Cuando un sitio web se cae, a menudo parece un misterio dentro de una caja negra. Los visitantes ven una rueda giratoria, un código de error o una pantalla en blanco, pero para los equipos de TI y los ingenieros de DevOps la primera pregunta siempre es la misma: ¿qué se rompió?
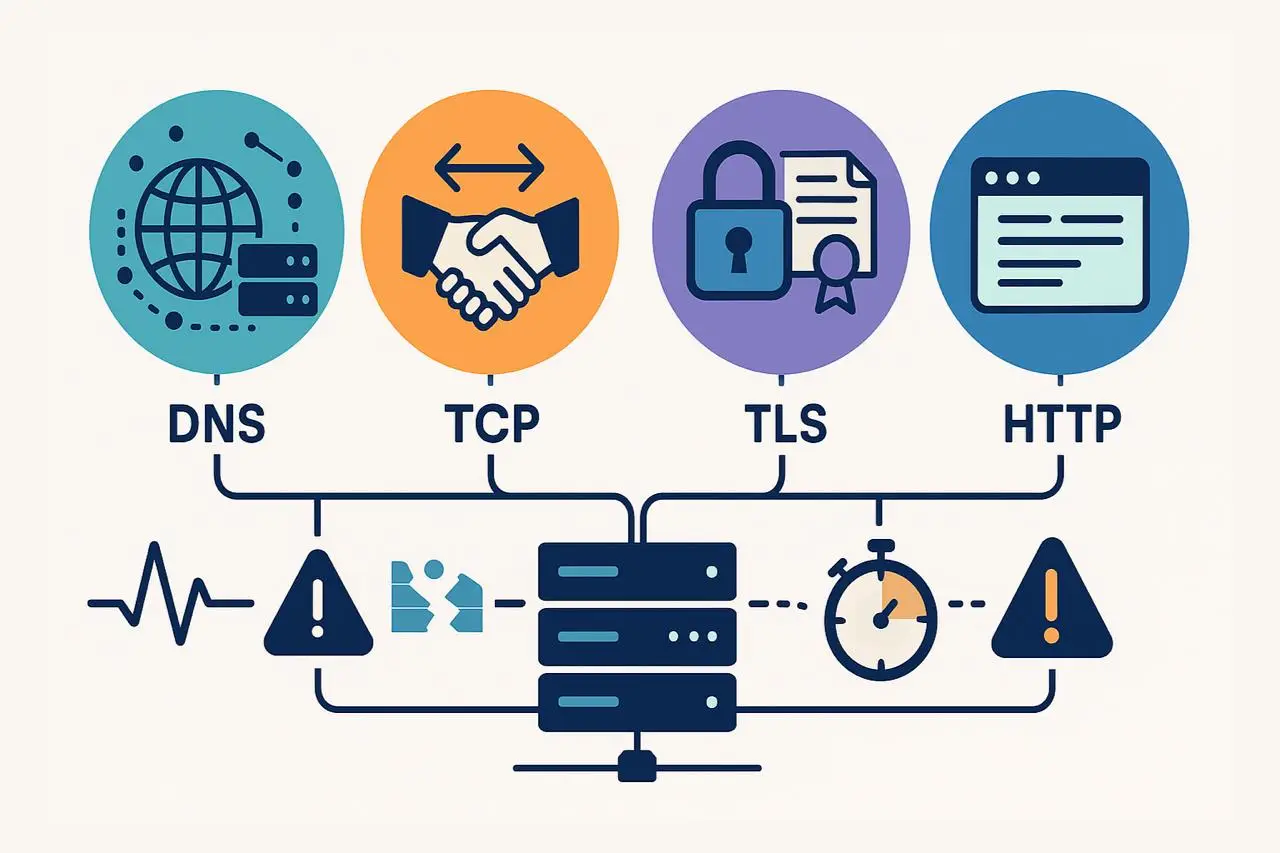
En realidad, no existe una sola forma en que un sitio web “se caiga”. Cada solicitud del navegador pasa por varias fases — resolución DNS, conexión TCP, negociación TLS/SSL y respuesta HTTP — y cada capa introduce sus propios puntos posibles de fallo. Si un eslabón de la cadena falla, la experiencia de usuario entera se ve interrumpida.
Por eso el monitoreo moderno de sitios web va más allá de simples comprobaciones de disponibilidad. El monitoreo inteligente no solo indica que un sitio está “caído”; señala exactamente dónde ocurrió el problema.
- Un error DNS apunta a problemas con el dominio o el resolvedor.
- Un fallo TCP sugiere problemas de conectividad o del cortafuegos.
- Un error TLS/SSL indica problemas de certificados o de seguridad.
