O monitoramento sintético é um método proativo de teste de desempenho que usa transações automatizadas e roteirizadas para simular interações reais de usuários com suas aplicações — medindo disponibilidade, tempo de resposta e funcionalidade antes que os problemas atinjam os usuários reais.
Se sua aplicação ficar indisponível às 3 da manhã ou acelerar para uma lentidão em uma região onde você ainda não tem usuários reais, você precisa saber disso rapidamente — dentro do próximo intervalo de sondagem — e não quando uma reclamação de cliente chegar na sua caixa de entrada. É exatamente para isso que o monitoramento sintético foi criado.
Neste guia, cobriremos tudo o que você precisa saber sobre monitoramento sintético: como ele funciona, os diferentes tipos de testes, quais métricas importam, como se compara ao monitoramento de usuários reais (RUM) e APM, e como usá-lo de forma eficaz em produção. Também apresentaremos as limitações que ninguém costuma falar e compartilharemos as melhores práticas usadas por equipes SRE e DevOps em grande escala.
O que é Monitoramento Sintético?
O monitoramento sintético — também chamado de monitoramento ativo, monitoramento dirigido, ou teste sintético — funciona ao implantar agentes de monitoramento automatizados que enviam continuamente solicitações roteirizadas para suas aplicações, APIs ou serviços web em uma programação definida. Esses agentes operam em diferentes níveis técnicos: agentes HTTP leves que enviam solicitações para verificar a disponibilidade básica e códigos de resposta, e agentes sofisticados baseados em navegador que executam motores completos de navegador para executar JavaScript, renderizar páginas, gerenciar sessões e simular interações complexas de múltiplas etapas do usuário. O EveryStep Web Recorder da Dotcom-Monitor usa navegadores reais — não apenas motores headless — para gravar e reproduzir qualquer ação do usuário em mais de 40 configurações de navegadores para desktop e mobile.
Por serem simulações roteirizadas e não observações passivas do tráfego real, o monitoramento sintético opera 24/7 independentemente de haver usuários reais ativos. Você obtém dados de desempenho consistentes e reproduzíveis sob condições controladas — dia ou noite, durante picos de tráfego ou janelas silenciosas de manutenção.
