 Para muitas equipes, o monitoramento de uptime de API ainda significa uma coisa simples: verificar se um endpoint responde com um 200 OK. Se a verificação passa, a API é marcada como “ativa”. Se falha, um alerta é disparado. No papel, isso parece razoável. Na prática, é um dos motivos mais comuns pelos quais falhas de API passam despercebidas até que os usuários reclamem.
Para muitas equipes, o monitoramento de uptime de API ainda significa uma coisa simples: verificar se um endpoint responde com um 200 OK. Se a verificação passa, a API é marcada como “ativa”. Se falha, um alerta é disparado. No papel, isso parece razoável. Na prática, é um dos motivos mais comuns pelos quais falhas de API passam despercebidas até que os usuários reclamem.
O problema é que as APIs modernas não são mais endpoints simples e sem estado. Elas dependem de várias partes móveis, incluindo:
- Fluxos de autenticação e autorização
- Bancos de dados e tarefas em segundo plano
- Serviços de terceiros e APIs externas
- Infraestrutura e roteamento específicos por região
Por causa dessa complexidade, uma API pode retornar um código de status de sucesso e ainda assim falhar de maneiras significativas. A resposta pode conter dados incompletos, valores desatualizados ou resultados logicamente incorretos. Em um painel de monitoramento, tudo parece saudável. Do ponto de vista do usuário, a API está efetivamente fora do ar.
Essa desconexão cria o que muitas equipes vivenciam como uptime falso. Verificações básicas de uptime são boas para responder a uma pergunta técnica estreita:
- O monitoramento de uptime de API confirma que uma API está acessível, rápida e retornando resultados corretos.
- “200 OK” por si só pode ocultar falhas silenciosas (payloads incorretos, falhas de autenticação, dados parciais).
- O uptime em produção deve incluir transações em múltiplas etapas e verificações em múltiplas regiões.
Por isso, o monitoramento de uptime de API precisa de uma definição mais ampla. Ele deve considerar disponibilidade, correção e desempenho do ponto de vista do usuário, não apenas a capacidade do servidor de responder.
O tempo de inatividade real não é teórico; ele tem um impacto financeiro mensurável. Segundo a Gartner, a interrupção média de TI custa cerca de US$ 5.600 por minuto, ou aproximadamente US$ 300.000 por hora para muitas organizações. E em pesquisas independentes, mais de 90% das empresas médias e grandes relatam custos horários de downtime acima de US$ 300.000, com 41% dizendo que as interrupções podem ultrapassar US$ 1 milhão por hora. Essas perdas vêm de transações perdidas, produtividade reduzida, penalidades de SLA e danos à confiança do cliente, tudo o que verificações básicas frequentemente deixam de detectar.
Neste guia, exploraremos o que o monitoramento de uptime de API realmente significa hoje, por que abordagens comuns ficam aquém e como as equipes podem projetar estratégias de monitoramento que reflitam o uso no mundo real. Assim, “API ativa” passa a significar “API funcionando”.
O Que o Monitoramento de Uptime de API Realmente Significa Hoje
Em sua essência, o monitoramento de uptime de API deve responder a uma pergunta simples: os consumidores podem confiar nesta API agora? O problema é que muitas equipes ainda definem “uptime” de forma estreita demais, focando apenas se um endpoint responde a uma solicitação. Em sistemas modernos, essa definição não se sustenta.
As APIs estão no centro de arquiteturas distribuídas. Elas autenticam usuários, orquestram fluxos de trabalho e dependem de múltiplos serviços internos e externos. Por causa disso, uptime não é mais um conceito binário. Uma API pode estar acessível e ainda assim inutilizável.
A diferença entre verificações básicas de uptime e o monitoramento moderno de uptime de API fica mais clara quando você observa como o monitoramento é realmente realizado. Em vez de um único ping de um local, o monitoramento eficaz valida fluxos de trabalho reais a partir de múltiplas regiões e caminhos de dependência.