- Una respuesta HTTP 5xx revela errores en la aplicación del lado del servidor.
Al identificar qué capa falló, sus equipos pueden responder más rápido, reducir el tiempo medio de resolución (MTTR) y solucionar el problema correcto sin escalados innecesarios ni conjeturas.
Errores DNS: el primer punto de fallo del sitio web
Cada solicitud web comienza con la resolución DNS (Domain Name System), lo que la convierte en una de las capas más críticas de la cadena de entrega de un sitio. Cuando un usuario escribe su dominio en un navegador, la primera acción es una consulta DNS que traduce el nombre de dominio en una dirección IP que indica al navegador dónde conectarse.
Si este paso falla, nada más puede continuar. El navegador no establecerá una conexión TCP, no validará un certificado TLS/SSL ni recibirá una respuesta HTTP. En otras palabras: DNS es la base, y cuando se rompe, todo su sitio se queda a oscuras.
Por eso el monitoreo DNS suele ser el primer y más importante indicador de una posible caída del sitio. Detectar problemas DNS temprano permite a los equipos prevenir interrupciones generalizadas, evitar pérdidas de ingresos y mantener la confianza de los usuarios antes de que los problemas se agraven.
Errores DNS comunes y qué significan
Porque DNS es el primer paso en cada solicitud de sitio web, incluso problemas menores aquí pueden causar grandes interrupciones. Entender los tipos de errores DNS más comunes ayuda a los equipos a identificar causas raíz con más rapidez y a reaccionar antes de que los usuarios sufran tiempo de inactividad.
Aquí están las fallas DNS más frecuentes que encontrará — y lo que indican:
1. NXDOMAIN (Dominio inexistente)
Este error significa que el nombre de dominio no existe o no puede resolverse.
Suele ser causado por:
- Dominios caducados o no registrados
- Archivos de zona DNS mal configurados
- Errores tipográficos en registros DNS o entradas CNAME
Un dominio caducado puede dejar su sitio inmediatamente fuera de línea, mientras que una pequeña mala configuración puede romper solo un subdominio o servicio específico. El monitoreo DNS continuo ayuda a detectar estos problemas temprano, especialmente después de renovaciones de dominio o cambios de configuración.
2. SERVFAIL (Fallo del servidor)
Un SERVFAIL indica que el servidor DNS autoritativo no pudo procesar la consulta.
Causas comunes incluyen:
- Archivos de zona corruptos o incompletos
- Registros glue faltantes
- Errores de validación DNSSEC
Las respuestas SERVFAIL suelen aparecer de forma súbita tras actualizaciones de sistema o configuración, y son una señal temprana de despliegues defectuosos. Las comprobaciones de salud DNS en tiempo real pueden alertar a su equipo en el momento en que ocurren estos problemas a nivel de servidor.
3. Timeouts DNS
Un timeout ocurre cuando una consulta DNS no recibe respuesta dentro de la ventana temporal esperada.
Causas típicas:
- Servidores de nombres sobrecargados o que no responden
- Latencia de red o fallos de conectividad
- Ataques DDoS que colapsan resolvers
Dado que las consultas DNS ocurren antes del caching o la entrega de contenido, incluso una pequeña demora puede desencadenar tiempos de carga más largos y una experiencia de usuario degradada. El monitoreo DNS global proactivo —como el que ofrece Dotcom-Monitor— prueba consultas desde múltiples ubicaciones para detectar estas lentitudes regionales o por proveedor antes de que los clientes las perciban.
Cómo monitorizar DNS de forma efectiva
Monitorizar la salud DNS es más que verificar que su dominio se resuelva una vez. Para comprender de verdad el rendimiento y la fiabilidad, el monitoreo debe replicar cómo los usuarios reales experimentan su sitio en diferentes ubicaciones y redes.
Así es como implementar un monitoreo DNS integral:
Realice comprobaciones DNS globales
El rendimiento DNS puede variar según la geografía. Un registro que se resuelve instantáneamente desde su oficina local puede fallar en otra región debido a problemas de anycast o caídas regionales de red.
Utilice agentes de monitorización sintética desde múltiples ubicaciones globales para simular consultas del mundo real y detectar problemas específicos de cada región antes de que afecten a los usuarios.
Herramientas como Dotcom-Monitor realizan pruebas de resolución DNS multi-región, identificando picos de latencia, consultas fallidas o registros inconsistentes en tiempo real.
Rastree el comportamiento del TTL (Time-to-Live)
Cada registro DNS incluye un valor TTL que define cuánto tiempo un resolver cachea el registro antes de volver a consultarlo.
Mientras que TTLs más largos mejoran el rendimiento para los usuarios finales, pueden retrasar actualizaciones tras cambios de configuración o migraciones.
