 Pour de nombreuses équipes, la surveillance de l’uptime des API signifie encore une chose simple : vérifier si un endpoint répond avec un code 200 OK. Si le test réussit, l’API est considérée comme « disponible ». S’il échoue, une alerte est déclenchée. Sur le papier, cela semble raisonnable. En pratique, c’est l’une des raisons les plus courantes pour lesquelles des pannes d’API passent inaperçues jusqu’à ce que les utilisateurs se plaignent.
Pour de nombreuses équipes, la surveillance de l’uptime des API signifie encore une chose simple : vérifier si un endpoint répond avec un code 200 OK. Si le test réussit, l’API est considérée comme « disponible ». S’il échoue, une alerte est déclenchée. Sur le papier, cela semble raisonnable. En pratique, c’est l’une des raisons les plus courantes pour lesquelles des pannes d’API passent inaperçues jusqu’à ce que les utilisateurs se plaignent.
Le problème est que les API modernes ne sont plus de simples endpoints sans état. Elles reposent sur de nombreux éléments interdépendants, notamment :
- Les flux d’authentification et d’autorisation
- Les bases de données et les tâches en arrière-plan
- Les services tiers et les API externes
- Une infrastructure et un routage spécifiques aux régions
En raison de cette complexité, une API peut renvoyer un code de statut de succès tout en échouant de manière significative. La réponse peut contenir des données incomplètes, des valeurs obsolètes ou des résultats logiquement incorrects. Du point de vue du tableau de bord de surveillance, tout semble sain. Du point de vue de l’utilisateur, l’API est pratiquement indisponible.
Ce décalage crée ce que de nombreuses équipes perçoivent comme un faux uptime. Les vérifications basiques de disponibilité sont efficaces pour répondre à une question technique très limitée :
- La surveillance de l’uptime des API confirme qu’une API est accessible, rapide et renvoie des résultats corrects.
- Un simple « 200 OK » peut masquer des défaillances silencieuses (payloads incorrects, échecs d’authentification, données partielles).
- L’uptime en production doit inclure des transactions multi-étapes et des vérifications multi-régions.
C’est pourquoi la surveillance de l’uptime des API nécessite une définition plus large. Elle doit prendre en compte la disponibilité, l’exactitude et la performance du point de vue de l’utilisateur, et non uniquement la capacité du serveur à répondre.
Les temps d’arrêt réels ne sont pas théoriques ; ils ont un impact financier mesurable. Selon Gartner, une panne informatique moyenne coûte environ 5 600 $ par minute, soit près de 300 000 $ par heure pour de nombreuses organisations. Et selon des études indépendantes, plus de 90 % des entreprises de taille moyenne et grande déclarent des coûts horaires supérieurs à 300 000 $, dont 41 % indiquent que les pannes peuvent dépasser 1 million de dollars par heure. Ces pertes proviennent de transactions manquées, de pertes de productivité, de pénalités liées aux SLA et d’une atteinte à la confiance des clients, autant d’éléments que les contrôles basiques ne détectent souvent pas.
Dans ce guide, nous allons explorer ce que signifie réellement aujourd’hui la surveillance de l’uptime des API, pourquoi les approches courantes sont insuffisantes et comment les équipes peuvent concevoir des stratégies de surveillance qui reflètent l’usage réel. Ainsi, « API disponible » signifie réellement « API fonctionnelle ».
Ce que signifie réellement la surveillance de l’uptime des API aujourd’hui
À la base, la surveillance de l’uptime des API vise à répondre à une question simple : les consommateurs peuvent-ils compter sur cette API à l’instant T ? Le problème est que de nombreuses équipes définissent encore l’« uptime » de manière trop restrictive, en se concentrant uniquement sur la réponse d’un endpoint à une requête. Dans les systèmes modernes, cette définition ne tient plus.
Les API sont au cœur des architectures distribuées. Elles authentifient les utilisateurs, orchestrent les flux de travail et dépendent de multiples services internes et externes. De ce fait, l’uptime n’est plus un concept binaire. Une API peut être accessible tout en étant inutilisable.
La différence entre les vérifications basiques d’uptime et la surveillance moderne de l’uptime des API apparaît clairement lorsqu’on examine la manière dont la surveillance est réellement effectuée. Au lieu d’un simple ping depuis un emplacement unique, une surveillance efficace valide des flux de travail réels à partir de plusieurs régions et chemins de dépendance.
