El monitoreo sintético es un método proactivo de prueba de rendimiento que utiliza transacciones automatizadas y con guion para simular interacciones reales de usuarios con tus aplicaciones, midiendo la disponibilidad, el tiempo de respuesta y la funcionalidad antes de que los problemas alcancen a los usuarios reales.
Si tu aplicación se cae a las 3 a.m. o se ralentiza en una región donde aún no tienes usuarios reales, necesitas saberlo rápidamente — dentro del siguiente intervalo de sondeo — no cuando una queja de un cliente llegue a tu bandeja de entrada. Precisamente para eso fue creado el monitoreo sintético.
En esta guía, cubriremos todo lo que necesitas saber sobre el monitoreo sintético: cómo funciona, los diferentes tipos de pruebas, qué métricas importan, cómo se compara con el monitoreo de usuarios reales (RUM) y APM, y cómo usarlo de manera efectiva en producción. También destacaremos las limitaciones que nadie menciona y compartiremos las mejores prácticas utilizadas por equipos de SRE y DevOps a gran escala.
¿Qué es el Monitoreo Sintético?
El monitoreo sintético — también llamado monitoreo activo, monitoreo dirigido o pruebas sintéticas — funciona desplegando agentes de monitoreo automatizados que envían continuamente solicitudes guionizadas a tus aplicaciones, APIs o servicios web según un horario establecido. Estos agentes operan en distintos niveles técnicos: agentes HTTP ligeros que envían solicitudes para verificar la disponibilidad básica y códigos de respuesta, y agentes sofisticados basados en navegadores que ejecutan motores completos para ejecutar JavaScript, renderizar páginas, administrar sesiones y simular interacciones complejas de usuario en varios pasos. El EveryStep Web Recorder de Dotcom-Monitor usa navegadores reales — no solo motores sin cabeza — para grabar y reproducir cualquier acción del usuario en más de 40 configuraciones de navegadores de escritorio y móviles.
Como son simulaciones con guion en lugar de observaciones pasivas del tráfico real, el monitoreo sintético opera 24/7 independientemente de si hay usuarios reales activos o no. Obtienes datos de rendimiento consistentes y reproducibles bajo condiciones controladas — de día o de noche, durante picos de tráfico o ventanas de mantenimiento silenciosas.