Las herramientas de monitoreo deben verificar que los valores actualizados se propaguen correctamente y que no queden entradas de caché DNS obsoletas en distintas regiones.
Configure detección de anomalías y alertas
Los insights más valiosos del monitoreo DNS provienen del análisis de tendencias.
- Un aumento repentino de respuestas NXDOMAIN o SERVFAIL
- Incremento de la latencia de resolución DNS
- Inconsistencias regionales en los tiempos de respuesta
Estos son indicadores tempranos de problemas más profundos —a menudo aparecen horas antes de que los usuarios reporten caídas. Las alertas automáticas de anomalías DNS permiten a los equipos reaccionar al instante, garantizando alta disponibilidad y una recuperación más rápida.
Cuando el monitoreo DNS está bien implementado, no solo identifica causas raíz, sino que también descarta lo que no está roto.
Si la resolución DNS falla, sabe que las comprobaciones de TCP, TLS y HTTP ni siquiera llegaron a ejecutarse. Esa claridad acota su investigación con rapidez y ayuda a que los equipos involucren a los proveedores adecuados (hosts DNS, registradores o proveedores de red) para la resolución.
Fallas de conexión TCP: cuando el handshake de red falla
Tras la resolución DNS exitosa que proporciona una dirección IP, la siguiente etapa en la cadena de solicitud es el handshake TCP —el “apretón de manos” digital que establece un canal de comunicación entre cliente y servidor.
Este handshake sigue un proceso de tres pasos:
- El cliente envía un paquete SYN (synchronize).
- El servidor responde con un SYN-ACK (synchronize acknowledgment).
- El cliente envía de vuelta un ACK, completando la conexión.
Solo cuando este handshake se completa pueden comenzar a fluir datos entre el navegador y el servidor web.
Cuando TCP falla, el navegador sabe dónde está el servidor (gracias al DNS) pero no puede conectarse. El resultado se siente como un agujero negro; las páginas se quedan colgadas, los sockets permanecen cerrados y los usuarios ven spinners de carga infinitos.
Los fallos DNS, que suelen ser inmediatos y obvios, y los problemas de conexión TCP con frecuencia causan caídas parciales; el sitio puede parecer disponible para algunos usuarios y no para otros. Estas inconsistencias hacen del monitoreo TCP una capa crucial en cualquier estrategia de monitoreo de rendimiento y disponibilidad.
Errores TCP comunes y lo que indican
Una vez que inicia el proceso de handshake TCP, pueden ocurrir varios fallos relacionados con la red que impiden la comunicación exitosa entre cliente y servidor. Comprender estos tipos de errores TCP ayuda a los equipos a diagnosticar rápidamente dónde se rompe la conexión y qué componente del sistema (red, cortafuegos o aplicación) necesita atención.
A continuación, los errores de conexión TCP más comunes y su significado típico:
1. Connection Refused
Este error significa que el cliente alcanzó con éxito el host objetivo, pero no había ningún servicio escuchando en el puerto esperado.
Causas comunes incluyen:
- Servicios web o de aplicación que se caen inesperadamente
- Contenedores o máquinas virtuales terminadas o redeplegadas
- Load balancers o enlaces de puerto mal configurados
Un ejemplo simple: un servidor web que no está enlazado al puerto 443 (HTTPS) aparece “caído” aunque el servidor subyacente esté funcionando.
Mejor práctica: Use monitoreo de puertos TCP para confirmar que los servicios están correctamente enlazados y escuchando en todas las instancias. Dotcom-Monitor puede probar continuamente la disponibilidad de puertos y alertar a su equipo cuando un servicio deja de responder.
2. Connection Timed Out
Un timeout TCP ocurre cuando paquetes se pierden o son bloqueados en alguna parte de la ruta hacia el destino.
Causas típicas:
- Firewalls que silenciosamente descartan paquetes
- Congestión o inestabilidad en la ruta de red
- Errores de enrutamiento o problemas a nivel ISP
Los timeouts son especialmente frustrantes porque no ofrecen retroalimentación diagnóstica inmediata; los usuarios simplemente ven un spinner hasta que el cliente se rinde.
Mejor práctica: Implante monitoreo de ruta TCP con herramientas que tracen los saltos de red y la latencia. Las diagnósticos de red de Dotcom-Monitor visualizan el flujo de paquetes para ubicar exactamente dónde ocurren los timeouts.
3. Connection Reset
Esto ocurre cuando un handshake TCP se completa pero es terminado abruptamente.
Causas frecuentes:
- Proxies o servidores sobrecargados que cierran conexiones prematuramente
- Ajustes agresivos de tiempo de inactividad en load balancers
- Middleboxes de seguridad (como WAFs) que rechazan sesiones percibidas como sospechosas
Los resets suelen aparecer como errores intermitentes difíciles de reproducir, especialmente en arquitecturas distribuidas o entornos con CDN.
