El monitoreo de API es la práctica continua y automatizada de validar los puntos finales de API para disponibilidad, tiempo de respuesta y corrección de datos — confirmando no solo que un punto final responde, sino que devuelve los datos correctos, en el formato correcto, dentro de una latencia aceptable, desde la perspectiva de los usuarios y los sistemas dependientes.

Las APIs son el tejido conectivo del software moderno. Cada vez que un usuario inicia sesión, realiza un pago o recibe una notificación en tiempo real, se ejecutan múltiples llamadas API detrás de escena — a menudo a través de microservicios, proveedores en la nube y proveedores externos. Cuando esas llamadas fallan o se ralentizan, el impacto es inmediato: flujos de pago interrumpidos, usuarios bloqueados y pérdida de ingresos.
Sin embargo, la mayoría de los equipos solo descubren las fallas de API cuando los clientes las reportan. Sin monitoreo proactivo, el retraso entre la falla y la investigación generalmente se mide en decenas de minutos — tiempo suficiente para exponer riesgos reales de ingresos y SLA antes de que alguien sea alertado.
Esta guía explica qué es el monitoreo de API, cómo funciona, qué métricas seguir, cómo se diferencia del testing de API y APM, y cómo implementarlo — con la precisión que los ingenieros DevOps, SREs y los equipos de QA necesitan para tomar decisiones informadas en producción.
¿Qué es el monitoreo de API?
El monitoreo de API cubre tres capas distintas de validación, en orden de especificidad creciente:
- Monitoreo de disponibilidad — ¿Es alcanzable el punto final? ¿Devuelve una respuesta HTTP sin tiempo de espera?
- Monitoreo de rendimiento — ¿Cuánto tarda la respuesta? ¿Introducen latencia el TTFB, la resolución DNS o el handshake TLS?
- Validación de carga útil — ¿Contiene el cuerpo de la respuesta la estructura de datos esperada? ¿Pasaron las aserciones JSONPath o XPath?
¿Qué es un punto final de API?
Una interfaz de programación de aplicaciones (API) es un conjunto de protocolos y definiciones que permite la comunicación entre sistemas de software. Un punto final de API es la URL específica en la que una API recibe solicitudes y devuelve respuestas — la unidad de observación para el monitoreo de API. Por ejemplo:
POST /v2/auth/token— punto final para emisión de tokenGET /v2/orders/{id}— punto final para recuperación de órdenesPOST /v2/payments/charge— punto final para procesamiento de pagos
Las aplicaciones modernas dependen simultáneamente de docenas o cientos de puntos finales como estos — microservicios internos, pasarelas de pago de terceros, proveedores de identidad, APIs de envío y sistemas CRM. El monitoreo de API mantiene visibilidad en todos ellos.
Tipos de monitoreo de API
No todo monitoreo de API es igual. Comprender las categorías ayuda a los equipos a construir una cobertura que se ajuste tanto a su arquitectura como a sus requisitos de negocios. Los cinco tipos principales aplican a casi todos los equipos; los tipos especializados importan cuando sus condiciones aplican.
Tipos principales
| Tipo | Qué valida | Mejor para |
|---|---|---|
| Monitoreo de tiempo de actividad | Accesibilidad del punto final; códigos de respuesta HTTP; respuesta dentro de la ventana de timeout | SLA de disponibilidad básica; detección inmediata de apagones |
| Monitoreo de rendimiento | Tiempo de respuesta, TTFB, resolución DNS, handshake TCP, tiempo TLS, rendimiento | SLA de latencia, objetivos P95/P99, planificación de capacidad |
| Monitoreo de carga útil / validación | Cuerpo de la respuesta mediante aserciones JSONPath/XPath; corrección de esquema; valores de campos | Detectar fallas silenciosas donde HTTP 200 ≠ datos correctos |
| Monitoreo sintético | Llamadas API simuladas desde ubicaciones globales en intervalos programados, independiente del tráfico real | Detección proactiva; cobertura geográfica; períodos sin tráfico |
| Monitoreo de transacciones multipartes | Secuencias encadenadas de llamadas API (p.ej., autenticación → consulta → envío → confirmación); paso de datos entre pasos | Flujos de comercio electrónico, procesos de inicio de sesión, flujos de órdenes |
Tipos especializados
| Tipo | Qué valida | Mejor para |
|---|---|---|
| Monitoreo de seguridad | Fallos de autenticación, patrones anómalos de solicitudes, expiración de certificados, abuso de límites, repetición de tokens | FinTech, salud; APIs que manejan PII/PHI |
| Revisiones relacionadas con cumplimiento | Validación de versión/cifrado TLS, expiración de certificados, presencia de encabezados de seguridad, pruebas de aplicación de autenticación | Salud, servicios financieros, industrias reguladas |
| Monitoreo de usuario real (RUM) | Interacciones reales de usuarios con API; visibilidad de sesión completa; variación geográfica y de dispositivo real | Comprender el impacto real a usuarios; validar hallazgos sintéticos |
| Monitoreo de versiones y desaprobación | Tasas de adopción de versiones API; picos de error después de cambios de versiones; compatibilidad hacia atrás | Equipos que gestionan múltiples versiones de API simultáneamente |
| Monitoreo de terceros / integraciones | Dependencias de API externas (Stripe, Okta, Salesforce, Twilio); aislar fallos externos vs. internos | Cualquier app que dependa de APIs de terceros para flujos críticos |
Una nota sobre las revisiones relacionadas con cumplimiento: estas proporcionan evidencia de soporte para controles técnicos específicos. El cumplimiento de marcos normativos (HIPAA, PCI DSS, SOC 2) requiere una gobernanza organizacional más amplia más allá de lo que solo el monitoreo puede ofrecer.
