.
Cessez d’apprendre les échecs d’API par vos clients.
La surveillance synthétique API de Dotcom-Monitor détecte les pannes en moins de 60 secondes et dirige les alertes vers PagerDuty, Slack ou Microsoft Teams. Surveillez passerelles de paiement, fournisseurs d’identité et APIs internes depuis une seule plateforme.
Essayez gratuitement pendant 30 jours → Sans carte de crédit
Surveillance des API vs Tests d’API
Les deux pratiques valident le comportement des API, mais servent des objectifs distincts dans le cycle de vie logiciel. Les confondre crée des lacunes.
| Dimension | Test d’API | Surveillance d’API |
|---|---|---|
| Quand | Avant déploiement — développement, QA, pipeline CI/CD | Après déploiement — en continu en production |
| Environnement | Développement, staging, environnement de test contrôlé | Production live, infrastructure réelle, trafic réel |
| Déclencheur | Commit, build, exécution manuelle, gate PR | Programmée (ex. toutes les 1 minute), continue 24/7 |
| Objectif | Prévenir l’arrivée de bugs en production | Détecter échecs et dégradations en production |
| Couverture | Tous comportements, cas limites, chemins d’erreur | Chemins critiques, endpoints SLA, chaînes de parcours utilisateur |
| Perspective | De l’intérieur vers l’extérieur : teste le code | De l’extérieur vers l’intérieur : valide du point de vue utilisateur |
| Résultat | Rapport succès/échec ; bloque le déploiement si échec | Alertes en temps réel, historiques d’incidents, suivis SLA |
La relation pratique : le test d’API est une activité de développement. La surveillance d’API est une activité opérationnelle. Le test détecte les bugs avant le déploiement ; la surveillance détecte les échecs, régressions, dégradations et problèmes de dépendances après déploiement — sous des conditions d’infrastructure réelles différentes des environnements contrôlés.
Une équipe mature utilise les deux — et exploite l’import Postman Collection pour faire le pont, convertissant les tests en environnements de développement en moniteurs de production sans dupliquer les définitions de requêtes.
Surveillance d’API vs APM
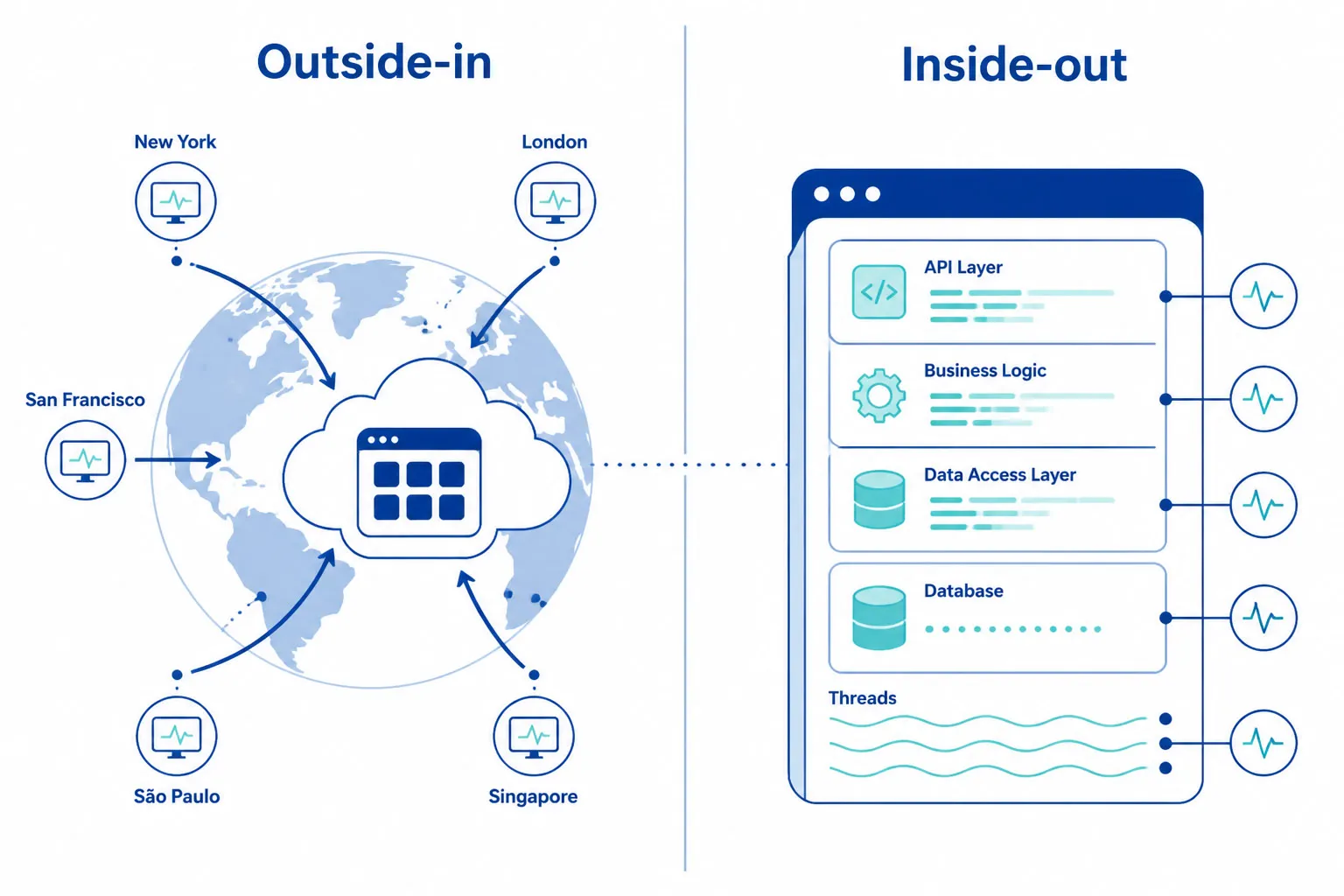
