API-Überwachung ist die kontinuierliche, automatisierte Praxis, API-Endpunkte auf Verfügbarkeit, Antwortzeit und Datenkorrektheit zu validieren — um nicht nur zu bestätigen, dass ein Endpunkt antwortet, sondern dass er die richtigen Daten im richtigen Format innerhalb akzeptabler Latenz aus der Perspektive von Nutzern und abhängigen Systemen zurückgibt.

APIs sind das verbindende Gewebe moderner Software. Jedes Mal, wenn sich ein Nutzer anmeldet, eine Zahlung abschickt oder eine Echtzeit-Benachrichtigung erhält, werden hinter den Kulissen mehrere API-Aufrufe ausgeführt — häufig verteilt auf Microservices, Cloud-Anbieter und Drittanbieter. Wenn diese Aufrufe fehlschlagen oder sich verlangsamen, ist die Auswirkung unmittelbar: unterbrochene Checkout-Prozesse, ausgesperrte Nutzer und verlorene Einnahmen.
Doch die meisten Teams entdecken API-Ausfälle erst, wenn Kunden sie melden. Ohne proactive Überwachung wird die Verzögerung zwischen Ausfall und Untersuchung typischerweise in zehn Minuten gemessen — lang genug, um echte Umsatz- und SLA-Risiken auszusetzen, bevor jemand alarmiert wird.
Dieser Leitfaden erklärt, was API-Überwachung ist, wie sie funktioniert, welche Metriken zu verfolgen sind, wie sie sich von API-Tests und APM unterscheidet und wie man sie implementiert — mit der Präzision, die DevOps-Ingenieure, SREs und QA-Teams benötigen, um fundierte Produktionsentscheidungen zu treffen.
Was ist API-Überwachung?
API-Überwachung umfasst drei verschiedene Validierungsebenen in aufsteigender Spezifität:
- Verfügbarkeitsüberwachung — Ist der Endpunkt erreichbar? Gibt er eine HTTP-Antwort ohne Zeitüberschreitung zurück?
- Leistungsüberwachung — Wie lange dauert die Antwort? Führen TTFB, DNS-Auflösung oder TLS-Handshake zu Latenzen?
- Nutzlastvalidierung — Enthält der Antwortkörper die erwartete Datenstruktur? Bestehen JSONPath- oder XPath-Assertions?
Was ist ein API-Endpunkt?
Eine Application Programming Interface (API) ist eine Reihe von Protokollen und Definitionen, die es Softwaresystemen ermöglichen miteinander zu kommunizieren. Ein API-Endpunkt ist die spezifische URL, unter der eine API Anfragen empfängt und Antworten zurückgibt — die Beobachtungseinheit für die API-Überwachung. Zum Beispiel:
POST /v2/auth/token— Token-AusgabepunktGET /v2/orders/{id}— Endpunkt zum Abrufen von BestellungenPOST /v2/payments/charge— Endpunkt zur Zahlungsabwicklung
Moderne Anwendungen sind gleichzeitig auf dutzende oder hunderte solcher Endpunkte angewiesen – interne Microservices, Drittanbieter-Zahlungsgateways, Identitätsanbieter, Versand-APIs und CRM-Systeme. API-Überwachung sorgt für Transparenz über alle diese Endpunkte.
Arten der API-Überwachung
Nicht alle API-Überwachungen sind gleich. Das Verständnis der Kategorien hilft Teams, eine Abdeckung zu schaffen, die sowohl zu ihrer Architektur als auch zu den Geschäftsanforderungen passt. Die fünf Kernarten gelten für fast jedes Team; spezialisierte Arten sind relevant, wenn deren Bedingungen zutreffen.
Kernarten
| Art | Was Sie validiert | Ideal für |
|---|---|---|
| Uptime-Überwachung | Erreichbarkeit des Endpunkts; HTTP-Antwortcodes; Antwort innerhalb des Timeoutfensters | Grundlegende Verfügbarkeits-SLAs; sofortige Fehlererkennung |
| Leistungsüberwachung | Antwortzeit, TTFB, DNS-Auflösung, TCP-Handshake, TLS-Zeit, Durchsatz | Latenz-SLAs, P95/P99 Ziele, Kapazitätsplanung |
| Nutzlast-/Validierungsüberwachung | Antwortkörper via JSONPath/XPath-Assertions; Schema-Korrektheit; Feldwerte | Erfassung stiller Fehler, bei denen HTTP 200 ≠ korrekte Daten ist |
| Synthetische Überwachung | Simulierte API-Aufrufe von globalen Standorten in geplanten Intervallen, unabhängig vom Realtraffic | Proaktive Erkennung; geografische Abdeckung; offline Zeiträume |
| Multi-Schritt-Transaktionsüberwachung | Verkettete API-Aufrufsequenzen (z. B. Auth → Abfrage → Übermittlung → Bestätigung); Übergabe von Daten zwischen Schritten | E-Commerce-Prozesse, Login-Journeys, Bestell-Workflows |
Spezialisierte Arten
| Art | Was Sie validiert | Ideal für |
|---|---|---|
| Sicherheitsüberwachung | Authentifizierungsfehler, anomale Anfrage-Muster, Zertifikatablauf, Rate-Limit-Missbrauch, Token-Replay | FinTech, Gesundheitswesen; APIs, die PII/PHI verarbeiten |
| Compliance-bezogene Prüfungen | TLS-Version/Kryptonvalidierung, Zertifikatablauf, Sicherheitsheader, Authentifizierungstests | Gesundheitswesen, Finanzdienstleistungen, regulierte Branchen |
| Real User Monitoring (RUM) | Tatsächliche Nutzer-API-Interaktionen; vollständige Sitzungsübersicht; reale geographische und Gerätevarianten | Verstehen des tatsächlichen Nutzer-Impacts; Validierung synthetischer Ergebnisse |
| Versions- & Deprecation-Monitoring | API-Versionsadoption, Fehleranstieg nach Versionswechsel, Abwärtskompatibilität | Teams mit gleichzeitiger Verwaltung mehrerer API-Versionen |
| Drittanbieter- / Integrations-Monitoring | Externe API-Abhängigkeiten (Stripe, Okta, Salesforce, Twilio); Unterscheidung zwischen internen und externen Fehlern | Jede App, die für kritische Workflows auf Drittanbieter-APIs angewiesen ist |
Ein Hinweis zu compliance-bezogenen Prüfungen: Diese liefern unterstützende Nachweise für spezifische technische Kontrollen. Framework-Compliance (HIPAA, PCI DSS, SOC 2) erfordert darüber hinausgehende organisatorische Governance, die allein mit Überwachung nicht abgedeckt wird.
