
大多数团队都有网站监控。真正能在客户、销售和支持团队发现问题之前捕捉到问题的网站监控少之又少。差距很少是工具的原因,而是围绕工具的实践:检查什么、从哪里检查、多久检查一次、什么触发通知、以及谁决定检查失败是检测点坏了还是网站坏了。
本操作手册收集了八条将SRE和DevOps团队信赖的监控设置与最终沦为噪音的设置区分开的最佳实践。每条都是具体的:阈值、间隔、反模式,以及一旦有效后该持续做什么。这些实践无论是对营销网站运行正常运行时间监控,还是跨SaaS结账流程做完整的合成事务监控,都适用。
“好”监控的标准(及大多数设置为何达不到)
一个可用的定义是:如果团队能从监控中首先得知所有面向客户的问题,而不是从客户那里得知,同时所收到的告警几乎都能执行行动,这就是好的监控。这个标准就是全部。
有三项指标评估:平均检测时间(MTTD)告诉你监控是否够快;平均恢复时间(MTTR)告诉你监控提供的数据是否足以修复问题;告警精准度——即真实且需立即处理的告警比例——则决定团队六个月后是否还会信任这些告警。大多数SRE团队会测量MTTD和MTTR,但大多数团队不测量精准度。这也是为什么许多值班轮换最终沦为无声确认和习得性无助。
接下来的内容将介绍如何同时推动这两个数字朝正确方向发展。
在完整请求路径上分层检查
单一的HTTPS检查就像只有一个传感器的烟雾报警器。它能告诉你有问题,但无法定位在哪里。当用户输入你的URL并等待页面渲染时,请求至少经过六个层面:DNS解析、TCP握手、TLS协商、HTTP响应、资源加载和客户端渲染最终视图。每层失败方式不同,根因也各异。

实际设置如下:
- DNS:从多个解析器检查A、AAAA、CNAME和MX记录是否解析到预期值。DNS问题最容易被忽视,事后排查最痛苦。最佳DNS监控工具可监测未授权记录变更、传播延迟和解析器特定故障。
- TCP和ICMP:确认端口开放且网络路径健康。防火墙屏蔽443端口不会在相同网络段的HTTP检查中体现。
- TLS:验证证书链、过期时间、主机名匹配和密码套件支持。大多数证书故障可预防——比如证书周日过期。应在60、30、14和3天时明确提醒。见如何监控SSL证书过期了解配置细节。
- HTTP:状态码、响应时间及内容断言。状态200但响应体为空视为失败检查,不是成功。
- 渲染和事务:驱动真实浏览器完成用户流程,断言最终状态的已知元素,并测量交互时间。合成监控使用真实浏览器能捕捉协议检查无法发现的问题——JavaScript错误、挂起的第三方脚本、缺失导致购物车按钮不可见的CSS文件。
- API:将API视为一流终端。站点加载成功但支付API超时导致无法完成结账,依然视为故障。API监控需要独立于依赖它的页面的检查计划。
出问题时,最先告警的层就是排查根因的起点。只监控HTTP的团队只能得到单一信息:故障;而全层监控团队拥有故障树。
合成监控和RUM并行运行,而非互相替代
两种方法回答不同问题,且并非相互替代。下表汇总了多数团队试用两季度后决定的配置分布。
| 能力 | 合成监控 | 真实用户监控(RUM) |
|---|---|---|
| 数据源 | 受控地点的脚本化检查 | 真实访客浏览器 |
