 Para muchos equipos, el monitoreo de uptime de API todavía significa una sola cosa simple: comprobar si un endpoint responde con un 200 OK. Si la comprobación pasa, la API se marca como “activa”. Si falla, se activa una alerta. Sobre el papel, eso suena razonable. En la práctica, es una de las razones más comunes por las que los fallos de API pasan desapercibidos hasta que los usuarios se quejan.
Para muchos equipos, el monitoreo de uptime de API todavía significa una sola cosa simple: comprobar si un endpoint responde con un 200 OK. Si la comprobación pasa, la API se marca como “activa”. Si falla, se activa una alerta. Sobre el papel, eso suena razonable. En la práctica, es una de las razones más comunes por las que los fallos de API pasan desapercibidos hasta que los usuarios se quejan.
El problema es que las APIs modernas ya no son endpoints simples y sin estado. Dependen de múltiples componentes, incluidos:
- Flujos de autenticación y autorización
- Bases de datos y trabajos en segundo plano
- Servicios de terceros y APIs externas
- Infraestructura y enrutamiento específicos por región
Debido a esta complejidad, una API puede devolver un código de estado exitoso y aun así fallar de manera significativa. La respuesta puede contener datos incompletos, valores desactualizados o resultados lógicamente incorrectos. Desde un panel de monitoreo, todo parece saludable. Desde la perspectiva del usuario, la API está efectivamente caída.
Esta desconexión genera lo que muchos equipos experimentan como uptime falso. Las comprobaciones básicas de uptime son buenas para responder una pregunta técnica muy limitada:
- El monitoreo de uptime de API confirma que una API es accesible, rápida y devuelve resultados correctos.
- Un simple “200 OK” puede ocultar fallos silenciosos (payloads incorrectos, fallos de autenticación, datos parciales).
- El uptime en producción debe incluir transacciones de varios pasos y comprobaciones en múltiples regiones.
Por eso, el monitoreo de uptime de API necesita una definición más amplia. Debe tener en cuenta la disponibilidad, la corrección y el rendimiento desde el punto de vista del usuario, no solo la capacidad del servidor para responder.
El tiempo de inactividad real no es teórico; tiene un impacto financiero medible. Según Gartner, una interrupción promedio de TI cuesta alrededor de 5.600 dólares por minuto, o aproximadamente 300.000 dólares por hora para muchas organizaciones. Y según investigaciones independientes, más del 90 % de las empresas medianas y grandes reportan costos horarios por encima de los 300.000 dólares, y el 41 % afirma que las interrupciones pueden superar el millón de dólares por hora. Estas pérdidas provienen de transacciones perdidas, pérdida de productividad, penalizaciones por SLA y daño a la confianza del cliente, todo lo cual las comprobaciones básicas suelen no detectar.
En esta guía, exploraremos qué significa realmente hoy el monitoreo de uptime de API, por qué los enfoques comunes se quedan cortos y cómo los equipos pueden diseñar estrategias de monitoreo que reflejen el uso en el mundo real. Así, “API activa” realmente significa “API funcionando”.
Qué Significa Realmente Hoy el Monitoreo de Uptime de API
En esencia, el monitoreo de uptime de API pretende responder una pregunta simple: ¿Pueden los consumidores confiar en esta API ahora mismo? El problema es que muchos equipos todavía definen el “uptime” de forma demasiado estrecha, centrándose solo en si un endpoint responde a una solicitud. En los sistemas modernos, esa definición ya no se sostiene.
Las APIs se sitúan en el centro de arquitecturas distribuidas. Autentican usuarios, orquestan flujos de trabajo y dependen de múltiples servicios internos y externos. Por ello, el uptime ya no es un concepto binario. Una API puede ser accesible y aun así resultar inutilizable.
La diferencia entre las comprobaciones básicas de uptime y el monitoreo moderno de uptime de API se vuelve clara cuando se observa cómo se realiza realmente el monitoreo. En lugar de un solo ping desde una ubicación, un monitoreo eficaz valida flujos de trabajo reales desde múltiples regiones y rutas de dependencias.
