 Für viele Teams bedeutet API-Uptime-Monitoring noch immer eine einfache Sache: zu prüfen, ob ein Endpoint mit einem 200 OK antwortet. Besteht der Check, gilt die API als „verfügbar“. Schlägt er fehl, wird ein Alarm ausgelöst. Auf dem Papier klingt das vernünftig. In der Praxis ist es jedoch einer der häufigsten Gründe, warum API-Ausfälle unbemerkt bleiben, bis sich Nutzer beschweren.
Für viele Teams bedeutet API-Uptime-Monitoring noch immer eine einfache Sache: zu prüfen, ob ein Endpoint mit einem 200 OK antwortet. Besteht der Check, gilt die API als „verfügbar“. Schlägt er fehl, wird ein Alarm ausgelöst. Auf dem Papier klingt das vernünftig. In der Praxis ist es jedoch einer der häufigsten Gründe, warum API-Ausfälle unbemerkt bleiben, bis sich Nutzer beschweren.
Das Problem ist, dass moderne APIs keine einfachen, zustandslosen Endpoints mehr sind. Sie basieren auf mehreren beweglichen Teilen, darunter:
- Authentifizierungs- und Autorisierungsabläufe
- Datenbanken und Hintergrundprozesse
- Drittanbieter-Services und externe APIs
- Regionsspezifische Infrastruktur und Routing
Aufgrund dieser Komplexität kann eine API einen erfolgreichen Statuscode zurückgeben und dennoch in entscheidenden Punkten versagen. Die Antwort kann unvollständige Daten, veraltete Werte oder logisch falsche Ergebnisse enthalten. Im Monitoring-Dashboard sieht alles gesund aus. Aus Sicht der Nutzer ist die API jedoch faktisch nicht verfügbar.
Diese Diskrepanz führt zu dem, was viele Teams als falschen Uptime erleben. Einfache Uptime-Checks sind gut darin, eine sehr enge technische Frage zu beantworten:
- API-Uptime-Monitoring bestätigt, dass eine API erreichbar, schnell und korrekte Ergebnisse liefert.
- Ein reines „200 OK“ kann stille Fehler verbergen (fehlerhafte Payloads, Authentifizierungsprobleme, Teildaten).
- Produktions-Uptime sollte mehrstufige Transaktionen und regionenübergreifende Prüfungen umfassen.
Deshalb benötigt API-Uptime-Monitoring eine breitere Definition. Es muss Verfügbarkeit, Korrektheit und Performance aus Sicht der Nutzer berücksichtigen, nicht nur die Fähigkeit des Servers zu antworten.
Echte Ausfallzeiten sind nicht theoretisch, sie haben messbare finanzielle Auswirkungen. Laut Gartner kostet ein durchschnittlicher IT-Ausfall etwa 5.600 US-Dollar pro Minute oder rund 300.000 US-Dollar pro Stunde für viele Unternehmen. Und laut unabhängigen Studien berichten mehr als 90 % der mittelgroßen und großen Unternehmen von stündlichen Ausfallkosten über 300.000 US-Dollar, wobei 41 % angeben, dass Ausfälle über 1 Million US-Dollar pro Stunde kosten können. Diese Verluste entstehen durch entgangene Transaktionen, Produktivitätsverluste, SLA-Strafen und Vertrauensverlust bei Kunden – all das wird von einfachen Checks häufig nicht erkannt.
In diesem Leitfaden untersuchen wir, was API-Uptime-Monitoring heute wirklich bedeutet, warum gängige Ansätze nicht ausreichen und wie Teams Monitoring-Strategien entwickeln können, die die Nutzung in der Praxis widerspiegeln. Denn „API verfügbar“ sollte tatsächlich „API funktioniert“ bedeuten.
Was API-Uptime-Monitoring heute wirklich bedeutet
Im Kern soll API-Uptime-Monitoring eine einfache Frage beantworten: Können Verbraucher dieser API jetzt vertrauen? Das Problem ist, dass viele Teams „Uptime“ noch immer zu eng definieren und sich nur darauf konzentrieren, ob ein Endpoint auf eine Anfrage antwortet. In modernen Systemen trägt diese Definition nicht mehr.
APIs stehen im Zentrum verteilter Architekturen. Sie authentifizieren Nutzer, orchestrieren Workflows und sind von zahlreichen internen und externen Services abhängig. Deshalb ist Uptime kein binäres Konzept mehr. Eine API kann erreichbar und dennoch unbenutzbar sein.
Der Unterschied zwischen einfachen Uptime-Checks und modernem API-Uptime-Monitoring wird deutlich, wenn man betrachtet, wie Monitoring tatsächlich durchgeführt wird. Statt eines einzelnen Pings von einem Standort aus validiert effektives Monitoring reale Workflows aus mehreren Regionen und entlang verschiedener Abhängigkeitspfade.