Ces deux catégories sont souvent confondues. Elles sont complémentaires, pas interchangeables.
| Surveillance API synthétique | APM (Application Performance Monitoring) | |
|---|---|---|
| Perspective | De l’extérieur vers l’intérieur — valide au même point de vue que utilisateurs et partenaires | De l’intérieur vers l’extérieur — observe le comportement interne |
| Ce qu’elle voit | Échecs DNS, problèmes de routage réseau, erreurs TLS, mauvaises routes CDN, lacunes géographiques | Requêtes BDD lentes, fuites mémoire, exceptions, appels de fonctions lents |
| Quand elle tourne | 24/7 — même en périodes sans trafic | Uniquement lors des requêtes réelles traitées |
| Question à laquelle elle répond | “Nos clients peuvent-ils appeler cette API maintenant ?” | “Que se passe-t-il dans l’application lors de la requête ?” |
Les équipes avec le MTTR le plus bas utilisent les deux : APM pour l’analyse racine interne, surveillance synthétique pour validation externe. Logs/traces répondent au “Quel est le bug dans notre code ?” La surveillance répond au “Nos clients peuvent-ils utiliser cette API maintenant ?”
Protocoles API : REST, SOAP, GraphQL, gRPC et WebSocket
Chaque protocole API demande des exigences de surveillance et modes d’échec spécifiques. Un outil traitant toutes les APIs comme de simples requêtes HTTP GET manquera des problèmes spécifiques.
Surveillance API REST
REST est le protocole dominant. La surveillance valide méthodes HTTP (GET, POST, PUT, PATCH, DELETE), codes d’état, en-têtes réponse, corps JSON via assertions JSONPath. Exigences clés : assertion sur les valeurs des champs de charge utile — pas seulement codes d’état ; surveiller toutes les méthodes HTTP, pas seulement GET (POST, PUT, DELETE déclenchant des logiques serveurs différentes) ; suivre le temps de réponse par point spécifique, pas en moyennes globales.
Surveillance API SOAP
Les APIs SOAP échangent du XML sur HTTP. Exigences : import WSDL pour définition endpoint et schéma ; assertions XPath sur éléments XML réponse ; support SOAP 1.1 et 1.2 ; configuration WS-Security pour services d’entreprise avec sécurité niveau message.
