
Ihr Pager geht um 2 Uhr morgens los. Die Alarmmeldung enthält einen Statuscode. Was Sie als nächstes tun, hängt fast ausschließlich davon ab, welchen Code Sie sehen.
Das ist der Teil, den die meisten HTTP-Statuscode-Anleitungen auslassen. Sie listen Definitionen auf, sortieren die Codes in fünf Gruppen und hören dann auf. Nützlich als Glossar, weniger nützlich, wenn ein echter Endpunkt 502er wirft und ein Geschäftsführer fragt, warum der Checkout nicht funktioniert.
Dieser Leitfaden behandelt dieselben zehn Codes, die Sie am häufigsten sehen werden, sowie ein paar ehrenwerte Erwähnungen. Für jeden: was er bedeutet, was ihn normalerweise in der Produktion auslöst und was Sie zuerst überprüfen sollten. Das Ziel ist, die Zeit zwischen „Ich sehe den Code“ und „Ich weiß, was zu beheben ist“ zu verkürzen.
Was ist ein HTTP-Statuscode?
Ein HTTP-Statuscode ist eine dreistellige Zahl, die der Server mit jeder Antwort zurücksendet. Er informiert den Client darüber, ob die Anfrage erfolgreich war, fehlgeschlagen ist oder umgeleitet werden muss. Sie sehen sie überall: im Netzwerk-Tab der DevTools Ihres Browsers, in Load-Balancer-Protokollen, in Monitoring-Alerts, in CDN-Dashboards. Dieser Leitfaden konzentriert sich auf die Codes, die tatsächlich jemanden aufwecken.
Die fünf Kategorien von HTTP-Statuscodes
Die erste Ziffer des Codes gibt die Antwortklasse an:
- 1xx Informativ. Selten im Tagesgeschäft. Meistens für Protokollverhandlungen verwendet (100 Continue, 101 Switching Protocols für WebSocket-Upgrades).
- 2xx Erfolg. Die Anfrage war erfolgreich. 200 ist Standard; 201 bedeutet, dass eine Ressource erstellt wurde; 204 bedeutet Erfolg ohne Inhalt.
- 3xx Weiterleitung. Die Ressource befindet sich woanders. Browser und Crawler folgen diesen automatisch bis zu einem Limit.
- 4xx Client-Fehler. Die Anfrage war fehlerhaft. Schlechte URL, fehlende Authentifizierung, gesperrte Berechtigungen, fehlerhafte Nutzlast.
- 5xx Server-Fehler. Die Anfrage war in Ordnung. Der Server konnte sie nicht erfüllen.
Die Unterscheidung zwischen 4xx und 5xx ist der wichtigste Teil für die Ersteinschätzung. Ein 4xx bedeutet „Der Anrufer hat etwas falsch gemacht“. Ein 5xx bedeutet „Wir haben etwas falsch gemacht“. Ersteres geht an den, der den Endpunkt aufgerufen hat. Letzteres geht an Sie.
Für eine vollständige Aufzählung listet das komplette HTTP-Statuscode-Referenz im Dotcom-Monitor Wiki jeden im Standard definierten Code auf. Der Rest dieses Leitfadens konzentriert sich auf die, die tatsächlich in Alerts erscheinen.
Die zehn häufigsten HTTP-Statuscodes
200 OK
Der Server hat die Anfrage verarbeitet und die erwartete Antwort zurückgegeben. Dies ist der Code, den Sie bei der überwiegenden Mehrheit der Anfragen an eine gesunde Produktionsseite sehen wollen.
Achten Sie auf: Ein 200 OK ist kein Beweis dafür, dass die Seite korrekt ist. JavaScript kann stillschweigend fehlschlagen und eine leere Seite rendern. Eine API kann 200 mit einem Fehlerkörper zurückgeben. Ein Login-Formular kann „ungültige Anmeldedaten“ in einer 200-Antwort anzeigen. Statuscode-only-Checks übersehen das. Kombinieren Sie sie mit echten Browser-Checks (mehr dazu unten).
301 Moved Permanently
Die Ressource hat eine neue permanente URL. Browser cachen die Weiterleitung aggressiv. Suchmaschinen übertragen den Großteil der Linkstärke auf das Ziel.
Verwenden Sie es für: URL-Änderungen nach einer Seitenmigration, Wechsel von HTTP zu HTTPS, Konsolidierung doppelter Pfade, Stilllegung alter Slugs. Sobald ein 301 live und gecacht ist, ist ein Zurückrollen schmerzhaft – Browser und Crawler gehen wochenlang zur neuen Adresse.