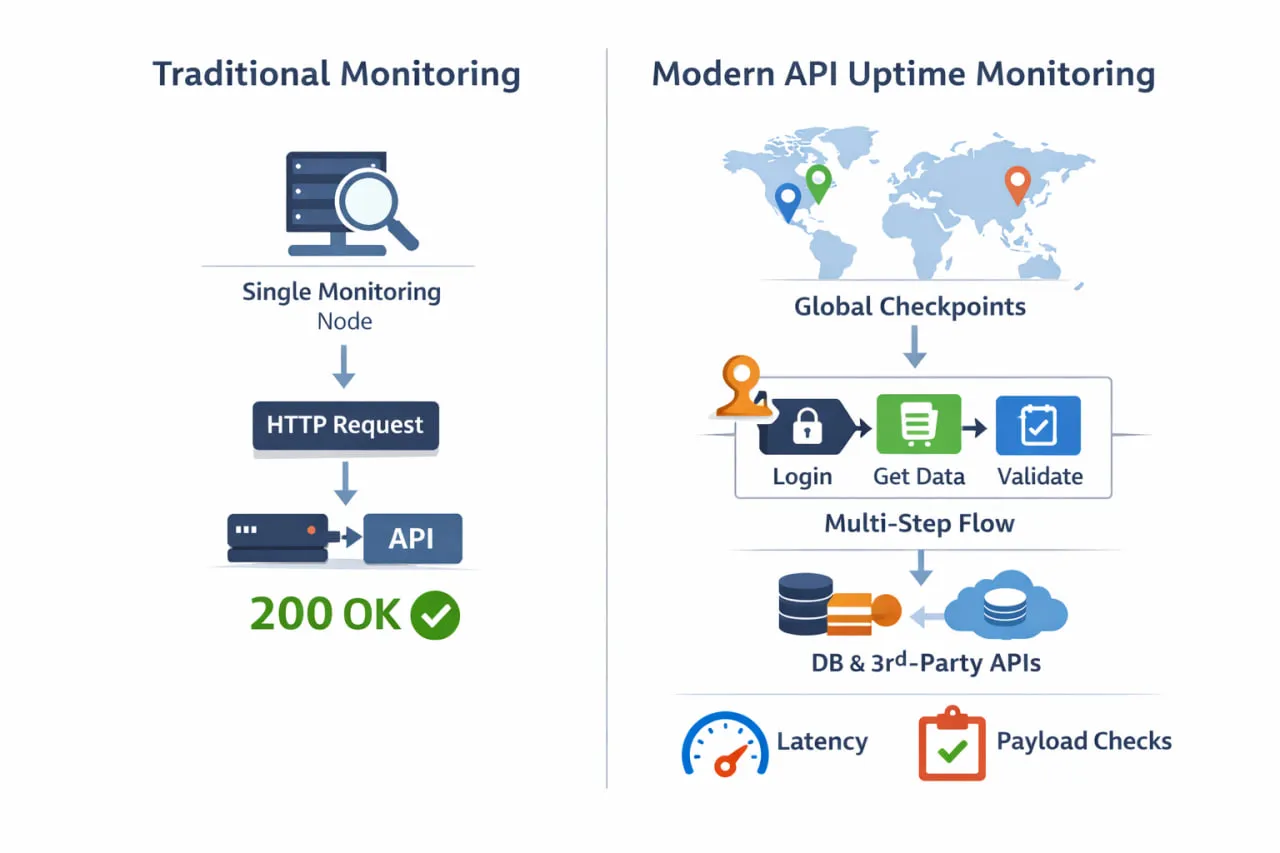
Una definición más precisa del uptime de API incluye tres dimensiones igualmente importantes:
- Disponibilidad – ¿Se puede acceder a la API desde donde se encuentran los usuarios?
- Corrección – ¿La API devuelve los datos, la estructura y los valores esperados?
- Capacidad de respuesta – ¿La API responde dentro de los umbrales de latencia aceptables?
Si cualquiera de estas falla, los usuarios experimentan una caída, incluso si la herramienta de monitoreo informa un 100 % de uptime.