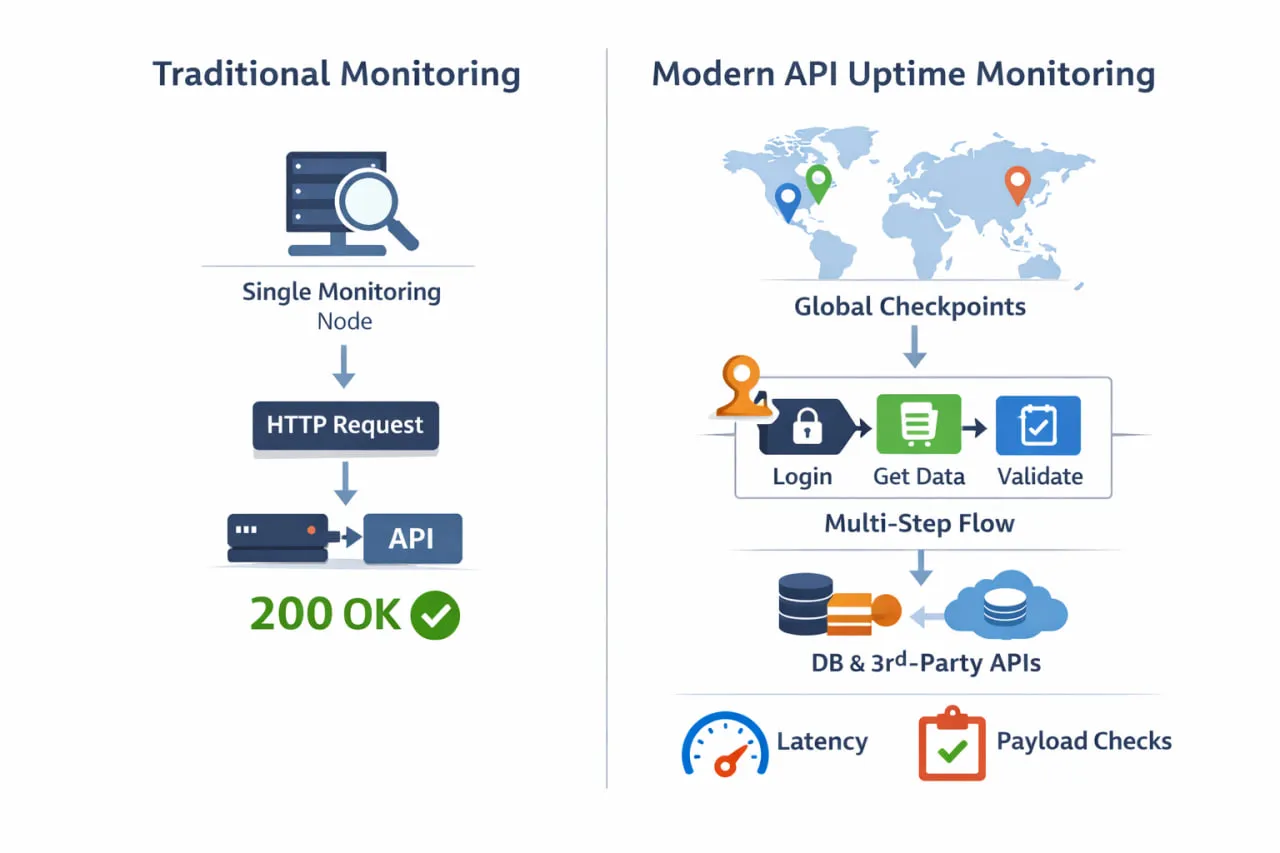
Uma definição mais precisa de uptime de API inclui três dimensões igualmente importantes:
- Disponibilidade – A API pode ser acessada de onde os usuários estão?
- Correção – A API retorna os dados, a estrutura e os valores esperados?
- Responsividade – A API responde dentro de limites aceitáveis de latência?