O termo “monitoramento ativo” o diferencia de abordagens passivas como o Monitoramento de Usuário Real (RUM), que captura dados apenas quando usuários reais interagem com o sistema. O monitoramento sintético não espera — ele realiza sondagens em uma programação definida para que você possa detectar falhas e regressões rapidamente, frequentemente dentro do próximo intervalo de sondagem, ao invés de esperar pelos relatos dos usuários.
Como Funciona o Monitoramento Sintético?
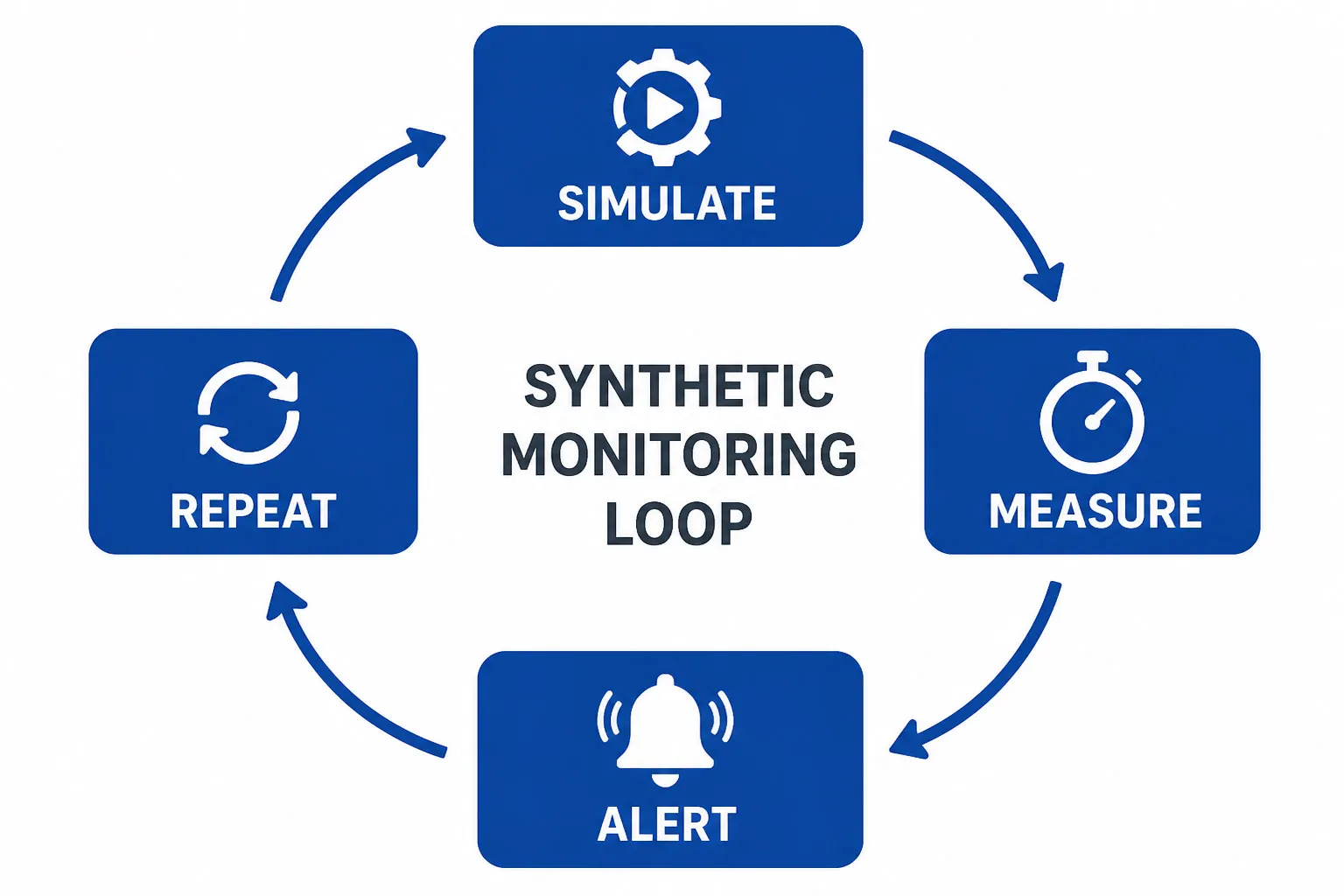
No seu núcleo, o monitoramento sintético segue um ciclo simples: simular, medir, alertar, repetir. Aqui está o fluxo de trabalho passo a passo:
- Defina jornadas e endpoints críticos do usuário. Identifique quais transações são mais importantes: fluxos de login, processos de checkout, verificações de saúde da API, resolução de DNS e validade do certificado SSL.
- Grave ou escreva seus testes. Use uma ferramenta como o EveryStep Web Recorder da Dotcom-Monitor para capturar interações reais do navegador — cliques, preenchimento de formulários, navegações — que são salvas como scripts reproduzíveis. Para verificações de API e protocolos, configure tarefas HTTP, DNS ou ping diretamente na plataforma.
- Implemente agentes de monitoramento globalmente. Execute testes de múltiplas localizações geográficas usando agentes públicos (30+ localizações globais) e/ou agentes privados implantados dentro dos seus próprios data centers ou perímetro de rede.
- Execute conforme agendamento. Os testes são realizados em intervalos configurados — tão frequentes quanto a cada minuto até a cada três horas. Um agente de monitoramento envia as requisições com script, aguarda uma resposta e registra o resultado.
- Meça resultados técnicos e funcionais. Capture tempos de resposta, códigos de status HTTP, tempo de carregamento da página, Time to First Byte (TTFB), First Contentful Paint (FCP) e Core Web Vitals (LCP, CLS e INP). Observe que métricas de interação como INP refletem entrada real do usuário e são melhor validadas junto com dados de usuários reais — o sintético fornece medições controladas, em estilo laboratorial.