Surveillance API GraphQL
Le défi principal : la plupart des serveurs GraphQL retournent HTTP 200 même en cas d’erreurs partielles ou requêtes malformées. Le code HTTP n’est pas un signal d’échec fiable. Il faut :
- Envoyer des charges de requêtes spécifiques et vérifier l’objet
dataen réponse - Contrôler le tableau
errorsdans la réponse — en GraphQL standard, chaque réponse a un champ optionnelerrorsen tête, vide ou absent lors de succès, rempli en cas d’échec. Un 200 avec unerrors[]rempli signifie échec GraphQL même si HTTP est réussi - Valider les invariants spécifiques aux requêtes : vérifier que les champs attendus sont présents, non-nuls, et du type correct dans
data— certains encodent les échecs de domaine dansdataplutôt que danserrors - Surveiller la complexité et la profondeur des requêtes pour détecter les dégradations avant timeout
Surveillance API gRPC
gRPC utilise Protocol Buffers sur HTTP/2 par défaut, gRPC-Web utilise HTTP/1.1 via proxy pour clients navigateurs. Exigences : import fichier proto pour définition services et méthodes ; support encodage/décodage binaire pour Protocol Buffer ; validation codes d’état via codes gRPC (OK, UNAVAILABLE, DEADLINE_EXCEEDED, etc.) — pas codes HTTP ; support RPC unary, stream serveur/client, bidirectionnel.
Surveillance API WebSocket
Les APIs WebSocket maintiennent des connexions bidirectionnelles persistantes pour les données en temps réel. La surveillance valide le temps d’établissement de connexion et la réussite de la poignée de main WebSocket, la latence et justesse des messages, la stabilité de la connexion dans le temps avec comportements de reconnexion.
Surveillance API publique vs interne

La plupart des guides de surveillance d’API se concentrent sur les points publics. Mais en architectures microservices, la majorité des appels critiques sont internes — appels services-à-services qui n’atteignent jamais Internet public.
| Surveillance API publique | Surveillance API interne | |
|---|---|---|
| Ce que ça couvre | Points publics clients, APIs partenaires, intégrations tierces | Microservices internes, VPC privées, environnements staging, APIs derrière pare-feu |
| Comment ça fonctionne | Agents externes exécutant des contrôles depuis le public via Internet | Agent Privé déployé dans le réseau initiant seulement des connexions sortantes vers la plateforme |
| Exigences pare-feu | Aucune — les contrôles viennent de l’extérieur | Aucune règle entrante requise — l’agent initie uniquement des connexions sortantes |
| Ce que ça détecte | Échecs DNS, problèmes routage CDN, erreurs TLS, lacunes géographiques | Défaillances inter-services, latence microservice d’auth, dégradation API requêtes base |
| Déploiement | Pas d’installation — fonctionne immédiatement | Agent installé sur site ou cloud privé (Windows et Linux supportés) |
Les APIs microservices internes sont la source la plus commune de pannes en cascade. Un service d’authentification dégradé ou un API accès données lent provoque des dysfonctionnements en aval visibles en frontend — rendant la cause difficile à localiser sans visibilité interne. La surveillance des APIs internes permet d’isoler si l’échec vient de la couche API, microservice aval, ou base de données. En savoir plus sur la surveillance Agent Privé derrière votre pare-feu.
Bonnes pratiques de surveillance des API
Ces pratiques réduisent le temps moyen jusqu’à détection (MTTD), améliorent la précision des alertes et garantissent une couverture conforme aux risques de production.
- Surveillez à intervalle d’1 minute pour les points critiques. Pour paiement, authentification et APIs données cœur, chaque minute non détectée a un impact business direct. Des intervalles de 5 ou 15 minutes sont acceptables pour points moins critiques.
- Exécutez les contrôles depuis au moins 5 emplacements géographiquement dispersés. Un seul lieu ne détecte pas les pannes DNS régionales, les erreurs CDN ou les problèmes de routage géo-spécifiques. Couvrez au moins Amérique du Nord, Europe, Asie-Pacifique.
- Validez le contenu de charge utile, pas seulement les codes d’état. Configurez des assertions JSONPath sur chaque point critique. Les échecs silencieux les plus coûteux sont les réponses HTTP 200 avec données incomplètes, périmées ou mal formées.
- Utilisez des seuils d’alerte dérivés de la base, pas des millisecondes statiques. Établissez une base de temps réponse par point et configurez une alerte à 2× la valeur P95. Les seuils statiques génèrent des faux positifs lors des pics normaux.
- Incluez l’authentification dans vos chaînes de surveillance. L’expiration des jetons, échecs de rafraîchissement OAuth, rotations de certificats sont causes majeures de pannes. Surveillez les étapes d’authentification pour attraper les défaillances avant propagation.
- Construisez des moniteurs de transactions multi-étapes pour chaque parcours utilisateur critique. Connexions, paiements, workflows sont des appels API chaînés. Les moniteurs simples ne détectent pas les échecs inter-étapes dus au passage incorrect de données ou gestion de session.
- Surveillez les dépendances API tierces comme moniteurs séparés. Créez des moniteurs dédiés pour Stripe, Okta, Salesforce, et autres dépendances externes. Cela répond immédiatement si une panne est interne ou externe.
