APIモニタリングは、APIエンドポイントの可用性、応答時間、データの正確性を継続的かつ自動的に検証する行為であり、エンドポイントが応答するだけでなく、ユーザーや依存システムの視点から適切なデータが適切な形式で許容できる遅延内に返されることを確認します。

APIは現代ソフトウェアの結合組織です。ユーザーがログイン、支払いを送信、リアルタイム通知を受け取るたびに、多数のAPI呼び出しが裏で実行されます──しばしばマイクロサービスやクラウドプロバイダー、サードパーティベンダーにまたがって。これらの呼び出しが失敗したり遅延したりすると、影響は即座に現れます:決済フローの破損、ユーザーのロックアウト、収益の損失です。
しかし、多くのチームは顧客の報告でAPI障害を初めて知ります。プロアクティブなモニタリングがなければ、障害から調査までの遅れは通常数十分で計測され、誰もページングされる前に実際の収益やSLAリスクをさらすことになります。
このガイドでは、APIモニタリングとは何か、その仕組み、追跡すべき指標、APIテストやAPMとの違い、実装方法を解説します――DevOpsエンジニア、SRE、QAチームが適切な本番環境の意思決定を行うための正確さで。
APIモニタリングとは?
APIモニタリングは、詳細度が増す3つの検証層をカバーします:
- 可用性モニタリング─ エンドポイントは到達可能か?タイムアウトせずHTTPレスポンスを返すか?
- パフォーマンスモニタリング─ 応答にどれくらい時間がかかるか?TTFB、DNS解決、TLSハンドシェイクが遅延を引き起こしているか?
- ペイロード検証─ レスポンスボディは期待したデータ構造を含むか?JSONPathやXPathのアサーションが合格するか?
APIエンドポイントとは?
API(アプリケーションプログラミングインターフェース)はソフトウェアシステム間の通信を可能にする一連のプロトコルと定義です。APIエンドポイントは、APIがリクエストを受信しレスポンスを返す特定のURLであり、APIモニタリングの観察単位です。例えば:
POST /v2/auth/token─ トークン発行エンドポイントGET /v2/orders/{id}─ 注文取得エンドポイントPOST /v2/payments/charge─ 支払い処理エンドポイント
現代アプリケーションは数十から数百ものこのようなエンドポイントに同時に依存しています──内部マイクロサービス、サードパーティ支払いゲートウェイ、IDプロバイダー、配送API、CRMシステムなど。APIモニタリングはこれらすべての可視性を維持します。
APIモニタリングの種類
すべてのAPIモニタリングは同じではありません。これらの分類を理解することで、チームは自組織のアーキテクチャやビジネス要件に合ったカバレッジを構築できます。基本の5種はほぼすべてのチームに当てはまり、条件が合う場合に専門的な種類が重要になります。
基本タイプ
| 種類 | 検証内容 | 最適用途 |
|---|---|---|
| アップタイムモニタリング | エンドポイントへの到達性;HTTP応答コード;タイムアウト内での応答 | 基本的な可用性SLA;即時障害検知 |
| パフォーマンスモニタリング | 応答時間、TTFB、DNS解決、TCPハンドシェイク、TLS時間、スループット | 遅延SLA、P95/P99ターゲット、容量計画 |
| ペイロード/検証モニタリング | JSONPath/XPathによるレスポンスボディのアサーション;スキーマの正確性;フィールド値 | HTTP 200 ≠ 正しいデータの無音障害検出 |
| 合成モニタリング | グローバルロケーションからスケジュールされた擬似APIコール。実際のトラフィックとは独立。 | プロアクティブ検知;地理的カバレッジ;トラフィックゼロ期間 |
| 多段トランザクションモニタリング | 連鎖したAPI呼び出しシーケンス(例:認証→クエリ→送信→確認);ステップ間のデータ受け渡し | ECフロー、ログインジャーニー、注文ワークフロー |
専門タイプ
| 種類 | 検証内容 | 最適用途 |
|---|---|---|