Synthetische Überwachung vs. Real User Monitoring (RUM)
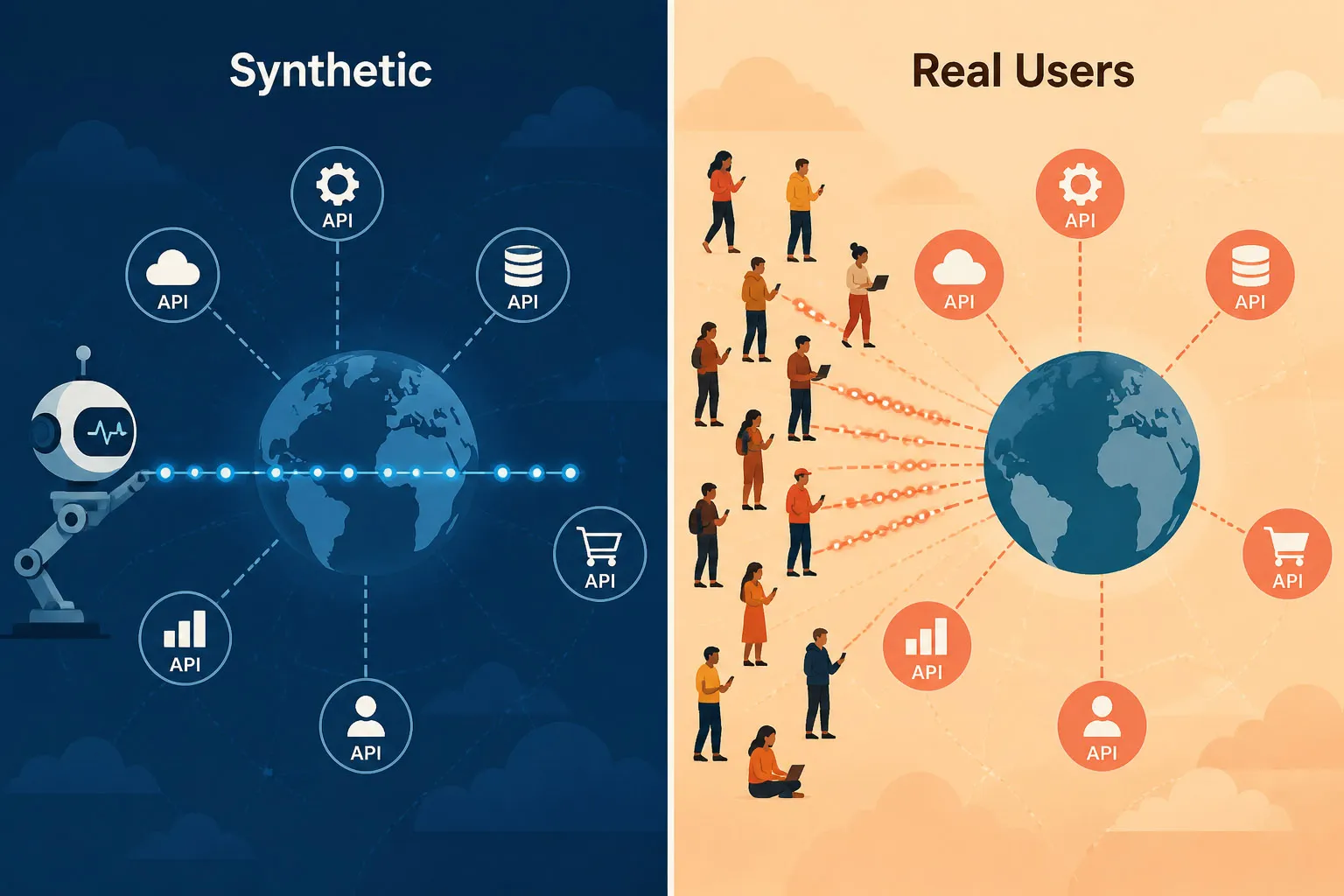
Beide Ansätze liefern API-Leistungsdaten, jedoch aus grundlegend unterschiedlichen Perspektiven:
| Synthetische Überwachung | Real User Monitoring (RUM) | |
|---|---|---|
| Auslöser | Scriptbasierte Prüfungen nach Zeitplan (z. B. alle 1 Minute) | Reale Nutzeranfragen in der Produktion |
| Abdeckung | 24/7 aktiv — auch wenn keine realen Nutzer aktiv sind | Erzeugt nur Daten, wenn Nutzer aktiv Anfragen stellen |
| Erkennung | Proaktiv — erkennt Fehler, bevor Nutzer betroffen sind | Reaktiv — Probleme werden erst angezeigt, wenn Nutzer bereits betroffen sind |
| Umfang | Öffentliche und private/interne APIs (via Private Agent) | APIs, die von realen Nutzern/Klienten erreicht werden — vorwiegend öffentlich, Enterprise-RUM kann auch interne API-Aufrufe instrumentierter Apps erfassen |
| Anwendungsfall | Kontinuierliche Validierung von Verfügbarkeit und Leistung | Verständnis der tatsächlichen Auswirkungsgröße und der Nutzererfahrung |
Wichtige API-Überwachungsmetriken
Das richtige Metriken-Tracking unterscheidet zwischen fundierter Vorfallsreaktion und Alarmmüdigkeit. Nachfolgend die wichtigsten Metriken — mit genauen Benchmarks und deren Aussagekraft.
| Metrik | Ziel / Benchmark | Was sie erkennt |
|---|---|---|
| Verfügbarkeit (Uptime %) | ≥ 99,9% (drei Neunen); 99,99% für umsatzkritische APIs | Vollständiger Ausfall, Teilweise Ausfälle, Zeitüberschreitung |
| Gesamte Antwortzeit | < 200 ms für einfache Endpunkte; < 1 s für komplexe Operationen | Serververlangsamung, Überlastung, Deployment-Regressions |
| Time to First Byte (TTFB) | Ideal < 100 ms; Akzeptabel < 300 ms | Serververarbeitungsverzögerung vor Beginn der Antwort |
| P95 / P99 Antwortzeit | Alarm bei 2× Baseline-P95 pro Endpunkt; Anpassung an Endpunktverhalten | Spitzenlatenz, die die langsamsten 1–5 % der Anfragen betrifft |
| Fehlerrate (4xx / 5xx) | < 0,1 % für Produktions-APIs | Authentifizierungsfehler, fehlerhafte Eingabe, Serverfehler |
| DNS-Auflösungszeit | < 50 ms für Caches im selben Region; über 100 ms für Cross-Region möglich | DNS-Propagation-Probleme, Resolver-Fehler |
| TLS-Handshake-Zeit | < 100 ms | Zertifikatfehlkonfiguration, TLS-Version-Verhandlungsprobleme |
| Payload-Assertion-Erfolgsrate | 100 % (Alarm bei jedem Fehler) | Stille Fehler: HTTP 200 mit falschen oder fehlenden Daten |
| Durchsatz (req/sec) | Vergleich mit historischem Baseline | Unerwartete Traffic-Einbrüche oder unnatürliche Spitzen |
| Zertifikatablauf (Tage verbleibend) | Alarm bei 30 Tagen; kritisch bei 7 Tagen | Bevorstehender TLS-Zertifikatablauf |
Antwortzeit-Benchmarks
Wie funktioniert API-Überwachung?