- Alerta sobre problemas confirmados. O Dotcom-Monitor envia alertas imediatamente após a detecção por padrão. Filtros configuráveis — como gatilhos baseados em limiar, condições de tipo de erro ou regras específicas por localização — permitem reduzir ruídos para verificações menos críticas. Para testes de transações multi-etapas, considere se tentar rodar novamente um script que falhou pode ter efeitos colaterais indesejados antes de habilitar tentativas automáticas.
- Use pontos de vista estrategicamente. Um agente privado que passa em um teste confirma que o serviço e a jornada específica estão funcionando a partir daquele ponto interno — ajudando a isolar se um problema é voltado para a internet, relacionado à borda ou interno. Agentes globais externos medem o caminho completo do usuário: resolução de DNS, bordas da CDN, roteamento do ISP e latência geográfica.
Veja o Monitoramento Sintético da Dotcom-Monitor em Ação → Explore a Página da Solução de Monitoramento Sintético
7 Tipos de Testes de Monitoramento Sintético

O monitoramento sintético não é um modelo único para todos. Diferentes tipos de testes servem a diferentes propósitos, e estratégias maduras de monitoramento combinam vários deles.
Monitoramento de Disponibilidade / Tempo de Atividade
O monitoramento de uptime usa sondas de rede e de endpoint para confirmar se um servidor ou serviço está acessível e respondendo. Essas verificações operam em diferentes camadas de rede, cada uma validando algo distinto:
- Monitoramento de Ping (ICMP) — testa a acessibilidade básica de rede a um host quando permitido pelas regras do firewall. Um ping bem-sucedido confirma que o host está na rede, mas não prova que a aplicação está saudável.
- Monitoramento de Porta (TCP) — testa se uma porta específica está aberta e aceitando conexões. Confirma a acessibilidade na camada de transporte.
- Verificações de Uptime HTTP/HTTPS — validam um endpoint de aplicação na camada de aplicação, verificando códigos de status, conteúdo da resposta e validade do SSL. Para o uptime da aplicação, as verificações HTTP com asserções de resposta e conteúdo são a camada mais significativa para monitorar.
Dotcom-Monitor oferece os três como produtos distintos — Monitoramento de Ping, Monitoramento de Porta e Monitoramento de Uptime baseado em HTTP — porque um ping bem-sucedido não garante uma aplicação saudável.
Monitoramento de Navegador / Desempenho de Página
Um navegador real carrega uma página web completa — executando JavaScript, renderizando CSS, carregando recursos de terceiros — e registra o tempo de carregamento granular. O monitoramento de páginas web do Dotcom-Monitor roda em navegadores reais Chrome, Edge, Firefox e móveis (mais de 40 configurações), em vez de apenas um motor headless, produzindo dados de desempenho autênticos que refletem a experiência real do usuário. Métricas chave incluem TTFB, FCP, LCP, tempo de carregamento do DOM e tempo total de carregamento da página. Gráficos de cascata e gravações de vídeo sincronizadas com esses gráficos permitem identificar exatamente quais recursos estão mais lentos. Isso é importante para SEO: os Core Web Vitals do Google (LCP, CLS, INP) são um fator de ranqueamento, e pontuações consistentemente ruins impactarão sua visibilidade nas buscas.
Monitoramento de Transação
O monitoramento de transação simula uma jornada completa do usuário — uma sequência em múltiplas etapas como buscar um produto, adicioná-lo ao carrinho, inserir detalhes de pagamento e concluir a compra. O EveryStep Web Recorder da Dotcom-Monitor captura essas jornadas gravando interações reais do navegador, que são reproduzidas cContinuamente por meio de agentes de monitoramento. Qualquer etapa quebrada — um formulário que não envia, um botão deslocado por uma mudança na UI, um loop de redirecionamento introduzido por uma implantação — é detectada imediatamente. Este é o tipo de teste mais poderoso para proteger fluxos de negócios críticos para a receita.