302 Found (Temporary Redirect)
Die Ressource befindet sich vorübergehend woanders. Browser cachen die Weiterleitung nicht, und Suchmaschinen übertragen nicht die volle Linkstärke.
Achten Sie auf: 302 wird übermäßig verwendet. Teams greifen darauf zurück, weil der Framework-Standard-Redirect-Helfer 302 zurückgibt. Wenn der Umzug dauerhaft ist, verwenden Sie 301. Wenn Sie die HTTP-Methode erhalten müssen (POST bleibt POST), verwenden Sie stattdessen 307 oder 308. Google behandelt persistente 302s letztlich als 301s, aber „letztlich“ ist keine Strategie.
400 Bad Request
Der Server kann die Anfrage nicht parsen. Fehlerhaftes JSON, ungültige Header, zu große Nutzlasten, Schema-Verstöße.
Prüfen Sie zuerst: den Anfragekörper. Ein plötzlicher Anstieg von 400 auf einem API-Endpunkt bedeutet meist, dass ein Client angefangen hat, falsche Daten zu senden – eine Änderung auf der Verbraucherseite, eine Schema-Änderung auf Ihrer Seite oder eine Aktualisierung eines Drittanbieter-Formats. Vergleichen Sie die Nutzlast mit der letzten bekannten korrekten Version.
401 Unauthorized
Die Anfrage hat keine oder abgelehnte Anmeldedaten. Der Name ist irreführend – das Problem ist die Authentifizierung, nicht die Autorisierung.
Prüfen Sie zuerst: Tokens. Ein plötzlicher Anstieg von 401 auf zuvor funktionierenden Endpunkten bedeutet oft, dass ein Token abgelaufen ist, ein Signaturschlüssel rotiert wurde, ein OIDC-Provider einen Ausfall hatte oder jemand den Audience-Claim geändert hat. Wenn Ihr API Verfügbarkeitsmonitor 401 zeigt, wo früher 200 war, ist meist die Authentifizierungsschicht schuld.
403 Forbidden
Die Anmeldedaten sind gültig, aber der Anrufer darf auf diese Ressource nicht zugreifen. Das Problem ist Autorisierung, nicht Authentifizierung.
Prüfen Sie zuerst: Berechtigungen und Infrastrukturregeln. 403 erscheinen, wenn eine IAM-Policy geändert wurde, eine WAF-Regel legitimen Traffic blockiert, eine CDN-Zugriffsregel zu streng ist oder ein Feature-Flag für die falsche Benutzergruppe aktiviert wurde. Wenn 403 direkt nach einem Deploy auftraten, prüfen Sie zuerst Policy- und Konfigurationsänderungen, bevor Sie den Anwendungs-Code betrachten.
404 Not Found
Der Server hat die Anfrage verstanden, findet aber keine Ressource unter dieser URL. Der bekannteste Statuscode überhaupt.
Zwei Fälle zu unterscheiden:
- Einzelne 404s durch Tippfehler, alte Lesezeichen oder Crawler, die nach Sicherheitslücken suchen. Diese sind Hintergrundrauschen.
- Ein Anstieg von 404s auf kanonischen URLs direkt nach einem Deploy. Das ist ein fehlerhaftes Release – Routen fehlen, ein Build-Artefakt ist verloren, oder jemand hat eine Slug-Änderung ohne Weiterleitungen veröffentlicht. Rollback oder Hotfix anstoßen.
Persistente 404 auf indexierten Seiten werden von Google irgendwann rausgekickt, daher kosten kanonische Seiten mit 404 auch SEO-Ranking.
Behebung
Schneller Weg: Wenn die Seite verschoben wurde, fügen Sie einen 301-Redirect von der alten URL zur neuen hinzu, damit Benutzer und Crawler an der richtigen Stelle landen. Wenn die Seite wirklich weg ist, geben Sie einen echten 404 oder 410 zurück anstelle eines unklaren Redirects auf die Startseite.
Wirkliche Lösung: Überprüfen Sie die Quelle der 404. Interne defekte Links werden an der Quelle korrigiert; fehlende Routen nach Deploy erhalten einen Hotfix; eine fehlerhafte Migration, die Slugs verloren hat, braucht eine Redirect-Map. Crawlen Sie Ihre eigene Seite regelmäßig, um tote Links vor Google zu finden.