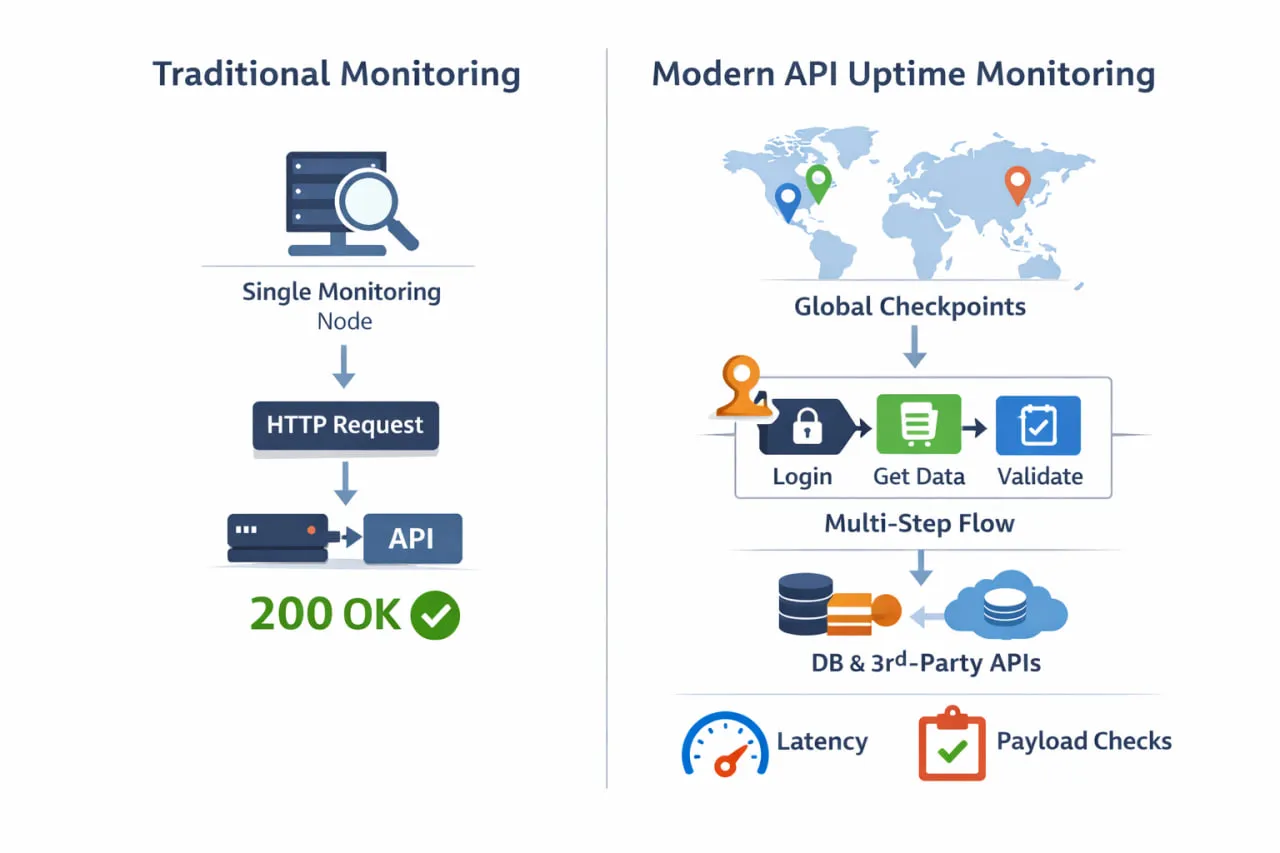
Une définition plus précise de l’uptime des API inclut trois dimensions tout aussi importantes :
- Disponibilité – L’API est-elle accessible depuis les emplacements des utilisateurs ?
- Exactitude – L’API renvoie-t-elle les données, la structure et les valeurs attendues ?
- Réactivité – L’API répond-elle dans des seuils de latence acceptables ?
Si l’un de ces éléments échoue, les utilisateurs subissent une indisponibilité, même si l’outil de surveillance affiche un uptime de 100 %.