Aquí es donde muchas comprobaciones tradicionales de uptime fallan. Una comprobación HTTP desde una sola región puede confirmar que un endpoint devuelve un 200 OK, pero no dirá si la autenticación está fallando, si una dependencia descendente está en timeout o si los usuarios en otra región experimentan un rendimiento degradado. Desde la perspectiva de ingeniería, todo se ve verde. Desde fuera, la API está rota.
Para entender correctamente el uptime, el monitoreo de API debe alinearse con la forma en que las APIs se consumen realmente. Eso significa observar las APIs como sistemas, no solo como endpoints. También significa conectar el monitoreo de uptime con prácticas más amplias de confiabilidad como logs, trazas y métricas, áreas comúnmente abordadas bajo observabilidad de API. Mientras que la observabilidad proporciona información interna profunda, el monitoreo de uptime cumple un papel complementario: validar lo que los usuarios reales experimentan desde el exterior.
Cuando se realiza correctamente, el monitoreo de uptime de API actúa como un sistema de alerta temprana. Detecta fallos antes de que los usuarios los reporten, resalta problemas regionales o condicionales y revela incidencias que las métricas internas por sí solas pueden pasar por alto. En lugar de responder “¿Respondió el servidor?”, responde una pregunta mucho más útil: ¿La API está entregando valor de forma confiable en este momento?
Este cambio de definición es la base de todo lo que sigue. Una vez que el uptime se enmarca en la usabilidad real, las limitaciones de las comprobaciones básicas se vuelven evidentes, al igual que la necesidad de estrategias de monitoreo más robustas.
Por Qué las Comprobaciones Básicas de Uptime Fallan en las APIs Modernas
Las comprobaciones básicas de uptime fueron diseñadas para una era más simple, cuando una aplicación exponía un pequeño número de endpoints predecibles y el éxito se medía con un solo código de respuesta. Las APIs modernas ya no funcionan así. Sin embargo, muchas configuraciones de monitoreo siguen basándose en esas mismas suposiciones obsoletas.
Las limitaciones de las comprobaciones básicas de uptime se hacen evidentes cuando se comparan lado a lado con el monitoreo moderno de uptime de API en producción.
| Capacidad | Comprobaciones Tradicionales de Uptime | Monitoreo Moderno de Uptime de API |
| Ubicación de monitoreo | Una sola región | Múltiples regiones globales |
| Qué se comprueba | Accesibilidad del endpoint | Usabilidad de la API de extremo a extremo |
| Soporte de autenticación | Raro o inexistente | Soporte completo (tokens, headers, OAuth) |
| Validación de respuestas | Solo código de estado | Payload, esquema, valores, lógica |
| Monitoreo de flujos | No soportado | Flujos transaccionales de varios pasos |
| Conciencia de dependencias | Ninguna | Detecta fallos descendentes |
| Visibilidad de rendimiento | Latencia básica o promedio | Tendencias, umbrales, degradación |
| Detección de fallos silenciosos | ❌ No detectados | ✅ Detectados tempranamente |
| Alineación con la experiencia del usuario | Baja | Alta |
Los pings tradicionales de uptime pueden indicar que un servidor es técnicamente accesible, pero no lo protegen de fallos silenciosos costosos. Algunos análisis de la industria estiman costos promedio de inactividad cercanos a 14.000 dólares por minuto, es decir, cientos de miles de dólares por hora en que una API está afectada, incluso si superficialmente parece “activa”.
Uno de los modos de fallo más comunes es la “ilusión del 200 OK”. Una API puede responder con éxito a nivel HTTP mientras falla a nivel de lógica de negocio. Por ejemplo, la respuesta puede:
- Devolver un payload vacío o parcial
- Contener datos obsoletos o incorrectos
- Omitir campos obligatorios o romper expectativas de esquema
Desde una comprobación tradicional de uptime, esto parece un éxito. Para los usuarios y los sistemas dependientes, es un fallo silencioso.
