
Tu buscapersonas suena a las 2 a.m. La carga útil de la alerta tiene un código de estado. Lo que haces a continuación depende casi por completo del código que veas.
Esa es la parte que la mayoría de las guías de códigos de estado HTTP omiten. Listan definiciones, clasifican los códigos en cinco grupos y paran. Útil como glosario, menos útil cuando un endpoint real está lanzando 502s y un ejecutivo pregunta por qué el checkout está roto.
Esta guía cubre los mismos diez códigos que verás con mayor frecuencia, además de algunas menciones honoríficas. Para cada uno: qué significa, qué suele desencadenarlo en producción y qué revisar primero. El objetivo es acortar el tiempo entre “Veo el código” y “Sé qué arreglar.”
¿Qué es un código de estado HTTP?
Un código de estado HTTP es un número de tres dígitos que el servidor envía con cada respuesta. Indica al cliente si la solicitud fue exitosa, fallida o necesita ser redirigida. Los ves en todas partes: en la pestaña Network de las DevTools de tu navegador, en los registros del balanceador de carga, en alertas de monitoreo, en paneles de CDN. Esta guía se enfoca en los que realmente despiertan a la gente.
Las cinco categorías de códigos de estado HTTP
El primer dígito del código indica la clase de respuesta:
- 1xx Informativos. Raros en el trabajo cotidiano. Principalmente usados para negociación de protocolo (100 Continue, 101 Switching Protocols para actualizaciones WebSocket).
- 2xx Éxito. La solicitud funcionó. 200 es el predeterminado; 201 significa que se creó un recurso; 204 significa éxito sin cuerpo.
- 3xx Redirección. El recurso vive en otro lugar. Los navegadores y rastreadores siguen estas automáticamente hasta un límite.
- 4xx Error del cliente. La solicitud fue incorrecta. URL mala, falta de autenticación, permisos bloqueados, carga útil mal formada.
- 5xx Error del servidor. La solicitud estaba bien. El servidor no pudo cumplirla.
La división entre 4xx y 5xx es lo que más importa para el triaje. Un 4xx indica “el que llama hizo algo mal.” Un 5xx indica “nosotros hicimos algo mal.” El primero va a quien llamó el endpoint. El segundo va a ti.
Para una enumeración completa, la referencia completa de códigos de estado HTTP del wiki de Dotcom-Monitor lista todos los códigos definidos en la especificación. El resto de esta guía se enfoca en los que realmente aparecen en alertas.
Los diez códigos de estado HTTP más comunes
200 OK
El servidor procesó la solicitud y devolvió la respuesta esperada. Este es el código que quieres ver en la gran mayoría de las solicitudes a un sitio productivo sano.
Cuidado con: un 200 OK no es prueba de que la página sea correcta. JavaScript puede fallar silenciosamente y mostrar una página en blanco. Un API puede devolver 200 con un cuerpo de error. Un formulario de login puede mostrar “credenciales inválidas” dentro de una respuesta 200. Las verificaciones solo por código de estado no detectan esto. Combínalas con verificaciones en navegador real (más sobre esto abajo).
301 Moved Permanently
El recurso tiene una nueva URL permanente. Los navegadores almacenan en caché la redirección agresivamente. Los motores de búsqueda transfieren la mayoría de la equidad del enlace al destino.
Úsalo para: cambios de URL tras una migración, cambiar HTTP a HTTPS, consolidar rutas duplicadas, retirar slugs antiguos. Una vez que un 301 está activo y cacheado, revertirlo es doloroso—los navegadores y rastreadores seguirán yendo a la nueva ubicación durante semanas.
302 Found (Redirección Temporal)
El recurso está temporalmente en otro lugar. Los navegadores no almacenan en caché la redirección, y los motores de búsqueda no pasan toda la equidad del enlace.
Cuidado con: el 302 está sobreusado. Los equipos lo usan porque la función de redirección por defecto del framework devuelve 302. Si el cambio es permanente, usa 301. Si necesitas preservar el método HTTP (un POST sigue siendo POST), usa 307 o 308 en su lugar. Google eventualmente tratará los 302 persistentes como 301, pero “eventualmente” no es una estrategia.