Monitoreo sintético vs. monitoreo de usuario real (RUM)
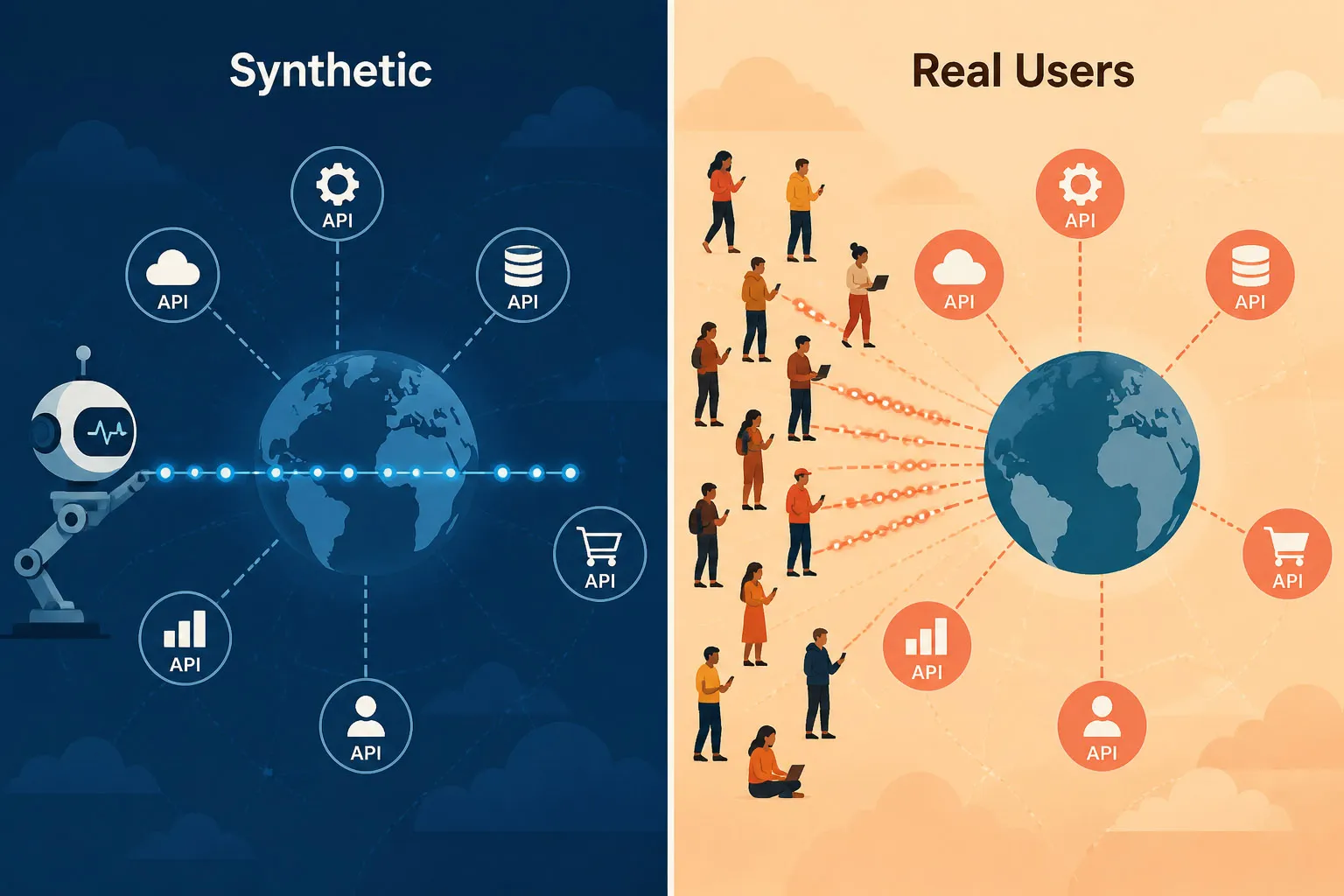
Ambos enfoques proporcionan datos de rendimiento de API, pero desde puntos de vista fundamentalmente diferentes:
| Monitoreo sintético | Monitoreo de usuario real (RUM) | |
|---|---|---|
| Disparador | Chequeos scriptados según un horario (p.ej., cada 1 minuto) | Solicitudes reales de usuarios en producción |
| Cobertura | Funciona 24/7 — incluyendo cuando no hay usuarios reales activos | Solo genera datos cuando los usuarios hacen solicitudes activamente |
| Detección | Proactiva — detecta fallas antes de que impacten a usuarios | Reactiva — revela problemas después que los usuarios ya se ven afectados |
| Alcance | APIs públicas y privadas/internas (vía Private Agent) | APIs alcanzadas por usuarios/clientes reales — principalmente públicas, aunque RUM empresarial también puede capturar llamadas API internas de apps instrumentadas |
| Caso de uso | Validación continua de disponibilidad y rendimiento | Entender el verdadero impacto y experiencia del usuario |
Métricas clave de monitoreo de API
Rastrear las métricas correctas es la diferencia entre una respuesta informada a incidentes y la fatiga por alertas. A continuación, las métricas más importantes — con benchmarks precisos y lo que cada una indica.
| Métrica | Objetivo / Benchmark | Lo que detecta |
|---|---|---|
| Disponibilidad (% de tiempo activo) | ≥ 99.9% (tres nueves); 99.99% para APIs críticas para ingresos | Apagón total, parcial, tiempo de espera |
| Tiempo total de respuesta | < 200ms para puntos simples; < 1s para operaciones complejas | Ralentizaciones del servidor, sobrecarga, regresiones de despliegue |
| Tiempo hasta el primer byte (TTFB) | < 100ms ideal; < 300ms aceptable | Retraso de procesamiento del servidor antes de iniciar la respuesta |
| Tiempo de respuesta P95 / P99 | Alerta en 2× del valor base P95 por punto final; ajuste según comportamiento del punto final | Latencia extrema que afecta al 1–5% de solicitudes más lentas |
| Tasa de errores (4xx / 5xx) | < 0.1% para APIs en producción | Fallos de autenticación, manejo erróneo de entradas, errores de servidor |
| Tiempo de resolución DNS | < 50ms para búsquedas cacheadas en la misma región; interregionales pueden superar 100ms | Problemas de propagación DNS, fallos de resolución |
| Tiempo de handshake TLS | < 100ms | Desconfiguración de certificados, problemas de negociación de versión TLS |
| Tasa de éxito en aserciones de carga útil | 100% (alerta ante cualquier fallo) | Fallas silenciosas: respuestas HTTP 200 con datos incorrectos o ausentes |
| Rendimiento (req/seg) | Comparar contra línea base histórica | Caídas inesperadas o picos anormales de tráfico |
| Expiración de certificado (días restantes) | Alerta a 30 días; crítico a 7 días | Expiración inminente de certificado TLS |
Benchmarks de tiempo de respuesta
¿Cómo funciona el monitoreo de API?
