Synthetisches Monitoring ist eine proaktive Leistungstestmethode, die skriptgesteuerte, automatisierte Transaktionen verwendet, um reale Benutzerinteraktionen mit Ihren Anwendungen zu simulieren – dabei werden Verfügbarkeit, Reaktionszeit und Funktionalität gemessen, bevor Probleme tatsächlich bei den Nutzern auftreten.
Wenn Ihre Anwendung um 3 Uhr morgens ausfällt oder in einer Region, in der Sie noch keine echten Nutzer haben, stark verlangsamt, müssen Sie schnell davon erfahren – noch im nächsten Überprüfungsintervall – und nicht erst, wenn eine Kundenbeschwerde in Ihrem Posteingang landet. Genau dafür ist synthetisches Monitoring konzipiert.
In diesem Leitfaden behandeln wir alles, was Sie über synthetisches Monitoring wissen müssen: wie es funktioniert, die verschiedenen Testarten, welche Metriken wichtig sind, wie es sich im Vergleich zu Real User Monitoring (RUM) und APM verhält und wie Sie es effektiv im produktiven Einsatz verwenden. Wir zeigen auch die Grenzen auf, über die niemand spricht, und teilen bewährte Verfahren, die von SRE- und DevOps-Teams im großen Maßstab verwendet werden.
Was ist synthetisches Monitoring?
Synthetisches Monitoring – auch aktives Monitoring, gezieltes Monitoring oder synthetisches Testen genannt – funktioniert, indem automatisierte Monitoring-Agenten eingesetzt werden, die kontinuierlich skriptgesteuerte Anfragen an Ihre Anwendungen, APIs oder Webservices nach einem festgelegten Zeitplan senden. Diese Agenten arbeiten auf verschiedenen technischen Ebenen: leichte HTTP-Agenten, die Anfragen senden, um die grundlegende Verfügbarkeit und Antwortcodes zu prüfen, sowie anspruchsvolle browserbasierte Agenten, die vollständige Browser-Engines ausführen, um JavaScript auszuführen, Seiten zu rendern, Sitzungen zu verwalten und komplexe, mehrstufige Benutzerinteraktionen zu simulieren. Der EveryStep Web Recorder von Dotcom-Monitor verwendet echte Browser – nicht nur Headless-Engines – um jede Benutzeraktion über mehr als 40 Desktop- und Mobilbrowser-Konfigurationen aufzuzeichnen und wiederzugeben.
Da es sich um skriptgesteuerte Simulationen und nicht um passive Beobachtungen von echtem Traffic handelt, läuft synthetisches Monitoring rund um die Uhr, unabhängig davon, ob echte Nutzer aktiv sind oder nicht. Sie erhalten konsistente, reproduzierbare Leistungsdaten aus kontrollierten Bedingungen – bei Tag oder Nacht, während Spitzenzeiten oder stillen Wartungsfenstern.