500 Internal Server Error
Der Server hatte eine unbehandelte Ausnahme. Der Allzweck-5xx-Code. Er sagt, dass etwas kaputt ist, aber nicht was.
Prüfen Sie zuerst: Anwendungsprotokolle. Jeder 500 hat irgendwo einen Stacktrace – wenn nicht, muss Ihr Logging verbessert werden, bevor Sie den Code debuggen. Häufige Ursachen: Eine ungefangene Ausnahme in einem kürzlich ausgerollten Codepfad, eine Abhängigkeit liefert unerwartete Daten, Verbindungs-Pool zur Datenbank erschöpft, ein Out-of-Memory-Restart-Loop. Ein andauernder 500-Anstieg an einem Produktions-Endpunkt sollte den Bereitschaftsdienst auslösen.
Behebung
Schneller Weg: Wenn der Anstieg direkt nach einem Release startete, rollen Sie zurück. Ein 500, das kurz nach einem Deploy erscheint, ist das Deploy bis zum Beweis des Gegenteils.
Wirkliche Lösung: Lesen Sie den Stacktrace und patchen Sie den fehlerhaften Codepfad, dann fügen Sie einen Regressionstest hinzu, damit das Problem nicht zurückkehrt. War die Ursache eine Ressourcenbegrenzung – Verbindungs-Pool, Speicher, Dateihandles – erhöhen Sie das Limit und fügen Sie eine Warnung hinzu, bevor Sie es das nächste Mal erreichen.
502 Bad Gateway
Ein Proxy, Load-Balancer oder CDN erhielt eine ungültige Antwort vom Upstream-Server. Der Proxy selbst ist gesund. Der dahinterliegende Server nicht.
Prüfen Sie zuerst: Den Gesundheitsstatus des Upstreams. Häufige Ursachen: Ein App-Container ist abgestürzt, aber der Load-Balancer sendet immer noch Traffic dorthin, der Upstream antwortet nicht rechtzeitig, ein Kubernetes-Pod steckt in CrashLoopBackOff, ein Nginx-Worker ist falsch konfiguriert, oder die Verbindung zwischen Proxy und Upstream wurde zurückgesetzt. 502 ist einer der aussagekräftigsten Codes bei Schichtenarchitekturen – er sagt, dass der Edge in Ordnung ist und das Problem eine Schicht weiter hinten liegt.
Behebung
Schneller Weg: Starten oder ersetzen Sie die ungesunde Upstream-Instanz neu und vergewissern Sie sich, dass die Health-Checks des Load-Balancers tote Knoten tatsächlich aus dem Verkehr ziehen.
Wirkliche Lösung: Finden Sie heraus, warum der Upstream Müll zurückgegeben hat. Prüfen Sie, ob das Timeout des Proxys kürzer ist als die tatsächliche Antwortzeit des Upstreams, ob der Pod beim Start in einer Crash-Schleife steckt und ob die Keep-Alive-Einstellungen auf beiden Seiten der Verbindung übereinstimmen.
503 Service Unavailable
Der Server ist vorübergehend nicht in der Lage, die Anfrage zu bearbeiten. Kapazität erschöpft, Wartungsmodus, Autoscaler ist noch am Hochfahren.
Prüfen Sie zuerst: Ressourcenauslastung und Rate-Limits. 503 während eines Traffic-Spikes bedeuten meist, dass der Autoscaler nicht nachkommt oder Sie eine Verbindungsgrenze erreicht haben. 503 im stabilen Zustand zeigen meist Wartungsprozesse oder Rückstau in einer Warteschlange. Manche Plattformen geben 503 auch zurück, wenn ein WAF- oder Anti-Bot-System den Anrufer limitiert – prüfen, bevor Sie annehmen, dass die App das Problem ist.
Behebung
Schneller Weg: Geben Sie 503 mit einem Retry-After-Header zurück, damit gut erzogene Clients und Crawler Abstand halten statt den angeschlagenen Server zu bombardieren. In PHP:
http_response_code(503);
header('Retry-After: 60');Wirkliche Lösung: Finden Sie die ausgelastete Ressource – Datenbankverbindungen, Worker-Pool, Autoscaler-Limit – und beseitigen Sie den Engpass. Kam die 503 von einem Rate-Limit eines CDN oder WAF, erhöhen Sie das Limit oder setzen Sie den legitimen Anrufer auf die Whitelist.
