Monitoramento de API é a prática contínua e automatizada de validar endpoints de API quanto à disponibilidade, tempo de resposta e correção dos dados — confirmando não apenas que um endpoint responde, mas que ele retorna os dados corretos, no formato certo, dentro de uma latência aceitável, sob a perspectiva de usuários e sistemas dependentes.

APIs são o tecido conectivo do software moderno. Toda vez que um usuário faz login, envia um pagamento ou recebe uma notificação em tempo real, múltiplas chamadas de API são executadas nos bastidores — frequentemente entre microserviços, provedores de nuvem e fornecedores terceiros. Quando essas chamadas falham ou desaceleram, o impacto é imediato: fluxos de checkout quebrados, usuários bloqueados e receita perdida.
Ainda assim, a maioria das equipes descobre falhas de API apenas quando os clientes as relatam. Sem monitoramento proativo, o atraso entre a falha e a investigação costuma ser medido em dezenas de minutos — tempo suficiente para expor riscos reais de receita e SLA antes que alguém seja acionado.
Este guia explica o que é monitoramento de API, como funciona, quais métricas acompanhar, como difere de testes de API e APM, e como implementá-lo — com a precisão que engenheiros DevOps, SREs e equipes de QA precisam para tomar decisões informadas em produção.
O Que É Monitoramento de API?
O monitoramento de API cobre três camadas distintas de validação, em ordem de especificidade crescente:
- Monitoramento de disponibilidade — O endpoint está acessível? Retorna uma resposta HTTP sem timeout?
- Monitoramento de desempenho — Quanto tempo a resposta leva? O TTFB, resolução DNS ou handshake TLS introduzem latência?
- Validação do payload — O corpo da resposta contém a estrutura de dados esperada? Asserções JSONPath ou XPath passam?
O Que É um Endpoint de API?
Uma interface de programação de aplicações (API) é um conjunto de protocolos e definições que permite que sistemas de software se comuniquem. Um endpoint de API é a URL específica onde uma API recebe solicitações e retorna respostas — a unidade de observação para monitoramento de API. Por exemplo:
POST /v2/auth/token— endpoint para emissão de tokenGET /v2/orders/{id}— endpoint de recuperação de pedidoPOST /v2/payments/charge— endpoint de processamento de pagamento
Aplicações modernas dependem simultaneamente de dezenas ou centenas desses endpoints — microserviços internos, gateways de pagamento terceiros, provedores de identidade, APIs de envio e sistemas CRM. O monitoramento de API mantém a visibilidade em todos eles.
Tipos de Monitoramento de API
Nem todo monitoramento de API é igual. Entender as categorias ajuda as equipes a construir coberturas que atendam tanto à sua arquitetura quanto aos seus requisitos de negócios. Os cinco tipos principais se aplicam a quase todas as equipes; os tipos especializados são importantes quando suas condições se aplicam.
Tipos Principais
| Tipo | O Que Valida | Ideal Para |
|---|---|---|
| Monitoramento de Uptime | Alcance do endpoint; códigos de resposta HTTP; resposta dentro da janela de timeout | SLAs básicos de disponibilidade; detecção imediata de indisponibilidade |
| Monitoramento de Desempenho | Tempo de resposta, TTFB, resolução DNS, handshake TCP, tempo TLS, throughput | SLAs de latência, metas P95/P99, planejamento de capacidade |
| Monitoramento de Payload / Validação | Corpo da resposta via asserções JSONPath/XPath; correção do schema; valores dos campos | Capturar falhas silenciosas onde HTTP 200 ≠ dados corretos |
| Monitoramento Sintético | Chamadas API simuladas de locais globais em intervalos agendados, independentes do tráfego real | Detecção proativa; cobertura geográfica; períodos de zero tráfego |
| Monitoramento de Transações Multi-etapas | Sequências encadeadas de chamadas API (ex: autenticação → consulta → submissão → confirmação); passagem de dados entre etapas | Fluxos de e-commerce, jornadas de login, workflows de pedidos |
Tipos Especializados
| Tipo | O Que Valida | Ideal Para |
|---|---|---|
| Monitoramento de Segurança | Falhas de autenticação, padrões anômalos de requisições, expiração de certificados, abuso de limite de taxa, replay de tokens | FinTech, saúde; APIs que manipulam PII/PHI |
| Verificações Relacionadas à Conformidade | Validação da versão/cifra TLS, expiração de certificado, presença de cabeçalhos de segurança, testes de aplicação de autenticação | Saúde, serviços financeiros, indústrias reguladas |
| Monitoramento de Usuário Real (RUM) | Interações reais dos usuários com APIs; visibilidade de sessão completa; variações geográficas e de dispositivos reais | Entender impacto real do usuário; validar achados sintéticos |
| Monitoramento de Versionamento & Descontinuação | Adoção de versões da API; picos de erros após mudanças; compatibilidade retroativa | Equipes que gerenciam múltiplas versões de API simultaneamente |
| Monitoramento de Terceiros / Integração | Dependências externas de API (Stripe, Okta, Salesforce, Twilio); isolar falhas externas vs. internas | Qualquer app que dependa de APIs terceiras para fluxos críticos |
Uma nota sobre verificações relacionadas à conformidade: elas fornecem evidências para controles técnicos específicos. A conformidade com frameworks (HIPAA, PCI DSS, SOC 2) exige governança organizacional mais ampla além do que o monitoramento isoladamente pode oferecer.