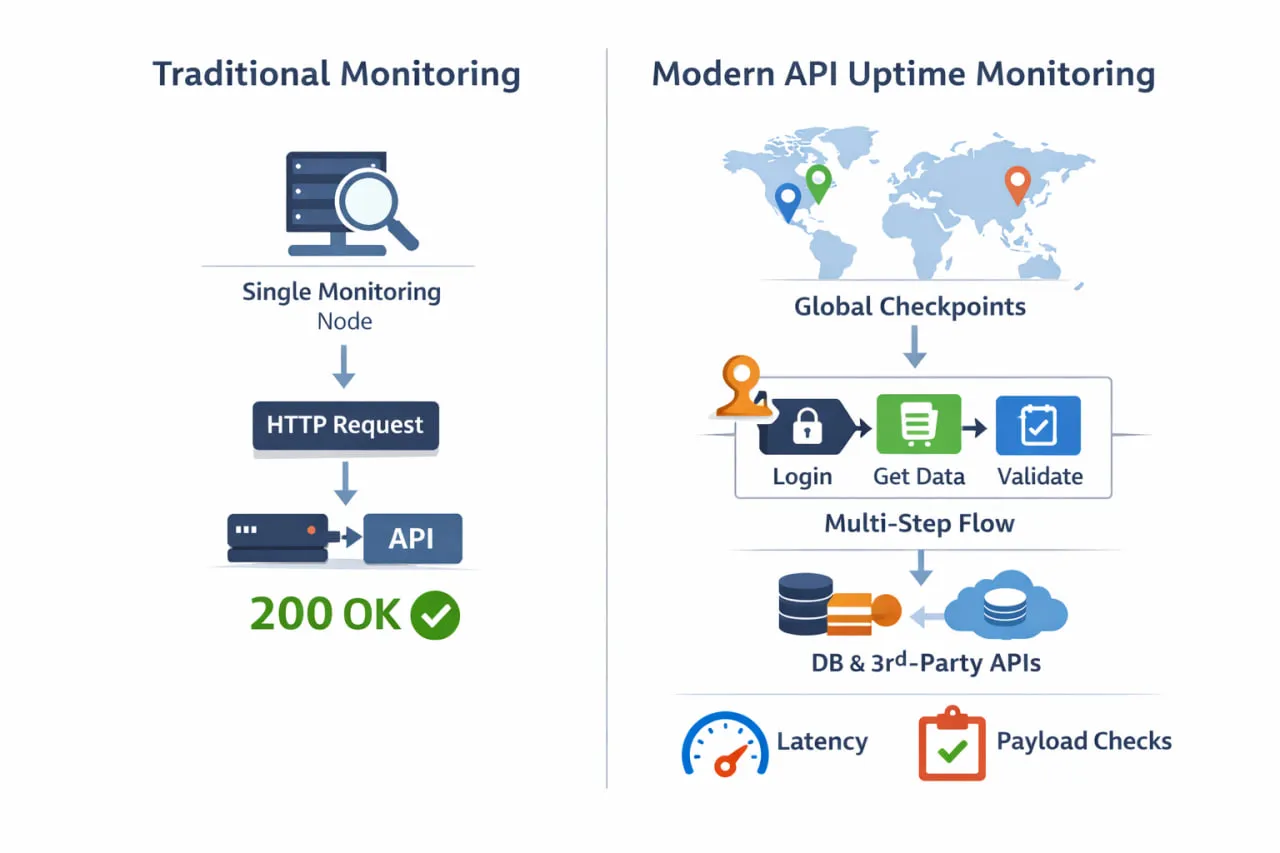
Eine genauere Definition von API-Uptime umfasst drei gleich wichtige Dimensionen:
- Verfügbarkeit – Ist die API von den Standorten der Nutzer aus erreichbar?
- Korrektheit – Liefert die API die erwarteten Daten, Strukturen und Werte?
- Reaktionsfähigkeit – Antwortet die API innerhalb akzeptabler Latenzgrenzen?
Fällt einer dieser Punkte aus, erleben Nutzer einen Ausfall – selbst wenn das Monitoring-Tool 100 % Uptime meldet.
Hier stoßen viele traditionelle Uptime-Checks an ihre Grenzen. Ein HTTP-Check aus einer einzelnen Region kann bestätigen, dass ein Endpoint 200 OK zurückgibt, sagt aber nichts darüber aus, ob die Authentifizierung fehlschlägt, eine nachgelagerte Abhängigkeit in ein Timeout läuft oder Nutzer in anderen Regionen eine verschlechterte Performance sehen. Aus technischer Sicht ist alles grün. Von außen betrachtet ist die API defekt.