El término “monitoreo activo” lo distingue de enfoques pasivos como el Monitoreo de Usuarios Reales (RUM), que sólo captura datos cuando los usuarios reales interactúan con el sistema. El monitoreo sintético no espera: sondea según un horario definido para que puedas detectar fallos y regresiones rápidamente, a menudo dentro del siguiente intervalo de sondeo, en lugar de esperar informes de usuarios.
¿Cómo Funciona el Monitoreo Sintético?
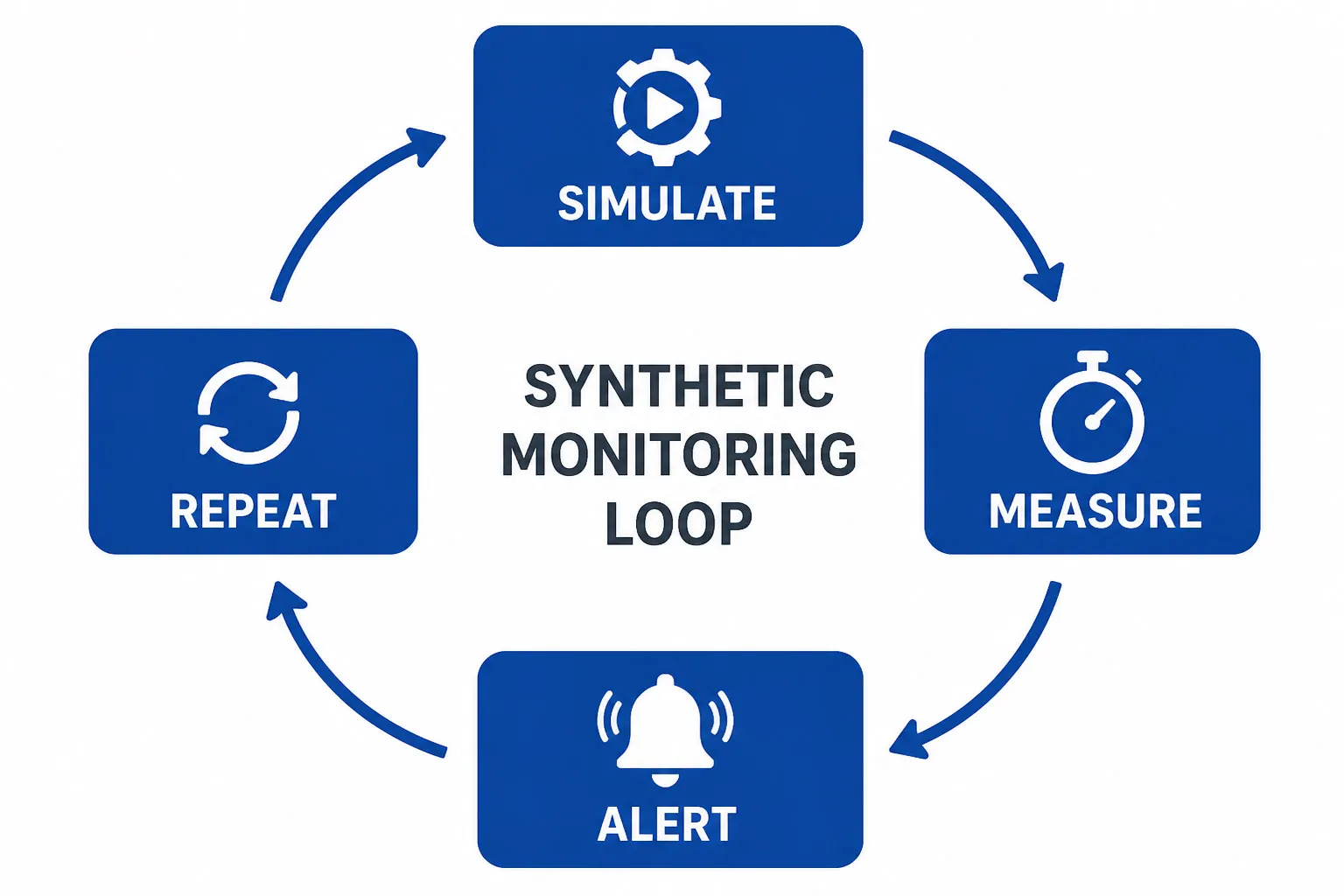
En su esencia, la monitorización sintética sigue un ciclo sencillo: simular, medir, alertar, repetir. Aquí está el flujo de trabajo paso a paso:
- Definir los recorridos y puntos finales críticos del usuario. Identificar qué transacciones son las más importantes: flujos de inicio de sesión, procesos de compra, comprobaciones de salud de API, resolución de DNS y validez del certificado SSL.
- Grabar o programar tus pruebas. Usa una herramienta como EveryStep Web Recorder de Dotcom-Monitor para capturar interacciones reales del navegador — clics, entradas en formularios, navegaciones — que se guardan como scripts reproducibles. Para las comprobaciones de API y protocolos, configura tareas HTTP, DNS o ping directamente en la plataforma.
- Desplegar agentes de monitorización globalmente. Ejecuta pruebas desde múltiples ubicaciones geográficas usando agentes públicos (30+ ubicaciones globales) y/o agentes privados desplegados dentro de tus propios centros de datos o perímetro de red.
- Ejecutar en un horario programado. Las pruebas se ejecutan en intervalos configurados — tan frecuentemente como cada minuto hasta cada tres horas. Un agente de monitorización transmite las solicitudes programadas, espera una respuesta y registra el resultado.
- Medir resultados técnicos y funcionales. Captura tiempos de respuesta, códigos de estado HTTP, tiempo de carga de página, Tiempo hasta el Primer Byte (TTFB), First Contentful Paint (FCP) y Core Web Vitals (LCP, CLS y INP). Ten en cuenta que métricas de interacción como INP reflejan la entrada real del usuario y se validan mejor junto con datos de usuarios reales — la sintética proporciona mediciones controladas, tipo laboratorio.