Mejor práctica: Utilice monitoreo continuo del rendimiento TCP para detectar patrones de reset y correlacionarlos con la carga, políticas de seguridad o comportamientos específicos de proxy.
Al categorizar los errores de esta manera, los equipos pueden acotar rápidamente el alcance del problema:
- Si TCP falla, la resolución DNS funciona, pero la conexión no puede establecerse.
- Esa claridad reduce el tiempo de diagnóstico y dirige la solución al equipo correcto: red, cortafuegos o infraestructura.
Cómo monitorizar TCP de forma efectiva
Comprobaciones básicas de disponibilidad como pings ICMP a menudo crean una falsa sensación de seguridad. Un servidor puede responder a pings pero aún así fallar al completar un handshake TCP, lo que significa que los usuarios no pueden conectarse realmente a su sitio o aplicación.
El verdadero monitoreo TCP va más profundo: valida el comportamiento de conexión en el mundo real y detecta problemas que las pruebas de ping pasan por alto. He aquí cómo hacerlo bien:
1. Validación del handshake
El monitoreo TCP efectivo comienza validando el handshake SYN/SYN-ACK/ACK en el puerto real del servicio (por ejemplo, 80 para HTTP o 443 para HTTPS).
Esto garantiza que el servidor sea accesible y esté escuchando activamente el tráfico, no solo “vivo” a nivel de red.
Mejor práctica: Use herramientas de monitoreo sintético, como el Network Monitoring de Dotcom-Monitor, para intentar automáticamente handshakes TCP completos y confirmar que cada endpoint de servicio responde correctamente en todos los nodos.
2. Análisis de ruta entre regiones
Un handshake exitoso depende de cada enlace en la ruta de conexión. Usar traceroutes o MTRs (My Traceroute) desde múltiples regiones geográficas revela dónde los paquetes se ralentizan o se detienen, ya sea en su centro de datos, en el edge del CDN o en el ISP upstream.
Mejor práctica: Ejecute comprobaciones de ruta TCP geo-distribuidas para detectar problemas de enrutamiento o congestión de forma temprana. La red global de monitoreo de Dotcom-Monitor facilita identificar anomalías regionales antes de que afecten a los usuarios.
3. Paridad de protocolo (monitoreo IPv4 e IPv6)
Muchas organizaciones ahora soportan tanto IPv4 como IPv6, pero incidentes reales pueden afectar a un protocolo y no al otro. Si solo prueba IPv4, podría perder problemas que ocurren en redes IPv6.
Mejor práctica: Incluya siempre ambos protocolos en su configuración de monitoreo. Con Dotcom-Monitor puede ejecutar cheques dual-stack para asegurar consistencia y detectar problemas de paridad entre tipos de conexión.
Por qué importa el monitoreo TCP
Las comprobaciones DNS o HTTP y el monitoreo TCP verifican que sus servidores estén listos para aceptar tráfico en vivo, no solo encendidos. Si TCP falla, significa que la resolución DNS funcionó, pero la conexión de red no pudo establecerse.
Esta información ayuda a su equipo a priorizar incidentes al instante:
- DNS está bien → enfoque en servidor, cortafuegos o load balancer.
- No hay necesidad de escalar innecesariamente a desarrolladores o equipos de aplicación.
Al implementar un monitoreo TCP por capas, las organizaciones obtienen una respuesta a incidentes más rápida, menos tiempo de inactividad y mayor fiabilidad de la red.
Errores TLS/SSL
En el panorama web de hoy, HTTPS ya no es opcional — es el valor por defecto. Tras el handshake TCP, el navegador y el servidor web inician una sesión TLS (Transport Layer Security) para asegurar la conexión.
TLS cumple dos funciones críticas:
- Cifrado: Protege todos los datos transmitidos entre navegador y servidor frente a la intercepción.
- Autenticación: Verifica que el servidor es legítimo validando su certificado digital.
Sin TLS, los usuarios enfrentan grandes riesgos de seguridad y privacidad. Pero incluso con TLS, malas configuraciones o certificados caducados pueden causar problemas graves.
Cuando TLS falla, los usuarios ven advertencias aterradoras del navegador como “Your connection is not private” o “This site’s certificate is invalid.” Estos mensajes minan la confianza de inmediato y, en muchos casos, bloquean el acceso del usuario.
Por eso el monitoreo TLS/SSL es crítico para mantener tanto la disponibilidad como la credibilidad. Un solo certificado caducado puede dejar su sitio fuera de línea y dañar su reputación de la noche a la mañana.
