La surveillance synthétique est une méthode proactive de test de performance qui utilise des transactions scriptées et automatisées pour simuler les interactions réelles des utilisateurs avec vos applications — mesurant la disponibilité, le temps de réponse et la fonctionnalité avant que les problèmes n’atteignent les utilisateurs réels.
Si votre application tombe en panne à 3h du matin ou ralentit dans une région où vous n’avez pas encore d’utilisateurs réels, vous devez le savoir rapidement — lors de l’intervalle de sonde suivant — et non lorsqu’une plainte client arrive dans votre boîte mail. C’est exactement à cela que sert la surveillance synthétique.
Dans ce guide, nous couvrirons tout ce que vous devez savoir sur la surveillance synthétique : son fonctionnement, les différents types de tests, les métriques importantes, comment elle se compare à la surveillance des utilisateurs réels (RUM) et à l’APM, et comment l’utiliser efficacement en production. Nous aborderons également les limites dont personne ne parle et partagerons les meilleures pratiques utilisées par les équipes SRE et DevOps à grande échelle.
Qu’est-ce que la Surveillance Synthétique ?
La surveillance synthétique — également appelée surveillance active, surveillance dirigée ou test synthétique — fonctionne en déployant des agents de surveillance automatisés qui envoient en continu des requêtes scriptées à vos applications, API ou services web selon un calendrier défini. Ces agents opèrent à différents niveaux techniques : des agents HTTP légers qui envoient des requêtes pour vérifier la disponibilité de base et les codes de réponse, et des agents sophistiqués basés sur des navigateurs qui exécutent des moteurs de navigateur complets pour exécuter du JavaScript, rendre les pages, gérer les sessions et simuler des interactions utilisateur complexes en plusieurs étapes. EveryStep Web Recorder de Dotcom-Monitor utilise de vrais navigateurs — pas seulement des moteurs headless — pour enregistrer et rejouer toute action utilisateur sur plus de 40 configurations de navigateurs desktop et mobiles.
Parce qu’il s’agit de simulations scriptées plutôt que d’observations passives du trafic réel, la surveillance synthétique fonctionne 24h/24 et 7j/7, que des utilisateurs réels soient actifs ou non. Vous obtenez des données de performance cohérentes et reproductibles dans des conditions contrôlées — de jour comme de nuit, durant les pics de trafic ou les fenêtres de maintenance calmes.