Das Verständnis der technischen Mechanik hilft Teams, die Überwachung korrekt zu konfigurieren und Ergebnisse genau zu interpretieren.
Der Kernüberwachungszyklus
- Planen. Ein synthetischer Check wird in einem konfigurierten Intervall ausgeführt (z. B. jede Minute) von einem ausgewählten globalen Überwachungsstandort.
- Anfrage senden. Der Überwachungsagent sendet eine HTTP-Anfrage an den Zielendpunkt — inklusive HTTP-Methoden (GET, POST, PUT, PATCH, DELETE), Anforderungsheadern, Authentifizierungsdaten und Anfrageinhalt.
- Zeit messen. Der Agent protokolliert DNS-Auflösungszeit, TCP-Verbindungszeit, TLS-Handshake-Zeit, Time to First Byte (TTFB) und Gesamtantwortzeit als unterschiedliche Komponenten.
- Assertions prüfen. Die Antwort wird anhand konfigurierter Assertions geprüft — HTTP-Statuscode, Antwortzeit, Antwortheader und Inhalt via JSONPath (REST) oder XPath (SOAP).
- Alarm oder Bestehen. Falls eine Assertion fehlschlägt oder die Anfrage eine Zeitüberschreitung hat, wird ein Vorfall erstellt und Alarme gemäß den konfigurierten Benachrichtigungsregeln ausgelöst.
- Erfassung. Alle Ergebnisse — erfolgreich oder fehlerhaft — werden mit Zeitstempeln, Antwortdaten und Assertionsergebnissen für historische Auswertungen und SLA-Berichte gespeichert.
Multi-Schritt-API-Transaktionsüberwachung

Die Überwachung einzelner Endpunkte bestätigt, dass einzelne Endpunkte antworten. Aber reale Nutzerreisen sind keine einzelnen API-Aufrufe — sie sind verkettete Sequenzen, bei denen jeder Schritt von der Ausgabe des vorherigen abhängt.
Betrachten wir einen E-Commerce-Checkout-Fluss:
- Schritt 1 —
POST /auth/token: Nutzer authentifizieren;access_tokenaus Antwort extrahieren - Schritt 2 —
GET /products/{id}: Produktdetails abrufen; Token inAuthorization-Header einfügen - Schritt 3 —
POST /cart/add: Artikel hinzufügen;cart_idaus Antwort extrahieren - Schritt 4 —
POST /checkout/initiate: Checkout mitcart_idstarten;checkout_session_idextrahieren - Schritt 5 —
POST /payments/charge: Zahlung verarbeiten; im Antwortfeldorder_statusden Wert'confirmed'erwarten
Bei Einzelendpunkt-Monitoring bestehen vielleicht alle fünf Schritte einzeln, aber die komplette Transaktion schlägt fehl — weil Sitzungsdaten nicht richtig zwischen Schritten übergeben werden, ein Token mittendrin abläuft oder das Zahlungs-API HTTP 200 mit einem Fehlerfeld im Payload zurückgibt. Multi-Step-Monitoring führt die gesamte Kette als einen Monitor aus, validiert jeden Schritt separat und übergibt dynamische Werte (Token, Session-IDs, Bestellnummern) automatisch zwischen den Schritten.
Dotcom-Monitor ermöglicht Multi-Step-Transaktionsüberwachung durch Verkettung sequentieller API-Aufrufe in einer einzigen Überwachungsaufgabe. Variablenauszug und -einspritzung zwischen den Schritten erfolgt automatisch. Jeder Schritt wird unabhängig geprüft, sodass Fehler genau auf den Schritt zurückverfolgt werden können, in dem die Transaktion fehlschlug.
Nutzlastvalidierung: JSONPath- und XPath-Assertions
Die Nutzlastvalidierung unterscheidet Monitoring von einfachem Verfügbarkeits-Ping. Wie Assertions formuliert werden, hängt vom Tool ab, die Logik ist aber konsistent:
- JSONPath-Feldzugriff (REST): Zugriff auf
$.data.status— dann prüfen, ob der zurückgegebene Wert'active'ist - JSONPath Array-Prüfung: Zugriff auf
$.items— prüfen, dass die Array-Länge größer als 0 ist - XPath-Assertion (SOAP):
//order/status/text()— prüfen, ob der Knotenwert'confirmed'ist - Header-Assertion: Prüfen, ob der Wert des Headers
Content-Type'application/json'entspricht - Antwortzeit-Assertion: Prüfen, dass die Gesamtantwortzeit unter 500 ms liegt
Authentifizierungsmonitoring
Produktions-APIs benötigen Authentifizierung. Ein Monitoring-Tool muss dieselben Authentifizierungsmethoden unterstützen wie Ihre echten API-Clients. Die folgenden Verfahren sollte eine produktionsreife Monitoring-Plattform beherrschen:
| Auth-Methode | Beschreibung | Hinweise |
|---|---|---|
| OAuth 2.0 — Client Credentials | Maschine-zu-Maschine; Client tauscht Anmeldedaten direkt gegen Token aus | Am häufigsten für Server-zu-Server-API-Überwachung |
| OAuth 2.0 — Autorisierungscode | Nutzerdelegierte Autorisierung; typischerweise mit PKCE für SPAs/Mobil-Apps | Monitoring-Tool sollte automatisches Token-Refresh unterstützen |
| OAuth 2.0 — Resource Owner Password (ROPC) | Direkter Benutzername + Passwort-Austausch — veralteter Flow | Nur verwenden, wenn Autorisierungscode nicht praktikabel ist |
| Bearer Token (JWT) | Statisches oder dynamisch erneuertes Token im Authorization-Header |
Kurzlebige JWTs erfordern automatischen Token-Refresh |
| API Key | Statischer Schlüssel in Header, Query-Parameter oder Cookie | Am einfachsten zu überwachen; auf Rotationsereignisse achten |
| Basic Authentication | Base64-codierte username:password im Authorization-Header |
Veraltet — aber immer noch verbreitet in Enterprise- und internen APIs |
| AWS Signature v4 | HMAC-signierte Anfrage mit AWS-Anmeldedaten | Erforderlich für AWS API Gateway Endpunkte |
| mTLS / Client-Zertifikat | Mutual TLS — beide Seiten präsentieren Zertifikate | Zero-Trust-Umgebungen; Überwachung von Zertifikatablauf kritisch |
| NTLM / Kerberos | Windows/Active Directory integrierte Authentifizierung | Enterprise-interne APIs; in Cloud-nativen Umgebungen seltener |
| Custom Headers | Eigenentwickelte Authentifizierungsschemata via benutzerdefinierte Header | Sammler für nicht standardisierte Auth-Implementierungen |
Token-Ablauf ist eine häufige Ursache für falsche Alarme bei der Überwachung. OAuth 2.0 Access Token-Lebensdauern variieren stark je nach Implementierung und Grant-Typ. Nutzerdelegierte Token (Authorization Code Flow) reichen typischerweise von 15 Minuten bis 1 Stunde. Maschine-zu-Maschine Token (Client Credentials Flow) werden oft für längere Zeiträume (1 bis 24 Stunden) konfiguriert, um den Aktualisierungsaufwand zu verringern. Hochsichere Umgebungen erzwingen manchmal nur 5 Minuten. Unabhängig vom Zeitraum verursacht ein Monitoring-Tool ohne automatischen Token-Refresh Fehlalarme oder erfordert manuelle Anmeldedatenrotation, was sowohl betrieblichen Mehraufwand als auch Ausfallrisiko erzeugt.