Weitere wichtige Codes
Die oben genannten zehn decken den Großteil des Produktions-Traffics ab. Aber ein paar andere Codes kommen oft genug bei echten Vorfällen vor, dass On-Call-Ingenieure sie auf Anhieb kennen sollten.
- 304 Not Modified. Gesendet, wenn eine gecachte Ressource noch aktuell ist. Häufig bei CDN-gestütztem Traffic. Ein Rückgang von 304 kann bedeuten, dass sich Ihre Cache-Control-Header geändert haben und Sie wieder Origin-Bandbreite zahlen statt zu sparen.
- 307 Temporary Redirect. Wie 302, aber die HTTP-Methode bleibt erhalten. Ein POST bleibt ein POST. Verwenden Sie 307 statt 302 bei Weiterleitungen von Formularen oder nicht-idempotenten API-Aufrufen.
- 308 Permanent Redirect. Wie 301, aber die HTTP-Methode bleibt erhalten. Die moderne Wahl bei dauerhaften Weiterleitungen von API-Endpunkten mit POST, PUT, PATCH oder DELETE.
- 429 Too Many Requests. Rate-Limit erreicht. Entweder werden Sie von einer Upstream-API gedrosselt oder Sie drosseln jemanden selbst. Prüfen Sie
Retry-After-Header; respektieren Sie diese. - 504 Gateway Timeout. Ein Proxy hat das Warten auf den Upstream aufgegeben. Anders als 502 hat der Upstream keine schlechte Antwort geliefert, sondern keine Antwort rechtzeitig. Meist eine lang laufende Abfrage, ein eingefrorener Worker oder eine langsame Downstream-API.
301 vs 302 vs 307 vs 308
Die vier Redirect-Codes werden ständig verwechselt. Der Unterschied beruht auf zwei Dingen: ob die Weiterleitung dauerhaft ist und ob die HTTP-Methode erhalten bleibt.
| Verhalten | 301 | 302 | 307 | 308 |
|---|---|---|---|---|
| Dauer | Dauerhaft | Vorübergehend | Vorübergehend | Dauerhaft |
| Methode erhalten | Nicht garantiert | Nicht garantiert | Ja | Ja |
| Browser-Cache | Aggressiv | Nein | Nein | Ja |
| Linkstärke übertragen | Großtenteils | Begrenzt | Begrenzt | Großtenteils |
| Verwendung | Dauerhafte URL-Änderung | Kurzfristige Änderung | Formular- oder POST-Redirect | Dauerhafte API-Endpunkt-Änderung |
Für eine einfache Seite, die dauerhaft verschoben wurde, verwenden Sie 301. Wenn die Weiterleitung eine POST-Anfrage als POST erhalten muss – bei Formularen oder nicht-idempotenten API-Anrufen – verwenden Sie 307 bei vorübergehender und 308 bei dauerhafter Umleitung.
Die vollständige HTTP-Statuscode-Referenz
Die obigen Codes decken fast alles ab, was einen echten Alarm auslöst. Für ungewöhnliche Codes – die einmal pro Quartal auftauchen und Sie etwas nachschlagen lassen – hier die komplette Standardliste plus nicht standardisierte Codes von gängigen Infrastruktur-Anbietern.
1xx Informativ
Der Server hat die Anfrage erhalten und verarbeitet sie weiter. Diese sieht man selten in Anwendungsprotokollen, da die meisten Clients und Proxys sie transparent behandeln.
| Code | Bedeutung |
|---|---|
| 100 | Continue |
| 101 | Switching Protocols |
| 102 | Processing |
| 103 | Early Hints |
2xx Erfolg
Die Anfrage wurde empfangen, verstanden und akzeptiert. 200 ist der Arbeitstier-Code; die anderen sind wichtig, wenn Sie APIs bauen oder mit Teilinhalten, WebDAV oder Batch-Operationen arbeiten.
| Code | Bedeutung |
|---|---|
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 203 | Non-Authoritative Information |
| 204 | No Content |
| 205 | Reset Content |
| 206 | Partial Content |
| 207 | Multi-Status |
| 208 | Already Reported |
| 226 | IM Used |
3xx Weiterleitung
Die Ressource befindet sich woanders, oder die gecachte Kopie ist noch gültig. 301 und 302 dominieren; die anderen sind wichtig für APIs (307/308 erhalten die HTTP-Methode) und Caching-Pipelines (304 spart Origin-Bandbreite).