Entender la mecánica técnica ayuda a los equipos a configurar correctamente el monitoreo e interpretar los resultados con precisión.
El ciclo principal de monitoreo
- Programar. Una verificación sintética se ejecuta en un intervalo configurado (p.ej., cada 1 minuto) desde una ubicación global seleccionada.
- Enviar solicitud. El agente de monitoreo envía una solicitud HTTP al punto final destino — incluyendo el método HTTP (GET, POST, PUT, PATCH, DELETE), encabezados, credenciales de autenticación y cuerpo de la solicitud.
- Medir tiempos. El agente registra tiempo de resolución DNS, tiempo de conexión TCP, tiempo de handshake TLS, tiempo hasta el primer byte (TTFB) y tiempo total de respuesta como componentes distintos.
- Aserción. La respuesta se evalúa contra aserciones configuradas — código de estado HTTP, umbral de tiempo de respuesta, encabezados de respuesta y contenido de carga útil vía JSONPath (REST) o XPath (SOAP).
- Alerta o pasa. Si alguna aserción falla, o si la solicitud caduca, se crea un incidente y se envían alertas según las reglas de notificación configuradas.
- Registrar. Todos los resultados — de éxito y fallo — se almacenan con marcas de tiempo, datos de respuesta y resultados de aserciones para análisis históricos y reportes SLA.
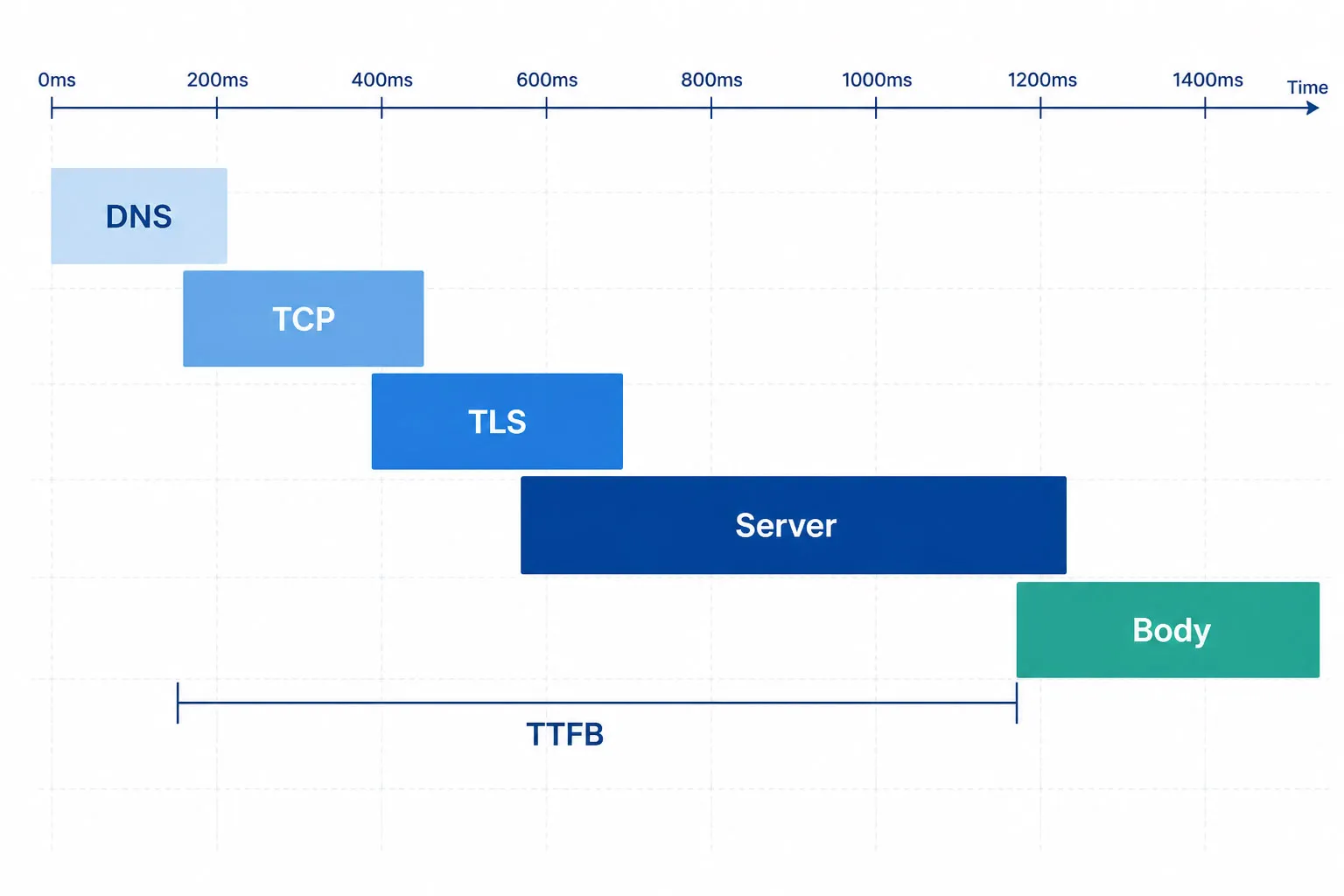
Monitoreo de transacciones de múltiples pasos de API

El monitoreo de un solo punto final confirma que los puntos individuales responden. Pero los recorridos reales de usuarios no son llamadas únicas — son secuencias encadenadas donde cada paso depende de la salida del previo.
Considera un flujo de pago en comercio electrónico:
- Paso 1 —
POST /auth/token: Autenticar usuario; extraeraccess_tokendel cuerpo de respuesta - Paso 2 —
GET /products/{id}: Obtener detalles del producto; inyectar token en encabezadoAuthorization - Paso 3 —
POST /cart/add: Agregar ítem; extraercart_idde la respuesta - Paso 4 —
POST /checkout/initiate: Iniciar pago concart_id; extraercheckout_session_id - Paso 5 —
POST /payments/charge: Procesar pago; afirmar que el campoorder_statusde respuesta sea'confirmed'
En el monitoreo de un solo punto final, los cinco pasos podrían pasar individualmente mientras que la transacción completa falla — porque los datos de sesión no se pasan correctamente entre pasos, un token expira en medio del flujo, o la API de pago devuelve HTTP 200 con un campo de error en la carga útil. El monitoreo multipartes ejecuta toda la cadena como un solo monitor, valida cada paso independientemente y pasa valores dinámicos (tokens, IDs de sesión, IDs de orden) entre los pasos automáticamente.
