


Starten Sie Ihren KOSTENLOSEN 30-Tage-Test
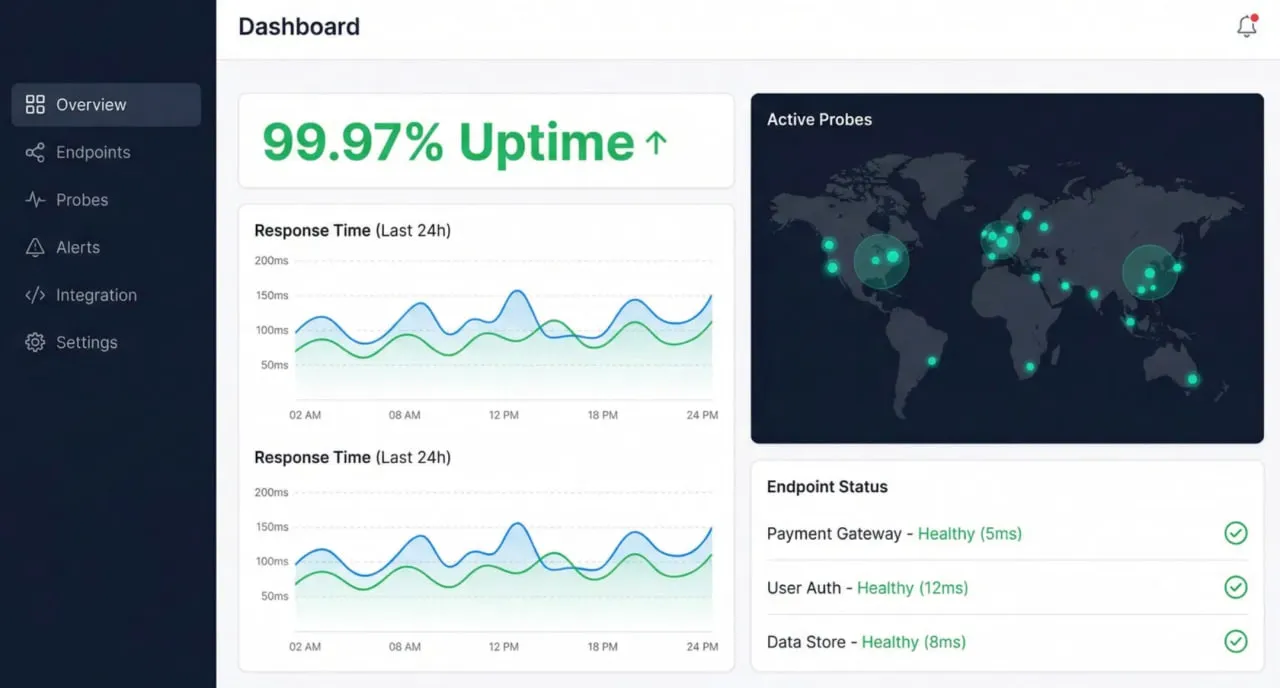
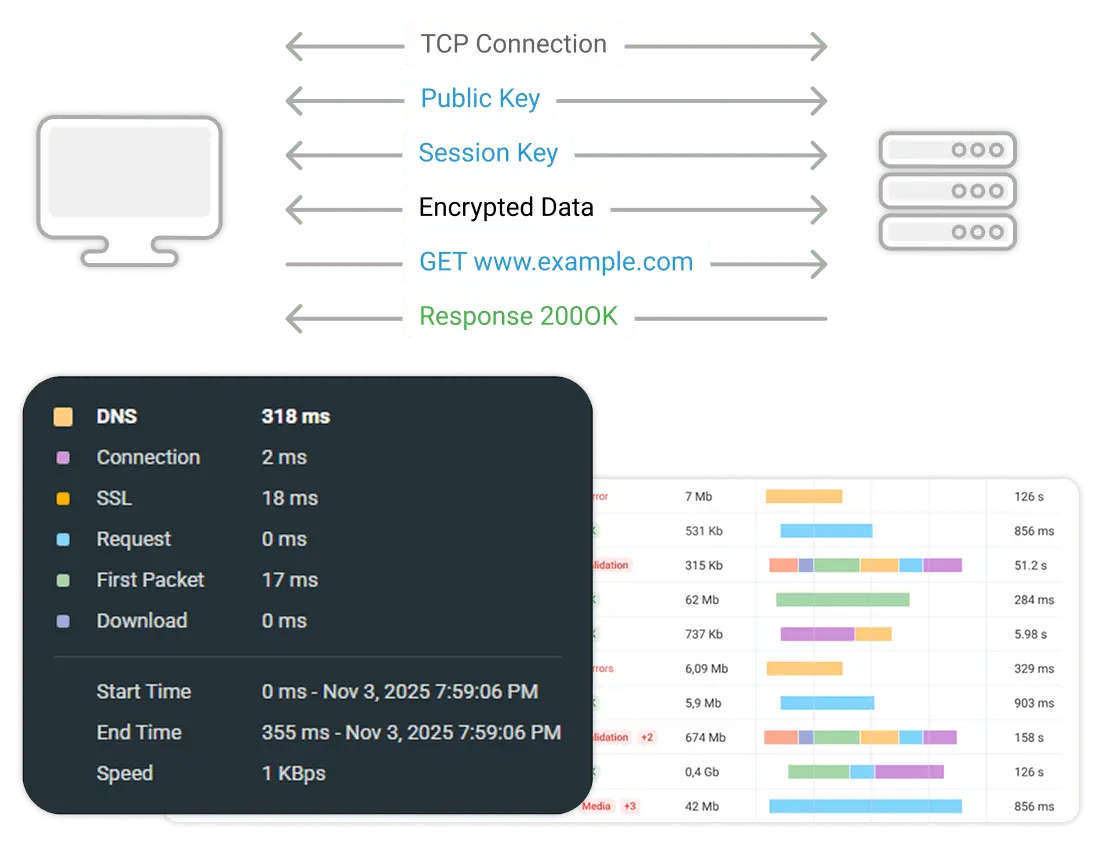
Voller Zugriff auf alle Monitoring-Funktionen — API-Uptime, synthetische Checks, Multi-Step-Transaktionen und globale Abdeckung von 30+ Standorten. Keine Kreditkarte erforderlich.
- Keine Kreditkarte erforderlich
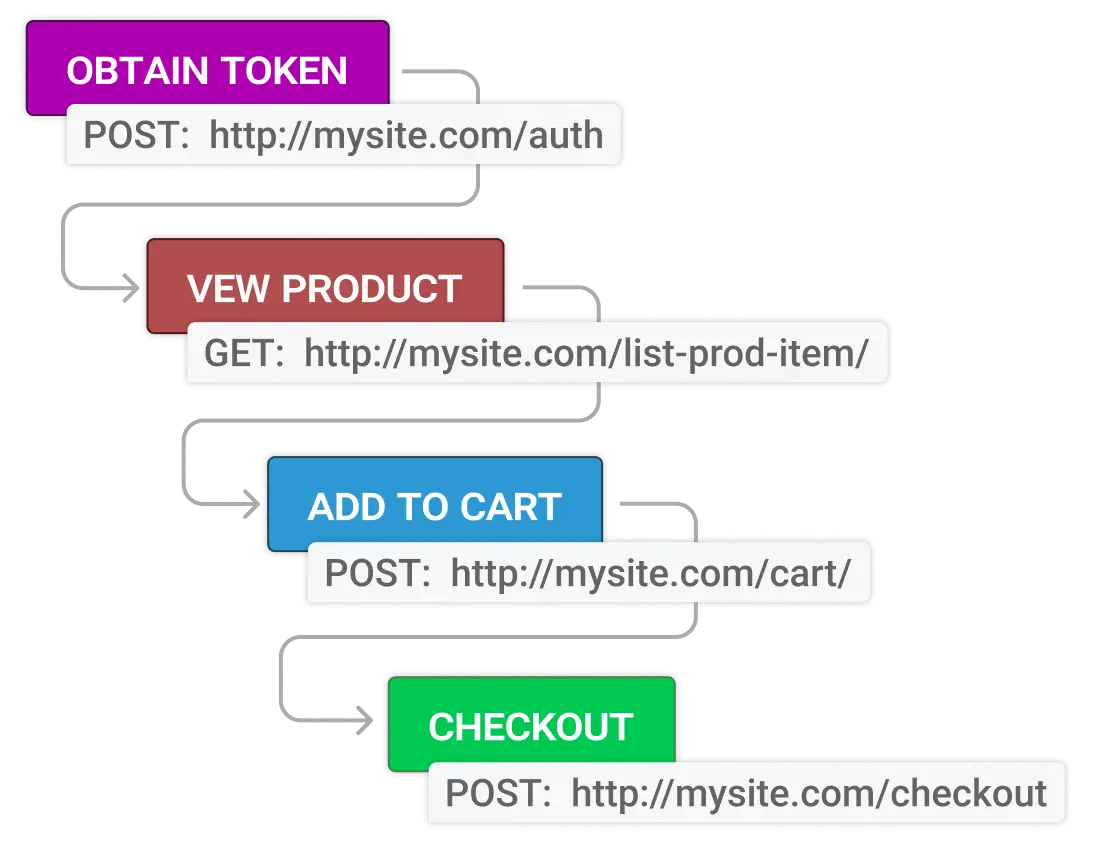
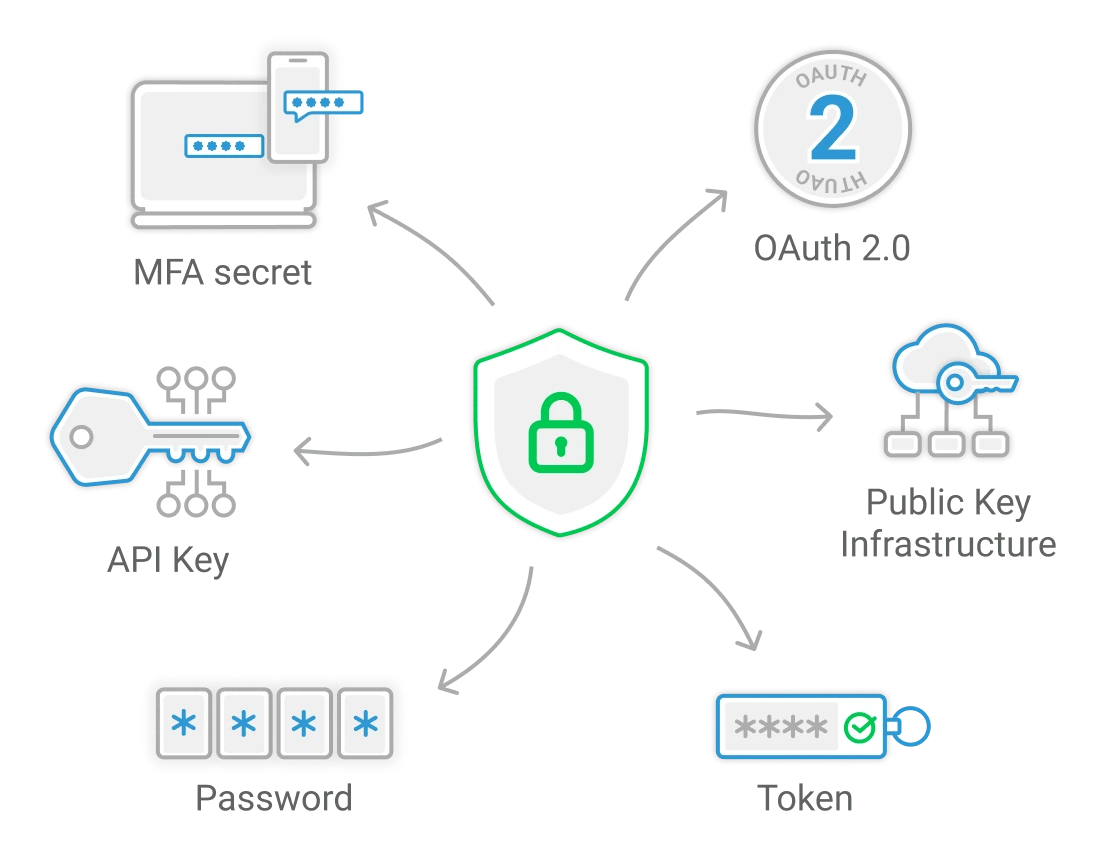
- REST, SOAP, Multi-Step und Alerting enthalten
- 24x7 Experten-Support