Monitoramento Sintético vs. Monitoramento de Usuário Real (RUM)
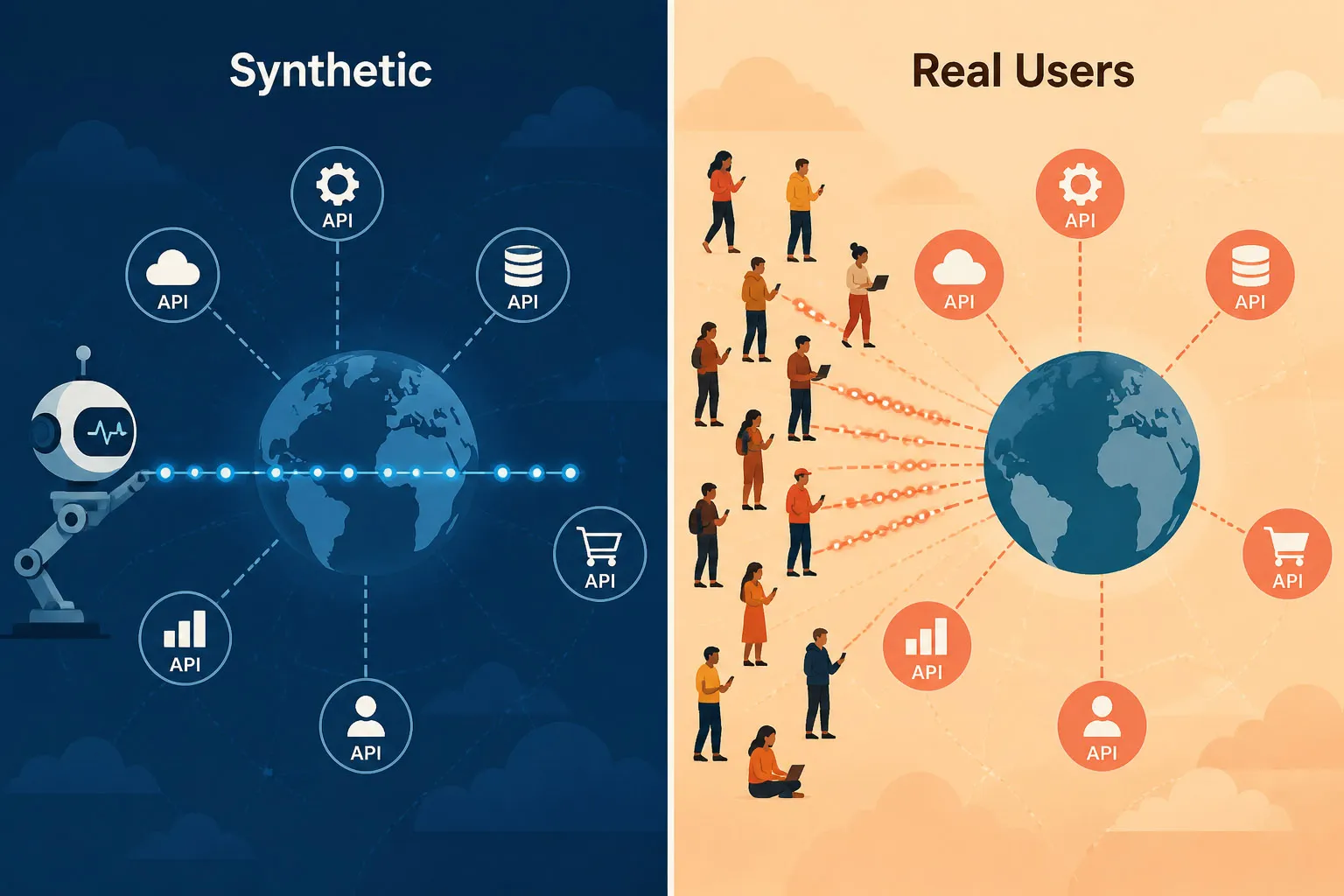
Ambas as abordagens fornecem dados de desempenho de API, mas de pontos de vista fundamentalmente diferentes:
| Monitoramento Sintético | Monitoramento de Usuário Real (RUM) | |
|---|---|---|
| Disparo | Checagens roteirizadas em cronograma (ex: a cada 1 minuto) | Solicitações reais dos usuários em produção |
| Cobertura | Executa 24/7 — inclusive quando não há usuários reais ativos | Gera dados apenas quando usuários estão ativamente fazendo requisições |
| Detecção | Proativo — detecta falhas antes que qualquer usuário seja impactado | Reativo — evidencia problemas após usuários terem sido afetados |
| Escopo | APIs públicas e privadas/internas (via Private Agent) | APIs acessadas por usuários/clientes reais — principalmente públicas, embora RUM empresarial também capte chamadas internas de apps instrumentados |
| Caso de uso | Validação contínua de disponibilidade e desempenho | Entender raio de impacto real e experiência do usuário final |
Principais Métricas de Monitoramento de API
Acompanhar as métricas corretas faz a diferença entre resposta informada a incidentes e fadiga de alertas. Abaixo estão as métricas que mais importam — com benchmarks precisos e o que cada uma indica.