400 Bad Request
El servidor no puede analizar la solicitud. JSON mal formado, cabeceras inválidas, cargas útiles demasiado grandes, violaciones de esquema.
Revisa primero: el cuerpo de la solicitud. Un aumento de 400 en un endpoint API suele indicar que un cliente comenzó a enviar datos con formato incorrecto—un despliegue en el lado consumidor, un cambio de esquema en el tuyo, o una integración de terceros que actualizó su formato. Compara la carga útil de la solicitud con tu última versión conocida correcta.
401 Unauthorized
La solicitud no tiene credenciales o las credenciales fueron rechazadas. El nombre es engañoso—el problema es autenticación, no autorización.
Revisa primero: los tokens. Un pico repentino de 401 en endpoints que funcionaban suele significar que un token expiró, una clave de firma fue rotada, un proveedor OIDC tuvo una caída o alguien cambió el claim de audience. Si tu monitoreo de disponibilidad API muestra 401s donde antes había 200s, usualmente la capa de autenticación es la culpable.
403 Forbidden
Las credenciales son válidas, pero el que llama no tiene permiso para acceder a este recurso. El problema es autorización, no autenticación.
Revisa primero: permisos y reglas de infraestructura. Los 403 aparecen cuando una política IAM cambia, una regla WAF comienza a bloquear tráfico legítimo, una política de acceso CDN es demasiado agresiva o un feature flag cambia para un segmento de usuarios incorrecto. Si los 403 empezaron justo después de un despliegue, revisa diferencias de políticas y configuraciones antes del código de la app.
404 Not Found
El servidor entendió la solicitud pero no tiene recurso en esa URL. El código de estado más famoso que existe.
Dos escenarios a diferenciar:
- 404 puntuales por errores tipográficos, antiguos marcadores o rastreadores buscando vulnerabilidades. Son ruido de fondo.
- Un estallido de 404 en URLs canónicas justo tras un despliegue. Eso es una versión rota—se eliminaron rutas, falta un artefacto de build o alguien desplegó un cambio de slug sin redirecciones. Revertir o aplicar un parche rápido.
Los 404 persistentes en páginas indexadas eventualmente serán eliminados por Google, por lo que las páginas canónicas que lanzan 404 también tienen un costo SEO.
Solución
Camino rápido: si la página se movió, añade una redirección 301 de la URL antigua a la nueva para que usuarios y rastreadores lleguen al lugar correcto. Si la página ya no existe, devuelve un 404 o 410 real en lugar de una redirección vaga a la página principal.
Solución real: audita la fuente de los 404. Los enlaces internos rotos se arreglan en la fuente; las rutas faltantes tras un despliegue se corrigen con un parche; una mala migración que eliminó slugs necesita un mapa de redirecciones. Rastrea tu propio sitio periódicamente para encontrar enlaces muertos antes que Google.
500 Internal Server Error
El servidor encontró una excepción no manejada. El 5xx comodín. Te dice que algo falló pero no qué.
Revisa primero: los logs de la aplicación. Cada 500 tiene un stack trace en algún lugar—si no, tu logging necesita mejora antes que tu código. Desencadenantes comunes: excepción no capturada en una ruta desplegada recientemente, dependencia downstream que devuelve un formato inesperado, pool de conexiones a base de datos agotado, un ciclo de reinicio por falta de memoria. Un pico sostenido de 500 en un endpoint productivo debe notificar a on-call.
Solución
Camino rápido: si el pico comenzó justo tras un despliegue, revierte. Un 500 que aparece minutos después de un deploy es el deploy hasta que se demuestre lo contrario.
Solución real: lee el stack trace y corrige la ruta de código que falla, luego añade un test de regresión para evitar que regrese. Si el desencadenante fue un límite de recurso—pool de conexiones, memoria, manejadores de archivos—aumenta el límite y añade una alerta antes de que se alcance la próxima vez.
502 Bad Gateway
Un proxy, balanceador de carga o CDN recibió una respuesta inválida del servidor upstream. El proxy mismo está saludable. Lo que está detrás no.