Dotcom-Monitor habilita el monitoreo de transacciones multipartes encadenando llamadas API secuenciales en una sola tarea de monitoreo. La extracción e inyección de variables entre pasos es automática. Cada paso se aserta de forma independiente, así que las fallas se localizan en el paso exacto donde se rompió la transacción.
Validación de carga útil: aserciones JSONPath y XPath
La validación de carga útil es lo que separa el monitoreo de un simple ping de disponibilidad. Cómo se expresan las aserciones depende de la herramienta, pero la lógica es consistente:
- Acceso a campo JSONPath (REST): Acceder a
$.data.status— luego afirmar que el valor retornado es'active' - Verificación de arreglo JSONPath: Acceder a
$.items— afirmar que la longitud del arreglo es mayor a 0 - Aserción XPath (SOAP):
//order/status/text()— afirmar que el valor del nodo es'confirmed' - Aserción de encabezado: Afirmar que el valor del encabezado
Content-Typees'application/json' - Aserción de tiempo de respuesta: Afirmar que el tiempo total de respuesta es inferior a 500ms
Monitoreo de autenticación
Las APIs en producción requieren autenticación. Una herramienta de monitoreo debe manejar los mismos métodos de autenticación que tus clientes API reales. Los esquemas que una plataforma lista para producción debe soportar:
| Método de autenticación | Descripción | Notas |
|---|---|---|
| OAuth 2.0 — Credenciales de cliente | Máquina a máquina; cliente intercambia credenciales por token directamente | El más común para monitoreo servidor a servidor |
| OAuth 2.0 — Código de autorización | Autorización delegada a usuario; típicamente usado con PKCE para SPAs/apps móviles | Requiere que la herramienta maneje refresco automático de token |
| OAuth 2.0 — Contraseña del propietario recurso (ROPC) | Intercambio directo usuario + contraseña — flujo legado | Usar solo donde Código de autorización no es factible |
| Token portador (JWT) | Token estático o refrescado dinámicamente en encabezado Authorization |
JWTs de vida corta requieren refresco automático |
| Clave API | Clave estática en encabezado, parámetro de consulta o cookie | El más simple para monitorear; vigilar eventos de rotación |
| Autenticación básica | username:password codificado en base64 en encabezado Authorization |
Legado — aún común en APIs internas y empresariales |
| Firma AWS v4 | Solicitud firmada HMAC usando credenciales AWS | Requerido para puntos finales AWS API Gateway |
| mTLS / certificado cliente | TLS mutuo — ambas partes presentan certificados | Entornos de confianza cero; monitoreo crítico de expiración de certificados |
| NTLM / Kerberos | Autenticación integrada Windows/Active Directory | APIs internas empresariales; menos común en stacks nativos de nube |
| Encabezados personalizados | Esquemas de autenticación propietarios vía encabezados personalizados | Para implementaciones no estándar |
La expiración de tokens es una causa principal de falsos positivos en monitoreo. La vida útil de tokens OAuth 2.0 varía ampliamente según implementación y tipo de concesión. Tokens delegados por usuario (flujo Código de autorización) suelen durar entre 15 minutos y 1 hora. Tokens máquina a máquina (flujo Credenciales de cliente) a menudo se configuran para ventanas más largas — 1 a 24 horas — para reducir la sobrecarga de refresco. Entornos de alta seguridad pueden imponer duraciones tan cortas como 5 minutos. Independientemente del intervalo, una herramienta de monitoreo que no maneje refresco automático de tokens generará falsos positivos o requerirá rotación manual de credenciales, creando tanto sobrecarga operativa como riesgo de caídas.
Una nota sobre la concesión implícita de OAuth 2.0: está obsoleta en las mejores prácticas de seguridad actuales (RFC 9700) y no debe usarse en sistemas nuevos. Si tus APIs existentes la usan, se recomienda fuertemente migrar a Código de autorización + PKCE.
Por qué importa el monitoreo de API: impacto en el negocio
Las APIs no son abstracciones de infraestructura — son caminos de ingresos. Cuando fallan, las consecuencias son financieras, operativas y contractuales.
El costo de fallas de API no detectadas
Sin monitoreo proactivo, los equipos dependen de reportes de clientes para detectar fallas. Encuestas industriales colocan el MTTD informado por clientes por arriba de 30 minutos — para cuando se registra, investiga, prioriza y escala una queja, ese tiempo ya pasó. El monitoreo sintético continuo con intervalos de chequeo de 1 minuto acorta la detección a menos de 60 segundos, permitiendo aislar la causa raíz antes de que el problema se agrave.
La fórmula de ingresos es sencilla: órdenes/min × valor promedio por orden × duración del apagón en minutos. Una plataforma que procesa 100 órdenes/min con un valor promedio de $50 pierde $25,000 en ingresos potenciales durante una caída de 5 minutos en la API de pagos. Aplica tu propio volumen y valor para dimensionar tu exposición.
Escenarios específicos por industria
- Comercio electrónico. Una falla en la API de pago durante un pico de tráficos detiene todas las conversiones. Una API de autorización de pago que devuelve HTTP 200 con estado declinado — pero sin alerta — bloquea transacciones silenciosamente por minutos antes que alguien lo note.
- FinTech. Las APIs de procesamiento de transacciones deben cumplir latencias subsegundo. Degradaciones persistentes por encima de umbrales SLA pueden generar penalizaciones contractuales y hallazgos de auditoría bajo PCI DSS.
- Salud. APIs de integración EHR y telemedicina deben mantener intercambio de datos conforme a HIPAA. Una API que devuelve HTTP 200 con datos incompletos del paciente es un evento de cumplimiento — no solo un tema de rendimiento.
