当网站宕机时,往往像是一个黑匣子里的谜团。访客看到的是加载旋转、错误代码或空白页面,但对 IT 团队和 DevOps 工程师来说,第一个问题始终相同:是什么坏了?
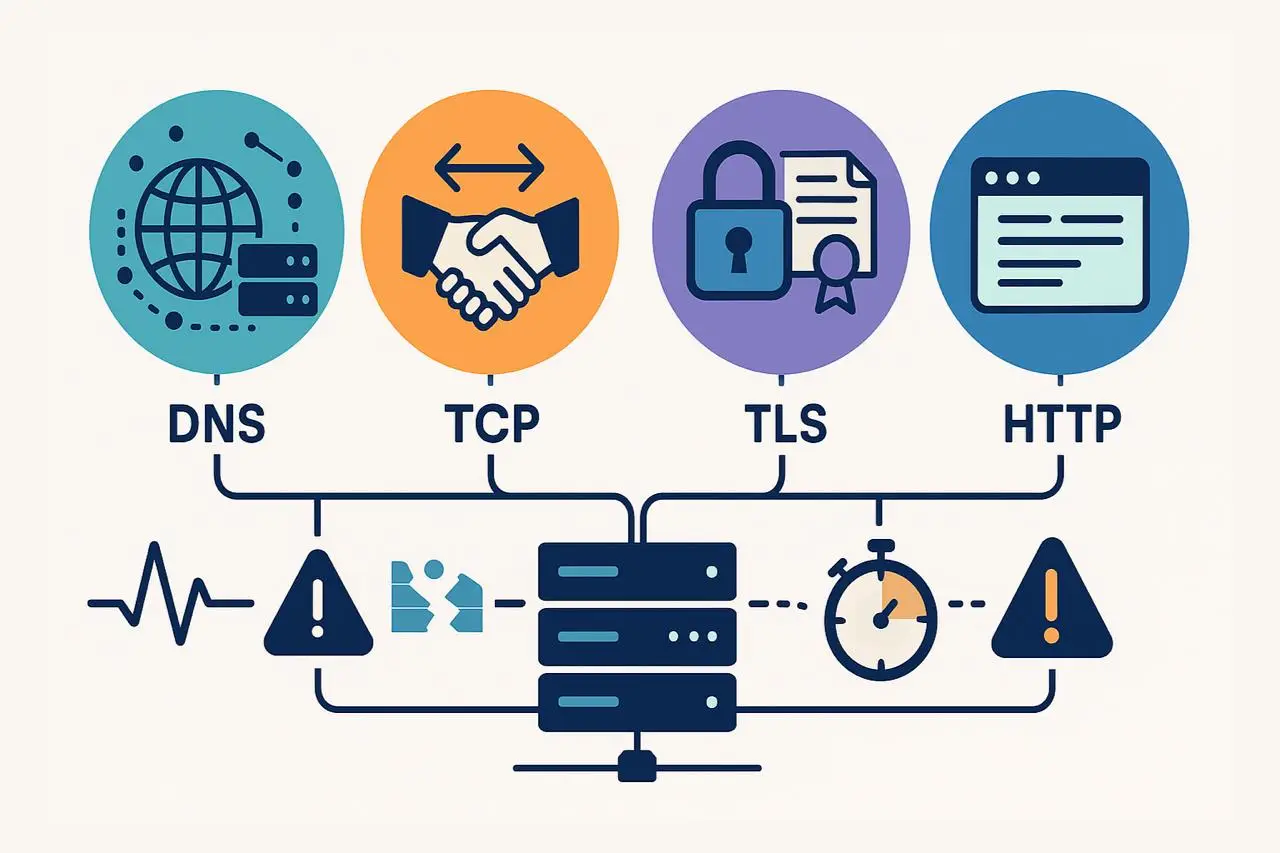
实际上,网站“宕机”并非只有一种方式。每个浏览器请求都会经过多个阶段——DNS 解析、TCP 连接、TLS/SSL 协商和 HTTP 响应——每一层都可能出现故障点。如果链条中的某一环出现故障,用户体验就会整体受影响。
因此,现代网站监控超越了简单的可用性检查。智能监控不仅告诉您网站“宕机”;还会定位问题发生的层级。
- DNS 错误指向域名或解析器问题。
- TCP 故障提示连接或防火墙问题。
- TLS/SSL 错误表示证书或安全相关问题。
- HTTP 5xx 响应揭示服务器端应用错误。
通过识别哪个层失败,团队可以更快响应、降低平均修复时间(MTTR),并在不浪费升级或猜测的情况下解决正确的问题。
DNS 错误:网站故障的第一点
每个网站请求都始于 DNS(域名系统)解析,使其成为网站交付链中最关键的层之一。当用户在浏览器中输入您的域名时,第一步是进行 DNS 查询,将域名转换为告诉浏览器去哪里连接的 IP 地址。
如果这一步失败,其余步骤都无法继续。浏览器不会建立 TCP 连接,也不会验证 TLS/SSL 证书,亦不会收到 HTTP 响应。换言之,DNS 是基础,基础出问题,整个网站就会“断电”。
因此,DNS 监控通常是潜在网站中断的首要且最重要的指标。提前捕捉 DNS 问题,使团队能在问题扩大前防止大面积停机、避免营收损失并维护用户信任。
常见 DNS 错误及其含义
因为 DNS 是每次网站请求的第一步,即便是微小的问题也能导致重大中断。理解常见的 DNS 错误类型 能帮助团队更快定位根因并在停机影响用户前做出响应。
以下是最常见的 DNS 故障及其指示含义:
1. NXDOMAIN(域名不存在)
该错误表示域名不存在或无法解析。
常见原因包括:
- 域名过期或未注册
- DNS 区域文件配置错误
- DNS 记录或 CNAME 条目中的拼写错误
域名过期会立即使网站离线,而小的配置错误可能只影响特定子域或服务。持续的 DNS 监控 有助于在域名续费或配置变更后及早发现这些问题。
2. SERVFAIL(服务器故障)
SERVFAIL 表示权威 DNS 服务器无法处理查询。
常见原因包括:
- 区域文件损坏或不完整
- 缺失的 glue 记录
- DNSSEC 验证错误
SERVFAIL 响应通常在系统或配置更新后突然出现,是有缺陷部署的早期预警信号。实时的 DNS 健康检查 能在这些服务器级别问题出现时立即提醒团队。
3. DNS 超时
当 DNS 查询在预期时间窗口内未收到响应时,就会发生超时。
典型根因包括:
- 名称服务器过载或无响应
- 网络延迟或连通性故障
- DDoS 攻击压垮解析器
由于 DNS 查询发生在缓存或内容交付之前,即便是小的延迟也可能级联为页面加载时间变长并降低用户体验。主动的 全球 DNS 监控(如 Dotcom-Monitor 提供的)从多个位置测试查询,以在客户感知到影响之前检测这些地区性或提供商特定的慢速情况。
如何有效监控 DNS
监控 DNS 健康 不只是验证域名能否解析一次。要真正理解性能与可靠性,监控应模拟真实用户在不同位置与网络下访问您网站的体验。
实施 全面 DNS 监控 的方法如下:
运行全球 DNS 检查