Revisa primero: la salud del upstream. Desencadenantes comunes: un contenedor de app se cayó y el balanceador sigue enviando tráfico, el upstream tarda demasiado en responder, un pod de Kubernetes está en CrashLoopBackOff, un trabajador Nginx está mal configurado, o la conexión entre proxy y upstream se reinició. El 502 es uno de los códigos con señal más alta en arquitecturas en capas—te dice que el borde está bien y el problema está a un salto.
Solución
Camino rápido: reinicia o reemplaza la instancia upstream no saludable y confirma que las verificaciones de salud del balanceador realmente sacan nodos muertos de la rotación.
Solución real: encuentra por qué el upstream devolvió basura. Revisa si el timeout del proxy es más corto que el tiempo real de respuesta del upstream, si el pod está en un ciclo de crashes al iniciar, y si las configuraciones de keep-alive coinciden en ambos lados de la conexión.
503 Service Unavailable
El servidor está temporalmente incapaz de manejar la solicitud. Capacidad agotada, modo mantenimiento, autoscaler aún arrancando.
Revisa primero: saturación de recursos y límites de tasa. Los 503 durante un pico de tráfico suelen significar que el autoscaler no da abasto o que llegaste a un límite de conexiones. Los 503 en estado estable suelen indicar que un proceso está en modo mantenimiento o una cola está saturada. Algunas plataformas también devuelven 503 cuando un WAF upstream o sistema anti-bots limita por tasa a un llamador—vale la pena comprobar antes de asumir que el problema es la app.
Solución
Camino rápido: devuelve el 503 con un encabezado Retry-After para que clientes bien comportados y rastreadores se retiren en lugar de golpear un servidor saturado. En PHP:
http_response_code(503);
header('Retry-After: 60');Solución real: encuentra el recurso saturado—conexiones a base de datos, pool de trabajadores, límite del autoscaler—y elimina el cuello de botella. Si el 503 viene de un límite de tasa de CDN o WAF, aumenta el límite o pon en lista blanca al llamador legítimo.
Otros códigos que vale la pena conocer
Los diez anteriores cubren la mayoría del tráfico en producción. Pero hay algunos otros que aparecen lo suficientemente seguido en incidentes reales que los ingenieros on-call deberían reconocerlos al instante.
- 304 Not Modified. Enviado cuando un recurso cacheado sigue fresco. Común en tráfico con CDN delante. Una disminución de 304 puede significar que tus encabezados cache-control cambiaron y estás pagando por ancho de banda de origen que antes ahorrabas.
- 307 Temporary Redirect. Como 302, pero preserva el método HTTP. Un POST sigue siendo POST. Usa 307 en lugar de 302 cuando redirijas envíos de formulario o llamadas API no idempotentes.
- 308 Permanent Redirect. Como 301, pero preserva el método HTTP. La opción moderna para redireccionar permanentemente endpoints API que manejan POST, PUT, PATCH o DELETE.
- 429 Too Many Requests. Se alcanzó límite de tasa. O te están throttling con un API upstream o tú estás limitando a alguien. Revisa los encabezados
Retry-After; respétalos. - 504 Gateway Timeout. Un proxy desistió de esperar al upstream. Diferente de 502 en que el upstream no devolvió una mala respuesta, sino ninguna respuesta a tiempo. Usualmente una consulta larga, un worker congelado o un API downstream lento.
301 vs 302 vs 307 vs 308
Los cuatro códigos de redirección se confunden constantemente. La diferencia se reduce a dos cosas: si el movimiento es permanente y si el método HTTP se mantiene tras la redirección.
| Comportamiento | 301 | 302 | 307 | 308 |
|---|---|---|---|---|
| Perdurabilidad | Permanente | Temporal | Temporal | Permanente |
| Método preservado | No garantizado | No garantizado | Sí | Sí |
| Cacheado por navegadores | Agresivamente | No | No | Sí |
| Equidad de enlace transmitida | Mayormente | Limitada | Limitada | Mayormente |
| Uso cuando | Movimiento permanente de URL | Cambio temporal | Redirección de formulario o POST | Endpoint API movido permanentemente |
Para una página simple que se movió permanentemente, usa 301. Cuando la redirección debe mantener un POST como POST—un envío de formulario o llamada API no idempotente—usa 307 si es temporal o 308 si es permanente.