C’est là que de nombreuses vérifications traditionnelles montrent leurs limites. Un test HTTP depuis une seule région peut confirmer qu’un endpoint renvoie un 200 OK, mais il ne dira pas si l’authentification échoue, si une dépendance en aval est en timeout ou si les utilisateurs d’une autre région subissent une dégradation des performances. Du point de vue de l’ingénierie, tout est au vert. De l’extérieur, l’API est défaillante.
Pour comprendre correctement l’uptime, la surveillance des API doit être alignée sur la manière dont les API sont réellement consommées. Cela signifie observer les API comme des systèmes, et non comme de simples endpoints. Cela implique également de relier la surveillance de l’uptime à des pratiques de fiabilité plus larges telles que les logs, le tracing et les métriques, des domaines souvent abordés sous le terme d’observabilité des API. Si l’observabilité fournit une visibilité interne approfondie, la surveillance de l’uptime joue un rôle complémentaire : valider ce que les utilisateurs réels vivent depuis l’extérieur.
Lorsqu’elle est correctement mise en œuvre, la surveillance de l’uptime des API agit comme un système d’alerte précoce. Elle détecte les défaillances avant que les utilisateurs ne les signalent, met en évidence des problèmes régionaux ou conditionnels et révèle des dysfonctionnements que les métriques internes seules peuvent manquer. Au lieu de répondre à « le serveur a-t-il répondu ? », elle répond à une question bien plus utile : l’API fournit-elle une valeur fiable à cet instant ?
Ce changement de définition constitue la base de tout ce qui suit. Une fois que l’uptime est envisagé sous l’angle de l’utilisabilité réelle, les limites des contrôles basiques deviennent évidentes, tout comme la nécessité de stratégies de surveillance plus robustes.
Pourquoi les vérifications basiques d’uptime échouent face aux API modernes
Les vérifications basiques d’uptime ont été conçues pour une époque plus simple, lorsque les applications exposaient un nombre limité d’endpoints prévisibles et que le succès pouvait être mesuré par un simple code de réponse. Les API modernes ne fonctionnent plus ainsi. Pourtant, de nombreuses configurations de surveillance reposent encore sur ces hypothèses obsolètes.
Les limites des vérifications basiques deviennent évidentes lorsqu’on les compare directement à une surveillance moderne de l’uptime des API, adaptée aux environnements de production.
| Capacité | Vérifications traditionnelles d’uptime | Surveillance moderne de l’uptime des API |
| Emplacement de surveillance | Région unique | Plusieurs régions mondiales |
| Ce qui est vérifié | Accessibilité de l’endpoint | Utilisabilité de bout en bout de l’API |
| Support de l’authentification | Rare ou inexistant | Support complet (tokens, en-têtes, OAuth) |
| Validation de la réponse | Code de statut uniquement | Payload, schéma, valeurs, logique |
| Surveillance des workflows | Non prise en charge | Flux multi-étapes / transactionnels |
| Prise en compte des dépendances | Aucune | Détection des défaillances en aval |
| Analyse des performances | Latence basique ou moyenne | Tendances, seuils, dégradations |
| Détection des défaillances silencieuses | ❌ Non détectées | ✅ Détectées précocement |
| Alignement avec l’expérience utilisateur | Faible | Élevé |
Les pings d’uptime traditionnels peuvent indiquer qu’un serveur est techniquement accessible, mais ils ne protègent pas contre des défaillances silencieuses coûteuses. Certaines analyses sectorielles estiment le coût moyen d’un downtime à près de 14 000 $ par minute, soit des centaines de milliers de dollars par heure pendant laquelle une API est dégradée, même si elle semble « disponible ».
L’un des modes de défaillance les plus courants est l’illusion du “200 OK”. Une API peut répondre avec succès au niveau HTTP tout en échouant au niveau de la logique métier. Par exemple, la réponse peut :
- Renvoyer un payload vide ou partiel
- Contenir des données obsolètes ou incorrectes
- Omettre des champs obligatoires ou violer les attentes de schéma
Pour une vérification traditionnelle d’uptime, cela ressemble à un succès. Pour les utilisateurs et les systèmes en aval, c’est une défaillance silencieuse.