Por qué ocurren errores TLS/SSL
Los problemas TLS suelen originarse en malas configuraciones o en renovaciones olvidadas. Causas comunes:
- Certificados caducados – Los certificados no renovados antes del vencimiento dispararán errores de seguridad y bloquearán el acceso.
- Coincidencia de nombre de host – Ocurre cuando un certificado fue emitido para un dominio (p. ej., www.example.com) pero se usa en otro (p. ej., api.example.com).
- Autoridad de certificación no confiable (CA) — Los navegadores no reconocen la CA porque el certificado es autofirmado o está encadenado a una raíz privada no instalada en el dispositivo cliente.
- Fallos de handshake — La negociación criptográfica entre cliente y servidor falla, a menudo por suites de cifrado no soportadas, versiones de protocolo obsoletas o cadenas de certificados incompletas.
Cada uno de estos errores impacta la confianza y accesibilidad del usuario, por eso la monitorización continua de TLS es esencial para la detección temprana.
Cómo monitorizar TLS/SSL de forma efectiva
Los certificados TLS no fallan de manera gradual; funcionan perfectamente un día y bloquean el acceso al siguiente. La mejor aproximación al monitoreo es proactiva y automatizada.
Así es como implementar un monitoreo TLS confiable:
1. Rastrear la validez del certificado
Monitoree la fecha de expiración de todos los certificados SSL/TLS de sus dominios y subdominios. Configure múltiples umbrales de alerta (p. ej., 30, 7 y 1 día antes del vencimiento) para garantizar que las renovaciones se realicen a tiempo.
2. Validar la cadena completa de certificados
Cadenas de certificados incompletas o mal configuradas pueden romper la confianza aunque el certificado principal sea válido. Pruebe regularmente las cadenas de certificados desde distintas regiones para detectar problemas con la CA o los certificados intermedios antes de que los usuarios los experimenten.
3. Comprobar compatibilidad de protocolos y cifrados
A medida que los navegadores deprecian protocolos antiguos (como TLS 1.0/1.1) y cifrados débiles, mantener la compatibilidad es crítico. Las herramientas de monitoreo deben validar las suites de cifrado y las versiones de protocolo soportadas para evitar que los usuarios queden bloqueados.
4. Vigilar fallos de handshake
Un aumento repentino de errores de handshake TLS suele indicar load balancers mal configurados, intermediarios caducados o problemas a nivel de red.
Por qué importa el monitoreo TLS
Los errores TLS no son solo problemas técnicos; son críticos para el negocio. Afectan directamente la confianza del usuario, la percepción de la marca y las conversiones.
Si su monitoreo TLS alerta temprano sobre problemas de certificados o handshake, su equipo puede actuar rápido antes de que se transformen en incidentes visibles para los usuarios.
Errores TLS/SSL comunes
Los errores TLS (Transport Layer Security) y SSL (Secure Sockets Layer) están entre los más visibles y dañinos para la reputación que puede sufrir un sitio. Cuando ocurren, los usuarios reciben advertencias del navegador como “Your connection is not private” o “This website’s security certificate has expired.” Estas alertas destruyen la confianza de inmediato y pueden impedir que los visitantes accedan a su sitio.
A continuación, los errores TLS/SSL más comunes, sus causas y por qué la monitorización continua es vital para prevenirlos.
Certificado caducado
Un certificado SSL caducado es una de las principales causas de interrupciones HTTPS. Los certificados se emiten por un periodo limitado (normalmente 90 días a un año). Si no se renuevan antes del vencimiento, los navegadores marcarán el sitio como inseguro y bloquearán el acceso.
Por qué pasa:
- No automatizar las renovaciones
- La renovación del certificado no se propagó a todos los servidores
- Load balancers mal configurados o problemas de caché
Coincidencia de nombre de host
La coincidencia de nombre de host ocurre cuando el dominio en el certificado no coincide con la URL que visita el usuario. Por ejemplo, un certificado emitido para www.example.com no será válido si el usuario visita api.example.com.
Por qué sucede:
- Agregar subdominios nuevos después de emitir el certificado
- Mover servicios detrás de un CDN o proxy sin reemitir certificados
- Configuración incorrecta de SAN (Subject Alternative Name)
Autoridad de certificación no confiable (CA)
Si la autoridad de certificación (CA) no es reconocida por el navegador, los usuarios verán una advertencia de “certificado no confiable”. Esto sucede cuando el certificado es autofirmado, emitido por una CA interna o encadenado a un certificado intermedio obsoleto o faltante.
