
Votre pager sonne à 2 heures du matin. La charge utile de l’alerte contient un code de statut. Ce que vous faites ensuite dépend presque entièrement du code que vous voyez.
C’est la partie que la plupart des guides de codes de statut HTTP omettent. Ils listent les définitions, classent les codes en cinq groupes, et s’arrêtent là. Utile comme glossaire, moins utile quand un vrai endpoint lance des 502 et qu’un dirigeant demande pourquoi le paiement est cassé.
Ce guide couvre les dix mêmes codes que vous verrez le plus souvent, plus quelques mentions honorables. Pour chacun : ce que cela signifie, ce qui le déclenche habituellement en production, et ce qu’il faut vérifier en premier. Le but est de raccourcir le temps entre « Je vois le code » et « Je sais quoi réparer. »
Qu’est-ce qu’un code de statut HTTP ?
Un code de statut HTTP est un nombre à trois chiffres que le serveur renvoie avec chaque réponse. Il indique au client si la requête a réussi, échoué, ou doit être redirigée. Vous les voyez partout : dans l’onglet Réseau des outils de développement de votre navigateur, dans les journaux du répartiteur de charge, dans les alertes de surveillance, dans les tableaux de bord CDN. Ce guide se concentre sur ceux qui réveillent vraiment les gens.
Les cinq catégories de codes de statut HTTP
Le premier chiffre du code indique la classe de réponse :
- 1xx Informationnel. Rare dans le travail quotidien. Principalement utilisé pour la négociation de protocole (100 Continue, 101 Switching Protocols pour les mises à niveau WebSocket).
- 2xx Succès. La requête a fonctionné. 200 est la valeur par défaut ; 201 signifie qu’une ressource a été créée ; 204 signifie succès sans contenu.
- 3xx Redirection. La ressource se trouve ailleurs. Les navigateurs et les moteurs de recherche suivent ces codes automatiquement jusqu’à une limite.
- 4xx Erreur client. La requête était erronée. URL incorrecte, auth manquante, permissions bloquées, charge utile mal formée.
- 5xx Erreur serveur. La requête était correcte. Le serveur a échoué à la traiter.
La distinction entre 4xx et 5xx est la plus importante pour le triage. Un 4xx signifie « c’est l’appelant qui a fait une erreur ». Un 5xx signifie « nous avons fait une erreur ». Le premier est renvoyé à celui qui a appelé le point de terminaison. Le second vous est adressé.
Pour une énumération complète, la référence complète des codes de statut HTTP dans le wiki Dotcom-Monitor liste tous les codes définis par la spécification. Le reste de ce guide se concentre sur ceux qui apparaissent réellement dans les alertes.
Les dix codes de statut HTTP les plus courants
200 OK
Le serveur a traité la requête et a renvoyé la réponse attendueréponse. C’est le code que vous souhaitez voir dans la grande majorité des requêtes vers un site de production sain.
Attention à : un 200 OK n’est pas la preuve que la page est correcte. JavaScript peut échouer silencieusement et afficher une page blanche. Une API peut renvoyer un 200 avec un corps d’erreur. Un formulaire de connexion peut afficher « identifiants invalides » dans une réponse 200. Les vérifications basées uniquement sur le code d’état manquent ces cas. Associez-les à des contrôles en navigateur réel (plus d’informations ci-dessous).
301 Moved Permanently
La ressource a une nouvelle URL permanente. Les navigateurs mettent en cache la redirection de manière agressive. Les moteurs de recherche transfèrent la plupart de l’équité des liens vers la cible.
Utilisez-le pour : les modifications d’URL après une migration de site, le passage de HTTP à HTTPS, la consolidation de chemins en double, la suppression d’anciens slugs. Une fois qu’un 301 est en place et mis en cache, revenir en arrière est compliqué — navigateurs et moteurs de recherche continueront d’aller à la nouvelle adresse pendant des semaines.