L’authentification introduit un autre angle mort majeur. Les API reposent souvent sur des tokens expirables, des clés tournantes ou des accès basés sur les rôles. Une vérification basique qui ne simule pas entièrement les flux d’authentification ne détectera pas des problèmes tels que des identifiants expirés ou des autorisations mal configurées. L’endpoint est accessible, mais aucun consommateur réel ne peut l’utiliser.
Les dépendances aggravent encore le problème. La plupart des API s’appuient sur des bases de données, des files de messages et des services tiers. Si une dépendance en aval se dégrade ou échoue de manière intermittente, l’API peut toujours répondre, mais avec une latence accrue, des résultats partiels ou un comportement incohérent. Ce sont précisément les types de problèmes que les vérifications basiques détectent le moins bien.
La géographie ajoute une couche supplémentaire de complexité. De nombreuses vérifications d’uptime sont exécutées depuis un seul emplacement, souvent proche de l’infrastructure hébergée. Cela masque des problèmes régionaux causés par des défauts de routage, des pannes d’ISP ou des configurations CDN incorrectes. Des utilisateurs dans certaines régions peuvent subir des timeouts tandis que les tableaux de bord indiquent que tout va bien.
Ces limites expliquent pourquoi les équipes pensent souvent disposer d’une surveillance robuste de l’uptime des API, jusqu’à ce que les clients signalent des problèmes en premier. Ce qui manque, c’est une visibilité sur le comportement réel des API dans des conditions d’utilisation concrètes.
C’est pourquoi les stratégies modernes d’uptime combinent des vérifications d’accessibilité avec la capacité de valider l’exactitude des réponses API et de surveiller les tendances de latence des API à travers plusieurs régions, afin que les problèmes soient détectés en fonction de l’impact réel sur l’utilisateur, et non uniquement de la disponibilité du serveur.
Tant que la surveillance ne dépasse pas les simples vérifications d’accessibilité, les équipes continueront de manquer les problèmes les plus critiques.
Les métriques clés qui définissent le véritable uptime des API
Une fois dépassée l’idée que l’uptime signifie simplement « endpoint accessible », la question suivante s’impose : que doit réellement mesurer la surveillance de l’uptime des API ? Une surveillance efficace se concentre sur un ensemble restreint de métriques qui reflètent le comportement des API dans le monde réel, et non uniquement sur le papier.
1. Disponibilité (accessibilité)
La disponibilité répond à la question la plus fondamentale : l’API est-elle accessible depuis un emplacement donné ?
Cette métrique reste essentielle, mais elle ne constitue qu’un point de départ. Une API qui répond aux requêtes mais échoue autrement est techniquement disponible, mais pratiquement inutilisable.
2. Latence (réactivité)
La latence mesure le temps nécessaire à l’API pour répondre. Même lorsque les requêtes aboutissent, des réponses lentes sont perçues comme une indisponibilité par les utilisateurs. La surveillance doit suivre :
- Les temps de réponse par rapport à des seuils définis
- Les tendances de latence dans le temps, pas seulement les moyennes
Cela permet aux équipes de détecter une dégradation progressive des performances avant qu’elle ne se transforme en panne.
3. Exactitude des réponses
C’est ici que de nombreuses stratégies d’uptime échouent. L’exactitude se concentre sur ce que l’API renvoie, et non seulement sur le fait qu’elle renvoie quelque chose. En pratique, l’exactitude des réponses est validée à l’aide d’assertions.
Par exemple, les équipes peuvent vérifier la présence de champs obligatoires via JSONPath, confirmer que des valeurs numériques se situent dans des plages attendues ou vérifier que le schéma de réponse correspond à une structure définie. Ces contrôles garantissent qu’un 200 OK représente réellement un résultat réussi.
Sans validation des réponses, les tableaux de bord peuvent afficher un uptime de 100 % alors que les utilisateurs rencontrent des échecs.
4. Cohérence régionale
Les API sont consommées à l’échelle mondiale, mais les pannes sont souvent régionales. Des problèmes de routage réseau, des pannes d’ISP ou des défaillances d’infrastructure localisées peuvent affecter une zone géographique sans toucher les autres. Une surveillance depuis plusieurs emplacements garantit que l’uptime reflète la réalité des utilisateurs, et non seulement la proximité de l’infrastructure.
