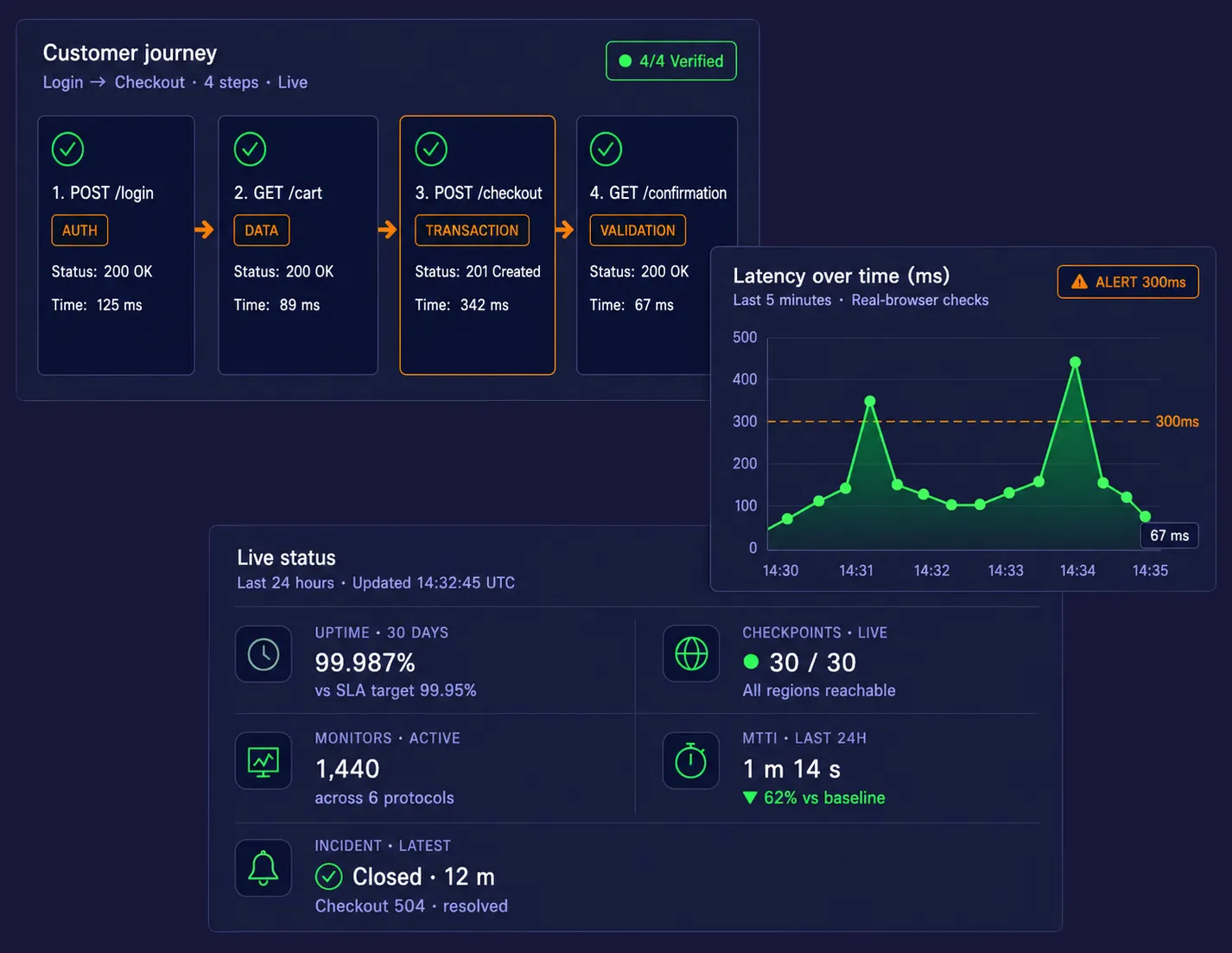
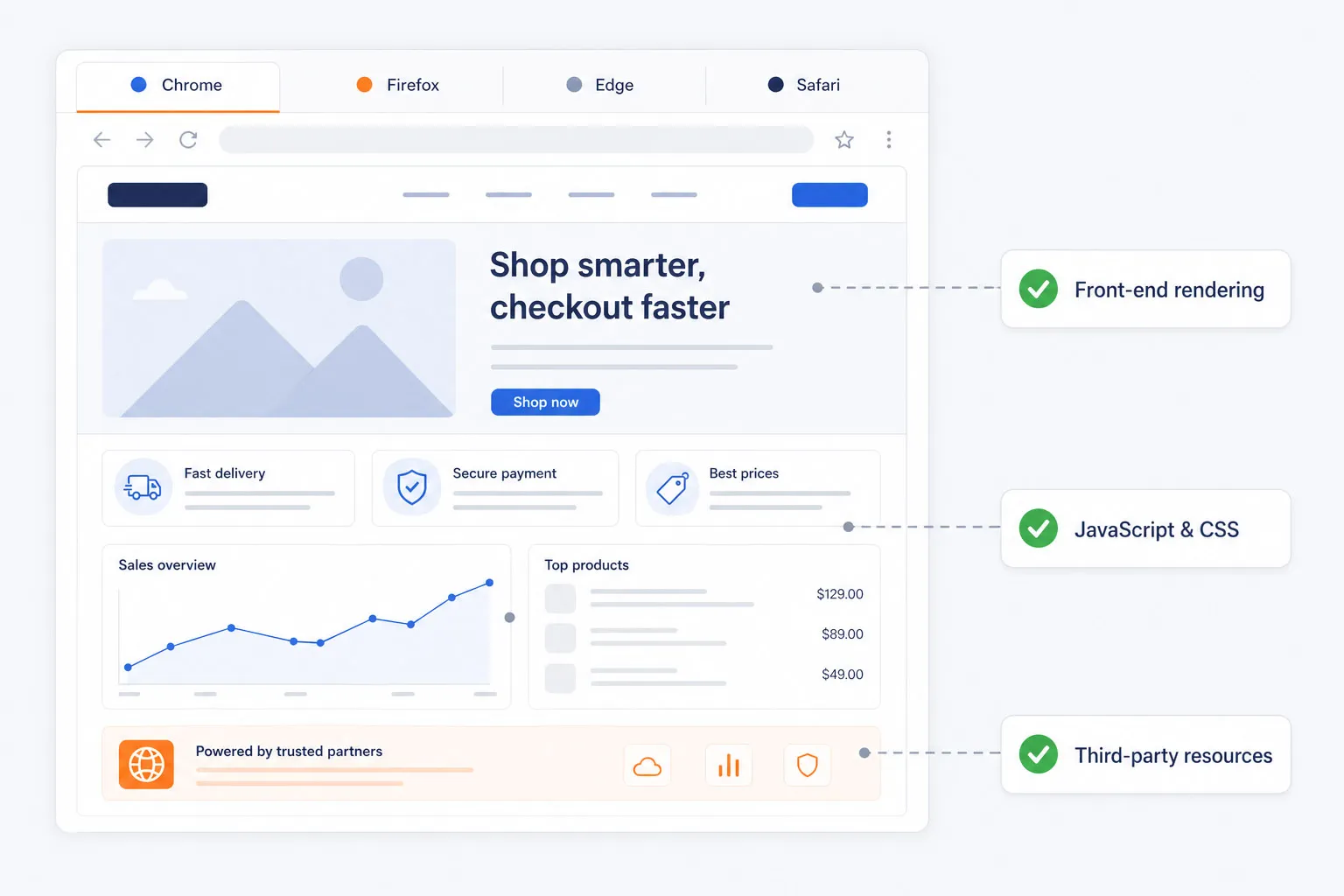
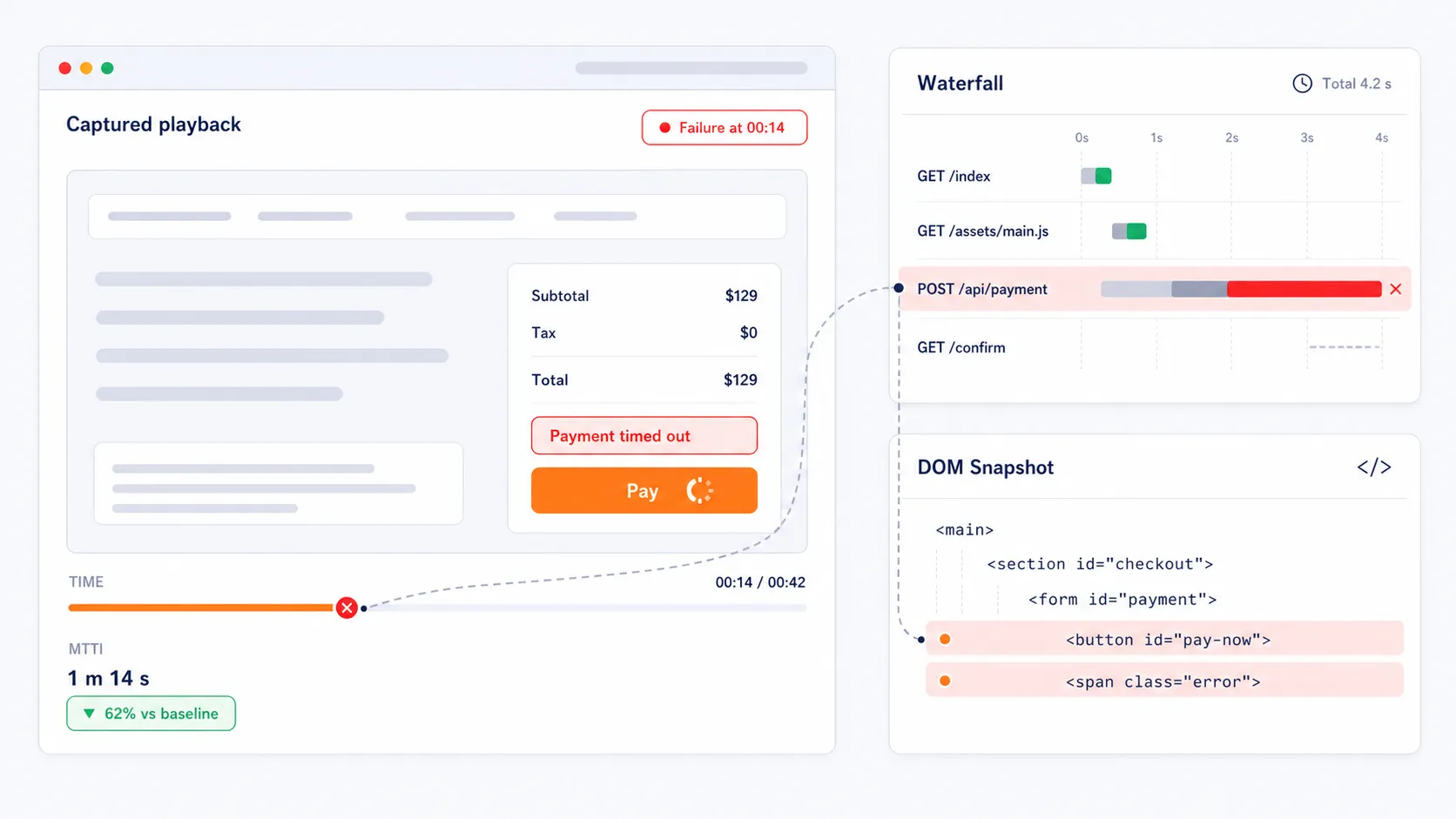
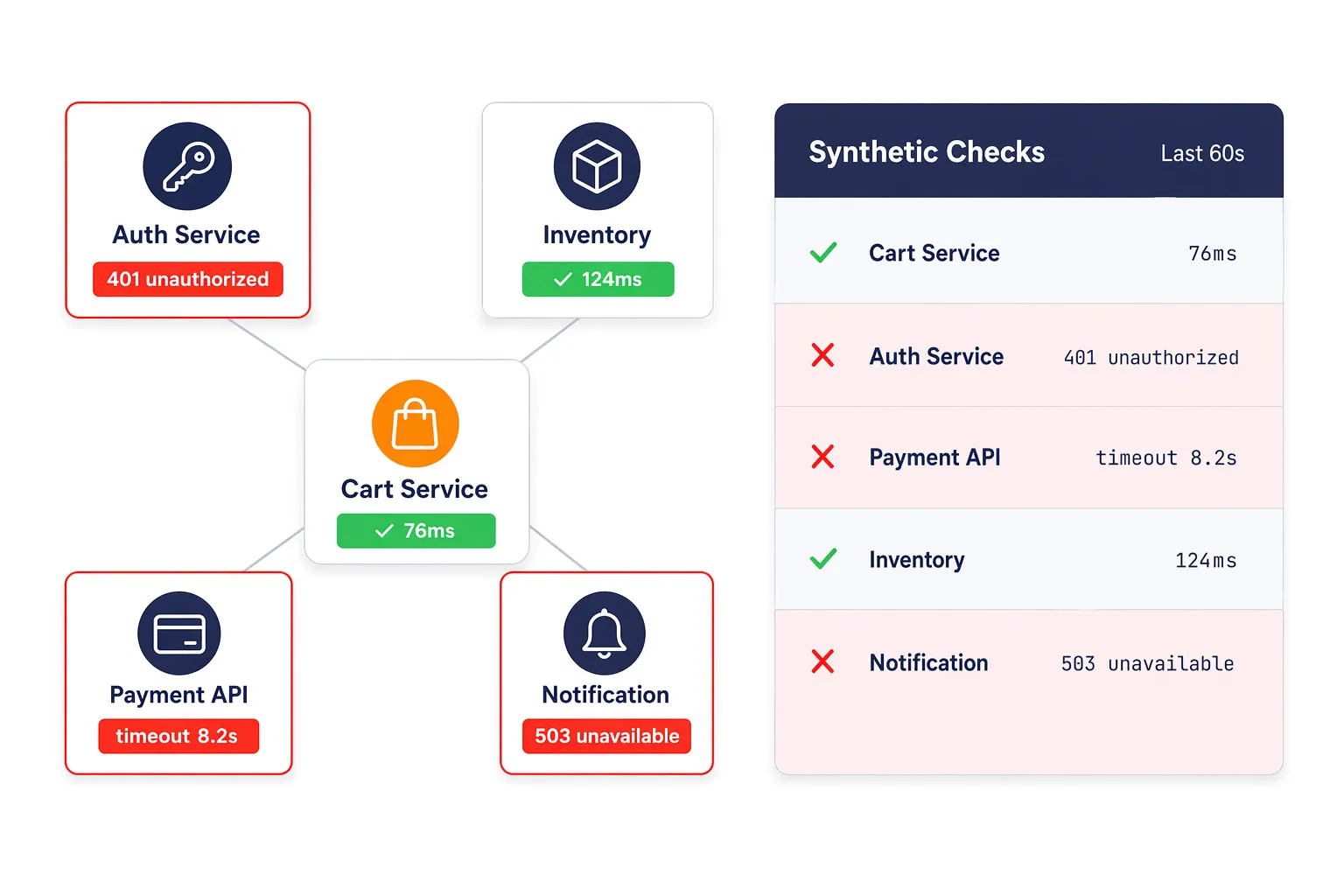
Synthetic monitors are categorized by the technical depth of the check: Web Uptime monitors handle basic protocol checks like DNS, FTP, and SSL certificate expiration. Web API monitors validate the functionality of REST, SOAP, and WebSocket responses. Web Application (UserView) monitors utilize a full browser engine to simulate multi-step transactions. Finally, Media Streaming monitors verify the availability and quality of audio and video playback.