- SaaS / API como producto. Cuando tu API es un producto facturable, la indisponibilidad genera penalizaciones contractuales SLA y deserción. El monitoreo provee evidencia documentada para reportes de adherencia SLA.
- IT empresarial. Integraciones API de CRM, ERP, y RRHH en departamentos. Una degradación de Salesforce API puede romper flujos de ventas a nivel organizacional sin que aparezca un solo error 500 en tus logs.
Riesgo de APIs de terceros
Las aplicaciones modernas dependen de APIs externas fuera de su control: pasarelas de pago (Stripe, PayPal, Braintree), proveedores de identidad (Okta, Auth0, AWS Cognito), APIs de envíos y sistemas CRM. Cuando estas se degradan, tu aplicación parece rota para los usuarios aunque tu infraestructura esté sana.
Monitorear puntos finales de terceros permite a los equipos aislar inmediatamente si una falla es interna o externa — una distinción que puede tomar tiempo considerable sin datos previos de monitoreo. También ofrece evidencia documentada para responsabilizar a los proveedores según sus SLA publicados.
Deja de enterarte de fallos de API por tus clientes.
El monitoreo sintético de API de Dotcom-Monitor detecta fallas en menos de 60 segundos y envía alertas directamente a PagerDuty, Slack o Microsoft Teams. Monitorea pasarelas de pago, proveedores de identidad y APIs internas desde una sola plataforma.
Prueba gratis por 30 días → No se requiere tarjeta de crédito
Monitoreo de API vs. Testing de API
Ambas prácticas validan el comportamiento de API, pero sirven para fines distintos en el ciclo de vida de entrega de software. Confundirlos crea brechas de cobertura.
| Dimensión | Testing de API | Monitoreo de API |
|---|---|---|
| Cuándo | Antes de despliegue — desarrollo, QA, pipeline CI/CD | Después de despliegue — de forma continua en producción |
| Entorno | Desarrollo, staging, entorno de pruebas controlado | Producción en vivo, infraestructura real, tráfico real |
| Disparador | Commit de código, build, ejecución manual, puerta PR | Programado (p.ej., cada 1 minuto), continuo 24/7 |
| Objetivo | Prevenir bugs antes de producción | Detectar fallas y degradación en producción |
| Cobertura | Todos los comportamientos, casos límite, rutas de error | Rutas críticas, endpoints SLA, cadenas de jornadas de usuario |
| Perspectiva | De adentro hacia fuera: prueba comportamiento del código | De afuera hacia dentro: valida desde el punto de vista del usuario |
| Salida | Reporte pasa/falla; bloquea despliegue si falla | Alertas en tiempo real, registros de tiempo activo SLA, historial de incidentes |
La relación práctica: el testing de API es una actividad de fase desarrollo. El monitoreo de API es una actividad operacional. El testing detecta bugs antes del despliegue; el monitoreo detecta fallas, regresiones, degradación de rendimiento y problemas de dependencias tras despliegue — bajo condiciones de infraestructura real que difieren de entornos de prueba controlados.
Un equipo de ingeniería maduro ejecuta ambos — y usa importaciones de colecciones Postman para unirlos, convirtiendo tests de desarrollo en monitores de producción sin duplicar definiciones de solicitudes.
Monitoreo de API vs. APM
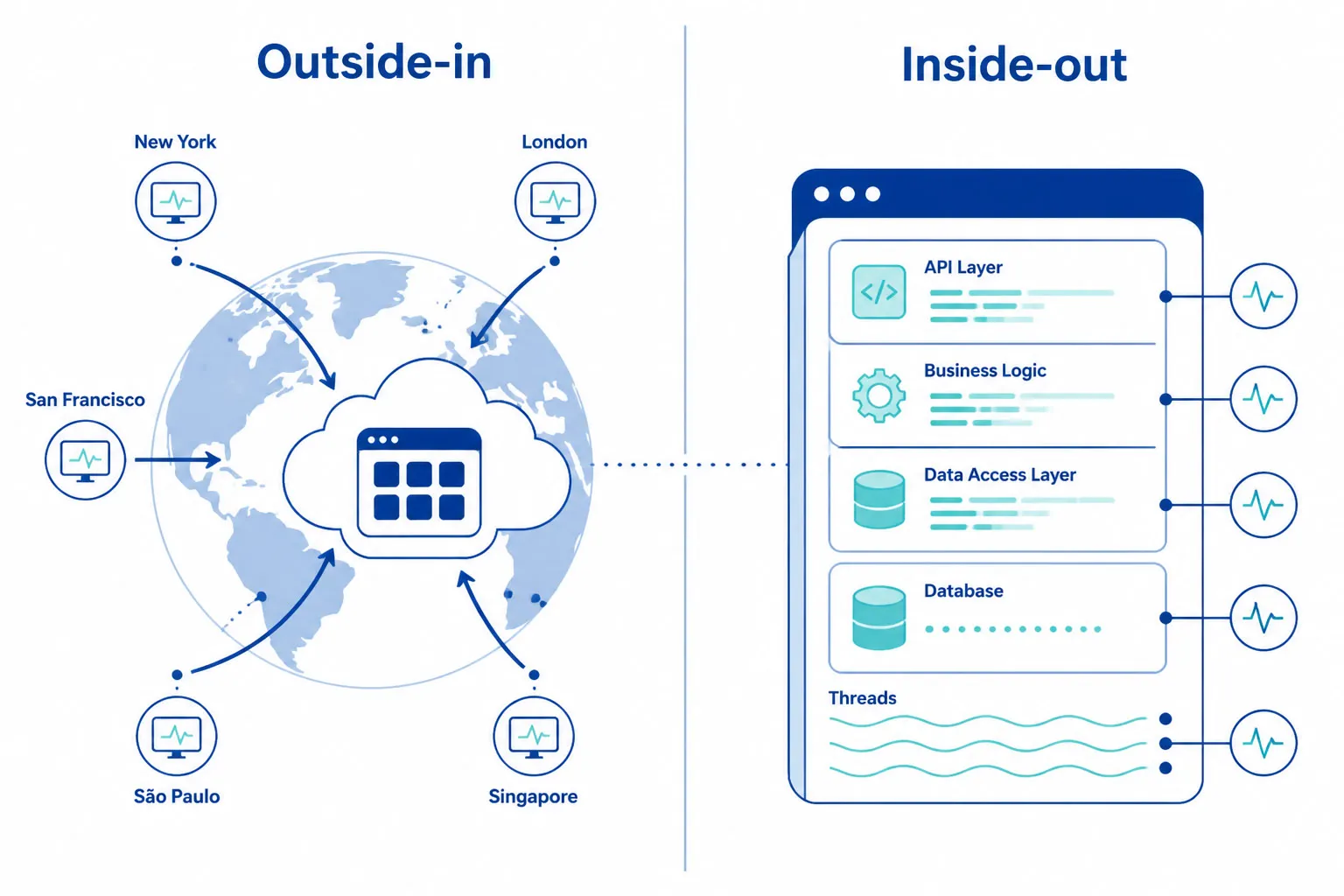
Estas dos categorías frecuentemente se confunden. Son complementarias, no intercambiables.