Monitoramento de API
Testa a saúde, desempenho e correção de endpoints de API REST e SOAP. Valida métodos HTTP (GET, POST, PUT, PATCH), verifica códigos de status de resposta, confirma cargas úteis de resposta e mede a latência. O Dotcom-Monitor suporta monitoramento de API REST, monitoramento de API SOAP, monitoramento de coleção Postman e monitoramento de coleção Insomnia — cobrindo toda a gama de tipos de API usados pelas equipes na prática. Testes API multietapas encadeiam as solicitações (autenticar → criar → buscar → deletar) para validar fluxos de trabalho completos. Verificações de certificado SSL/TLS podem ser executadas junto com testes de API para confirmar que os certificados são válidos e não estão próximos do vencimento.
Monitoramento de DNS
Verifica se seus servidores DNS resolvem nomes de host corretamente e dentro de tempos de resposta aceitáveis. Problemas no DNS podem causar interrupções generalizadas e difíceis de diagnosticar — quando o DNS falha, os usuários não conseguem acessar sua aplicação mesmo que seus servidores estejam funcionando perfeitamente. O monitoramento DNS do Dotcom-Monitor valida a precisão da resolução, tempos de resposta e a saúde da cadeia completa de propagação DNS em locais globais. Também valida a cadeia de confiança DNSSEC para garantir que as respostas DNS não foram adulteradas, monitora a consistência do registro SOA e sinaliza mudanças anômalas de DNS — como endereços IP inesperados ou modificações não autorizadas de registros — que podem indicar roteamento incorreto ou envenenamento de cache. O monitoramento DNS suporta os tipos de registro A, AAAA, MX, NS, CNAME, PTR e SOA.
Monitoramento de Certificado SSL
Acompanha a validade, datas de expiração e status de revogação de certificados SSL/TLS. Um certificado expirado ou mal configurado causa avisos de confiança imediatos em todos os navegadores, impactando diretamente a confiança do usuário e as taxas de conversão. O monitoramento SSL automatizado alerta você dias ou semanas antes do vencimento de um certificado, dando tempo para sua equipe renovar sem interrupções.
Monitoramento de Protocolo e Rede
Além dos checagens de web e API, o Dotcom-Monitor monitora a pilha completa de protocolos de rede: email (SMTP, POP3, IMAP), VoIP e SIP, FTP, UDP, WebSocket e análise de caminho traceroute. O monitoramento de ping (ICMP) e a varredura de portas completam a visibilidade da camada de rede. Esses testes são particularmente valiosos para organizações que operam infraestruturas complexas onde a saúde da aplicação depende de múltiplos serviços subjacentes.
3 Métricas Principais de Monitoramento Sintético para Acompanhar

O que você mede determina o que pode melhorar. As métricas sintéticas mais importantes operacionalmente se enquadram em três categorias:
Métricas de Disponibilidade
- Porcentagem de uptime (meta: 99,9% ou melhor conforme SLA)
- Taxa de erro por endpoint e região geográfica
- Códigos de status HTTP (erros 4xx do cliente, erros 5xx do servidor)
- Taxa de sucesso e tempo de resposta na resolução de DNS
- Validade do certificado SSL/TLS e dias até a expiração
Métricas de Desempenho
- Tempo para o Primeiro Byte (TTFB) — responsividade do servidor
- First Contentful Paint (FCP) e Largest Contentful Paint (LCP) — Core Web Vitals
- Cumulative Layout Shift (CLS) — estabilidade visual
- Interaction to Next Paint (INP) — responsividade Core Web Vital (medições de laboratório aproximam valores de campo)
- Tempo total de carregamento da página e tempo de carregamento do DOM
- Tempo de resposta da API (latência p50, p95, p99)
- Tempo das etapas da transação — qual etapa na jornada multi-etapas é a mais lenta
Métricas de Confiabilidade & SLA
- Tempo Médio para Detecção (MTTD) — rapidez com que problemas são detectados dentro do intervalo da sonda
- Tempo Médio para Resolução (MTTR) — rapidez com que são corrigidos
- Porcentagem de conformidade com SLA/SLO em janelas de tempo móveis
- Delta da linha de base de desempenho — variação no tempo de resposta vs média histórica