| 可在无流量时工作 | 是 | 否 |
| 稳定基线 | 是—相同脚本,相同地点 | 否—随流量结构变化 |
| 在用户前捕捉回归 | 是 | 否 |
| 反映真实设备和网络多样性 | 有限 | 是 |
| 最佳用途 | SLA报告,主动告警,正常运行时间监控 | 真实体验分析,修复优先级排序 |
| 常见失败模式 | 遗漏未脚本化的边缘案例 | 通过Twitter获知故障 |
合成监控在固定时间表和地点运行脚本化检查。数据随时间保持一致,不受流量中断影响。它还能在凌晨3点在无真实用户注意到登陆页面崩溃时运行。这就是为何合成监控适合SLA报告、回归检测和主动告警。
RUM 捕捉真实浏览器的性能和错误数据,反映真实用户的设备、网络和地理分布。它是唯一能告诉你某移动运营商下2%的安卓用户首次字节时延达9秒的来源。RUM是了解真实体验和优先级排序的正确工具。
用合成监控确保站点在线并表现正常。用RUM了解这种表现如何映射到付费用户。选用其一而忽略另一方的团队,要么被边缘案例突袭(只用合成监控),要么从Twitter获知故障(只用RUM)。
从创收地区监控
邻近的数据中心检查只能告诉你数据中心是否在线,却不能告诉你圣保罗的用户体验如何。
规则简单:在所有有显著收入贡献的地区部署检查点,外加一到两个控制地区。如果35%的销售来自EMEA,至少需两个EMEA检查点——一个设在主要市场如法兰克福或伦敦,一个设在次要市场如马德里或斯德哥尔摩。单点EMEA覆盖掩盖了区域ISP故障和CDN边缘节点故障。
三种值得配置的模式:
- 多地区确认后再通知。要求至少两个不同地区在60秒内重复失败才通知。单一区域故障通常是区域运营商或单点故障,而非网站故障。
- 区域基线设定。东京和爱荷华的访问速度不同,不应使用统一阈值。应按地区跟踪p95延迟,依据区域偏离触发告警,而非全球平均。
- 企业网络内的私有代理。若向企业销售服务,且其从自有防火墙后访问,需在其环境内运行检查点。私有代理捕捉由客户网络引起的问题,这些问题对客户来说仍是你的问题。
Dotcom-Monitor检查点网络覆盖30多个国家;开启的具体节点取决于收入来源,而非数据中心所在。
基于基线而非圆整数字设置阈值
最常见的监控错误是“响应时间>3秒报警”。3秒是个圆整数字。你的网站不在意圆整数字。若实际p95为4.2秒且稳定,你每天会因正常行为被呼叫24次;若实际p95为0.8秒降至2.5秒,你却没有任何告警因为2.5秒低于3秒。
解决方案是基于基线的阈值:
当10分钟窗口内持续p95超过(baseline p95 × 1.5) 或 (baseline p95 + 2σ)中更大值,且条件持续两个连续评估窗口时触发告警。
该公式同时实现三点。1.5倍因子使不同快慢页面共享规则。2σ因子抑制正常波动。“两个连续窗口”规则屏蔽大多数因突发峰值而迅速恢复的虚假告警。
大多数团队跳过基线计算。应每周重算过去14天的基线,排除部署窗口和已知事件期。若不愿手动管理,可用自动基线的异常检测产品,但必须验证其排除逻辑。被上周事故污染的基线比无基线更糟。
正常工作时间检查的等效规则是:须两次连续且来自不同地区的失败检查才通知。单点失败基本都是监测点故障。双点故障才是真实故障。