Se qualquer uma dessas falhar, os usuários experimentam downtime, mesmo que sua ferramenta de monitoramento reporte 100% de uptime.
É aqui que muitas verificações tradicionais de uptime falham. Uma verificação HTTP de uma única região pode confirmar que um endpoint retorna 200 OK, mas não dirá se a autenticação está falhando, se uma dependência downstream está expirando ou se usuários em outra região estão enfrentando desempenho degradado. Do ponto de vista da engenharia, tudo parece verde. Do lado de fora, a API está quebrada.
Para entender uptime corretamente, o monitoramento de API precisa estar alinhado com a forma como as APIs são realmente consumidas. Isso significa observar APIs como sistemas, não apenas como endpoints. Também significa conectar o monitoramento de uptime a práticas mais amplas de confiabilidade, como logs, tracing e métricas, áreas comumente discutidas sob observabilidade de API. Embora a observabilidade forneça insights internos profundos, o monitoramento de uptime desempenha um papel complementar: validar o que os usuários reais experimentam do lado de fora.
Quando feito corretamente, o monitoramento de uptime de API atua como um sistema de alerta precoce. Ele detecta falhas antes que os usuários as relatem, destaca problemas regionais ou condicionais e revela questões que métricas internas sozinhas podem não captar. Em vez de responder “o servidor respondeu?”, ele responde a uma pergunta muito mais útil: a API está entregando valor de forma confiável agora?
Essa mudança de definição é a base para tudo o que vem a seguir. Quando o uptime é enquadrado em torno da usabilidade real, as limitações das verificações básicas ficam claras, assim como a necessidade de estratégias de monitoramento mais robustas.
Por Que Verificações Básicas de Uptime Falham em APIs Modernas
As verificações básicas de uptime foram projetadas para uma era mais simples, quando um aplicativo expunha um pequeno número de endpoints previsíveis e o sucesso podia ser medido por um único código de resposta. As APIs modernas não funcionam mais assim. Ainda assim, muitas configurações de monitoramento continuam dependentes das mesmas suposições ultrapassadas.
As limitações das verificações básicas de uptime ficam evidentes quando você as compara lado a lado com o monitoramento moderno e pronto para produção de uptime de API.
| Capacidade | Verificações Tradicionais de Uptime | Monitoramento Moderno de Uptime de API |
| Local de monitoramento | Região única | Múltiplas regiões globais |
| O que é verificado | Acessibilidade do endpoint | Usabilidade de ponta a ponta da API |
| Suporte a autenticação | Raro ou inexistente | Suporte completo (tokens, headers, OAuth) |
| Validação de resposta | Apenas código de status | Payload, esquema, valores e lógica |
| Monitoramento de fluxo | Não suportado | Fluxos multi-etapas / transacionais |
| Consciência de dependências | Nenhuma | Detecta falhas downstream |
| Insight de desempenho | Latência básica ou média | Tendências, limites e degradação |
| Detecção de falhas silenciosas | ❌ Perdidas | ✅ Detectadas cedo |
| Alinhamento com a experiência do usuário | Baixo | Alto |
Pings tradicionais de uptime podem dizer que um servidor está tecnicamente acessível, mas não protegem contra falhas silenciosas custosas. Algumas análises do setor estimam custos médios de downtime próximos de US$ 14.000 por minuto. Isso representa centenas de milhares de dólares por hora em que uma API está prejudicada, mesmo que superficialmente “ativa”.
Um dos modos de falha mais comuns é a “ilusão do 200 OK”. Uma API pode responder com sucesso no nível HTTP enquanto falha no nível da lógica de negócio. Por exemplo, a resposta pode:
- Retornar um payload vazio ou parcial
- Conter dados obsoletos ou incorretos
- Omitir campos obrigatórios ou quebrar expectativas de esquema
Para uma verificação tradicional de uptime, isso parece sucesso. Para usuários e sistemas downstream, é uma falha silenciosa.