DNS 性能会因地理位置而异。从您本地办公室即时解析的记录可能在其他地区因为 anycast 路由问题 或区域网络中断而失败。
使用来自多个全球位置的 合成监控 代理 来模拟真实世界的查询,并在问题影响用户之前检测特定区域的问题。
像 Dotcom-Monitor 这样的工具执行 多区域 DNS 解析测试,实时识别延迟峰值、查询失败或不一致的记录。
跟踪 TTL(生存时间)行为
每条 DNS 记录都包含一个 TTL 值,定义解析器在重新查询前缓存该记录的时间。
较长的 TTL 可提升终端用户的性能,但会在配置更改或迁移后延迟更新生效。
监控工具应验证更新值是否正确传播,并检查是否在各区域遗留有 陈旧的 DNS 缓存条目。
设置异常检测与警报
DNS 监控最有价值的洞见来源于趋势分析。
- NXDOMAIN 或 SERVFAIL 响应的突然增加
- DNS 解析延迟上升
- 响应时间的地区性不一致
这些是深层问题的早期迹象——通常在用户报告故障前数小时就会出现。自动化的 DNS 异常告警 使团队能够即时反应,确保高可用性并加快恢复速度。
当 DNS 监控正确实施时,它不仅能识别根因,还能排查哪些内容并未出问题。
如果 DNS 解析失败,说明 TCP、TLS 和 HTTP 检查根本未开始执行。这种清晰度能快速缩小调查范围,并帮助团队联系合适的供应商(DNS 托管商、注册商或网络提供商)来解决问题。
TCP 连接失败:当网络握手中断
在 DNS 解析 成功返回 IP 地址后,请求链的下一阶段是 TCP 握手——在客户端与服务器之间建立通信通道的数字“握手”。
该握手遵循一个简单的三步过程:
- 客户端发送一个 SYN(同步)包。
- 服务器回复一个 SYN-ACK(同步确认)包。
- 客户端发送回一个 ACK,完成连接。
只有在握手完成后,浏览器与 Web 服务器之间的数据才能开始传输。
当 TCP 失败 时,浏览器知道服务器在哪里(多亏了 DNS),但无法与之建立连接。结果就像一个 黑洞:页面无限挂起,套接字保持关闭,用户看到无尽的加载动画。
与通常立即且明显的 DNS 故障 不同,TCP 连接问题 常导致 部分宕机:站点对于部分用户可达,而对另一部分用户不可达。这种不一致性使得 TCP 监控 成为任何网站性能与可用性策略的关键层。
常见 TCP 错误及其含义
一旦 TCP 握手开始,就可能发生若干与网络相关的故障,阻止客户端和服务器之间成功通信。理解这些 TCP 错误类型能帮助团队迅速诊断连接断在哪一环,以及需要关注的是网络、防火墙还是应用组件。
下面列出最常见的 TCP 连接错误及其典型含义:
1. Connection Refused(连接被拒)
该错误表示客户端已成功到达目标主机,但在预期端口上没有任何服务在监听。
常见原因包括:
- Web 或应用服务意外崩溃
- 容器或虚拟机被终止或重新部署
- 负载均衡器或端口绑定配置错误
一个简单的示例:Web 服务器未绑定到端口 443(HTTPS)时,即便底层服务器运行正常,该站点仍会显得“宕机”。
最佳实践: 使用 TCP 端口监控确认服务正确绑定并在所有实例上监听。Dotcom-Monitor 可持续测试端口可用性并在服务停止响应时提醒您的团队。
2. Connection Timed Out(连接超时)
当数据包在到达目的地的途中丢失或被阻断时,会发生 TCP 超时。
典型根因包括:
- 防火墙悄然丢弃数据包
- 网络路径拥塞或不稳定
- 路由配置错误或 ISP 级问题