Ein Hinweis zum OAuth 2.0 Implicit-Grant: Dieser ist in aktuellen OAuth 2.0 Sicherheitsbest-Practices (RFC 9700) veraltet und sollte in neuen Systemen nicht verwendet werden. Falls Ihre bestehenden APIs den Implicit-Flow nutzen, wird eine Migration zu Authorization Code + PKCE dringend empfohlen.
Warum API-Überwachung wichtig ist: Geschäftsauswirkungen
APIs sind keine abstrakten Infrastrukturen — sie sind Einnahmepfade. Wenn sie ausfallen, sind die Konsequenzen finanziell, operativ und vertraglich.
Die Kosten unerkannter API-Fehler
Ohne proactive Überwachung verlassen sich Teams auf Kundenmeldungen, um Ausfälle zu erkennen. Branchenumfragen zeigen konsistent, dass die mittlere Erkennungszeit (MTTD) bei Kundenmeldungen über 30 Minuten liegt — in der Zeit seit der Meldung bis zur Untersuchung, Priorisierung und Eskalation ist dieses Zeitfenster bereits verstrichen. Kontinuierliche synthetische Überwachung mit 1-Minuten-Checks verkürzt die Erkennung auf unter 60 Sekunden und ermöglicht Root Cause-Analyse vor der weiteren Komplikation.
Die Umsatzrechnung ist simpel: Bestellungen pro Minute × durchschnittlicher Bestellwert × Ausfalldauer in Minuten. Eine Plattform mit 100 Bestellungen/Minute bei $50 durchschnittlichem Bestellwert verliert bei 5-minütigem Zahlungs-API-Ausfall $25.000 potenziellen Umsatz. Benutzen Sie eigene Werte zur Größenschätzung Ihres Risikos.
Branchenspezifische Szenarien
- E-Commerce. Ein Checkout-API-Ausfall während Spitzenlast stoppt alle Konversionen. Ein Zahlungsautorisierungs-API, das HTTP 200 mit abgelehntem Status, aber ohne Alarm zurückgibt, blockiert stille Transaktionen für Minuten, bevor jemand reagiert.
- FinTech. Transaktionsverarbeitungs-APIs müssen Sub-Sekunden-Latenzen erfüllen. Anhaltende SLA-Verletzungen können Vertragsstrafen und Audit-Feststellungen unter PCI DSS auslösen.
- Gesundheitswesen. EHR-Integrations-APIs und Telemedizin-Endpunkte müssen HIPAA-konformen Datenaustausch gewährleisten. Ein API, das HTTP 200 mit unvollständigen Patientendaten zurückgibt, ist ein Compliance-Vorfall — nicht nur ein Leistungsproblem.
- SaaS / API as a Product. Wenn Ihre API ein kostenpflichtiges Produkt ist, verursachen Ausfälle SLA-Strafzahlungen und Kundenabwanderung. Monitoring liefert dokumentierte Nachweise für SLA-Berichte.
- Enterprise IT. CRM-, ERP- und HR-API-Integrationen über Abteilungen hinweg. Ein Salesforce API-Performanceabfall kann Verkaufs-Workflows heimlich lahmlegen, ohne dass ein einziger 500er-Fehler in Logs auftaucht.
Drittanbieter-API-Risiko
Moderne Anwendungen sind auf externe APIs angewiesen, die sie nicht kontrollieren: Zahlungsgateways (Stripe, PayPal, Braintree), Identitätsanbieter (Okta, Auth0, AWS Cognito), Versand-APIs und CRM-Systeme. Wenn diese ausfallen oder sich verschlechtern, wirkt Ihre Anwendung für Nutzer defekt, obwohl Ihre Infrastruktur gesund ist.
Drittanbieter-Endpunktüberwachung ermöglicht es Teams sofort zu unterscheiden, ob ein Fehler intern oder extern verursacht wird — eine Unterscheidung, die ohne Monitoring-Daten oft erhebliche Ermittlungszeit erfordert. Zudem liefert es dokumentierte Nachweise, um Anbieter an ihre SLA-Verpflichtungen zu binden.
Hören Sie auf, von Ihren Kunden über API-Ausfälle zu erfahren.
Dotcom-Monitors synthetische API-Überwachung entdeckt Ausfälle in unter 60 Sekunden und leitet Alarme direkt an PagerDuty, Slack oder Microsoft Teams weiter. Überwachen Sie Zahlungsgateways, Identitätsanbieter und interne APIs von einer Plattform aus.