Le terme « surveillance active » la distingue des approches passives comme la surveillance des utilisateurs réels (RUM), qui ne capture des données que lorsque des utilisateurs réels interagissent avec le système. La surveillance synthétique n’attend pas — elle sonde selon un calendrier défini pour que vous puissiez détecter rapidement les pannes et régressions, souvent lors de l’intervalle de sonde suivant, sans attendre les rapports utilisateurs.
Comment Fonctionne la Surveillance Synthétique ?
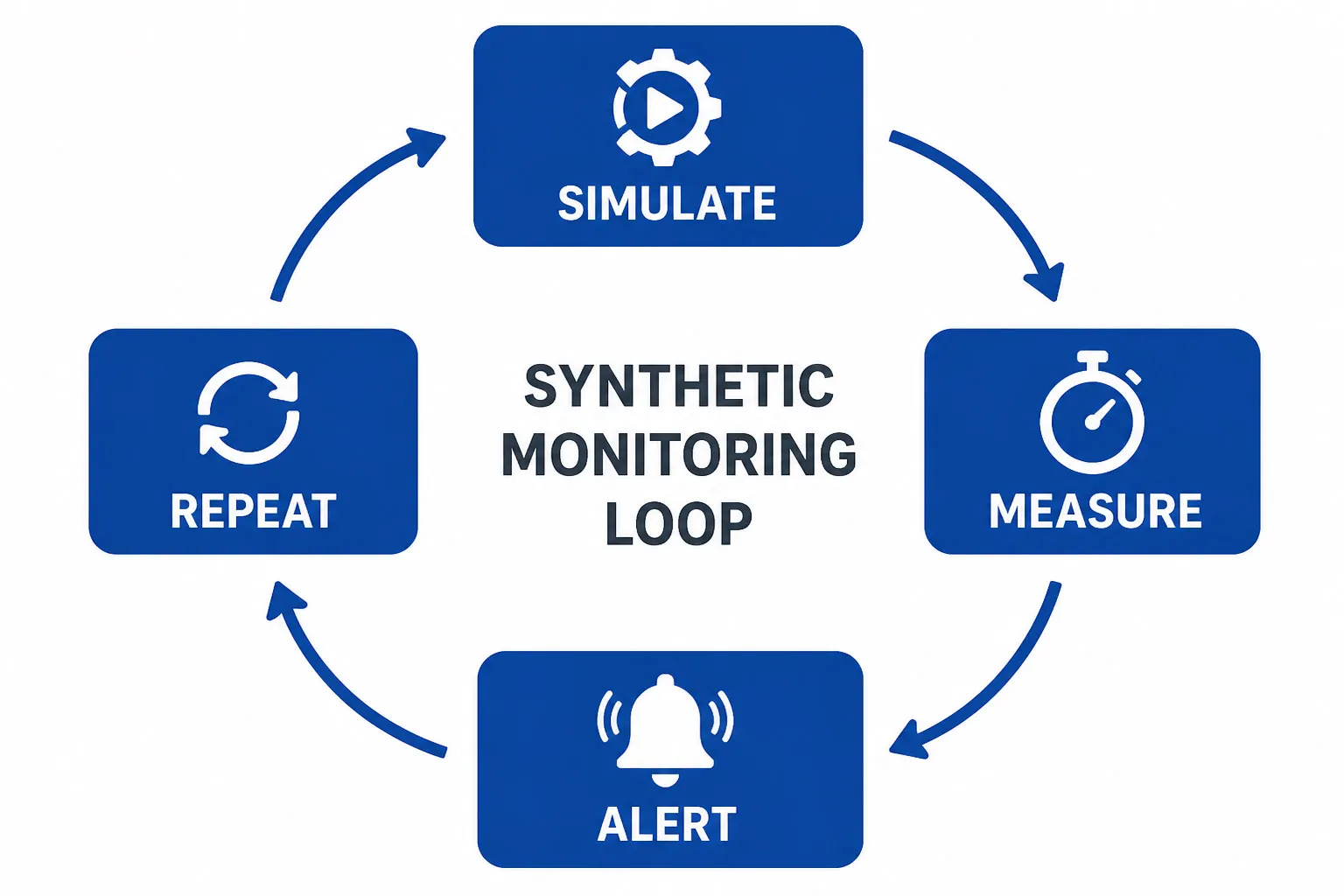 : simuler, mesurer, alerter, répéter” width=”1536″ height=”1024″ /> La surveillance synthétique suit une boucle continue — Simuler, Mesurer, Alerter, Répéter.[/caption]
: simuler, mesurer, alerter, répéter” width=”1536″ height=”1024″ /> La surveillance synthétique suit une boucle continue — Simuler, Mesurer, Alerter, Répéter.[/caption]
Au cœur, la surveillance synthétique suit une boucle simple : simuler, mesurer, alerter, répéter. Voici le flux de travail étape par étape :
- Définir les parcours utilisateur critiques et les points de terminaison. Identifier quelles transactions sont les plus importantes : les flux de connexion, les processus de paiement, les contrôles de santé API, la résolution DNS et la validité des certificats SSL.
- Enregistrer ou script vos tests. Utilisez un outil comme EveryStep Web Recorder de Dotcom-Monitor pour capturer les interactions réelles du navigateur — clics, saisie de formulaire, navigations — qui sont sauvegardées sous forme de scripts rejouables. Pour les vérifications API et protocoles, configurez directement des tâches HTTP, DNS ou ping dans la plateforme.
- Déployer des agents de surveillance globalement. Exécutez des tests depuis plusieurs localisations géographiques à l’aide d’agents publics (plus de 30 localisations globales) et/ou d’agents privés déployés dans vos propres centres de données ou périmètre réseau.
- Exécuter selon un planning. Les tests s’exécutent à des intervalles configurés — aussi fréquemment que chaque minute jusqu’à toutes les trois heures. Un agent de surveillance transmet les requêtes scriptées, attend une réponse, et enregistre le résultat.
- Mesurer les résultats techniques et fonctionnels. Capturer les temps de réponse, codes d’état HTTP, temps de chargement de la page, Time to First Byte (TTFB), First Contentful Paint (FCP), et les Core Web Vitals (LCP, CLS et INP). Notez que les métriques d’interaction telles que INP reflètent la saisie utilisateur réelle et sont mieux validées conjointement avec des données utilisateurs réelles — la méthode synthétique fournit des mesures contrôlées, en laboratoire.