超时尤其令人沮丧,因为它们没有 立即的诊断反馈;用户只是看到加载动画,直到客户端放弃。
最佳实践:实现带有跳数与延迟追踪的 TCP 路径监控。Dotcom-Monitor 的网络诊断可视化数据包流,精确定位超时发生的位置。
3. Connection Reset(连接重置)
当 TCP 握手完成但随后被 突然终止 时会发生此情况。
常见原因包括:
- 代理或服务器过载导致提前关闭连接
- 负载均衡器的空闲超时设置过于激进
- 安全中间设备(例如 WAF)拒绝被判定为可疑的会话
重置通常表现为难以复现的间歇性错误,尤其在分布式架构或 CDN 环境中更难追踪。
最佳实践:使用 持续的 TCP 性能监控 来检测重置模式,并将其与负载、策略或特定代理行为相关联。
通过这样对错误进行分类,团队可以快速缩小问题范围:
- 若 TCP 失败,则说明 DNS 解析正常,但无法建立连接。
- 这份清晰度减少了排查时间,并将修复指向正确的团队(网络、防火墙或基础设施)。
如何有效监控 TCP
像简单的 ICMP ping 这类基本可用性检查常会造成安全感的错觉。服务器可能响应 ping,但仍然无法完成 TCP 握手,这意味着用户无法真正连接到您的网站或应用。
真正的 TCP 监控 更深层次地验证真实世界的连接行为,检测基本 ping 测试无法发现的问题。正确做法包括:
1. 握手验证
有效的 TCP 监控应从验证在实际服务端口(例如 HTTP 的 80 或 HTTPS 的 443)上的 SYN/SYN-ACK/ACK 握手开始。
这确保服务器不仅在网络层“活着”,而且在主动监听流量。
最佳实践:使用合成监控工具(如 Dotcom-Monitor 的网络监控),自动尝试完整的 TCP 握手,并确认每个服务端点在所有节点上都能正确响应。
2. 跨区域路径分析
握手是否成功取决于连接路径上的每一条链路。使用来自多个地理区域的 traceroute 或 MTR(My Traceroute) 可发现数据包在数据中心、CDN 边缘或上游 ISP 的哪个环节变慢或停止。
最佳实践:运行地理分布的 TCP 路径检查,及早检测路由或拥塞问题。Dotcom-Monitor 的全球监控网络能帮助您在影响用户前识别区域异常。
3. 协议并行(IPv4 与 IPv6 监控)
许多组织同时支持 IPv4 与 IPv6,但实际事故可能仅影响其中一种协议。如果您只测试 IPv4,可能会错过发生在 IPv6 网络上的用户可见问题。
最佳实践:在监控配置中始终同时包含两种协议。使用 Dotcom-Monitor,您可以运行双栈检查,确保不同连接类型间的一致性并检测并行问题。
为什么 TCP 监控重要
DNS 或 HTTP 检查与 TCP 监控共同验证服务器是否 准备好接收真实流量,而非仅仅处于开机状态。如果 TCP 失败,说明 DNS 解析成功,但网络连接无法建立。
这一洞察可帮助团队 立即分类故障:
- DNS 正常 → 聚焦服务器、防火墙或负载均衡器。
- 无需不必要地升级到开发或应用团队。
通过实施分层 TCP 监控,组织能获得更快的事件响应、更少的停机时间和更高的网络可靠性。
TLS/SSL 错误
在当今的网络环境中,HTTPS 已非可选而是默认。在 TCP 握手之后,浏览器与 Web 服务器会启动 TLS(传输层安全)会话以保护连接。
TLS 承担两项关键功能:
- 加密:保护浏览器与服务器之间传输的所有数据,防止被窃听。