设计告警,而不仅仅是检查
检查告诉你事件发生了。告警驱使人来处理。两者是不同问题,但多数团队只设计了前者。
告警设计的任务是把正确的信息以能在60秒内行动的形式送达正确的人。阻碍通常是:
- 告警过多。如果值班工程师每班被叫超过三次,下一次告警会被敷衍应对。这不是道德问题,而是人类注意力的自然表现。
- 无情境的告警。“结账慢”不可执行;“结账p95 4.8秒(基线1.1秒),欧洲地区,14:32 UTC开始,关联14:30部署abc123”则可执行。
- 渠道错误。Slack非呼叫告警;邮件非呼叫告警;短信、推送或电话才是呼叫。混用渠道会稀释信号。
有效模式:
- 三级严重性、三种渠道。严重(网站宕机、支付失效)→短信或电话。警告(持续降级)→推送或带值班标记的聊天。信息(单次失败、基线漂移)→仪表盘或日报。信息不呼叫。
- 依赖抑制。DNS失败时不同时呼叫依赖DNS的14个HTTP检查。告警分组和依赖抑制是基本功能,不支持即是失眠之源。
- 升级网络非链条。主值班5分钟未确认,呼叫次值班并通知频道。串行升级耗时长,网站故障期间每跳耗时5分钟。
- 非关键告警静音时间。周日凌晨2点的性能回归通常不需要叫醒。关键告警需要。配置规则时要诚实区分两者。
测量精准度。每月统计触发的告警,标记为真实事件、误报、无需行动。精准度低于80%时,先修复最噪声告警再新增。
覆盖不可控部分
你的网站不仅是你的代码。现代结账页加载支付处理、标签管理、分析、聊天、小工具、A/B测试、CDN,甚至欺诈检测等第三方脚本。任何一方故障都能导致整页崩溃。
第三方依赖需独立监控:
- 每区域CDN边缘响应时间。CDN确实会在区域事件中失效。
- 支付网关往返时间。作为针对支付网关状态端点或沙箱的合成API检查。
- 标签管理和分析脚本加载时间。作为合成事务一部分测量。阻塞性分析标签每页会加2秒延迟;需知晓。
- 外部认证提供商(OAuth、SSO)。例如“用谷歌登录”按钮失效,要先知道,别等支持工单炸锅。
- DNS提供商。从多个解析器进行DNS监控,捕捉传播延迟和部分故障。
记录各第三方阻断哪些用户流程。事件发生时,运行手册需明确正确操作是“回退”、“等待恢复”还是“呼叫供应商值班”。无此映射,所有第三方事件均成为即兴演出。
为每个监控绑定运行手册
事故最贵的五分钟是值班工程师试图理解告警含义的时间。
这项工作只需做一次:每个监控链接至一个运行手册条目。手册无需复杂。三部分足矣:
- 检查涵盖内容一句话说明。(“验证法兰克福和阿姆斯特丹的EU结账事务完成时间低于5秒。”)
- 触发时首先检查的五件事。状态页面链接、仪表盘、最近部署、相关告警、供应商状态页。
- 已知的误报模式,如有。(“法兰克福检查点偶尔因供应商维护窗口(周六UTC 02:00-02:30)超时,已抑制。”)
初次撰写需15分钟,后续每次事故节省15分钟。计算显而易见但多数团队仍未实践。
季度验证监控与覆盖审计
未经测试的监控只是愿望,不是保障。两种做法可发现缺口。
混沌演练告警。每季度有意破坏某检查——关闭测试端点、让阶段环境证书过期、将响应阈值降至0——确认告警触发、升级并送达正确人员。约三成告警首次演练失败。常见原因:过时的值班轮换、过期的集成令牌、无人维护的Slack频道。