| セキュリティモニタリング | 認証失敗、異常なリクエストパターン、証明書失効、レート制限の乱用、トークンリプレイ | FinTech、ヘルスケア;PII/PHIを扱うAPI |
| コンプライアンス関連チェック | TLSバージョン/暗号化検証、証明書失効、セキュリティヘッダーの有無、認証強制テスト | 医療、金融、規制業界 |
| 実ユーザーモニタリング(RUM) | 実際のユーザーAPIインタラクション;セッション全体の可視性;実際の地理的・デバイス差異 | 真のユーザー影響把握;合成モニタリング検知の検証 |
| バージョニング&廃止モニタリング | APIバージョン採用率;バージョン変更後のエラー急増;後方互換性 | 複数APIバージョンを同時に管理するチーム |
| サードパーティ/統合モニタリング | 外部API依存(Stripe、Okta、Salesforce、Twilio);外部障害と内部障害の切り分け | クリティカルワークフローに外部APIを使うあらゆるアプリ |
コンプライアンス関連チェックについての注記:これは特定技術制御の証拠を提供します。フレームワーク準拠(HIPAA、PCI DSS、SOC 2)は、モニタリングだけではなく組織全体のガバナンスが広く必要です。
合成モニタリング vs. 実ユーザーモニタリング(RUM)
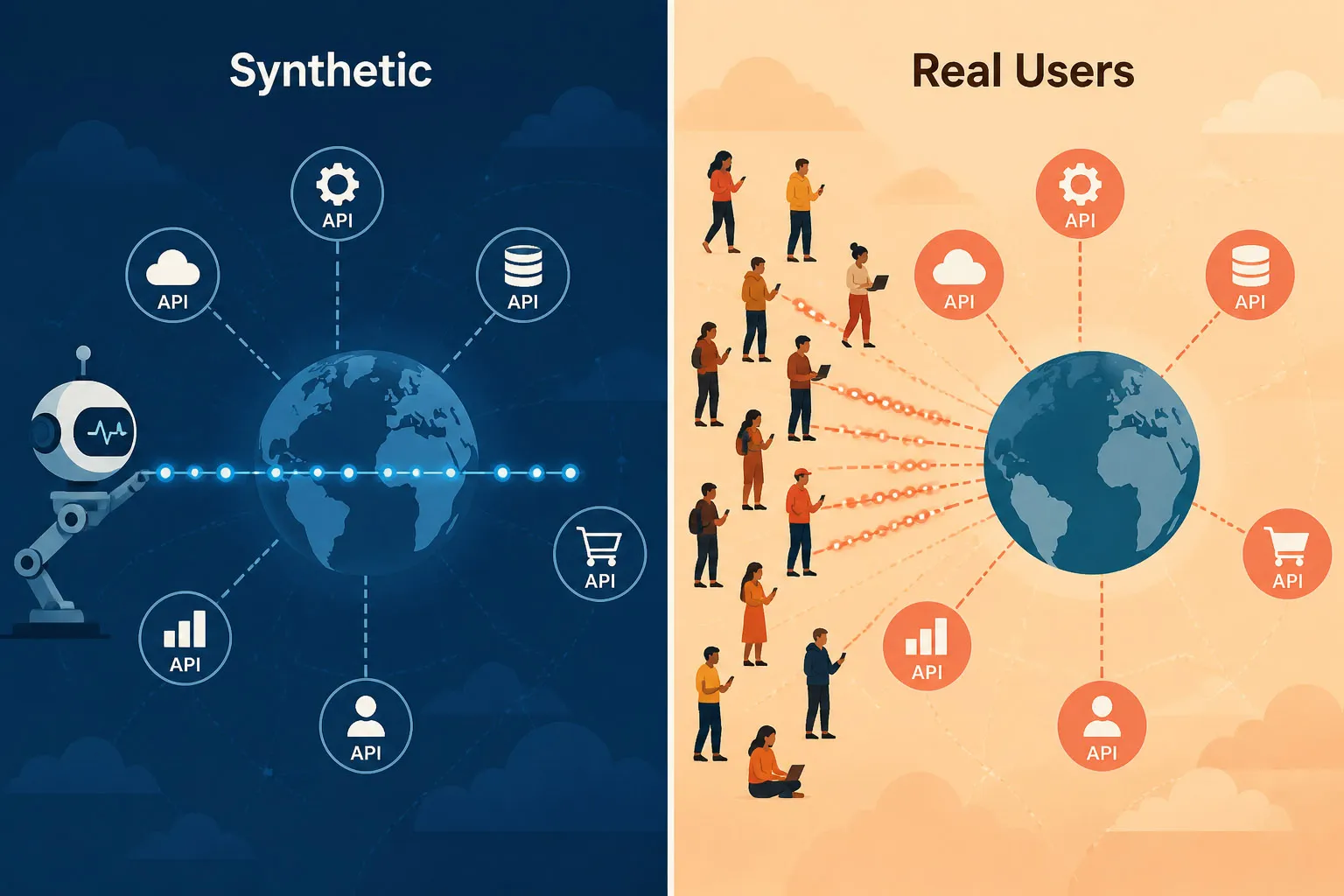
どちらもAPIパフォーマンスデータを提供しますが、視点が根本的に異なります:
| 合成モニタリング | 実ユーザーモニタリング(RUM) | |
|---|---|---|
| トリガー | スケジュールされたスクリプトチェック(例:1分毎) | 本番での実ユーザーのリクエスト |
| カバレッジ | 24時間365日、ユーザートラフィックゼロ時も稼働 | ユーザーが積極的にリクエストしているときのみデータ生成 |
| 検出 | プロアクティブ―ユーザー影響発生前に障害検出 | リアクティブ―ユーザー影響発生後に問題を露呈 |
| 範囲 | パブリック及びプライベート/内部API(プライベートエージェント経由) | 実ユーザー・クライアントがアクセスするAPIが対象。主にパブリック向けだが、エンタープライズRUMは計測済みアプリから内部APIも捕捉可能 |
| ユースケース | 継続的可用性・パフォーマンス検証 | 実際の影響範囲とユーザー体験の理解 |
主要なAPIモニタリング指標
正しい指標を追跡することは、情報に基づくインシデント対応とアラート疲労の違いを生みます。以下は最も重要な指標と正確なベンチマーク、およびそれぞれが示す内容です。
| 指標 | 目標/ベンチマーク | 検出対象 |
|---|---|---|
| 可用性(アップタイム%) | 99.9%以上(三つの9);収益重要APIは99.99% | 全体障害、部分障害、タイムアウト |
| 合計応答時間 | 単純なエンドポイントは200ms未満、複雑な操作は1秒未満 | サーバーの遅延、過負荷、デプロイ後の回帰 |
| TTFB(Time to First Byte) | 理想は100ms未満、許容は300ms未満 | 応答開始前のサーバー処理遅延 |
| P95 / P99応答時間 | エンドポイントごとの基準P95の2倍でアラート。エンドポイントごとの挙動に調整 | 要求の最遅1~5%に影響するテイル遅延 |
| エラー率(4xx / 5xx) | 本番APIは0.1%未満 | 認証失敗、不正入力処理、サーバーエラー |
| DNS解決時間 | 同地域キャッシュ済みは50ms未満、跨地域は100ms超もありうる | DNS伝播問題、リゾルバ失敗 |
| TLSハンドシェイク時間 | 100ms未満 | 証明書設定ミス、TLSバージョン交渉問題 |
| ペイロードアサーション合格率 | 100%(失敗時にアラート) | 無音障害:不正確または欠落データのHTTP 200レスポンス |
| スループット(req/sec) | 過去基準と比較 | 予期しないトラフィックの落ち込みや異常急増 |
| 証明書有効期限(残日数) | 30日でアラート、7日でクリティカル | 迫るTLS証明書の有効期限切れ |
応答時間ベンチマーク
APIモニタリングはどう動作するのか?