La referencia completa de códigos de estado HTTP
Los códigos arriba cubren casi todo lo que genera una alerta real. Para los inusuales—los códigos que aparecen una vez por trimestre y te hacen detenerte a buscar algo—aquí está la lista estándar completa, más los códigos no estándar que verás de proveedores comunes de infraestructura.
1xx Informativos
El servidor ha recibido la solicitud y continúa procesándola. Raramente verás estos en logs de aplicación porque la mayoría de clientes y proxies los manejan transparentemente.
| Código | Significado |
|---|---|
| 100 | Continue |
| 101 | Switching Protocols |
| 102 | Processing |
| 103 | Early Hints |
2xx Éxito
La solicitud fue recibida, entendida y aceptada. 200 es el caballo de batalla; el resto importan cuando construyes APIs o trabajas con contenido parcial, WebDAV o operaciones batch.
| Código | Significado |
|---|---|
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 203 | Non-Authoritative Information |
| 204 | No Content |
| 205 | Reset Content |
| 206 | Partial Content |
| 207 | Multi-Status |
| 208 | Already Reported |
| 226 | IM Used |
3xx Redirección
El recurso vive en otra parte, o la copia cacheada sigue vigente. 301 y 302 dominan; el resto importan para APIs (307/308 preservan el método HTTP) y pipelines de cacheo (304 ahorra ancho de banda al origen).
| Código | Significado |
|---|---|
| 300 | Multiple Choices |
| 301 | Moved Permanently |
| 302 | Found |
| 303 | See Other |
| 304 | Not Modified |
| 305 | Use Proxy (deprecated) |
| 306 | Switch Proxy (unused) |
| 307 | Temporary Redirect |
| 308 | Permanent Redirect |
4xx Errores del cliente
La solicitud fue incorrecta. La mayoría nunca los verás; la media docena común aparece a diario. Vale la pena saber que existen los raros para no perder tiempo adivinando cuando caen un 418 o 451 en un log.
| Código | Significado |
|---|---|
| 400 | Bad Request |
| 401 | Unauthorized |
| 402 | Payment Required |
| 403 | Forbidden |
| 404 | Not Found |
| 405 | Method Not Allowed |
| 406 | Not Acceptable |
| 407 | Proxy Authentication Required |
| 408 | Request Timeout |
| 409 | Conflict |
| 410 | Gone |
| 411 | Length Required |
| 412 | Precondition Failed |
| 413 | Payload Too Large |
| 414 | URI Too Long |
| 415 | Unsupported Media Type |
| 416 | Range Not Satisfiable |
| 417 | Expectation Failed |
| 418 | I’m a teapot |
| 421 | Misdirected Request |
| 422 | Unprocessable Content |
| 423 | Locked |
| 424 | Failed Dependency |
| 425 | Too Early |
| 426 | Upgrade Required |
| 428 | Precondition Required |
| 429 | Too Many Requests |
| 431 | Request Header Fields Too Large |
| 451 | Unavailable For Legal Reasons |
5xx Errores del servidor
La solicitud estaba bien. Algo en el servidor falló. Estos son los códigos que más probablemente despertarán a alguien.
| Código | Significado |
|---|---|
| 500 | Internal Server Error |
| 501 | Not Implemented |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
| 504 | Gateway Timeout |
| 505 | HTTP Version Not Supported |
| 506 | Variant Also Negotiates |
| 507 | Insufficient Storage |
| 508 | Loop Detected |
| 510 | Not Extended |
| 511 | Network Authentication Required |
Códigos no estándar y de proveedores
Cloudflare, Nginx, Microsoft y Akamai devuelven códigos fuera de la especificación oficial cuando su capa de infraestructura falla. Estos son los códigos que debes reconocer al instante porque indican que la falla está en el borde, no en tu origen.