Um Uptime korrekt zu verstehen, muss API-Monitoring an der tatsächlichen Nutzung ausgerichtet sein. Das bedeutet, APIs als Systeme zu betrachten und nicht nur als einzelne Endpoints. Es bedeutet auch, Uptime-Monitoring mit umfassenderen Zuverlässigkeitspraktiken wie Logging, Tracing und Metriken zu verbinden – Themen, die häufig unter dem Begriff API-Observability zusammengefasst werden. Während Observability tiefe interne Einblicke liefert, übernimmt Uptime-Monitoring eine ergänzende Rolle: die Validierung dessen, was reale Nutzer von außen erleben.
Richtig umgesetzt fungiert API-Uptime-Monitoring als Frühwarnsystem. Es erkennt Fehler, bevor Nutzer sie melden, hebt regionale oder bedingte Probleme hervor und deckt Störungen auf, die interne Metriken allein möglicherweise nicht zeigen. Statt nur zu beantworten „Hat der Server geantwortet?“, beantwortet es eine wesentlich relevantere Frage: Liefert die API aktuell zuverlässig einen Mehrwert?
Dieser Perspektivwechsel bildet die Grundlage für alles Weitere. Sobald Uptime im Kontext realer Nutzbarkeit verstanden wird, werden die Grenzen einfacher Checks deutlich – ebenso wie die Notwendigkeit robusterer Monitoring-Strategien.
Warum einfache Uptime-Checks bei modernen APIs versagen
Einfache Uptime-Checks wurden für eine einfachere Zeit entwickelt, als Anwendungen nur wenige vorhersehbare Endpoints hatten und Erfolg anhand eines einzelnen Statuscodes gemessen werden konnte. Moderne APIs funktionieren nicht mehr so. Dennoch stützen sich viele Monitoring-Setups weiterhin auf diese überholten Annahmen.
Die Schwächen einfacher Uptime-Checks werden deutlich, wenn man sie direkt mit modernem, produktionsreifem API-Uptime-Monitoring vergleicht.
| Fähigkeit | Traditionelle Uptime-Checks | Modernes API-Uptime-Monitoring |
| Monitoring-Standort | Eine Region | Mehrere globale Regionen |
| Was geprüft wird | Erreichbarkeit des Endpoints | End-to-End-Nutzbarkeit der API |
| Unterstützung der Authentifizierung | Selten oder keine | Vollständig (Tokens, Header, OAuth) |
| Antwortvalidierung | Nur Statuscode | Payload, Schema, Werte, Logik |
| Workflow-Monitoring | Nicht unterstützt | Mehrstufige / transaktionale Abläufe |
| Berücksichtigung von Abhängigkeiten | Keine | Erkennt nachgelagerte Fehler |
| Performance-Einblicke | Grundlegende oder durchschnittliche Latenz | Trends, Schwellenwerte, Degradierung |
| Erkennung stiller Fehler | ❌ Übersehen | ✅ Frühzeitig erkannt |
| Ausrichtung an der Nutzererfahrung | Niedrig | Hoch |
Traditionelle Uptime-Pings können anzeigen, dass ein Server technisch erreichbar ist, aber sie schützen nicht vor kostspieligen stillen Fehlern. Einige Branchenanalysen schätzen durchschnittliche Ausfallkosten von nahezu 14.000 US-Dollar pro Minute – also Hunderttausende Dollar pro Stunde, in der eine API beeinträchtigt ist, selbst wenn sie oberflächlich „verfügbar“ erscheint.
Einer der häufigsten Fehlermodi ist die „200-OK-Illusion“. Eine API kann auf HTTP-Ebene erfolgreich antworten, während sie auf Ebene der Geschäftslogik versagt. Die Antwort kann zum Beispiel:
- Einen leeren oder unvollständigen Payload zurückgeben
- Veraltete oder falsche Daten enthalten
- Pflichtfelder auslassen oder Schema-Erwartungen verletzen
Für einen klassischen Uptime-Check sieht das nach Erfolg aus. Für Nutzer und nachgelagerte Systeme ist es ein stiller Fehler.
Authentifizierung stellt einen weiteren großen blinden Fleck dar. APIs basieren häufig auf ablaufenden Tokens, rotierenden Schlüsseln oder rollenbasiertem Zugriff. Ein einfacher Check, der Authentifizierungsabläufe nicht vollständig simuliert, erkennt Probleme wie abgelaufene Zugangsdaten oder falsch konfigurierte Berechtigungen nicht. Der Endpoint ist erreichbar, aber kein realer Verbraucher kann ihn nutzen.