技術的な仕組みを理解することで、モニタリングの正しい設定と結果の正確な解釈が可能になります。
コアモニタリングループ
- スケジュール。 設定された間隔(例:1分毎)で合成チェックが選択されたグローバルロケーションから実行される。
- リクエスト送信。 モニタリングエージェントは、HTTPメソッド(GET, POST, PUT, PATCH, DELETE)、リクエストヘッダ、認証情報、リクエストボディを含むHTTPリクエストをターゲットエンドポイントに送信する。
- タイミング計測。 エージェントはDNS解決時間、TCP接続時間、TLSハンドシェイク時間、TTFB、合計応答時間を個別のコンポーネントとして記録する。
- アサート。 レスポンスを設定されたアサーション(HTTPステータスコード、応答時間閾値、レスポンスヘッダ、JSONPath/XPathによるペイロード内容)と照合する。
- アラートまたはパス。 アサーションのいずれかが失敗、またはリクエストがタイムアウトすると、インシデントが作成され、設定された通知ルールに従いアラートが送出される。
- 記録。 合格・不合格の結果はすべて、タイムスタンプ、レスポンスデータ、アサーション結果とともに保存され、履歴トレンドやSLAレポートに使用される。
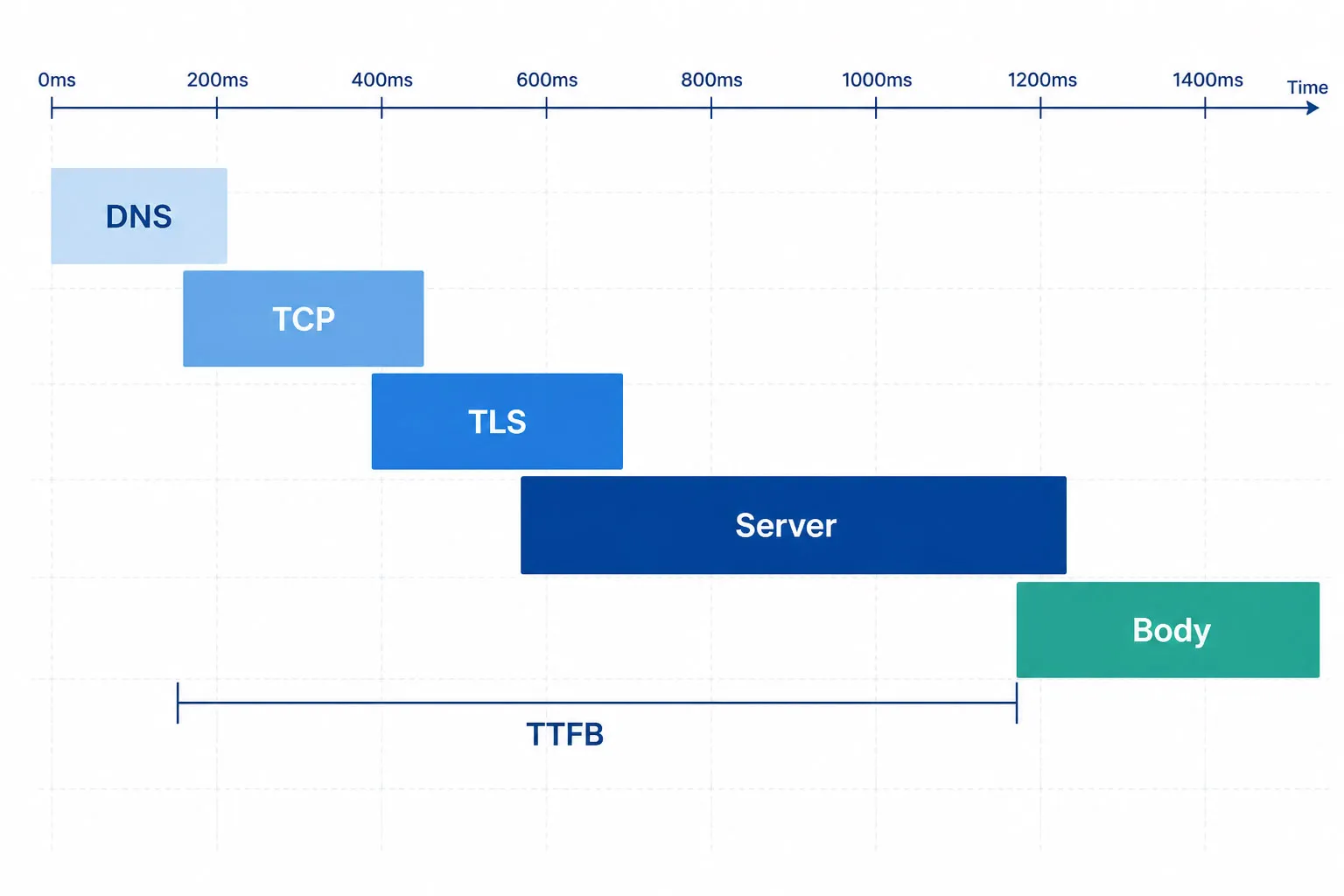 HTTPリクエストを構成するフェーズ。TTFBはDNS、TCP、TLS、サーバー処理をカバーし、ボディ転送は含まれません。TTFBが速くてもボディ転送が遅い場合は大容量ペイロード、TTFBが遅くてボディが速い場合はサーバー処理の遅延を意味します。
HTTPリクエストを構成するフェーズ。TTFBはDNS、TCP、TLS、サーバー処理をカバーし、ボディ転送は含まれません。TTFBが速くてもボディ転送が遅い場合は大容量ペイロード、TTFBが遅くてボディが速い場合はサーバー処理の遅延を意味します。
多段APIトランザクションモニタリング
 実際のユーザージャーニーは単一API呼び出しではありません。多段モニタリングはこれらの呼び出しを連鎖させ、トークンやセッションID、注文IDなどの動的値を自動で渡します。
実際のユーザージャーニーは単一API呼び出しではありません。多段モニタリングはこれらの呼び出しを連鎖させ、トークンやセッションID、注文IDなどの動的値を自動で渡します。
単一エンドポイントのモニタリングは個別の応答を確認しますが、実際のユーザージャーニーは連鎖したステップの連続であり、各ステップが前段のデータに依存します。
例:ECのチェックアウトフロー
- ステップ 1 —
POST /auth/token:ユーザー認証し、応答ボディからaccess_tokenを抽出 - ステップ 2 —
GET /products/{id}:商品詳細取得。Authorizationヘッダにトークンを注入 - ステップ 3 —
POST /cart/add:アイテム追加。レスポンスからcart_idを抽出 - ステップ 4 —
POST /checkout/initiate:cart_idでチェックアウト開始。checkout_session_idを抽出 - ステップ 5 —
POST /payments/charge:支払い処理。レスポンスのorder_statusが'confirmed'であることをアサート
単一エンドポイントのモニタリングでは個別に合格しても、連鎖全体で障害が起こることがあります。セッションデータが正確に引き継がれない、トークンが途中で期限切れ、支払いAPIがエラーフィールドを含むHTTP 200を返す場合などです。多段モニタリングは連鎖全体を単一のモニタで実行し、各ステップを独立してアサートし、ステップ間で動的値を自動的に受け渡します。
Dotcom-Monitorは多段トランザクションモニタリングを提供し、連続したAPI呼び出しを単一タスクでチェーン化します。変数の抽出・注入は自動で、各ステップの障害箇所を正確に特定可能です。
ペイロード検証:JSONPathおよびXPathアサーション
ペイロード検証は単純な可用性チェックと監視を区別します。表現方法はツールにより異なりますが、論理は一貫しています:
- JSONPathフィールドアクセス(REST):
$.data.statusにアクセスし、値が'active'であることをアサート - JSONPath配列チェック:
$.itemsにアクセスし、配列の長さが0より大きいことをアサート - XPathアサーション(SOAP):
//order/status/text()にアクセスし、ノード値が'confirmed'であることをアサート - ヘッダーアサーション:
Content-Typeヘッダー値が'application/json'であることをアサート - 応答時間アサーション: 合計応答時間が500ms未満であることをアサート
認証モニタリング
本番APIは認証を必要とします。モニタリングツールは実環境のAPIクライアントと同じ認証方式に対応する必要があります。本番対応ツールがサポートすべき方式:
| 認証方式 | 説明 | 備考 |
|---|---|---|
| OAuth 2.0 – クライアントクレデンシャル | マシン間通信。クライアントが直接トークンを取得 | サーバー間API監視で最も一般的 |
| OAuth 2.0 – 認可コード | ユーザー委譲認可。SPAやモバイルでPKCEと併用通常 | トークンの自動更新機能が必要 |
| OAuth 2.0 – リソースオーナーパスワード(ROPC) | 直接のユーザー名とパスワード交換。旧来のフロー | 認可コードが使えない場合のみ利用推奨 |
| ベアラートークン(JWT) | Authorizationヘッダーに静的または動的更新トークン | 短命JWTは自動トークン更新が必要 |
| APIキー | ヘッダー、クエリパラメータ、クッキーに静的キー | 最も簡単に監視可能。キー回転に注意 |
| ベーシック認証 | AuthorizationヘッダーにBase64エンコードしたusername:password |
旧方式。エンタープライズや内部APIでまだ多用 |
| AWSシグネチャv4 | AWSクレデンシャルでHMAC署名 | AWS API Gatewayエンドポイントで必須 |
| mTLS / クライアント証明書 | 相互TLS。双方が証明書を提示 | ゼロトラスト環境。証明書失効監視が重要 |
| NTLM / Kerberos | Windows/Active Directory統合認証 | 企業内部APIで利用。クラウドネイティブではやや稀 |
| カスタムヘッダー | 独自認証方式をカスタムヘッダーで実装 | 標準外認証用のオールラウンド |
トークン期限切れはモニタリングの誤検知の主な原因です。OAuth 2.0アクセストークンの寿命は実装や付与タイプにより大きく異なります。ユーザー委譲トークン(認可コードフロー)は通常15分から1時間、マシン間トークン(クライアントクレデンシャル)は1~24時間で設定されることが多く、更新負荷を軽減します。セキュリティの高い環境では5分など短時間に設定されることもあります。いずれにせよ、自動トークン更新を扱わないモニタリングツールは誤検知を生み、操作負荷と障害リスクを増やします。
OAuth 2.0インプリシットグラントは現行のベストプラクティス(RFC 9700)で非推奨です。新規システムでは使用すべきでありません。既存APIで使われていれば認可コード+PKCEへの移行を強く推奨します。
APIモニタリングの重要性:ビジネスへの影響
APIはインフラの抽象ではなく、収益の経路です。失敗すると財務的、運用的、契約上の影響があります。
検知されないAPI障害のコスト
プロアクティブなモニタリング無く、チームは顧客の報告に頼って障害を検知します。業界調査では、顧客報告によるMTTDは常に30分を超えます。報告、調査、絞り込み、エスカレーションの遅れですでに時間が経過しています。1分間隔で継続的な合成モニタリングは検知時間を60秒未満に短縮し、問題が拡大する前に根本原因を特定可能にします。
収益影響はシンプルな数式:分毎注文数 × 平均注文額 × 障害分数。1分間に100注文、平均注文額$50のプラットフォームが5分間支払いAPI障害を起こすと$25,000の潜在損失。実数値でリスクを算出してください。
業界別シナリオ
- EC:ピークトラフィック中のチェックアウトAPI障害は全コンバージョン停止。HTTP 200で却下ステータスを返す支払い承認APIがアラートなしに数分間トランザクションを黙ってブロック。
- FinTech:トランザクション処理APIは1秒未満の遅延SLAが必要。継続的なSLA超過はPCI DSS監査での罰則につながる。
- ヘルスケア:EHR統合APIや遠隔診療エンドポイントはHIPAA準拠が求められ、HTTP 200で患者データが不完全なのは単なるパフォーマンス問題ではなく準拠違反。
- SaaS/API商品:APIが課金商品であれば障害は契約上のSLA違反および顧客離れを招く。モニタリングはSLA遵守報告に必要な有効なアップタイム証拠を提供。
- エンタープライズIT:全社CRM、ERP、HR API統合。Salesforce API劣化はログに500エラーなしに営業ワークフローを社内全体で静かに破壊する。
サードパーティAPIリスク
現代のアプリはStripe、PayPal、Oktaなど制御できない外部APIに依存。これらが劣化すると、自社インフラは正常でもユーザーにはサービス全体が壊れたと見える。