API-Überwachung vs. API-Testing
Beide Praktiken validieren API-Verhalten, dienen jedoch unterschiedlichen Zwecken im Software-Lebenszyklus. Das Vermischen führt zu Lücken in der Abdeckung.
| Dimension | API-Testing | API-Überwachung |
|---|---|---|
| Wann | Vor Deployment — Entwicklung, QA, CI/CD-Pipeline | Nach Deployment — kontinuierlich in der Produktion |
| Umgebung | Entwicklungs-, Staging- und kontrollierte Testumgebung | Produktivumgebung, reale Infrastruktur, echter Traffic |
| Auslöser | Code-Commit, Build, manuelle Ausführung, PR-Gate | Geplant (z. B. jede Minute), 24/7 kontinuierlich |
| Ziel | Fehler vor Deployment verhindern | Fehler und Verschlechterungen während des Betriebs erkennen |
| Abdeckung | Alle Verhalten, Randfälle, Fehlerpfade | Kritische Pfade, SLA-Endpunkte, Nutzerreise-Ketten |
| Perspektive | Von innen nach außen: Test des Verhaltens des Codes | Von außen nach innen: Validierung aus Nutzer-Perspektive |
| Ergebnis | Pass/Fail-Bericht; verhindert Deployment bei Fehlern | Echtzeit-Alarme, SLA-Verfügbarkeitsdaten, Vorfallhistorie |
Die praktische Beziehung: API-Testing ist eine Entwicklungsphase. API-Überwachung ist eine Betriebsaktivität. Testing findet Bugs vor Deployment; Monitoring erkennt Ausfälle, Regressionen, Performance-Einbußen und Abhängigkeitsprobleme nach Deployment unter realen Infrastrukturbedingungen, die sich von kontrollierten Testumgebungen unterscheiden.
Ein erfahrenes Team nutzt beides — und verwendet Postman Collection Importe als Brücke, um Entwicklungstests in produktive Monitore zu überführen, ohne Anfragedefinitionen zu duplizieren.
API-Überwachung vs. APM
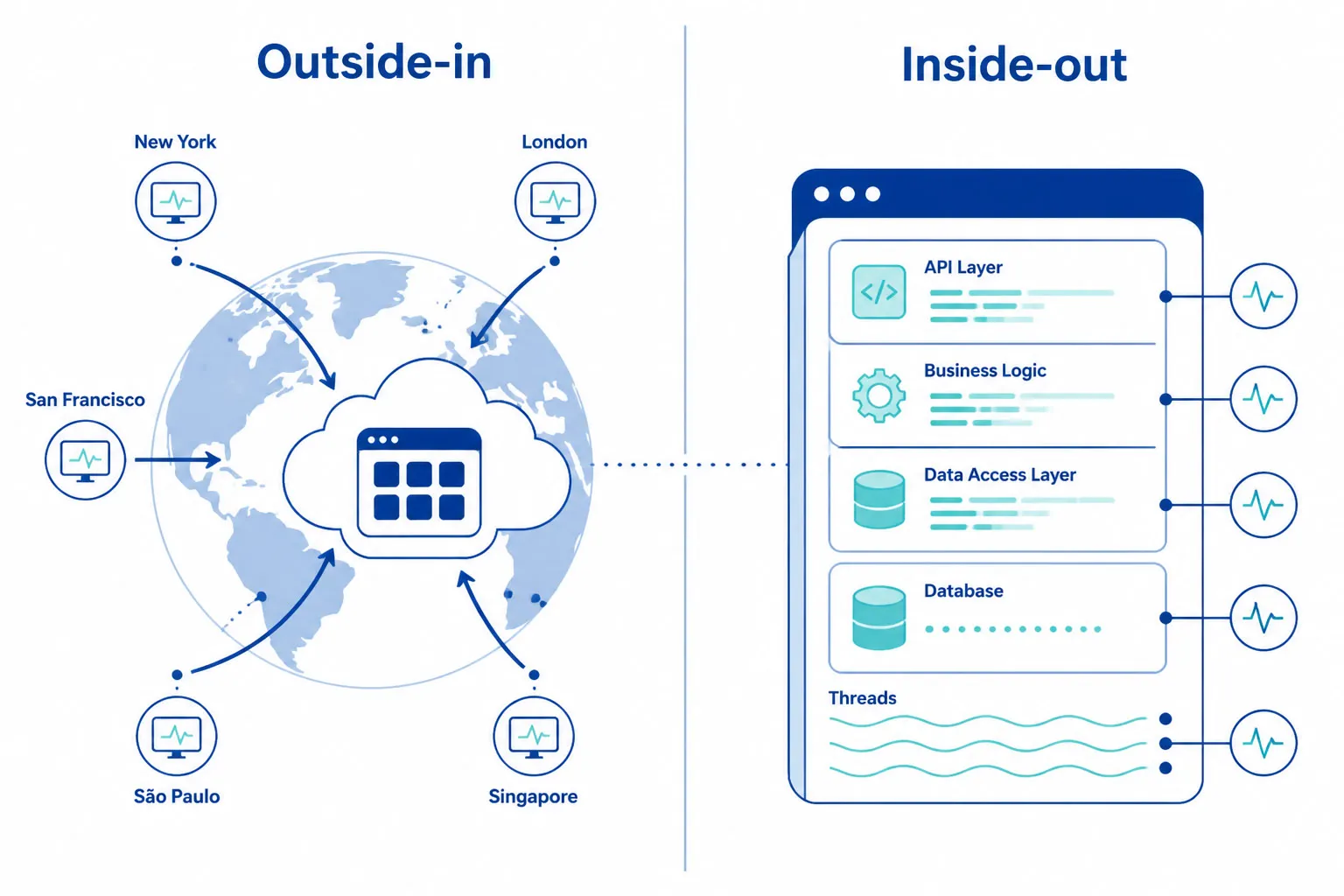
Diese beiden Kategorien werden häufig verwechselt. Sie ergänzen sich, sind aber nicht austauschbar.
| Synthetische API-Überwachung | APM (Application Performance Monitoring) | |
|---|---|---|
| Perspektive | Outside-in — validiert aus der gleichen Perspektive wie Nutzer und Partner | Inside-out — beobachtet internes Anwendungsverhalten |
| Was es sieht | DNS-Ausfälle, Netzwerk-Routing-Probleme, TLS-Fehler, CDN-Fehlleitungen, geografische Abdeckungslücken | Langsame DB-Abfragen, Speicherlecks, Code-Exceptions, langsame Funktionsaufrufe |
| Wann es läuft | 24/7 — auch bei Null-Traffic | Nur bei tatsächlicher Anfrageverarbeitung |
| Frage, die beantwortet wird | „Können unsere Kunden diese API gerade tatsächlich aufrufen?“ | „Was passiert im Inneren unserer Anwendung, wenn eine Anfrage eingeht?“ |
Teams mit der niedrigsten MTTR nutzen beides: APM für interne Root-Cause-Analyse, synthetische API-Überwachung für externe Validierung. Logs und Traces beantworten „Was ging im Code schief?“ Synthetisches Monitoring beantwortet „Können unsere Kunden diese API jetzt nutzen?“
API-Protokolle: REST, SOAP, GraphQL, gRPC und WebSocket
Jedes API-Protokoll hat unterschiedliche Überwachungsanforderungen und Fehlerarten. Ein Tool, das alle APIs als einfache HTTP-GET-Anfragen behandelt, verfehlt spezifische Protokollprobleme.
