ウェブサイトがダウンすると、多くの場合ブラックボックスの中の謎のように感じられます。訪問者はくるくる回るローディング、エラーコード、または白い画面を見るだけですが、IT チームや DevOps エンジニアにとって最初の問いは常に同じです:何が壊れたのか?
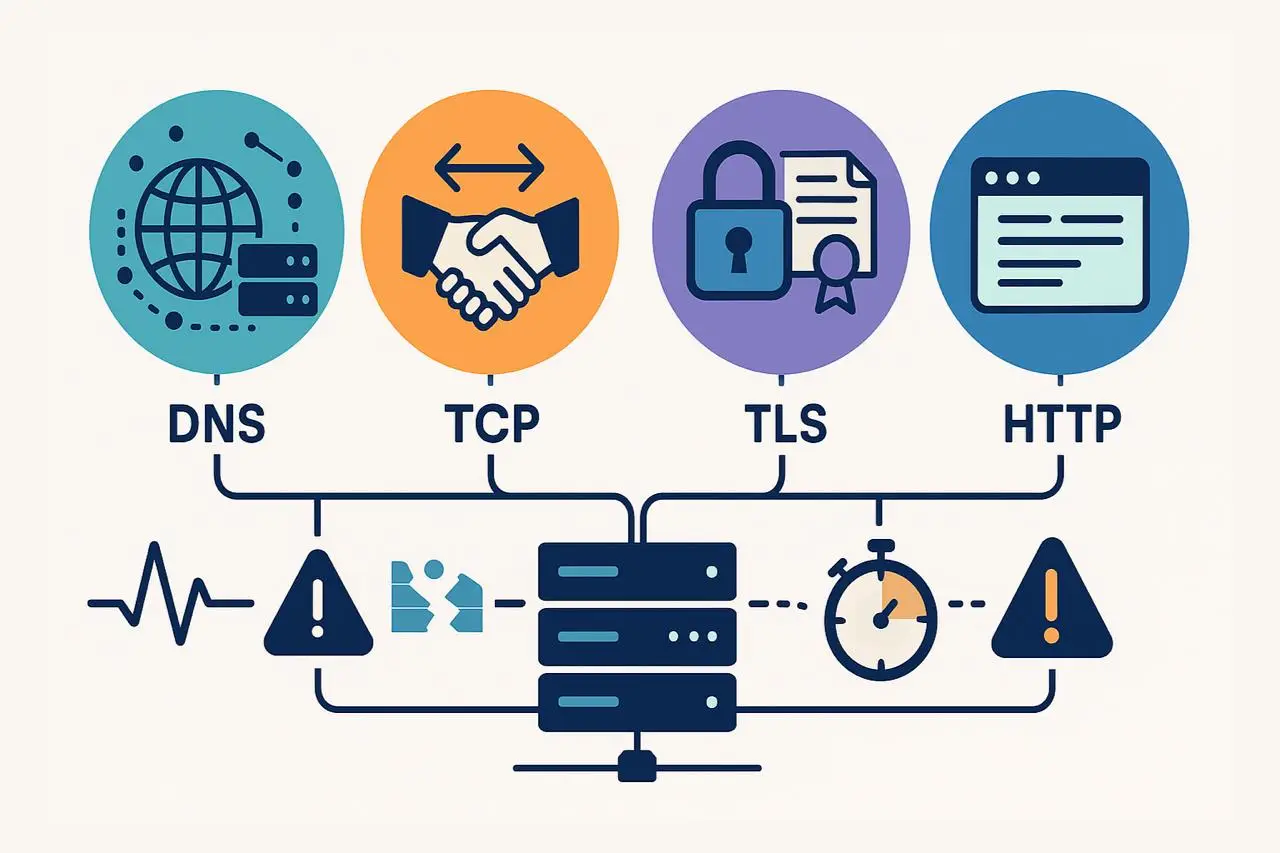
実際には、ウェブサイトが「ダウンする」方法は一つだけではありません。すべてのブラウザリクエストは複数の段階を経ます——DNS 解決、TCP 接続、TLS/SSL ネゴシエーション、HTTP 応答——そして各レイヤーは潜在的な故障点を持ちます。チェーンの一部が機能しなくなると、ユーザー体験全体が阻害されます。
だからこそ、現代のウェブ監視は単純な稼働確認を超えています。スマートな監視は単にサイトが「ダウン」であると知らせるだけでなく、問題が発生したレイヤーを特定します。
- DNS エラーはドメインやリゾルバの問題を示します。
- TCP 障害は接続やファイアウォールの問題を示唆します。
- TLS/SSL エラーは証明書やセキュリティ関連の問題を示します。
- HTTP の 5xx 応答はサーバー側のアプリケーションエラーを明らかにします。
どのレイヤーが失敗したかを識別することで、チームはより速く対応し、平均復旧時間(MTTR)を短縮し、無駄なエスカレーションや推測を避けて正しい問題を解決できます。
DNS エラー:ウェブサイト障害の最初のポイント
すべてのウェブリクエストは DNS(ドメインネームシステム)の解決から始まります。これにより、ウェブ配信チェーンの中でも最も重要なレイヤーの一つになります。ユーザーがブラウザにドメインを入力すると、最初のアクションは DNS クエリで、ドメイン名をブラウザが接続すべき IP アドレスに変換します。
このステップが失敗すると、他の処理は何も進みません。ブラウザは TCP 接続を確立せず、TLS/SSL 証明書を検証せず、HTTP 応答も受け取りません。言い換えれば、DNS が基礎であり、それが壊れるとサイト全体が真っ暗になります。
そのため、DNS 監視は潜在的なサイト停止の最初かつ最重要の指標であることが多いのです。早期に DNS の問題を検知することで、チームは広範なダウンタイムを防ぎ、収益損失を回避し、問題が拡大する前にユーザーの信頼を維持できます。
よくある DNS エラーとその意味
DNS はすべてのウェブリクエストの最初のステップであるため、ここでの小さな問題でも大きな障害につながることがあります。一般的な DNS エラーの種類 を理解することで、チームは根本原因をより早く特定し、ダウンタイムがユーザーに影響を及ぼす前に対応できます。
以下は、最も頻繁に遭遇する DNS 障害とその示す内容です:
1. NXDOMAIN(存在しないドメイン)
このエラーはドメイン名が存在しないか解決できないことを意味します。
主な原因には以下がよくあります:
- ドメインの期限切れまたは未登録
- DNS ゾーンファイルの設定ミス
- DNS レコードや CNAME エントリのタイプミス
ドメインの期限切れはサイトを即座にオフラインにする可能性があり、わずかな設定ミスは特定のサブドメインやサービスだけを壊すことがあります。継続的な DNS 監視 により、特にドメインの更新や設定変更後にこれらの問題を早期に検出できます。
2. SERVFAIL(サーバー障害)
SERVFAIL は、権威ある DNS サーバーがクエリを処理できなかったことを示します。
一般的な原因は:
- 破損または不完全なゾーンファイル
- 不足しているグルーレコード(glue records)
- DNSSEC の検証エラー
SERVFAIL 応答は、システムや設定の更新後に突然現れることが多く、不具合あるデプロイの早期警告サインとなります。リアルタイムの DNS 健康チェック により、これらのサーバーレベル問題が発生した瞬間にチームに通知できます。
3. DNS タイムアウト
タイムアウトは DNS クエリが期待される時間内に応答を受けないときに発生します。
典型的な根本原因には以下が含まれます:
- 過負荷または応答しないネームサーバー
- ネットワーク遅延または接続障害
- DDoS 攻撃によるリゾルバの圧迫