| Code | Bedeutung |
|---|---|
| 300 | Multiple Choices |
| 301 | Moved Permanently |
| 302 | Found |
| 303 | See Other |
| 304 | Not Modified |
| 305 | Use Proxy (deprecated) |
| 306 | Switch Proxy (unused) |
| 307 | Temporary Redirect |
| 308 | Permanent Redirect |
4xx Client-Fehler
Die Anfrage war fehlerhaft. Die meisten davon sehen Sie nie; die eine Handvoll häufigerer kommen täglich vor. Es lohnt sich, die seltenen zu kennen, damit Sie keine Zeit verschwenden, wenn ein 418 oder 451 in einem Log auftaucht.
| Code | Bedeutung |
|---|---|
| 400 | Bad Request |
| 401 | Unauthorized |
| 402 | Payment Required |
| 403 | Forbidden |
| 404 | Not Found |
| 405 | Method Not Allowed |
| 406 | Not Acceptable |
| 407 | Proxy Authentication Required |
| 408 | Request Timeout |
| 409 | Conflict |
| 410 | Gone |
| 411 | Length Required |
| 412 | Precondition Failed |
| 413 | Payload Too Large |
| 414 | URI Too Long |
| 415 | Unsupported Media Type |
| 416 | Range Not Satisfiable |
| 417 | Expectation Failed |
| 418 | I’m a teapot |
| 421 | Misdirected Request |
| 422 | Unprocessable Content |
| 423 | Locked |
| 424 | Failed Dependency |
| 425 | Too Early |
| 426 | Upgrade Required |
| 428 | Precondition Required |
| 429 | Too Many Requests |
| 431 | Request Header Fields Too Large |
| 451 | Unavailable For Legal Reasons |
5xx Server-Fehler
Die Anfrage war in Ordnung. Etwas auf der Serverseite ist fehlgeschlagen. Diese Codes wecken meistens jemanden auf.
| Code | Bedeutung |
|---|---|
| 500 | Internal Server Error |
| 501 | Not Implemented |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
| 504 | Gateway Timeout |
| 505 | HTTP Version Not Supported |
| 506 | Variant Also Negotiates |
| 507 | Insufficient Storage |
| 508 | Loop Detected |
| 510 | Not Extended |
| 511 | Network Authentication Required |
Nicht standardisierte und Vendor-Codes
Cloudflare, Nginx, Microsoft und Akamai geben alle Codes außerhalb der offiziellen Spezifikation zurück, wenn ihre Infrastrukturschicht ausfällt. Diese sollten Sie auf Anhieb erkennen, weil sie anzeigen, dass der Fehler am Edge liegt, nicht am Origin.
| Code | Bedeutung |
|---|---|
| 419 | Authentication Timeout |
| 420 | Enhance Your Calm / Method Failure |
| 440 | Login Timeout (Microsoft) |
| 444 | No Response (Nginx) |
| 449 | Retry With (Microsoft) |
| 450 | Blocked by Windows Parental Controls |
| 460 | Client Closed Connection |
| 494 | Request Header Too Large (Nginx) |
| 495 | SSL Certificate Error (Nginx) |
| 496 | SSL Certificate Required (Nginx) |
| 497 | HTTP Request Sent to HTTPS Port |
| 498 | Invalid Token |
| 499 | Client Closed Request (Nginx) |
| 509 | Bandwidth Limit Exceeded |
| 520 | Unknown Error (Cloudflare) |
| 521 | Web Server Is Down (Cloudflare) |
| 522 | Connection Timed Out (Cloudflare) |
| 523 | Origin Is Unreachable (Cloudflare) |
| 524 | A Timeout Occurred (Cloudflare) |
| 525 | SSL Handshake Failed (Cloudflare) |
| 526 | Invalid SSL Certificate (Cloudflare) |
| 527 | Railgun Error (Cloudflare) |
| 529 | Site Overloaded |
| 530 | Site Frozen / Origin DNS Error |
| 561 | Unauthorized (Akamai) |
| 598 | Network Read Timeout |
| 599 | Network Connect Timeout |
Code-Bereiche, die oben nicht gelistet sind (104-199, 209-225, 227-299, 309-399, 432-450, 452-499, 512-599), sind entweder nicht zugewiesen, veraltet oder für Vendor-Codes reserviert. Behandeln Sie Codes in diesen Bereichen als herstellerspezifisch und lesen Sie die Infrastruktur-Dokumentation.