A autenticação introduz outro grande ponto cego. As APIs geralmente dependem de tokens que expiram, chaves rotativas ou acesso baseado em funções. Uma verificação básica que não simula totalmente fluxos de autenticação não detectará problemas como credenciais expiradas ou permissões mal configuradas. O endpoint está acessível, mas nenhum consumidor real consegue usá-lo.
As dependências pioram o problema. A maioria das APIs depende de bancos de dados, filas de mensagens e serviços de terceiros. Se uma dependência downstream degrada ou falha de forma intermitente, a API ainda pode responder, mas com latência aumentada, resultados parciais ou comportamento inconsistente. Esses são exatamente os tipos de problemas que verificações básicas têm mais dificuldade para capturar.
A geografia adiciona outra camada de complexidade. Muitas verificações de uptime são executadas a partir de um único local, muitas vezes próximo de onde a infraestrutura está hospedada. Isso oculta problemas regionais causados por roteamento, interrupções de ISPs ou configurações incorretas de CDN. Usuários em uma parte do mundo podem estar enfrentando timeouts enquanto os painéis de monitoramento mostram que tudo está bem.
Essas limitações explicam por que as equipes frequentemente acreditam que têm um forte monitoramento de uptime de API, até que os clientes relatem problemas primeiro. O que falta é visibilidade sobre como as APIs se comportam em condições reais.
Por isso, estratégias modernas de uptime combinam verificações de acessibilidade com a capacidade de validar a correção da resposta da API e monitorar tendências de latência da API em várias regiões, para que os problemas sejam detectados com base no impacto real para o usuário, não apenas na disponibilidade do servidor.
Até que o monitoramento vá além de verificações básicas de acessibilidade, as equipes continuarão a perder os problemas que mais importam.
As Métricas Centrais que Definem o Verdadeiro Uptime de API
Depois que você supera a ideia de que uptime significa apenas “endpoint acessível”, a próxima pergunta fica clara: o que o monitoramento de uptime de API deve realmente medir? Um monitoramento eficaz foca em um pequeno conjunto de métricas que refletem como as APIs se comportam no mundo real — não apenas no papel.
1. Disponibilidade (Acessibilidade)
Disponibilidade responde à pergunta mais básica: a API pode ser acessada a partir de um determinado local?
Essa métrica ainda é importante, mas é apenas o ponto de partida. Uma API que responde às solicitações, mas falha de outras maneiras, é tecnicamente disponível, porém praticamente inutilizável.
2. Latência (Responsividade)
Latência mede quanto tempo a API leva para responder. Mesmo quando as solicitações têm sucesso, respostas lentas são percebidas como downtime pelos usuários. O monitoramento deve acompanhar:
- Tempos de resposta em relação a limites definidos
- Tendências de latência ao longo do tempo, não apenas médias
Isso ajuda as equipes a capturar a degradação gradual de desempenho antes que ela se transforme em uma interrupção.
3. Correção da Resposta
É aqui que muitas estratégias de uptime falham. A correção foca no que a API retorna, não apenas no fato de retornar algo. Na prática, a correção da resposta é validada por meio de asserções.
Por exemplo, as equipes podem verificar se campos obrigatórios existem usando JSONPath, confirmar se valores numéricos estão dentro de faixas esperadas ou verificar se o esquema da resposta corresponde a uma estrutura esperada. Essas verificações garantem que um 200 OK represente de fato um resultado bem-sucedido.
Sem validação de resposta, os painéis de monitoramento podem mostrar 100% de uptime enquanto os usuários enfrentam falhas.
4. Consistência Regional
As APIs são consumidas globalmente, mas as falhas geralmente são regionais. Problemas de roteamento de rede, interrupções de ISPs ou falhas de infraestrutura localizadas podem afetar uma geografia enquanto deixam outras intactas. Monitorar a partir de vários locais garante que o uptime reflita a realidade do usuário, não apenas a proximidade da infraestrutura.