DNS クエリはキャッシュやコンテンツ配信の前に発生するため、わずかな遅延でもページ読み込み時間の増加やユーザー体験の劣化につながる可能性があります。Dotcom-Monitor のような プロアクティブなグローバル DNS 監視 は複数のロケーションからクエリをテストし、顧客が影響を感じる前にこれらの地域的またはプロバイダ特有の遅延を検出します。
DNS を効果的に監視する方法
DNS の健全性 を監視するとは、単にドメインが一度解析されるかを確認する以上のことです。パフォーマンスと信頼性を真に理解するには、監視は実際のユーザーが異なる場所やネットワークでどのようにウェブサイトを体験するかを再現する必要があります。
包括的な DNS 監視 を実装する方法は次のとおりです:
グローバル DNS チェックを実行する
DNS のパフォーマンスは地理的に変動することがあります。ローカルオフィスから即座に解決されるレコードが、anycast ルーティングの問題や地域的なネットワーク障害のために別地域では失敗することがあります。
複数のグローバル拠点から シンセティック監視 エージェント を使用して、実際のクエリをシミュレーションし、ユーザーに影響が及ぶ前に地域特有の問題を検出します。
Dotcom-Monitor のようなツールは マルチリージョン DNS 解決テスト を実行し、遅延のスパイク、クエリの失敗、または記録の不一致をリアルタイムで特定します。
TTL(Time-to-Live)挙動を追跡する
すべての DNS レコードには TTL 値 が含まれ、これはリゾルバが再問い合わせを行う前にレコードをキャッシュする時間を定義します。
長めの TTL はエンドユーザーのパフォーマンスを向上させますが、設定変更や移行後の更新が反映されるまでに時間がかかることがあります。
監視ツールは、更新された値が正しく伝搬されているか、地域間で 古い DNS キャッシュエントリ が残っていないかを検証する必要があります。
異常検出とアラートを設定する
DNS 監視で最も価値のある洞察はトレンド分析から得られます。
- NXDOMAIN や SERVFAIL 応答の急増
- DNS 解決レイテンシの上昇
- 応答時間の地域的不一致
これらはより深刻な問題の初期指標であり、しばしばユーザーの報告よりも数時間前に現れます。自動化された DNS 異常アラート により、チームは即時に対応でき、高い稼働率と迅速な復旧を実現できます。
DNS 監視が適切に実装されていると、根本原因を識別するだけでなく、何が壊れていないかを除外する手助けにもなります。
もし DNS 解決が失敗しているなら、TCP、TLS、HTTP のチェックはそもそも開始されていません。この明確さにより調査範囲が迅速に絞られ、適切なベンダー(DNS ホスティング、レジストラ、ネットワークプロバイダ)に連絡して解決を図ることができます。
TCP 接続障害:ネットワークハンドシェイクが壊れたとき
DNS 解決 が成功して IP アドレスを返した後、リクエストチェーンの次の段階は TCP ハンドシェイク です。これはクライアントとサーバーの間で通信チャネルを確立するデジタルな「握手」です。
このハンドシェイクは単純な三段階のプロセスに従います:
- クライアントが SYN(同期)パケットを送信します。
- サーバーが SYN-ACK(同期確認)で応答します。
- クライアントが ACK を返し、接続が完了します。
このハンドシェイクが完了して初めてブラウザとウェブサーバー間でデータの送受信が開始されます。
TCP が失敗すると、ブラウザはサーバーの場所を知っていても(DNS により)接続できません。結果は ブラックホール のように感じられます:ページは無限に停止し、ソケットは閉じたまま、ユーザーは終わりのないローディングスピナーを見ます。
即時かつ明白なことが多い DNS 障害 と異なり、TCP 接続問題 はしばしば 部分的な障害 を引き起こします;あるユーザーにはサイトが動作しているように見え、別のユーザーには到達不能に見えることがあります。こうした不整合性により、TCP 監視 はウェブパフォーマンスと稼働性の戦略において重要な層となります。
一般的な TCP エラーとその意味
TCP ハンドシェイクが開始されると、クライアントとサーバー間の正常な通信を妨げるいくつかのネットワーク関連障害が発生する可能性があります。これらの TCP エラーの種類を理解することで、どこで接続が途切れているか、どのコンポーネント(ネットワーク、ファイアウォール、アプリケーション)に注目すべきかを迅速に診断できます。