| Código | Significado |
|---|---|
| 419 | Authentication Timeout |
| 420 | Enhance Your Calm / Method Failure |
| 440 | Login Timeout (Microsoft) |
| 444 | No Response (Nginx) |
| 449 | Retry With (Microsoft) |
| 450 | Blocked by Windows Parental Controls |
| 460 | Client Closed Connection |
| 494 | Request Header Too Large (Nginx) |
| 495 | SSL Certificate Error (Nginx) |
| 496 | SSL Certificate Required (Nginx) |
| 497 | HTTP Request Sent to HTTPS Port |
| 498 | Invalid Token |
| 499 | Client Closed Request (Nginx) |
| 509 | Bandwidth Limit Exceeded |
| 520 | Unknown Error (Cloudflare) |
| 521 | Web Server Is Down (Cloudflare) |
| 522 | Connection Timed Out (Cloudflare) |
| 523 | Origin Is Unreachable (Cloudflare) |
| 524 | A Timeout Occurred (Cloudflare) |
| 525 | SSL Handshake Failed (Cloudflare) |
| 526 | Invalid SSL Certificate (Cloudflare) |
| 527 | Railgun Error (Cloudflare) |
| 529 | Site Overloaded |
| 530 | Site Frozen / Origin DNS Error |
| 561 | Unauthorized (Akamai) |
| 598 | Network Read Timeout |
| 599 | Network Connect Timeout |
Los rangos de códigos no listados arriba (104-199, 209-225, 227-299, 309-399, 432-450, 452-499, 512-599) son no asignados, obsoletos o reservados para uso del proveedor. Trata cualquier código en esos rangos como específico de proveedor y verifica la documentación de tu infraestructura.
Los códigos que tu monitoreo realmente debería alertar
De los más de 60 códigos anteriores, los que establecen umbrales de alerta en la mayoría de configuraciones productivas son una lista mucho más corta:
- 200—como ratio base. Una caída repentina indica que algo más está fallando.
- 301, 302, 307, 308—conteos de redirecciones. Picos pueden indicar enrutamiento mal configurado o un despliegue que rompió URLs canónicas.
- 400—solicitudes mal formadas. Usualmente un cambio del consumidor.
- 401, 403—fallos de autenticación y permisos. Frecuentemente un cambio en token, IAM o WAF.
- 404—recursos faltantes. Ruido de fondo como casos aislados; problema de lanzamiento en picos.
- 408—time-outs del cliente. Vale la pena alertar en tasas sostenidas; señala llamadas lentas downstream.
- 429—limitación de tasa. O te throttlean o tú estás limitando a alguien.
- 500, 502, 503, 504—fallas de aplicación, upstream, capacidad y timeout de gateway. Estos notifican a on-call.
- 520-526—fallas en el borde de Cloudflare. Si estás detrás de Cloudflare, estos son señales críticas porque aíslan la falla al camino borde-origen.
Todo lo demás vale la pena registrar pero rara vez merece despertar a alguien.
Cómo revisar el código de estado HTTP de una página
Antes de actuar sobre un código, debes verlo. Tres formas, de la más rápida a la más completa.
En Chrome DevTools
- Abre la página.
- Haz clic derecho en cualquier parte y elige Inspeccionar, luego abre la pestaña Network.
- Recarga. La primera solicitud de documento muestra el código en la columna Status.
Desde la línea de comandos
Una solicitud solo de encabezados devuelve la línea de estado sin descargar el cuerpo:
curl -I https://example.comLa primera línea de la respuesta es el código de estado—por ejemplo, HTTP/2 200.
A escala
Las verificaciones puntuales te dicen el estado actual. No atraparán la falla que ocurre a las 3 a.m. y se resuelve antes de que despiertes. Para detectar fallas intermitentes, necesitas verificaciones programadas desde múltiples regiones—que es lo que hace el monitoreo sintético.
Cuando un 200 OK miente
Un equipo de comercio electrónico recibe una alerta a las 11 a.m. de un martes. La conversión bajó un 80%. Revisan su panel de uptime. Todos los endpoints están verdes. Todos los códigos de estado son 200. Todas las regiones reportan que el sitio está activo.
El sitio no está activo. Un despliegue 40 minutos antes lanzó un bundle de JavaScript que falla en la página de checkout. El HTML se carga, el servidor devuelve 200, el monitor de código de estado ve 200, no hay alerta. Los usuarios ven un carrito vacío y se van.