Monitoramento Sintético vs. Monitoramento de Usuário Real vs. APM

Essas três abordagens de monitoramento atendem a propósitos distintos e frequentemente são confundidas. Veja como elas diferem:
| Dimensão | Monitoramento Sintético | Monitoramento de Usuário Real (RUM) | APM |
|---|---|---|---|
| Fonte dos dados | Simulações scriptadas a partir de agentes | Sessões reais dos usuários (snippet JS) | Instrumentação backend (traces, logs) |
| Quando os dados são coletados | 24/7, em cronograma definido de sondagem | Apenas quando usuários reais estão ativos | Durante a execução real da aplicação |
| Tipo | Ativo / proativo | Passivo / reativo | Interno / nível de código |
| Melhor para | Disponibilidade, detecção de regressão, validação de SLA | UX real, desempenho geográfico, análise de sessões | Análise de causa raiz, gargalos em nível de código |
| Funciona pré-lançamento? | Sim | Não | Sim (em staging) |
| Funciona em janelas de baixo tráfego? | Sim | Limitado | Sim, mas menos solicitações = menos amostras |
| Cobre serviços de terceiros? | Sim (testes de API e DNS) | Parcialmente | Depende da instrumentação |
| Detecta caminhos desconhecidos de usuários? | Não (somente scriptado) | Sim | Parcialmente |
A principal percepção: monitoramento sintético e RUM são complementares, não concorrentes. O monitoramento sintético fornece medições de linha de base consistentes e proativas. O RUM mostra o que está acontecendo para diversos usuários reais em todos os dispositivos, navegadores e condições de rede. Usar ambos juntos oferece a imagem mais completa da experiência digital.
APM está em uma camada diferente, fornecendo rastreamentos a nível de código e dados de desempenho do lado do servidor. Juntos, os três formam uma cobertura abrangente de monitoramento pela experiência do usuário e desempenho do backend. Para uma prática completa de observabilidade, as equipes normalmente combinam APM com logs, métricas e rastreamentos distribuídos para apoiar a investigação da causa raiz.
Por que as equipes usam monitoramento sintético: 8 benefícios principais
- Detectar problemas antes dos usuários.Os testes sintéticos são executados continuamente, mesmo fora do horário comercial. Você saberá sobre um problema no fluxo de checkout às 2 da manhã antes que seus clientes acordem e o encontrem.
- Estabelecer linhas de base de desempenho.Ao executar os mesmos testes repetidamente ao longo do tempo, você constrói uma linha de base confiável do desempenho esperado. Desvios além dos limites definidos — confirmados entre locais ou intervalos consecutivos — podem disparar alertas, filtrando ruídos transitórios da rede.
- Validar novos deployments rapidamente.Execute testes sintéticos contra seu ambiente de staging antes de entrar em produção para confirmar que nada quebrou, depois continue monitorando imediatamente após a implantação para validar o comportamento em produção — capturando regressões antes que afetem usuários reais.
- Proteger SLAs e SLOs.O monitoramento sintético produz dados contínuos e objetivos de desempenho que você precisa para comprovar conformidade com SLAs para os clientes e identificar rapidamente quando um fornecedor terceirizado não está atendendo os padrões acordados.
- Responsabilizar fornecedores terceiros.Aplicações modernas dependem de CDNs, processadores de pagamento, plataformas de análise e APIs SaaS. Testes sintéticos podem monitorar cada um desses independentemente, fornecendo evidências quando a degradação de um fornecedor está impactando seus usuários.
- Reduzir MTTR.Porque as verificações sintéticas capturam etapas, tempos e artefatos consistentes — incluindo gravações de vídeo sincronizadas com gráficos waterfall no Dotcom-Monitor — elas frequentemente facilitam a reprodução e triagem de problemas. Falhas intermitentes ou dependentes do estado podem ainda exigir investigação mais profunda do lado do servidor, mas ter a sequência exata das etapase o timing reduzem significativamente a busca.