| Métrica | Meta / Benchmark | O Que Captura |
|---|---|---|
| Disponibilidade (Uptime %) | ≥ 99,9% (três noves); 99,99% para APIs críticas de receita | Queda total, queda parcial, timeout |
| Tempo Total de Resposta | < 200ms para endpoints simples; < 1s para operações complexas | Desacelerações do servidor, sobrecarga, regressões pós-deployment |
| Tempo até o Primeiro Byte (TTFB) | < 100ms ideal; < 300ms aceitável | Atraso do servidor antes de começar a resposta |
| Tempo de Resposta P95 / P99 | Alerta em 2× o valor basal do P95 por endpoint; ajuste conforme comportamento do endpoint | Latência da cauda impactando 1–5% das requisições mais lentas |
| Taxa de Erro (4xx / 5xx) | < 0,1% para APIs em produção | Falhas de autenticação, manuseio de entrada inválida, erros de servidor |
| Tempo de Resolução DNS | < 50ms para consultas em cache na mesma região; pode ultrapassar 100ms cross-region | Problemas de propagação DNS, falhas do resolvedor |
| Tempo de Handshake TLS | < 100ms | Configuração incorreta de certificado, problemas na negociação de versão TLS |
| Taxa de Passagem em Asserções de Payload | 100% (alerta para qualquer falha) | Falhas silenciosas: respostas HTTP 200 com dados incorretos ou ausentes |
| Throughput (req/s) | Compare com baseline histórica | Quedas inesperadas de tráfego ou picos anormais |
| Expiração de Certificado (dias restantes) | Alerta a 30 dias; crítico a 7 dias | Expiração iminente do certificado TLS |
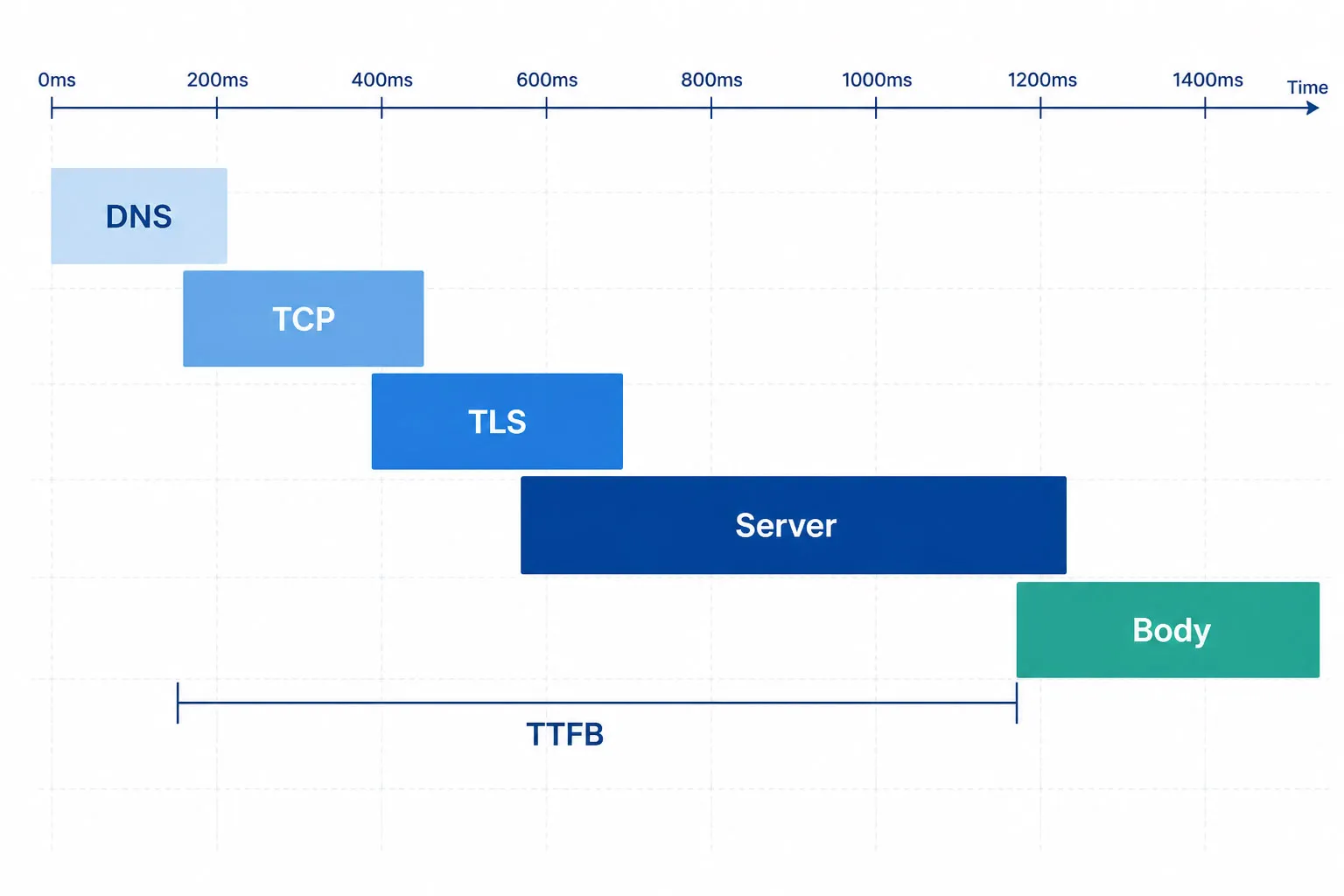
Benchmarks de Tempo de Resposta
Como Funciona o Monitoramento de API?
Compreender a mecânica técnica ajuda as equipes a configurar corretamente o monitoramento e interpretar os resultados com precisão.
O Loop Central de Monitoramento
- Agendar. Uma checagem sintética é executada em um intervalo configurado (ex: a cada 1 minuto) de um local global selecionado.
- Enviar requisição. O agente de monitoramento envia uma requisição HTTP para o endpoint alvo — incluindo o método HTTP (GET, POST, PUT, PATCH, DELETE), cabeçalhos de requisição, credenciais de autenticação e corpo da requisição.
- Medir tempos. O agente registra o tempo de resolução DNS, tempo de conexão TCP, tempo de handshake TLS, Time to First Byte (TTFB) e tempo total de resposta como componentes distintos.
- Validar. A resposta é avaliada contra asserções configuradas — código de status HTTP, limite de tempo de resposta, cabeçalhos da resposta e conteúdo do payload via JSONPath (REST) ou XPath (SOAP).
- Alertar ou passar. Se qualquer asserção falhar, ou se a requisição expirar, um incidente é criado e alertas são enviados conforme regras de notificação configuradas.
- Registrar. Todos os resultados — passados e falhados — são armazenados com timestamps, dados da resposta e resultados das asserções para análise histórica e relatórios de SLA.
Monitoramento de Transação API Multi-etapas

O monitoramento de endpoint único confirma que endpoints individuais respondem. Mas jornadas reais de usuários não são chamadas de API únicas — são sequências encadeadas onde cada etapa depende da saída da etapa anterior.
Considere um fluxo de checkout de e-commerce:
- Etapa 1 —
POST /auth/token: Autenticar usuário; extrairaccess_tokendo corpo da resposta - Etapa 2 —
GET /products/{id}: Buscar detalhes do produto; injetar token no cabeçalhoAuthorization - Etapa 3 —
POST /cart/add: Adicionar item; extraircart_idda resposta - Etapa 4 —
POST /checkout/initiate: Iniciar checkout comcart_id; extraircheckout_session_id - Etapa 5 —
POST /payments/charge: Processar pagamento; validar que o campoorder_statusna resposta seja igual a'confirmed'
No monitoramento de endpoint único, todas as cinco etapas podem passar individualmente enquanto a transação completa falha — porque os dados da sessão não são passados corretamente entre etapas, um token expira no meio do fluxo, ou a API de pagamento retorna HTTP 200 com um campo de erro no payload. O monitoramento multi-etapas executa toda a cadeia como uma única tarefa de monitoramento, valida cada etapa independentemente e passa valores dinâmicos (tokens, IDs de sessão, IDs de pedido) entre etapas automaticamente.