Abhängigkeiten verschärfen das Problem zusätzlich. Die meisten APIs sind auf Datenbanken, Message Queues und Drittanbieter-Services angewiesen. Wenn eine nachgelagerte Abhängigkeit sich verschlechtert oder intermittierend ausfällt, kann die API weiterhin antworten – jedoch mit erhöhter Latenz, Teilergebnissen oder inkonsistentem Verhalten. Genau diese Arten von Problemen sind mit einfachen Checks am schwersten zu erkennen.
Die geografische Dimension erhöht die Komplexität weiter. Viele Uptime-Checks laufen von einem einzigen Standort aus, oft nahe der Infrastruktur. Dadurch bleiben regionale Probleme durch Routing-Fehler, ISP-Ausfälle oder CDN-Fehlkonfigurationen verborgen. Nutzer in bestimmten Regionen erleben Timeouts, während Dashboards anzeigen, dass alles in Ordnung ist.
Diese Einschränkungen erklären, warum Teams häufig glauben, über ein starkes API-Uptime-Monitoring zu verfügen – bis Kunden zuerst Probleme melden. Was fehlt, ist Transparenz darüber, wie sich APIs unter realen Bedingungen verhalten.
Deshalb kombinieren moderne Uptime-Strategien Erreichbarkeitsprüfungen mit der Möglichkeit, die Korrektheit von API-Antworten zu validieren und Latenztrends von APIs zu überwachen – über mehrere Regionen hinweg. So werden Probleme anhand realer Nutzerwirkung erkannt und nicht nur anhand der Serververfügbarkeit.
Solange Monitoring nicht über reine Erreichbarkeitsprüfungen hinausgeht, werden Teams weiterhin die wichtigsten Probleme übersehen.
Die Kernmetriken, die echte API-Uptime definieren
Hat man sich von der Vorstellung gelöst, dass Uptime einfach „Endpoint erreichbar“ bedeutet, stellt sich die nächste Frage: Was sollte API-Uptime-Monitoring tatsächlich messen? Effektives Monitoring konzentriert sich auf eine kleine Anzahl von Metriken, die widerspiegeln, wie APIs sich in der realen Welt verhalten – nicht nur auf dem Papier.
1. Verfügbarkeit (Erreichbarkeit)
Verfügbarkeit beantwortet die grundlegendste Frage: Ist die API von einem bestimmten Standort aus erreichbar?
Diese Metrik ist weiterhin wichtig, aber sie ist nur der Ausgangspunkt. Eine API, die auf Anfragen antwortet, aber in anderer Hinsicht versagt, ist technisch verfügbar, praktisch jedoch unbrauchbar.
2. Latenz (Reaktionsfähigkeit)
Latenz misst, wie lange die API für eine Antwort benötigt. Selbst wenn Anfragen erfolgreich sind, fühlen sich langsame Antworten für Nutzer wie ein Ausfall an. Monitoring sollte erfassen:
- Antwortzeiten im Vergleich zu definierten Schwellenwerten
- Latenztrends über die Zeit, nicht nur Durchschnittswerte
So können Teams eine schleichende Performance-Verschlechterung erkennen, bevor sie zu einem Ausfall wird.
3. Korrektheit der Antworten
Hier scheitern viele Uptime-Strategien. Korrektheit bezieht sich darauf, was die API zurückgibt, nicht nur darauf, dass sie etwas zurückgibt. In der Praxis wird die Antwortkorrektheit mithilfe von Assertions geprüft.
Beispielsweise können Teams prüfen, ob Pflichtfelder per JSONPath vorhanden sind, ob numerische Werte in erwarteten Bereichen liegen oder ob das Antwortschema einer definierten Struktur entspricht. Diese Prüfungen stellen sicher, dass ein 200 OK tatsächlich ein erfolgreiches Ergebnis darstellt.
Ohne Antwortvalidierung können Monitoring-Dashboards 100 % Uptime anzeigen, während Nutzer Fehler erleben.
4. Regionale Konsistenz
APIs werden weltweit genutzt, Ausfälle sind jedoch häufig regional begrenzt. Netzwerk-Routing-Probleme, ISP-Ausfälle oder lokale Infrastrukturstörungen können eine Region betreffen, während andere unbeeinträchtigt bleiben. Monitoring aus mehreren Standorten stellt sicher, dass die Uptime die Realität der Nutzer widerspiegelt und nicht nur die Nähe zur Infrastruktur.