5. Comportement des erreurs
Toutes les défaillances ne se valent pas. Le suivi des types d’erreurs apporte un contexte essentiel aux données d’uptime :
- Les erreurs 401/403 signalent souvent des problèmes d’authentification
- Les erreurs de niveau 500 indiquent des défaillances côté serveur
- Les timeouts révèlent généralement des problèmes de performance ou de dépendances en aval
Lorsque ces métriques sont surveillées conjointement, l’uptime devient un véritable indicateur de fiabilité plutôt qu’un simple chiffre flatteur.
C’est pourquoi la surveillance réelle de l’uptime des API recoupe naturellement la surveillance des performances des API. Les tendances de performance, les contrôles d’exactitude et la visibilité régionale contribuent tous à déterminer si une API est réellement utilisable.
En se concentrant sur ces métriques clés, les équipes passent d’une surveillance réactive à une fiabilité proactive, détectent les problèmes plus tôt, réduisent la fausse confiance et alignent l’uptime sur l’expérience réelle des utilisateurs.
Associer l’uptime des API aux SLO et SLI
À mesure que les API mûrissent, l’uptime cesse d’être un pourcentage vague pour devenir un engagement de fiabilité. C’est là qu’interviennent les objectifs de niveau de service (SLO) et les indicateurs de niveau de service (SLI).
Au lieu de demander « l’API est-elle disponible ? », les équipes définissent l’uptime en termes d’expérience utilisateur mesurable :
- SLI de disponibilité – Les requêtes aboutissent-elles ?
- SLI de latence – Les réponses sont-elles suffisamment rapides ?
- SLI d’exactitude – Les réponses sont-elles précises et complètes ?
La surveillance de l’uptime des API alimente directement ces indicateurs. Les vérifications de disponibilité confirment l’accessibilité, le suivi de la latence met en évidence les ralentissements et la validation des réponses garantit que l’API se comporte correctement, non seulement sur le plan technique, mais aussi fonctionnel.
Un SLO définit ensuite les seuils acceptables pour chaque indicateur. Par exemple, une API peut viser :
- 99,9 % de réponses réussies
- 95 % des requêtes en moins de 300 ms
- Zéro échec de schéma ou de validation pour les endpoints critiques
Lorsque la surveillance de l’uptime est alignée sur les SLO, les alertes cessent d’être arbitraires. Elles signalent un risque réel pour la fiabilité perçue par l’utilisateur, et non simplement l’absence de réponse d’un serveur. L’uptime devient alors un outil d’aide à la décision qui guide les priorités d’ingénierie et la gestion des incidents.
Comment calculer le véritable uptime des API
Le véritable uptime des API ne se limite pas à vérifier si un endpoint répond. Il est calculé en fonction du nombre de requêtes qui réussissent réellement du point de vue de l’utilisateur.
La disponibilité est mesurée comme suit :
SLI de disponibilité = requêtes_bonnes / requêtes_totales
Une requête bonne est une requête qui :
- Renvoie un statut 2xx
- Passe les assertions de schéma et de réponse
- Respecte les seuils de latence
L’uptime doit être mesuré sur une fenêtre définie (par exemple, 28 jours glissants) et évalué par rapport à un SLO cible. La marge restante (1 − SLO) constitue le budget d’erreur.
Cette approche garantit que l’uptime reflète l’utilisabilité réelle, et non seulement l’accessibilité.
Comment concevoir une stratégie efficace de surveillance de l’uptime des API
Concevoir une stratégie efficace de surveillance de l’uptime des API ne consiste pas à multiplier les contrôles, mais à choisir les bons contrôles et à valider les bons résultats. L’objectif est de reproduire l’usage réel aussi fidèlement que possible, sans générer de bruit ni de zones d’ombre.
Commencer par les API les plus critiques
Tous les endpoints ne méritent pas le même niveau d’attention. Commencez par identifier les API les plus critiques pour les utilisateurs et pour l’activité. Il s’agit généralement :
- Des endpoints d’authentification et d’autorisation
- Des API transactionnelles clés ou génératrices de revenus
- Des API publiques ou partenaires avec des dépendances externes
Se concentrer sur ces API garantit que les métriques d’uptime reflètent l’impact réel, et non simplement la couverture de la surveillance.