| Monitoreo sintético de API | APM (Monitoreo de rendimiento de aplicaciones) | |
|---|---|---|
| Perspectiva | De afuera hacia dentro — valida desde la misma vista que usuarios y socios | De adentro hacia afuera — observa comportamiento interno de la app |
| Qué ve | Fallos DNS, problemas de enrutamiento, errores TLS, malas rutas CDN, brechas geográficas | Consultas lentas a DB, fugas de memoria, excepciones de código, llamadas lentas a funciones |
| Cuándo corre | 24/7 — incluso sin tráfico real | Sólo cuando se procesan solicitudes reales |
| Pregunta que responde | “¿Pueden nuestros clientes llamar esta API ahora mismo?” | “¿Qué pasa dentro de nuestra aplicación cuando llega una solicitud?” |
Los equipos de menor MTTR usan ambos: APM para análisis raíz interno, monitoreo sintético para validación externa. Logs y traces responden “¿qué falló en nuestro código?” Monitoreo responde “¿pueden nuestros clientes usar esta API ahora?”
Protocolos de API: REST, SOAP, GraphQL, gRPC y WebSocket
Cada protocolo API tiene requerimientos específicos de monitoreo y modos de falla. Una herramienta que trate todas las APIs como simples solicitudes HTTP GET perderá problemas específicos del protocolo.
Monitoreo de API REST
REST es el protocolo API dominante. El monitoreo valida métodos HTTP (GET, POST, PUT, PATCH, DELETE), códigos de estado, encabezados de respuesta y cuerpos JSON mediante aserciones JSONPath. Requisitos clave: afirmar sobre valores de campos de carga útil — no sólo códigos de estado; monitorear todos los métodos HTTP, no sólo GET (POST, PUT y DELETE activan lógicas servidoras y modos de falla distintos); rastrear tiempo de respuesta por punto final individualmente, no como promedios agregados.
Monitoreo de API SOAP
APIs SOAP intercambian XML sobre HTTP. Requisitos: importación WSDL para definición de punto final y esquema; aserciones XPath en elementos XML de respuesta; soporte de SOAP 1.1 y SOAP 1.2; configuración WS-Security para servicios SOAP empresariales usando seguridad a nivel de mensaje.
Monitoreo de API GraphQL
El desafío clave en GraphQL: la mayoría de servidores GraphQL devuelven HTTP 200 incluso para errores parciales o consultas malformadas. El código HTTP no es una señal de falla confiable. Debes:
- Enviar cargas específicas de consulta y afirmar sobre el objeto
dataen la respuesta - Revisar el array
errorsen el cuerpo — en GraphQL estándar, cada respuesta tiene un campoerrorsopcional a nivel superior que es vacío o ausente en éxito y poblado en fallo. Una respuesta 200 conerrors[]poblado significa falla en capa GraphQL aun si HTTP tuvo éxito - Validar invariantes específicas de consulta: afirmar que campos esperados estén presentes, no nulos y con tipo correcto en el objeto data — algunos sistemas codifican fallas de dominio en data en vez de usar errors
- Monitorear límites de complejidad y profundidad de consulta para detectar degradación de rendimiento antes de que cause timeouts
Monitoreo de API gRPC
gRPC usa Protocol Buffers sobre HTTP/2 por defecto, aunque gRPC-Web soporta HTTP/1.1 vía proxy para clientes navegador. Requisitos: importación de archivo proto para definiciones de servicio y método; soporte para codificación/decodificación binaria de mensajes Protocol Buffer; validación de código de estado usando códigos gRPC (OK, UNAVAILABLE, DEADLINE_EXCEEDED, etc.) — no códigos HTTP; soporte para RPC unario, streaming servidor, cliente y bidireccional.
Monitoreo de API WebSocket
APIs WebSocket mantienen conexiones bidireccionales persistentes para datos en tiempo real. El monitoreo valida tiempo de establecimiento de conexión y éxito de handshake WebSocket, latencia en entrega de mensajes y corrección de carga útil, y estabilidad de conexión en el tiempo incluyendo reconexión tras caídas.
Monitoreo de API públicas vs. APIs internas
 Un Private Agent corre dentro de tu red y realiza conexiones salientes a la plataforma de monitoreo — no se requieren reglas de firewall entrantes. Esto lleva la misma fidelidad de monitoreo a microservicios internos que a APIs públicas.
Un Private Agent corre dentro de tu red y realiza conexiones salientes a la plataforma de monitoreo — no se requieren reglas de firewall entrantes. Esto lleva la misma fidelidad de monitoreo a microservicios internos que a APIs públicas.