- Alerter sur les problèmes confirmés. Dotcom-Monitor envoie des alertes immédiatement dès détection par défaut. Des filtres configurables — tels que des déclencheurs basés sur des seuils, types d’erreurs, ou règles spécifiques à la localisation — vous permettent de réduire le bruit pour les vérifications moins critiques. Pour les tests de transactions en plusieurs étapes, considérez si la relance d’un script échoué peut avoir des effets secondaires non désirés avant d’activer les relances automatiques.
- Utiliser les points de vue stratégiquement. Un agent privé passant un test confirme que le service et le parcours spécifiques fonctionnent depuis ce point de vue interne — ce qui vous aide à isoler si un problème est face à Internet, lié à la périphérie, ou interne. Les agents externes globaux mesurent le chemin complet côté utilisateur : résolution DNS, CDN, routage ISP, et latence géographique.
Voir la surveillance synthétique de Dotcom-Monitor en action → Explorer la page solution Surveillance Synthétique
7 Types de tests de surveillance synthétique

La surveillance synthétique n’est pas universelle. Différents types de tests servent des objectifs différents, et les stratégies de surveillance matures en combinent plusieurs.
Surveillance de la disponibilité / du temps de fonctionnement
La surveillance du temps de fonctionnement utilise des sondes réseau et de point final pour confirmer qu’un serveur ou service est accessible et répond. Ces vérifications opèrent à différents niveaux du réseau, chacun validant quelque chose de distinct :
- Surveillance Ping (ICMP) — teste la portée réseau de base vers un hôte lorsque cela est permis par les règles du pare-feu. Un ping réussi confirme que l’hôte est sur le réseau, mais ne prouve pas que l’application est saine.
- Surveillance de port (TCP) — teste si un port spécifique est ouvert et accepte les connexions. Confirme la portée au niveau de la couche transport.
- Vérifications de disponibilité HTTP/HTTPS — valident un point de terminaison d’application au niveau de la couche application, en vérifiant les codes d’état, le contenu de la réponse et la validité SSL. Pour la disponibilité de l’application, les vérifications HTTP avec des assertions de réponse et de contenu sont la couche la plus significative à surveiller.
Dotcom-Monitor propose les trois en tant que produits distincts — Surveillance Ping, Surveillance de port et Surveillance de disponibilité basée sur HTTP — car un ping réussi ne garantit pas une application saine.
Surveillance de la performance du navigateur / de la page
Un véritable navigateur charge une page web complète — exécutant JavaScript, rendant le CSS, chargeant des ressources tierces — et enregistre des temps de chargement granulaires. La surveillance des pages web de Dotcom-Monitor s’exécute dans de vrais navigateurs Chrome, Edge, Firefox et mobiles (plus de 40 configurations) plutôt que dans un simple moteur sans interface, produisant des données de performance authentiques qui reflètent l’expérience utilisateur réelle. Les métriques clés incluent TTFB, FCP, LCP, temps de chargement DOM et temps total de chargement de la page. Les graphiques en cascade et les enregistrements vidéo synchronisés à ces graphiques permettent d’identifier précisément quelles ressources sont les plus lentes. Cela compte pour le SEO : les Core Web Vitals de Google (LCP, CLS, INP) sont un facteur de classement, et des scores constamment mauvais affecteront votre visibilité dans les recherches.
Surveillance des transactions
La surveillance des transactions simule un parcours utilisateur complet — une séquence multi-étapes comme rechercher un produit, l’ajouter au panier, saisir les détails de paiement et finaliser la commande. L’enregistreur EveryStep Web de Dotcom-Monitor capture ces parcours en enregistrant des interactions dans un navigateur réel, qui sont rejouées cffectués en continu par des agents de surveillance. Toute étape défaillante — un formulaire qui ne se soumet pas, un bouton déplacé à cause d’un changement d’interface utilisateur, une boucle de redirection introduite par un déploiement — est immédiatement détectée. C’est le type de test le plus puissant pour protéger les flux commerciaux critiques pour le chiffre d’affaires.