- 认证:通过验证服务器的数字证书来确认该服务器的合法性。
没有 TLS,用户将面临重大安全与隐私风险。但即便有 TLS,错误配置或证书过期也会导致严重问题。
当 TLS 失败时,用户会看到浏览器警告,例如 “Your connection is not private” 或 “This site’s certificate is invalid.” 这些提示会立即侵蚀信任,在许多情况下会阻止用户继续访问。
因此,TLS/SSL 监控 对于维护可用性与信誉至关重要。单个过期证书可能在一夜之间令网站下线并损害声誉。
为何会发生 TLS/SSL 错误
TLS 问题往往源自配置错误或忘记续期。常见原因包括:
- 证书过期——证书未在到期前续订会立即触发安全错误并阻止访问。
- 主机名不匹配——当证书为某一域名(例如 www.example.com)签发但用于另一域名(例如 api.example.com)时发生。
- 不受信任的证书颁发机构(CA)——浏览器不识别该 CA,可能因为证书为自签名或链至未安装在客户端设备上的私有根证书。
- 握手失败——客户端与服务器之间的加密协商失败,通常由于不支持的加密套件、已弃用的协议版本或不完整的证书链。
这些错误都会影响用户信任与可访问性,因此持续的 TLS 监控对于早期检测至关重要。
如何有效监控 TLS/SSL
TLS 证书并不会逐步失效;它们一天还工作正常,第二天就可能阻断访问。最佳的监控方法是 主动且自动化。
实现可靠 TLS 监控的措施包括:
1. 跟踪证书有效性
监控所有域名与子域的 SSL/TLS 证书到期日。设置多个告警阈值(例如在到期前 30、7、1 天)以确保按时续订。
2. 验证完整证书链
不完整或配置错误的证书链会破坏信任,即便主证书有效。应定期从不同区域测试证书链,以在用户遇到问题前发现 CA 或中间证书问题。
3. 检查协议与加密套件兼容性
随着浏览器逐步弃用旧协议(如 TLS 1.0/1.1)和弱加密,保持兼容性变得至关重要。监控工具应验证支持的 加密套件 与 协议版本,确保用户不会因不兼容而被锁定。
4. 关注握手失败
TLS 握手错误的突然增加通常指示负载均衡器配置错误、过期的中间证书或网络级问题。
为何 TLS 监控很重要
TLS 错误不仅是技术问题;它们是 业务关键 的问题。它们直接影响用户信任、品牌形象和转化率。
当 TLS 监控能及早警告证书或握手问题时,您的团队可以在问题演变为用户可见事件前迅速采取行动。
常见 TLS/SSL 错误
TLS(传输层安全)与 SSL(安全套接层)错误是网站可能面临的最可见且最损害名誉的问题之一。发生时,用户会看到浏览器警告,例如 “Your connection is not private” 或 “This website’s security certificate has expired.” 这些提示会立即破坏信任并可能阻止用户访问网站。
以下是最常见的 TLS/SSL 错误、其成因以及为何持续监控可以预防它们。
证书过期
证书过期是 HTTPS 中断的主要原因之一。证书的有效期有限(通常为 90 天到 1 年)。若在到期前未续订,浏览器会标记网站为不安全并阻止访问。
为何会发生:
- 未对续订进行自动化
- 证书续订未传播到所有服务器
- 负载均衡器配置不当或缓存问题
主机名不匹配
主机名不匹配在证书中的域名与用户访问的 URL 不一致时发生。例如,为 www.example.com 签发的证书在用户访问 api.example.com 时不会被验证通过。