- Alertar sobre problemas confirmados. Dotcom-Monitor envía alertas inmediatamente al detectar un problema por defecto. Filtros configurables — como disparadores basados en umbrales, condiciones por tipo de error o reglas específicas por ubicación — te permiten reducir el ruido en cheques menos críticos. Para pruebas de transacciones multi-paso, considera si reintentar un script fallido puede tener efectos secundarios no deseados antes de habilitar reintentos automáticos.
- Usar puntos de vista estratégicamente. Un agente privado que pasa una prueba confirma que ese servicio específico y recorrido están funcionando desde ese punto de vista interno — ayudándote a aislar si un problema es visible en internet, relacionado con el borde (edge), o interno. Los agentes globales externos miden la ruta completa hacia el usuario: resolución DNS, bordes CDN, enrutamiento ISP y latencia geográfica.
Ve la monitorización sintética de Dotcom-Monitor en acción → Explora la página de la solución de monitorización sintética
7 Tipos de Pruebas de Monitoreo Sintético

El monitoreo sintético no es universal. Diferentes tipos de pruebas sirven para distintos propósitos, y las estrategias maduras de monitoreo combinan varias de ellas.
Monitoreo de Disponibilidad / Tiempo Activo
El monitoreo de tiempo activo utiliza sondas de red y de punto final para confirmar que un servidor o servicio es accesible y responde. Estas comprobaciones operan en diferentes capas de red, cada una validando algo distinto:
- Monitoreo Ping (ICMP) — prueba la accesibilidad básica de red a un host cuando lo permiten las reglas del firewall. Un ping exitoso confirma que el host está en la red, pero no prueba que la aplicación esté saludable.
- Monitoreo de Puertos (TCP) — prueba si un puerto específico está abierto y aceptando conexiones. Confirma la accesibilidad a nivel de capa de transporte.
- Verificaciones de Tiempo Activo HTTP/HTTPS — validan un punto final de la aplicación en la capa de aplicación, revisando códigos de estado, contenido de respuesta y validez SSL. Para el tiempo activo de aplicaciones, las verificaciones HTTP con afirmaciones de respuesta y contenido son la capa más significativa a monitorear.
Dotcom-Monitor ofrece los tres como productos distintos — Monitoreo Ping, Monitoreo de Puertos y Monitoreo de Tiempo Activo basado en HTTP — porque un ping exitoso no garantiza una aplicación saludable.
Monitoreo de Navegador / Rendimiento de Página
Un navegador real carga una página web completa — ejecutando JavaScript, renderizando CSS, cargando recursos de terceros — y registra tiempos detallados de carga. El monitoreo de páginas web de Dotcom-Monitor se ejecuta en navegadores reales como Chrome, Edge, Firefox y móviles (más de 40 configuraciones) en lugar de solo un motor sin interfaz, produciendo datos auténticos de rendimiento que reflejan la experiencia real del usuario. Las métricas clave incluyen TTFB, FCP, LCP, tiempo de carga del DOM y tiempo total de carga de la página. Los gráficos de cascada y las grabaciones de video sincronizadas con esos gráficos te permiten identificar exactamente qué recursos son los más lentos. Esto es importante para SEO: los Core Web Vitals de Google (LCP, CLS, INP) son un factor de posicionamiento, y las puntuaciones consistentemente bajas afectarán tu visibilidad en búsquedas.
Monitoreo de Transacciones
El monitoreo de transacciones simula una jornada completa del usuario — una secuencia de varios pasos como buscar un producto, añadirlo al carrito, ingresar datos de pago y completar la compra. El EveryStep Web Recorder de Dotcom-Monitor captura estas jornadas grabando interacciones reales del navegador, las cuales se reproducen cntemente mediante agentes de monitoreo. Cualquier paso roto — un formulario que no se envía, un botón desplazado por un cambio en la interfaz, un bucle de redireccionamiento introducido por un despliegue — se detecta de inmediato. Este es el tipo de prueba más potente para proteger flujos de negocio críticos para ingresos.