Este es el modo de falla que la monitorización pura de códigos de estado no puede detectar. La solución es en capas:
- Ejecutar verificaciones con navegador real en caminos críticos de usuario—home, búsqueda, producto, carrito, checkout. Los navegadores reales ejecutan JavaScript y muestran errores del lado cliente que una verificación estilo curl no ve.
- Vigilar señales a nivel de cuerpo: presencia de palabras clave, visibilidad de elementos, estructura esperada de respuesta. No confíes solo en el código de estado.
- Relacionar despliegues con monitoreo: cualquier verificación que pase de verde a rojo en 15 minutos tras un release debe autoetiquetar el despliegue. La mitad del tiempo post-mortem es descubrir qué cambió; el sistema de monitoreo ya lo sabe.
¿Qué es un soft 404?
Una versión de este problema tiene nombre: el soft 404. Un soft 404 es una página que devuelve 200 OK mientras informa al usuario que el contenido no existe—un mensaje de “página no encontrada” servido con código de éxito. La guía de Google es devolver un 404 o 410 real en su lugar, porque los soft 404s desperdician el presupuesto de rastreo y confunden al índice sobre qué páginas son reales.
La monitorización pura por código de estado no captará un soft 404, por la misma razón que falla con un checkout roto: el código dice 200. Las verificaciones con navegador real y aserciones en el cuerpo—buscando el contenido real esperado o la ausencia de un texto “no encontrado”—sí lo harán.
Cómo afectan los códigos de estado HTTP al SEO
Los motores de búsqueda usan códigos de estado para decidir qué rastrear, qué indexar y con qué frecuencia volver. Tres patrones importan:
- Códigos 4xx erosionan el índice con el tiempo. Una página que devuelve 404 en varios intentos de rastreo se elimina. Si eliminas una página, redirígela con 301 en lugar de dejar que dé 404.
- Códigos 5xx ralentizan el rastreo y dañan rankings. Googlebot interpreta 5xx persistentes como “este sitio está enfermo.” La tasa de rastreo baja, la indexación se enlentece, el ranking puede caer.
- 301 vs 302 importa. El 301 pasa equidad de enlace. El 302 se trata como temporal y puede que no lo haga. Si el movimiento es permanente, elige 301.