Dotcom-Monitor possibilita monitoramento de transações multi-etapas encadeando chamadas sequenciais de API em uma única tarefa de monitoramento. A extração e injeção de variáveis entre etapas é automática. Cada passo é validado independentemente, permitindo localizar precisamente onde a transação quebrou.
Validação de Payload: Asserções JSONPath e XPath
A validação de payload é o que separa o monitoramento de um simples ping de disponibilidade. Como as asserções são expressas depende da ferramenta, mas a lógica é consistente:
- Acesso a campos JSONPath (REST): Acessar
$.data.status— então validar que o valor retornado é'active' - Checagem de array JSONPath: Acessar
$.items— validar que o comprimento do array é maior que 0 - Asserção XPath (SOAP):
//order/status/text()— validar que o valor do nó é'confirmed' - Asserção de cabeçalho: Validar que o valor do cabeçalho
Content-Typeé'application/json' - Asserção de tempo de resposta: Validar que o tempo total de resposta está abaixo de 500ms
Monitoramento de Autenticação
APIs em produção requerem autenticação. Uma ferramenta de monitoramento deve suportar os mesmos métodos de autenticação que os clientes reais da API. Os esquemas que uma plataforma pronta para produção deve suportar:
| Método de Auth | Descrição | Notas |
|---|---|---|
| OAuth 2.0 — Client Credentials | Máquina para máquina; cliente troca credenciais por token diretamente | Mais comum para monitoramento de API servidor-servidor |
| OAuth 2.0 — Authorization Code | Autorização delegada pelo usuário; tipicamente usado com PKCE para SPAs/apps móveis | Requer que a ferramenta de monitoramento trate renovação automática do token |
| OAuth 2.0 — Resource Owner Password (ROPC) | Troca direta de usuário + senha — fluxo legado | Use somente onde Authorization Code não for viável |
| Bearer Token (JWT) | Token estático ou renovado dinamicamente no cabeçalho Authorization |
JWTs de curta duração requerem renovação automática do token |
| API Key | Chave estática no cabeçalho, parâmetro de consulta ou cookie | Mais simples para monitorar; fique atento a eventos de rotação |
| Autenticação Básica | username:password codificado em Base64 no cabeçalho Authorization |
Legado — ainda comum em APIs empresariais e internas |
| Assinatura AWS v4 | Requisição assinada HMAC usando credenciais AWS | Obrigatório para endpoints AWS API Gateway |
| mTLS / Certificado Cliente | TLS mútuo — ambos os lados apresentam certificados | Ambientes zero-trust; monitoramento de expiração de certificado crítico |
| NTLM / Kerberos | Autenticação integrada Windows/Active Directory | APIs internas empresariais; menos comum em stacks nativos de nuvem |
| Headers Customizados | Esquemas de auth proprietários via cabeçalhos personalizados de requisição | Categoria catch-all para implementações não padrão |
A expiração do token é uma das principais causas de falsos positivos no monitoramento. A duração dos tokens de acesso OAuth 2.0 varia amplamente conforme implementação e tipo de concessão. Tokens delegados ao usuário (fluxo Authorization Code) geralmente duram de 15 minutos a 1 hora. Tokens máquina a máquina (fluxo Client Credentials) costumam ter janelas maiores — 1 a 24 horas — para reduzir overhead de renovação. Ambientes de alta segurança podem impor janelas tão curtas quanto 5 minutos. Independentemente da janela, uma ferramenta de monitoramento que não trate renovação automática do token gerará falsos positivos ou exigirá rotação manual de credenciais, criando tanto overhead operacional quanto risco de indisponibilidade.
Uma nota sobre a concessão Implícita do OAuth 2.0: está depreciada nas melhores práticas atuais de segurança OAuth 2.0 (RFC 9700) e não deve ser usada em sistemas novos. Se suas APIs existentes ainda usam o fluxo Implícito, recomenda-se fortemente migrar para Authorization Code + PKCE.
Por Que Monitorar API Importa: Impacto no Negócio
APIs não são abstrações de infraestrutura — são caminhos de receita. Quando falham, as consequências são financeiras, operacionais e contratuais.
O Custo das Falhas de API Não Detectadas
Sem monitoramento proativo, as equipes dependem de relatórios dos clientes para detectar falhas. Pesquisas do setor colocam consistentemente o MTTD reportado pelo cliente muito acima de 30 minutos — até que a reclamação seja registrada, investigada, triada e escalada, esse tempo já passou. Monitoramento sintético contínuo em intervalos de 1 minuto reduz a detecção para menos de 60 segundos, permitindo isolamento da causa raiz antes que o problema se agrave.
A fórmula da receita é simples: pedidos/min × valor médio do pedido × duração da indisponibilidade em minutos. Uma plataforma processando 100 pedidos/min a $50 cada perde $25.000 em receita potencial durante 5 minutos de indisponibilidade da API de pagamento. Insira seu próprio throughput e valor médio para dimensionar sua exposição.
Cenários Específicos do Setor
- E-commerce. Falha na API de checkout durante pico de tráfego paralisa todas as conversões. Uma API de autorização de pagamento retornando HTTP 200 com status negado — mas sem alerta — bloqueia silenciosamente transações por minutos antes de ser notada.
- FinTech. APIs de processamento de transações devem atender requisitos de latência sub-segundo. Degradação persistente acima dos limites SLA pode gerar penalidades contratuais e achados de auditoria no PCI DSS.
- Saúde. APIs de integração EHR e endpoints de telemedicina devem manter troca de dados conforme HIPAA. Uma API retornando HTTP 200 com dados incompletos do paciente é um evento de conformidade — não apenas um problema de desempenho.