Monitoreo API
Prueba la salud, el rendimiento y la corrección de los endpoints de API REST y SOAP. Valida métodos HTTP (GET, POST, PUT, PATCH), verifica los códigos de estado de respuesta, comprueba los payloads de respuesta y mide la latencia. Dotcom-Monitor soporta monitoreo de API REST, monitoreo de API SOAP, monitoreo de colecciones Postman y monitoreo de colecciones Insomnia — cubriendo toda la gama de tipos de API que los equipos usan en la práctica. Las pruebas API multietapa encadenan solicitudes (autenticarse → crear → obtener → eliminar) para validar flujos de trabajo completos. Las comprobaciones de certificados SSL/TLS pueden ejecutarse junto con las pruebas API para confirmar que los certificados son válidos y no estén próximos a expirar.
Monitoreo DNS
Verifica que tus servidores DNS resuelvan los nombres de host correctamente y dentro de tiempos de respuesta aceptables. Los problemas de DNS pueden causar interrupciones generalizadas y difíciles de diagnosticar — cuando el DNS falla, los usuarios no pueden acceder a tu aplicación aunque tus servidores estén funcionando perfectamente. El monitoreo DNS de Dotcom-Monitor valida la precisión de la resolución, los tiempos de respuesta y la salud de la cadena completa de propagación DNS en ubicaciones globales. También valida la cadena de confianza DNSSEC para asegurarse de que las respuestas DNS no hayan sido manipuladas, monitorea la consistencia del registro SOA, y señala cambios anómalos en el DNS — como direcciones IP inesperadas o modificaciones no autorizadas en registros — que pueden indicar enrutamiento erróneo o envenenamiento de cache. El monitoreo DNS soporta tipos de registros A, AAAA, MX, NS, CNAME, PTR y SOA.
Monitoreo de Certificados SSL
Rastrea la validez, fechas de expiración y estado de revocación de certificados SSL/TLS. Un certificado expirado o mal configurado provoca advertencias inmediatas de confianza en todos los navegadores, impactando directamente la confianza del usuario y las tasas de conversión. El monitoreo automático de SSL te alerta días o semanas antes de que un certificado expire, dándole a tu equipo tiempo para renovarlo sin interrupciones.
Monitoreo de Protocolos y Redes
Más allá de las verificaciones web y API, Dotcom-Monitor monitorea toda la pila de protocolos de red: correo electrónico (SMTP, POP3, IMAP), VoIP y SIP, FTP, UDP, WebSocket y análisis de rutas traceroute. El monitoreo de ping (ICMP) y el escaneo de puertos completan la visibilidad a nivel de red. Estas pruebas son particularmente valiosas para organizaciones que ejecutan infraestructuras complejas donde la salud de la aplicación depende de múltiples servicios subyacentes.
3 Métricas Clave de Monitoreo Sintético para Rastrear

Lo que mides determina lo que puedes mejorar. Las métricas sintéticas más importantes operativamente se dividen en tres categorías:
Métricas de Disponibilidad
- Porcentaje de tiempo activo (objetivo: 99.9% o mejor según SLA)
- Tasa de error por endpoint y región geográfica
- Códigos de estado HTTP (errores 4xx del cliente, errores 5xx del servidor)
- Tasa de éxito de resolución DNS y tiempo de respuesta
- Validez del certificado SSL/TLS y días hasta su expiración
Métricas de Rendimiento
- Tiempo hasta el primer byte (TTFB) — capacidad de respuesta del servidor
- First Contentful Paint (FCP) y Largest Contentful Paint (LCP) — Core Web Vitals
- Cumulative Layout Shift (CLS) — estabilidad visual
- Interaction to Next Paint (INP) — Core Web Vital de capacidad de respuesta (mediciones de laboratorio aproximan valores en campo)
- Tiempo total de carga de página y tiempo de carga del DOM
- Tiempo de respuesta de la API (latencia p50, p95, p99)
- Tiempo por paso de la transacción — qué paso en el recorrido de múltiples pasos es el más lento
Métricas de Confiabilidad y SLA
- Tiempo medio para la detección (MTTD) — qué tan rápido se detectan los problemas dentro del intervalo de prueba
- Tiempo medio para la resolución (MTTR) — qué tan rápido se solucionan
- Porcentaje de cumplimiento de SLA/SLO sobre ventanas temporales móviles