302 Found (Temporary Redirect)
La ressource est temporairement ailleurs. Les navigateurs ne mettent pas en cache la redirection et les moteurs de recherche ne transmettent pas l’équité complète des liens.
Attention à : le 302 est trop utilisé. Les équipes l’utilisent parce que l’assistant de redirection par défaut du framework renvoie un 302. Si le déplacement est permanent, utilisez 301. Si vous devez conserver la méthode HTTP (POST reste POST), utilisez plutôt 307 ou 308. Google finira par traiter les 302 persistants comme des 301, mais « finir par » n’est pas une stratégie.
400 Bad Request
Le serveur ne peut pas analyser la requête. JSON mal formé, en-têtes invalides, charge utile trop volumineuse, violations de schéma.
Vérifiez d’abord : le corps de la requête. Une explosion des 400 sur un point d’API indique généralement qu’un client a commencé à envoyer une forme incorrecte — un déploiement côté client, un changement de schéma de votre côté, ou une intégration tierce ayant mis à jour leur format. Comparez la charge de la requête avec votre dernière version fonctionnelle connue.
401 Unauthorized
La requête n’a pas de justificatifs, ou des justificatifs qui ont été rejetés. Le nom est trompeur — le problème est l’authentification, pas l’autorisation.
Vérifiez d’abord : les jetons. Une montée soudaine de 401 sur des points qui fonctionnaient auparavant signifie souvent qu’un jeton a expiré, une clé de signature a été tournée, un fournisseur OIDC a eu une panne, ou quelqu’un a changé la revendication d’audience. Si votre surveillance de la disponibilité API montre des 401 là où il y avait des 200, la couche d’auth est généralement en cause.
403 Forbidden
Les justificatifs sont valides, mais l’appelant n’a pas le droit d’accéder à cette ressource. Le problème est l’autorisation, pas l’authentification.
Vérifiez d’abord : les permissions et règles d’infrastructure. Des 403 apparaissent quand une politique IAM change, une règle WAF commence à bloquer du trafic légitime, une politique d’accès CDN devient trop stricte, ou un flag de fonctionnalité est activé pour le mauvais segment d’utilisateurs. Si les 403 ont commencé juste après un déploiement, examinez les différences de politiques et de configuration avant le code applicatif.
404 Not Found
Le serveur a compris la requête mais ne dispose d’aucune ressource à thà l’URL. Le code d’état le plus célèbre qui existe.
Deux scénarios à différencier :
- 404 ponctuels dus à des fautes de frappe, anciens favoris ou robots explorant des vulnérabilités. Ce sont des bruits de fond.
- Une rafale de 404 sur des URLs canoniques juste après un déploiement. C’est une version cassée — des routes ont été supprimées, un artefact de build est manquant, ou quelqu’un a déployé un changement de slug sans redirections. Revenir en arrière ou pousser un hotfix.
Les 404 persistants sur des pages indexées finiront par être désindexés par Google, donc les pages canoniques qui renvoient un 404 ont aussi un coût SEO.
Correction
Solution rapide : si la page a été déplacée, ajoutez une redirection 301 de l’ancienne URL vers la nouvelle pour que les utilisateurs et les robots arrivent au bon endroit. Si la page a vraiment disparu, renvoyez un vrai 404 ou 410 plutôt qu’une redirection vague vers la page d’accueil.
Correction réelle : auditez la source des 404. Les liens internes cassés sont corrigés à la source ; les routes manquantes après un déploiement nécessitent un hotfix ; une mauvaise migration qui a supprimé des slugs requiert une carte de redirection. Parcourez votre propre site régulièrement pour détecter les liens morts avant Google.
500 Internal Server Error
Le serveur a rencontré une exception non gérée. Le 5xx attrape-tout. Il vous dit que quelque chose a cassé mais pas quoi.
Vérifiez d’abord : les logs de l’application. Chaque 500 a une trace de pile quelque part — s’il n’y en a pas, votre journalisation doit être améliorée avant votre code. Déclencheurs courants : une exception non capturée dans un chemin de code récemment déployé, une dépendance en aval retournant une forme inattendue, un pool de connexions à la base de données épuisé, une boucle de redémarrage par manque de mémoire. Une montée en flèche soutenue des 500 sur un endpoint de production doit alerter l’équipe de garde.