- Monitore áreas de pré-lançamento e baixo tráfego.Lançando em uma nova região? Construindo um novo recurso ainda não em produção? O monitoramento sintético pode testar essas áreas antes que qualquer usuário real as visite.
- Suporte ao planejamento de capacidade.Dados históricos do monitoramento sintético revelam tendências: sua API está ficando mais lenta à medida que sua base de usuários cresce? Os períodos de pico de tráfego estão causando degradação? Esses dados alimentam diretamente as decisões de planejamento de capacidade e infraestrutura.
Casos de Uso de Monitoramento Sintético por Equipe e Indústria
Por Equipe
- Equipes de SRE e plataforma: Responsáveis pelos SLOs de uptime. Use o monitoramento sintético para acompanhar as taxas de queima de SLO, definir orçamentos de erro e receber alertas sobre violações antes que ultrapassem os limites SLA.
- DevOps e engenharia de aplicações: Execute verificações sintéticas contra ambientes de staging como parte da validação de lançamentos. Monitore pós-implantação para detectar regressões rapidamente e reduzir o tempo de decisão para rollback.
- Equipes de API e backend: Monitore disponibilidade, latência e correção dos endpoints REST e SOAP. Execute testes multietapas de API que encadeiam autenticação, operações CRUD e validação em sequência.
- Equipes de ecommerce e experiência digital: Proteja fluxos de checkout, pesquisa de produtos e login de conta. Monitore Core Web Vitals para proteger tanto a experiência do usuário quanto o ranking de SEO. Estudos em ecommerce mostraram impactos mensuráveis na conversão causados por atrasos no tempo de carregamento — embora o limite específico varie conforme a indústria, expectativas do usuário e desempenho básico.
Por Indústria
- Serviços financeiros: Monitore plataformas bancárias online, gateways de pagamento e sistemas de negociação para disponibilidade e tempos de resposta abaixo de um segundo. Valide continuamente a configuração SSL/TLS.
- Tecnologia em saúde: Garanta que sistemas EHR, portais de pacientes e plataformas de telemedicina estejam acessíveis e com bom desempenho — especialmente críticos durante períodos de alta demanda.
- Ecommerce e varejo: Monitore APIs de inventário, funcionalidade do carrinho e fluxos de checkout para disponibilidade contínua.
- Mídia e streaming: Valide desempenho do CDN, endpoints de API para motores de recomendação e disponibilidade do serviço de streaming.
- Setor público: Monitore portais e serviços voltados ao cidadão que devem manter compromissos de disponibilidade definidos em SLAs públicos.
7 Desafios e Limitações do Monitoramento Sintético
O monitoramento sintético é uma ferramenta poderosa, mas tem limitações reais que toda equipe deve entender.
- lacunas na cobertura scriptada: Os testes sintéticos cobrem somente as jornadas de usuário que você scriptou. A combinação de diferentes caminhos de usuário, configurações de dispositivo, condições de rede, estados da aplicação e edgecasos cria um espaço combinatório impraticável para scriptar de forma abrangente. O Monitoramento de Usuário Real preenche essa lacuna capturando o que os usuários reais encontram.
- Fragilidade dos testes: Scripts de transações baseados em navegador são sensíveis a mudanças na interface do usuário. Quando o texto de um botão muda, um campo de formulário é renomeado ou uma página é reestruturada, os testes podem falhar — mesmo que a aplicação esteja funcionando bem. Isso gera ruído de alertas e requer manutenção contínua.
- Sobrecarga de manutenção: À medida que sua aplicação evolui, seus scripts de teste também devem evoluir. Para aplicações grandes com lançamentos frequentes, manter os scripts atualizados é um custo operacional real.
- Falta de sinal subjetivo de UX: O monitoramento sintético mede métricas objetivas: tempos de resposta, taxas de erro, disponibilidade. Ele não consegue capturar satisfação do usuário, problemas de design visual, acessibilidade ou a sensação subjetiva de uma interface confusa.