La conclusión práctica: los errores 5xx no son solo un problema de disponibilidad. Son un problema SEO que se agrava cuanto más persisten. Los errores DNS, TCP, TLS y HTTP tienen cada uno un costo SEO diferente—saber qué capa falla te ayuda a hacer triaje más rápido.
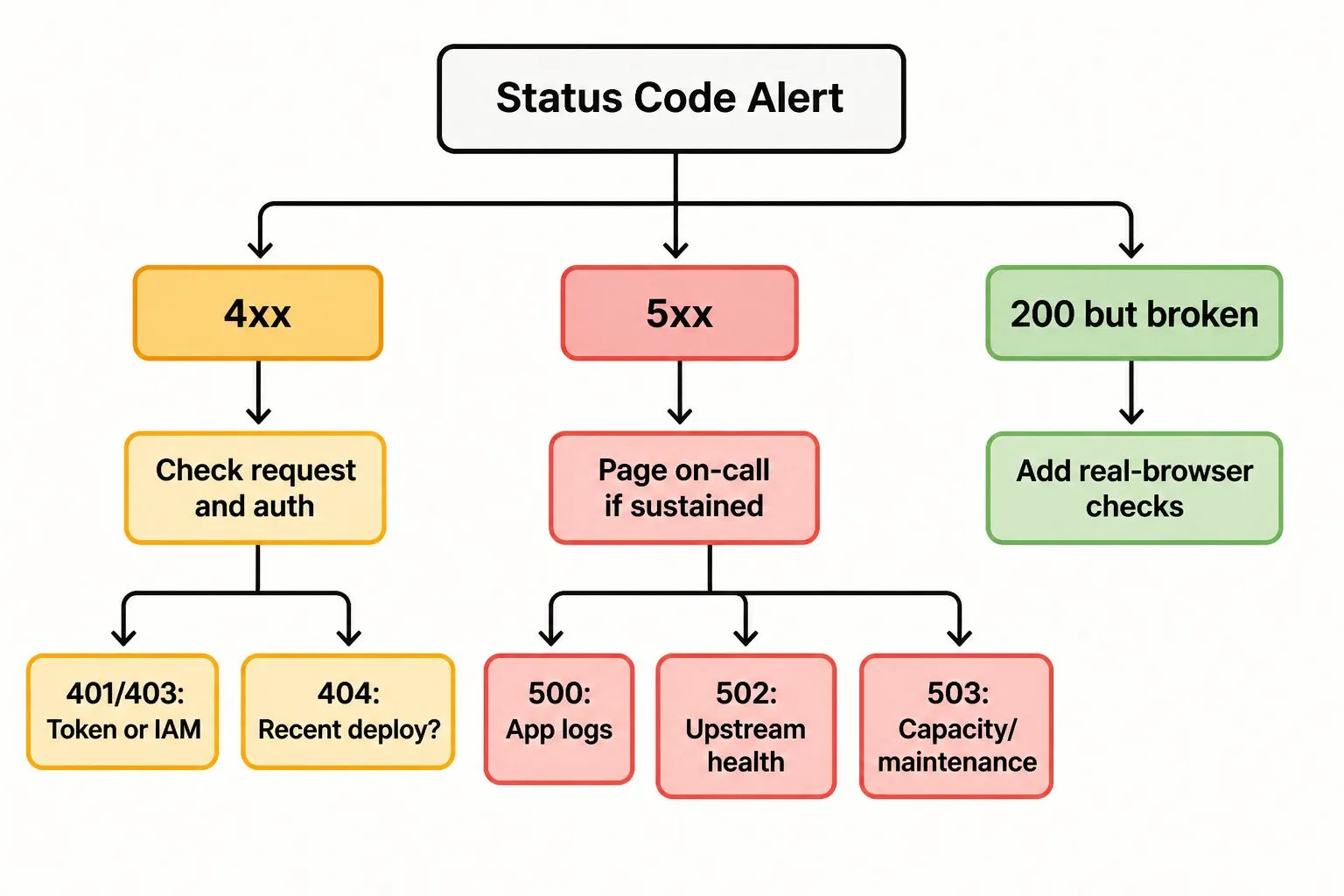
Monitorear códigos de estado HTTP sin ahogarse en alertas
Cada equipo que monitorea tráfico HTTP eventualmente enfrenta el mismo problema: demasiadas alertas, poca señal. Algunas prácticas mantienen útil el monitoreo de códigos de estado en lugar de ruidoso.
Alerta sobre tasas, no solicitudes individuales. Un 500 es ruido. Cincuenta 500 en cinco minutos es un incidente. Configura umbrales según tu volumen base de tráfico.
Separa endpoints públicos de los internos. Un 500 en API de checkout debe notificar. Un 500 en endpoint admin que nadie usa puede esperar a horas hábiles.
Prueba desde donde están tus usuarios. Una verificación desde un solo centro de datos no detectará una falla regional de CDN. Usa una red de monitoreo con múltiples geografías para detectar problemas localizados antes que los clientes.
Combina chequeos de estado con chequeos de contenido. 200 OK es un punto de partida, no una línea de meta. Valida que la respuesta contenga lo que debe.
El monitoreo de aplicaciones web de Dotcom-Monitor maneja los cuatro: alertas basadas en tasa, segmentación de endpoints, ubicaciones globales de monitoreo y chequeos de contenido con navegador real. Para stacks con APIs intensivas, la ruta de monitoreo API añade validación de esquema y SLOs de tiempo de respuesta encima del chequeo de códigos de estado. Ambos alimentan el mismo canal de alertas para que no estés uniendo señales de tres proveedores distintos.
Reflexiones finales
Los códigos de estado HTTP más comunes no han cambiado en años. 200, 301, 404, 500, 502, 503—verás todos esta semana. Lo que cambia es qué tan rápido tu equipo pasa de “vi el código” a “arreglé la causa.”
Esa brecha es donde un buen monitoreo paga dividendos. Los códigos de estado solos te dicen que algo pasó. Los chequeos en capas—estado, contenido, navegador real, multi-región—te dicen qué, dónde y qué hacer después.
Si quieres ver cómo funciona, Dotcom-Monitor tiene una prueba gratuita. Apúntalo a uno de tus endpoints y mira qué detecta.