为何发生:
- 在证书签发后新增子域
- 将服务移到 CDN 或代理后未重新签发证书
- SAN(Subject Alternative Name)配置错误
不受信任的证书颁发机构(CA)
如果证书颁发机构(CA)不被浏览器识别或信任,用户会看到“证书不受信任”的警告。通常发生在使用自签名证书、内部 CA 签发或与过期/缺失的中间证书相连时。
为何会发生:
- 在生产环境中使用自签名证书
- 客户端设备上未安装私有根证书
- 缺失或无效的中间证书
握手失败
当浏览器与服务器无法就如何安全连接达成一致时,就会发生 TLS 握手失败。握手过程确保双方支持相同的加密协议与套件。
为何会发生:
- 弃用或不受支持的加密套件
- 使用过时的 TLS 版本(如 1.0 或 1.1)
- 证书链配置错误或中间证书缺失
确保您的网站永远不会因 TLS 握手失败而中断
使用 Dotcom-Monitor 的 TLS/SSL 监控,您可以自动检测证书错误、握手问题和过期的 SSL,在它们影响用户或声誉之前加以处理。
如何监控 TLS
TLS(传输层安全)监控需要 主动、自动化并持续。证书不会逐渐失效;它们今天可能工作正常,明天就可能阻断访问。因此,实施有效的 TLS/SSL 监控 是任何网站监控策略的关键组成部分。
以下是确保证书不会导致意外停机或信任问题的关键做法:
跟踪证书有效期与到期
证书会在没有通知的情况下到期,当发生时,用户会立即看到阻止访问的浏览器错误。为避免这种情况,应持续监控证书到期并在到期前设置告警——理想设置为在到期前 30 天、7 天和 1 天 提醒。
验证完整的证书链
一个有效的 SSL 证书取决于其信任链的完整性。即使叶证书有效,缺失的中间证书也会在特定浏览器或区域造成信任断裂。
应定期从多个全球位置验证 整个证书链,以尽早发现区域性不一致问题。
检查协议与加密套件兼容性
浏览器会逐步淘汰旧协议(例如 TLS 1.0 与 1.1)以及弱加密套件。如果服务器仍依赖这些被弃用的配置,用户可能无法安全连接。
监控握手失败与延迟
TLS 握手是加密通信的基础。如果握手失败或耗时过长,用户会遇到延迟、超时或连接错误。
握手错误的激增通常可追溯到负载均衡器配置错误、过期的中间证书或最近的 CDN 部署。
自动化证书管理
防止证书相关中断的最佳方式是自动化。把证书当作代码来处理:自动续订、在各环境中一致部署更新,并像监控磁盘空间或 CPU 一样积极地监控证书到期。
HTTP 错误
在 DNS、TCP 和 TLS 成功完成各自的工作之后,浏览器最终会向 Web 服务器发送一个 HTTP 请求。当一切正常运行时,服务器会返回一个 HTTP 状态码 200 OK;当出现问题时,则会返回相应的错误代码。
监控这些 HTTP 响应通常是人们想到 网站可用性监控 时的第一印象。但仅监控 HTTP 响应只是可用性监控的一部分。若没有前面各层(DNS、TCP、TLS)的上下文,HTTP 监控可以揭示 发生了什么,但不能解释 为什么。这就是为何高级 Web 应用监控需要超越可用性,关注性能、响应码与事务完整性。
常见 HTTP 错误
以下是影响网站可用性与用户体验的一些常见 HTTP 问题:
- 404 Not Found: 请求的页面或资源不存在。可能由断链、删除的页面或路由配置错误导致。
- 500 Internal Server Error: 服务器遇到意外状况——通常由应用代码缺陷、配置错误或进程过载引起。