以下は最も一般的な TCP 接続エラーとその典型的な意味です:
1. Connection Refused(接続拒否)
このエラーは、クライアントがターゲットホストに正常に到達したが、期待されるポートでサービスがリッスンしていないことを意味します。
一般的な原因:
- Web またはアプリケーションサービスの予期せぬクラッシュ
- コンテナや VM の終了または再デプロイ
- 負荷分散の設定ミスやポートバインドの誤設定
簡単な例:Web サーバーがポート 443(HTTPS)にバインドされていないと、基盤となるサーバーが稼働していてもサイトは「ダウン」に見えます。
ベストプラクティス: TCP ポート監視を使用して、サービスが正しくバインドされ、すべてのインスタンスでリッスンしていることを確認します。Dotcom-Monitor はポートの可用性を継続的にテストし、サービスが応答を停止したときにチームに通知できます。
2. Connection Timed Out(接続タイムアウト)
TCP タイムアウト は、パケットが目的地までのルート上で失われたりブロックされたりしたときに発生します。
典型的な根本原因は:
- パケットを静かにドロップするファイアウォール
- ネットワーク経路の輻輳や不安定性
- ルーティング設定の誤りや ISP レベルの問題
タイムアウトは特に診断フィードバックを提供しないためフラストレーションを生みます;ユーザーはクライアントが諦めるまでただローディングを見続けます。
ベストプラクティス:ネットワークホップと遅延を追跡するツールを用いた TCP パス監視 を実装してください。Dotcom-Monitor のネットワーク診断はパケットフローを可視化し、タイムアウトが発生している正確な箇所を特定します。
3. Connection Reset(接続リセット)
これは TCP ハンドシェイクが完了したが、その後突然終了したときに発生します。
頻繁な原因には:
- 過負荷のプロキシやサーバーが接続を早期に切断する
- 負荷分散装置の空きタイムアウト設定が厳しすぎる
- WAF 等のセキュリティミドルボックスが疑わしいセッションを拒否する
リセットはしばしば再現が難しい断続的なエラーとして現れ、特に分散アーキテクチャや CDN 環境では追跡が困難です。
ベストプラクティス:継続的な TCP パフォーマンス監視 を使い、リセットのパターンを検出して負荷、セキュリティポリシー、または特定のプロキシ挙動と相関させます。
このようにエラーを分類することで、チームは問題の範囲を迅速に絞り込めます:
- もし TCP が失敗 しているなら、DNS は正常 だが接続が確立できないことを意味します。
- この明確さはトラブルシューティング時間を短縮し、修正をネットワーク、ファイアウォール、またはインフラ運用の正しい担当に導きます。
TCP を効果的に監視する方法
単純な ICMP ping のような基本的な稼働チェックは誤った安心感を生むことがあります。サーバーが ping に応答していても、TCP ハンドシェイク を完了できない場合があり、その場合はユーザーが実際に接続できないことを意味します。
真の TCP 監視 は、実世界の接続挙動を検証し、基本的な ping テストでは見逃される問題を検出します。適切な方法は次のとおりです:
1. ハンドシェイクの検証
有効な TCP 監視は、実際のサービスポート(例:HTTP は 80、HTTPS は 443)での SYN/SYN-ACK/ACK ハンドシェイクの検証から始まります。
これにより、サーバーが単にネットワーク層で「生きている」だけでなく、実際にトラフィックを受け入れるためにリッスンしていることが確認できます。
ベストプラクティス:合成監視ツール(例:Dotcom-Monitor のネットワーク監視)を使用して、完全な TCP ハンドシェイクを自動的に試行し、各サービスエンドポイントがすべてのノードで正しく応答することを確認してください。
2. 地域横断のパス分析
ハンドシェイクの成功は接続パス上のすべてのリンクに依存します。複数の地理的領域からの traceroute や MTR(My Traceroute) を使用して、パケットがデータセンター、CDN エッジ、または上流 ISP のどの地点で遅延または停止しているかを明らかにします。