Surveillance API
Test de la santé, des performances et de la conformité des points d’accès API REST et SOAP. Validation des méthodes HTTP (GET, POST, PUT, PATCH), vérification des codes de statut de réponse, validation des charges utiles de réponse et mesure de la latence. Dotcom-Monitor prend en charge la surveillance des API REST, des API SOAP, des collections Postman et des collections Insomnia — couvrant l’ensemble des types d’API que les équipes utilisent en pratique. Les tests API multisteps chaînent les requêtes (authentification → création → récupération → suppression) pour valider des flux entiers. Les vérifications SSL/TLS peuvent s’exécuter parallèlement aux tests API afin de confirmer que les certificats sont valides et ne sont pas proches de leur expiration.
Surveillance DNS
Vérifie que vos serveurs DNS résolvent correctement les noms d’hôtes et dans des temps de réponse acceptables. Les problèmes DNS peuvent causer des pannes étendues et difficiles à diagnostiquer — lorsque le DNS échoue, les utilisateurs ne peuvent pas accéder à votre application même si vos serveurs fonctionnent parfaitement. La surveillance DNS de Dotcom-Monitor valide la précision de la résolution, les temps de réponse et la santé de la chaîne de propagation DNS complète à travers les emplacements mondiaux. Elle valide aussi la chaîne de confiance DNSSEC pour garantir que les réponses DNS n’ont pas été falsifiées, surveille la cohérence des enregistrements SOA, et signale les changements DNS anormaux — comme des adresses IP inattendues ou des modifications non autorisées des enregistrements — qui pourraient indiquer un mauvais routage ou un empoisonnement du cache. La surveillance DNS prend en charge les types d’enregistrements A, AAAA, MX, NS, CNAME, PTR, et SOA.
Surveillance des certificats SSL
Surveille la validité des certificats SSL/TLS, leurs dates d’expiration et leur statut de révocation. Un certificat expiré ou mal configuré provoque des avertissements de confiance immédiats dans tous les navigateurs, impactant directement la confiance des utilisateurs et les taux de conversion. La surveillance SSL automatisée vous alerte des jours ou semaines avant l’expiration d’un certificat, laissant à votre équipe le temps de le renouveler sans interruption.
Surveillance des protocoles et du réseau
Au-delà des contrôles web et API, Dotcom-Monitor surveille l’ensemble des protocoles réseau : email (SMTP, POP3, IMAP), VoIP et SIP, FTP, UDP, WebSocket, et l’analyse des chemins traceroute. La surveillance par ping (ICMP) et l’analyse des ports complètent la visibilité au niveau réseau. Ces tests sont particulièrement précieux pour les organisations disposant d’infrastructures complexes où la santé des applications dépend de multiples services sous-jacents.
3 métriques clés de surveillance synthétique à suivre

Ce que vous mesurez détermine ce que vous pouvez améliorer. Les métriques les plus importantes en synthèse opérationnelle se répartissent en trois catégories :
Métriques de disponibilité
- Pourcentage de disponibilité (objectif : 99,9 % ou mieux selon le SLA)
- Taux d’erreur par point de terminaison et région géographique
- Codes d’état HTTP (erreurs 4xx client, erreurs 5xx serveur)
- Taux de réussite de résolution DNS et temps de réponse
- Validité du certificat SSL/TLS et nombre de jours jusqu’à expiration
Métriques de performance
- Temps jusqu’au premier octet (TTFB) — réactivité du serveur
- Premier rendu significatif (FCP) et plus grand rendu significatif (LCP) — Core Web Vitals
- Décalage cumulatif de mise en page (CLS) — stabilité visuelle
- Interaction jusqu’au prochain rendu (INP) — réactivité Core Web Vital (mesures en laboratoire approximant les valeurs sur le terrain)
- Temps total de chargement de la page et chargement du DOM
- Temps de réponse API (latences p50, p95, p99)
- Durée des étapes de transaction — quelle étape du parcours multi-étapes est la plus lente
Métriques de fiabilité et SLA
- Temps moyen de détection (MTTD) — rapidité de détection des problèmes dans l’intervalle de sonde
- Temps moyen de résolution (MTTR) — rapidité de résolution des problèmes
- Pourcentage de conformité SLA/SLO sur des fenêtres temporelles glissantes
- Delta de référence de performance — variation du temps de réponse par rapport à la moyenne historique