Choisir la fréquence avec intention
Il peut être tentant de vérifier chaque endpoint toutes les quelques secondes, mais une fréquence plus élevée n’apporte pas toujours de meilleurs enseignements. Les intervalles de surveillance doivent être déterminés en fonction :
- De la rapidité de détection nécessaire des défaillances
- De la tolérance des utilisateurs aux interruptions courtes
- Du risque de fatigue liée aux alertes
Pour les API à fort impact, des contrôles fréquents sont justifiés. Pour les services moins critiques, des intervalles plus longs fournissent souvent un signal suffisant sans bruit inutile.
Surveiller les flux multi-étapes et transactionnels
La plupart des API modernes ne fonctionnent pas de manière isolée. Une seule action utilisateur déclenche souvent plusieurs appels d’API en chaîne. Surveiller uniquement des endpoints individuels peut faire passer à côté de défaillances survenant entre les étapes.
C’est là que la surveillance des API multi-étapes devient essentielle. Au lieu de contrôler les endpoints séparément, les équipes surveillent des workflows complets, tels que l’authentification, la création de données, la récupération et la validation, comme une transaction unique. Cette approche met en évidence des problèmes que les simples contrôles d’uptime ne peuvent pas détecter.
Valider bien plus que les codes de statut
Une véritable surveillance de l’uptime exige de valider les réponses, pas seulement de les recevoir. Des contrôles efficaces vérifient :
- La structure des réponses et les champs obligatoires
- Des valeurs spécifiques indiquant le succès
- Des règles métier confirmant le bon fonctionnement de l’API
Sans ce niveau de validation, les tableaux de bord peuvent afficher une disponibilité de 100 % alors que les utilisateurs rencontrent des fonctionnalités défaillantes.
Inclure les API authentifiées et privées
De nombreuses API critiques sont protégées par une authentification ou des pare-feu. Une stratégie d’uptime réaliste doit prendre en charge les tokens, les en-têtes et la rotation des identifiants. Sinon, les équipes finissent par ne surveiller que les parties les moins importantes du système.
Les capacités de Web API Monitoring et de surveillance des API REST de Dotcom-Monitor prennent en charge les endpoints authentifiés et privés, permettant aux équipes de surveiller les mêmes API que celles utilisées par leurs applications en production.
Surveiller depuis les emplacements des utilisateurs
Une surveillance depuis un seul emplacement crée une fausse impression de fiabilité. Les API doivent être surveillées depuis plusieurs zones géographiques correspondant à la distribution réelle des utilisateurs. Cela permet de détecter des pics de latence régionaux, des problèmes de routage et des pannes liées aux fournisseurs d’accès avant qu’ils ne s’aggravent.
Aligner l’uptime sur les objectifs de fiabilité
Enfin, la surveillance de l’uptime doit être alignée sur les objectifs de niveau de service (SLO). Au lieu de demander « l’API est-elle disponible ? », les équipes doivent se demander :
- Atteint-elle les objectifs de disponibilité ?
- Les performances restent-elles dans des limites acceptables ?
- Les taux d’erreur dépassent-ils les seuils définis ?
Lorsque les métriques d’uptime sont alignées sur les objectifs de fiabilité, la surveillance devient actionnable plutôt que purement informative.
Pour les équipes mettant en œuvre ces stratégies, la documentation de Dotcom-Monitor, telle que la configuration de la surveillance des Web API et Ajouter/Modifier une tâche Web API REST (avec des options avancées également couvertes dans Configuration des tâches Web API REST), facilite le passage de contrôles basiques à une surveillance de l’uptime des API adaptée à la production.
L’uptime des API dépend du consommateur
L’uptime des API n’est pas universel. Les API internes peuvent tolérer de brèves interruptions, mais nécessitent une exactitude stricte pour maintenir les workflows. Les API publiques exigent une disponibilité mondiale constante et une faible latence afin de préserver l’expérience utilisateur et la confiance dans la marque.
Les API partenaires ou critiques pour le chiffre d’affaires impliquent les exigences les plus élevées, où la moindre dégradation peut avoir un impact sur les contrats ou les revenus. Une surveillance efficace de l’uptime des API s’adapte à ces différences en priorisant les endpoints, la profondeur de validation et les seuils d’alerte en fonction de la manière dont l’API est réellement consommée.