- Condições simuladas diferem da realidade: Agentes sintéticos rodam em ambientes controlados. Eles podem não replicar a diversidade de dispositivos reais, redes móveis com largura de banda variável, proxies corporativos ou roteamento regional de ISP.
- Ponto cego no backend: O monitoramento sintético é uma visão de fora para dentro. Ele indica que a aplicação está lenta, mas não o porquê no nível do código. APM e rastreamento distribuído são necessários para análise de causa raiz no nível do código.
- Custo em escala: Executar testes frequentes de muitos locais globais com scripts de transações complexas pode se tornar caro, especialmente conforme o número de agentes, a frequência dos testes e os requisitos de retenção de dados crescem.
9 Melhores Práticas de Monitoramento Sintético

- Comece com seus caminhos críticos. Não tente testar tudo de uma vez. Comece com as 3–5 jornadas de usuário que diretamente geram receita ou são cobertas por SLAs: login, checkout, API principal e suas páginas de destino mais visitadas.
- Monitore de onde seus usuários estão. Execute testes das regiões geográficas onde os usuários reais estão localizados. Um teste bem-sucedido de um nó US-East não diz nada sobre o desempenho no Sudeste Asiático ou na Europa Ocidental. Os mais de 30 locais globais do Dotcom-Monitor permitem que você alinhe a localização dos agentes à geografia de seus usuários.
- Use agentes privados para ambientes internos. Para serviços atrás de firewall — APIs internas, intrane aplicativos, ambientes de staging — implante um agente privado dentro da sua rede. Lembre-se: um agente privado que passa em um teste confirma que aquele serviço específico está funcionando daquele ponto, não que todo o seu ambiente interno está saudável.
- Defina limites de alerta significativos. Configure condições de alerta com base na linha de base de desempenho estabelecida — por exemplo, alerte quando o tempo de resposta exceder 1,5–2x a média da linha de base, ou quando a disponibilidade cair abaixo do seu limite SLO. O Dotcom-Monitor suporta filtros configuráveis para que você possa ajustar a sensibilidade por verificação, em vez de alertar a cada flutuação.
- Valide o staging antes de entrar em produção. Execute verificações do Dotcom-Monitor contra seu ambiente de staging antes de cada release para detectar regressões cedo. Após a implantação, monitore a produção imediatamente nos primeiros 30–60 minutos — o período em que a maioria dos problemas relacionados à implantação surgem. Use as integrações de alerta do Dotcom-Monitor (Slack, PagerDuty) para direcionar alertas pós-implantação diretamente para sua equipe de plantão.
- Mantenha scripts de teste no controle de versão. Trate scripts de monitoramento como código. Armazene-os no Git, revise mudanças em pull requests e faça rollback quando uma atualização de script gerar falsos alertas.
- Combine com RUM para cobertura completa. Use monitoramento sintético para detecção proativa e medição da linha de base. Sobreponha o RUM para capturar a experiência real dos usuários sob diversas condições. Juntos, eles fornecem cobertura abrangente do monitoramento da sua experiência digital.
- Analise gráficos de waterfall regularmente. Não olhe apenas para o tempo total de carregamento. Revise gráficos de waterfall para ver quais recursos individuais — scripts de terceiros, imagens grandes, chamadas lentas de API — estão contribuindo mais para o tempo de carregamento. A captura de vídeo do Dotcom-Monitor sincronizada com os gráficos de waterfall torna esse diagnóstico muito mais rápido.
- Revise e atualize scripts após grandes releases. Após qualquer mudança significativa na UI ou refatoração de API, audite seus scripts de teste sintético para garantir que ainda refletem jornadas reais do usuário e não foram invalidados pela release.
Como Analisar Dados de Monitoramento Sintético?
Coletar dados de monitoramento sintético só tem valor se você agir com base neles. Aqui está um fluxo prático para transformar resultados brutos de testes em melhorias de desempenho:
- Revise dashboards de disponibilidade e taxa de erro diariamente. Procure padrões: os erros estão concentrados em uma região específica, em um endpoint específico ou em um horário específico do dia?