Surveillance synthétique vs. surveillance des utilisateurs réels vs. APM

Ces trois approches de surveillance ont des objectifs distincts et sont souvent confondues. Voici leurs différences :
| Dimension | Surveillance Synthétique | Surveillance des Utilisateurs Réels (RUM) | APM |
|---|---|---|---|
| Source de données | Simulations scriptées par agents | Sessions utilisateur réelles (extrait JS) | Instrumentation backend (traces, logs) |
| Moment de collecte des données | 24/7, selon un planning de sondes défini | Uniquement lorsque les utilisateurs réels sont actifs | Pendant l’exécution réelle de l’application |
| Type | Actif / proactif | Passif / réactif | Interne / au niveau du code |
| Meilleur pour | Disponibilité, détection de régressions, validation SLA | Expérience utilisateur réelle, performance géographique, analyse de sessions | Analyse des causes racines, goulets d’étranglement au niveau du code |
| Fonctionne avant le lancement? | Oui | Non | Oui (en staging) |
| Fonctionne-t-il pendant les fenêtres de faible trafic ? | Oui | Limité | Oui, mais moins de requêtes = moins d’échantillons |
| Couvre-t-il les services tiers ? | Oui (tests API et DNS) | Partiellement | Dépend de l’instrumentation |
| Détecte-t-il les chemins utilisateurs inconnus ? | Non (scripts uniquement) | Oui | Partiellement |
L’idée clé : la surveillance synthétique et le RUM sont complémentaires, pas concurrents. La surveillance synthétique vous donne des mesures de référence cohérentes et proactives. Le RUM vous indique ce qui se passe pour des utilisateurs réels et variés sur chaque appareil, navigateur et condition réseau. Utiliser les deux ensemble vous donne l’image la plus complète de l’expérience numérique.
L’APM se situe à un autre niveau, fournissant des traces au niveau du code et des données de performance côté serveur. Ensemble, ces trois forment une couverture complète de la surveillance entre l’expérience utilisateur et la performance backend. Pour une pratique d’observabilité complète, les équipes combinent généralement l’APM avec les logs, les métriques et les traces distribuées pour soutenir l’enquête sur la cause première.
Pourquoi les équipes utilisent la surveillance synthétique : 8 avantages clés
- Détecter les problèmes avant les utilisateurs.Les tests synthétiques s’exécutent en continu, même en heures creuses. Vous serez informé d’un problème dans le processus de paiement à 2 h du matin avant que vos clients ne se réveillent pour le découvrir.
- Établir des bases de référence de performance.En exécutant les mêmes tests de manière répétée dans le temps, vous construisez une base fiable de performances attendues. Les écarts au-delà des seuils définis — confirmés à travers plusieurs sites ou intervalles consécutifs — peuvent déclencher des alertes, filtrant le bruit réseau transitoire.
- Valider rapidement les nouvelles mises en production.Effectuez des tests synthétiques contre votre environnement de staging avant la mise en production pour confirmer qu’aucune rupture n’est survenue, puis continuez la surveillance immédiatement après déploiement pour valider le comportement en production — détectant ainsi les régressions avant qu’elles n’affectent les utilisateurs réels.
- Protéger les SLA et SLO.La surveillance synthétique produit des données objectives et continues de performance nécessaires pour prouver la conformité aux SLA auprès des clients et identifier rapidement lorsqu’un fournisseur tiers ne respecte pas les normes convenues.
- Tenir les fournisseurs tiers responsables.Les applications modernes dépendent des CDN, des processeurs de paiement, des plateformes analytiques et des API SaaS. Les tests synthétiques peuvent surveiller chacun d’eux indépendamment, vous fournissant des preuves lorsque la dégradation d’un fournisseur impacte vos utilisateurs.
- Réduire le MTTR.Parce que les vérifications synthétiques capturent des étapes, des timings et des artefacts cohérents — y compris des enregistrements vidéo synchronisés avec des graphiques en cascade dans Dotcom-Monitor — elles facilitent souvent la reproduction et le triage des problèmes. Les défaillances intermittentes ou dépendantes de l’état peuvent nécessiter une enquête serveur plus approfondie, mais disposer de la séquence exacte des étapes…e et le moment réduisent considérablement la recherche.
