APIモニタリングとは、APIエンドポイントの可用性、応答時間、およびデータの正確性を継続的かつ自動的に検証する手法です。エンドポイントが応答するだけでなく、適切な遅延時間内にユーザーおよび依存システムの視点から適切なデータを適切な形式で返すことを確認します。

APIは現代ソフトウェアの結合組織です。ユーザーがログインしたり、支払いを送信したり、リアルタイム通知を受け取るたびに、複数のAPIコールがマイクロサービス、クラウドプロバイダ、サードパーティベンダーをまたいで裏で実行されます。これらのコールが失敗したり遅延したりすると、影響は即時に現れ: チェックアウトフローの中断、ユーザーのログイン不能、収益の損失となります。
しかし、多くのチームは顧客からの報告で初めてAPIの失敗を発見します。積極的な監視がないと、失敗から調査までの遅延は通常数十分に及び、誰にも通知される前に実際の収益やSLAリスクが発生します。
このガイドは、APIモニタリングとは何か、どのように機能するか、追跡すべき指標、APIテストやAPMとの違い、そして実装方法を説明します。DevOpsエンジニア、SRE、QAチームが生産環境での意思決定を行うための正確な知識を得るための内容です。
APIモニタリングとは?
APIモニタリングは、検証レベルに応じて次の3つの層で構成されます:
- 可用性モニタリング — エンドポイントに到達可能か?タイムアウトなしにHTTPレスポンスを返すか?
- パフォーマンスモニタリング — 応答にかかる時間は?TTFB、DNS解決、TLSハンドシェイクが遅延を生んでいるか?
- ペイロード検証 — レスポンスボディが期待されるデータ構造を含むか?JSONPathやXPathのアサーションを通過するか?
APIエンドポイントとは?
アプリケーションプログラミングインターフェース(API)は、ソフトウェアシステム間の通信を可能にする一連のプロトコルと定義です。APIエンドポイントは、APIがリクエストを受け取りレスポンスを返す特定のURLであり、APIモニタリングにおける観測単位です。例として:
POST /v2/auth/token— トークン発行エンドポイントGET /v2/orders/{id}— 注文取得エンドポイントPOST /v2/payments/charge— 支払い処理エンドポイント
現代アプリケーションは同時に多数のこのようなエンドポイントに依存しています — 内部マイクロサービス、サードパーティの支払ゲートウェイ、IDプロバイダ、配送API、CRMシステムなど。APIモニタリングはこれら全ての可視性を維持します。
APIモニタリングの種類
すべてのAPIモニタリングは同じではありません。カテゴリを理解することで、アーキテクチャとビジネス要件に合った監視範囲を構築できます。以下の5つのコアタイプはほぼ全てのチームに適用され、特定条件下では専門的なタイプも重要となります。
コアタイプ
| タイプ | 検証内容 | 最適用途 |
|---|---|---|
| 稼働時間モニタリング | エンドポイント到達性;HTTPレスポンスコード;タイムアウト内の応答 | 基本的な可用性SLA; 即時の障害検出 |
| パフォーマンスモニタリング | 応答時間、TTFB、DNS解決、TCPハンドシェイク、TLS時間、スループット | 遅延SLA、P95/P99ターゲット、容量計画 |
| ペイロード / バリデーションモニタリング | JSONPath/XPathアサーションによるレスポンスボディ;スキーマ正確性;フィールド値検証 | HTTP 200では正しいデータが返さないサイレントな失敗の検出 |
| シンセティックモニタリング | 実トラフィックとは独立して、グローバルロケーションからの模擬APIコールをスケジュール実行 | 積極的な障害検出;地理的カバレッジ;ゼロトラフィック時の検査 |
| マルチステップトランザクションモニタリング | 認証→クエリー→送信→確認などの連鎖したAPIコールシーケンス;ステップ間のデータ受け渡し | ECフロー、ログインフロー、注文ワークフロー |
専門的タイプ
| タイプ | 検証内容 | 最適用途 |
|---|---|---|
| セキュリティモニタリング | 認証失敗、異常リクエストパターン、証明書期限切れ、レート制限の乱用、トークンリプレイ | FinTech、医療;個人情報(PII/PHI)を扱うAPI |
| コンプライアンス関連チェック | TLSバージョン/暗号検証、証明書有効期限、セキュリティヘッダーの有無、認証強制テスト | 医療、金融、規制産業 |
| リアルユーザーモニタリング (RUM) | 実際のユーザーAPIインタラクション;フルセッションの可視性;地理的およびデバイスの多様性 | 実際のユーザー影響の理解;シンセティック結果の検証 |