- Importez les collections Postman ou Insomnia pour démarrer la surveillance. Convertissez vos définitions existantes en moniteurs 24/7 de production sans recréer les structures de requêtes. Cela élimine l’écart entre tests développement et surveillance production.
- Intégrez les contrôles API post-déploiement dans les pipelines CI/CD. Faites tourner des contrôles synthétiques comme tests automatiques après chaque déploiement. Si des contrôles échouent, envisagez de déclencher rollback automatisé ou hold de trafic dans les déploiements progressifs (blue/green, canary) — en confirmant depuis un second lieu pour réduire les faux positifs avant mesures automatiques.
- Dirigez les alertes vers PagerDuty, Slack ou Microsoft Teams avec politiques d’escalade. Les alertes par mail uniquement créer du retard. Les intégrations natives avec des outils de gestion d’incident assurent la réception immédiate par la bonne personne, avec escalades définies en cas de non-réponse.
Défis de la surveillance des API
Même bien conçues, les configurations de surveillance rencontrent des défis opérationnels. Les anticiper aide à les contourner.
Visibilité sur les API tierces
Surveiller les dépendances externes apporte données disponibilité et latence, mais pas la cause interne des dégradations. Lorsqu’un service comme Stripe ou Okta ralentit, vous pouvez le confirmer et isoler l’impact, mais l’analyse racine dépend des pages de statut fournisseurs et processus d’escalade.
Limitation de débit
Les agents de surveillance comptent dans les limites de débit API. Le volume total de requêtes synthétiques calcule : emplacements × contrôles par heure × appels API par exécution × tentatives de confirmation. Pour un moniteur point unique : 30 × 60 = 1800 requêtes/heure. Pour un moniteur transaction 5 étapes pareil : 30 × 60 × 5 = 9000 requêtes/heure. Prenez cela en compte dans le budget limite de taux, surtout pour les APIs internes avec seuils stricts. Veillez à ce que les plages IP de votre fournisseur soient sur liste blanche.
Complexité d’authentification
Les APIs utilisant des jetons courts ont besoin d’outils gérant automatiquement le rafraîchissement. Les jetons OAuth 2.0 utilisateurs expirent généralement en 15 min à 1 h ; les jetons machine ont des fenêtres de 1–24 h ; environnements hautement sécurisés imposent 5 min. Les authentifications certifiées et clés API rotatives demandent aussi une gestion attentive.
Réponses dynamiques et non-déterministes
APIs renvoyant données horodatées, résultats paginés, ou tableaux ordonnés aléatoirement sont difficiles à valider par correspondance valeur exacte. Utilisez JSONPath validant structure, présence et type de champs — plutôt que valeurs strictes changeant à chaque requête.
Fatigue des alertes
Surveillance excessive — trop de points à 1 minute, seuils trop stricts — génère du bruit désensibilisant aux alertes réelles. Utilisez la surveillance à paliers : 1 min pour chemins critiques, 5–15 min pour moins importants. Confirmez alertes depuis un second lieu avant d’alerter pour éliminer faux positifs transitoires.
Diversité des protocoles
REST, SOAP, GraphQL, gRPC et WebSocket demandent des stratégies d’assertions différentes. Un outil ne gérant que REST manquera les échecs SOAP et signalera incorrectement les erreurs GraphQL comme réussites (car elles renvoient HTTP 200).
Comment configurer la surveillance API avec Dotcom-Monitor
Dotcom-Monitor fournit une surveillance API synthétique pour REST, SOAP et GraphQL depuis plus de 30 emplacements globaux, avec une fréquence de contrôle à 1 minute, support des transactions multi-étapes, et intégrations natives PagerDuty, Slack, Microsoft Teams.
Étape 1 — Définissez votre point de terminaison et les assertions
- URL du point de terminaison : point API à surveiller
- Méthode HTTP : GET, POST, PUT, PATCH ou DELETE
- En-têtes :
Content-Type,Authorization, et en-têtes personnalisés requis - Corps de la requête : charge JSON pour POST/PUT
- Authentification : OAuth 2.0, Bearer Token, Clé API, Basic Auth, mTLS, Signature AWS v4, NTLM, Kerberos, ou en-têtes personnalisés
- Assertions : code HTTP, seuil temps réponse, valeurs en-têtes, assertions JSONPath/XPath sur charge utile
Étape 2 — Importez depuis Postman ou Insomnia
Si votre équipe utilise Postman ou Insomnia, évitez la configuration manuelle :
- Postman : exportez votre Collection au format JSON v2.0/v2.1 et importez-la dans Dotcom-Monitor. Définitions requêtes, en-têtes, corps, variables environnement et assertions tests sont conservés.