5. Fehlerverhalten
Nicht alle Fehler sind gleich. Die Erfassung von Fehlertypen liefert wichtigen Kontext für Uptime-Daten:
- 401/403-Fehler deuten häufig auf Authentifizierungsprobleme hin
- 500er-Fehler weisen auf serverseitige Probleme hin
- Timeouts deuten meist auf Performance- oder Abhängigkeitsprobleme hin
Werden diese Metriken gemeinsam überwacht, wird Uptime zu einem aussagekräftigen Zuverlässigkeitssignal statt zu einer reinen Schönzahl.
Deshalb überschneidet sich echtes API-Uptime-Monitoring zwangsläufig mit dem API-Performance-Monitoring. Performance-Trends, Korrektheitsprüfungen und regionale Transparenz tragen gemeinsam dazu bei, zu beurteilen, ob eine API tatsächlich nutzbar ist.
Durch die Fokussierung auf diese Kernmetriken wechseln Teams von reaktivem Monitoring zu proaktiver Zuverlässigkeit, erkennen Probleme frühzeitig, reduzieren falsches Sicherheitsgefühl und richten Uptime an der realen Nutzererfahrung aus.
API-Uptime mit SLOs und SLIs verknüpfen
Mit zunehmender Reife von APIs wird Uptime von einer vagen Prozentzahl zu einer Zuverlässigkeitsverpflichtung. An dieser Stelle kommen Service Level Objectives (SLOs) und Service Level Indicators (SLIs) ins Spiel.
Statt zu fragen „Ist die API verfügbar?“, definieren Teams Uptime anhand messbarer Nutzererfahrung:
- Verfügbarkeits-SLI – Sind Anfragen erfolgreich?
- Latenz-SLI – Sind die Antworten schnell genug?
- Korrektheits-SLI – Sind die Antworten korrekt und vollständig?
API-Uptime-Monitoring speist diese Indikatoren direkt. Verfügbarkeitschecks bestätigen die Erreichbarkeit, Latenztracking deckt Verlangsamungen auf und Antwortvalidierung stellt sicher, dass sich die API nicht nur technisch, sondern auch funktional korrekt verhält.
Ein SLO definiert anschließend die akzeptablen Schwellenwerte für jeden Indikator. Eine API kann sich zum Beispiel folgende Ziele setzen:
- 99,9 % erfolgreiche Antworten
- 95 % der Anfragen unter 300 ms
- Keine Schema- oder Validierungsfehler bei kritischen Endpoints
Wenn Uptime-Monitoring mit SLOs abgestimmt ist, sind Alarme nicht mehr willkürlich. Sie signalisieren, wann die nutzerseitige Zuverlässigkeit gefährdet ist – nicht nur, wann ein Server nicht antwortet. Dadurch wird Uptime von einer Vanity-Metrik zu einem Entscheidungswerkzeug für Engineering-Prioritäten und Incident-Management.
Wie man echte API-Uptime berechnet
Echte API-Uptime hängt nicht nur davon ab, ob ein Endpoint antwortet. Sie wird anhand der Anzahl der Anfragen berechnet, die tatsächlich erfolgreich sind – aus Sicht der Nutzer.
Die Verfügbarkeit wird gemessen als:
Verfügbarkeits-SLI = gute_Anfragen / Gesamt_Anfragen
Eine gute Anfrage ist eine Anfrage, die:
- Einen 2xx-Status zurückgibt
- Schema- und Antwort-Assertions besteht
- Die Latenzschwellen einhält
Uptime sollte über ein definiertes Zeitfenster (zum Beispiel rollierend über 28 Tage) gemessen und mit einem Ziel-SLO verglichen werden. Der verbleibende Spielraum (1 − SLO) bildet das Fehlerbudget.
Dieser Ansatz stellt sicher, dass Uptime die tatsächliche Nutzbarkeit widerspiegelt und nicht nur die Erreichbarkeit.
Wie man eine effektive API-Uptime-Monitoring-Strategie entwickelt
Eine effektive API-Uptime-Monitoring-Strategie bedeutet nicht, mehr Checks hinzuzufügen, sondern die richtigen Checks auszuwählen und die richtigen Ergebnisse zu validieren. Ziel ist es, die reale Nutzung möglichst genau abzubilden, ohne Rauschen oder blinde Flecken zu erzeugen.
Mit den wichtigsten APIs beginnen
Nicht jeder Endpoint verdient die gleiche Aufmerksamkeit. Beginnen Sie damit, die APIs zu identifizieren, die für Nutzer und Geschäft am kritischsten sind. Dazu gehören in der Regel:
- Authentifizierungs- und Autorisierungsendpoints
- Zentrale transaktionale oder umsatzrelevante APIs
- Öffentliche oder partnerorientierte APIs mit externen Abhängigkeiten
Die Fokussierung auf diese APIs stellt sicher, dass Uptime-Metriken den realen Einfluss widerspiegeln und nicht nur die Monitoring-Abdeckung.