季度覆盖图审计。维护一份文档列出所有用户流程、外部依赖和URL分类。标明覆盖的监控。空行即缺口。新功能通常落在缺口行。
审计还会发现反向问题:覆盖已不存在URL的监控。删除它们。针对410端点的监控永远制造噪音,却无保护作用。
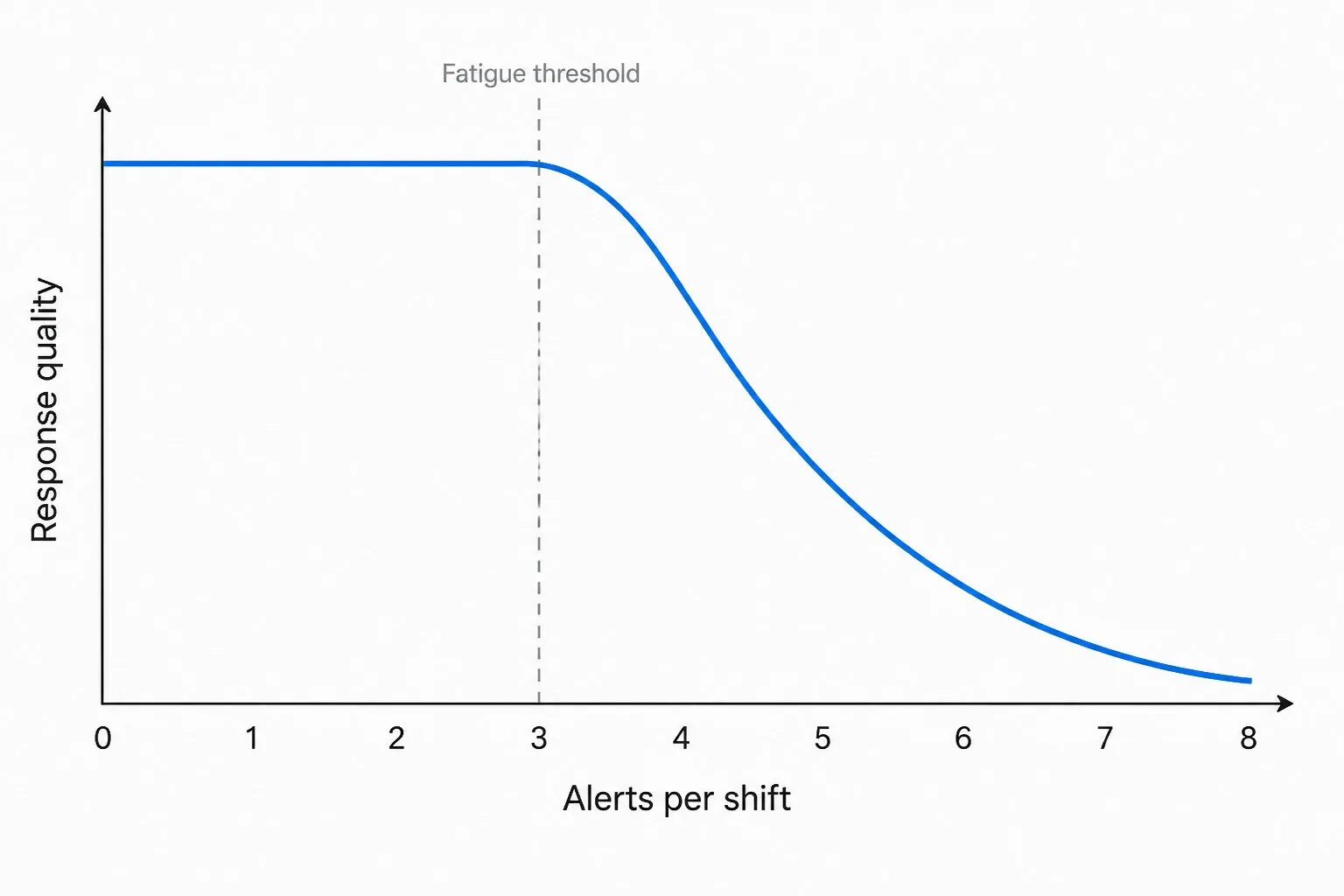 每班超过三次告警,响应质量下降比告警量增长更快。
每班超过三次告警,响应质量下降比告警量增长更快。
监控平台选择要点
多数平台能ping一个URL。真正差异在难题上。评估工具时,超越仪表盘演示,问:
- 能否脚本化真实浏览器事务并支持条件逻辑?静态录制页面一变即断。可脚本化事务监控(Selenium式或专有)能应对正常产品迭代。
- 支持多少原生协议?HTTP、HTTPS、DNS、FTP、SMTP、IMAP、POP3、TCP、UDP、ICMP。每外包一个即多一个供应商关系和登录账户。
- 全球检查点布局如何?200个“检查点”却仅三个云区域的供应商并非全球。要城市列表。
- 能否在内部网络运行?私有代理必需用于阶段环境、内部应用和客户私有部署监控。
- 如何处理告警依赖和分组?一个DNS故障却呼叫14次的系统让人暴躁。
- 数据导出形式?无法导出原始检查结果至自建分析堆栈,将无法排查疑难事件。
- 与事故工具集成?PagerDuty、Opsgenie、Slack、Microsoft Teams、ServiceNow、Jira。原生集成胜过Webhook拼接。
欲了解更完整买家清单及评分标准,见如何选出最佳网站监控工具及Datadog竞品与替代方案,了解各选手定位。
常见失败模式
以下模式几乎贯穿所有监控复盘。均不需新工具即可改正。
- 多区域站点用单一全局阈值。快区上升,慢区退化,全球均值无异常,告警未触发。
- 状态200检查无内容断言。CDN错误页空白200响应通过检查,上线即死。
- 依赖真实账户的合成事务。密码过期、多因子认证激活、账户锁定。用具专属监控权限的服务账户。
- 仅7天证书告警。7天是截止日非预警。届时多已告急。应在60、30、14、3天告警。SSL证书监控应先在测试环境部署。
- 无部署关联。告警若未显示“3分钟前部署abc123后触发”,每次事件都需手工查git日志。将CI与监控注解联通。
- 告警阈值从未收紧。两年前设“>5秒”阈值,现站点速度翻倍,阈值形同虚设。
- 监控主页未监控关键业务流程。主页可用是虚荣指标,结账、注册和登录可用才是业务指标。
关于应用层细节——尤其是API、脚本化旅程和微服务拓扑,可配合Web应用监控最佳实践阅读。SEO层面为何延迟预算重要,见网站速度如何影响SEO。
将操作手册付诸实践
从清单中选三条当前未覆盖的实践,本次迭代实现。完成后用混沌演练验证新监控。30天后审计精准度。
若平台成瓶颈,Dotcom-Monitor一站式覆盖全堆栈:真实浏览器合成监控、多协议检查、全球检查点网络带私有代理,以及针对上述模式打造的告警工程功能。见Web应用监控、API监控、DNS监控、SSL证书监控,或直接看企业监控概览,适用更大环境。