La autenticación introduce otro gran punto ciego. Las APIs suelen depender de tokens que expiran, claves rotativas o acceso basado en roles. Una comprobación básica que no simula completamente los flujos de autenticación no detectará problemas como credenciales expiradas o permisos mal configurados. El endpoint es accesible, pero ningún consumidor real puede usarlo.
Las dependencias empeoran el problema. La mayoría de las APIs dependen de bases de datos, colas de mensajes y servicios de terceros. Si una dependencia descendente se degrada o falla de forma intermitente, la API puede seguir respondiendo, pero con mayor latencia, resultados parciales o comportamiento inconsistente. Estos son precisamente los tipos de problemas que las comprobaciones básicas tienen más dificultad para detectar.
La geografía añade otra capa de complejidad. Muchas comprobaciones de uptime se ejecutan desde una sola ubicación, a menudo cerca de donde se aloja la infraestructura. Esto oculta problemas regionales causados por fallos de enrutamiento, caídas de ISP o configuraciones incorrectas de CDN. Los usuarios en una parte del mundo pueden experimentar timeouts mientras los paneles de monitoreo muestran que todo está bien.
Estas limitaciones explican por qué los equipos suelen creer que tienen un monitoreo sólido de uptime de API, hasta que los clientes reportan problemas primero. Lo que falta es visibilidad sobre cómo se comportan las APIs en condiciones reales.
Por eso, las estrategias modernas de uptime combinan comprobaciones de accesibilidad con la capacidad de validar la corrección de las respuestas de la API y monitorear tendencias de latencia de la API en múltiples regiones, de modo que los problemas se detecten según el impacto real en el usuario, no solo según la disponibilidad del servidor.
Hasta que el monitoreo vaya más allá de las comprobaciones básicas de accesibilidad, los equipos seguirán pasando por alto los problemas que más importan.
Las Métricas Clave que Definen el Verdadero Uptime de una API
Una vez que se supera la idea de que el uptime simplemente significa “endpoint accesible”, surge la siguiente pregunta: ¿qué debería medir realmente el monitoreo de uptime de API? Un monitoreo eficaz se centra en un pequeño conjunto de métricas que reflejan cómo se comportan las APIs en el mundo real, no solo en teoría.
1. Disponibilidad (Accesibilidad)
La disponibilidad responde a la pregunta más básica: ¿Se puede acceder a la API desde una ubicación determinada?
Esta métrica sigue siendo importante, pero es solo el punto de partida. Una API que responde a las solicitudes pero falla de otras maneras es técnicamente disponible, pero prácticamente inutilizable.
2. Latencia (Capacidad de respuesta)
La latencia mide cuánto tiempo tarda la API en responder. Incluso cuando las solicitudes tienen éxito, las respuestas lentas se sienten como caídas para los usuarios. El monitoreo debe seguir:
- Tiempos de respuesta frente a umbrales definidos
- Tendencias de latencia a lo largo del tiempo, no solo promedios
Esto ayuda a los equipos a detectar una degradación gradual del rendimiento antes de que se convierta en una interrupción.
3. Corrección de la respuesta
Aquí es donde muchas estrategias de uptime fallan. La corrección se centra en qué devuelve la API, no solo en que devuelve algo. En la práctica, la corrección de la respuesta se valida mediante aserciones.
Por ejemplo, los equipos pueden comprobar que los campos obligatorios existen mediante JSONPath, confirmar que los valores numéricos están dentro de rangos esperados o verificar que el esquema de la respuesta coincide con una estructura prevista. Estas comprobaciones aseguran que un 200 OK represente realmente un resultado exitoso.
Sin validación de la respuesta, los paneles de monitoreo pueden mostrar un 100 % de uptime mientras los usuarios experimentan fallos.
4. Consistencia regional
Las APIs se consumen globalmente, pero los fallos suelen ser regionales. Problemas de enrutamiento de red, caídas de ISP o problemas de infraestructura local pueden afectar a una geografía mientras dejan a otras intactas. El monitoreo desde múltiples ubicaciones garantiza que el uptime refleje la realidad del usuario, no solo la proximidad a la infraestructura.