- 502 Bad Gateway: 代理或负载均衡器从上游服务器收到无效响应。在分布式或微服务环境中常见。
- 503 Service Unavailable: 服务器暂时无法处理请求,通常由于维护或容量限制。
- 504 Gateway Timeout: 上游服务响应超时,导致请求在返回用户前失败。
这些错误会影响用户信任与转化率,在大多数情况下,您的客户不会知道(或关心)发生了什么——他们只会离开。
如何监控 HTTP
有效的 HTTP 监控 远不止检查首页是否加载。它应验证 响应码、响应时间和事务成功率,覆盖 Web 体验的每一层。
关键最佳实践包括:
- 合成事务:模拟真实用户交互(如登录、加入购物车或完成结账),确保完整工作流可用。
- 响应码跟踪:自动捕获并对任何 200–299 范围外的响应发出告警,以快速发现服务器或应用层故障。
- 性能阈值:全球范围监控响应时间与页面加载速度。即便站点“可用”,性能缓慢也会驱走用户。
- 全球监控位置:从多个地理区域运行 HTTP 检查,识别影响全球受众的延迟、CDN 问题或路由瓶颈。
为何 HTTP 监控重要
监控 HTTP 不只是确认网站在线;它是理解应用健康与用户体验的手段。响应慢或不稳定的网站会损失流量、转化和 SEO 排名。将 HTTP 监控与 DNS、TCP、TLS 检查叠加,您就能全面了解问题起源,是代码、基础设施还是上游依赖导致的。
常见 HTTP 错误(重复节,强调)
在监控可用性与性能时,HTTP 响应码揭示了每个用户请求的结果。理解这些常见 HTTP 错误有助于判断问题是在您的 应用、服务器 还是 上游依赖。
- 404 Not Found: 表示请求的资源或页面不存在。通常由 断链、内容被删除 或 URL 路由错误 引起。定期的 HTTP 监控 有助于提前发现这些错误,维护 SEO 与用户信任。
- 500 Internal Server Error: 一种通用的服务器端失败,常由 应用缺陷、服务器配置错误 或 后端进程过载 引起。监控 HTTP 响应日志可以在它们影响用户前快速识别反复出现的 500 错误。
- 502 Bad Gateway: 当 代理、CDN 或负载均衡器 从上游服务器收到无效响应时发生。在分布式或微服务环境中较为常见,其中一个组件无法正确与另一个组件通信。
- 503 Service Unavailable: 表示服务器临时无法处理请求,通常与 计划内维护、资源耗尽 或 流量峰值 有关。主动监控有助于在故障扩散前识别并缓解过载状况。
- 504 Gateway Timeout: 当上游服务器响应过慢,导致网关或代理超时时发生。这可能表明存在 延迟、数据库瓶颈 或应用栈内依赖变慢的情况。
整合:分层错误监控策略
现代 网站监控 不仅仅是检测停机——它旨在理解 为什么 站点出现故障以及 哪一层 导致了故障。连接序列中的每一步——DNS、TCP、TLS 与 HTTP——都有不同角色,并且可以独立失败。
每次故障的发生顺序为:
- 如果 DNS 失败,则无法建立任何连接。
- 如果 TCP 失败,DNS 解析正常,但网络握手未完成。
- 如果 TLS 失败,则加密设置或证书验证被破坏。
- 如果 HTTP 失败,则前述各层均已成功——问题位于应用或服务器端。
这种分层方法在诊断 Web 性能与可用性问题时提供了 清晰度与精确性。
全面错误监控的四个层次
- 从 DNS 检查开始:验证域名在多个全球位置是否正确解析。