ベストプラクティス:地域分散された TCP パスチェックを実行し、ルーティングや輻輳の問題を早期に検出します。Dotcom-Monitor のグローバル監視ネットワークは、ユーザーに影響が出る前に地域の異常を特定するのに役立ちます。
3. プロトコルの整合性(IPv4 と IPv6 の監視)
多くの組織は現在 IPv4 と IPv6 の両方をサポートしていますが、実際の障害は一方のプロトコルだけに影響することがあります。IPv4 のみをテストしていると、IPv6 ネットワークで発生するユーザー影響の問題を見逃す可能性があります。
ベストプラクティス:監視構成には常に両方のプロトコルを含めてください。Dotcom-Monitor を使用すると、デュアルスタックチェックを実行して接続タイプ間の一貫性を確保し、パリティ問題を検出できます。
なぜ TCP 監視が重要か
DNS や HTTP チェックに加えた TCP 監視は、サーバーが 実際のトラフィック受け入れ準備ができているか を検証します。もし TCP が失敗しているなら、DNS は解析されているが、ネットワーク接続が確立できないことを意味します。
この洞察により、チームは即座にトリアージできます:
- DNS は正常 → サーバー、ファイアウォール、または負荷分散装置に注目。
- 不必要に開発チームやアプリケーションチームへエスカレーションする必要はありません。
分層化された TCP 監視を導入することで、組織はより速いインシデント対応、ダウンタイムの削減、ネットワーク信頼性の向上を実現します。
TLS/SSL エラー
現代のウェブ環境では、HTTPS はもはやオプションではなくデフォルトです。TCP ハンドシェイクの後、ブラウザとウェブサーバーは接続を保護するために TLS(Transport Layer Security)セッションを開始します。
TLS は二つの重要な役割を果たします:
- 暗号化:ブラウザとサーバー間で送受信されるすべてのデータを傍受から保護します。
- 認証:サーバーが正当であることをデジタル証明書の検証によって確認します。
TLS がないとユーザーは重大なセキュリティやプライバシーのリスクにさらされます。しかし、TLS があっても設定ミスや証明書の期限切れは重大な問題を引き起こす可能性があります。
TLS が失敗すると、ユーザーは 「Your connection is not private」 や 「This site’s certificate is invalid.」 のようなブラウザ警告を見ることになります。これらのメッセージは即座に信頼を損ない、多くの場合ユーザーが先に進むのを阻止します。
したがって、TLS/SSL 監視 は稼働性と信頼性を維持するために不可欠です。1 つの期限切れ証明書が一晩でサイトをダウンさせ、評判を傷つけることがあります。
TLS/SSL エラーが発生する理由
TLS の問題は多くの場合設定ミスや更新忘れに起因します。一般的な原因は:
- 証明書の期限切れ — 期限前に更新されない証明書は即座にセキュリティエラーを引き起こし、アクセスをブロックします。
- ホスト名の不一致 — 例えば www.example.com 用に発行された証明書を api.example.com で使うと検証に失敗します。
- 信頼されていない証明書発行機関(CA) — 証明書が自己署名であるかクライアントにインストールされていないプライベートルートにチェーンされている場合、ブラウザは CA を認識しません。
- ハンドシェイク失敗 — 暗号交渉が失敗することがあり、これはサポートされていない暗号スイート、廃止されたプロトコルバージョン、または不完全な証明書チェーンが原因となることが多いです。
これらのエラーはユーザーの信頼性とアクセス性に影響するため、継続的な TLS 監視が早期検出に不可欠です。
TLS/SSL を効果的に監視する方法
TLS 証明書は徐々に壊れるわけではありません;ある日正常に動作していても次の日にアクセスをブロックする可能性があります。最良の監視アプローチは プロアクティブで自動化されたもの です。
信頼性の高い TLS 監視を実装する方法は次の通りです:
1. 証明書の有効性を追跡する
ドメインやサブドメイン全体の SSL/TLS 証明書の有効期限を監視します。複数のアラート閾値(例:期限 30 日前、7 日前、1 日前)を設定し、期限切れ前に更新が行われるようにします。