Por qué pasa:
- Uso de certificados autofirmados en entornos de producción
- Certificados raíz privados no instalados en dispositivos clientes
- Certificados intermedios faltantes o inválidos
Fallo de handshake
Un fallo de handshake TLS ocurre cuando el navegador y el servidor no logran ponerse de acuerdo sobre cómo conectar de forma segura. El handshake asegura que ambas partes soportan los mismos protocolos y cifrados.
Por qué pasa:
- Suites de cifrado obsoletas o no soportadas
- Uso de versiones TLS desactualizadas (como 1.0 o 1.1)
- Configuración incorrecta de la cadena de certificados o intermediarios faltantes
Asegúrese de que su sitio nunca falle en un handshake TLS
Con el monitoreo TLS/SSL de Dotcom-Monitor, puede detectar automáticamente errores de certificado, problemas de handshake y certificados caducados antes de que afecten a sus usuarios o reputación.
Cómo monitorizar TLS
El monitoreo TLS (Transport Layer Security) debe ser proactivo, automatizado y continuo. Los certificados no se degradan gradualmente; funcionan un día y bloquean el acceso al día siguiente. Por eso las prácticas clave para un monitoreo TLS/SSL eficaz son:
Supervisar la validez y expiración de certificados
Los certificados expiran sin aviso, y cuando lo hacen, los usuarios ven errores del navegador que bloquean el acceso. Para evitar esto, monitorice las fechas de expiración continuamente y configure alertas con antelación —idealmente 30 días, 7 días y 1 día antes del vencimiento.
Validar la cadena completa de certificados
Un certificado SSL válido solo es tan fuerte como su cadena de confianza. Incluso si el certificado leaf es válido, certificados intermedios faltantes pueden romper la confianza en ciertos navegadores o regiones.
Valide regularmente la cadena completa desde múltiples ubicaciones globales para detectar inconsistencias regionales tempranas.
Comprobar compatibilidad de protocolos y cifrados
Los navegadores levantan gradualmente protocolos antiguos (por ejemplo, TLS 1.0 y 1.1) y suites débiles. Si su servidor depende de configuraciones obsoletas, los usuarios pueden no poder conectarse de forma segura.
Monitorizar fallos de handshake y latencia
Los handshakes TLS son la base de la comunicación cifrada. Si fallan o tardan demasiado, los usuarios sufren retrasos, timeouts o errores de conexión.
Picos en errores de handshake suelen trazar a load balancers mal configurados, intermediarios caducados o despliegues de CDN recientes.
Automatizar la gestión de certificados
La mejor forma de prevenir interrupciones por certificados es la automatización. Trate los certificados como código: renuévelos automáticamente, despliegue actualizaciones de forma consistente entre entornos y monitorice la expiración con la misma severidad que monitoriza espacio en disco o uso de CPU.
Errores HTTP
Después de que DNS, TCP y TLS hayan realizado correctamente sus funciones, el navegador finalmente envía una solicitud HTTP al servidor web. A continuación, el servidor responde con un código de estado HTTP 200 OK cuando todo funciona con normalidad o con un código de error cuando algo falla.
El monitoreo de estas respuestas HTTP es a menudo lo primero que la gente imagina al pensar en monitoreo de disponibilidad. Sin embargo, monitorizar solo las respuestas HTTP es solo un aspecto de la supervisión de disponibilidad. Sin el contexto de las capas anteriores (DNS, TCP y TLS), el monitoreo HTTP puede mostrar qué falló pero no por qué. Por eso el monitoreo avanzado de aplicaciones web debe mirar más allá de la disponibilidad hacia el rendimiento, códigos de respuesta e integridad de transacciones.
Errores HTTP comunes
Aquí están algunos de los problemas HTTP más frecuentes que afectan la disponibilidad y la experiencia del usuario:
- 404 Not Found: La página o recurso solicitado no existe. Esto puede ser causado por enlaces rotos, páginas eliminadas o configuraciones de enrutamiento incorrectas.
- 500 Internal Server Error: El servidor encontró una condición inesperada —a menudo debido a errores en el código de la aplicación, configuraciones defectuosas o procesos sobrecargados.
- 502 Bad Gateway: Un proxy o load balancer recibió una respuesta inválida de un servidor upstream. Esto es común en entornos distribuidos o basados en microservicios.
- 503 Service Unavailable: El servidor está temporalmente incapaz de manejar solicitudes, habitualmente por mantenimiento o límites de capacidad.
- 504 Gateway Timeout: Un servicio upstream tardó demasiado en responder, causando que la solicitud falle antes de enviar una respuesta al usuario.
Cada uno de estos errores afecta la confianza del usuario y las conversiones, y en la mayoría de los casos sus clientes no sabrán (o no les importará) por qué. Simplemente se irán.