5. Comportamiento de errores
No todos los fallos son iguales. El seguimiento de tipos de error añade un contexto crucial a los datos de uptime:
- Los errores 401/403 suelen indicar problemas de autenticación
- Los errores de nivel 500 apuntan a fallos del lado del servidor
- Los timeouts generalmente indican problemas de rendimiento o dependencias
Cuando estas métricas se monitorean juntas, el uptime se convierte en una señal de confiabilidad significativa en lugar de un número de vanidad.
Por eso, el verdadero monitoreo de uptime de API se solapa de forma natural con el monitoreo de rendimiento de API. Las tendencias de rendimiento, las comprobaciones de corrección y la visibilidad regional contribuyen a comprender si una API es realmente utilizable.
Al centrarse en estas métricas clave, los equipos pasan de un monitoreo reactivo a una confiabilidad proactiva, detectando problemas temprano, reduciendo la falsa confianza y alineando el uptime con la experiencia real del usuario.
Vincular el Uptime de la API con SLOs y SLIs
A medida que las APIs maduran, el uptime deja de ser un porcentaje vago y se convierte en un compromiso de confiabilidad. Aquí es donde entran los objetivos de nivel de servicio (SLOs) y los indicadores de nivel de servicio (SLIs).
En lugar de preguntar “¿La API está activa?”, los equipos definen el uptime en términos de experiencia del usuario medible:
- SLI de disponibilidad – ¿Las solicitudes tienen éxito?
- SLI de latencia – ¿Las respuestas son lo suficientemente rápidas?
- SLI de corrección – ¿Las respuestas son precisas y completas?
El monitoreo de uptime de API alimenta directamente estos indicadores. Las comprobaciones de disponibilidad confirman la accesibilidad, el seguimiento de latencia revela ralentizaciones y la validación de respuestas asegura que la API se comporte correctamente, no solo a nivel técnico, sino también funcional.
Un SLO define entonces el umbral aceptable para cada indicador. Por ejemplo, una API podría establecer como objetivos:
- 99,9 % de respuestas exitosas
- 95 % de las solicitudes por debajo de 300 ms
- Cero fallos de esquema o validación en endpoints críticos
Cuando el monitoreo de uptime está alineado con los SLOs, las alertas dejan de ser arbitrarias. Señalan cuándo la confiabilidad orientada al usuario está en riesgo, no solo cuándo un servidor deja de responder. Esto transforma el uptime de una métrica de vanidad en una herramienta de toma de decisiones para prioridades de ingeniería y respuesta a incidentes.
Cómo Calcular el Verdadero Uptime de una API
El verdadero uptime de una API no se basa únicamente en si un endpoint responde. Se calcula según cuántas solicitudes realmente tienen éxito desde el punto de vista del usuario.
La disponibilidad se mide como:
SLI de disponibilidad = solicitudes_buenas / solicitudes_totales
Una solicitud buena es aquella que:
- Devuelve un estado 2xx
- Pasa las aserciones de esquema y respuesta
- Cumple los umbrales de latencia
El uptime debe medirse en una ventana definida (por ejemplo, 28 días móviles) y evaluarse frente a un SLO objetivo. El margen restante (1 − SLO) se convierte en su presupuesto de errores.
Este enfoque garantiza que el uptime refleje la usabilidad real, no solo la accesibilidad.
Cómo Diseñar una Estrategia Eficaz de Monitoreo de Uptime de API
Diseñar una estrategia eficaz de monitoreo de uptime de API no consiste en añadir más comprobaciones, sino en elegir las correctas y validar los resultados adecuados. El objetivo es reflejar el uso real lo más fielmente posible, sin generar ruido ni puntos ciegos.
Comenzar con las APIs que más importan
No todos los endpoints merecen el mismo nivel de escrutinio. Empiece por identificar las APIs más críticas para los usuarios y el negocio. Estas suelen incluir:
- Endpoints de autenticación y autorización
- APIs transaccionales clave o generadoras de ingresos
- APIs públicas o orientadas a socios con dependencias externas
Centrarse en estas APIs garantiza que las métricas de uptime reflejen el impacto real, no solo la cobertura de monitoreo.