2. 完全な証明書チェーンを検証する
不完全または誤設定の証明書チェーンは、主証明書が有効であっても信頼を壊す可能性があります。地域ごとに証明書チェーンを定期的にテストし、CA や中間証明書の問題をユーザーが遭遇する前に検出してください。
3. プロトコルと暗号スイートの互換性をチェックする
ブラウザは古いプロトコル(例:TLS 1.0/1.1)や弱い暗号を段階的に廃止しています。サーバーがまだ廃止された設定に依存している場合、ユーザーは安全に接続できない可能性があります。監視ツールはサポートされる 暗号スイート と プロトコルバージョン を検証するべきです。
4. ハンドシェイク失敗を監視する
TLS ハンドシェイクエラーの急増は、負荷分散器の誤設定、期限切れ中間証明書、またはネットワークレベルの問題を示すことが多いです。
TLS 監視が重要な理由
TLS のエラーは単なる技術的問題ではなく、ビジネスクリティカル です。ユーザーの信頼、ブランドの印象、コンバージョン率に直接影響します。
TLS 監視が証明書やハンドシェイクの問題を早期に警告すれば、チームはユーザーに影響が出る前に迅速に対応できます。
よくある TLS/SSL エラー
TLS(Transport Layer Security)および SSL(Secure Sockets Layer)エラーは、発生時に最も目に見え、評判を損なうウェブ上の問題の一つです。発生するとユーザーは 「Your connection is not private」 や 「This website’s security certificate has expired.」 のようなブラウザ警告に直面し、これらは即座に信頼を損ね、訪問者をサイトから遠ざけます。
以下は最も一般的な TLS/SSL エラー、その原因、および継続的監視が予防に役立つ理由です。
期限切れ証明書
期限切れの SSL 証明書は HTTPS 障害の主要な原因の一つです。証明書は有限の有効期間(通常 90 日から 1 年)で発行されます。期限前に更新されないと、ブラウザはサイトを安全でないと表示しアクセスをブロックします。
なぜ起こるのか:
- 更新の自動化失敗
- 証明書の更新がすべてのサーバーに伝搬しなかった
- 負荷分散器の誤設定やキャッシュ問題
ホスト名不一致
ホスト名不一致は、証明書内のドメイン名がユーザーがアクセスしている URL と一致しない場合に発生します。例えば www.example.com 用に発行された証明書は、api.example.com で使用されると検証に失敗します。
なぜ起こるか:
- 証明書発行後にサブドメインを追加した
- CDN やプロキシの背後にサービスを移動したが証明書を再発行しなかった
- SAN(Subject Alternative Name)の設定ミス
信頼されていない証明書発行機関(CA)
証明書発行機関(CA)がブラウザに認識または信頼されていない場合、ユーザーは「証明書が信頼されていない」という警告を目にします。これは自己署名証明書、内部 CA による発行、または期限切れ・欠落した中間証明書にチェーンされている場合に起こります。
なぜ起こるのか:
- 本番環境で自己署名証明書を使用している
- クライアントデバイスにプライベートルート証明書がインストールされていない
- 中間証明書が欠落または無効
ハンドシェイク失敗
TLS ハンドシェイク失敗は、ブラウザとサーバーが安全に接続する方法で合意できないときに発生します。ハンドシェイクは双方が同じ暗号プロトコルとスイートをサポートしていることを確認します。
なぜ起こるか:
- 廃止されたまたはサポートされていない暗号スイート
- 古い TLS バージョン(例:1.0 または 1.1)の使用
- 証明書チェーンの設定ミスや中間証明書の欠落
TLS ハンドシェイクで二度とサイトが失敗しないようにしましょう
Dotcom-Monitor の TLS/SSL Monitoring を使えば、証明書エラー、ハンドシェイク問題、期限切れ SSL を自動検出し、ユーザーや評判に影響が出る前に対応できます。
TLS を監視する方法
TLS(Transport Layer Security)監視は プロアクティブ、 自動化、継続的 である必要があります。証明書は徐々に壊れるわけではありません;ある日正常で、次の日にアクセスをブロックすることがあります。だからこそ効果的な TLS/SSL 監視 はウェブ監視戦略の重要な部分です。