| バージョニング&廃止モニタリング | APIバージョンの採用率;バージョン変更後のエラースパイク;後方互換性 | 複数バージョンのAPIを同時に管理するチーム |
| サードパーティ/統合モニタリング | 外部API依存(Stripe、Okta、Salesforce、Twilioなど);内外部の障害切り分け | 重要なワークフローで外部APIを利用するアプリ全般 |
コンプライアンス関連チェックについての注意:これらは特定の技術的コントロールをサポートする証拠を提供します。HIPAA、PCI DSS、SOC 2等のフレームワーク遵守は、監視だけではなく組織全体のガバナンスを必要とします。
シンセティックモニタリングとリアルユーザーモニタリング(RUM)
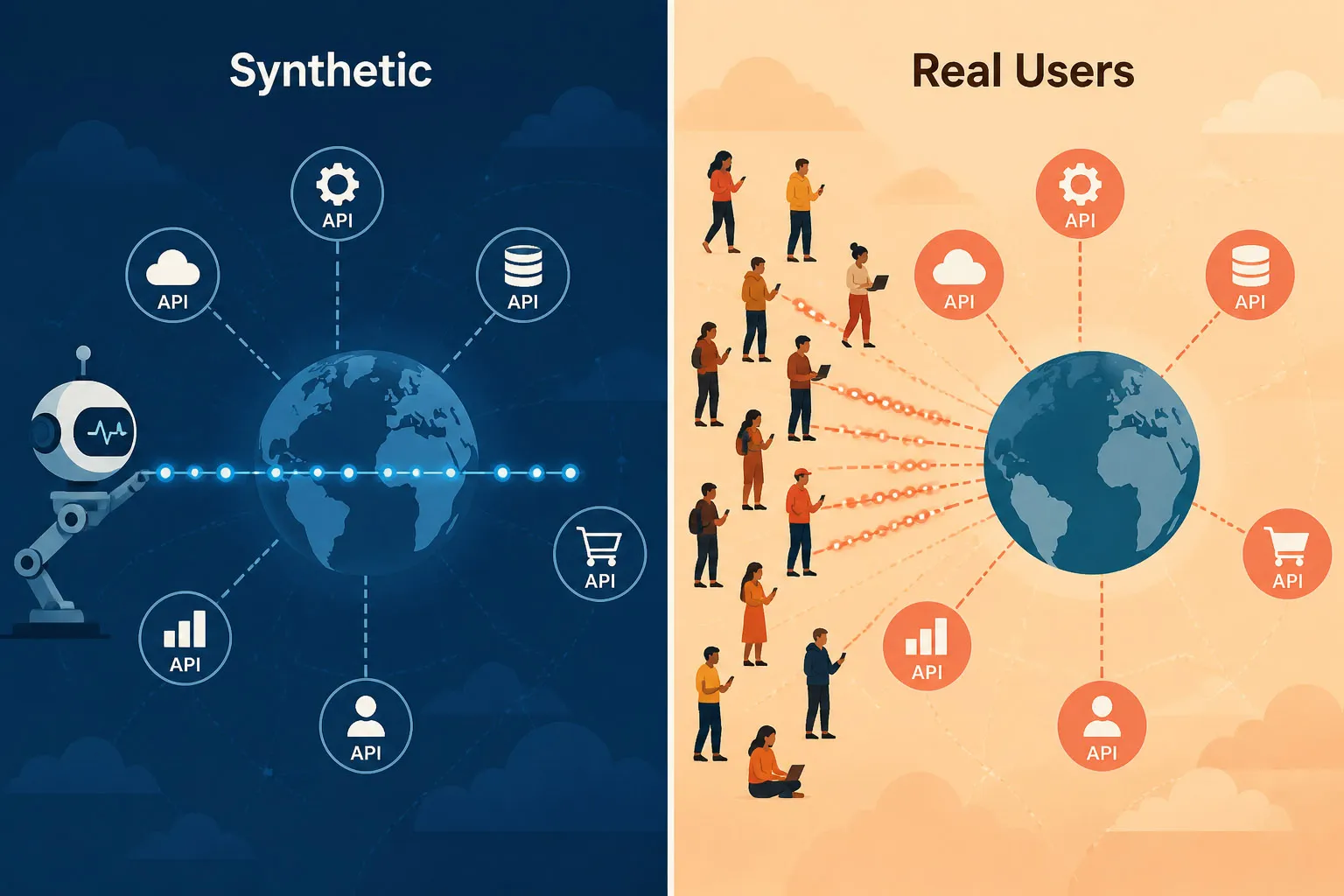
双方はAPIパフォーマンスデータを提供しますが、根本的に異なる観点から見ています:
| シンセティックモニタリング | リアルユーザーモニタリング (RUM) | |
|---|---|---|
| トリガー | スケジュールされたスクリプトチェック(例: 1分ごと) | 実際のプロダクションユーザーリクエスト |
| カバレッジ | 24時間365日稼働、ゼロユーザー時も実行 | ユーザーがアクティブにリクエストしている時のみデータ生成 |
| 検出 | 積極的 – ユーザー影響前に障害を検出 | 反応的 – 既に影響が出た後に問題を発見 |
| スコープ | パブリック及びプライベート/内部API(プライベートエージェント経由) | 実際のユーザー/クライアントが到達するAPI — 主にパブリック向け、ただしエンタープライズRUMではインストルメント化されたアプリから内部API呼び出しも捕捉可能 |
| 利用ケース | 継続的な可用性とパフォーマンス検証 | 真の影響範囲とユーザー体験の理解 |
主なAPIモニタリング指標
適切な指標を追跡することが、インシデント対応の質とアラート疲労の違いを生み出します。重要な指標とその目標値、捉えるべき内容を示します。
| 指標 | 目標/ベンチマーク | 検出内容 |
|---|---|---|
| 可用性 (稼働率 %) | ≥ 99.9%(三つの9);収益重要APIは99.99% | 完全な停止、部分的停止、タイムアウト |
| 合計応答時間 | 単純なエンドポイントは< 200ms; 複雑な操作は< 1秒 | サーバー遅延、過負荷、デプロイ失敗 |
| TTFB(最初のバイトまでの時間) | 理想は< 100ms; 許容は< 300ms | レスポンス開始までのサーバ処理遅延 |
| P95 / P99応答時間 | エンドポイント基準のP95の2倍超でアラート; エンドポイントの振る舞いに合わせて調整 | 遅い1~5%のリクエストに影響する尾部遅延 |
| エラーレート (4xx / 5xx) | 本番APIで< 0.1% | 認証失敗、不正入力処理、サーバーエラー |
| DNS解決時間 | 同一地域のキャッシュ済み検索で< 50ms; 地域間は100ms超もあり | DNS伝播問題、リゾルバ故障 |
| TLSハンドシェイク時間 | < 100ms | 証明書設定誤り、TLSバージョン問題 |
| ペイロードアサーション合格率 | 100%(失敗時にアラート) | HTTP 200でも誤ったまたは欠落したデータによるサイレントな失敗 |
| スループット(リクエスト/秒) | 過去のベースラインと比較 | 予期しないトラフィック減少や異常スパイク |
| 証明書有効期限(日数) | 30日でアラート、7日で重大アラート | TLS証明書の有効期限切れ間近 |
応答時間ベンチマーク
APIモニタリングの仕組み
技術的な動作原理を理解すると、監視設定や結果解釈が適切に行えます。
コアモニタリングループ
- スケジューリング。 シンセティックチェックが設定された間隔(例:1分毎)で選択されたグローバルロケーションから実行されます。
- リクエスト送信。 モニタリングエージェントはターゲットエンドポイントにHTTPリクエストを送信します — HTTPメソッド(GET、POST、PUT、PATCH、DELETE)、リクエストヘッダー、認証資格情報、リクエストボディを含みます。
- タイミング計測。 エージェントはDNS解決時間、TCP接続時間、TLSハンドシェイク時間、TTFB、合計応答時間を個別のコンポーネントとして記録します。
- アサーション。 レスポンスが設定されたアサーション(HTTPステータスコード、応答時間閾値、レスポンスヘッダー、JSONPath(REST)またはXPath(SOAP)によるペイロード内容)に対して評価されます。