- 添加 TCP 连接监控:确认服务器能接收并响应连接请求。
- 覆盖 TLS 证书监控:跟踪 SSL 证书有效性、握手性能与链信任。
- 以 HTTP 响应监控收尾:测量真实可用性、延迟与响应码。
更快的根因分析
将监控与这些层级对齐,您的团队就能准确定位故障点 —— 并找到正确的负责人来修复它:
- DNS 错误? 联系您的 DNS 托管提供商。
- TCP 错误? 升级到您的 网络或主机提供商。
- TLS 错误? 检查证书有效性或边缘配置。
- HTTP 错误? 通知您的 应用或 DevOps 团队。
与模糊的 “站点宕机” 警报不同,您将获得可执行的洞见,从而减少 MTTR 并消除团队间的猜测。
结论
网站不会单一方式失败;它们是按 层 失败的。每次故障都始于连接链中的某个特定点:DNS、TCP、TLS 或 HTTP。每一层都有其自身的风险、行为特征与故障签名。
通过采用 按错误类型的监控,您可以将复杂性转化为清晰度,把通用的 “网站宕机” 警报变成精确且可操作的洞见。
借助像 Dotcom-Monitor 这样的工具支持的稳健 网站监控策略,您获得的不仅是可用性数据,还有理解。您将知道 为什么 站点宕机、哪一层 引起了问题以及 谁 需要修复它——无论是注册商层面的 DNS 操作、主机商导致的 TCP 超时,还是 TLS 证书过期——都能在用户注意到之前快速定位根因。
归根结底,基于错误的监控不仅关乎保持网站在线;它关乎 责任、可见性与速度。下次您的网站出现问题时,不要满足于不确定性。要确切知道是什么坏了、为什么坏了,以及如何以自信与清晰解决它。
常见问题解答
按类型监控网站错误是指根据连接过程的具体层级(DNS、TCP、TLS或HTTP)来追踪和分析网站故障。每种错误类型揭示不同的根本原因:
- DNS错误表明域名解析存在问题。
- TCP错误表明网络连接失败或速度缓慢。
- TLS/SSL错误指向证书或加密问题。
- HTTP错误揭示Web服务器或应用程序故障。
通过使用Dotcom-Monitor等多层网站监控工具,团队可精准定位停机原因与发生位置,从而提升网站可用性、性能及可靠性,同时缩短故障排查时间。
多层网站监控不可或缺,因为网站故障并非仅由单一原因导致——它们可能发生在互联网协议栈的不同层级。传统正常运行时间检测仅能告知网站是否“在线”或“离线”,却无法揭示故障根源。
通过DNS、TCP、TLS和HTTP的分层监控可实现全面可视化:
- DNS故障导致域名无法解析
- TCP故障导致网络握手中断
- TLS故障引发SSL证书错误及浏览器警告
- 若HTTP层故障,则表明Web应用或服务器运行异常。
这种方法能加速根本原因分析,提升运行时监控精度,优化用户体验——这些对业务关键型网站至关重要。
Dotcom-Monitor 提供先进的网站性能和正常运行时间监控工具,能够从全球多个位置模拟真实用户的交互行为。它持续测试连接的每个层级以确保可靠性:
- DNS监控:检测全球域名解析速度与可用性
- TCP监控:验证握手成功性并检测连接问题
- TLS/SSL监控:追踪SSL证书有效期、过期状态及加密强度
- HTTP监控:测量运行时间、页面速度及错误响应代码
通过实时警报和可视化诊断,Dotcom-Monitor 助力 IT 与 DevOps 团队精准定位停机根源——无论是 DNS 超时、TCP 连接故障、TLS 握手失败还是 HTTP 500 错误——并在影响用户体验或搜索引擎排名前予以解决。