以下は証明書が予期せぬダウンタイムや信頼問題を引き起こさないようにするための主要な実践事項です:
証明書の有効性と期限を追跡する
証明書は通知なしに期限切れになることがあり、その際ユーザーは即座にブラウザエラーを見ます。これを防ぐために、証明書の期限を継続的に監視し、期限前に適切なアラートを設定してください。理想的には 30 日、7 日、1 日 前に警告を出します。
完全な証明書チェーンを検証する
有効な SSL 証明書は信頼チェーンの完全性に依存します。葉(リーフ)証明書が有効でも、中間証明書が欠落していれば特定のブラウザや地域で信頼が破綻する可能性があります。
複数のグローバルロケーションから 証明書チェーン全体 を定期的に検証し、地域的な不一致を早期に発見してください。
プロトコルと暗号スイートの互換性をチェックする
ブラウザは古いプロトコル(例:TLS 1.0、1.1)を段階的に廃止し、弱い暗号を排除しています。サーバーが廃止された設定に依存していると、ユーザーは安全に接続できないことがあります。
ハンドシェイク失敗とレイテンシを監視する
TLS ハンドシェイクは暗号化通信の基礎です。これが失敗したり遅くなったりするとユーザーは遅延、タイムアウト、接続エラーを経験します。
ハンドシェイクエラーのスパイクは負荷分散器の誤設定、期限切れ中間証明書、または最近の CDN ロールアウトに起因することが多いです。
証明書管理を自動化する
証明書関連の障害を防ぐ最良の方法は自動化です。証明書をコードのように扱い、更新を自動化し、環境間で一貫して展開し、ディスク容量や CPU と同じ積極性で期限を監視してください。
HTTP エラー
DNS、TCP、TLS がそれぞれの役割を正常に完了した後、ブラウザは最終的に Web サーバーへ HTTP リクエスト を送信します。サーバーは、すべてが正常に動作している場合は HTTP ステータスコード 200 OK を返し、問題が発生した場合はエラーコードを返します。
これらの HTTP 応答を監視することは、多くの人が ウェブサイト稼働監視 と聞いて最初に想像することです。しかし、これらの HTTP 応答だけを監視することはウェブ監視の一側面に過ぎません。DNS、TCP、TLS といった前段のレイヤーからの文脈がなければ、HTTP 監視は 何が失敗したか を示すことはできますが、なぜ そうなったかを説明することはできません。だからこそ高度な Web アプリケーション監視 は可用性を超え、パフォーマンス、応答コード、トランザクションの整合性も見る必要があります。
一般的な HTTP エラー
ここでは、ウェブサイトの稼働性とユーザー体験に影響する最も頻繁な HTTP 問題を紹介します:
- 404 Not Found: リクエストされたページやリソースが存在しない。壊れたリンク、削除されたページ、またはルーティングの設定ミスが原因であることが多い。
- 500 Internal Server Error: サーバーが予期しない条件に遭遇した。多くの場合、アプリケーションのバグ、設定ミス、または過負荷プロセスが原因。
- 502 Bad Gateway: プロキシやロードバランサーが上流サーバーから無効な応答を受け取った。分散型やマイクロサービス環境で一般的。
- 503 Service Unavailable: サーバーが一時的にリクエストを処理できない。通常はメンテナンスや容量制限が原因。
- 504 Gateway Timeout: 上流サービスの応答が遅く、ゲートウェイがタイムアウトした。レイテンシ、データベースのボトルネック、または依存関係の遅延を示すことがある。
これらのエラーはユーザーの信頼やコンバージョンに影響し、多くの場合、顧客は原因を知らずに離脱してしまいます。
HTTP を監視する方法
効果的な HTTP 監視 はホームページが読み込めるか確認する以上のことを行います。応答コード、応答時間、トランザクション成功率を検証し、ウェブ体験のすべての層をカバーする必要があります。
主要なベストプラクティスは次の通りです:
- 合成トランザクション: ログイン、カートへの追加、チェックアウト完了などの実際のユーザー操作をシミュレートし、フルワークフローが機能することを確認します。