- Diferencia de línea base de rendimiento — cambio en tiempo de respuesta vs promedio histórico
Monitoreo Sintético vs Monitoreo de Usuario Real vs APM

Estos tres enfoques de monitoreo sirven para propósitos distintos y a menudo se confunden. Así es como difieren:
| Dimensión | Monitoreo Sintético | Monitoreo de Usuario Real (RUM) | APM |
|---|---|---|---|
| Fuente de datos | Simulaciones con scripts desde agentes | Sesiones reales de usuario (fragmento JS) | Instrumentación backend (trazas, registros) |
| Cuándo se recopilan los datos | 24/7, en un calendario definido de pruebas | Sólo cuando hay usuarios reales activos | Durante la ejecución real de la aplicación |
| Tipo | Activo / proactivo | Pasivo / reactivo | Interno / nivel de código |
| Mejor para | Tiempo activo, detección de regresiones, validación de SLA | Experiencia real del usuario, rendimiento geográfico, análisis de sesiones | Análisis de causa raíz, cuellos de botella a nivel de código |
| Funciona pre-lanzamiento? | Sí | No | Sí (en staging) |
| ¿Funciona en ventanas de bajo tráfico? | Sí | Limitado | Sí, pero menos solicitudes = menos muestras |
| ¿Cubre servicios de terceros? | Sí (pruebas API y DNS) | Parcialmente | Depende de la instrumentación |
| ¿Detecta rutas de usuario desconocidas? | No (solo con guiones) | Sí | Parcialmente |
La clave: el monitoreo sintético y RUM son complementarios, no competidores. El monitoreo sintético te da mediciones base coherentes y proactivas. RUM te dice qué está pasando con usuarios reales diversos en cada dispositivo, navegador y condición de red. Usar ambos juntos te da la imagen más completa de la experiencia digital.
APM se sitúa en una capa diferente, proporcionando trazas a nivel de código y datos de rendimiento del servidor. Juntos, los tres forman una cobertura integral de monitoreo del rendimiento del backend y la experiencia del usuario. Para una práctica completa de observabilidad, los equipos típicamente combinan APM con logs, métricas y trazas distribuidas para apoyar investigaciones de causa raíz.
Por qué los equipos usan el monitoreo sintético: 8 beneficios clave
- Detectar problemas antes que los usuarios. Las pruebas sintéticas se ejecutan continuamente, incluso fuera de horas laborables. Sabrás sobre un flujo de pago roto a las 2 a.m. antes que tus clientes se despierten y lo encuentren.
- Establecer líneas base de rendimiento. Al ejecutar las mismas pruebas repetidamente con el tiempo, construyes una base confiable de rendimiento esperado. Desviaciones más allá de los umbrales definidos — confirmadas en ubicaciones o intervalos consecutivos — pueden activar alertas, filtrando ruidos transitorios de red.
- Validar despliegues nuevos rápidamente. Ejecuta pruebas sintéticas contra tu entorno de staging antes de poner en vivo para confirmar que nada se rompió, luego continúa monitoreando inmediatamente después del despliegue para validar el comportamiento en producción — detectando regresiones antes que afecten a usuarios reales.
- Proteger SLAs y SLOs. El monitoreo sintético produce datos continuos y objetivos de rendimiento que necesitas para demostrar cumplimiento de SLA a clientes y rápidamente identificar cuando un proveedor externo no cumple con los estándares acordados.
- Responsabilizar a proveedores externos. Las aplicaciones modernas dependen de CDNs, procesadores de pagos, plataformas de análisis y APIs SaaS. Las pruebas sintéticas pueden monitorear cada uno de estos independientemente, dándote evidencia cuando la degradación de un proveedor impacta a tus usuarios.
- Reducir MTTR. Debido a que las verificaciones sintéticas capturan pasos, tiempos y artefactos consistentes — incluyendo grabaciones de video sincronizadas con gráficos de cascada en Dotcom-Monitor — a menudo facilitan reproducir y diagnosticar problemas. Fallos intermitentes o dependientes del estado pueden requerir investigación más profunda del lado del servidor, pero contar con la secuencia exacta de pasose y el tiempo reducen significativamente la búsqueda.