Die Codes, auf die Ihre Überwachung tatsächlich alarmieren sollte
Von den über 60 Codes oben ist die Liste derjenigen, die in den meisten Produktionsumgebungen Alarme auslösen, deutlich kürzer:
- 200 – als Grundlinie. Ein plötzlicher Rückgang bedeutet, dass etwas anderes schief läuft.
- 301, 302, 307, 308 – Anzahl der Weiterleitungen. Anstiege können auf Fehlkonfigurationen oder Deployments hinweisen, die kanonische URLs brechen.
- 400 – fehlerhafte Anfragen. Meist Änderungen auf der Verbraucherseite.
- 401, 403 – Authentifizierungs- und Berechtigungsfehler. Oft Token-, IAM- oder WAF-Änderungen.
- 404 – fehlende Ressourcen. Einzelne Fehler sind Hintergrundrauschen; gehäuftes Auftreten ein Release-Problem.
- 408 – Client-Timeouts. Bei anhaltender Rate alarmieren; deuten auf langsame Downstream-Aufrufe.
- 429 – Rate-Limits. Entweder Sie werden limitiert oder drosseln selbst zu stark.
- 500, 502, 503, 504 – Fehler in Anwendung, Upstream, Kapazität und Gateway-Timeout. Diese lösen Paging aus.
- 520-526 – Edge-Fehler bei Cloudflare. Wenn Sie hinter Cloudflare sind, sind diese kritische Signale, da sie den Fehler auf den Edge-Origin-Pfad eingrenzen.
Alles andere ist es wert, protokolliert zu werden, aber selten so wichtig, dass jemand geweckt werden muss.
Wie man den HTTP-Statuscode einer Seite prüft
Bevor Sie auf einen Code reagieren, müssen Sie ihn sehen. Drei Methoden, von der schnellsten bis zur gründlichsten.
In Chrome DevTools
- Öffnen Sie die Seite.
- Rechtsklick irgendwo und „Untersuchen“ wählen, dann den Netzwerk-Tab öffnen.
- Seite neu laden. Die erste Dokument-Anfrage zeigt den Code in der Spalte „Status“.
Über die Kommandozeile
Eine reine Header-Anfrage gibt die Statuszeile zurück, ohne den Body herunterzuladen:
curl -I https://example.comDie erste Zeile der Antwort ist der Statuscode – zum Beispiel HTTP/2 200.
Im großen Maßstab
Einmalige Checks zeigen den aktuellen Zustand. Sie erfassen aber nicht den Fehler, der um 3 Uhr morgens passiert und verschwindet, bevor Sie aufwachen. Um intermittierende Fehler zu erfassen, brauchen Sie geplante Checks von mehreren Regionen – wie synthetisches Monitoring es leistet.
Wenn ein 200 OK lügt
Ein E-Commerce-Team bekommt am Dienstag um 11 Uhr eine Pager-Alarmierung. Die Conversion ist um 80 Prozent eingebrochen. Sie prüfen ihr Uptime-Dashboard. Alle Endpunkte sind grün. Alle Statuscodes 200. Alle Regionen melden die Seite als erreichbar.
Die Seite ist nicht erreichbar. Ein Deploy 40 Minuten zuvor hat ein JavaScript-Bündel ausgeliefert, das auf der Checkout-Seite Fehler wirft. Das HTML rendert, der Server gibt 200 zurück, der Status-Code-Monitor erkennt 200, kein Alarm wird ausgelöst. Nutzer sehen einen leeren Warenkorb und springen ab.
Das ist der Fehlerfall, den reines Statuscode-Monitoring nicht erkennen kann. Die Lösung ist vielschichtig:
- Führen Sie echte Browser-Checks durch auf kritischen Nutzerpfaden – Startseite, Suche, Produkt, Warenkorb, Checkout. Echte Browser führen JavaScript aus und erkennen Client-Seite Fehler, die ein Curl-artiger Check verpasst.
- Achten Sie auf Signale im Antwortkörper: Schlüsselwörter, Sichtbarkeit von Elementen, erwartete Antwortstruktur. Vertrauen Sie nicht nur dem Statuscode.
- Verknüpfen Sie Deployments mit dem Monitoring: Jeder Check, der innerhalb von 15 Minuten nach einem Release von grün auf rot springt, sollte das Deployment automatisch taggen. Die Hälfte der Post-Mortem-Zeit entfällt darauf, herauszufinden, was sich geändert hat; das Monitoring-System weiß das bereits.