Correction
Solution rapide : si la montée a commencé juste après une publication, revenez en arrière. Un 500 qui apparaît dans les minutes suivant un déploiement est ce déploiement jusqu’à preuve du contraire.
Correction réelle : lisez la trace de pile et corrigez le chemin de code défaillant, puis ajoutez un test de régression pour éviter que cela ne revienne. Si le déclencheur était un plafond de ressources — pool de connexions, mémoire, descripteurs de fichiers — augmentez la limite et ajoutez une alerte avant que cela ne se reproduise.
502 Bad Gateway
Un proxy, load balancer ou CDN a reçu une réponse invalide du serveur en amont. Le proxy lui-même est sain. Ce qu’il y a derrière ne l’est pas.
Vérifiez d’abord : la santé de l’amont. Déclencheurs courants : un conteneur d’application a planté et le load balancer continue à y router, l’amont dépasse le temps imparti sans répondre, un pod Kubernetes est en CrashLoopBackOff, un worker Nginx est mal configuré, ou la connexion entre le proxy et l’amont a été réinitialisée. Le 502 est un des codes les plus significatifs pour les architectures en couches — il indique que la périphérie est correcte et que le problème est une étape en amont.
Correction
Solution rapide : redémarrez ou remplacez l’instance amont défaillante et confirmez que les vérifications de santé du load balancer retirent effectivement les nœuds morts de la rotation.
Real fix : trouvez pourquoi l’upstream a retourné des données corrompues. Vérifiez si le timeout du proxy est plus court que le temps de réponse réel de l’upstream, si le pod est en boucle de plantage au démarrage, et si les paramètres keep-alive correspondent des deux côtés de la connexion.
503 Service Unavailable
Le serveur est temporairement incapable de traiter la requête. Capacité épuisée, mode maintenance, autoscaler encore en train de se lancer.
Vérifiez d’abord : saturation des ressources et limites de taux. Les 503 lors d’un pic de trafic signifient généralement que l’autoscaler ne peut pas suivre ou que vous avez atteint une limite de connexion. Les 503 en état stable signifient généralement qu’un processus est en mode maintenance ou qu’une file d’attente est saturée. Certaines plateformes renvoient aussi un 503 lorsqu’un WAF ou système anti-bot en amont limite le taux d’un appelant—il vaut mieux vérifier avant de supposer que l’application est en cause.
Correction
Solution rapide : renvoyez le 503 avec un en-tête Retry-After afin que les clients bienveillants et les crawlers se retirent au lieu de surcharger un serveur en difficulté. En PHP :
http_response_code(503);
header('Retry-After: 60');Correction réelle : trouvez la ressource saturée—connexions à la base de données, pool de workers, plafond d’autoscaler—et supprimez le goulot d’étranglement. Si le 503 vient d’une limite de taux CDN ou WAF, relevez la limite ou mettez sur liste blanche l’appelant légitime.
Autres codes à connaître
Les dix codes précédents couvrent la majorité du trafic en production. Mais quelques autres apparaissent assez souvent dans des incidents réels pour que les ingénieurs en astreinte devraient les reconnaître au premier coup d’œil.
- 304 Not Modified. Envoyé lorsqu’une ressource mise en cache est toujours fraîche. Courant dans le trafic derrière un CDN. Une baisse des 304 peut signifier que vos en-têtes cache-control ont changé et que vous payez désormais la bande passante d’origine que vous économisiez auparavant.
- 307 Temporary Redirect. Comme le 302, mais conserve la méthode HTTP. Un POST reste un POST. Utilisez le 307 au lieu du 302 pour rediriger des soumissions de formulaires ou des appels API non idempotents.
- 308 Permanent Redirect. Comme le 301, mais conserve la méthode HTTP. Le choix moderne pour rediriger de manière permanente des points d’API qui utilisent POST, PUT, PATCH ou DELETE.