- アラートまたは合格。 いずれかのアサーションが失敗するか、リクエストがタイムアウトするとインシデントが作成され、設定された通知ルールに基づいてアラートが送信されます。
- 記録。 結果(合格・失敗問わず)はタイムスタンプ、応答データ、アサーション結果と共に保存され、履歴トレンドとSLA報告に利用されます。
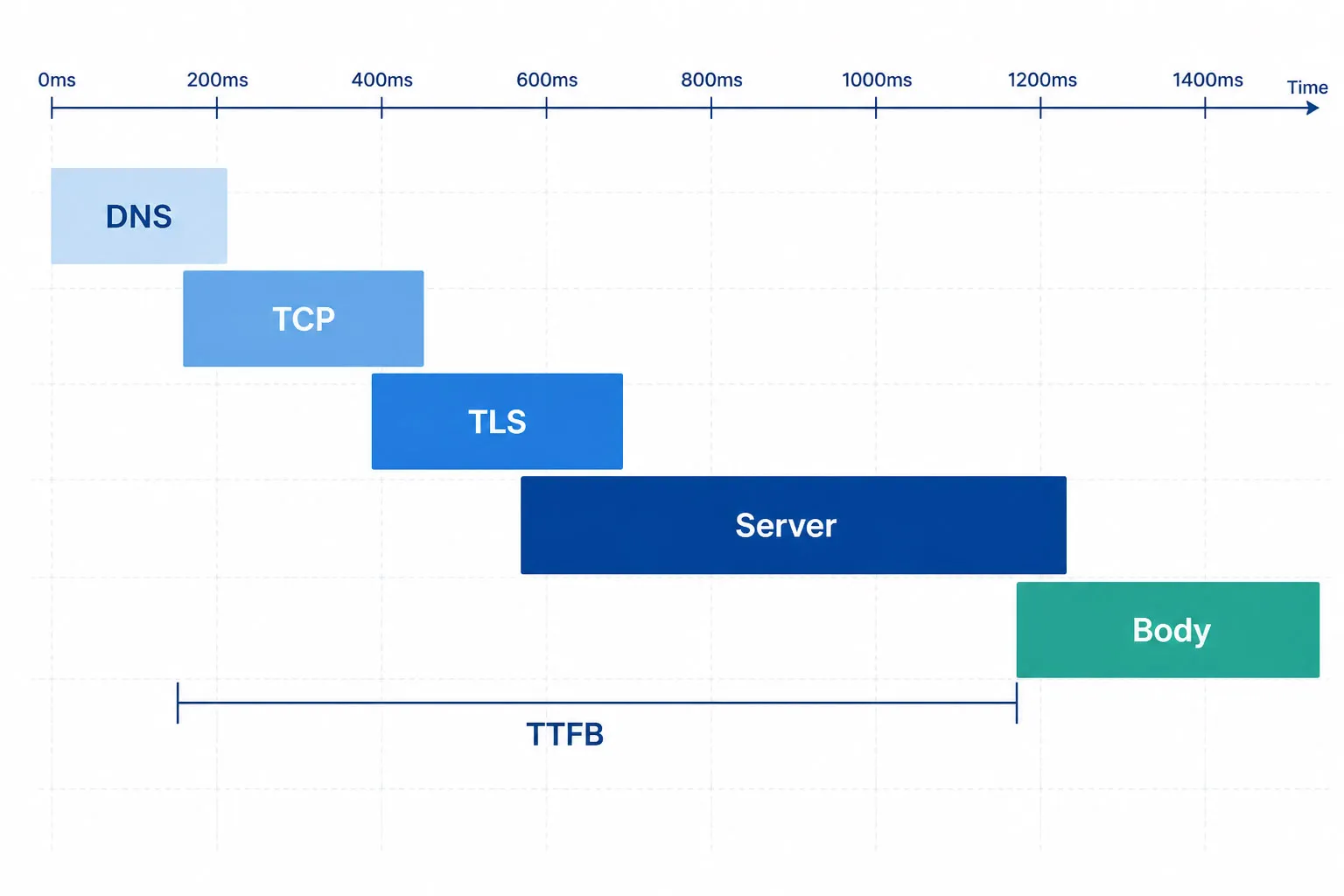 HTTPリクエストの各段階。TTFBはDNS、TCP、TLS、サーバ処理を含みますが、ボディ転送は含みません。TTFBが速くボディ転送が遅い場合はペイロードが大きいことを示し、TTFBが遅くボディ転送が速い場合はサーバ側処理が遅いことを示します。
HTTPリクエストの各段階。TTFBはDNS、TCP、TLS、サーバ処理を含みますが、ボディ転送は含みません。TTFBが速くボディ転送が遅い場合はペイロードが大きいことを示し、TTFBが遅くボディ転送が速い場合はサーバ側処理が遅いことを示します。
マルチステップAPIトランザクションモニタリング
 実際のユーザージャーニーは単一APIコールではありません。マルチステップ監視はAPIコールを連鎖させ、トークンやセッションID、注文IDなどの動的値を自動的に渡します。
実際のユーザージャーニーは単一APIコールではありません。マルチステップ監視はAPIコールを連鎖させ、トークンやセッションID、注文IDなどの動的値を自動的に渡します。
単一エンドポイント監視は個々のエンドポイントが応答するかを確認します。しかし実ユーザージャーニーは一連の連鎖したAPI呼び出しで構成され、各ステップは前の結果に依存します。
例:ECのチェックアウトフロー
- ステップ1 —
POST /auth/token: ユーザー認証。レスポンスからaccess_tokenを抽出 - ステップ2 —
GET /products/{id}: 商品詳細取得。Authorizationヘッダーにトークンを注入 - ステップ3 —
POST /cart/add: アイテム追加。レスポンスからcart_idを抽出 - ステップ4 —
POST /checkout/initiate:cart_idでチェックアウト開始。レスポンスからcheckout_session_idを抽出 - ステップ5 —
POST /payments/charge: 支払い処理。レスポンスのorder_statusが'confirmed'であることをアサート
単一エンドポイント監視では5ステップすべてが個別に成功する可能性がある一方、ジャーニー全体では失敗することがあります(例:ステップ間のセッションデータが正しく渡らない、トークン期限切れ、HTTP 200ながらエラーフィールドを返す支払いAPIなど)。マルチステップ監視は一つの監視タスクとしてチェーン全体を実行し、各ステップを独立して検証、動的値を自動的に渡します。
Dotcom-Monitorはマルチステップトランザクションモニタリングをサポートし、複数APIコールを連鎖させた単一監視タスクを作成可能。各ステップは独立してアサートされ、障害の起きた正確なステップを特定できます。
ペイロード検証:JSONPathとXPathアサーション
ペイロード検証は単なる可用性確認から監視を区別します。アサーション表現はツールにより異なりますがロジックは一貫しています:
- JSONPathフィールドアクセス(REST):
$.data.statusにアクセスし、返された値が'active'と等しいことをアサート - JSONPath配列チェック:
$.itemsにアクセスし、配列長が0より大きいことをアサート - XPathアサーション(SOAP):
//order/status/text()にアクセスし、ノード値が'confirmed'と等しいことをアサート - ヘッダーアサーション:
Content-Typeヘッダー値が'application/json'であることをアサート - 応答時間アサーション: 合計応答時間が500ms未満であることをアサート
認証モニタリング
本番APIは認証が必要です。監視ツールは実際のAPIクライアントと同じ認証方式に対応すべきです。主な認証方式は以下の通りです:
| 認証方式 | 説明 | 備考 |
|---|---|---|
| OAuth 2.0 — クライアント認証情報 | 機械間通信;クライアントはトークンと引換に認証情報を送信 | サーバ間APIモニタリングで最も一般的 |
| OAuth 2.0 — 認可コード | ユーザーデリゲート認可;SPAs/モバイルにPKCEを使用 | トークン自動更新に対応が必要 |
| OAuth 2.0 — リソースオーナーパスワード(ROPC) | 直接的なユーザー名とパスワード交換—レガシーフロー | 認可コード利用不可の状況での限定使用 |