Was ist ein Soft 404?
Eine Variante dieses Problems hat einen Namen: das Soft 404. Eine Soft 404-Seite gibt 200 OK zurück, sagt aber dem Nutzer, dass der Inhalt nicht existiert – eine Seite mit einer „Nicht gefunden“-Meldung, die mit einem Erfolgs-Code ausgeliefert wird. Googles Empfehlung ist, stattdessen einen echten 404 oder 410 zurückzugeben, da Soft 404s Crawl-Budget verschwenden und den Index verwirren, welche Seiten real sind.
Reines Statuscode-Monitoring erkennt ein Soft 404 nicht, aus dem gleichen Grund, warum es einen kaputten Checkout nicht bemerkt: Der Code ist 200. Echte Browser-Checks mit Assertions im Body – die nach dem erwarteten Inhalt oder dem Fehlen eines „nicht gefunden“-Strings suchen – schon.
Wie HTTP-Statuscodes SEO beeinflussen
Suchmaschinen nutzen Statuscodes, um zu entscheiden, was gecrawlt, indexiert und wie oft eine Seite besucht wird. Drei Muster sind wichtig:
- 4xx-Codes reduzieren den Index im Laufe der Zeit. Eine Seite, die bei mehreren Crawl-Versuchen 404 zurückgibt, wird entfernt. Wenn Sie eine Seite löschen, leiten Sie mit 301 um, statt sie einfach 404 geben zu lassen.
- 5xx-Codes verlangsamen das Crawling und verschlechtern Rankings. Googlebot interpretiert persistente 5xx als „diese Seite ist ungesund“. Die Crawl-Rate sinkt, das Indexieren verlangsamt sich, Rankings können fallen.
- 301 vs 302 ist wichtig. 301 überträgt Linkstärke. 302 wird als temporär behandelt und unter Umständen nicht. Wenn die Änderung dauerhaft ist, wählen Sie 301.
Die praktische Erkenntnis: 5xx-Fehler sind nicht nur ein Verfügbarkeitsproblem. Sie sind ein SEO-Problem, das sich umso mehr auswirkt, je länger es besteht. DNS-, TCP-, TLS- und HTTP-Fehler haben jeweils unterschiedliche SEO-Kosten – zu wissen, welche Schicht ausfällt, hilft bei der schnelleren Fehlerbehebung.
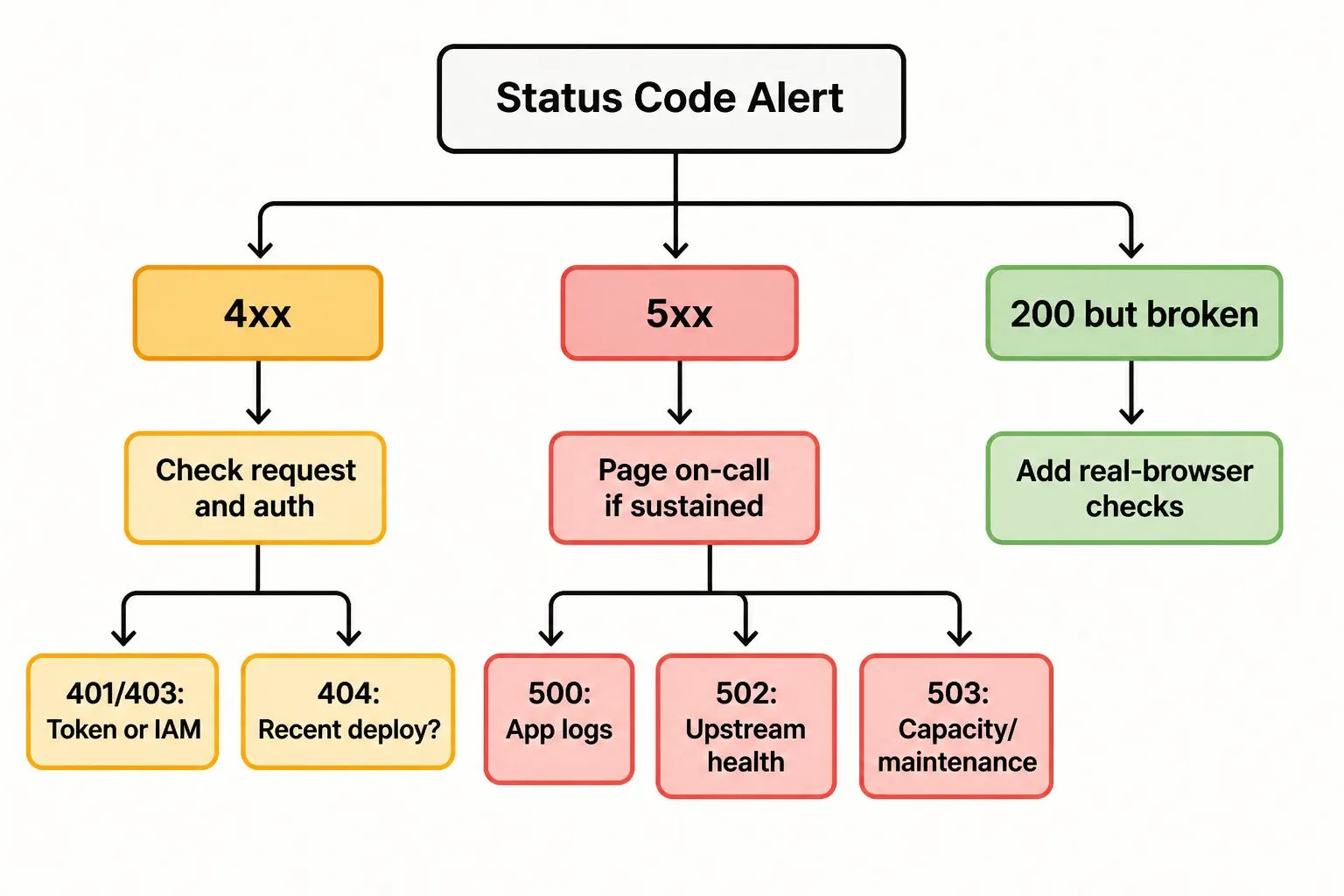
HTTP-Statuscodes überwachen, ohne in Alarmen unterzugehen