Der Begriff „aktives Monitoring“ unterscheidet es von passiven Ansätzen wie Real User Monitoring (RUM), das nur Daten erfasst, wenn tatsächliche Nutzer mit dem System interagieren. Synthetisches Monitoring wartet nicht – es überprüft nach einem definierten Zeitplan, sodass Sie Ausfälle und Rückschritte schnell erkennen können, oft bereits im nächsten Überprüfungsintervall, anstatt auf Nutzerberichte zu warten.
Wie funktioniert synthetisches Monitoring?
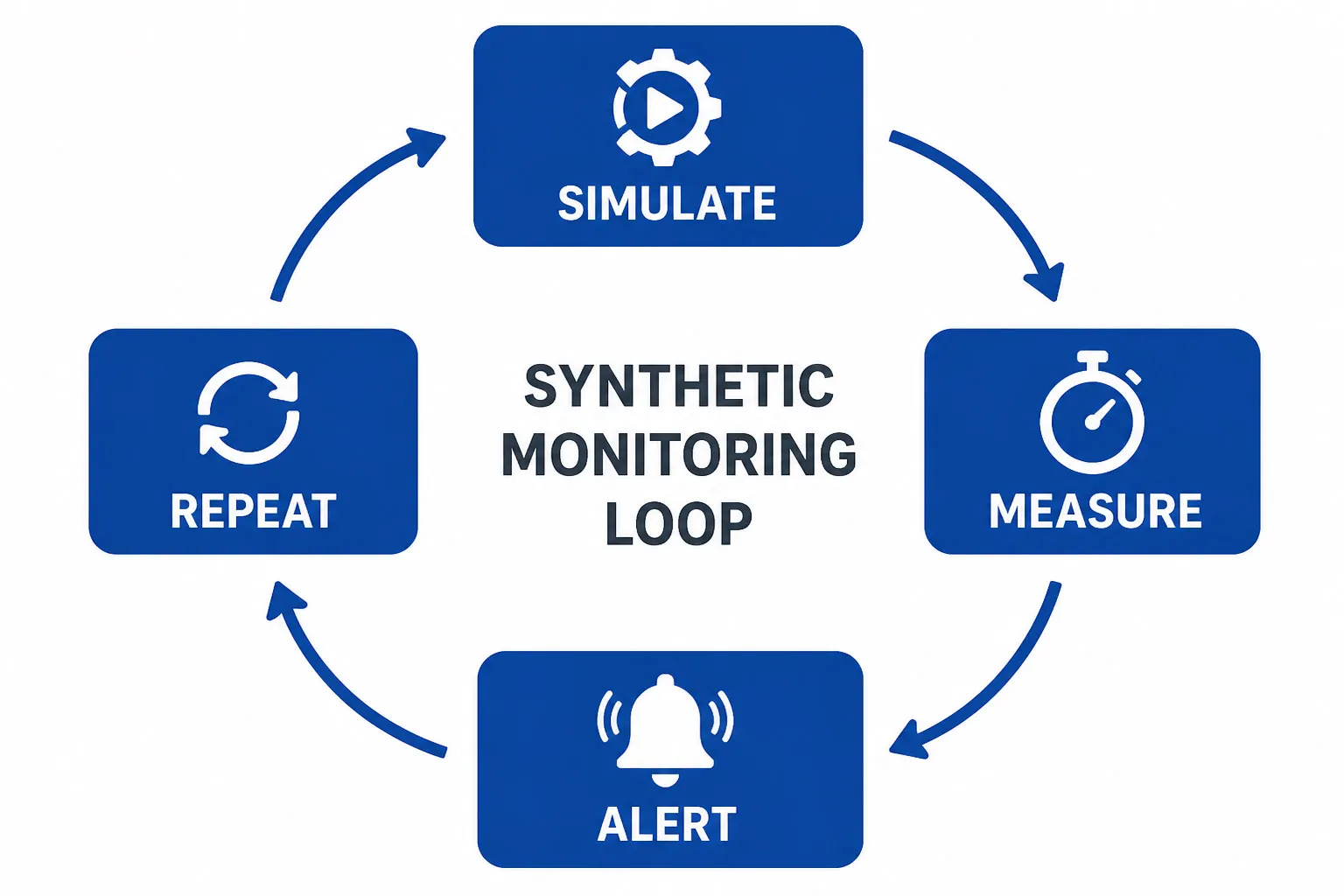 : simulieren, messen, alarmieren, wiederholen” width=”1536″ height=”1024″ /> Synthetisches Monitoring folgt einer kontinuierlichen Schleife – Simulieren, Messen, Alarmieren, Wiederholen.[/caption]
: simulieren, messen, alarmieren, wiederholen” width=”1536″ height=”1024″ /> Synthetisches Monitoring folgt einer kontinuierlichen Schleife – Simulieren, Messen, Alarmieren, Wiederholen.[/caption]
Im Kern folgt synthetisches Monitoring einem einfachen Ablauf: simulieren, messen, alarmieren, wiederholen. Hier ist der Schritt-für-Schritt-Workflow:
- Definieren Sie kritische Benutzerabläufe und Endpunkte. Identifizieren Sie, welche Transaktionen am wichtigsten sind: Login-Prozesse, Checkout-Prozesse, API-Gesundheitschecks, DNS-Auflösung und Gültigkeit von SSL-Zertifikaten.
- Nehmen Sie Ihre Tests auf oder erstellen Sie Skripte. Verwenden Sie ein Tool wie den EveryStep Web Recorder von Dotcom-Monitor, um echte Browserinteraktionen – Klicks, Formulareingaben, Navigationen – aufzuzeichnen, die als wiederholbare Skripte gespeichert werden. Für API- und Protokollprüfungen konfigurieren Sie HTTP-, DNS- oder Ping-Aufgaben direkt auf der Plattform.
- Setzen Sie Monitoring-Agenten global ein. Führen Sie Tests von mehreren geografischen Standorten aus mit öffentlichen Agenten (30+ globale Standorte) und/oder privaten Agenten, die in Ihren eigenen Rechenzentren oder im Netzwerkperimeter bereitgestellt werden.
- Führen Sie die Tests nach Zeitplan aus. Tests laufen in konfigurierten Intervallen – so häufig wie jede Minute bis alle drei Stunden. Ein Monitoring-Agent sendet die skriptgesteuerten Anfragen, wartet auf eine Antwort und zeichnet das Ergebnis auf.
- Messen Sie technische und funktionale Ergebnisse. Erfassen Sie Antwortzeiten, HTTP-Statuscodes, Seitenladezeit, Time to First Byte (TTFB), First Contentful Paint (FCP) und Core Web Vitals (LCP, CLS und INP). Beachten Sie, dass Interaktionsmetriken wie INP tatsächliche Benutzereingaben widerspiegeln und am besten zusammen mit Real-User-Daten validiert werden – synthetische Messungen liefern kontrollierte, Labor-artige Ergebnisse.