- SaaS / API como Produto. Quando sua API é um produto faturável, indisponibilidade gera penalidades contratuais de SLA e churn de clientes. O monitoramento fornece evidência documentada de uptime necessária para relatórios de conformidade SLA.
- TI Empresarial. Integrações API CRM, ERP e RH via departamentos. Uma degradação da API Salesforce pode quebrar silenciosamente workflows de vendas em toda a organização sem um único erro 500 nos logs.
Risco de API Terceira
Aplicações modernas dependem de APIs externas que não controlam: gateways de pagamento (Stripe, PayPal, Braintree), provedores de identidade (Okta, Auth0, AWS Cognito), APIs de envio e sistemas CRM. Quando elas se degradam, seu app parece quebrado para os usuários mesmo que sua infraestrutura esteja saudável.
Monitorar endpoints terceiros permite que equipes isolem imediatamente se a falha é interna ou externa — distinção que pode demandar investigação significativa sem dados prévios de monitoramento. Também fornece evidências documentadas para responsabilizar fornecedores sobre seus SLAs publicados.
Pare de descobrir falhas de API pelos seus clientes.
O monitoramento sintético de API da Dotcom-Monitor detecta falhas em menos de 60 segundos e envia alertas diretamente para PagerDuty, Slack ou Microsoft Teams. Monitore gateways de pagamento, provedores de identidade e APIs internas de uma só plataforma.
Monitoramento de API vs. Teste de API
Ambas as práticas validam o comportamento da API, mas servem a propósitos diferentes no ciclo de vida de entrega de software. Confundi-las gera lacunas de cobertura.
| Dimensão | Teste de API | Monitoramento de API |
|---|---|---|
| Quando | Pré-deployment — desenvolvimento, QA, pipeline CI/CD | Pós-deployment — continuamente em produção |
| Ambiente | Desenvolvimento, staging, ambiente de teste controlado | Produção ao vivo, infraestrutura real, tráfego real |
| Disparo | Commit de código, build, execução manual, gate PR | Agendado (ex: a cada 1 minuto), contínuo 24/7 |
| Objetivo | Evitar que bugs cheguem à produção | Detectar falhas e degradação em produção |
| Cobertura | Todos os comportamentos, casos extremos, caminhos de erro | Fluxos críticos, endpoints SLA, cadeias de jornada do usuário |
| Perspectiva | De dentro para fora: testa o comportamento do código | De fora para dentro: valida do ponto de vista do usuário |
| Resultado | Relatório de aprovação/erro; bloqueia deploy se falha | Alertas em tempo real, registros de uptime SLA, histórico de incidentes |
A relação prática: teste de API é uma atividade de fase de desenvolvimento. Monitoramento de API é uma atividade operacional. Teste captura bugs antes do deployment; monitoramento captura falhas, regressões, degradação de desempenho e problemas de dependência após o deployment — sob condições reais de infraestrutura que diferem dos ambientes controlados de teste.
Uma equipe madura executa ambos — e usa imports de coleções Postman para conectar os dois, convertendo testes de desenvolvimento em monitores de produção sem duplicar definições de requisição.
Monitoramento de API vs. APM
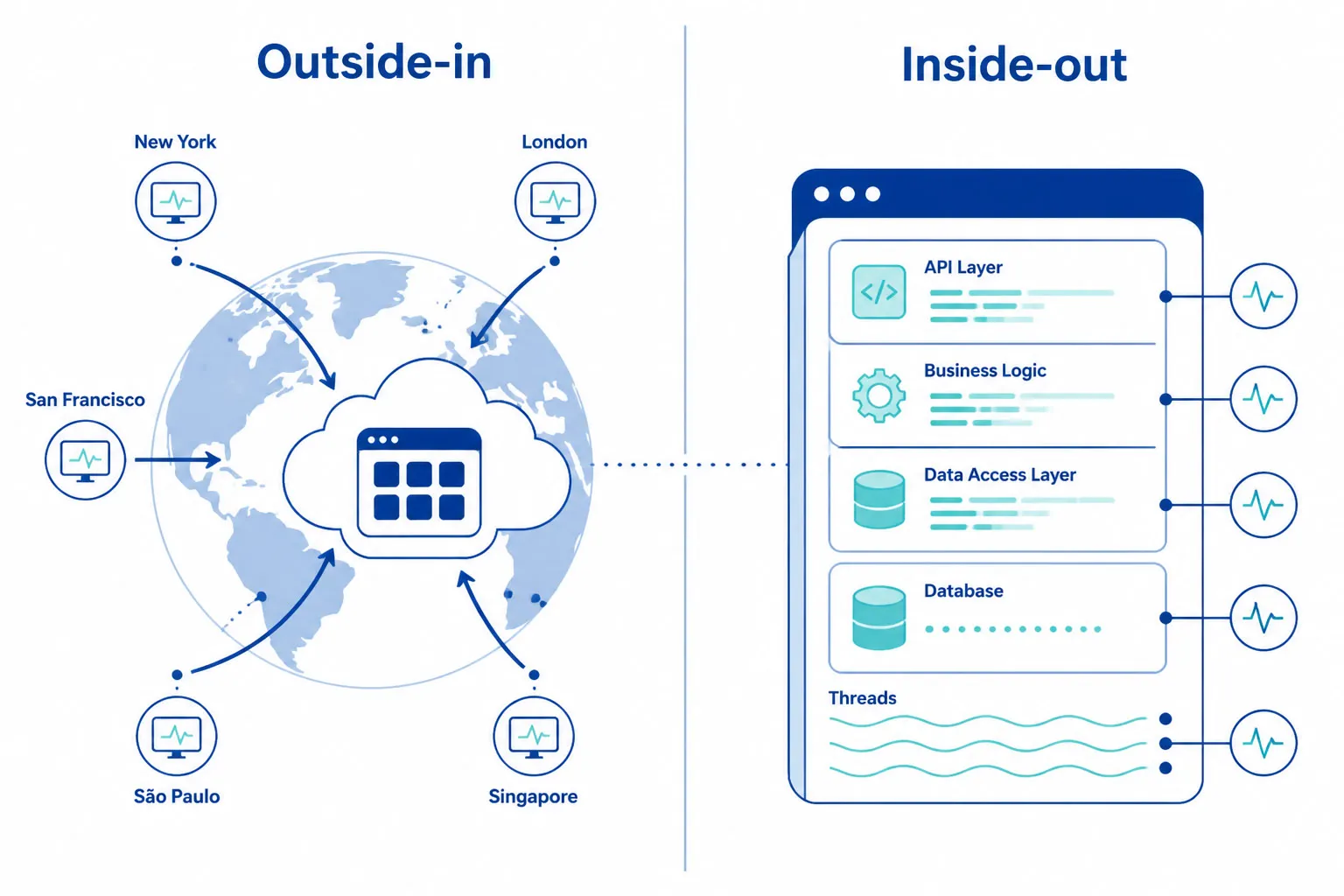
Essas duas categorias são frequentemente confundidas. São complementares, não intercambiáveis.