- 429 Too Many Requests. Limite de taux atteinte. Vous êtes soit limité par une API en amont, soit vous limitez quelqu’un d’autre vous-même. Vérifiez les en-têtes
Retry-After; respectez-les. - 504 Gateway Timeout. Un proxy a abandonné l’attente de l’upstream. Différent du 502 car l’upstream n’a pas retourné une mauvaise réponse—il n’a retourné aucune réponse dans les temps. Souvent une requête longue, un worker bloqué ou une API aval lente.
301 vs 302 vs 307 vs 308
Les quatre codes de redirection sont souvent confondus. La différence repose sur deux critères : si la redirection est permanente, et si la méthode HTTP est conservée lors de la redirection.
| Comportement | 301 | 302 | 307 | 308 |
|---|---|---|---|---|
| Permanence | Permanent | Temporaire | Temporaire | Permanente |
| Méthode conservée | Non garantie | Non garantie | Oui | Oui |
| Mis en cache par les navigateurs | Aggressivement | Non | Non | Oui |
| Equité des liens transférée | La plupart | Limitée | Limitée | La plupart |
| Utiliser quand | Déplacement permanent de l’URL | Changement de courte durée | Redirection de formulaire ou POST | Point d’accès API déplacé définitivement |
Pour une page simple déplacée définitivement, utilisez 301. Lorsque la redirection doit garder un POST en tant que POST — une soumission de formulaire ou un appel API non idempotent — utilisez 307 si le déplacement est temporaire ou 308 s’il est permanent.
La référence complète des codes d’état HTTP
Les codes ci-dessus couvrent presque tout ce qui déclenche une alerte réelle. Pour les plus rares — les codes qui apparaissent une fois par trimestre et vous obligent à chercher — voici la liste complète standard, plus les codes non standard que vous verrez chez les fournisseurs d’infrastructure courants.
1xx Informationnel
Le serveur a reçu la requête et continue de la traiter. Vous verrez rarement ces codes dans les journaux d’application car la plupart des clients et proxies les gèrent de manière transparente.
| Code | Signification |
|---|---|
| 100 | Continue |
| 101 | Changement de protocole |
| 102 | En traitement |
| 103 | Indices précoces |
2xx Succès
La requête a été reçue, comprise et acceptée. 200 est la valeur de référence ; les autres importent lorsque vous construisez des API ou travaillez avec des contenus partiels, WebDAV ou des opérations par lots.
| Code | Signification |
|---|---|
| 200 | OK |
| 201 | Créé |
| 202 | Accepté |
| 203 | Information non autoritaire |
| 204 | Pas de contenu |
| 205 | Réinitialiser le contenu |
| 206 | Contenu partiel |
| 207 | Multi-Statut |
| 208 | Déjà rapporté |
| 226 | IM utilisé |
3xx Redirection
La ressource se trouve ailleurs, ou la copie mise en cache est toujours valide. 301 et 302 dominent ; les autres sont importants pour les API (307/308 conservent la méthode HTTP) et les pipelines de mise en cache (304 économise la bande passante d’origine).
| Code | Signification |
|---|---|
| 300 | Choix multiples | 301 | Déplacé de façon permanente |
| 302 | Trouvé |
| 303 | Voir autre |
| 304 | Non modifié |
| 305 | Utiliser un proxy (obsolète) |
| 306 | Changer de proxy (non utilisé) |
| 307 | Redirection temporaire |
| 308 | Redirection permanente |
Erreurs 4xx Client
La requête était incorrecte. La plupart de celles-ci, vous ne les verrez jamais ; une demi-douzaine de codes courants apparaissent quotidiennement. Il vaut la peine de savoir que les rares existent pour ne pas perdre de temps à deviner lorsqu’un 418 ou 451 apparaît dans un journal.