- Alarmieren Sie bei bestätigten Problemen. Dotcom-Monitor sendet standardmäßig sofort Alarme bei Erkennung. Konfigurierbare Filter – wie schwellenwertbasierte Trigger, Fehlerarten oder standortspezifische Regeln – helfen, die Störmeldungen bei weniger kritischen Checks zu reduzieren. Bei Multi-Step-Transaktionstests sollten Sie bedenken, ob das erneute Ausführen eines fehlgeschlagenen Skripts unbeabsichtigte Nebeneffekte haben könnte, bevor automatische Wiederholungen aktiviert werden.
- Nutzen Sie vantage points strategisch. Ein privater Agent, der einen Test besteht, bestätigt, dass der spezifische Service und der Ablauf von diesem internen vantage point aus funktionieren – was Ihnen hilft, zu isolieren, ob ein Problem internetseitig, edge-bezogen oder intern ist. Externe globale Agenten messen den gesamten benutzerorientierten Pfad: DNS-Auflösung, CDN-Edges, ISP-Routing und geografische Latenz.
Sehen Sie Dotcom-Monitors synthetisches Monitoring in Aktion → Erkunden Sie die Seite zur Lösung für synthetisches Monitoring
7 Arten von synthetischen Überwachungstests

Synthetische Überwachung ist nicht für alle gleich passend. Verschiedene Testtypen dienen unterschiedlichen Zwecken, und ausgereifte Überwachungsstrategien kombinieren mehrere davon.
Verfügbarkeits- / Uptime-Monitoring
Das Uptime-Monitoring verwendet Netzwerk- und Endpunktsonden, um zu bestätigen, dass ein Server oder Dienst erreichbar ist und reagiert. Diese Prüfungen arbeiten auf verschiedenen Netzwerkschichten, die jeweils etwas anderes validieren:
- Ping-Monitoring (ICMP) — testet die grundlegende Netzwerk-Erreichbarkeit eines Hosts, sofern dies durch Firewall-Regeln erlaubt ist. Ein erfolgreicher Ping bestätigt, dass der Host im Netzwerk ist, beweist jedoch nicht, dass die Anwendung gesund ist.
- Port-Monitoring (TCP) — testet, ob ein bestimmter Port geöffnet ist und Verbindungen akzeptiert. Bestätigt Transport-Schicht-Erreichbarkeit.
- HTTP/HTTPS Uptime-Checks — validieren einen Anwendungspunkt auf Anwendungsebene, prüfen Statuscodes, Antwortinhalte und SSL-Gültigkeit. Für die Verfügbarkeit der Anwendung sind HTTP-Checks mit Antwort- und Inhaltsüberprüfungen die aussagekräftigste zu überwachende Schicht.
Dotcom-Monitor bietet alle drei als eigenständige Produkte — Ping Monitoring, Port Monitoring und HTTP-basiertes Uptime Monitoring — weil ein erfolgreicher Ping keine gesunde Anwendung garantiert.
Browser- / Seitenleistungs-Überwachung
Ein echter Browser lädt eine vollständige Webseite — führt JavaScript aus, rendert CSS, lädt Ressourcen von Drittanbietern — und zeichnet detaillierte Ladezeiten auf. Dotcom-Monitors Webseitenüberwachung läuft in echten Chrome-, Edge-, Firefox- und mobilen Browsern (40+ Konfigurationen) und nicht nur in einer Headless-Engine, wodurch authentische Leistungsdaten entstehen, die die tatsächliche Benutzererfahrung widerspiegeln. Wichtige Metriken umfassen TTFB, FCP, LCP, DOM-Ladezeit und gesamte Seitenladezeit. Waterfall-Diagramme und Videoaufzeichnungen, synchronisiert mit diesen Diagrammen, ermöglichen es, genau zu identifizieren, welche Ressourcen am langsamsten sind. Dies ist für SEO wichtig: Googles Core Web Vitals (LCP, CLS, INP) sind ein Rankingfaktor, und konstant schlechte Werte wirken sich auf Ihre Such-Sichtbarkeit aus.
Transaktionsüberwachung
Die Transaktionsüberwachung simuliert eine vollständige Nutzerreise — eine mehrstufige Sequenz wie Produktsuche, Hinzufügen zum Warenkorb, Eingabe der Zahlungsdetails und Abschluss des Bezahlvorgangs. Dotcom-Monitors EveryStep Web Recorder zeichnet diese Reisen auf, indem er echte Browser-Interaktionen aufnimmt, die dann abgespielt werden continuierlich durch Überwachungsagenten. Jeder defekte Schritt – ein Formular, das nicht abgesendet wird, ein durch eine UI-Änderung verschobener Button, eine durch ein Deployment eingeführte Weiterleitungsschleife – wird sofort erkannt. Dies ist der leistungsfähigste Testtyp zum Schutz umsatzkritischer Geschäftsabläufe.