| Monitoramento Sintético de API | APM (Application Performance Monitoring) | |
|---|---|---|
| Perspectiva | De fora para dentro — valida do mesmo ponto de vista que usuários e parceiros | De dentro para fora — observa comportamento interno da aplicação |
| O Que Vê | Falhas DNS, problemas de roteamento de rede, erros TLS, mau roteamento CDN, lacunas geográficas | Consultas lentas ao BD, vazamentos de memória, exceções de código, chamadas lentas de funções |
| Quando Executa | 24/7 — mesmo em períodos de zero tráfego | Somente durante processamentos reais de requisições |
| Questão Respondida | “Nossos clientes realmente conseguem chamar esta API agora?” | “O que está acontecendo dentro da nossa aplicação quando uma requisição chega?” |
Equipes com menor MTTR usam ambos: APM para análise interna da causa raiz, monitoramento sintético para validação externa. Logs e traces respondem “o que deu errado no código?” Monitoramento sintético responde “meus clientes podem usar esta API agora?”
Protocolos de API: REST, SOAP, GraphQL, gRPC e WebSocket
Cada protocolo de API tem requisitos e modos de falha distintos. Uma ferramenta que trate todas as APIs como simples requisições HTTP GET perderá problemas específicos do protocolo.
Monitoramento de API REST
REST é o protocolo dominante de API. O monitoramento valida métodos HTTP (GET, POST, PUT, PATCH, DELETE), códigos de status, cabeçalhos da resposta e corpos JSON via asserções JSONPath. Requisitos chave: validar valores de campos do payload — não apenas códigos de status; monitorar todos os métodos HTTP, não só GET (POST, PUT e DELETE disparam lógicas e modos de falha diferentes no servidor); acompanhar tempo de resposta por endpoint individualmente, não como médias agregadas entre endpoints.
Monitoramento de API SOAP
APIs SOAP trocam XML sobre HTTP. Requisitos de monitoramento: importação de WSDL para definição de endpoint e schema; asserções XPath em elementos de resposta XML; suporte a protocol SOAP 1.1 e 1.2; configuração WS-Security para serviços SOAP empresariais com segurança a nível de mensagem.
Monitoramento de API GraphQL
O desafio principal no monitoramento GraphQL: a maioria das implementações de servidores GraphQL retorna HTTP 200 mesmo para erros parciais ou queries malformadas. O código HTTP não é um sinal confiável de falha. Você deve:
- Enviar payloads de query específicas e validar o objeto
datada resposta - Checar o array
errorsno corpo da resposta — em GraphQL padrão, toda resposta pode ter um campoerrorsde topo que fica vazio ou ausente no sucesso e populado na falha. Um 200 comerrors[]preenchido significa que a requisição falhou na camada GraphQL embora HTTP tenha sido bem-sucedido - Validar invariantes de dados específicas da query: validar que campos esperados estão presentes, não são nulos e têm o tipo correto no objeto data — alguns sistemas codificam falhas de domínio dentro do objeto data em vez de preencher o array de erros de topo
- Monitorar limites de complexidade e profundidade da query para detectar degradação de performance antes que cause timeouts
Monitoramento de API gRPC
gRPC usa Protocol Buffers sobre HTTP/2 por padrão, embora gRPC-Web suporte HTTP/1.1 via proxy para clientes browser. Requisitos de monitoramento: importação de arquivo proto para definições de serviço e método; suporte a codificação/decodificação binária para mensagens Protocol Buffer; validação de código de status usando códigos gRPC (OK, UNAVAILABLE, DEADLINE_EXCEEDED, etc) — não códigos HTTP; suporte para RPC Unário, Streaming do Servidor, Streaming do Cliente e Bidirecional.
Monitoramento de API WebSocket
APIs WebSocket mantêm conexões bidirecionais persistentes para dados em tempo real. O monitoramento valida tempo de estabelecimento da conexão e sucesso no handshake WebSocket, latência de entrega de mensagens e correção do payload, e estabilidade da conexão ao longo do tempo, incluindo comportamento de reconexão após quedas.
Monitoramento de API Pública vs. Monitoramento de API Interna

A maioria dos guias de monitoramento de API foca exclusivamente em endpoints públicos. Mas em arquiteturas de microserviços, a maioria das chamadas críticas de API são internas — chamadas serviço a serviço que nunca chegam à internet pública.
| Monitoramento de API Pública | Monitoramento de API Interna | |
|---|---|---|
| O Que Cobre | Endpoints para clientes, APIs de parceiros, integrações terceiras | Microserviços internos, VPCs privadas, ambientes de staging, APIs atrás de firewall |
| Como Funciona | Agentes externos executam checagens de locais globais pela internet pública | Um Private Agent implantado dentro da rede inicia conexões de saída para a plataforma |
| Requisitos de Firewall | Nenhum — checagens iniciam externamente | Sem regras de entrada — agente inicia apenas conexões de saída |
| O Que Detecta | Falhas de resolução DNS, problemas de roteamento CDN, erros TLS, lacunas de disponibilidade geográfica | Falhas entre serviços, latência na autenticação por microserviço, degradação de API de consultas a banco |
| Implantação | Sem instalação — funciona imediatamente | Agente instalado on-premises ou em nuvem privada (suporta Windows e Linux) |
APIs internas de microserviços são a fonte mais comum de falhas em cascata. Um serviço de autenticação degradado ou uma API lenta de acesso a dados causam problemas a jusante que aparecem como falhas no frontend — tornando difícil localizar a causa raiz sem visibilidade interna. Monitorar APIs internas permite às equipes isolar se a falha está na camada API, no microserviço a jusante ou no banco de dados. Saiba mais sobre Monitoramento Private Agent atrás do seu firewall.