Cómo monitorizar HTTP
El monitoreo HTTP eficaz va mucho más allá de comprobar si su página de inicio carga. Debe verificar códigos de respuesta, tiempos de respuesta y tasas de éxito de transacciones a través de todas las capas de la experiencia web.
Buenas prácticas clave incluyen:
- Transacciones sintéticas: Simule interacciones reales de usuarios como iniciar sesión, añadir un artículo al carrito o completar un pago para asegurar que los flujos completos funcionen.
- Seguimiento de códigos de respuesta: Capture automáticamente y alerte sobre cualquier respuesta fuera del rango 200–299 para detectar rápidamente fallos del servidor o de la aplicación.
- Umbrales de rendimiento: Monitoree tiempos de respuesta y velocidad de carga de páginas a nivel global. Aunque un sitio esté “disponible”, un rendimiento lento puede alejar a los usuarios.
- Ubicaciones de monitoreo globales: Ejecute comprobaciones HTTP desde múltiples regiones para identificar latencia, problemas de CDN o cuellos de botella de enrutamiento que afecten a audiencias globales.
Por qué importa el monitoreo HTTP
Monitorizar HTTP no se trata solo de confirmar la disponibilidad; se trata de entender la salud de la aplicación y la experiencia del usuario. Un sitio que responde lenta o inconsistentemente le cuesta tráfico, conversiones y posicionamiento SEO. Al superponer el monitoreo HTTP sobre DNS, TCP y TLS obtiene visibilidad completa de dónde se originan los problemas, ya sea en su código, en la infraestructura o en una dependencia upstream.
Errores HTTP comunes
Al monitorizar la disponibilidad y el rendimiento, los códigos de respuesta HTTP revelan el resultado de cada solicitud de usuario. Entender estos errores HTTP comunes le ayuda a determinar si los problemas residen en su aplicación, en su servidor o en dependencias externas.
- 404 Not Found: Indica que el recurso o página solicitada no existe. Esto suele deberse a enlaces rotos, contenido eliminado o rutas URL incorrectas. El monitoreo HTTP regular ayuda a detectar estos errores temprano y preservar el SEO y la confianza del usuario.
- 500 Internal Server Error: Un fallo genérico del servidor, a menudo causado por bugs en la aplicación, configuraciones incorrectas del servidor o procesos backend sobrecargados. Monitorizar logs de respuestas HTTP puede identificar 500s recurrentes antes de que afecten a los usuarios.
- 502 Bad Gateway: Ocurre cuando un proxy, CDN o load balancer recibe una respuesta inválida de un servidor upstream. Es común en arquitecturas distribuidas o de microservicios donde un componente falla en comunicarse con otro.
- 503 Service Unavailable: Señala que el servidor no puede procesar solicitudes temporalmente, usualmente por mantenimiento programado, agotamiento de recursos o picos de tráfico. El monitoreo proactivo ayuda a identificar y mitigar condiciones de sobrecarga antes de que se propaguen.
- 504 Gateway Timeout: Sucede cuando un servidor upstream tarda demasiado en responder, provocando que el gateway o proxy agote el tiempo. Esto puede indicar latencia, cuellos de botella en la base de datos o lentitud en dependencias dentro del stack de la aplicación.
Juntándolo todo: una estrategia de monitoreo por capas
El monitoreo moderno de sitios web no se limita a detectar tiempo de inactividad —se trata de entender por qué un sitio está caído y qué capa lo causó. Cada paso en la secuencia de conexión —DNS, TCP, TLS y HTTP— juega un papel distinto y puede fallar de forma independiente.
Cada caída ocurre en orden:
- Si DNS falla, no se puede establecer ninguna conexión.
- Si TCP falla, la resolución DNS funciona, pero el handshake de red no se completa.
- Si TLS falla, la configuración de cifrado o la validación de certificados se rompe.
- Si HTTP falla, todas las capas anteriores tuvieron éxito —el problema está en la aplicación o el servidor.
Este enfoque por capas aporta claridad y precisión en el diagnóstico de problemas de rendimiento y disponibilidad web.
Las cuatro capas del monitoreo integral de errores
- Comience con comprobaciones DNS: Verifique que los dominios se resuelven correctamente desde múltiples ubicaciones globales.
- Agregue monitoreo de conexión TCP: Confirme que los servidores aceptan y responden a solicitudes de conexión.
- Añada monitoreo de certificados TLS: Rastree la validez de SSL, la performance del handshake y la confianza de la cadena.
- Finalice con monitoreo de respuestas HTTP: Mida la disponibilidad real, la latencia y los códigos de respuesta.
Análisis de causa raíz más rápido
Alinear el monitoreo con estas capas permite a su equipo identificar el punto exacto de fallo —y al propietario correcto para su remediación:
- ¿Error DNS? Contacte a su proveedor de hosting DNS.