| Code | Signification |
|---|---|
| 400 | Mauvaise requête |
| 401 | Non autorisé |
| 402 | Paiement requis |
| 403 | Interdit |
| 404 | Non trouvé |
| 405 | Méthode non autorisée |
| 406 | Non acceptable |
| 407 | Authentification proxy requise |
| 408 | Délai de la requête dépassé |
| 409 | Conflit |
| 410 | Parti |
| 411 | Longueur requise |
| 412 | Précondition échouée |
| 413 | Charge utile trop grande |
| 414 | URI trop longue |
| 415 | Type de média non supporté |
| 416 | Plage non satisfaisante |
| 417 | Attente échouée |
| 418 | Je suis une théière |
| 421 | Requête mal dirigée |
| 422 | Contenu non traitable |
| 423 | Verrouillé |
| 424 | Dépendance échouée |
| 425 | Trop tôt |
| 426 | Mise à niveau requise |
| 428 | Précondition requise |
| 429 | Trop de requêtes |
| 431 | Champs d’en-tête de requête trop volumineux |
| 451 | Indisponible pour des raisons légales |
Erreurs 5xx Serveur
La requête était correcte. Quelque chose a échoué côté serveur. Ce sont les codes les plus susceptibles de réveiller quelqu’un.
| Code | Signification |
|---|---|
| 500 | Erreur interne du serveur |
| 501 | Non implémenté |
| 502 | Mauvaise passerelle |
| 503 | Service indisponible |
| 504 | Délai d’attente de la passerelle dépassé |
| 505 | Version HTTP non supportée |
| 506 | Variante Aaussi Négocie |
| 507 | Stockage insuffisant |
| 508 | Boucle détectée |
| 510 | Non étendu |
| 511 | Authentification réseau requise |
Codes non standard et codes fournisseurs
Cloudflare, Nginx, Microsoft, et Akamai renvoient tous des codes hors de la spécification officielle lorsque leur couche d’infrastructure échoue. Ce sont ceux à reconnaître immédiatement car ils indiquent que l’échec se situe au niveau de la périphérie, pas à votre origine.
| Code | Signification |
|---|---|
| 419 | Délai d’authentification dépassé |
| 420 | Calmez-vous / Échec de la méthode |
| 440 | Délai de connexion dépassé (Microsoft) |
| 444 | Pas de réponse (Nginx) |
| 449 | Réessayez avec (Microsoft) |
| 450 | Bloqué par les contrôles parentaux Windows |
| 460 | Connexion client fermée |
| 494 | En-tête de la requête trop large (Nginx) |
| 495 | Erreur de certificat SSL (Nginx) |
| 496 | Certificat SSL requis (Nginx) |
| 497 | Requête HTTP envoyée au port HTTPS |
| 498 | Jeton invalide |
| 499 | Requête client fermée (Nginx) |
| 509 | Limite de bande passante dépassée |
| 520 | Erreur inconnue (Cloudflare) |
| 521 | Serveur Web indisponible (Cloudflare) |
| 522 | Délai de connexion dépassé (Cloudflare) |
| 523 | Origine inaccessible (Cloudflare) |
| 524 | Un délai est survenu (Cloudflare) |
| 525 | Échec de la négociation SSL (Cloudflare) |
| 526 | Certificat SSL invalide (Cloudflare) |
| 527 | Erreur Railgun (Cloudflare) |
| 529 | Site surchargé |
| 530 | Site gelé / Erreur DNS d’origine |
| 561 | Non autorisé (Akamai) |
| 598 | Délai de lecture réseau dépassé |
| 599 | Délai de connexion réseau dépassé |
Les plages de codes non listées ci-dessus (104-199, 209-225, 227-299, 309-399, 432-450, 452-499, 512-599) sont soit non attribuées, obsolètes, ou réservées à un usage fournisseur. Traitez tout code dans ces plages comme spécifique au fournisseur et vérifiez la documentation de votre infrastructure.