Melhores Práticas de Monitoramento de API
Essas práticas reduzem o tempo médio para detecção (MTTD), melhoram a precisão dos alertas e garantem que a cobertura do monitoramento combine com o risco em produção.
- Monitore em intervalos de 1 minuto para endpoints críticos de receita. Para APIs de pagamento, autenticação e dados centrais, cada minuto não detectado tem impacto direto no negócio. Intervalos de 5 ou 15 minutos são aceitáveis para endpoints de menor criticidade.
- Execute checagens de pelo menos 5 locais geograficamente distribuídos. Um único local de monitoramento não detecta falhas DNS regionais, más configurações CDN ou problemas de roteamento geo-específicos. No mínimo, cubra América do Norte, Europa e Ásia-Pacífico.
- Valide o conteúdo do payload, não apenas códigos de status. Configure asserções JSONPath para cada endpoint crítico. As falhas silenciosas mais caras são APIs retornando HTTP 200 com dados incompletos, desatualizados ou malformados.
- Use limiares de alerta derivados de baseline, não valores estáticos em milissegundos. Estabeleça uma baseline de tempo de resposta por endpoint e configure alertas em 2× o valor P95. Limiares estáticos geram falsos positivos durante picos normais de tráfego.
- Inclua autenticação nas suas cadeias de monitoramento. Expiração de token, falhas na renovação OAuth, rotação de certificados são causas principais de indisponibilidade da API. Monitorar etapas de auth captura falhas relacionadas às credenciais antes que propaguem.
- Construa monitores de transações multi-etapas para cada jornada crítica do usuário. Fluxos de login, sequências de checkout e workflows de submissão de dados são chamadas encadeadas. Monitores de endpoint único não capturam falhas entre etapas causadas por passagem incorreta de dados ou gerenciamento de sessão.
- Monitore dependências de API terceiras como monitores separados. Crie monitores dedicados para Stripe, Okta, Salesforce e outras dependências externas. Isso responde imediatamente se uma falha é interna ou externa.
- Importe coleções Postman ou Insomnia para acelerar o monitoramento. Converta definições de API existentes em monitores de produção contínuos 24/7 sem recriar estruturas de requisição. Isso elimina a lacuna entre teste em desenvolvimento e monitoramento em produção.
- Integre checagens pós-deployment em pipelines CI/CD. Execute checagens sintéticas de API como testes automatizados após cada deployment. Se falharem, considere acionar rollback automático ou suspensão de tráfego em setups de entrega progressiva (blue/green ou canary) — usando execuções de confirmação de um segundo local para reduzir falsos positivos antes de qualquer ação automática.
- Envie alertas para PagerDuty, Slack ou Microsoft Teams com políticas de escalonamento. Alertas somente por email criam atraso na detecção. Integrações nativas com ferramentas de gestão de incidentes garantem que alertas cheguem à pessoa certa imediatamente, com caminhos de escalonamento definidos para falta de resposta.
Desafios do Monitoramento de API
Mesmo configurações bem planejadas enfrentam desafios operacionais. Antecipá-los ajuda na criação de soluções eficazes.
Visibilidade de APIs Terceiras
Monitorar dependências externas fornece dados de disponibilidade e latência, mas não expõe a causa interna da degradação. Quando Stripe ou Okta desaceleram, você pode confirmar e isolar o raio de impacto — porém a análise de causa raiz depende de páginas de status do fornecedor e caminhos de escalonamento do suporte.
Limitação de Taxa
Agentes de monitoramento contam para os limites de taxa da sua API. O volume total de requisições sintéticas escala como: locais × checagens por hora × chamadas de API por execução do monitor × tentativas de confirmação. Para um monitor de endpoint único: 30 locais × 60 checagens/hora = 1.800 requisições/hora. Para um monitor de transação de 5 etapas com as mesmas configurações: 30 × 60 × 5 = 9.000 requisições/hora por monitor. Considere isso no orçamento do limite de taxa, especialmente para APIs internas com limites mais apertados. Certifique-se de que as faixas de IP do seu provedor de monitoramento estejam na whitelist onde necessário.
Complexidade de Autenticação
APIs com tokens de curta duração requerem ferramentas que tratem renovação automática de token. Tokens delegados do usuário OAuth 2.0 (fluxo Authorization Code) tipicamente expiram em 15 min a 1 hora; tokens máquina a máquina Client Credentials duram de 1 a 24 horas; ambientes de alta segurança podem impor 5 minutos. Autenticação baseada em certificado e rotação de API keys também demandam gestão cuidadosa de credenciais.
Respostas Dinâmicas e Não Determinísticas
APIs que retornam dados com timestamp, resultados paginados ou arrays com ordem aleatória são difíceis de validar com correspondência de valor exato. Use expressões JSONPath que validem estrutura, presença de campo e tipos, ao invés de valores exatos que mudam a cada requisição.
Fadiga de Alertas
Monitoramento excessivo — muitos endpoints a cada 1 minuto, ou limiares programados muito apertados — gera ruído que dessensibiliza equipes a alertas verdadeiros. Use monitoramento em níveis: 1 minuto para fluxos críticos, 5–15 minutos para endpoints não críticos. Confirme alertas de um local secundário antes de enviar notificações para eliminar falsos positivos transitórios.