5. Comportamento de Erros
Nem todas as falhas são iguais. Acompanhar tipos de erro adiciona contexto crucial aos dados de uptime:
- Erros 401/403 geralmente sinalizam problemas de autenticação
- Erros de nível 500 apontam para falhas no servidor
- Timeouts geralmente indicam problemas downstream ou de desempenho
Quando essas métricas são monitoradas em conjunto, o uptime se torna um sinal de confiabilidade significativo, em vez de um número de vaidade.
É por isso que o verdadeiro monitoramento de uptime de API naturalmente se sobrepõe ao monitoramento de desempenho de API. Tendências de desempenho, verificações de correção e visibilidade regional contribuem para entender se uma API é genuinamente utilizável.
Ao focar nessas métricas centrais, as equipes passam do monitoramento reativo para a confiabilidade proativa, capturando problemas cedo, reduzindo falsa confiança e alinhando o uptime à experiência real do usuário.
Mapeando o Uptime de API para SLOs e SLIs
À medida que as APIs amadurecem, o uptime deixa de ser uma porcentagem vaga e se torna um compromisso de confiabilidade. É aqui que entram os objetivos de nível de serviço (SLOs) e os indicadores de nível de serviço (SLIs).
Em vez de perguntar “a API está ativa?”, as equipes definem uptime em termos de experiência do usuário mensurável:
- SLI de Disponibilidade – As solicitações estão tendo sucesso?
- SLI de Latência – As respostas são rápidas o suficiente?
- SLI de Correção – As respostas são precisas e completas?
O monitoramento de uptime de API alimenta diretamente esses indicadores. Verificações de disponibilidade confirmam a acessibilidade, o acompanhamento de latência expõe lentidões e a validação de resposta garante que a API se comporte corretamente, não apenas tecnicamente, mas funcionalmente.
Um SLO então define o limite aceitável para cada indicador. Por exemplo, uma API pode ter como alvo:
- 99,9% de respostas bem-sucedidas
- 95% das solicitações abaixo de 300 ms
- Zero falhas de esquema ou validação para endpoints críticos
Quando o monitoramento de uptime está alinhado com SLOs, os alertas deixam de ser arbitrários. Eles sinalizam quando a confiabilidade voltada ao usuário está em risco, não apenas quando um servidor deixa de responder. Isso reformula o uptime de uma métrica de vaidade para uma ferramenta de tomada de decisão que orienta prioridades de engenharia e resposta a incidentes.
Como Calcular o Verdadeiro Uptime de API
O verdadeiro uptime de API não se resume a verificar se um endpoint responde. Ele é calculado com base em quantas solicitações realmente têm sucesso do ponto de vista do usuário.
A disponibilidade é medida como:
SLI de Disponibilidade = solicitações_boas / solicitações_totais
Uma solicitação boa é aquela que:
- Retorna um status 2xx
- Passa nas asserções de esquema e resposta
- Atende aos limites de latência
O uptime deve ser medido ao longo de uma janela definida (por exemplo, 28 dias contínuos) e avaliado em relação a um SLO-alvo. A margem restante (1 − SLO) torna-se seu orçamento de erro.
Essa abordagem garante que o uptime reflita a usabilidade real, não apenas a acessibilidade.
Como Projetar uma Estratégia Eficaz de Monitoramento de Uptime de API
Projetar uma estratégia eficaz de monitoramento de uptime de API não é sobre adicionar mais verificações — é sobre escolher as verificações certas e validar os resultados certos. O objetivo é espelhar o uso real o mais próximo possível, sem criar ruído ou pontos cegos.
Comece pelas APIs que mais importam
Nem todo endpoint merece o mesmo nível de escrutínio. Comece identificando as APIs que são mais críticas para os usuários e para o negócio. Normalmente, isso inclui:
- Endpoints de autenticação e autorização
- APIs centrais transacionais ou geradoras de receita
- APIs públicas ou voltadas a parceiros com dependências externas
Focar nessas APIs garante que as métricas de uptime reflitam impacto real, não apenas cobertura de monitoramento.