- Monitorear pre-lanzamiento y áreas de bajo tráfico.¿Lanzando en una nueva geografía? ¿Construyendo una nueva función que aún no está en producción? El monitoreo sintético puede probar esas áreas antes de que cualquier usuario real las visite.
- Apoyar la planificación de capacidad.Los datos históricos de monitoreo sintético revelan tendencias: ¿se está volviendo más lenta tu API a medida que crece tu base de usuarios? ¿Los períodos de mayor tráfico causan degradación? Estos datos alimentan directamente las decisiones de planificación de capacidad e infraestructura.
Casos de Uso de Monitoreo Sintético por Equipo e Industria
Por Equipo
- Equipos SRE y de plataforma: Son responsables de los SLO de disponibilidad. Usan el monitoreo sintético para rastrear las tasas de quema de SLO, establecer presupuestos de error y recibir alertas sobre violaciones antes de que superen los límites de SLA.
- DevOps e ingeniería de aplicaciones: Ejecutan verificaciones sintéticas en entornos de staging como parte de la validación de lanzamiento. Monitorean después del despliegue para detectar regresiones rápidamente y reducir el tiempo para decidir sobre reversión.
- Equipos de API y backend: Monitorean la disponibilidad, latencia y corrección de los endpoints API REST y SOAP. Ejecutan pruebas API multietapa que enlazan autenticación, operaciones CRUD y validación en secuencia.
- Equipos de ecommerce y experiencia digital: Protegen los flujos de pago, la búsqueda de productos y el inicio de sesión en cuentas. Monitorean Core Web Vitals para proteger tanto la experiencia del usuario como el posicionamiento SEO. Estudios en ecommerce han mostrado impactos medibles en la conversión debido a retrasos en el tiempo de carga — aunque el umbral específico varía según la industria, las expectativas de los usuarios y el rendimiento base.
Por Industria
- Servicios financieros: Monitorean plataformas de banca en línea, pasarelas de pago y sistemas de trading para disponibilidad y tiempos de respuesta subsegundos. Validan la configuración SSL/TLS de forma continua.
- Tecnología en salud: Aseguran que los sistemas EHR, portales de pacientes y plataformas de telemedicina sean accesibles y tengan buen desempeño — particularmente crítico durante períodos de alta demanda.
- Ecommerce y retail: Monitorean las APIs de inventario, la funcionalidad del carrito y los flujos de pago para garantizar disponibilidad continua.
- Medios y streaming: Validan el desempeño de CDN, endpoints API para motores de recomendación y la disponibilidad de servicios de streaming.
- Sector público: Monitorean portales y servicios dirigidos a ciudadanos que deben mantener compromisos de disponibilidad definidos en SLAs públicos.
7 Desafíos y Limitaciones del Monitoreo Sintético
El monitoreo sintético es una herramienta poderosa, pero tiene limitaciones reales que todo equipo debe comprender.
- Brechas de cobertura con scripts: Las pruebas sintéticas solo cubren los recorridos de usuario que hayas scriptado. La combinación de diferentes caminos de usuario, configuraciones de dispositivos, condiciones de red, estados de aplicación y edgelos casos crean un espacio combinatorio que es poco práctico de programar de manera exhaustiva. El Monitoreo de Usuarios Reales llena este vacío capturando lo que encuentran los usuarios reales.
- Fragilidad de las pruebas: Los scripts de transacciones basados en navegador son sensibles a los cambios en la interfaz de usuario. Cuando cambia el texto de un botón, se renombra un campo de formulario o se reestructura una página, las pruebas pueden fallar, incluso si la aplicación en sí funciona bien. Esto genera ruido en las alertas y requiere mantenimiento continuo.
- Carga de mantenimiento: A medida que su aplicación evoluciona, sus scripts de prueba también deben evolucionar. Para aplicaciones grandes con lanzamientos frecuentes, mantener los scripts actualizados representa un costo operativo real.
- No hay señal subjetiva de UX: El monitoreo sintético mide métricas objetivas: tiempos de respuesta, tasas de error, disponibilidad. No puede capturar la satisfacción del usuario, problemas de diseño visual, accesibilidad o la sensación subjetiva de una interfaz confusa.