API-Überwachung
Testet die Gesundheit, Leistung und Korrektheit von REST- und SOAP-API-Endpunkten. Validiert HTTP-Methoden (GET, POST, PUT, PATCH), prüft Antwortstatuscodes, verifiziert Antwortdaten und misst Latenzzeiten. Dotcom-Monitor unterstützt REST-API-Überwachung, SOAP-API-Überwachung, Postman Collection-Überwachung und Insomnia Collection-Überwachung – und deckt somit die gesamte Bandbreite der API-Typen ab, die Teams in der Praxis verwenden. Mehrstufige API-Tests verketten Anfragen (Authentifizierung → Erstellen → Abrufen → Löschen), um ganze Workflows zu validieren. SSL/TLS-Zertifikatsprüfungen können parallel zu API-Tests durchgeführt werden, um zu bestätigen, dass Zertifikate gültig sind und kein nahendes Ablaufdatum haben.
DNS-Überwachung
Überprüft, ob Ihre DNS-Server Hostnamen korrekt und innerhalb akzeptabler Antwortzeiten auflösen. DNS-Probleme können weitreichende, schwer zu diagnostizierende Ausfälle verursachen – wenn DNS fehlschlägt, können Benutzer Ihre Anwendung nicht erreichen, selbst wenn Ihre Server einwandfrei laufen. Die DNS-Überwachung von Dotcom-Monitor validiert Auflösungskorrektheit, Antwortzeiten und die Gesundheit der gesamten DNS-Propagation-Kette an globalen Standorten. Zudem wird die DNSSEC-Vertrauenskette überprüft, um sicherzustellen, dass DNS-Antworten nicht manipuliert wurden, die Konsistenz von SOA-Records überwacht und anomale DNS-Änderungen – wie unerwartete IP-Adressen oder unautorisierte Record-Änderungen – erkannt, die auf Fehlrouten oder Cache-Poisoning hinweisen können. Die DNS-Überwachung unterstützt A-, AAAA-, MX-, NS-, CNAME-, PTR- und SOA-Recordtypen.
SSL-Zertifikatüberwachung
Überwacht die Gültigkeit, Ablaufdaten und den Widerrufsstatus von SSL/TLS-Zertifikaten. Ein abgelaufenes oder falsch konfiguriertes Zertifikat verursacht sofort Vertrauenswarnungen in jedem Browser, was das Vertrauen der Nutzer und die Konversionsraten direkt beeinträchtigt. Die automatische SSL-Überwachung benachrichtigt Sie Tage oder Wochen vor Ablauf eines Zertifikats, sodass Ihr Team Zeit zur Erneuerung hat, ohne eine Unterbrechung zu riskieren.
Protokoll- und Netzwerküberwachung
Über die Web- und API-Prüfungen hinaus überwacht Dotcom-Monitor den gesamten Stack von Netzwerkprotokollen: E-Mail (SMTP, POP3, IMAP), VoIP und SIP, FTP, UDP, WebSocket und Traceroute-Pfadanalyse. Ping-Überwachung (ICMP) und Port-Scans runden die Sichtbarkeit auf Netzwerkebene ab. Diese Tests sind besonders wertvoll für Organisationen mit komplexer Infrastruktur, bei denen die Anwendungs-Performance von mehreren zugrundeliegenden Diensten abhängt.
3 Wichtige Metriken für Synthetic Monitoring

Was Sie messen, bestimmt, was Sie verbessern können. Die wichtigsten operativen synthetischen Überwachungsmetriken fallen in drei Kategorien:
Verfügbarkeitsmetriken
- Verfügbarkeitsprozentsatz (Ziel: 99,9 % oder besser gemäß SLA)
- Fehlerrate nach Endpunkt und geografischer Region
- HTTP-Statuscodes (4xx Client-Fehler, 5xx Server-Fehler)
- Erfolgsrate und Antwortzeit der DNS-Auflösung
- SSL/TLS-Zertifikatsgültigkeit und Tage bis zum Ablauf
Leistungsmetriken
- Time to First Byte (TTFB) — Serverreaktionszeit
- First Contentful Paint (FCP) und Largest Contentful Paint (LCP) — Core Web Vitals
- Cumulative Layout Shift (CLS) — visuelle Stabilität
- Interaction to Next Paint (INP) — Reaktionsfähigkeit Core Web Vital (Labormessungen näherungsweise Feldwerte)
- Gesamte Seitenladezeit und DOM-Ladezeit
- API-Antwortzeit (p50, p95, p99 Latenz)
- Timing der Transaktionsschritte — welcher Schritt in der mehrstufigen Abfolge am langsamsten ist
Zuverlässigkeits- & SLA-Metriken
- Mean Time to Detection (MTTD) — wie schnell Probleme innerhalb des Prüfintervalls erkannt werden
- Mean Time to Resolution (MTTR) — wie schnell sie behoben werden
- SLA/SLO-Compliance-Prozentsatz über rollierende Zeitfenster
- Leistungs-Basislinien-Delta — Veränderung der Antwortzeit im Vergleich zum historischen Durchschnitt
Synthetische Überwachung vs. Real User Monitoring vs. APM