| ベアラートークン(JWT) | Authorizationヘッダー内の静的または動的更新トークン |
短命なJWTは自動トークン更新必須 |
| APIキー | ヘッダー、クエリパラメータ、クッキー内の静的キー | 最も簡単に監視可能。ローテーションイベントに注意 |
| 基本認証 | username:passwordをBase64エンコードしてAuthorizationヘッダーに格納 |
レガシーだが企業や内部APIでまだ使用される |
| AWS署名v4 | AWS認証情報でHMAC署名されたリクエスト | AWS API Gatewayエンドポイントに必須 |
| mTLS / クライアント証明書 | 相互TLS—両者が証明書を提示 | ゼロトラスト環境;証明書有効期限の監視が重要 |
| NTLM / Kerberos | Windows/Active Directory連携認証 | 企業内APIで利用;クラウドネイティブでは少ない |
| カスタムヘッダー | 独自認証スキームをリクエストヘッダーで実装 | 非標準認証の包括対応 |
トークン期限切れは監視の誤検知原因の筆頭です。OAuth 2.0アクセストークンの寿命は実装や付与タイプで大きく異なります。ユーザーデリゲートトークン(認可コードフロー)は通常15分~1時間。機械間トークン(クライアント認証情報フロー)は1時間~24時間と長めに設定されることが多く、更新オーバーヘッドを減らします。高セキュリティ環境では5分程度の短い寿命を強制することもあります。自動トークン更新に対応しない監視ツールは誤検知を生み、手動での資格情報ローテーションが必要となり、運用負荷と障害リスクを増大させます。
OAuth 2.0インプリシットグラントは現在のOAuth 2.0セキュリティベストプラクティス(RFC 9700)で非推奨です。既存APIがこれを使っている場合は、認可コード + PKCEへの移行を強く推奨します。
APIモニタリングの重要性:ビジネスへの影響
APIは単なるインフラの抽象化ではなく、収益経路です。失敗すると財務、運用、契約に影響を及ぼします。
検知されないAPI障害のコスト
積極的監視がない場合、チームは顧客からの報告に頼って障害を検出します。業界調査では、顧客報告による平均検知時間(MTTD)は30分を大きく超えます。苦情の受付、調査、トリアージ、エスカレーションを経る間にその時間は過ぎています。1分間隔の連続シンセティック監視は検知時間を60秒以下に短縮し、問題が複雑化する前に根本原因の特定を可能にします。
収益計算式は単純です:注文数/分 × 平均注文額 × 障害継続時間(分)。例えば1分間に100注文、平均50ドルのプラットフォームは、5分間の決済API障害で25,000ドルの潜在収益損失となります。自身のスループットと注文額を当てはめてリスクを把握しましょう。
業界別シナリオ
- EC:ピーク時のチェックアウトAPI障害は全コンバージョンを停止。HTTP 200を返しつつ却下ステータスの決済認可APIは、数分間取引を静かにブロックし誰にも気づかれません。
- FinTech:秒未満の遅延SLAを満たす必要があり、SLA超過の持続的劣化はPCI DSSの契約違反や監査指摘につながります。
- ヘルスケア:EHR統合APIや遠隔医療エンドポイントはHIPAA準拠のデータ交換を保つ必要があり、HTTP 200で患者データが不完全な場合はパフォーマンス問題ではなくコンプライアンス問題となります。
- SaaS / API-as-a-Product:API自体が課金プロダクトの場合、ダウンタイムはSLA違反罰金や顧客解約を招きます。監視はSLA遵守報告に必要な稼働時間の根拠を提供します。
- エンタープライズIT:CRM、ERP、HR API統合が複数部門にまたがる中、Salesforce APIの劣化が全社的な営業ワークフローに影響してもログに500エラーが1件も現れないことがあります。
サードパーティAPIリスク
現代アプリは自社で管理しない外部APIに依存します:決済ゲートウェイ(Stripe、PayPal、Braintree)、IDプロバイダー(Okta、Auth0、AWS Cognito)、配送API、CRMなど。これらが劣化すると、自社インフラは正常でもユーザーにはサービス停止に見えます。
サードパーティエンドポイントの監視により、障害が内部起因か外部起因か即座に切り分け可能となり、通常長時間を要する調査が大幅に短縮されます。また、ベンダーに対するSLA遵守を証明する証拠も得られます。
顧客からAPI障害を知るのをやめましょう。
Dotcom-MonitorのシンセティックAPIモニタリングは60秒以内に障害を検出し、PagerDuty、Slack、Microsoft Teamsへ直接アラートを送信します。決済ゲートウェイ、IDプロバイダー、内部APIを1つのプラットフォームで監視可能です。