Die Frequenz bewusst wählen
Es ist verlockend, jeden Endpoint alle paar Sekunden zu prüfen, doch eine höhere Frequenz liefert nicht immer bessere Erkenntnisse. Monitoring-Intervalle sollten sich richten nach:
- Der Geschwindigkeit, mit der Fehler erkannt werden müssen
- Der Toleranz der Nutzer gegenüber kurzen Unterbrechungen
- Dem Risiko von Alarmmüdigkeit
Für geschäftskritische APIs sind häufige Checks gerechtfertigt. Für weniger kritische Services liefern längere Intervalle oft ausreichend Signal ohne unnötiges Rauschen.
Mehrstufige und transaktionale Abläufe überwachen
Die meisten modernen APIs arbeiten nicht isoliert. Eine einzelne Nutzeraktion löst häufig mehrere API-Aufrufe in Folge aus. Werden nur einzelne Endpoints überwacht, bleiben Fehler zwischen den Schritten oft unentdeckt.
Hier wird mehrstufiges API-Monitoring essenziell. Statt Endpoints unabhängig voneinander zu prüfen, überwachen Teams komplette Workflows – etwa Authentifizierung, Datenerstellung, Abruf und Validierung – als eine Transaktion. Dieser Ansatz deckt Probleme auf, die einfache Uptime-Checks nicht erfassen können.
Mehr als nur Statuscodes validieren
Echtes Uptime-Monitoring erfordert die Validierung von Antworten, nicht nur deren Empfang. Effektive Checks prüfen:
- Antwortstruktur und Pflichtfelder
- Spezifische Werte, die auf Erfolg hinweisen
- Geschäftsregeln, die korrektes API-Verhalten bestätigen
Ohne dieses Validierungsniveau können Uptime-Dashboards 100 % Verfügbarkeit anzeigen, während Nutzer fehlerhafte Funktionen erleben.
Authentifizierte und private APIs einbeziehen
Viele kritische APIs sind durch Authentifizierung oder Firewalls geschützt. Eine realistische Uptime-Strategie muss Tokens, Header und Credential-Rotation unterstützen. Andernfalls überwachen Teams nur die unwichtigsten Teile ihres Systems.
Die Web API Monitoring– und REST-API-Monitoring-Funktionen von Dotcom-Monitor unterstützen authentifizierte und private Endpoints, sodass Teams genau die APIs überwachen können, auf die ihre Anwendungen in der Produktion angewiesen sind.
Dort überwachen, wo sich die Nutzer befinden
Monitoring von nur einem Standort aus vermittelt ein falsches Gefühl von Zuverlässigkeit. APIs sollten von mehreren geografischen Standorten aus überwacht werden, die der tatsächlichen Nutzerverteilung entsprechen. So lassen sich regionale Latenzspitzen, Routing-Probleme und ISP-bedingte Ausfälle erkennen, bevor sie eskalieren.
Uptime an Zuverlässigkeitszielen ausrichten
Schließlich sollte Uptime-Monitoring an Service Level Objectives (SLOs) ausgerichtet sein. Statt zu fragen „Ist die API verfügbar?“, sollten Teams fragen:
- Erfüllt sie die Verfügbarkeitsziele?
- Liegt die Performance innerhalb akzeptabler Grenzen?
- Überschreiten die Fehlerraten definierte Schwellenwerte?
Wenn Uptime-Metriken mit Zuverlässigkeitszielen übereinstimmen, wird Monitoring handlungsrelevant statt rein informativ.
Für Teams, die diese Strategien umsetzen, erleichtert die Dokumentation von Dotcom-Monitor – etwa zur Einrichtung des Web-API-Monitorings und zum Hinzufügen/Bearbeiten von REST-Web-API-Aufgaben (mit erweiterten Optionen in Konfiguration von REST-Web-API-Aufgaben) – den Übergang von einfachen Checks zu produktionsreifem API-Uptime-Monitoring.
API-Uptime hängt vom Verbraucher ab
API-Uptime ist nicht für alle gleich. Interne APIs können kurze Unterbrechungen tolerieren, benötigen jedoch strenge Korrektheit, um Workflows aufrechtzuerhalten. Öffentliche APIs verlangen eine konsistente globale Verfügbarkeit und geringe Latenz, um Nutzererfahrung und Markenvertrauen zu schützen.
Partner- oder umsatzkritische APIs haben die höchsten Anforderungen, bei denen selbst geringe Beeinträchtigungen Verträge oder Einnahmen beeinflussen können. Effektives API-Uptime-Monitoring passt sich diesen Unterschieden an, indem es Endpoints, Validierungstiefe und Alarmschwellen entsprechend der tatsächlichen Nutzung priorisiert.