Diese drei Überwachungsansätze dienen unterschiedlichen Zwecken und werden oft verwechselt. So unterscheiden sie sich:
| Dimension | Synthetische Überwachung | Real User Monitoring (RUM) | APM |
|---|---|---|---|
| Datenquelle | Geleitete Simulationen von Agenten | Aktuelle Benutzersitzungen (JS-Snippet) | Backend-Instrumentierung (Traces, Logs) |
| Wann Daten gesammelt werden | 24/7, zu einem definierten Prüfplan | Nur wenn reale Nutzer aktiv sind | Während der realen Anwendungsausführung |
| Typ | Aktiv / proaktiv | Passiv / reaktiv | Intern / Codeebene |
| Am besten geeignet für | Verfügbarkeit, Regressions-Erkennung, SLA-Validierung | Reale UX, geografische Leistung, Sitzungsanalyse | Ursachenanalyse, Engpässe auf Codeebene |
| Funktioniert vor dem Start? | Ja | Nein | Ja (im Staging) |
| Funktioniert in verkehrsarmen Zeitfenstern? | Ja | Begrenzt | Ja, aber weniger Anfragen = weniger Proben |
| Deckt Drittanbieterdienste ab? | Ja (API- und DNS-Tests) | Teilweise | Hängt von der Instrumentierung ab |
| Erfasst unbekannte Benutzerpfade? | Nein (nur scripted) | Ja | Teilweise |
Die wichtigste Erkenntnis: Synthetic Monitoring und RUM ergänzen sich, sie konkurrieren nicht. Synthetic Monitoring liefert Ihnen konsistente, proaktive Basislinienmessungen. RUM zeigt Ihnen, was bei verschiedenen echten Nutzern auf jedem Gerät, Browser und unter jeder Netzwerkbedingung passiert. Die Kombination beider Methoden ergibt das vollständigste Bild der digitalen Nutzererfahrung.
APM arbeitet auf einer anderen Ebene und liefert Code-Ebene-Traces sowie serverseitige Leistungsdaten. Zusammen bilden alle drei eine umfassende Überwachungsabdeckung von der Nutzererfahrung bis zur Backend-Leistung. Für eine vollständige Observability-Praxis kombinieren Teams typischerweise APM mit Logs, Metriken und verteilten Traces, um die Ursachenanalyse zu unterstützen.
Warum Teams Synthetic Monitoring nutzen: 8 Hauptvorteile
- Probleme erkennen, bevor Nutzer sie bemerken. Synthetic-Tests laufen kontinuierlich, auch außerhalb der Geschäftszeiten. So wissen Sie um 2 Uhr morgens von einem defekten Checkout, bevor Ihre Kunden aufwachen und es bemerken.
- Performance-Baselines etablieren. Durch wiederholtes Durchführen derselben Tests über einen längeren Zeitraum bauen Sie eine verlässliche Basislinie der erwarteten Leistung auf. Abweichungen über definierte Schwellenwerte – bestätigt an verschiedenen Standorten oder aufeinanderfolgenden Intervallen – können Warnungen auslösen und flüchtiges Netzwerkrauschen herausfiltern.
- Neue Deployments schnell validieren. Führen Sie Synthetic-Tests in Ihrer Staging-Umgebung durch, bevor Sie live gehen, um sicherzustellen, dass nichts kaputt gegangen ist. Überwachen Sie anschließend direkt nach dem Deployment weiter, um das Produktionsverhalten zu validieren und Regressionen zu erkennen, bevor sie echte Nutzer beeinträchtigen.
- SLAs und SLOs schützen. Synthetic Monitoring liefert kontinuierliche, objektive Leistungsdaten, die Sie benötigen, um SLA-Compliance gegenüber Kunden nachzuweisen und schnell zu erkennen, wenn ein Drittanbieter die vereinbarten Standards nicht einhält.
- Drittanbieter zur Rechenschaft ziehen. Moderne Anwendungen sind auf CDNs, Zahlungsabwickler, Analyseplattformen und SaaS-APIs angewiesen. Synthetic-Tests können jeden davon unabhängig überwachen und liefern Beweise, wenn eine Verschlechterung bei einem Anbieter Ihre Nutzer beeinträchtigt.
- MTTR reduzieren. Da Synthetic-Checks konsistente Schritte, Zeitangaben und Artefakte erfassen – inklusive Videoaufnahmen, die mit Waterfall-Diagrammen in Dotcom-Monitor synchronisiert sind – erleichtern sie oft die Reproduktion und Analyse von Problemen. Intermittierende oder zustandsabhängige Fehler erfordern möglicherweise tiefere serverseitige Untersuchungen, doch die genaue Schrittfolge hilft dabei erheblich.
- Überwachen Sie Pre-Launch- und Bereiche mit geringem Traffic.Starten Sie in einer neuen Region? Entwickeln Sie eine neue Funktion, die noch nicht produktiv ist? Synthetic Monitoring kann diese Bereiche testen, bevor ein echter Nutzer sie besucht.