APIモニタリングとAPIテストの違い
両者はAPI挙動を検証しますが、ソフトウェア開発ライフサイクルで異なる役割を担います。混同すると監視対象に抜けが生じます。
| 観点 | APIテスト | APIモニタリング |
|---|---|---|
| 実行時期 | デプロイ前 — 開発、QA、CI/CDパイプライン内 | デプロイ後 — 本番環境で継続的に実施 |
| 環境 | 開発、ステージング、制御されたテスト環境 | 実際の本番環境、実インフラ、実トラフィック |
| トリガー | コードコミット、ビルド、手動実行、PRゲート | スケジュール実行(例:1分毎)、24/7継続 |
| 目的 | 本番へのバグ流出防止 | 本番環境での障害、劣化を検出 |
| カバレッジ | すべての振る舞い、エッジケース、エラーパス | 重要経路、SLAエンドポイント、ユーザージャーニーのチェーン |
| 視点 | 内部から外をテスト—コードの振る舞いを検証 | 外部から内部を検証—ユーザー視点で検証 |
| 成果物 | 合否レポート。失敗でデプロイ停止 | リアルタイムアラート、稼働率記録、インシデント履歴 |
実際の関係性は、APIテストは開発段階の作業、APIモニタリングは運用段階の作業です。テストはデプロイ前にバグを捕捉し、防止。モニタリングは本番環境で障害や回帰、パフォーマンス劣化、依存関係問題を検出します。
成熟したエンジニアリングチームは両方を実施し、Postmanコレクションのインポートで開発用テストから生産監視へシームレスに橋渡しし、リクエスト定義の重複をなくしています。
APIモニタリングとAPMの違い
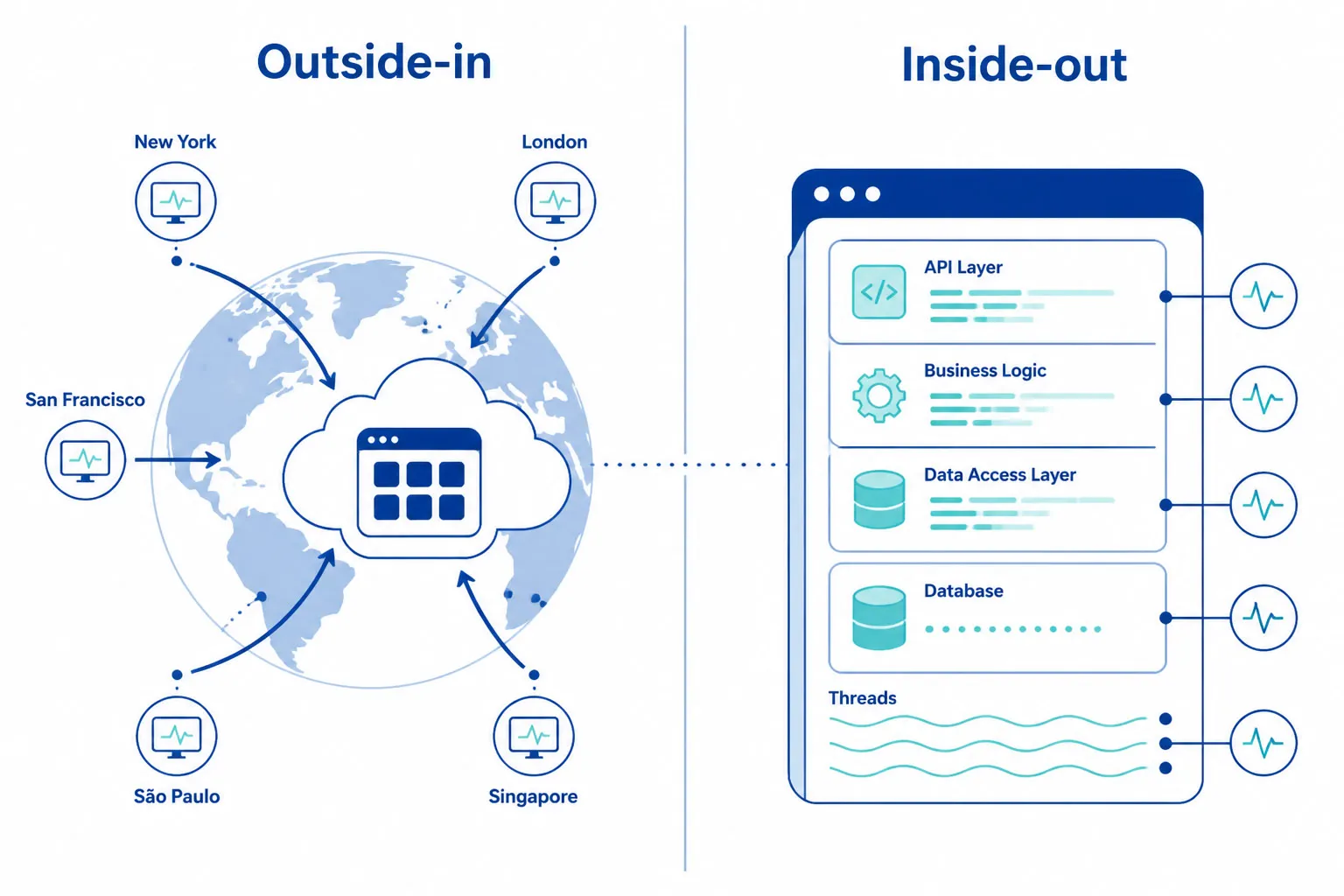 シンセティックAPIモニタリングは顧客の見ているものを確認し、APMはコード内部の挙動を観察します。両者は補完的であり、置き換え可能ではありません。
シンセティックAPIモニタリングは顧客の見ているものを確認し、APMはコード内部の挙動を観察します。両者は補完的であり、置き換え可能ではありません。
これらはよく混同されがちですが補完的関係であり、互換ではありません。
| シンセティックAPIモニタリング | APM (アプリケーションパフォーマンスモニタリング) | |
|---|---|---|
| 視点 | 外部から内を見る—ユーザーと同じ視点で検証 | 内部から外を見る—アプリケーションの内部挙動を観察 |
| 見る対象 | DNS障害、ネットワーク経路問題、TLSエラー、CDN誤ルーティング、地域的カバレッジギャップ | 遅いDBクエリ、メモリリーク、例外、遅い関数呼び出しなどコード内部 |
| 実行タイミング | 24時間365日—トラフィックゼロ時も実行 | 実リクエスト処理時のみ |
| 問う質問 | 「今このAPIを顧客は実際に呼べるか?」 | 「リクエスト時にアプリ内部では何が起きているのか?」 |
最低のMTTRを持つチームは両方を使います:APMは内部の根本原因分析に、シンセティックAPIモニタリングは外部からの検証に。ログとトレースは「コード内部で何が悪かったか」を答え、シンセティック監視は「顧客は今このAPIを使えるか」を答えます。
APIプロトコル:REST、SOAP、GraphQL、gRPC、WebSocket
各APIプロトコルは監視要件や障害特性が異なります。すべてのAPIを単純なHTTP GETとみなす監視ツールはプロトコル固有の問題を見逃します。
REST APIモニタリング
RESTは主流のAPIプロトコルです。監視ではHTTPメソッド(GET, POST, PUT, PATCH, DELETE)、ステータスコード、レスポンスヘッダー、JSONレスポンスボディをJSONPathアサーションで検証します。重要要件は、ステータスコードだけでなくレスポンスペイロードのフィールド値をアサートし、全HTTPメソッドを監視し(特にGET以外は異なる処理と障害モードを持ち)、エンドポイントごとに応答時間を個別管理し平均でまとめないことです。
SOAP APIモニタリング
SOAP APIはHTTP上のXML交換です。監視要件は、エンドポイントやスキーマを定義するWSDLのインポート、XPathによるXMLレスポンスの要素検証、SOAP 1.1と1.2のサポート、メッセージレベルセキュリティ用のEnterprise WS-Security設定対応です。
GraphQL APIモニタリング
GraphQLの主要な監視上の課題は、大多数のGraphQLサーバ実装が部分的なエラーや構文エラーでもHTTP 200を返す点です。HTTPステータスは信頼できる障害信号ではありません。対策は次の通りです:
- 特定のクエリペイロードを送り、レスポンスの
dataオブジェクトをアサート - レスポンスボディ内の
errors配列を確認 — 標準GraphQLでは、成功ならトップレベルのerrorsフィールドは空か無し、失敗なら populated。HTTP 200でerrors[]がある場合は、HTTPは成功してもGraphQLレイヤーで失敗 - クエリ固有のデータ不変条件を検証:期待フィールドが存在し、nullでなく、正型であることをアサート。データオブジェクトにドメインエラーを格納しトップレベル
errorsに載せない設計もある - クエリの複雑度と深さ制限を監視し、パフォーマンス劣化がタイムアウト前に分かるようにする
gRPC APIモニタリング
gRPCはデフォルトでHTTP/2上のProtocol Buffersを使用しますが、gRPC-Webはブラウザクライアント向けにHTTP/1.1プロキシを使います。監視要件は、サービスとメソッド定義用のprotoファイルインポート、Protocol Bufferメッセージのバイナリエンコード/デコード対応、ステータスコード検証はHTTPではなくgRPCステータスコード(OK、UNAVAILABLE、DEADLINE_EXCEEDEDなど)を利用、Unary、Server-Streaming、Client-Streaming、Bidirectional-StreamingのRPCタイプ対応です。
WebSocket APIモニタリング
WebSocket APIはリアルタイムデータのため双方向の持続接続を維持します。監視は接続確立時間、ハンドシェイク成功、メッセージ遅延およびペイロード正確性、接続安定性を長時間にわたり評価し、切断後の再接続動作も検証します。
パブリックAPIモニタリングと内部APIモニタリング
 プライベートエージェントはネットワーク内で動作し、監視プラットフォームへアウトバウンド接続を開始します—インバウンドのファイアウォール規則は不要です。これにより、内部マイクロサービスにもパブリックAPIと同じ高精度な監視が可能になります。
プライベートエージェントはネットワーク内で動作し、監視プラットフォームへアウトバウンド接続を開始します—インバウンドのファイアウォール規則は不要です。これにより、内部マイクロサービスにもパブリックAPIと同じ高精度な監視が可能になります。
多くのAPIモニタリングガイドはパブリック向けエンドポイントだけを対象とします。しかしマイクロサービスアーキテクチャでは、重要なAPI呼び出しの大部分は内部—サービス間通信であり、パブリックインターネットには到達しません。
| パブリックAPIモニタリング | 内部APIモニタリング | |
|---|---|---|
| 対象範囲 | 顧客向けエンドポイント、パートナーAPI、サードパーティ統合 | 内部マイクロサービス、プライベートVPC、ステージング環境、ファイアウォール内API |
| 動作方法 | 外部監視エージェントがグローバルロケーションからパブリックインターネット経由でチェック | ネットワーク内に配置したプライベートエージェントがアウトバウンド接続で監視プラットフォームへ通信 |
| ファイアウォール要件 | 不要 — チェックは外部発信 | 不要 — エージェントはアウトバウンド接続のみ |
| 検出できる障害 | DNS障害、CDNルーティング問題、TLSエラー、地域的可用性の不均衡 | サービス間障害、認証マイクロサービスの遅延、DBクエリAPIの劣化 |
| 導入形態 | インストール不要、即時利用可能 | オンプレまたはプライベートクラウドにエージェントをインストール(Windows/Linux対応) |
内部マイクロサービスAPIはカスケード障害の最も一般的な発生源です。認証サービスの劣化や遅延するデータアクセスAPIはフロントエンド障害として表れ、根本原因の特定が困難です。内部API監視で障害がAPI層、下流のマイクロサービス、またはDBにあるかを切り分け可能です。詳しくはファイアウォール内でのプライベートエージェント監視をご覧ください。
APIモニタリングのベストプラクティス
これらの実践は検知時間(MTTD)を短縮し、アラートの精度を高め、監視範囲が生産リスクに見合うようにします。
- 収益に重要なエンドポイントは1分間隔で監視。 決済、認証、コアデータAPIは未検知の1分でも直接ビジネス影響あり。重要度が低い場合は5分や15分間隔も許容。
- 少なくとも5か所の地理的に分散した場所からチェックを実施。 1つの監視拠点では地域DNS障害、CDN誤設定、地理特有のルーティング障害を検出できません。北米、欧州、アジア太平洋は最低限含めます。