Les codes sur lesquels votre surveillance devrait vraiment alerter
Parmi plus de 60 codes listés ci-dessus, ceux qui déclenchent des seuils d’alerte dans la plupart des environnements de production sont beaucoup plus restreints :
- 200 — comme ratio de référence. Une chute soudaine signifie qu’il y a un autre problème.
- 301, 302, 307, 308—comptes de redirection. Des pics peuvent signifier un routage mal configuré ou un déploiement ayant cassé les URL canoniques.
- 400—requêtes mal formées. Habituellement un changement côté consommateur.
- 401, 403—échecs d’authentification et d’autorisation. Souvent un changement de jeton, IAM ou WAF.
- 404—ressources manquantes. Bruit de fond comme cas isolés ; un problème de version en rafales.
- 408—temps d’attente côté client. Il vaut la peine d’alerter à des taux soutenus ; signale des appels en aval lents.
- 429—limitation de débit. Soit vous êtes limité, soit votre limite est trop agressive.
- 500, 502, 503, 504—échecs d’application, en amont, de capacité et de passerelle. Ces codes déclenchent une alerte d’astreinte.
- 520-526—échecs au niveau du edge Cloudflare. Si vous êtes derrière Cloudflare, ceux-ci sont des signaux critiques parce qu’ils isolent l’échec au chemin edge-vers-origin.
Tout le reste mérite d’être enregistré mais rarement de réveiller quelqu’un pour cela.
Comment vérifier le code d’état HTTP d’une page
Avant de pouvoir agir sur un code, vous devez le voir. Trois méthodes, de la plus rapide à la plus complète.
Dans Chrome DevTools
- Ouvrez la page.
- Cliquez droit n’importe où et choisissez Inspecter, puis ouvrez l’onglet Réseau.
- Rechargez. La première requête de document affiche le code dans la colonne Statut.
Depuis la ligne de commande
Une requête en-tête seulement renvoie la ligne de statut sans télécharger le corps :
c url -I https://example.comLa première ligne de la réponse est le code d’état — par exemple, HTTP/2 200.
À grande échelle
Les vérifications ponctuelles indiquent l’état actuel. Elles ne détectent pas la panne qui survient à 3 h du matin et disparaît avant votre réveil. Pour saisir les pannes intermittentes, vous avez besoin de contrôles programmés depuis plusieurs régions — ce que fait la surveillance synthétique.
Quand un 200 OK Ment
Une équipe e-commerce reçoit une alerte à 11 h un mardi. La conversion a chuté de 80 %. Ils consultent leur tableau de bord de disponibilité. Chaque point de terminaison est vert. Tous les codes d’état sont 200. Chaque région rapporte que le site est en ligne.
Le site n’est pas en ligne. Un déploiement 40 minutes plus tôt a livré un bundle JavaScript qui plante sur la page de paiement. Le HTML s’affiche, le serveur renvoie 200, le moniteur de code de statut voit 200, aucune alerte ne se déclenche. Les utilisateurs voient un panier vide et quittent le site.
C’est le mode de défaillance que la simple surveillance par code de statut ne peut pas détecter. La solution est multiple :
- Effectuer des vérifications en vrai navigateur sur les parcours utilisateurs critiques — accueil, recherche, produit, panier, paiement. Les vrais navigateurs exécutent le JavaScript et révèlent les erreurs côté client qu’un contrôle de type curl ne voit pas.
- Surveiller les signaux au niveau du corps : présence de mots-clés, visibilité des éléments, structure de réponse attendue. Ne faites pas confiance au code de statutseul.
- Lier les déploiements à la surveillance : toute vérification qui passe du vert au rouge dans les 15 minutes suivant une mise en production doit automatiquement étiqueter le déploiement. La moitié du temps post-mortem est consacrée à comprendre ce qui a changé ; le système de surveillance le sait déjà.
Qu’est-ce qu’un Soft 404 ?
Une version de ce problème a un nom : le soft 404. Un soft 404 est une page qui retourne 200 OK tout en indiquant à l’utilisateur que le contenu n’existe pas—un message “page non trouvée” servi avec un code de succès. La recommandation de Google est de retourner un vrai 404 ou 410 à la place, car les soft 404 gaspillent le budget d’exploration et perturbent l’index sur la réalité des pages.