Jedes Team, das HTTP-Traffic überwacht, trifft irgendwann auf dasselbe Problem: zu viele Alarme, zu wenig Signal. Einige Praktiken halten Statuscode-Monitoring nützlich statt störend.
Alarmieren Sie bei Raten, nicht bei einzelnen Anfragen. Ein einzelner 500er ist Rauschen. Fünfzig 500er in fünf Minuten sind ein Vorfall. Konfigurieren Sie Schwellenwerte anhand Ihres Basisverkehrs.
Trennen Sie nutzerseitige Endpunkte von internen. Ein 500 am Checkout-API sollte page. Ein 500 an einem Admin-Endpunkt, den niemand nutzt, kann bis zu den Geschäftszeiten warten.
Testen Sie von dort, wo Ihre Nutzer sind. Ein Check von einem Rechenzentrum fängt keinen regionalen CDN-Ausfall. Nutzen Sie ein Monitoring-Netzwerk mit mehreren Standorten, um standortbezogene Probleme vor Kunden zu erkennen.
Kombinieren Sie Status-Checks mit Inhaltsprüfungen. 200 OK ist ein Startpunkt, kein Endpunkt. Prüfen Sie, ob die Antwort das enthält, was sie enthalten soll.
Das Web Application Monitoring von Dotcom-Monitor deckt alle vier ab: alarm gestützte Überwachung, Endpunkt-Segmentierung, globale Teststandorte und echte Browser-Inhaltsprüfungen. Für API-lastige Stacks erweitert der API-Monitoring-Weg Schemavalidierung und Antwortzeit-SLOs zusätzlich zu Statuscode-Checks. Beides speist dieselbe Alerting-Pipeline, sodass Sie nicht Signale von drei Anbietern zusammenführen müssen.
Abschließende Gedanken
Die häufigsten HTTP-Statuscodes haben sich seit Jahren nicht geändert. 200, 301, 404, 500, 502, 503 – diese werden Sie diese Woche alle sehen. Was sich ändert, ist, wie schnell Ihr Team vom „Code sehen“ zum „Ursache beheben“ kommt.
Diese Lücke ist es, in der gutes Monitoring sich auszahlt. Statuscodes allein sagen: Etwas ist passiert. Mehrschichtige Checks – Status, Inhalt, echter Browser, Multi-Region – sagen: Was, wo und was als nächstes zu tun ist.
Wenn Sie sehen möchten, wie das aussieht, hat Dotcom-Monitor eine kostenlose Testversion. Richten Sie sie auf einen Ihrer Endpunkte aus und sehen Sie, was sie anzeigt.