サードパーティのエンドポイントを監視することで、障害が内部か外部かを即座に切り分け可能にし、ベンダーのSLA遵守を担保する証拠も得られます。
顧客からAPI障害を知るのはやめましょう。
Dotcom-Monitorの合成APIモニタリングは60秒以内に障害を検出し、PagerDuty、Slack、Microsoft Teamsに直接アラートを送信。支払いゲートウェイ、IDプロバイダー、内部APIを一元監視。
APIモニタリング vs. APIテスト
両者はAPIの挙動を検証しますが、ソフトウェア開発ライフサイクル内で役割が異なり、混同するとカバレッジの抜けが生まれます。
| 観点 | APIテスト | APIモニタリング |
|---|---|---|
| タイミング | デプロイ前─開発、QA、CI/CDパイプライン | デプロイ後─本番環境で継続的 |
| 環境 | 開発、ステージング、制御されたテスト環境 | 本番環境、実稼働インフラ、実トラフィック |
| トリガー | コードコミット、ビルド、手動実行、PRゲート | スケジュール(例1分毎)、24時間365日継続 |
| 目的 | バグの本番環境流出防止 | 本番での障害・劣化・回帰検知 |
| カバレッジ | すべての挙動、エッジケース、エラーパス | 重要パス、SLA対象エンドポイント、ユーザージャーニーチェーン |
| 視点 | インサイドアウト:コードの挙動をテスト | アウトサイドイン:ユーザー視点で検証 |
| 出力 | 合格/不合格レポート、不合格でデプロイ阻止 | リアルタイムアラート、アップタイムSLA記録、インシデント履歴 |
実務的関係:APIテストは開発段階の作業。APIモニタリングは運用作業。テストはデプロイ前にバグをキャッチ、モニタリングは本番のリアルインフラ条件で障害や性能劣化、依存問題を検知。
成熟した開発チームは両方を運用し、Postmanコレクションインポートで二者を橋渡しし、開発テストを本番監視に変換しリクエスト定義の重複を避けます。
APIモニタリング vs. APM
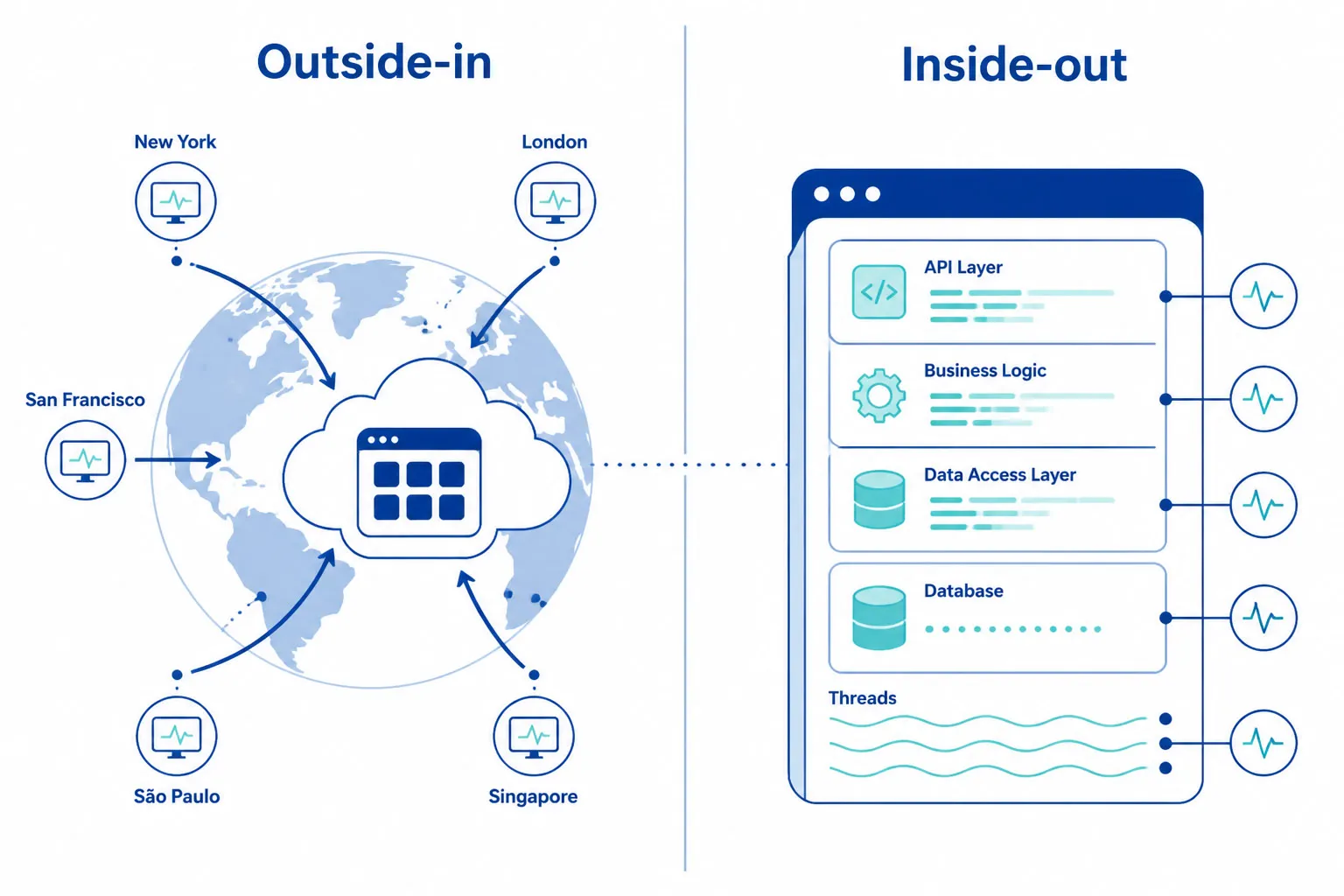 合成APIモニタリングは顧客視点を捉え、APMはコード内部の挙動を観察。両者は相補的であり、代替ではない。
合成APIモニタリングは顧客視点を捉え、APMはコード内部の挙動を観察。両者は相補的であり、代替ではない。
この二つは頻繁に混同されますが、補完関係で代替ではありません。
| 合成APIモニタリング | APM(アプリケーションパフォーマンスモニタリング) | |
|---|---|---|
| 視点 | アウトサイドイン―ユーザーやパートナーと同じ視点 | インサイドアウト―アプリ内部の挙動観察 |
| 検出対象 | DNS障害、ネットワークルーティング、TLSエラー、CDNミスルート、地理的ギャップ | 遅いDBクエリ、メモリリーク、コード例外、遅い関数呼び出し |
| 稼働タイミング | 24時間365日、トラフィックゼロ期も含む | 実リクエスト処理時のみ |
| 回答する質問 | 「顧客はこのAPIを今呼べるか?」 | 「リクエスト時にアプリ内部で何が起こっているか?」 |
MTTRが最も短いチームは両方を使います。APMは内部の根本原因解析に、合成モニタリングは外部からの検証に。ログやトレースは「コードで何が問題か?」に応え、合成は「顧客がAPIを今使えるか?」に応えます。
APIプロトコル:REST、SOAP、GraphQL、gRPC、WebSocket
各APIプロトコルは異なる監視要件と障害モードがあります。すべてのAPIを単純なHTTP GETリクエストとして扱うツールはプロトコル固有の問題を見逃します。
REST APIモニタリング
RESTは主流のAPIプロトコル。監視はHTTPメソッド(GET, POST, PUT, PATCH, DELETE)、ステータスコード、レスポンスヘッダ、JSONレスポンスボディのJSONPathアサーションを検証。重要要件は応答ペイロードのフィールド値をアサートすること(コードだけでなく)、全HTTPメソッドを対象にすること(GET以外はサーバー側ロジックや障害が異なる)、エンドポイントごとに応答時間を個別に追跡すること。
SOAP APIモニタリング
SOAPはHTTP上のXML交換。監視要件はWSDLインポートでエンドポイントとスキーマ定義、XMLレスポンス要素のXPathアサーション、SOAP 1.1と1.2対応、メッセージレベルセキュリティのWS-Security設定。
GraphQL APIモニタリング
GraphQLの主な監視課題は多くのGraphQL実装が部分エラーや不正クエリでもHTTP 200を返すこと。HTTPステータスコードは障害の信頼できる指標になりません。以下が必須:
- 特定のクエリペイロードを送信しレスポンスの
dataオブジェクトをアサート - レスポンスボディの
errors配列をチェック。標準GraphQLでは全レスポンスに任意のトップレベルerrorsフィールドがあり、成功時は空または不在、失敗時に値がある。200応答でerrors[]があればHTTP的成功でもGraphQL層での失敗 - 期待フィールドの存在、非null、型の正確性をデータオブジェクト内で検証。データオブジェクト内にドメイン障害が埋め込まれるケースもある
- クエリの複雑度と深さの制限を監視し、タイムアウト前に性能劣化を検知
gRPC APIモニタリング
gRPCはHTTP/2上のProtocol Buffers。gRPC-WebはHTTP/1.1をプロキシ経由でサポート。監視要件はサービスとメソッド定義のprotoファイルインポート、プロトコルバッファのバイナリエンコード/デコード対応、gRPCステータスコード(OK、UNAVAILABLE、DEADLINE_EXCEEDED等)での検証(HTTPステータスコードではない)、Unary、サーバーストリーミング、クライアントストリーミング、双方向ストリーミングRPCタイプのサポート。
WebSocket APIモニタリング
WebSocketは双方向の持続接続でリアルタイムデータを提供。接続確立時間、ハンドシェイク成功、メッセージ配信遅延、ペイロード正確性、接続の安定性、切断後の再接続挙動などを検証。
パブリックAPIモニタリング vs. 内部APIモニタリング
 プライベートエージェントはネットワーク内からアウトバウンド接続で監視プラットフォームに接続し、インバウンドファイアウォールルール不要。内部マイクロサービスにパブリックAPIと同等の監視忠実度をもたらす。
プライベートエージェントはネットワーク内からアウトバウンド接続で監視プラットフォームに接続し、インバウンドファイアウォールルール不要。内部マイクロサービスにパブリックAPIと同等の監視忠実度をもたらす。
ほとんどのAPIモニタリングガイドはパブリック向けエンドポイントに集中しますが、マイクロサービス構造では重要API呼び出しの多くは内部、サービス間呼び出しで公開インターネットに達しません。
| パブリックAPIモニタリング | 内部APIモニタリング | |
|---|---|---|
| 対象範囲 | 顧客向けエンドポイント、パートナーAPI、サードパーティ統合 | 内部マイクロサービス、プライベートVPC、ステージング環境、ファイアウォール後ろAPI |
| 仕組み | 外部監視エージェントがグローバルロケーションからパブリック回線を通じてチェック | ネットワーク内部に展開したプライベートエージェントがアウトバウンド接続で監視プラットフォームへ送信 |
| ファイアウォール要件 | なし。チェックは外部起点 | なし。エージェントはアウトバウンド接続のみ。インバウンド不要 |
| 検出対象 | DNS障害、CDNルーティング問題、TLSエラー、地理的可用性ギャップ | サービス間障害、認証マイクロサービス遅延、DBクエリAPI劣化 |
| 導入方法 | インストール不要。即利用可 | オンプレまたはプライベートクラウドにエージェント導入(WindowsとLinux対応) |
内部マイクロサービスAPIは連鎖的障害の最も一般的な原因。認証サービス劣化や遅延したデータアクセスAPIはフロントエンド障害として表面化し、根本原因特定が困難。内部API監視によりAPI層、マイクロサービス、DBのどこが問題かを区分可能。詳細は ファイアウォール後ろのプライベートエージェント監視 を参照。
APIモニタリングのベストプラクティス
これらの手法によりMTTD短縮、アラート精度向上、リスクに見合った監視カバレッジが実現します。
- 収益重要エンドポイントは1分間隔で監視。 支払い、認証、コアデータAPIは未検知の1分が直接的なビジネス影響となる。重要度低いエンドポイントは5分または15分で許容。
- 5拠点以上の地理的分散からチェック。 単一拠点では地域DNS障害、CDN設定ミス、地理的ルーティング問題の検知は不十分。最低でも北米、欧州、アジア太平洋の3地域をカバー。
- ステータスコードだけでなくペイロード内容を検証。 重要エンドポイントにJSONPathアサーションを設定。最も高コストの無音障害はHTTP 200レスポンスで不完全・古い・不正データを返すケース。
- 静的な閾値ではなくベースライン由来のアラート閾値を使う。 エンドポイントごとのP95基準値の2倍でアラート設定。静的閾値は通常トラフィックピークで誤検知を生む。