La surveillance pure des codes d’état ne détectera pas un soft 404, pour la même raison qu’elle rate un paiement cassé : le code indique 200. Les vérifications dans un vrai navigateur avec des assertions sur le contenu—cherchant le contenu attendu ou l’absence d’une chaîne “non trouvé”—le feront.
Comment les Codes d’État HTTP Affectent le SEO
Les moteurs de recherche utilisent les codes d’état pour décider quoi explorer, quoi indexer, et à quelle fréquence revenir. Trois schémas comptent :
- Les codes 4xx érodent l’index au fil du temps. Une page qui retourne 404 pendant plusieurs tentatives d’exploration est supprimée. Si vous supprimez une page, redirigez-la avec un 301 au lieu de la laisser en 404.
- Les codes 5xx ralentissent l’exploration et dégradent les classements. Googlebot interprète un 5xx persistant comme “ce site est en mauvaise santé”. Le taux d’exploration diminue, l’indexation ralentit, les classements peuvent chuter.
- La différence entre 301 et 302 est importante. Le 301 passe l’équité des liens. Le 302 est traité comme temporaire et peut ne pas le faire. Si le déplacement est permanent, choisissez 301.
Le conseil pratique : les erreurs 5xx ne sont pas seulement un problème de disponibilité. Elles sont un problème SEO qui s’aggrave avec le temps. Les erreurs DNS, TCP, TLS et HTTP ont chacune un coût SEO différent—savoir quelle couche échoue vous aide à trier plus rapidement.
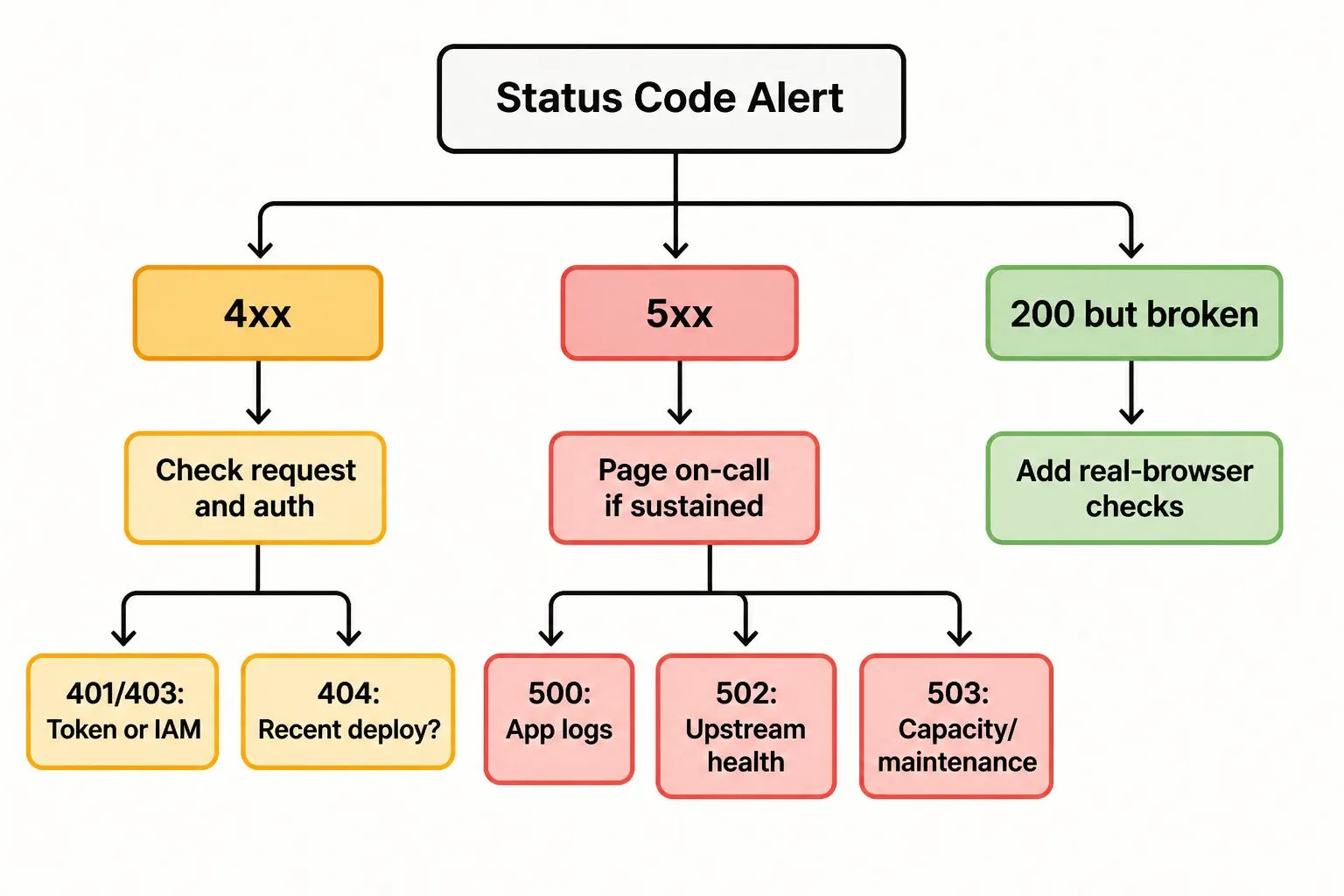
Surveiller les Codes d’État HTTP Sans Être Submergé d’Alertes
Chaque équipe qui surveille le trafic HTTP rencontre finalement le même problème : trop d’alertes, pas assez d’informations pertinentes. Quelques pratiques permettent de garder la surveillance des codes d’état utile plutôt que bruyante.
Alerter sur des taux, pas sur des requêtes uniques. Un 500 est du bruit. Cinquante 500 en cinq minutes, c’est un incident. Configurez des seuils selon votre volume de trafic de référence.