- ステータスコードだけでなくペイロード内容も検証。 重要なエンドポイントにはJSONPathアサーションを設定。HTTP 200でも不完全、古い、不正なデータを返すサイレント障害が最も費用が嵩みます。
- 固定のミリ秒値ではなくベースラインに基づく閾値でアラートを設定。 エンドポイントごとに応答時間のベースラインを作成し、P95の2倍をアラート閾値にします。固定閾値は通常トラフィックのピークで誤報が増加します。
- 監視チェーンに認証を含める。 トークン期限切れ、OAuth更新失敗、証明書ローテーションはAPI障害の主要要因。認証ステップを監視し資格情報問題を早期に検知。
- 重要なユーザージャーニーはマルチステップ取引監視を構築。 ログインフロー、チェックアウト連続など連鎖API呼び出し。単一エンドポイント監視はステップ間のデータ受け渡し問題を検知不能。
- サードパーティAPI依存は個別の監視を設定。 Stripe、Okta、Salesforceなどの外部依存監視を作成し内部起因か外部起因か即答可能に。
- PostmanやInsomniaコレクションをインポートして監視開始。 既存のAPI定義を24/7の本番監視にそのまま転用し、リクエスト構造を再作成不要に。
- CI/CDパイプラインに監視チェックを統合。 デプロイ後にシンセティックAPIチェックをスモークテストとして自動実行。失敗時は自動ロールバックや段階的配信停止を検討。2ロケーション確認で誤報を減らします。
- PagerDuty、Slack、Microsoft Teamsへエスカレーションポリシー付きでアラートを送信。 Eメールのみの通知は遅延を招く。ネイティブ連携で即時に正しい担当者へ伝達。
APIモニタリングの課題
運用的な難点も多いですが、それを踏まえた設計が重要です。
サードパーティAPIの可視性
外部依存の可用性と遅延データは得られても、内部原因特定は困難です。StripeやOktaの劣化は検出可能ですが、根本原因分析はベンダーステータスページや支持エスカレーションに依存します。
レート制限
モニタリングエージェントのリクエストはAPIのレート制限対象となります。総リクエスト数は 拠点数 × 時間あたりチェック数 × 1監視タスクのAPI呼び出し回数 × 確認リトライ数 で算出。単一エンドポイントでは30拠点×60チェック=1,800リクエスト/時、5段階取引監視なら30×60×5=9,000リクエスト/時。内部APIは制限が厳しいことが多く、IPレンジのホワイトリスト化も検討が必要です。
認証の複雑さ
短命トークンは自動更新対応が必須。ユーザーデリゲートトークンは15分~1時間、機械間トークンは1~24時間、最高セキュリティ環境では5分もあり得ます。証明書認証やAPIキーのローテーションも慎重な管理が必要です。
動的かつ非決定的レスポンス
タイムスタンプ入りデータ、ページング結果、ランダム順序配列は厳密な値アサーションが難しいです。構造やフィールド有無、型を検証するJSONPath表現を使いましょう。
アラート疲労
重要エンドポイントを1分間隔で大量監視、または閾値を厳しくすると誤報が増え、本当の障害を無視してしまいます。重要経路を1分間隔、非重要エンドポイントは5~15分間隔に分け、二次ロケーションの確認で誤報を排除しましょう。
プロトコル多様性
REST、SOAP、GraphQL、gRPC、WebSocketはそれぞれ異なるアサーション方式が必要。RESTのみ対応のツールではSOAP障害を見逃し、GraphQLのHTTP 200エラーを成功と誤判定します。
Dotcom-MonitorでのAPIモニタリング設定方法
 チェック失敗時、アラートは誰も見ない監視専用受信箱ではなく、既存のインシデント対応ツールにルーティングされます。
チェック失敗時、アラートは誰も見ない監視専用受信箱ではなく、既存のインシデント対応ツールにルーティングされます。
Dotcom-MonitorはREST、SOAP、GraphQLの合成API監視を30以上のグローバルリージョンから1分間隔で実施、多段トランザクション対応、PagerDuty、Slack、Microsoft Teamsとネイティブ連携します。
ステップ1 — エンドポイントとアサーションを定義
- エンドポイントURL: 監視対象APIのURL
- HTTPメソッド: GET、POST、PUT、PATCH、DELETE
- リクエストヘッダー:
Content-Type、Authorization、任意のカスタムヘッダー - リクエストボディ: POST/PUTリクエスト向けJSONペイロード
- 認証: OAuth 2.0、ベアラートークン、APIキー、基本認証、mTLS、AWS署名v4、NTLM、Kerberos、カスタムヘッダー
- アサーション: HTTPステータスコード、応答時間閾値、ヘッダー値、JSONPath/XPathペイロードアサーション