- ¿Error TCP? Escale al proveedor de red o de hosting.
- ¿Error TLS? Revise la validez de los certificados o las configuraciones en el edge.
- ¿Error HTTP? Alarme a su equipo de aplicación o DevOps.
En lugar de una vaga alerta “el sitio está caído”, obtiene información accionable que reduce el MTTR y elimina las conjeturas entre equipos.
Conclusión
Los sitios web no solo fallan; fallan en capas. Cada caída empieza en un punto específico de la cadena de conexión: DNS, TCP, TLS o HTTP. Cada capa conlleva sus propios riesgos, comportamientos y firmas de fallo.
Adoptando el monitoreo por tipo de error convierte la complejidad en claridad, transformando una alerta genérica “sitio caído” en conocimientos precisos y accionables.
Con una sólida estrategia de monitoreo de sitios web respaldada por herramientas como Dotcom-Monitor, usted obtiene más que datos de disponibilidad; obtiene entendimiento. Sabe por qué su sitio está caído, qué capa lo causó y quién debe solucionarlo —sea una acción con el registrador, un timeout del proveedor de hosting o un certificado TLS caducado— y podrá identificar la causa raíz rápidamente antes de que los usuarios lo noten.
En última instancia, el monitoreo basado en errores no se trata solo de mantener su sitio en línea; se trata de responsabilidad, visibilidad y velocidad. La próxima vez que su sitio tenga un problema, no se conforme con la incertidumbre. Sepa exactamente qué se rompió, por qué se rompió y cómo resolverlo con confianza y claridad.
¿Listo para monitorear su sitio de forma inteligente?
Detecte problemas DNS, TCP, TLS y HTTP antes que sus usuarios.
Preguntas frecuentes
Supervisar los errores de un sitio web por tipo se refiere al seguimiento y análisis de los fallos del sitio web en función de la capa específica del proceso de conexión: DNS, TCP, TLS o HTTP. Cada tipo de error revela una causa raíz diferente:
- Los errores de DNS indican problemas con la resolución de nombres de dominio.
- Los errores TCP indican conexiones de red fallidas o lentas.
- Los errores TLS/SSL apuntan a problemas de certificados o cifrado.
- Los errores HTTP ponen de relieve fallos en el servidor web o en la aplicación.
Mediante el uso de herramientas de supervisión de sitios web multicapa como Dotcom-Monitor, los equipos pueden detectar dónde y por qué se producen los tiempos de inactividad, lo que mejora el tiempo de actividad, el rendimiento y la fiabilidad del sitio web, al tiempo que se reduce el tiempo de resolución de problemas.
La supervisión multicapa de sitios web es esencial porque los sitios web no solo se caen por una razón, sino que fallan en diferentes capas de la pila de Internet. Las comprobaciones tradicionales del tiempo de actividad solo indican si un sitio está «activo» o «inactivo», pero no por qué.
La supervisión por capas a través de DNS, TCP, TLS y HTTP ofrece una visibilidad completa:
- Si falla el DNS, no se puede encontrar su dominio.
- Si falla el TCP, se interrumpe el protocolo de enlace de red.
- Si falla el TLS, los usuarios se enfrentan a errores de certificado SSL y advertencias del navegador.
- Si falla el HTTP, su aplicación web o servidor no funciona correctamente.
Este enfoque garantiza un análisis más rápido de la causa raíz, una mejor supervisión del tiempo de actividad y una mejor experiencia de usuario, todo lo cual es crucial para los sitios web críticos para el negocio.
Dotcom-Monitor proporciona herramientas avanzadas de supervisión del rendimiento y el tiempo de actividad de sitios web que replican las interacciones de usuarios reales desde múltiples ubicaciones globales. Comprueba continuamente todas las capas de la conexión para garantizar la fiabilidad:
- Supervisión de DNS: comprueba la velocidad y la disponibilidad de la resolución de dominios a nivel mundial.
- Supervisión de TCP: verifica el éxito de los handshakes y detecta problemas de conectividad.
- Supervisión de TLS/SSL: realiza un seguimiento de la validez, la caducidad y la fuerza del cifrado de los certificados SSL.
- Supervisión de HTTP: mide el tiempo de actividad, la velocidad de la página y los códigos de respuesta de error.
Con alertas en tiempo real y diagnósticos visuales, Dotcom-Monitor permite a los equipos de TI y DevOps identificar la causa exacta del tiempo de inactividad, ya sea un tiempo de espera de DNS, un problema de conexión TCP, un fallo de establecimiento de conexión TLS o un error HTTP 500, y resolverlo antes de que afecte a los usuarios o a las clasificaciones SEO.