- 応答コード追跡: 200–299 範囲外の応答を自動でキャプチャしてアラートを上げ、サーバーサイドやアプリケーションレベルの障害を迅速に検出します。
- パフォーマンス閾値: グローバルに応答時間とページ読み込み速度を監視します。サイトが「稼働中」でもパフォーマンスが遅ければユーザーは離れます。
- グローバル監視ロケーション: 複数の地理的リージョンから HTTP チェックを実行し、レイテンシ、CDN 問題、ルーティングのボトルネックを特定します。
HTTP 監視が重要な理由
HTTP を監視することは単に稼働確認をするだけではなく、アプリケーションの健全性とユーザー体験を理解することです。応答が遅い、または一貫性がないサイトはトラフィック、コンバージョン、SEO ランキングを失います。HTTP 監視を DNS、TCP、TLS のチェックと重ねることで、問題の発生源をコード、インフラ、または上流の依存関係のいずれかに絞り込むことができます。
一般的な HTTP エラー
ウェブサイトの稼働性とパフォーマンスを監視する際、HTTP 応答コードは各ユーザーリクエストの結果を示します。これらの一般的な HTTP エラーを理解することで、問題が アプリケーション、サーバー、あるいは 上流依存 のどこにあるかを特定しやすくなります。
- 404 Not Found: リクエストしたリソースやページが存在しないことを示します。通常、断リンク、コンテンツ削除、または URL ルーティングの誤り が原因です。定期的な HTTP 監視 により、これらのエラーを早期に検出し SEO とユーザー信頼を守ることができます。
- 500 Internal Server Error: アプリケーションのバグ、サーバー設定ミス、またはバックエンドプロセスの過負荷により発生する一般的なサーバー側の失敗です。HTTP 応答ログを監視することで、ユーザーに影響が出る前に繰り返し発生する 500 エラーを迅速に特定できます。
- 502 Bad Gateway: プロキシ、CDN、またはロードバランサー が上流サーバーからの無効な応答を受け取ったときに発生します。分散型やマイクロサービス環境で、あるコンポーネントが別のコンポーネントと正しく通信できない場合に一般的です。
- 503 Service Unavailable: サーバーが一時的にリクエストを処理できないことを示し、通常は 計画されたメンテナンス、リソース不足、または トラフィックスパイク に起因します。プロアクティブな監視により、障害の拡大前に過負荷状態を特定して緩和できます。
- 504 Gateway Timeout: 上流サーバーの応答が遅くゲートウェイやプロキシがタイムアウトしたときに発生します。これは レイテンシ、データベースのボトルネック、またはアプリケーションスタック内の依存関係の遅延を示すことがあります。
まとめ:分層化されたエラー監視戦略
現代の ウェブサイト監視 は単なるダウン検知ではなく、サイトがなぜダウンしたのか、どのレイヤーが原因かを理解することにあります。接続シーケンスの各ステップ——DNS、TCP、TLS、および HTTP——はそれぞれ異なる役割を果たし、独立して障害を起こす可能性があります。
すべての障害は順序立って発生します:
- もし DNS が失敗 すれば、接続は成立しません。
- もし TCP が失敗 すれば、DNS 解決は成功しているがネットワークハンドシェイクが完了していません。
- もし TLS が失敗 すれば、暗号化設定や証明書検証が壊れています。
- もし HTTP が失敗 すれば、前段のすべてが成功しており、問題はアプリケーションやサーバー側にあります。
この分層アプローチは、Web パフォーマンスと可用性の問題を診断する際に 明確さと精度 を提供します。
包括的なエラー監視の四つの層
- DNS チェックから始める:ドメインが複数のグローバルロケーションから正しく解決されることを確認します。
- TCP 接続監視を追加する:サーバーが接続要求を受け入れ応答していることを確認します。
- TLS 証明書監視を導入する:SSL 証明書の有効性、ハンドシェイク性能、チェーン信頼を追跡します。
- HTTP 応答監視で締めくくる:実際の稼働性、レイテンシ、応答コードを測定します。
より速い根本原因分析
これらの層に沿って監視を整えることで、チームは正確な故障箇所と修正の担当者を迅速に特定できます:
- DNS エラー? DNS ホスティングプロバイダに連絡してください。