- Unterstützen Sie die Kapazitätsplanung.Historische Daten aus dem Synthetic Monitoring zeigen Trends: Wird Ihre API langsamer, wenn die Nutzerbasis wächst? Verursachen Spitzenverkehrszeiten eine Verschlechterung? Diese Daten fließen direkt in Entscheidungen zur Kapazitäts- und Infrastrukturplanung ein.
e und das Timing verengen die Suche erheblich.
Anwendungsfälle von Synthetic Monitoring nach Team und Branche
Nach Team
- SRE- und Plattform-Teams: Verantwortlich für Uptime-SLOs. Nutzen Synthetic Monitoring, um SLO-Verbrauchsraten zu verfolgen, Fehlerbudgets festzulegen und bei Verstößen alarmiert zu werden, bevor SLA-Grenzwerte überschritten werden.
- DevOps und Anwendungsentwicklung: Führen Sie synthetische Prüfungen in Staging-Umgebungen als Teil der Release-Validierung durch. Überwachen Sie nach der Bereitstellung, um Regressionen schnell zu erkennen und die Zeit für Rollback-Entscheidungen zu verkürzen.
- API- und Backend-Teams: Überwachen Sie die Verfügbarkeit, Latenz und Korrektheit von REST- und SOAP-API-Endpunkten. Führen Sie mehrstufige API-Tests durch, die Authentifizierung, CRUD-Operationen und Validierung in Folge verketten.
- E-Commerce- und Digital Experience-Teams: Schützen Sie Checkout-Prozesse, Produktsuche und Kontoanmeldungen. Überwachen Sie Core Web Vitals, um sowohl die Nutzererfahrung als auch die SEO-Rankings zu schützen. Studien im E-Commerce haben messbare Conversion-Einflüsse durch Ladezeitverzögerungen gezeigt – obwohl die spezifische Schwelle je nach Branche, Benutzererwartungen und Basisleistung variiert.
Nach Branche
- Finanzdienstleistungen: Überwachen Sie Online-Banking-Plattformen, Zahlungsgateways und Handelssysteme auf Verfügbarkeit und Reaktionszeiten unter einer Sekunde. Validieren Sie kontinuierlich SSL/TLS-Konfigurationen.
- Gesundheitstechnologie: Stellen Sie sicher, dass EHR-Systeme, Patientenportale und Telemedizin-Plattformen zugänglich und leistungsfähig sind – besonders wichtig in Zeiten hoher Nachfrage.
- E-Commerce und Einzelhandel: Überwachen Sie Inventar-APIs, Warenkorb-Funktionalität und Checkout-Prozesse auf kontinuierliche Verfügbarkeit.
- Medien und Streaming: Validieren Sie die CDN-Performance, API-Endpunkte für Empfehlungssysteme und die Verfügbarkeit von Streaming-Diensten.
- Öffentlicher Sektor: Überwachen Sie bürgerorientierte Portale und Dienste, die Verfügbarkeitsverpflichtungen aus öffentlichen SLAs einhalten müssen.
7 Herausforderungen und Begrenzungen des Synthetic Monitorings
Synthetic Monitoring ist ein mächtiges Werkzeug, hat aber reale Einschränkungen, die jedes Team verstehen sollte.
- Abdeckungslücken durch Skripterstellung: Synthetische Tests erfassen nur die Benutzerpfade, die Sie skriptiert haben. Die Kombination aus verschiedenen Nutzerpfaden, Gerätekonfigurationen, Netzwerkbedingungen, Anwendungszuständen und EdgeFälle schaffen einen kombinatorischen Raum, der unpraktisch ist, umfassend zu skripten. Real User Monitoring schließt diese Lücke, indem es erfasst, was tatsächliche Benutzer erleben.
- Testfragilität: Browserbasierte Transaktionsskripte sind empfindlich gegenüber UI-Änderungen. Wenn sich ein Button-Text ändert, ein Formularfeld umbenannt wird oder eine Seite umstrukturiert wird, können Tests fehlschlagen – selbst wenn die Anwendung selbst einwandfrei funktioniert. Dies erzeugt Alarmgeräusche und erfordert ständige Wartung.
- Wartungsaufwand: Mit der Weiterentwicklung Ihrer Anwendung müssen sich auch Ihre Testscripte weiterentwickeln. Für große Anwendungen mit häufigen Releases ist das Aktualisieren der Skripte ein realer Betriebskostenfaktor.
- Kein subjektives UX-Signal: Synthetisches Monitoring misst objektive Metriken: Antwortzeiten, Fehlerquoten, Verfügbarkeit. Es kann keine Nutzerzufriedenheit, visuelle Designprobleme, Barrierefreiheitsprobleme oder das subjektive Empfinden einer verwirrenden Oberfläche erfassen.
- Simulierte Bedingungen unterscheiden sich von der Realität: Synthetische Agenten laufen in kontrollierten Umgebungen. Sie können nicht die Vielfalt realer Nutzergeräte, mobile Netzwerke mit variabler Bandbreite, Unternehmensproxies oder regionale ISP-Routen nachbilden.