Escolha a frequência com intenção
É tentador verificar cada endpoint a cada poucos segundos, mas maior frequência nem sempre produz melhor insight. Os intervalos de monitoramento devem ser baseados em:
- Quão rapidamente as falhas precisam ser detectadas
- Quão tolerantes os usuários são a interrupções curtas
- O risco de fadiga de alertas
Para APIs de alto impacto, verificações frequentes são justificadas. Para serviços de menor risco, intervalos mais longos geralmente fornecem sinal suficiente sem ruído desnecessário.
Monitore fluxos multi-etapas e transacionais
A maioria das APIs modernas não opera isoladamente. Uma única ação do usuário geralmente aciona várias chamadas de API em sequência. Monitorar apenas endpoints individuais pode perder falhas que ocorrem entre etapas.
É aqui que o monitoramento de API em múltiplas etapas se torna essencial. Em vez de verificar endpoints de forma independente, as equipes monitoram fluxos de trabalho inteiros, como autenticação, criação de dados, recuperação e validação, como uma única transação. Essa abordagem expõe problemas que verificações simples de uptime não conseguem capturar.
Valide mais do que códigos de status
O verdadeiro monitoramento de uptime exige validar respostas, não apenas recebê-las. Verificações eficazes afirmam:
- Estrutura da resposta e campos obrigatórios
- Valores específicos que indicam sucesso
- Regras de negócio que confirmam que a API está se comportando corretamente
Sem esse nível de validação, os painéis de uptime podem mostrar 100% de disponibilidade enquanto os usuários experimentam funcionalidades quebradas.
Inclua APIs autenticadas e privadas
Muitas APIs críticas ficam atrás de autenticação ou firewalls. Uma estratégia realista de uptime deve oferecer suporte a tokens, headers e rotação de credenciais. Caso contrário, as equipes acabam monitorando apenas as partes menos importantes do sistema.
As capacidades de Web API Monitoring e monitoramento de API REST da Dotcom-Monitor suportam endpoints autenticados e privados, permitindo que as equipes monitorem as mesmas APIs das quais seus aplicativos dependem em produção.
Monitore de onde os usuários estão
O monitoramento em um único local cria uma falsa sensação de confiabilidade. As APIs devem ser monitoradas a partir de múltiplas localizações geográficas que reflitam a distribuição real dos usuários. Isso ajuda a descobrir picos regionais de latência, problemas de roteamento e interrupções relacionadas a ISPs antes que se agravem.
Alinhe o uptime com metas de confiabilidade
Por fim, o monitoramento de uptime deve estar alinhado com objetivos de nível de serviço (SLOs). Em vez de perguntar “a API está ativa?”, as equipes devem perguntar:
- Ela está atendendo às metas de disponibilidade?
- O desempenho está dentro de limites aceitáveis?
- As taxas de erro estão excedendo os limites?
Quando as métricas de uptime se alinham às metas de confiabilidade, o monitoramento se torna acionável em vez de puramente informativo.
Para equipes que implementam essas estratégias, a documentação da Dotcom-Monitor, como configuração de monitoramento de Web API e Adicionar/Editar tarefa de Web API REST (com opções avançadas também abordadas em Configuração de tarefas de Web API REST), facilita a transição de verificações básicas para um monitoramento de uptime de API pronto para produção.
O Uptime de API Depende do Consumidor
O uptime de API não é tamanho único. APIs internas podem tolerar breves interrupções, mas exigem correção rigorosa para manter fluxos de trabalho em execução. APIs públicas exigem disponibilidade global consistente e baixa latência para proteger a experiência do usuário e a confiança na marca.
APIs de parceiros ou críticas para receita carregam as maiores expectativas, onde até pequenas degradações podem impactar contratos ou receitas. O monitoramento eficaz de uptime de API se adapta a essas diferenças priorizando endpoints, profundidade de validação e limites de alerta que refletem como a API é realmente consumida.