- TCP エラー? ネットワークまたはホスティングプロバイダへエスカレーションしてください。
- TLS エラー? 証明書の有効性やエッジ設定を確認してください。
- HTTP エラー? アプリケーションまたは DevOps チームに通知してください。
漠然とした 「サイトがダウン」 の警告ではなく、実行可能な洞察を得ることで MTTR を短縮し、チーム間の推測を排除できます。
結論
ウェブサイトは単一の方法で故障するのではなく、層ごとに 故障します。すべての障害は接続チェーンの特定のポイント(DNS、TCP、TLS、または HTTP)から始まり、それぞれ固有のリスク、挙動、故障シグネチャを持ちます。
エラー種類別の監視 を採用することで、複雑さを明確さに変え、一般的な 「サイトがダウン」 のアラートを精密で実行可能な洞察に変えることができます。
Dotcom-Monitor のようなツールで強化された堅牢な ウェブサイト監視戦略 により、あなたは単なる稼働データ以上のものを得ます。なぜ サイトがダウンしたのか、どの層 が原因か、そして 誰が 修正すべきかを知ることができます。レジストラ側の DNS 操作が必要な場合でも、ホスティングプロバイダによる TCP タイムアウトであっても、あるいは TLS 証明書の期限切れであっても、ユーザーが気付く前に根本原因を迅速に特定できます。
最終的に、エラーに基づく監視は単にサイトを稼働させ続けることではなく、責任、可視性、速度 に関するものです。次にウェブサイトに問題が生じたときは、不確実さで妥協しないでください。何が壊れたのか、なぜ壊れたのか、そしてどのように自信を持ってそれを解決するかを正確に把握しましょう。
よくある質問
ウェブサイトエラーを種類別に監視するとは、接続プロセスの特定の層(DNS、TCP、TLS、HTTP)に基づいてウェブサイト障害を追跡・分析することを指します。各エラータイプは異なる根本原因を示します:
- DNSエラーはドメイン名解決の問題を示します。
- TCPエラーはネットワーク接続の失敗または遅延を示します。
- TLS/SSLエラーは証明書または暗号化の問題を示します。
- HTTPエラーはウェブサーバーまたはアプリケーションの障害を指摘します。
Dotcom-Monitorのような多層型ウェブサイト監視ツールを使用することで、チームはダウンタイムの発生箇所と原因を特定でき、トラブルシューティング時間を短縮しながらウェブサイトの稼働率、パフォーマンス、信頼性を向上させられます。
マルチレイヤーのウェブサイト監視が不可欠なのは、ウェブサイトが単一の理由だけでダウンするわけではないからです。インターネットスタックの異なるレイヤー全体で障害が発生します。従来の稼働時間チェックでは、サイトが「稼働中」か「停止中」かはわかりますが、その理由はわかりません。
DNS、TCP、TLS、HTTPを横断する階層型監視により、完全な可視性が得られます:
- DNSが失敗すると、ドメインが見つかりません。
- TCPが失敗すると、ネットワークハンドシェイクが破綻します。
- TLSが失敗すると、ユーザーはSSL証明書エラーやブラウザ警告に直面します。
- HTTPが失敗すると、Webアプリケーションまたはサーバーが正常に動作していません。
このアプローチにより、根本原因分析の迅速化、稼働時間監視の改善、ユーザー体験の向上を実現します。これらはすべて、ビジネスに不可欠なWebサイトにとって極めて重要です。
Dotcom-Monitorは、複数のグローバル拠点から実際のユーザー操作を再現する高度なウェブサイトパフォーマンスおよび稼働時間監視ツールを提供します。接続の全レイヤーを継続的にテストし、信頼性を確保します:
- DNS監視:グローバルなドメイン解決速度と可用性を確認します。
- TCP監視:ハンドシェイクの成功を検証し、接続問題を検出します。
- TLS/SSL監視:SSL証明書の有効性、有効期限、暗号化強度を追跡します。
- HTTP監視:稼働時間、ページ速度、エラー応答コードを測定します。
リアルタイムアラートと視覚的診断機能により、Dotcom-MonitorはITおよびDevOpsチームがダウンタイムの正確な原因(DNSタイムアウト、TCP接続問題、TLSハンドシェイク失敗、HTTP 500エラーなど)を特定し、ユーザーやSEOランキングに影響を与える前に解決することを可能にします。