REST API-Monitoring
REST ist das dominierende API-Protokoll. Die Überwachung validiert HTTP-Methoden (GET, POST, PUT, PATCH, DELETE), Statuscodes, Antwortheader und JSON-Antwortkörper via JSONPath-Assertions. Wichtige Anforderungen: Validierung von Nutzlastfeldwerten — nicht nur Statuscodes; Überwachung aller HTTP-Methoden, nicht nur GET (POST, PUT und DELETE lösen unterschiedliche serverseitige Logiken und Fehlerarten aus); Messung der Antwortzeit pro Endpunkt individuell, nicht als aggregiertes Mittel über Endpunkte.
SOAP API-Überwachung
SOAP APIs tauschen XML über HTTP aus. Überwachungsanforderungen: WSDL-Import für Endpunkt- und Schema-Definition; XPath-Assertions auf XML-Antwortelemente; Unterstützung von SOAP 1.1 und SOAP 1.2 Protokollen; WS-Security-Konfiguration für Enterprise-SOAP-Services mit Nachrichtensicherheit.
GraphQL API-Überwachung
Die größte Herausforderung bei GraphQL: die meisten GraphQL-Server-Implementierungen liefern HTTP 200 selbst bei partiellen Fehlern oder fehlerhaften Abfragen. Der HTTP-Statuscode ist kein zuverlässiges Fehler-Signal. Sie müssen:
- Bestimmte Abfrage-Payloads senden und auf das
data-Objekt in der Antwort prüfen - Das
errors-Array im Antwortkörper prüfen — in Standard GraphQL besitzt jede Antwort ein optionales Top-Level-errors-Feld, das im Erfolgsfall leer oder abwesend und im Fehlerfall gefüllt ist. Ein 200 mit gefülltemerrors[]bedeutet, dass die Anfrage auf GraphQL-Ebene fehlgeschlagen ist, obwohl HTTP erfolgreich war - Abfrage-spezifische Dateninvarianten validieren: Sicherstellen, dass erwartete Felder vorhanden, nicht null und korrekt typisiert sind — manche Systeme kodieren Domänenfehler in das Datenobjekt anstelle der Nutzung des top-level error-Arrays
- Komplexitäts- und Tiefenlimits der Abfragen überwachen, um Performanceverschlechterungen vor Zeitüberschreitungen zu erkennen
gRPC API-Überwachung
gRPC nutzt standardmäßig Protocol Buffers über HTTP/2, während gRPC-Web HTTP/1.1 via Proxy für Browser-Clients unterstützt. Überwachungsanforderungen: Import von Proto-Dateien für Service- und Methoden-Definitionen; Unterstützung für binäre Kodierung/Decodierung von Protocol Buffer-Nachrichten; Statuscode-Validierung via gRPC-Statuscodes (OK, UNAVAILABLE, DEADLINE_EXCEEDED, etc.) — nicht HTTP-Statuscodes; Unterstützung von Unary, Server-Streaming, Client-Streaming und Bidirektionalen Streaming-RPC-Typen.
WebSocket API-Überwachung
WebSocket-APIs halten persistente bidirektionale Verbindungen für Echtzeitdaten aufrecht. Die Überwachung validiert Verbindungsaufbauzeit und Erfolg des WebSocket-Handshakes, Nachrichtenübermittlungs-Latenz und Nutzlastkorrektheit sowie Verbindungsstabilität über die Zeit einschließlich Wiederverbindungsverhalten nach Verbindungsabbrüchen.
Öffentliche API-Überwachung vs. Interne API-Überwachung

Die meisten API-Überwachungsleitfäden fokussieren ausschließlich öffentliche Endpunkte. Doch in Microservice-Architekturen sind die meisten kritischen API-Aufrufe intern — Service-zu-Service-Kommunikation, die das öffentliche Internet nie erreicht.
| Öffentliche API-Überwachung | Interne API-Überwachung | |
|---|---|---|
| Abgedeckt | Kundenorientierte Endpunkte, Partner-APIs, Drittanbieter-Integrationen | Interne Microservices, private VPCs, Staging, APIs hinter Firewalls |
| Funktionsweise | Externe Monitoring-Agenten führen Prüfungen von globalen Standorten über das öffentliche Internet aus | Ein innerhalb Ihres Netzwerks eingesetzter Private Agent initiiert ausgehende Verbindungen zur Monitoring-Plattform |
| Firewall-Anforderungen | Keine — Prüfungen kommen von extern | Keine eingehenden Regeln nötig — Agent initiiert nur ausgehende Verbindungen |
| Was erkannt wird | DNS-Ausfälle, CDN-Routing-Probleme, TLS-Fehler, geografische Verfügbarkeitslücken | Inter-Service-Ausfälle, Microservice-Latenzen, Datenbank-API-Verschlechterungen |
| Implementierung | Keine Installation notwendig — sofort einsatzbereit | Agent vor Ort oder in privater Cloud installieren (unterstützt Windows und Linux) |
Interne Microservice-APIs sind die häufigste Ursache für kaskadierende Fehler. Ein degradierter Authentifizierungsservice oder ein langsamer Datenzugriffs-API verursacht nachgelagerte Probleme, die Frontend-Fehler hervorrufen — ohne interne Sichtbarkeit ist die Ursache schwer zu lokalisieren. Die Überwachung interner APIs lässt Teams erkennen, ob der Fehler in der API-Schicht, in einem nachgelagerten Microservice oder der Datenbank liegt. Mehr erfahren Sie über Private Agent-Überwachung hinter der Firewall.
Best Practices für API-Überwachung
Diese Praktiken reduzieren die mittlere Erkennungszeit (MTTD), verbessern die Alarmgenauigkeit und sorgen für eine Überwachungsabdeckung, die dem Produktionsrisiko entspricht.
- Überwachen Sie umsatzkritische Endpunkte mit 1-Minuten-Intervallen. Für Zahlungs-, Authentifizierungs- und Kern-Daten-APIs hat jede unerkannte Minute direkten Geschäftseinfluss. 5- oder 15-Minuten-Intervalle sind für weniger kritische Endpunkte akzeptabel.
- Führen Sie Prüfungen von mindestens 5 geografisch verteilten Standorten aus. Ein einzelner Standort kann regionale DNS-Ausfälle, CDN-Fehlkonfigurationen oder Lokalspezifische Routingprobleme nicht erkennen. Mindestens Nordamerika, Europa und Asien-Pazifik abdecken.
- Validieren Sie den Nutzlastinhalt, nicht nur Statuscodes. Konfigurieren Sie JSONPath-Assertions für alle kritischen Endpunkte. Die teuersten stillen Fehler sind APIs, die HTTP 200 mit unvollständigen, veralteten oder fehlerhaften Daten zurückgeben.