Elegir la frecuencia con intención
Es tentador comprobar cada endpoint cada pocos segundos, pero una mayor frecuencia no siempre produce mejores insights. Los intervalos de monitoreo deben basarse en:
- La rapidez con la que deben detectarse los fallos
- La tolerancia de los usuarios a interrupciones breves
- El riesgo de fatiga de alertas
Para APIs de alto impacto, las comprobaciones frecuentes están justificadas. Para servicios de menor riesgo, intervalos más largos suelen proporcionar señal suficiente sin ruido innecesario.
Monitorear flujos transaccionales y de varios pasos
La mayoría de las APIs modernas no operan de forma aislada. Una sola acción del usuario suele desencadenar varias llamadas a la API en secuencia. Monitorear solo endpoints individuales puede pasar por alto fallos que ocurren entre pasos.
Aquí es donde el monitoreo de APIs de varios pasos se vuelve esencial. En lugar de comprobar endpoints de forma independiente, los equipos monitorean flujos completos, como autenticación, creación de datos, recuperación y validación, como una sola transacción. Este enfoque revela problemas que las comprobaciones simples de uptime no pueden detectar.
Validar más que solo códigos de estado
El verdadero monitoreo de uptime requiere validar las respuestas, no solo recibirlas. Las comprobaciones eficaces afirman:
- Estructura de la respuesta y campos obligatorios
- Valores específicos que indican éxito
- Reglas de negocio que confirman que la API se comporta correctamente
Sin este nivel de validación, los paneles de uptime pueden mostrar un 100 % de disponibilidad mientras los usuarios experimentan funcionalidades rotas.
Incluir APIs autenticadas y privadas
Muchas APIs críticas están protegidas por autenticación o firewalls. Una estrategia realista de uptime debe admitir tokens, headers y rotación de credenciales. De lo contrario, los equipos terminan monitoreando solo las partes menos importantes de su sistema.
Las capacidades de Web API Monitoring y monitoreo de API REST de Dotcom-Monitor admiten endpoints autenticados y privados, lo que permite a los equipos monitorear las mismas APIs de las que dependen sus aplicaciones en producción.
Monitorear desde donde están los usuarios
El monitoreo desde una sola ubicación crea una falsa sensación de confiabilidad. Las APIs deben monitorearse desde múltiples ubicaciones geográficas que reflejen la distribución real de los usuarios. Esto ayuda a descubrir picos de latencia regionales, problemas de enrutamiento y caídas relacionadas con ISPs antes de que escalen.
Alinear el uptime con los objetivos de confiabilidad
Finalmente, el monitoreo de uptime debe alinearse con los objetivos de nivel de servicio (SLOs). En lugar de preguntar “¿La API está activa?”, los equipos deberían preguntarse:
- ¿Cumple los objetivos de disponibilidad?
- ¿El rendimiento está dentro de límites aceptables?
- ¿Las tasas de error superan los umbrales?
Cuando las métricas de uptime se alinean con los objetivos de confiabilidad, el monitoreo se vuelve accionable en lugar de meramente informativo.
Para los equipos que implementan estas estrategias, la documentación de Dotcom-Monitor, como la configuración del monitoreo de Web API y Añadir/Editar tareas de Web API REST (con opciones avanzadas cubiertas en Configuración de tareas de Web API REST), facilita el paso de comprobaciones básicas a un monitoreo de uptime de API de nivel producción.
El Uptime de la API Depende del Consumidor
El uptime de la API no es igual para todos. Las APIs internas pueden tolerar interrupciones breves, pero requieren una corrección estricta para mantener los flujos de trabajo. Las APIs públicas exigen una disponibilidad global constante y baja latencia para proteger la experiencia del usuario y la confianza en la marca.
Las APIs críticas para socios o ingresos tienen las expectativas más altas, donde incluso una degradación menor puede afectar contratos o ingresos. Un monitoreo eficaz del uptime de API se adapta a estas diferencias priorizando los endpoints, la profundidad de validación y los umbrales de alerta según cómo se consume realmente la API.