Erros Comuns no Monitoramento de Uptime de API (e Como Evitá-los)
Mesmo equipes com stacks de monitoramento maduros frequentemente caem nas mesmas armadilhas de monitoramento de uptime de API. Esses erros geralmente não vêm de negligência; vêm de confiar em suposições simplificadas demais sobre como as APIs falham em produção.
1. Tratar uptime como uma verificação de código de status
Um dos erros mais comuns é equiparar uptime a uma resposta HTTP bem-sucedida. Um 200 OK apenas confirma que o servidor respondeu, não que a API funcionou corretamente. Sem validar payloads, esquemas ou lógica de negócio, as equipes acabam medindo acessibilidade, não usabilidade.
Como evitar:
Vá além dos códigos de status validando o conteúdo da resposta e os valores esperados como parte das verificações de uptime.
2. Monitorar apenas a partir de um único local
Executar verificações de uptime a partir de uma única localização geográfica — muitas vezes próxima à sua infraestrutura — cria uma falsa sensação de confiabilidade. Problemas regionais de roteamento, interrupções de ISPs ou falhas de DNS podem afetar usuários em áreas específicas sem disparar alertas.
Como evitar:
Monitore APIs a partir de múltiplas localizações globais que reflitam onde seus usuários realmente estão.
3. Ignorar endpoints autenticados
Muitas equipes evitam monitorar APIs autenticadas porque a configuração parece complexa. Como resultado, as APIs mais críticas — aquelas que exigem tokens, headers ou permissões — ficam sem monitoramento.
Como evitar:
Use ferramentas de monitoramento que suportem autenticação, headers e rotação de credenciais para que o uptime reflita o comportamento real do aplicativo.
4. Alertar em toda falha
Alertar para cada verificação com falha leva a ruído, fadiga de alertas e, eventualmente, notificações ignoradas. Interrupções temporárias de rede ou problemas em uma única região nem sempre exigem escalonamento imediato.
Como evitar:
Projete a lógica de alertas para verificar falhas em várias localizações ou em múltiplas verificações antes de disparar alertas.
5. Tratar uptime como uma métrica de vaidade
Altas porcentagens de uptime ficam bonitas em relatórios, mas frequentemente ocultam problemas subjacentes. Uma API pode atingir sua meta de uptime e ainda assim entregar uma experiência ruim ao usuário.
Como evitar:
Vincule o monitoramento de uptime a metas de confiabilidade, como taxas de erro, limites de latência e objetivos de nível de serviço.
Esses erros explicam por que as equipes frequentemente se sentem confiantes em seu monitoramento, até que os usuários relatem problemas primeiro. Evitá-los exige uma mudança de mentalidade: monitoramento de uptime não é sobre provar que os sistemas estão online, é sobre provar que eles são utilizáveis.
É também aqui que práticas mais amplas como ferramentas de monitoramento de API e monitoramento de saúde de API ajudam a preencher as lacunas deixadas por verificações básicas, fornecendo uma visão mais realista da confiabilidade da API.
Quando Ferramentas Nativas ou Apenas para Desenvolvedores Deixam de Ser Suficientes
Ferramentas nativas e focadas em desenvolvedores são valiosas no início. Verificações de CI/CD, testes unitários e monitores em nível de plataforma ajudam a capturar problemas óbvios antes que o código chegue à produção. Mas, à medida que as APIs escalam e se tornam voltadas ao cliente, essas ferramentas começam a mostrar limitações claras.
Um grande problema é o viés de ambiente. Ferramentas apenas para desenvolvedores geralmente rodam dentro da mesma nuvem, rede ou pipeline da própria API. Isso as torna eficazes para validação de deploy, mas fracas para detectar problemas que os usuários enfrentam fora do seu ambiente, como problemas de roteamento ou interrupções regionais.