- Verwenden Sie benachrichtigungsbasierte Schwellenwerte, keine statischen Millisekundenwerte. Ermitteln Sie eine Antwortzeit-Basislinie pro Endpunkt und konfigurieren Sie Alarme bei 2× dem P95-Wert. Statische Schwellenwerte verursachen Fehlalarme bei normalen Verkehrsspitzen.
- Integrieren Sie Authentifizierung in Ihre Überwachungsketten. Tokenablauf, OAuth-Refresh-Fehler und Zertifikatsrotation sind Hauptursachen für API-Ausfälle. Auth-Schritte überwachen fängt Anmeldefehler, bevor sie eskalieren.
- Erstellen Sie Multi-Schritt-Transaktionsmonitore für jede kritische Nutzerreise. Login-Flows, Checkout-Sequenzen und Datenübermittlungs-Workflows sind verkettete API-Aufrufe. Einzelendpunkt-Monitore erfassen keine Fehler, die durch falsche Datenübergabe oder Session-Handling zwischen den Schritten entstehen.
- Überwachen Sie Drittanbieter-API-Abhängigkeiten als separate Monitore. Erstellen Sie eigene Monitore für Stripe, Okta, Salesforce und andere externe Dienste. Das liefert sofort Transparenz, ob ein Fehler intern oder extern verursacht ist.
- Importieren Sie Postman- oder Insomnia-Collections zur Überwachung. Überführen Sie bestehende API-Definitionen in 24/7 Produktionsmonitore, ohne Anforderungsstrukturen neu anlegen zu müssen. So schließen Sie die Lücke zwischen Entwicklungstests und Produktionsüberwachung.
- Integrieren Sie API-Prüfungen nach dem Deployment in CI/CD-Pipelines. Führen Sie synthetische API-Prüfungen als automatisierte Smoke Tests nach jedem Deployment aus. Schlagen sie fehl, erwägen Sie einen automatisierten Rollback oder Traffic-Hold in progressive Delivery Setups (Blue/Green oder Canary) — mit Bestätigungsprüfungen von einem zweiten Standort, um Fehlalarme vor automatischen Aktionen zu reduzieren.
- Leiten Sie Alarme an PagerDuty, Slack oder Microsoft Teams mit Eskalationsrichtlinien. Nur per E-Mail zu alarmieren führt zu Erkennungsverzögerung. Native Integrationen mit Incident-Management-Tools sorgen dafür, dass Alarme die richtige Person sofort erreichen, mit definierten Eskalationswegen bei Nicht-Reaktion.
Herausforderungen bei der API-Überwachung
Selbst gut gestaltete Monitoring-Konfigurationen stehen vor betrieblichen Herausforderungen. Vorwegnahme hilft Teams, um geeignete Strategien zu entwickeln.
Sichtbarkeit von Drittanbieter-APIs
Überwachung externer Abhängigkeiten liefert Verfügbarkeits- und Latenzdaten, kann aber die interne Ursache einer Verschlechterung nicht aufdecken. Wenn Stripe oder Okta langsamer werden, lässt sich das bestätigen und der Wirkungsbereich eingrenzen — aber die Ursachenanalyse hängt von Statusseiten der Anbieter und Support-Eskalationspfaden ab.
Rate-Limiting
Monitoring-Agenten verbrauchen Anfragelimits Ihrer API. Das synthetische Anfragevolumen berechnet sich als: Standorte × Checks pro Stunde × API-Aufrufe pro Monitorlauf × Bestätigungsversuche. Für einen Einzelendpunkt-Monitor: 30 Standorte × 60 Checks/Stunde = 1800 Anfragen/Stunde. Für einen 5-Schritt-Transaktionsmonitor bei gleicher Einstellung: 30 × 60 × 5 = 9000 Anfragen/Stunde pro Monitor. Berücksichtigen Sie das bei Ihrem Rate-Limit-Budget, vor allem bei internen APIs mit engen Grenzen. Stellen Sie sicher, dass IP-Bereiche Ihres Monitoring-Anbieters, wo erforderlich, auf Whitelist stehen.
Komplexität der Authentifizierung
APIs mit kurzlebigen Tokens erfordern Monitoring-Tools mit automatischem Token-Refresh. Nutzerdelegierte OAuth 2.0-Tokens (Authorization Code Flow) laufen meist nach 15 Minuten bis zu 1 Stunde ab; Maschinen-Tokens (Client Credentials Flow) oft nach 1 bis 24 Stunden; Hochsicherheitsumgebungen erzwingen 5 Minuten. Zertifikat-basierte Authentifizierung und rotierende API-Schlüssel erfordern ebenfalls sorgfältiges Credential-Management.
Dynamische und nicht-deterministische Antworten
APIs mit Zeitstempel-Daten, paginierten Ergebnissen oder zufällig sortierten Arrays sind schwer mit exakten Wertvergleichen zu prüfen. Nutzen Sie JSONPath-Ausdrücke, die Struktur, Feldpräsenz und Typen validieren — statt exakter Feldwerte, die sich bei jeder Anfrage ändern.
Alarmmüdigkeit
Überwachung zu vieler Endpunkte mit 1-Minuten-Intervallen oder zu eng gesetzte Schwellenwerte erzeugen Lärm, der Teams für echte Alarme abstumpft. Verwenden Sie gestufte Überwachung: 1 Minute für kritische Pfade, 5–15 Minuten für weniger kritische Endpunkte. Bestätigen Sie Alarme an einem sekundären Standort vor Weiterleitung, um temporäre Fehlalarme auszuschließen.
Protokollvielfalt
REST, SOAP, GraphQL, gRPC und WebSocket erfordern unterschiedliche Assertion-Strategien. Ein Tool, das nur REST kann, übersieht SOAP-Fehler und meldet GraphQL-Fehler fälschlich als erfolgreich, da sie HTTP 200 zurückgeben.
So richten Sie API-Überwachung mit Dotcom-Monitor ein
 Wenn ein Check fehlschlägt, leiten Alarme an Ihre vorhandenen Incident-Response-Tools weiter — nicht an ein separates, unbeachtetes Monitoring-Postfach.
Wenn ein Check fehlschlägt, leiten Alarme an Ihre vorhandenen Incident-Response-Tools weiter — nicht an ein separates, unbeachtetes Monitoring-Postfach.
Dotcom-Monitor bietet synthetische API-Überwachung für REST, SOAP und GraphQL von über 30 globalen Standorten mit 1-Minuten-Checkintervallen, Multi-Step-Transaktionssupport und nativen Integrationen für PagerDuty, Slack und Microsoft Teams.