Häufige Fehler beim API-Uptime-Monitoring (und wie man sie vermeidet)
Selbst Teams mit ausgereiften Monitoring-Stacks tappen häufig in dieselben Fallen beim API-Uptime-Monitoring. Diese Fehler entstehen meist nicht aus Nachlässigkeit, sondern aus zu vereinfachten Annahmen darüber, wie APIs in der Produktion versagen.
1. Uptime als reinen Statuscode-Check behandeln
Einer der häufigsten Fehler besteht darin, Uptime mit einer erfolgreichen HTTP-Antwort gleichzusetzen. Ein 200 OK bestätigt nur, dass der Server geantwortet hat – nicht, dass die API korrekt funktioniert. Ohne Validierung von Payloads, Schemas oder Geschäftslogik messen Teams lediglich die Erreichbarkeit, nicht die Nutzbarkeit.
So vermeiden Sie es:
Gehen Sie über Statuscodes hinaus und validieren Sie Antwortinhalte und erwartete Werte als Teil Ihrer Uptime-Checks.
2. Nur von einem Standort aus überwachen
Uptime-Checks von nur einem geografischen Standort – oft nahe der eigenen Infrastruktur – erzeugen ein falsches Gefühl von Zuverlässigkeit. Regionale Routing-Probleme, ISP-Ausfälle oder DNS-Fehler können bestimmte Nutzer betreffen, ohne Alarme auszulösen.
So vermeiden Sie es:
Überwachen Sie APIs von mehreren globalen Standorten aus, die der tatsächlichen Nutzerverteilung entsprechen.
3. Authentifizierte Endpoints ignorieren
Viele Teams vermeiden das Monitoring authentifizierter APIs, weil die Einrichtung komplex erscheint. Dadurch bleiben gerade die kritischsten APIs – jene mit Tokens, Headern oder Berechtigungen – unbeobachtet.
So vermeiden Sie es:
Nutzen Sie Monitoring-Tools, die Authentifizierung, Header und Credential-Rotation unterstützen, damit die Uptime das reale Anwendungsverhalten widerspiegelt.
4. Bei jedem Fehler alarmieren
Alarme bei jedem fehlgeschlagenen Check erzeugen Rauschen, Alarmmüdigkeit und letztlich ignorierte Benachrichtigungen. Kurzzeitige Netzwerkprobleme oder einzelne regionale Störungen rechtfertigen nicht immer eine sofortige Eskalation.
So vermeiden Sie es:
Gestalten Sie Alarmierungslogik so, dass Fehler über mehrere Standorte oder mehrere Checks hinweg bestätigt werden, bevor ein Alarm ausgelöst wird.
5. Uptime als Vanity-Metrik behandeln
Hohe Uptime-Prozentsätze sehen in Berichten gut aus, verdecken aber häufig zugrunde liegende Probleme. Eine API kann ihr Uptime-Ziel erreichen und dennoch eine schlechte Nutzererfahrung liefern.
So vermeiden Sie es:
Verknüpfen Sie Uptime-Monitoring mit Zuverlässigkeitszielen wie Fehlerraten, Latenzschwellen und Service Level Objectives.
Diese Fehler erklären, warum Teams sich oft sicher in ihrem Monitoring fühlen – bis Nutzer zuerst Probleme melden. Sie zu vermeiden erfordert einen Perspektivwechsel: Uptime-Monitoring dient nicht dazu zu beweisen, dass Systeme online sind, sondern dass sie nutzbar sind.
Hier helfen auch umfassendere Praktiken wie API-Monitoring-Tools und API-Health-Monitoring, die die Lücken einfacher Checks schließen und ein realistischeres Bild der API-Zuverlässigkeit liefern.
Wenn native oder rein entwicklerorientierte Tools nicht mehr ausreichen
Native und entwicklerorientierte Tools sind zu Beginn wertvoll. CI/CD-Checks, Unit-Tests und plattformnahe Monitore helfen, offensichtliche Probleme zu erkennen, bevor Code in die Produktion gelangt. Doch mit wachsender Skalierung und zunehmender Kundennähe von APIs zeigen diese Tools klare Grenzen.
Ein zentrales Problem ist der Umgebungsbias. Entwicklerorientierte Tools laufen meist innerhalb derselben Cloud, desselben Netzwerks oder derselben Pipeline wie die API selbst. Das macht sie effektiv für Deploy-Validierung, aber ungeeignet, um Probleme zu erkennen, die Nutzer außerhalb Ihrer Umgebung erleben – etwa Routing-Probleme oder regionale Ausfälle.