ステップ2 — PostmanまたはInsomniaからインポート
チームがPostmanまたはInsomniaを使っている場合は手動設定をスキップ可能です:
- Postman: v2.0またはv2.1 JSON形式でコレクションをエクスポートし、Dotcom-Monitorへインポート。リクエスト定義、ヘッダー、ボディ、環境変数、テストアサーションが保持されます。
- Insomnia: ワークスペースをInsomnia v4 JSONでエクスポートし、Dotcom-Monitorへインポート。リクエストグループ、認証設定、環境変数が保持されます。
両者のインポート形式は開発段階のテスト定義をフル稼働の継続監視に変換可能です。
Postmanユーザーなら5分で24/7本番監視が始められます。
既存のPostmanコレクションを直にDotcom-Monitorへインポートしてください。リクエスト定義、ヘッダー、環境変数、アサーションがそのまま引き継がれます—再設定は不要です。
ステップ3 — 監視ロケーションと頻度を設定
- チェック頻度: 1分、3分、5分、15分間隔からエンドポイント重要度に応じて設定
- 監視ロケーション: 北米、欧州、アジア太平洋、南米を含む30以上のロケーションから選択
- プライベートエージェント: 内部またはファイアウォール内API向け。オンプレまたはプライベートクラウドにエージェントを配置(Windows/Linux対応)。アウトバウンド接続のみで、インバウンドのファイアウォール設定不要。
- 確認リトライ: アラート発生前に二次ロケーションでの確認チェックを設定し、一時的な誤報を排除
ステップ4 — アラートルーティングを設定
- PagerDuty: 重要アラートをオンコールスケジュールへ直接送信、自動インシデント作成とエスカレーション対応
- Slack / Microsoft Teams: チャネルにエンドポイント詳細、エラー種類、レスポンスデータ付きアラート投稿
- メール、SMS、電話: 個別連絡先やチーム別通知設定
- Webhook: OpsGenie、ServiceNow等、HTTP互換サービスと連携
- 閾値設定: 指標別に応答時間、エラーレート、アサーション失敗率を重症度別に設定
ステップ5 — CI/CDパイプライン連携
- Dotcom-Monitor REST API: HTTP API経由で監視タスクの作成、更新、実行をプログラム制御可能
- GitHub Actions / Azure DevOps / Jenkins: デプロイ後にDotcom-Monitorチェックをトリガーし結果待機。アサーション失敗でパイプライン失敗に設定可
- プレプロダクション検証: ステージング環境で同様のシンセティックチェックを実行し、ユーザー影響前に回帰検出
業界別APIモニタリング活用例
| 業界 | 監視対象の重要API | 主要な監視要件 |
|---|---|---|
| EC | チェックアウト、決済認可、在庫、配送、カート管理 | マルチステップトランザクションチェーン;1分間隔;決済確認状況のペイロード検証 |
| FinTech / 銀行 | 取引処理、KYC/AML検証、残高、為替、送金API | 200ms未満の遅延SLA;PCI DSS証拠を支えるコンプライアンスチェック;フル認証フロー検証 |
| ヘルスケア | EHR統合(HL7 FHIR)、保険ポータル、遠隔医療エンドポイント、患者スケジューリング | HIPAA対応のコンプライアンスチェック;データ完全性のペイロード検証;99.99%稼働率SLA |
| SaaS | コア製品API、Webhook配信エンドポイント、パートナー統合API、認証API | API-as-a-ProductのSLA遵守;Postmanインポートで開発と監視の整合性;サードパーティ依存監視 |
| エンタープライズIT | CRM、ERP、HRIS、IDプロバイダー、社内ワークフロー自動化API | ファイアウォール内API向けプライベートエージェント;NTLM/Kerberos認証対応;部門横断API可視化 |
| メディア / ゲーム | CDNコンテンツ配信API、認証、リアルタイムスコアリング、ソーシャル機能API | 地理的分散監視;WebSocket接続監視;トラフィックスパイク検出 |
今日からAPIを監視開始しましょう。
Dotcom-Monitorは30以上のグローバルロケーションからのシンセティックAPI監視を提供し、1分間隔、多段トランザクション対応、PagerDuty、Slack、Microsoft Teamsとのネイティブ連携あり。設定は5分未満で完了。30日間の無料トライアルにはクレジットカード不要です。