- Backend-Blindspot: Synthetisches Monitoring bietet einen Außenblick. Es sagt Ihnen, dass die Anwendung langsam ist, aber nicht warum auf Code-Ebene. APM und verteiltes Tracing sind für die Ursachenanalyse auf Code-Ebene erforderlich.
- Kosten im großen Maßstab: Häufige Tests von vielen globalen Standorten mit komplexen Transaktionsskripten können teuer werden, vor allem wenn die Agentenzahl, Testfrequenz und Anforderungen an die Datenspeicherung wachsen.
9 Best Practices für synthetisches Monitoring

- Beginnen Sie mit Ihren kritischen Pfaden. Versuchen Sie nicht, alles auf einmal zu testen. Starten Sie mit den 3–5 Nutzerreisen, die direkt Einnahmen generieren oder durch SLAs abgedeckt sind: Login, Checkout, Kern-API und Ihre meistbesuchten Landingpages.
- Überwachen Sie dort, wo Ihre Nutzer sind. Führen Sie Tests aus den geografischen Regionen durch, in denen sich echte Nutzer befinden. Ein Test, der von einem US-East-Knotenpunkt aus besteht, sagt nichts über die Performance in Südostasien oder Westeuropa aus. Die 30+ globalen Standorte von Dotcom-Monitor ermöglichen es Ihnen, die Agentenplatzierung an Ihre Nutzergeografie anzupassen.
- Verwenden Sie private Agenten für interne Umgebungen. Für Dienste hinter einer Firewall – interne APIs, Intran-et Apps, Staging-Umgebungen – setzen Sie innerhalb Ihres Netzwerks einen privaten Agenten ein. Denken Sie daran: Ein privater Agent, der einen Test besteht, bestätigt, dass dieser spezifische Dienst von diesem Standort aus funktioniert, nicht jedoch, dass Ihre gesamte interne Umgebung gesund ist.
- Setzen Sie sinnvolle Alarmgrenzen. Konfigurieren Sie Alarmbedingungen basierend auf Ihrer etablierten Leistungsgrundlage – zum Beispiel Alarm, wenn die Antwortzeit das 1,5- bis 2-fache des Durchschnitts übersteigt oder wenn die Verfügbarkeit unter Ihre SLO-Grenze fällt. Dotcom-Monitor unterstützt konfigurierbare Filter, sodass Sie die Empfindlichkeit pro Check anpassen können, anstatt bei jeder Schwankung Alarm zu schlagen.
- Validieren Sie die Staging-Umgebung vor dem Live-Gang. Führen Sie Dotcom-Monitor-Checks gegen Ihre Staging-Umgebung vor jedem Release aus, um Regressionen frühzeitig zu erkennen. Überwachen Sie nach der Bereitstellung die Produktion sofort für die ersten 30–60 Minuten – die Zeitspanne, in der die meisten Deploy-bezogenen Probleme auftreten. Verwenden Sie die Alarmintegrationen von Dotcom-Monitor (Slack, PagerDuty), um Post-Deploy-Alarme direkt an Ihr Bereitschaftsteam zu senden.
- Bewahren Sie Testskripte in der Versionskontrolle auf. Behandeln Sie Monitoring-Skripte wie Code. Speichern Sie sie in Git, überprüfen Sie Änderungen in Pull Requests und rollen Sie zurück, wenn ein Skript-Update Fehlalarme verursacht.
- Kombinieren Sie mit RUM für vollständige Abdeckung. Verwenden Sie synthetisches Monitoring für proaktive Erkennung und Basislinienmessung. Ergänzen Sie RUM, um die reale Nutzererfahrung unter verschiedenen Bedingungen zu erfassen. Zusammen bieten beide eine umfassende Überwachung Ihrer digitalen Erfahrung.
- Analysieren Sie regelmäßig Waterfall-Diagramme. Betrachten Sie nicht nur die gesamte Ladezeit. Prüfen Sie die Waterfall-Diagramme, um zu sehen, welche einzelnen Ressourcen – Drittskripte, große Bilder, langsame API-Aufrufe – am meisten zur Ladezeit beitragen. Die von Dotcom-Monitor synchronisierte Videoaufzeichnung mit Waterfall-Diagrammen beschleunigt diese Analyse deutlich.
- Überprüfen und aktualisieren Sie Skripte nach größeren Releases. Nach jeder bedeutenden UI-Änderung oder API-Überarbeitung auditieren Sie Ihre synthetischen Testscripte, um sicherzustellen, dass sie noch korrekte Nutzerpfade abbilden und nicht durch das Release ungültig geworden sind.
Wie analysiert man synthetische Monitoring-Daten?
Das Sammeln von synthetischen Monitoring-Daten ist nur dann wertvoll, wenn Sie darauf reagieren. Hier ist ein praktischer Workflow, um rohe Testergebnisse in Leistungsverbesserungen umzuwandeln:
- Überprüfen Sie täglich Verfügbarkeits- und Fehlerquoten-Dashboards. Suchen Sie nach Mustern: Konzentrieren sich Fehler in einer bestimmten Region, an einem bestimmten Endpunkt oder zu einer bestimmten Tageszeit?