Errores Comunes en el Monitoreo de Uptime de API (y Cómo Evitarlos)
Incluso los equipos con stacks de monitoreo maduros suelen caer en las mismas trampas del monitoreo de uptime de API. Estos errores no suelen deberse a negligencia, sino a suposiciones simplificadas en exceso sobre cómo fallan las APIs en producción.
1. Tratar el uptime como una comprobación de código de estado
Uno de los errores más comunes es equiparar el uptime con una respuesta HTTP exitosa. Un 200 OK solo confirma que el servidor respondió, no que la API funcionó correctamente. Sin validar payloads, esquemas o lógica de negocio, los equipos terminan midiendo accesibilidad, no usabilidad.
Cómo evitarlo:
Vaya más allá de los códigos de estado validando el contenido de la respuesta y los valores esperados como parte de sus comprobaciones de uptime.
2. Monitorear solo desde una ubicación
Ejecutar comprobaciones de uptime desde una sola ubicación geográfica, a menudo cerca de su infraestructura, crea una falsa sensación de confiabilidad. Problemas de enrutamiento regional, caídas de ISP o problemas de DNS pueden afectar a usuarios específicos sin activar alertas.
Cómo evitarlo:
Monitoree las APIs desde múltiples ubicaciones globales que reflejen dónde están realmente sus usuarios.
3. Ignorar endpoints autenticados
Muchos equipos evitan monitorear APIs autenticadas porque la configuración parece compleja. Como resultado, las APIs más críticas, aquellas que requieren tokens, headers o permisos, quedan sin monitoreo.
Cómo evitarlo:
Utilice herramientas de monitoreo que admitan autenticación, headers y rotación de credenciales para que el uptime refleje el comportamiento real de la aplicación.
4. Alertar ante cada fallo
Alertar ante cada comprobación fallida genera ruido, fatiga de alertas y, finalmente, notificaciones ignoradas. Los fallos temporales de red o los problemas de una sola región no siempre justifican una escalada inmediata.
Cómo evitarlo:
Diseñe la lógica de alertas para verificar fallos en múltiples ubicaciones o a lo largo de varias comprobaciones antes de activar alertas.
5. Tratar el uptime como una métrica de vanidad
Los porcentajes altos de uptime se ven bien en los informes, pero a menudo ocultan problemas subyacentes. Una API puede cumplir su objetivo de uptime y aun así ofrecer una mala experiencia de usuario.
Cómo evitarlo:
Vincule el monitoreo de uptime con objetivos de confiabilidad como tasas de error, umbrales de latencia y objetivos de nivel de servicio.
Estos errores explican por qué los equipos suelen sentirse confiados en su monitoreo hasta que los usuarios reportan problemas primero. Evitarlos requiere un cambio de mentalidad: el monitoreo de uptime no trata de demostrar que los sistemas están en línea, sino de demostrar que son utilizables.
Aquí es donde prácticas más amplias como herramientas de monitoreo de API y monitoreo de salud de API ayudan a cubrir los vacíos que dejan las comprobaciones básicas, ofreciendo una visión más realista de la confiabilidad de la API.
Cuando las Herramientas Nativas o Solo para Desarrolladores Dejan de Ser Suficientes
Las herramientas nativas y orientadas a desarrolladores son valiosas al principio. Las comprobaciones de CI/CD, las pruebas unitarias y los monitores a nivel de plataforma ayudan a detectar problemas obvios antes de que el código llegue a producción. Pero a medida que las APIs escalan y se vuelven de cara al cliente, estas herramientas empiezan a mostrar claras limitaciones.
Un problema importante es el sesgo del entorno. Las herramientas solo para desarrolladores suelen ejecutarse dentro de la misma nube, red o pipeline que la propia API. Esto las hace eficaces para validar despliegues, pero débiles para detectar problemas que los usuarios experimentan fuera de su entorno, como fallos de enrutamiento o caídas regionales.