- Surveillez les zones pré-lancement et à faible trafic.Vous lancez dans une nouvelle région ? Vous développez une nouvelle fonctionnalité qui n’est pas encore en production ? La surveillance synthétique peut tester ces zones avant que de véritables utilisateurs ne les visitent.
- Soutenez la planification de la capacité.Les données historiques de la surveillance synthétique révèlent des tendances : votre API ralentit-elle à mesure que votre base d’utilisateurs grandit ? Les périodes de trafic de pointe causent-elles une dégradation ? Ces données alimentent directement les décisions de planification de capacité et d’infrastructure.
Cas d’utilisation de la surveillance synthétique par équipe et secteur
Par équipe
- Équipes SRE et plateforme : Possèdent les SLO de disponibilité. Utilisent la surveillance synthétique pour suivre les taux de consommation des SLO, définir les budgets d’erreur et être alertés en cas de violations avant qu’elles ne dépassent les seuils des SLA.
- DevOps et ingénierie applicative : Effectuent des contrôles synthétiques dans les environnements de pré-production dans le cadre de la validation des versions. Surveillent après déploiement pour détecter rapidement les régressions et réduire le temps de décision de retour en arrière.
- Équipes API et backend : Surveillent la disponibilité, la latence et la justesse des points d’accès API REST et SOAP. Effectuent des tests API multi-étapes enchaînant authentification, opérations CRUD et validation en séquence.
- Équipes ecommerce et expérience digitale : Protègent les flux de paiement, la recherche de produits et la connexion aux comptes. Surveillent les Core Web Vitals pour protéger à la fois l’expérience utilisateur et le référencement SEO. Des études dans le ecommerce ont montré des impacts mesurables sur la conversion liés aux délais de chargement — bien que le seuil spécifique varie selon le secteur, les attentes des utilisateurs et les performances de base.
Par secteur
- Services financiers : Surveillent les plateformes de banque en ligne, les passerelles de paiement et les systèmes de trading pour la disponibilité et les temps de réponse sous la seconde. Valident en continu la configuration SSL/TLS.
- Technologie de santé : Assurent l’accessibilité et la performance des systèmes DSE, portails patients et plateformes de télémédecine — particulièrement critique durant les périodes de forte demande.
- Ecommerce et commerce de détail : Surveillent les API d’inventaire, la fonctionnalité du panier et les flux de paiement pour une disponibilité continue.
- Médias et streaming : Valident la performance du CDN, les points d’accès API pour les moteurs de recommandation et la disponibilité des services de streaming.
- Secteur public : Surveillent les portails et services destinés aux citoyens qui doivent respecter les engagements de disponibilité définis dans les SLA publics.
7 défis et limites de la surveillance synthétique
La surveillance synthétique est un outil puissant, mais elle présente de réelles limites que chaque équipe doit comprendre.
- Lacunes dans la couverture scriptée : Les tests synthétiques ne couvrent que les parcours utilisateurs que vous avez scriptés. La combinaison de différents chemins utilisateurs, configurations d’appareils, conditions réseau, états applicatifs et edge cas crée un espace combinatoire qui est impraticable à script de manière exhaustive. La surveillance des utilisateurs réels comble cette lacune en capturant ce que rencontrent réellement les utilisateurs.
- Fragilité des tests : Les scripts de transactions basés sur le navigateur sont sensibles aux changements d’interface utilisateur. Lorsqu’un texte de bouton change, un champ de formulaire est renommé ou une page est restructurée, les tests peuvent échouer — même si l’application elle-même fonctionne correctement. Cela génère du bruit d’alerte et nécessite une maintenance continue.
- Surcharge de maintenance : Au fur et à mesure que votre application évolue, vos scripts de test doivent également évoluer. Pour les grandes applications avec des versions fréquentes, le maintien des scripts à jour représente un coût opérationnel réel.
- Pas de signal UX subjectif : La surveillance synthétique mesure des métriques objectives : temps de réponse, taux d’erreur, disponibilité. Elle ne peut pas capturer la satisfaction utilisateur, les problèmes de design visuel, d’accessibilité ou la sensation subjective d’une interface confuse.
- Conditions simulées différentes de la réalité : Les agents synthétiques s’exécutent dans des environnements contrôlés. Ils ne reproduisent pas nécessairement la diversité des appareils réels des utilisateurs, les réseaux mobiles avec bande passante variable, les proxies d’entreprise ou le routage des fournisseurs d’accès régionaux.