Erreurs courantes en surveillance de l’uptime des API (et comment les éviter)
Même les équipes disposant de stacks de surveillance matures tombent souvent dans les mêmes pièges. Ces erreurs ne proviennent généralement pas d’une négligence, mais d’hypothèses trop simplifiées sur la manière dont les API échouent en production.
1. Assimiler l’uptime à un simple code de statut
L’une des erreurs les plus fréquentes consiste à assimiler l’uptime à une réponse HTTP réussie. Un 200 OK confirme seulement que le serveur a répondu, pas que l’API a fonctionné correctement. Sans validation des payloads, des schémas ou de la logique métier, les équipes mesurent l’accessibilité, et non l’utilisabilité.
Comment l’éviter :
Aller au-delà des codes de statut en validant le contenu des réponses et les valeurs attendues dans les contrôles d’uptime.
2. Surveiller depuis un seul emplacement
Effectuer des contrôles d’uptime depuis un seul emplacement géographique, souvent proche de l’infrastructure, crée une fausse impression de fiabilité. Des problèmes régionaux de routage, des pannes d’ISP ou des erreurs DNS peuvent affecter certains utilisateurs sans déclencher d’alerte.
Comment l’éviter :
Surveiller les API depuis plusieurs emplacements mondiaux reflétant réellement la localisation des utilisateurs.
3. Ignorer les endpoints authentifiés
De nombreuses équipes évitent de surveiller les API authentifiées en raison de la complexité de la configuration. En conséquence, les API les plus critiques, celles qui nécessitent des tokens, des en-têtes ou des autorisations, ne sont pas surveillées.
Comment l’éviter :
Utiliser des outils de surveillance prenant en charge l’authentification, les en-têtes et la rotation des identifiants afin que l’uptime reflète le comportement réel de l’application.
4. Alerter à chaque échec
Déclencher une alerte pour chaque échec génère du bruit, de la fatigue liée aux alertes et conduit à ignorer les notifications. Des problèmes réseau temporaires ou limités à une seule région ne nécessitent pas toujours une escalade immédiate.
Comment l’éviter :
Concevoir une logique d’alerte qui vérifie les échecs sur plusieurs emplacements ou sur plusieurs contrôles avant de déclencher une alerte.
5. Traiter l’uptime comme une métrique de vanité
Des pourcentages d’uptime élevés sont flatteurs dans les rapports, mais masquent souvent des problèmes sous-jacents. Une API peut atteindre ses objectifs d’uptime tout en offrant une mauvaise expérience utilisateur.
Comment l’éviter :
Relier la surveillance de l’uptime à des objectifs de fiabilité tels que les taux d’erreur, les seuils de latence et les objectifs de niveau de service.
Ces erreurs expliquent pourquoi les équipes se sentent souvent confiantes dans leur surveillance, jusqu’à ce que les utilisateurs signalent des problèmes en premier. Les éviter nécessite un changement de mentalité : la surveillance de l’uptime ne consiste pas à prouver que les systèmes sont en ligne, mais à prouver qu’ils sont utilisables.
C’est également là que des pratiques plus larges comme les outils de surveillance des API et la surveillance de la santé des API comblent les lacunes laissées par les contrôles basiques, en offrant une vision plus réaliste de la fiabilité des API.
Quand les outils natifs ou exclusivement orientés développeurs ne suffisent plus
Les outils natifs et orientés développeurs sont précieux au début. Les contrôles CI/CD, les tests unitaires et les moniteurs au niveau de la plateforme permettent de détecter des problèmes évidents avant que le code n’atteigne la production. Mais à mesure que les API évoluent et deviennent orientées client, ces outils montrent des limites claires.
Un problème majeur est le biais d’environnement. Les outils exclusivement destinés aux développeurs s’exécutent généralement dans le même cloud, le même réseau ou le même pipeline que l’API elle-même. Ils sont efficaces pour valider les déploiements, mais peu adaptés pour détecter les problèmes rencontrés par les utilisateurs en dehors de votre environnement, comme des soucis de routage ou des pannes régionales.