Outra limitação é o escopo e a continuidade. A maioria das verificações nativas é projetada para execuções de curta duração, não para monitoramento contínuo. Elas frequentemente perdem problemas que se desenvolvem ao longo do tempo, incluindo:
- Aumentos graduais de latência
- Falhas intermitentes de dependências
- Degradação de desempenho específica por região
Há também o problema da confiança nos alertas. Quando os alertas se originam de dentro da própria infraestrutura, as equipes frequentemente questionam se um problema é real ou apenas uma anomalia interna. Essa incerteza desacelera os tempos de resposta e leva a investigações desnecessárias.
À medida que as APIs amadurecem, as equipes precisam de monitoramento que forneça um ponto de vista independente, que reflita como os usuários realmente experimentam a API. O monitoramento externo de uptime adiciona essa perspectiva ausente ao validar disponibilidade e desempenho fora do seu ambiente.
É aqui que o monitoramento de API REST se torna essencial. Em vez de depender apenas de verificações internas, as equipes podem monitorar continuamente APIs a partir de múltiplas localizações globais, validar respostas reais e confirmar se as falhas são generalizadas ou isoladas.
A mudança para longe de ferramentas apenas para desenvolvedores geralmente não é teórica. Ela é desencadeada por incidentes perdidos, alertas atrasados ou clientes relatando problemas primeiro. Reconhecer esses sinais de alerta cedo ajuda as equipes a evoluir sua estratégia de monitoramento antes que problemas de confiabilidade se transformem em riscos de negócio.
Também é importante reconhecer os limites do monitoramento sintético de uptime. Embora ele confirme a disponibilidade voltada ao usuário e o impacto, não substitui logs, traces ou métricas para análise profunda de causa raiz. Essas ferramentas funcionam melhor em conjunto.
Como a Dotcom-Monitor Aborda o Monitoramento de Uptime de API
A Dotcom-Monitor utiliza monitoramento sintético externo a partir de checkpoints globais independentes para validar disponibilidade, correção e desempenho conforme os usuários experimentam.
No núcleo dessa abordagem está o monitoramento sintético externo. As APIs são testadas fora da sua infraestrutura, usando checkpoints globais independentes. Isso remove o viés interno e garante que os dados de uptime reflitam o que os usuários vivenciam, não o que seus próprios sistemas reportam.
As principais capacidades que sustentam essa abordagem incluem:
- Localizações globais de monitoramento que revelam falhas regionais e problemas de latência
- Validação avançada de resposta, para que um 200 OK não seja confundido com um resultado bem-sucedido
- Monitoramento de API em múltiplas etapas que valida fluxos de trabalho completos, não apenas chamadas únicas
- Suporte a APIs autenticadas e privadas, incluindo headers, tokens e lógica personalizada
Isso torna possível detectar falhas silenciosas que verificações básicas de uptime deixam passar, como payloads incorretos, fluxos de autenticação quebrados ou falhas parciais de dependências.
Outro elemento crítico é a confiabilidade dos alertas. A Dotcom-Monitor pode ser configurada para reduzir falsos positivos usando verificações de falso positivo e regras de alerta baseadas na duração do erro e no número de localizações com falha. Os alertas se tornam sinais, não ruído.
Como o monitoramento é contínuo, as equipes também podem analisar tendências ao longo do tempo. Picos de latência, degradação regional e erros intermitentes aparecem antes de se transformarem em interrupções completas. Isso desloca o monitoramento de uptime de uma atividade reativa para uma prática de confiabilidade proativa.
Tudo isso é entregue por meio do Web API Monitoring da Dotcom-Monitor, que é projetado especificamente para ambientes de produção. Em vez de monitorar o que é mais fácil de verificar, ele se concentra no que mais importa: disponibilidade, correção e desempenho conforme experimentados por usuários reais.
Para equipes prontas para ir além de verificações básicas, explore nossa ferramenta de monitoramento de Web API de nível de produção