- Las condiciones simuladas difieren de la realidad: Los agentes sintéticos se ejecutan desde entornos controlados. Puede que no reproduzcan la diversidad de dispositivos reales de usuarios, redes móviles con ancho de banda variable, proxies corporativos o enrutamiento regional de ISP.
- Punto ciego en el backend: El monitoreo sintético es una vista de fuera hacia adentro. Te dice que la aplicación está lenta, pero no por qué a nivel de código. Para análisis de causa raíz a nivel de código se necesitan APM y trazado distribuido.
- Costo a gran escala: Ejecutar pruebas frecuentes desde muchas ubicaciones globales con scripts de transacción complejos puede volverse costoso, especialmente a medida que crecen el número de agentes, la frecuencia de pruebas y los requisitos de retención de datos.
9 Mejores Prácticas de Monitoreo Sintético

- Empiece con sus rutas críticas. No intente probar todo a la vez. Comience con los 3–5 viajes de usuario que impulsan directamente los ingresos o están cubiertos por SLAs: inicio de sesión, pago, API principal y sus páginas de aterrizaje más visitadas.
- Monitoree desde donde están sus usuarios. Ejecute pruebas desde las regiones geográficas donde se encuentran los usuarios reales. Una prueba que pasa desde un nodo en US-East no le dice nada sobre el rendimiento en el Sudeste Asiático o Europa Occidental. Las más de 30 ubicaciones globales de Dotcom-Monitor le permiten adecuar la ubicación de agentes a la geografía de sus usuarios.
- Utilice agentes privados para entornos internos. Para servicios detrás de un firewall — APIs internas, intrany aplicaciones, entornos de staging — despliega un agente privado dentro de tu red. Recuerda: un agente privado que pasa una prueba confirma que ese servicio específico está funcionando desde ese punto de vista, no que todo tu entorno interno esté saludable.
- Establece umbrales de alerta significativos. Configura las condiciones de alerta basadas en tu línea base de rendimiento establecida — por ejemplo, alerta cuando el tiempo de respuesta exceda 1.5–2x el promedio de la línea base, o cuando la disponibilidad baje del umbral de tu SLO. Dotcom-Monitor soporta filtros configurables para que puedas ajustar la sensibilidad por revisión en lugar de alertar ante cada fluctuación.
- Valida el staging antes de pasar a producción. Ejecuta las pruebas de Dotcom-Monitor contra tu entorno de staging antes de cada lanzamiento para detectar regresiones tempranamente. Después del despliegue, monitorea producción inmediatamente durante los primeros 30–60 minutos — el período cuando surgen la mayoría de problemas relacionados con el despliegue. Usa las integraciones de alerta de Dotcom-Monitor (Slack, PagerDuty) para dirigir las alertas post-despliegue directamente a tu equipo de guardia.
- Mantén los scripts de prueba en control de versiones. Trata los scripts de monitoreo como código. Guárdalos en Git, revisa los cambios con pull requests, y revierte cuando una actualización de script cause falsas alarmas.
- Combina con RUM para cobertura completa. Usa monitoreo sintético para detección proactiva y medición de línea base. Añade RUM para capturar la experiencia real de los usuarios en condiciones diversas. Ambos juntos proveen una cobertura completa del monitoreo de tu experiencia digital.
- Analiza regularmente los gráficos de cascada. No sólo observes el tiempo total de carga. Revisa los gráficos de cascada para ver qué recursos individuales — scripts de terceros, imágenes grandes, llamadas API lentas — contribuyen más al tiempo de carga. La captura de video sincronizada con los gráficos de cascada de Dotcom-Monitor hace este diagnóstico mucho más rápido.
- Revisa y actualiza los scripts después de lanzamientos importantes. Tras cualquier cambio significativo en la UI o refactorización de API, audita tus scripts sintéticos para asegurar que todavía reflejan los recorridos de usuario con precisión y no han quedado inválidos con el lanzamiento.
¿Cómo analizar los datos del monitoreo sintético?
Recopilar datos de monitoreo sintético sólo es valioso si actúas en base a ellos. Aquí hay un flujo de trabajo práctico para transformar los resultados crudos en mejoras de rendimiento:
- Revisa diariamente los paneles de disponibilidad y tasa de errores. Busca patrones: ¿los errores se concentran en una región específica, en un endpoint particular o en una hora del día determinada?