- 認証も監視チェーンに含める。 トークン期限切れ、OAuth更新失敗、証明書ローテーションはAPI障害の主要原因。認証ステップの監視は連鎖的障害検知に効果的。
- 重要なユーザージャーニーは多段トランザクション監視を構築。 ログイン、チェックアウト、データ送信など連鎖するAPI呼び出し。単一エンドポイント監視は不正なデータ受け渡しやセッション不備による階段的障害を検知できない。
- サードパーティAPI依存は専用モニタを設ける。 Stripe、Okta、Salesforce等を個別監視。障害が内部か外部か即時に判別可能。
- PostmanやInsomniaコレクションのインポートを利用。 既存API定義を24/7本番監視に変換し、リクエスト定義の再設定を省略。開発時のテストとモニタリングのギャップを埋める。
- CI/CDパイプラインとAPIチェックを統合。 デプロイ後に自動化された合成APIチェックをスモークテストとして実行。不合格なら自動ロールバックや段階的デリバリー(ブルーグリーン、カナリア)でトラフィック停止。誤検知を減らすため二拠点以上の確認チェックを実施。
- アラートはPagerDuty、Slack、Microsoft Teamsにエスカレーション設定付きで送る。 メールのみは検知遅延の原因。インシデント管理ツールとのネイティブ統合で即時通知と対応者指定、未応答時のエスカレーションを確立。
APIモニタリングの課題
良好な設計でも運用上の課題を抱えることがあります。あらかじめ知り設計に反映しましょう。
サードパーティAPIの可視性
外部依存は可用性や遅延データを得られますが、劣化の根本原因は見えません。StripeやOktaが遅いとわかっても、根本原因分析はベンダーのステータスページやサポート対応に依存。
レート制限
監視エージェントのリクエストもAPIのレート制限に加算されます。総リクエスト数はロケーション数 × 時間あたりチェック数 × 1回のモニタあたりAPI呼び出し回数 × 再試行回数で計算。例:単一エンドポイント監視で30ロケーション、1分間隔(60回/時)の場合、1,800リクエスト/時。5ステップトランザクション監視は単純計算で9,000リクエスト/時。レート制限緩和計画にこれを含め、必要があればモニタリングプロバイダのIPレンジをホワイトリスト化。
認証の複雑性
短命トークンを使うAPIは自動トークン更新対応のモニタリングツールが必要。ユーザー委譲OAuth 2.0(認可コードフロー)は15分~1時間、マシン間トークンは1~24時間、セキュリティ強化環境では5分程度の短時間も。証明書ベースやAPIキーのローテーション管理も慎重に。
動的かつ非決定的なレスポンス
タイムスタンプやページネーション、ランダム順序の配列を返すAPIは、正確値比較によるアサーションが困難です。構造、存在、型を検証するJSONPath表現を用いてください。
アラート疲労
過度の監視―1分間隔で多数エンドポイント監視、または閾値が厳しすぎる設定はノイズを増やし、チームが本当に重要なアラートを見逃すリスクを招く。重要経路には1分、それ以外は5~15分間隔の階層化監視を使い、二次拠点確認で確定アラート化して一過性の誤検知を排除。
プロトコル多様性
REST, SOAP, GraphQL, gRPC, WebSocketはそれぞれ異なるアサーション戦略を必要とします。RESTだけ対応のツールはSOAP障害を見逃し、GraphQLエラーを正しく失敗と判定できません。
Dotcom-MonitorによるAPIモニタリング設定方法
 チェック失敗時にアラートは誰も見ない別モニターボックスではなく、既存のインシデント対応ツールにルーティング。
チェック失敗時にアラートは誰も見ない別モニターボックスではなく、既存のインシデント対応ツールにルーティング。
Dotcom-MonitorはREST、SOAP、GraphQLの合成APIモニタリングを30以上のグローバルロケーションから提供。1分間隔チェック、多段トランザクション、PagerDuty、Slack、Microsoft Teamsとのネイティブ統合をサポート。
ステップ1 – エンドポイントとアサーションを定義
- エンドポイントURL:監視対象のAPIエンドポイント
- HTTPメソッド:GET、POST、PUT、PATCH、DELETE
- リクエストヘッダー:
Content-Type、Authorization、および必要なカスタムヘッダー - リクエストボディ:POST/PUTリクエスト用JSONペイロード
- 認証:OAuth 2.0、ベアラートークン、APIキー、ベーシック認証、mTLS、AWSシグネチャv4、NTLM、Kerberos、カスタムヘッダー
- アサーション:HTTPステータスコード、応答時間閾値、ヘッダー値、JSONPath/XPathペイロードアサーション