- Verfolgen Sie Leistungstrends über die Zeit, nicht nur Momentaufnahmen. Eine Seite, die heute 2,1 Sekunden braucht, aber zuvor 1.6 Sekunden vor drei Wochen hat eine Regression — auch wenn Ihre Alarmgrenze noch nicht überschritten wurde.
- Verwenden Sie Wasserfalldiagramme und Videos, um Engpässe zu identifizieren. Finden Sie die langsamsten Ressourcen auf jeder Seite. Die Videoaufzeichnungen von Dotcom-Monitor, synchronisiert mit Wasserfalldiagrammen, zeigen genau, was der Browser während eines Ausfalls erlebt hat — kein Raten.
- Korrelation von synthetischen Fehlern mit Deployment-Ereignissen. Wenn ein Test ausfällt, überprüfen Sie Ihr Deployment-Log. Ein Release kurz vor dem Fehler ist ein starkes Signal, das zuerst untersucht werden sollte.
- Führen Sie eine Ursachenanalyse (RCA) bei wiederkehrenden Fehlern durch. Beheben Sie nicht nur Alarme — dokumentieren Sie diese. Wiederkehrende Fehler in bestimmten Regionen oder zu bestimmten Zeiten deuten oft auf systemische Infrastrukturprobleme hin, die proaktiv angegangen werden sollten.
- Berichten Sie regelmäßig über SLA/SLO-Einhaltung. Verwenden Sie historische synthetische Überwachungsdaten, um Uptime-Berichte für Stakeholder und Kunden zu erstellen. Objektive, mit Zeitstempel versehene Daten schaffen Vertrauen und sind bei Streitigkeiten mit Drittanbietern unerlässlich.
Worauf sollte man bei einem Tool zur synthetischen Überwachung achten?
Nicht alle Plattformen zur synthetischen Überwachung sind gleich. Beim Bewerten einer Lösung achten Sie auf folgende Fähigkeiten:
- Globales Überwachungsnetzwerk — über 30 Standorte, damit Sie von dort aus testen können, wo Ihre Nutzer tatsächlich sind
- Unterstützung privater Agenten — setzen Sie Agenten in Ihrem eigenen Netzwerk für Intranet- und Staging-Überwachung ein
- Breite Testabdeckung — Uptime, Browser, Transaktions-, API- (REST, SOAP, Postman, Insomnia), DNS-, SSL- und Protokollprüfungen in einer einzigen Plattform
- Echter Browser-Test — Überwachung, die in tatsächlichen Chrome-, Edge-, Firefox- und mobilen Browsern läuft, nicht nur in Headless-Engines
- Visuelle Debugging-Tools — Wasserfalldiagramme, synchronisierte Videoaufnahmen von Überwachungsläufen sowie Filmstreifen-Screenshots für schnelle Diagnosen
- Flexible Skriptaufzeichnung — Tools wie EveryStep Web Recorder, die echte Benutzerinteraktionen ohne handkodierte Automatisierungsskripte erfassen
- Umfangreiche Leistungsmetriken — TTFB, FCP, LCP, CLS, INP und vollständige Aufschlüsselung der Navigationstiming-Daten
- Integrationen für Benachrichtigungen — PagerDuty, Slack, Teams, E-Mail, SMS, WhatsApp und Webhook-Unterstützung für Ihren Bereitschaftsdienstprozess
- Bedarfsorientierte ausgelöste Prüfungen — Möglichkeit, Prüfungen über API auszuführen, um Monitoring als Teil von Release-Workflows zu aktivieren
- SLA/SLO-Dashboards — integrierte Berichte über Verfügbarkeits- und Leistungszusagen mit teilbaren Dashboards
- Transparente Preisgestaltung — vorhersehbare KostenModell, das mit Ihren Anforderungen skaliert
Starten Sie Synthetic Monitoring mit Dotcom-Monitor
Dotcom-Monitor bietet synthetisches Monitoring auf Unternehmensniveau aus einem globalen Netzwerk von über 30 Überwachungsstandorten, unterstützt Uptime-Checks, Real-Browser-Seitentests, Transaktionsüberwachung via EveryStep Web Recorder, API-Überwachung (REST, SOAP, Postman, Insomnia), DNS-Überwachung mit DNSSEC-Validierung, SSL-Zertifikatsüberwachung und eine vollständige Suite von Protokollprüfungen – alles in einer einzigen Plattform.
Egal, ob Sie einen E-Commerce-Checkout-Prozess schützen, eine öffentlich zugängliche API überwachen, SLA-Konformität für Unternehmenskunden validieren oder interne Anwendungen für Ihr Team am Laufen halten – Dotcom-Monitor bietet Ihnen die proaktive Sichtbarkeit, um Probleme zu erkennen und zu beheben, bevor sie echte Nutzer beeinträchtigen.