Eine weitere Einschränkung betrifft Umfang und Kontinuität. Die meisten nativen Checks sind für kurzzeitige Ausführungen konzipiert, nicht für kontinuierliches Monitoring. Sie verpassen häufig Probleme, die sich schleichend entwickeln, darunter:
- Allmähliche Latenzerhöhungen
- Intermittierende Ausfälle von Abhängigkeiten
- Regionsspezifische Performance-Degradierungen
Hinzu kommt das Problem der Alarmvertrauenswürdigkeit. Wenn Alarme aus der eigenen Infrastruktur stammen, zweifeln Teams oft, ob es sich um ein echtes Problem oder nur um eine interne Anomalie handelt. Diese Unsicherheit verlangsamt Reaktionszeiten und führt zu unnötigen Untersuchungen.
Mit zunehmender Reife von APIs benötigen Teams Monitoring mit einem unabhängigen Blickwinkel, der widerspiegelt, wie Nutzer die API tatsächlich erleben. Externes Uptime-Monitoring liefert diese fehlende Perspektive, indem es Verfügbarkeit und Performance von außerhalb Ihrer Umgebung validiert.
Hier wird das REST-API-Monitoring essenziell. Statt sich ausschließlich auf interne Checks zu verlassen, können Teams APIs kontinuierlich aus mehreren globalen Standorten überwachen, reale Antworten validieren und feststellen, ob Ausfälle weitreichend oder isoliert sind.
Der Abschied von rein entwicklerorientierten Tools ist selten theoretisch. Er wird durch verpasste Incidents, verspätete Alarme oder zuerst von Kunden gemeldete Probleme ausgelöst. Diese Warnsignale früh zu erkennen, hilft Teams, ihre Monitoring-Strategie weiterzuentwickeln, bevor Zuverlässigkeitsprobleme zu Geschäftsrisiken werden.
Ebenso wichtig ist es, die Grenzen des synthetischen Uptime-Monitorings zu verstehen. Es bestätigt die nutzerseitige Verfügbarkeit und den Impact, ersetzt jedoch keine Logs, Traces oder Metriken für eine tiefgehende Ursachenanalyse. Diese Tools ergänzen sich gegenseitig.
Wie Dotcom-Monitor API-Uptime-Monitoring umsetzt
Dotcom-Monitor setzt auf externes synthetisches Monitoring von unabhängigen globalen Checkpoints, um Verfügbarkeit, Korrektheit und Performance so zu validieren, wie Nutzer sie erleben.
Kern dieses Ansatzes ist das externe, synthetische Monitoring. APIs werden von außerhalb Ihrer Infrastruktur getestet, über unabhängige globale Checkpoints. Dadurch wird interner Bias eliminiert und sichergestellt, dass Uptime-Daten widerspiegeln, was Nutzer tatsächlich erleben – nicht nur das, was Ihre eigenen Systeme melden.
Zu den zentralen Funktionen dieses Ansatzes gehören:
- Globale Monitoring-Standorte, die regionale Ausfälle und Latenzprobleme sichtbar machen
- Erweiterte Antwortvalidierung, sodass ein 200 OK nicht fälschlich als Erfolg gewertet wird
- Mehrstufiges API-Monitoring, das komplette Workflows statt einzelner Aufrufe validiert
- Unterstützung für authentifizierte und private APIs, einschließlich Headern, Tokens und benutzerdefinierter Logik
So lassen sich stille Fehler erkennen, die einfache Uptime-Checks übersehen, etwa fehlerhafte Payloads, defekte Authentifizierungsabläufe oder partielle Abhängigkeitsfehler.
Ein weiterer entscheidender Faktor ist die Zuverlässigkeit der Alarme. Dotcom-Monitor kann so konfiguriert werden, dass Fehlalarme reduziert werden – durch False-Positive-Checks und Alarmregeln basierend auf Fehlerdauer und Anzahl betroffener Standorte. Alarme werden zu Signalen statt zu Rauschen.
Da das Monitoring kontinuierlich erfolgt, können Teams zudem Trends über die Zeit analysieren. Latenzspitzen, regionale Degradierungen und intermittierende Fehler werden sichtbar, bevor sie zu vollständigen Ausfällen eskalieren. Dadurch entwickelt sich Uptime-Monitoring von einer reaktiven Tätigkeit zu einer proaktiven Zuverlässigkeitspraxis.
All dies wird über Dotcom-Monitors Web API Monitoring bereitgestellt, das speziell für Produktionsumgebungen entwickelt wurde. Statt das Einfachste zu überwachen, konzentriert es sich auf das Wesentliche: Verfügbarkeit, Korrektheit und Performance aus Sicht realer Nutzer.
Für Teams, die über einfache Checks hinausgehen möchten, entdecken Sie unser produktionsreifes Web-API-Monitoring-Tool