Une autre limite concerne le périmètre et la continuité. La plupart des contrôles natifs sont conçus pour des exécutions ponctuelles, et non pour une surveillance continue. Ils manquent souvent des problèmes qui apparaissent progressivement, notamment :
- Les augmentations graduelles de latence
- Les défaillances intermittentes de dépendances
- Les dégradations de performance spécifiques à certaines régions
Il existe également un problème de confiance dans les alertes. Lorsque les alertes proviennent de l’intérieur de votre propre infrastructure, les équipes doutent souvent de leur réalité ou les considèrent comme de simples anomalies internes. Cette incertitude ralentit les temps de réponse et entraîne des investigations inutiles.
À mesure que les API mûrissent, les équipes ont besoin d’une surveillance offrant un point de vue indépendant, reflétant l’expérience réelle des utilisateurs. La surveillance externe de l’uptime apporte cette perspective manquante en validant la disponibilité et les performances depuis l’extérieur de votre environnement.
C’est là que la surveillance des API REST devient essentielle. Plutôt que de s’appuyer uniquement sur des contrôles internes, les équipes peuvent surveiller en continu les API depuis plusieurs emplacements mondiaux, valider des réponses réelles et déterminer si les défaillances sont généralisées ou isolées.
Le passage au-delà des outils uniquement orientés développeurs n’est généralement pas théorique. Il est déclenché par des incidents manqués, des alertes tardives ou des problèmes signalés en premier par les clients. Identifier ces signaux d’alerte tôt permet aux équipes de faire évoluer leur stratégie de surveillance avant que des problèmes de fiabilité ne deviennent des risques métier.
Il est également important de reconnaître les limites de la surveillance synthétique de l’uptime. Si elle confirme la disponibilité et l’impact côté utilisateur, elle ne remplace pas les logs, traces ou métriques pour une analyse approfondie des causes racines. Ces outils sont complémentaires.
Comment Dotcom-Monitor aborde la surveillance de l’uptime des API
Dotcom-Monitor utilise une surveillance synthétique externe depuis des points de contrôle mondiaux indépendants afin de valider la disponibilité, l’exactitude et les performances telles qu’elles sont perçues par les utilisateurs.
Au cœur de cette approche se trouve la surveillance synthétique externe. Les API sont testées depuis l’extérieur de votre infrastructure, à l’aide de points de contrôle mondiaux indépendants. Cela élimine le biais interne et garantit que les données d’uptime reflètent l’expérience des utilisateurs, et non ce que rapportent vos propres systèmes.
Les principales capacités qui soutiennent cette approche incluent :
- Des emplacements de surveillance mondiaux qui révèlent les pannes régionales et les problèmes de latence
- Une validation avancée des réponses, afin qu’un 200 OK ne soit pas confondu avec un résultat réussi
- La surveillance des API multi-étapes qui valide des workflows complets, et non de simples appels isolés
- La prise en charge des API authentifiées et privées, incluant les en-têtes, les tokens et une logique personnalisée
Cela permet de détecter des défaillances silencieuses que les contrôles basiques d’uptime ne repèrent pas, telles que des payloads incorrects, des flux d’authentification défaillants ou des échecs partiels de dépendances.
Un autre élément clé est la fiabilité des alertes. Dotcom-Monitor peut être configuré pour réduire les faux positifs à l’aide de contrôles de faux positifs et de règles d’alerte basées sur la durée des erreurs et le nombre d’emplacements affectés. Les alertes deviennent ainsi des signaux pertinents, et non du bruit.
Grâce à une surveillance continue, les équipes peuvent également analyser les tendances dans le temps. Les pics de latence, les dégradations régionales et les erreurs intermittentes apparaissent avant de se transformer en pannes complètes. Cela fait évoluer la surveillance de l’uptime d’une activité réactive vers une pratique proactive de fiabilité.
L’ensemble de ces fonctionnalités est proposé via Web API Monitoring de Dotcom-Monitor, conçu spécifiquement pour les environnements de production. Plutôt que de surveiller ce qui est le plus simple à vérifier, la solution se concentre sur l’essentiel : la disponibilité, l’exactitude et les performances telles qu’elles sont vécues par les utilisateurs réels.
Pour les équipes prêtes à aller au-delà des contrôles basiques, découvrez notre outil de surveillance des Web API de niveau production