- Angle mort du backend : La surveillance synthétique est une vue de l’extérieur vers l’intérieur. Elle indique que l’application est lente, mais pas pourquoi au niveau du code. Les outils APM et le traçage distribué sont nécessaires pour une analyse approfondie des causes au niveau du code.
- Coût à grande échelle : Effectuer des tests fréquents depuis de nombreux emplacements mondiaux avec des scripts de transactions complexes peut devenir coûteux, surtout à mesure que le nombre d’agents, la fréquence des tests et les exigences de rétention des données augmentent.
9 bonnes pratiques de la surveillance synthétique

- Commencez par vos chemins critiques. N’essayez pas de tout tester d’un coup. Commencez par les 3 à 5 parcours utilisateurs qui génèrent directement du chiffre d’affaires ou sont couverts par des SLA : connexion, paiement, API principale et vos pages d’atterrissage les plus visitées.
- Surveillez depuis les zones géographiques de vos utilisateurs. Effectuez les tests depuis les régions géographiques où se trouvent réellement les utilisateurs. Un test réussi depuis un nœud US-East ne vous informe rien sur les performances en Asie du Sud-Est ou en Europe de l’Ouest. Les plus de 30 emplacements globaux de Dotcom-Monitor vous permettent de faire correspondre le placement des agents à la géographie de vos utilisateurs.
- Utilisez des agents privés pour les environnements internes. Pour les services derrière un pare-feu — APIs internes, intranet applications, environnements de staging — déployez un agent privé à l’intérieur de votre réseau. N’oubliez pas : un agent privé réussissant un test confirme que ce service spécifique fonctionne depuis ce point de vue, mais pas que tout votre environnement interne est sain.
- Définissez des seuils d’alerte significatifs. Configurez des conditions d’alerte basées sur votre ligne de base de performance établie — par exemple, alerter lorsque le temps de réponse dépasse 1,5 à 2 fois la moyenne de référence, ou lorsque la disponibilité tombe en dessous de votre seuil SLO. Dotcom-Monitor prend en charge des filtres configurables afin que vous puissiez ajuster la sensibilité par vérification plutôt que d’alerter à chaque fluctuation.
- Validez le staging avant la mise en production. Exécutez les vérifications Dotcom-Monitor sur votre environnement de staging avant chaque mise en production pour détecter tôt les régressions. Après le déploiement, surveillez immédiatement la production pendant les 30 à 60 premières minutes — la période où la plupart des problèmes liés au déploiement apparaissent. Utilisez les intégrations d’alerte de Dotcom-Monitor (Slack, PagerDuty) pour diriger les alertes post-déploiement directement vers votre équipe d’astreinte.
- Gardez les scripts de test sous contrôle de version. Traitez les scripts de surveillance comme du code. Stockez-les dans Git, révisez les modifications via des pull requests et revenez en arrière si une mise à jour du script cause des fausses alertes.
- Combinez avec RUM pour une couverture complète. Utilisez la surveillance synthétique pour une détection proactive et une mesure de référence. Superposez RUM pour capturer l’expérience réelle des utilisateurs finaux dans des conditions diverses. Les deux ensemble fournissent une couverture complète de la surveillance de votre expérience numérique.
- Analysez régulièrement les graphiques waterfall. Ne vous contentez pas de regarder le temps de chargement total. Passez en revue les graphiques waterfall pour voir quelles ressources individuelles — scripts tiers, images volumineuses, appels API lents — contribuent le plus au temps de chargement. La capture vidéo synchronisée avec les graphiques waterfall de Dotcom-Monitor accélère considérablement ce diagnostic.
- Révisez et mettez à jour les scripts après des mises à jour majeures. Après tout changement significatif d’interface utilisateur ou refonte API, auditez vos scripts de test synthétiques pour vous assurer qu’ils reflètent toujours des parcours utilisateurs précis et n’ont pas été invalidés par la mise à jour.
Comment analyser les données de la surveillance synthétique ?
Collecter des données de surveillance synthétique n’a de valeur que si vous les exploitez. Voici un workflow pratique pour transformer des résultats bruts de test en améliorations de performance :
- Examinez quotidiennement les tableaux de bord de disponibilité et de taux d’erreur. Recherchez des tendances : les erreurs sont-elles concentrées dans une région spécifique, un endpoint précis ou à un moment donné de la journée ?