La mayoría de guías de monitoreo API se enfocan exclusivamente en puntos finales públicos. Pero en arquitecturas de microservicios, la mayoría de llamadas críticas son internas — llamadas de servicio a servicio que nunca llegan a internet público.
| Monitoreo de API públicas | Monitoreo de API internas | |
|---|---|---|
| Qué cubre | Puntos finales de cara a clientes, APIs de socios, integraciones de terceros | Microservicios internos, VPC privadas, entornos staging, APIs detrás de firewall |
| Cómo funciona | Agentes externos realizan chequeos desde ubicaciones globales vía internet público | Un Private Agent desplegado dentro de tu red inicia conexiones salientes a la plataforma de monitoreo |
| Requisitos de firewall | Ninguno — los chequeos se originan externamente | No se requieren reglas entrantes — el agente solo conecta salientes |
| Qué detecta | Fallos en resolución DNS, problemas de rutas CDN, errores TLS, brechas geográficas de disponibilidad | Fallos inter-servicios, latencia en autenticación, degradación de API de acceso a base de datos |
| Despliegue | No requiere instalación — funciona inmediatamente | Agente instalado on-premise o en nube privada (soporta Windows y Linux) |
Las APIs internas de microservicios son la fuente más común de fallas en cascada. Un servicio de autenticación degradado o una API lenta de acceso a datos genera problemas downstream que se manifiestan como fallos en frontend — dificultando ubicar la causa raíz sin visibilidad interna. Monitorear APIs internas permite a los equipos aislar si la falla está en la capa API, microservicio downstream o base de datos. Aprende más sobre monitoreo con Private Agent detrás de tu firewall.
Mejores prácticas de monitoreo de API
Estas prácticas reducen el tiempo medio de detección (MTTD), mejoran la precisión de alertas y aseguran que la cobertura de monitoreo coincida con el riesgo en producción.
- Monitorea a intervalos de 1 minuto para puntos críticos. Para APIs de pago, autenticación y datos centrales, cada minuto no detectado impacta directamente el negocio. Intervalos de 5 o 15 minutos son aceptables para puntos menos críticos.
- Realiza chequeos desde al menos 5 ubicaciones geográficas distribuidas. Una sola ubicación no detecta fallos regionales DNS, malas configuraciones CDN o problemas geográficos de enrutamiento. Cubre al menos América del Norte, Europa y Asia-Pacífico.
- Valida contenido de carga útil, no solo códigos de estado. Configura aserciones JSONPath para cada punto crítico. Las fallas silenciosas más costosas son APIs que devuelven HTTP 200 con datos incompletos, obsoletos o mal formateados.
- Usa umbrales de alerta derivados de líneas base, no valores estáticos. Establece una línea base de tiempo de respuesta por punto final y alerta al doble del valor P95. Umbrales estáticos generan falsos positivos en picos normales de tráfico.
- Incluye autenticación en tus cadenas de monitoreo. La expiración de tokens, fallas en refresco OAuth y rotación de certificados son causas principales de caídas. Monitorear pasos de auth detecta fallas relacionadas antes que propaguen.
- Crea monitores de transacciones multipartes para cada recorrido crítico. Flujos de inicio de sesión, secuencias de pago y workflows de datos son llamadas API encadenadas. Monitores simples no detectan fallas entre pasos por manejo incorrecto de datos o sesiones.
- Monitorea dependencias de APIs de terceros como monitores separados. Crea monitores dedicados para Stripe, Okta, Salesforce y otros externos. Esto responde de inmediato si la falla es interna o externa.
- Importa colecciones Postman o Insomnia para iniciar el monitoreo. Convierte definiciones existentes en monitores 24/7 sin recrear estructuras de solicitud. Elimina la brecha entre testing en desarrollo y monitoreo en producción.
- Integra chequeos post-despliegue en pipelines CI/CD. Ejecuta chequeos sintéticos API como pruebas humo automáticas tras cada despliegue. Si fallan chequeos post-despliegue, considera rollback o pausa de tráfico en entregas progresivas (blue/green o canary) — usando ejecuciones confirmatorias desde una segunda ubicación para reducir falsos positivos antes de acciones automáticas.
- Dirige alertas a PagerDuty, Slack o Microsoft Teams con políticas de escalamiento. Alertas solo por email generan retraso en detección. Integraciones nativas con herramientas de gestión de incidentes aseguran alertas llegan a la persona correcta inmediatamente, con rutas de escalamiento definidas ante no respuesta.
Desafíos del monitoreo de API
Incluso configuraciones bien diseñadas enfrentan desafíos operacionales. Anticiparlos ayuda a diseñar soluciones a prueba de ellos.
Visibilidad en APIs de terceros
Monitorear dependencias externas te da datos de disponibilidad y latencia pero no puede exponer causa interna de degradación. Cuando Stripe u Okta se ralentizan, puedes confirmarlo y aislar el radio de impacto — pero análisis raíz depende de páginas de estado del proveedor y vías de escalación de soporte.
Limitación de tasa
Los agentes de monitoreo cuentan para límites de tasa de tu API. El volumen sintético total escala como: ubicaciones × chequeos por hora × llamadas API por ejecución × reintentos. Para un monitor simple: 30 ubicaciones × 60 chequeos/hora = 1,800 solicitudes/hora. Para un monitor de 5 pasos a mismos ajustes: 30 × 60 × 5 = 9,000 solicitudes/hora por monitor. Considera esto en el presupuesto de límites de tasa, especialmente para APIs internas con umbrales estrictos. Asegúrate de tener en lista blanca rangos IP de tu proveedor.
Complejidad de autenticación
APIs con tokens de vida corta requieren herramientas de monitoreo que manejen refresco automático. Tokens OAuth 2.0 delegados por usuario (flujo Código autorización) vencen típicamente en 15 minutos a 1 hora; tokens máquina a máquina (flujo Credenciales cliente) duran 1–24 horas; ambientes de alta seguridad pueden exigir ventanas de 5 minutos. Autenticación basada en certificados y rotación de API keys también requieren manejo cuidadoso.
Respuestas dinámicas y no deterministas
APIs que devuelven datos con marca de tiempo, resultados paginados o arreglos en orden aleatorio son difíciles de asertar con igualdad exacta. Usa expresiones JSONPath que validen estructura, presencia y tipo de campos — más que valores exactos que cambian por solicitud.
Fatiga por alertas
Monitoreo excesivo — demasiados puntos a intervalos de 1 minuto o umbrales demasiado ajustados — genera ruido que insensibiliza a equipos. Usa monitoreo escalonado: 1 minuto para rutas críticas, 5–15 minutos para puntos no críticos. Confirma alertas desde una ubicación secundaria antes de notificar para eliminar falsos positivos transitorios.
Diversidad de protocolos
REST, SOAP, GraphQL, gRPC y WebSocket requieren estrategias de aserción diferentes. Una herramienta que solo maneja REST perderá fallas en servicios SOAP y reportará erróneamente errores GraphQL como exitosos porque devuelven HTTP 200.