Séparez les points d’entrée face utilisateur des internes. Un 500 sur l’API de paiement doit déclencher une alerte. Un 500 sur un point d’entrée admin que personne n’utiliseg peut attendre les heures d’ouverture.
Testez d’où viennent vos utilisateurs. Un contrôle depuis un seul centre de données ne détectera pas une panne régionale de CDN. Utilisez un réseau de surveillance avec plusieurs géographies pour repérer les problèmes spécifiques à une localisation avant que les clients ne les rencontrent.
Combinez les vérifications de statut avec les vérifications de contenu. Le code 200 OK est un point de départ, pas une ligne d’arrivée. Validez que la réponse contient ce qu’elle doit contenir.
La surveillance des applications web de Dotcom-Monitor gère les quatre aspects : alertes basées sur le taux, segmentation des points de terminaison, emplacements mondiaux de surveillance et vérifications de contenu en navigateur réel. Pour les piles fortement orientées API, la surveillance API ajoute la validation de schéma et des SLO de temps de réponse en plus des contrôles de code de statut. Les deux alimentent le même pipeline d’alerte pour que vous n’ayez pas à assembler des signaux de trois fournisseurs différents.
Conclusion
Les codes d’état HTTP les plus courants n’ont pas changé depuis des années. 200, 301, 404, 500, 502, 503 — vous les verrez tous cette semaine. Ce qui change, c’est la rapidité avec laquelle votre équipe passe de « a vu le code » à « a corrigé la cause ».
C’est cet écart où une bonne surveillance fait la différence. Les codes d’état seuls vous indiquent qu’une chose s’est produite. Des vérifications en couches — statut, contenu, navigateur réel, multi-régions — vous disent quoi, où, et quoi faire ensuite.
Si vous voulez voir à quoi cela ressemble, Dotcom-Monitor propose un essai gratuit. Pointez-le vers un de vos points de terminaison et voyez ce qu’il révèle.