Otra limitación es el alcance y la continuidad. La mayoría de las comprobaciones nativas están diseñadas para ejecuciones de corta duración, no para un monitoreo continuo. A menudo pasan por alto problemas que se desarrollan con el tiempo, incluidos:
- Aumentos graduales de latencia
- Fallos intermitentes de dependencias
- Degradación de rendimiento específica por región
También está el problema de la confianza en las alertas. Cuando las alertas se originan dentro de su propia infraestructura, los equipos suelen cuestionar si un problema es real o solo una anomalía interna. Esta incertidumbre ralentiza los tiempos de respuesta y conduce a investigaciones innecesarias.
A medida que las APIs maduran, los equipos necesitan un monitoreo que proporcione un punto de vista independiente, que refleje cómo los usuarios realmente experimentan la API. El monitoreo externo de uptime añade esa perspectiva faltante al validar la disponibilidad y el rendimiento desde fuera de su entorno.
Aquí es donde el monitoreo de API REST se vuelve esencial. En lugar de depender únicamente de comprobaciones internas, los equipos pueden monitorear continuamente las APIs desde múltiples ubicaciones globales, validar respuestas reales y confirmar si los fallos son generalizados o aislados.
El cambio lejos de las herramientas solo para desarrolladores rara vez es teórico. Se desencadena por incidentes no detectados, alertas tardías o problemas reportados primero por los clientes. Reconocer estas señales de advertencia a tiempo ayuda a los equipos a evolucionar su estrategia de monitoreo antes de que los problemas de confiabilidad se conviertan en riesgos para el negocio.
También es importante reconocer los límites del monitoreo sintético de uptime. Si bien confirma la disponibilidad orientada al usuario y el impacto, no sustituye a los logs, trazas o métricas para un análisis profundo de causa raíz. Estas herramientas funcionan mejor juntas.
Cómo Dotcom-Monitor Aborda el Monitoreo de Uptime de API
Dotcom-Monitor utiliza monitoreo sintético externo desde checkpoints globales independientes para validar la disponibilidad, la corrección y el rendimiento tal como lo experimentan los usuarios.
En el núcleo de este enfoque se encuentra el monitoreo sintético externo. Las APIs se prueban desde fuera de su infraestructura, utilizando checkpoints globales independientes. Esto elimina el sesgo interno y garantiza que los datos de uptime reflejen lo que experimentan los usuarios, no solo lo que informan sus propios sistemas.
Las capacidades clave que respaldan este enfoque incluyen:
- Ubicaciones de monitoreo globales que revelan fallos regionales y problemas de latencia
- Validación avanzada de respuestas, para que un 200 OK no se confunda con un resultado exitoso
- Monitoreo de APIs de varios pasos que valida flujos completos, no solo llamadas individuales
- Soporte para APIs autenticadas y privadas, incluidos headers, tokens y lógica personalizada
Esto permite detectar fallos silenciosos que las comprobaciones básicas de uptime no detectan, como payloads incorrectos, flujos de autenticación rotos o fallos parciales de dependencias.
Otro elemento crítico es la fiabilidad de las alertas. Dotcom-Monitor puede configurarse para reducir falsos positivos mediante comprobaciones de falsos positivos y reglas de alerta basadas en la duración del error y el número de ubicaciones fallidas. Las alertas se convierten en señales, no en ruido.
Dado que el monitoreo es continuo, los equipos también pueden analizar tendencias a lo largo del tiempo. Los picos de latencia, la degradación regional y los errores intermitentes salen a la luz antes de escalar a interrupciones completas. Esto transforma el monitoreo de uptime de una actividad reactiva en una práctica proactiva de confiabilidad.
Todo esto se ofrece a través de Web API Monitoring de Dotcom-Monitor, diseñado específicamente para entornos de producción. En lugar de monitorear lo más fácil de comprobar, se centra en lo que más importa: disponibilidad, corrección y rendimiento tal como lo experimentan los usuarios reales.
Para los equipos listos para ir más allá de las comprobaciones básicas, explore nuestra herramienta de monitoreo de Web API de nivel producción