Diversidade de Protocolos
REST, SOAP, GraphQL, gRPC e WebSocket exigem estratégias de asserção diferentes. Uma ferramenta que só suporte REST perderá falhas de serviços SOAP e reportará erros GraphQL incorretamente como sucesso, pois retornam HTTP 200.
Como Configurar Monitoramento de API com Dotcom-Monitor
Dotcom-Monitor oferece monitoramento sintético de API para REST, SOAP e GraphQL de mais de 30 locais globais, com intervalos de checagem de 1 minuto, suporte a transações multi-etapas e integrações nativas com PagerDuty, Slack e Microsoft Teams.
Passo 1 — Defina Seu Endpoint e Asserções
- URL do endpoint: O endpoint da API a ser monitorado
- Método HTTP: GET, POST, PUT, PATCH ou DELETE
- Cabeçalhos da requisição:
Content-Type,Authorizatione quaisquer cabeçalhos customizados necessários - Corpo da requisição: Payload JSON para requisições POST/PUT
- Autenticação: OAuth 2.0, Bearer Token, API Key, Basic Auth, mTLS, Assinatura AWS v4, NTLM, Kerberos ou cabeçalhos customizados
- Asserções: Código de status HTTP, limite de tempo de resposta, valores de cabeçalhos, asserções JSONPath/XPath no payload
Passo 2 — Importe de Postman ou Insomnia
Se sua equipe usa Postman ou Insomnia, pule a configuração manual de endpoint:
- Postman: Exporte sua Coleção em JSON v2.0 ou v2.1 e importe para o Dotcom-Monitor. Definições de requisição, cabeçalhos, corpo, variáveis de ambiente e asserções de teste são preservadas.
- Insomnia: Exporte seu workspace como JSON Insomnia v4 e importe para o Dotcom-Monitor. Grupos de requisição, configurações de auth e variáveis de ambiente são mantidas.
Ambos os formatos de importação convertem testes pontuais de desenvolvimento em monitores contínuos de produção 24/7 sem precisar reconfigurar.
Já usa Postman? Está a 5 minutos de monitoramento 24/7 em produção.
Importe sua Coleção Postman existente diretamente no Dotcom-Monitor. Suas definições de requisição, cabeçalhos, variáveis de ambiente e asserções são preservadas — sem necessidade de reconfiguração.
Passo 3 — Configure Locais de Monitoramento e Frequência
- Frequência de checagem: Intervalos de 1, 3, 5 ou 15 minutos — defina por endpoint conforme criticidade
- Locais de monitoramento: Escolha entre 30+ locais na América do Norte, Europa, Ásia-Pacífico e América do Sul
- Private Agent: Para APIs internas ou atrás de firewall — implante o agente on-premises ou em nuvem privada (suporta Windows e Linux). Agente inicia apenas conexões de saída — nenhuma regra de firewall de entrada necessária.
- Tentativas de confirmação: Configure uma checagem de confirmação de um local secundário antes de disparar alertas, para eliminar falsos positivos transitórios de rede
Passo 4 — Configure Encaminhamento de Alertas
- PagerDuty: Envie alertas críticos diretamente para escalas de plantão com criação e escalonamento automático de incidentes
- Slack / Microsoft Teams: Publique mensagens de alerta com detalhes do endpoint, tipo de erro e dados da resposta para canais de operações
- Email, SMS, Chamada telefônica: Configure preferências de notificação por contato ou equipe
- Webhook: Integre com OpsGenie, ServiceNow ou qualquer serviço HTTP compatível
- Configuração de limiares: Defina condições de alerta por métrica — tempo de resposta, taxa de erro, taxa de falha dasserções — com níveis de severidade
Passo 5 — Integração com Pipeline CI/CD
- REST API Dotcom-Monitor: Crie, atualize e dispare tarefas de monitoramento programaticamente via chamadas HTTP API de qualquer sistema CI/CD
- GitHub Actions / Azure DevOps / Jenkins: Adicione um passo pós-deployment que dispare uma checagem Dotcom-Monitor, aguarde resultados e falhe a pipeline se alguma asserção falhar
- Validação pré-produção: Execute as mesmas checagens sintéticas contra seu ambiente de staging antes de promover builds para produção — capture regressões antes que impactos atinjam usuários
Casos de Uso de Monitoramento de API por Indústria
| Indústria | APIs Críticas Para Monitorar | Requisitos Chave de Monitoramento |
|---|---|---|
| E-commerce | Checkout, autorização de pagamento, inventário, envio, gerenciamento de carrinho | Transações multi-etapas; intervalos de 1 minuto; asserção de payload no status de confirmação de pagamento |
| FinTech / Bancos | Processamento de transações, verificação KYC/AML, saldo de conta, taxas FX, APIs de transferência bancária | SLAs de latência abaixo de 200ms; verificações de conformidade para evidências PCI DSS; validação completa do fluxo de autenticação |
| Saúde | Integrações EHR (HL7 FHIR), portais de seguro, endpoints de telemedicina, agendamento de pacientes | Verificações de conformidade para evidências HIPAA; validação de payload para completude dos dados; SLA de uptime de 99,99% |
| SaaS | APIs do produto central, endpoints de entrega de webhook, APIs de integração de parceiros, APIs de autenticação | Atendimento a SLA API como Produto; importação Postman para consistência dev-monitor; monitoramento de dependências terceiras |
| TI Empresarial | APIs CRM, ERP, RHIS, provedores de identidade, automação de workflows internos | Private Agent para APIs atrás do firewall; suporte a autenticação NTLM/Kerberos; visibilidade de API entre departamentos |
| Mídia / Gaming | APIs de entrega CDN, autenticação, pontuação em tempo real, APIs de recursos sociais | Monitoramento geográfico; monitoramento de conexão WebSocket; detecção de picos de tráfego |
Comece a monitorar suas APIs hoje.
Dotcom-Monitor oferece monitoramento sintético de API de mais de 30 locais globais, com intervalos de checagem de 1 minuto, suporte a transações multi-etapas e integrações nativas com PagerDuty, Slack e Microsoft Teams. A configuração leva menos de 5 minutos. Não é necessário cartão de crédito para o teste de 30 dias.