- Suivez les tendances de performance sur le long terme, pas seulement des instantanés ponctuels. Une page qui prend 2,1 secondes aujourd’hui mais prenait 1.6 secondes il y a trois semaines présente une régression — même si cela n’a pas encore dépassé votre seuil d’alerte.
- Utilisez des graphiques en cascade et des vidéos pour identifier les goulets d’étranglement. Identifiez les ressources les plus lentes sur chaque page. Les enregistrements vidéo de Dotcom-Monitor synchronisés avec les graphiques en cascade montrent exactement ce que le navigateur a vécu lors d’une défaillance — sans deviner.
- Corrélez les échecs synthétiques avec les événements de déploiement. Lorsqu’un test commence à échouer, vérifiez votre journal de déploiement. Une mise à jour juste avant l’échec est un signal fort à investiguer en priorité.
- Effectuez une analyse des causes profondes (RCA) sur les échecs récurrents. Ne vous contentez pas de résoudre les alertes — documentez-les. Les schémas de défaillance récurrents dans des régions spécifiques ou à des moments précis indiquent souvent des problèmes systémiques d’infrastructure à traiter de manière proactive.
- Faites régulièrement des rapports sur la conformité SLA/SLO. Utilisez les données historiques de surveillance synthétique pour générer des rapports de disponibilité pour les parties prenantes et les clients. Des données objectives horodatées renforcent la confiance et sont essentielles en cas de litiges avec des fournisseurs tiers.
Que rechercher dans un outil de surveillance synthétique ?
Toutes les plateformes de surveillance synthétique ne se valent pas. Lors de l’évaluation d’une solution, recherchez ces fonctionnalités :
- Réseau mondial de surveillance — plus de 30 emplacements pour tester depuis l’endroit où se trouvent réellement vos utilisateurs
- Support des agents privés — déployez des agents dans votre propre réseau pour la surveillance intranet et de préproduction
- Large couverture des types de tests — disponibilité, navigateur, transaction, API (REST, SOAP, Postman, Insomnia), DNS, SSL, et vérifications de protocoles dans une seule plateforme
- Tests dans des navigateurs réels — une surveillance qui s’exécute dans de vrais navigateurs Chrome, Edge, Firefox et mobiles, pas seulement dans des moteurs sans interface
- Outils de débogage visuel — graphiques en cascade, enregistrements vidéo synchronisés avec les exécutions de surveillance, et captures d’écran filmstrip pour un diagnostic rapide
- Enregistrement flexible de scripts — des outils comme EveryStep Web Recorder qui capturent les interactions réelles des utilisateurs sans nécessiter de scripts d’automatisation codés manuellement
- Profondeur des métriques de performance — TTFB, FCP, LCP, CLS, INP, et ventilation complète du chronométrage de navigation
- Intégrations d’alertes — support de PagerDuty, Slack, Teams, email, SMS, WhatsApp, et webhook pour votre flux de travail d’astreinte
- Vérifications déclenchées à la demande — possibilité d’exécuter des vérifications via API pour déclencher la surveillance dans le cadre des workflows de déploiement
- Tableaux de bord SLA/SLO — rapports intégrés sur la disponibilité et les engagements de performance avec tableaux de bord partageables
- Tarification transparente — coût prévisiblemodèle qui s’adapte à vos besoins
Commencez la surveillance synthétique avec Dotcom-Monitor
Dotcom-Monitor offre une surveillance synthétique de qualité entreprise depuis un réseau mondial de plus de 30 emplacements de surveillance, prenant en charge les contrôles de disponibilité, les tests de pages en navigateur réel, la surveillance des transactions via EveryStep Web Recorder, la surveillance API (REST, SOAP, Postman, Insomnia), la surveillance DNS avec validation DNSSEC, la surveillance des certificats SSL, et une suite complète de contrôles de protocoles — le tout sur une seule plateforme.
Que vous protégiez un flux de paiement e-commerce, surveilliez une API publique, validiez la conformité SLA pour des clients entreprise, ou assuriez le bon fonctionnement d’applications internes pour votre équipe, Dotcom-Monitor vous offre la visibilité proactive pour détecter et résoudre les problèmes avant qu’ils n’affectent les utilisateurs réels.