- Haz seguimiento de las tendencias de rendimiento a lo largo del tiempo, no sólo capturas puntuales. Una página que tarda 2.1 segundos hoy pero que tardaba 1.6 segundos hace tres semanas tiene una regresión — incluso si aún no ha superado tu umbral de alerta.
- Usa gráficos de cascada y video para identificar cuellos de botella. Identifica los recursos más lentos en cada página. Las grabaciones de video de Dotcom-Monitor sincronizadas con gráficos de cascada muestran exactamente lo que experimentó el navegador durante una falla — sin suposiciones.
- Correlaciona las fallas sintéticas con eventos de despliegue. Cuando una prueba comienza a fallar, revisa tu registro de despliegue. Un lanzamiento poco antes de la falla es una señal fuerte que vale la pena investigar primero.
- Realiza análisis de causa raíz (RCA) en fallas recurrentes. No solo soluciones las alertas — documéntalas. Los patrones de fallas recurrentes en regiones específicas o en momentos específicos suelen indicar problemas sistémicos de infraestructura que deben abordarse de manera proactiva.
- Informa regularmente sobre el cumplimiento de SLA/SLO. Usa datos históricos de monitoreo sintético para generar informes de tiempo de actividad para las partes interesadas y clientes. Datos objetivos con marcas de tiempo generan confianza y son esenciales cuando surgen disputas con proveedores externos.
¿Qué buscar en una herramienta de monitoreo sintético?
No todas las plataformas de monitoreo sintético son iguales. Al evaluar una solución, busca estas capacidades:
- Red global de monitoreo — más de 30 ubicaciones para que puedas probar desde donde realmente están tus usuarios
- Soporte para agentes privados — despliega agentes dentro de tu propia red para monitoreo de intranet y staging
- Amplia cobertura de tipos de prueba — uptime, navegador, transacción, API (REST, SOAP, Postman, Insomnia), DNS, SSL y verificaciones de protocolo en una sola plataforma
- Pruebas en navegador real — monitoreo que se ejecuta en Chrome, Edge, Firefox y navegadores móviles reales, no solo motores sin cabeza
- Herramientas visuales de depuración — gráficos de cascada, grabaciones de video sincronizadas con ejecuciones de monitoreo y capturas de pantalla tipo filmstrip para diagnóstico rápido
- Grabación flexible de scripts — herramientas como EveryStep Web Recorder que capturan interacciones reales de usuarios sin requerir scripts de automatización codificados a mano
- Profundidad en métricas de rendimiento — TTFB, FCP, LCP, CLS, INP y desglose completo de tiempos de navegación
- Integraciones de alertas — soporte para PagerDuty, Slack, Teams, email, SMS, WhatsApp y webhooks para tu flujo de trabajo de guardia
- Cheques activados bajo demanda — capacidad para ejecutar verificaciones vía API para que puedas activar monitoreo como parte de flujos de trabajo de lanzamiento
- Paneles SLA/SLO — informes integrados sobre compromisos de tiempo de actividad y rendimiento con paneles compartibles
- Precios transparentes — costo predecible modelo que se adapta a tus necesidades
Comienza el Monitoreo Sintético con Dotcom-Monitor
Dotcom-Monitor ofrece monitoreo sintético de nivel empresarial desde una red global de más de 30 ubicaciones de monitoreo, soportando verificaciones de tiempo de actividad, pruebas de páginas con navegador real, monitoreo de transacciones mediante EveryStep Web Recorder, monitoreo de API (REST, SOAP, Postman, Insomnia), monitoreo DNS con validación DNSSEC, monitoreo de certificados SSL y una suite completa de verificaciones de protocolos — todo en una sola plataforma.
Ya sea que estés protegiendo un flujo de pago de comercio electrónico, monitoreando una API pública, validando el cumplimiento de SLA para clientes empresariales o manteniendo aplicaciones internas para tu equipo, Dotcom-Monitor te brinda la visibilidad proactiva para detectar y resolver problemas antes de que afecten a usuarios reales.