Schritt 1 — Definieren Sie Ihren Endpunkt und Assertions
- Endpunkt-URL: Der zu überwachende API-Endpunkt
- HTTP-Methode: GET, POST, PUT, PATCH oder DELETE
- Request-Header:
Content-Type,Authorizationund beliebige benutzerdefinierte Header - Request-Body: JSON-Payload für POST/PUT-Anfragen
- Authentifizierung: OAuth 2.0, Bearer Token, API Key, Basic Auth, mTLS, AWS Signature v4, NTLM, Kerberos oder benutzerdefinierte Header
- Assertions: HTTP-Statuscode, Antwortzeit-Schwellenwert, Headerwerte, JSONPath/XPath Payload-Assertions
Schritt 2 — Importieren Sie aus Postman oder Insomnia
Wenn Ihr Team Postman oder Insomnia nutzt, überspringen Sie die manuelle Konfiguration vollständig:
- Postman: Exportieren Sie Ihre Collection als v2.0 oder v2.1 JSON und importieren Sie sie in Dotcom-Monitor. Anforderungsdefinitionen, Header, Body, Umgebungsvariablen und Test-Assertions bleiben erhalten.
- Insomnia: Exportieren Sie Ihren Workspace als Insomnia v4 JSON-Datei und importieren Sie sie in Dotcom-Monitor. Anforderungsgruppen, Auth-Konfigurationen und Umgebungsvariablen bleiben erhalten.
Beide Importformate wandeln einmalig erstellte Entwicklungstests in dauerhaft geplante 24/7-Produktionstests um, ohne Neu-Konfiguration.
Sie nutzen bereits Postman? Nur noch 5 Minuten bis zur 24/7-Produktionsüberwachung.
Importieren Sie Ihre bestehende Postman-Collection direkt in Dotcom-Monitor. Ihre Anforderungsdefinitionen, Header, Umgebungsvariablen und Assertions bleiben erhalten — keine Neu-Konfiguration nötig.
Schritt 3 — Konfigurieren Sie Überwachungsstandorte und Häufigkeit
- Check-Frequenz: 1-, 3-, 5- oder 15-Minuten-Intervalle — je nach Kritikalität pro Endpunkt einstellen
- Überwachungsstandorte: Auswahl aus über 30 Standorten in Nordamerika, Europa, Asien-Pazifik und Südamerika
- Private Agent: Für interne oder hinter Firewall liegende APIs — installieren Sie den Agent vor Ort oder in privater Cloud (Windows und Linux unterstützt). Agent initiiert nur ausgehende Verbindungen — keine eingehenden Firewall-Regeln erforderlich.
- Bestätigungsversuche: Konfigurieren Sie eine sekundäre Standortbestätigung vor Alarmierung, um vorübergehende Netzwerkfehlalarme auszuschließen
Schritt 4 — Konfigurieren Sie Alarmweiterleitung
- PagerDuty: Leiten Sie kritische Alarme direkt an Bereitschaftspläne mit automatischer Vorfallerstellung und Eskalation weiter
- Slack / Microsoft Teams: Posten Sie Alarmnachrichten mit Endpunktdetails, Fehlertyp und Antwortdaten in Operations-Kanäle
- E-Mail, SMS, Telefonanruf: Konfigurieren Sie Benachrichtigungsvorlieben pro Kontakt oder Team
- Webhook: Integration mit OpsGenie, ServiceNow oder jedem HTTP-kompatiblen Dienst
- Schwellenwertkonfiguration: Legen Sie Alarmbedingungen pro Metrik fest — Antwortzeit, Fehlerrate, Assertion-Fehlerquote — mit verschiedenen Schweregraden
Schritt 5 — CI/CD-Pipeline-Integration
- Dotcom-Monitor REST API: Erstellen, aktualisieren und starten Sie Monitoring-Aufgaben programmatisch via HTTP-API-Aufrufe aus jedem CI/CD-System
- GitHub Actions / Azure DevOps / Jenkins: Fügen Sie einen Post-Deploy-Schritt hinzu, der einen Dotcom-Monitor-Check ausführt, auf Ergebnisse wartet und die Pipeline bei Assertion-Fehlern fehlschlägt
- Pre-Production-Validierung: Führen Sie dieselben synthetischen Checks vor dem Überführen ins Produktivsystem gegen Ihre Staging-Umgebung aus — erkennen Sie Regressionen, bevor Nutzer betroffen sind
API-Überwachungsfallbeispiele nach Branche
| Branche | Kritische APIs zur Überwachung | Wichtige Überwachungsanforderungen |
|---|---|---|
| E-Commerce | Checkout, Zahlungsautorisierung, Inventar, Versand, Warenkorbverwaltung | Multi-Schritt-Transaktionsketten; 1-Minuten-Intervalle; Payload-Assertion auf Zahlungsbestätigungsstatus |
| FinTech / Banking | Transaktionsverarbeitung, KYC/AML-Überprüfung, Kontostand, Devisenkurse, Überweisungs-APIs | Sub-200 ms Latenz-SLAs; Compliance-relevante Prüfungen zur PCI DSS-Unterstützung; vollständige Auth-Flow-Validierung |
| Gesundheitswesen | EHR-Integrationen (HL7 FHIR), Versicherungsportale, Telemedizin, Patiententerminplanung | Compliance-Prüfungen zur Unterstützung von HIPAA-Nachweisen; Payload-Validierung für Datenvollständigkeit; 99,99 % Uptime-SLA |
| SaaS | Kernprodukt-APIs, Webhook-Zustellendpunkte, Partnerintegrations-APIs, Authentifizierungs-APIs | API-as-a-Product SLA-Einhaltung; Postman-Import für Dev-to-Monitor Konsistenz; Drittanbieter-Abhängigkeitsüberwachung |
| Enterprise IT | CRM, ERP, HRIS, Identitätsprovider, API für interne Workflow-Automatisierung | Private Agent für APIs hinter Firewalls; NTLM/Kerberos-Unterstützung; API-Übersicht über Abteilungsgrenzen hinweg |
| Medien / Gaming | CDN Content Delivery APIs, Authentifizierung, Echtzeit-Scoring, Social-Features-APIs | Geografisches Verteilungsmonitoring; WebSocket-Verbindungsüberwachung; Traffic-Spikenerkennung |
Beginnen Sie noch heute mit der Überwachung Ihrer APIs.
Dotcom-Monitor bietet synthetische API-Überwachung von über 30 globalen Standorten mit 1-Minuten-Checks, Multi-Step-Transaktionssupport und nativen Integrationen für PagerDuty, Slack und Microsoft Teams. Die Einrichtung dauert unter 5 Minuten. Für die 30-Tage-Testversion ist keine Kreditkarte erforderlich.