- Insomnia : exportez votre workspace en JSON v4 et importez dans Dotcom-Monitor. Groupes de requêtes, configurations auth, variables sont retenus.
Les deux formats d’import convertissent les tests dev uniques en moniteurs 24/7 programmés sans reconfiguration.
Vous utilisez déjà Postman ? Vous êtes à 5 minutes d’une surveillance 24/7.
Importez votre Collection Postman directement dans Dotcom-Monitor. Vos définitions requêtes, en-têtes, variables d’environnement et assertions restent inchangées — sans reconfiguration.
Étape 3 — Configurez emplacements et fréquence
- Fréquence : intervalles de 1, 3, 5 ou 15 minutes — définis par point selon criticité
- Emplacements de surveillance : choisissez parmi 30+ emplacements en Amérique, Europe, Asie-Pacifique et Amérique du Sud
- Agent Privé : pour APIs internes ou derrière pare-feu — déployez l’agent sur site ou cloud privé (Windows et Linux supportés). L’agent initie uniquement des connexions sortantes — pas de règles d’entrée au pare-feu.
- Tentatives de confirmation : configurez un contrôle de confirmation depuis un second emplacement avant déclenchement d’alerte pour éliminer les faux positifs transitoires
Étape 4 — Configurez le routage des alertes
- PagerDuty : envoyez les alertes critiques vers les plannings on-call avec création automatique d’incidents et escalades
- Slack / Microsoft Teams : publiez messages d’alerte avec détails endpoint, type d’erreur, données réponse dans les canaux ops
- Email, SMS, Appel : configurez préférences de notification par contact ou équipe
- Webhook : intégrez OpsGenie, ServiceNow ou tout service HTTP compatible
- Configuration des seuils : définissez conditions d’alerte par métrique — temps réponse, taux d’erreur, taux d’échec des assertions — avec niveaux de gravité
Étape 5 — Intégration dans pipeline CI/CD
- API REST Dotcom-Monitor : créez, mettez à jour et déclenchez les tâches de surveillance par appels API HTTP programmatiques depuis n’importe quel système CI/CD
- GitHub Actions / Azure DevOps / Jenkins : ajoutez une étape post-déploiement déclenchant un contrôle Dotcom-Monitor, attendant résultats et échouant pipeline si assertions échouent
- Validation pré-production : lancez les mêmes contrôles synthétiques contre l’environnement staging avant promotion en production — détectez régressions avant impact utilisateur
Cas d’utilisation de surveillance API par industrie
| Industrie | APIs critiques à surveiller | Exigences clés de surveillance |
|---|---|---|
| E-commerce | Paiement, autorisation, gestion inventaire, livraison, gestion panier | Transactions multi-étapes ; intervalles 1 minute ; assertions charge utile sur confirmation paiement |
| FinTech / Banque | Traitement transaction, vérification KYC/AML, solde compte, taux FX, transferts virements | SLA latence sub-200 ms ; vérifications conformité PCI DSS ; validation complète du flux d’authentification |
| Santé | Intégrations DSE (HL7 FHIR), portails assurance, endpoints télémédecine, planification patients | Vérifications conformité HIPAA ; validation complétude des données ; SLA 99,99 % uptime |
| SaaS | APIs produits cœur, endpoints livraison webhook, intégrations partenaires, APIs authentification | SLA APIs produit ; import Postman pour cohérence dev → surveillance ; surveillance dépendances tierces |
| IT d’entreprise | CRM, ERP, SIRH, fournisseur identité, automatisation workflow interne | Agent Privé pour APIs derrière pare-feu ; support auth NTLM/Kerberos ; visibilité inter-départements |
| Média / Jeux | APIs CDN de contenu, authentification, score temps réel, APIs sociales | Surveillance distribution géographique ; surveillance connexions WebSocket ; détection pics trafic |
Commencez à surveiller vos APIs dès aujourd’hui.
Dotcom-Monitor offre une surveillance API synthétique depuis 30+ emplacements globaux, avec intervalles d’1 minute, support transactions multi-étapes, intégrations natives PagerDuty, Slack, Microsoft Teams. Configuration en moins de 5 minutes. Essai 30 jours sans carte de crédit.