ステップ2 – PostmanまたはInsomniaからインポート
チームがPostmanやInsomniaを使っていれば、エンドポイントの手動設定は不要:
- Postman:コレクションをv2.0またはv2.1 JSONでエクスポートし、Dotcom-Monitorにインポート。リクエスト定義、ヘッダー、ボディ、環境変数、テストアサーションが保持される。
- Insomnia:ワークスペースをInsomnia v4 JSONでエクスポートし、Dotcom-Monitorにインポート。リクエストグループ、認証設定、環境変数が維持される。
両方のインポート形式は一度だけの開発テストを24/7本番モニタに変換し、再設定不要。
すでにPostmanを使っているなら、5分で24/7本番監視開始。
既存のPostmanコレクションをDotcom-Monitorに直接インポート。リクエスト定義、ヘッダー、環境変数、アサーションそのまま。再設定不要。
ステップ3 – 監視ロケーションと頻度を設定
- チェック頻度:1、3、5、15分間隔から選択。エンドポイントの重要度に応じて設定。
- 監視ロケーション:北米、欧州、アジア太平洋、南米を含む30以上のロケーションから選択。
- プライベートエージェント:内部またはファイアウォール背後のAPI向けに、オンプレまたはプライベートクラウドに導入(Windows、Linux対応)。エージェントはアウトバウンド接続のみ。インバウンドルール不要。
- 再試行確認:アラート発生前に二次拠点確認を設定し、ネットワークの一過性誤検知を排除。
ステップ4 – アラートルーティング設定
- PagerDuty:重大アラートをオンコールスケジュールに直接送信し、自動インシデント作成とエスカレーションを設定。
- Slack / Microsoft Teams:エンドポイント詳細、エラー種別、レスポンスデータを含む警告メッセージをオペレーションチャネルに投稿。
- メール、SMS、電話:個別連絡先やチームごとに通知設定可能。
- Webhook:OpsGenie、ServiceNow、HTTP対応任意サービスと連携可能。
- 閾値設定:指標ごとにアラート条件を設定(応答時間、エラー率、アサーション失敗率)し、重大度レベルも設定。
ステップ5 – CI/CDパイプライン連携
- Dotcom-Monitor REST API:HTTP API経由で任意のCI/CDシステムから監視タスクの作成、更新、トリガーが可能。
- GitHub Actions、Azure DevOps、Jenkins:デプロイ後のステップにDotcom-Monitorのチェック実行を追加。結果待ちし、アサーション失敗でパイプライン失敗。
- プレプロダクション検証:本番昇格前にステージング環境での同一合成チェック実行。ユーザー影響前に回帰検知。
業界別APIモニタリングユースケース
| 業界 | 監視対象の重要API | 主要監視要件 |
|---|---|---|
| EC | チェックアウト、支払い承認、在庫、配送、カート管理 | 多段トランザクションチェーン;1分間隔;支払い確認ステータスのペイロード検証 |
| FinTech / 銀行 | 取引処理、KYC/AML検証、口座残高、為替レート、送金API | 200ms未満の遅延SLA;PCI DSS証拠サポートのコンプライアンスチェック;完全認証フロー検証 |
| ヘルスケア | EHR統合(HL7 FHIR)、保険ポータル、遠隔診療エンドポイント、患者スケジューリング | HIPAA証拠をサポートするコンプライアンスチェック;データ完全性のためのペイロード検証;99.99%アップタイムSLA |
| SaaS | コアプロダクトAPI、Webhook配信エンドポイント、パートナー統合API、認証API | 製品としてのAPIのSLA遵守;Postmanインポートによる開発と監視の整合;サードパーティ依存監視 |
| エンタープライズIT | CRM、ERP、HRIS、IDプロバイダー、内部ワークフロー自動化API | ファイアウォール背後API用プライベートエージェント;NTLM/Kerberos認証対応;部門横断のAPI可視化 |
| メディア/ゲーム | CDNコンテンツ配信API、認証、リアルタイムスコアリング、ソーシャル機能API | 地理的分散監視;WebSocket接続監視;トラフィック急増検知 |
今日からAPI監視を始めましょう。
Dotcom-Monitorは30以上のグローバルロケーションから合成API監視を提供。1分間隔チェック、多段トランザクションサポート、PagerDuty、Slack、Microsoft Teamsのネイティブ統合。設定は5分以内。30日間無料トライアル、クレジットカード不要。