Cómo configurar el monitoreo de API con Dotcom-Monitor
 Cuando una verificación falla, las alertas se dirigen a tus herramientas de respuesta a incidentes existentes — no a una bandeja de monitoreo que nadie ve.
Cuando una verificación falla, las alertas se dirigen a tus herramientas de respuesta a incidentes existentes — no a una bandeja de monitoreo que nadie ve.
Dotcom-Monitor provee monitoreo sintético de API para REST, SOAP y GraphQL desde más de 30 ubicaciones globales, con intervalos de verificación de 1 minuto, soporte para transacciones multipartes e integraciones nativas con PagerDuty, Slack y Microsoft Teams.
Paso 1 — Define tu punto final y aserciones
- URL del punto final: El API endpoint a monitorear
- Método HTTP: GET, POST, PUT, PATCH o DELETE
- Encabezados de solicitud:
Content-Type,Authorizationy cualquier encabezado personalizado requerido - Cuerpo de la solicitud: Payload JSON para solicitudes POST/PUT
- Autenticación: OAuth 2.0, Bearer Token, API Key, Basic Auth, mTLS, AWS Signature v4, NTLM, Kerberos, o encabezados personalizados
- Aserciones: Código de estado HTTP, umbrales de tiempo de respuesta, valores de encabezado, aserciones de carga JSONPath/XPath
Paso 2 — Importa desde Postman o Insomnia
Si tu equipo usa Postman o Insomnia, evita configurar manualmente puntos finales:
- Postman: Exporta tu colección como JSON v2.0 o v2.1 e importa a Dotcom-Monitor. Se preservan definiciones de solicitudes, encabezados, cuerpo, variables de entorno y aserciones de prueba.
- Insomnia: Exporta tu workspace como JSON v4 de Insomnia e importa a Dotcom-Monitor. Se retienen grupos de solicitudes, configuraciones de auth y variables de entorno.
Ambos formatos convierten tests de desarrollo únicos en monitores programados continuos 24/7 sin reconfiguración.
¿Ya usas Postman? Estás a 5 minutos de monitoreo 24/7 en producción.
Importa tu colección Postman existente directamente a Dotcom-Monitor. Tus definiciones de solicitud, encabezados, variables de entorno y aserciones se conservan — sin necesidad de reconfiguración.
Paso 3 — Configura ubicaciones y frecuencia de monitoreo
- Frecuencia de chequeo: Intervalos de 1, 3, 5 o 15 minutos — establece según criticidad por punto
- Ubicaciones de monitoreo: Selecciona entre más de 30 ubicaciones en Norteamérica, Europa, Asia-Pacífico y Sudamérica
- Private Agent: Para APIs internas o detrás de firewall — despliega agente on-premises o en nube privada (soporta Windows y Linux). El agente inicia conexiones salientes — no se requieren reglas entrantes.
- Reintentos de confirmación: Configura chequeo confirmatorio en ubicación secundaria antes de alertar para eliminar falsos positivos transitorios
Paso 4 — Configura enrutamiento de alertas
- PagerDuty: Dirige alertas críticas directamente a turnos on-call con creación automática y escalamiento de incidentes
- Slack / Microsoft Teams: Publica mensajes de alerta con detalles del punto final, tipo de error y datos de respuesta a canales de operaciones
- Email, SMS, llamada telefónica: Configura preferencias por contacto o equipo
- Webhook: Integra con OpsGenie, ServiceNow o cualquier servicio compatible HTTP
- Configuración de umbrales: Define condiciones para alertas por métrica — tiempo de respuesta, tasa de error, tasa de fallo de aserciones — con niveles de severidad
Paso 5 — Integración en pipeline CI/CD
- REST API de Dotcom-Monitor: Crea, actualiza y activa tareas de monitoreo programáticamente vía llamadas API HTTP desde cualquier sistema CI/CD
- GitHub Actions / Azure DevOps / Jenkins: Añade paso post-despliegue que activa chequeo Dotcom-Monitor, espera resultados y falla pipeline si hay fallos en aserciones
- Validación pre-producción: Ejecuta los mismos chequeos sintéticos contra tu entorno de staging antes de promover builds a producción — detecta regresiones antes que impacten usuarios
Casos de uso de monitoreo de API por industria
| Industria | APIs críticas para monitorear | Requisitos clave de monitoreo |
|---|---|---|
| Comercio electrónico | Puntos finales de checkout, autorización de pago, inventario, envíos, gestión de carrito | Cadenas de transacciones multipartes; intervalos de 1 minuto; aserción de carga útil en estado de confirmación de pago |
| FinTech / Banca | Procesamiento de transacciones, verificación KYC/AML, saldo de cuenta, tasas FX, APIs de transferencias | SLA de latencia sub-200ms; revisiones de cumplimiento para evidencias PCI DSS; validación completa de flujo de autenticación |
| Salud | Integraciones EHR (HL7 FHIR), portales de seguros, endpoints de telemedicina, programación de pacientes | Revisiones de cumplimiento para evidencias HIPAA; validación de carga para integridad de datos; SLA de 99.99% de uptime |
| SaaS | APIs núcleo del producto, endpoints de entrega webhook, APIs de integración de socios, APIs de autenticación | SLA por API como producto; importación Postman para consistencia dev a monitoreo; monitoreo de dependencias externas |
| IT empresarial | Integraciones de CRM, ERP, HRIS, proveedor identidad, automatización interna | Private Agent para APIs detrás de firewall; soporte auth NTLM/Kerberos; visibilidad API cross-departamental |
| Medios / Juegos | APIs CDN para entrega de contenido, autenticación, puntuación en tiempo real, APIs de funciones sociales | Monitoreo de distribución geográfica; monitoreo de conexión WebSocket; detección de picos de tráfico |
Comienza a monitorear tus APIs hoy.
Dotcom-Monitor provee monitoreo sintético de API desde más de 30 ubicaciones globales, con intervalos de verificación de 1 minuto, soporte para transacciones multipartes e integraciones nativas con PagerDuty, Slack y Microsoft Teams. La configuración toma menos de 5 minutos. No se requiere tarjeta de crédito para prueba de 30 días.