- Monitore tendências de desempenho ao longo do tempo, não apenas instantâneos pontuais. Uma página que leva 2,1 segundos hoje, mas levou 1.6 segundos três semanas atrás tem uma regressão — mesmo que ainda não tenha ultrapassado seu limite de alerta.
- Use gráficos de cascata e vídeo para identificar gargalos. Identifique os recursos mais lentos em cada página. As gravações de vídeo da Dotcom-Monitor sincronizadas com gráficos de cascata mostram exatamente o que o navegador experimentou durante uma falha — sem suposições.
- Correlacione falhas sintéticas com eventos de implantação. Quando um teste começar a falhar, verifique seu registro de implantação. Um lançamento pouco antes da falha é um forte sinal que vale a pena investigar primeiro.
- Realize análise de causa raiz (RCA) em falhas recorrentes. Não apenas resolva os alertas — documente-os. Padrões de falhas recorrentes em regiões específicas ou em horários específicos frequentemente indicam problemas sistêmicos na infraestrutura que valem a pena ser abordados de forma proativa.
- Relate a conformidade com SLA/SLO regularmente. Use dados históricos do monitoramento sintético para gerar relatórios de tempo de atividade para partes interessadas e clientes. Dados objetivos com carimbo de data e hora constroem confiança e são essenciais quando surgem disputas com fornecedores terceiros.
O que procurar em uma ferramenta de monitoramento sintético?
Nem todas as plataformas de monitoramento sintético são criadas iguais. Ao avaliar uma solução, procure estas capacidades:
- Rede global de monitoramento — mais de 30 locais para que você possa testar de onde seus usuários realmente estão
- Suporte a agentes privados — implemente agentes dentro da sua própria rede para monitoramento de intranet e ambiente de testes
- Amplo cobertura de tipos de teste — uptime, navegador, transação, API (REST, SOAP, Postman, Insomnia), DNS, SSL e verificações de protocolo em uma única plataforma
- Teste em navegador real — monitoramento que roda em navegadores reais como Chrome, Edge, Firefox e navegadores móveis, não apenas motores headless
- Ferramentas visuais de depuração — gráficos de cascata, gravações de vídeo sincronizadas com execuções de monitoramento e capturas de tela em formato filmstrip para diagnóstico rápido
- Gravação flexível de scripts — ferramentas como EveryStep Web Recorder que capturam interações reais de usuários sem exigir scripts de automação codificados manualmente
- Profundidade das métricas de desempenho — TTFB, FCP, LCP, CLS, INP e detalhamento completo do tempo de navegação
- Integrações de alerta — suporte a PagerDuty, Slack, Teams, email, SMS, WhatsApp e webhook para seu fluxo de trabalho de plantão
- Verificações acionadas sob demanda — capacidade de executar verificações via API para que você possa acionar o monitoramento como parte dos fluxos de trabalho de lançamento
- Dashboards SLA/SLO — relatórios integrados sobre compromissos de uptime e desempenho com dashboards compartilháveis
- Preços transparentes — custo previsível modelo que escala com suas necessidades
Comece o Monitoramento Sintético com Dotcom-Monitor
Dotcom-Monitor oferece monitoramento sintético de nível empresarial a partir de uma rede global com mais de 30 locais de monitoramento, suportando verificações de tempo de atividade, testes de página com navegador real, monitoramento de transações via EveryStep Web Recorder, monitoramento de API (REST, SOAP, Postman, Insomnia), monitoramento DNS com validação DNSSEC, monitoramento de certificado SSL e uma suíte completa de verificações de protocolo — tudo em uma única plataforma.
Quer você esteja protegendo um fluxo de checkout de ecommerce, monitorando uma API pública, validando conformidade com SLA para clientes empresariais ou mantendo aplicações internas funcionando para sua equipe, o Dotcom-Monitor oferece a visibilidade proativa para detectar e resolver problemas antes que impactem usuários reais.
