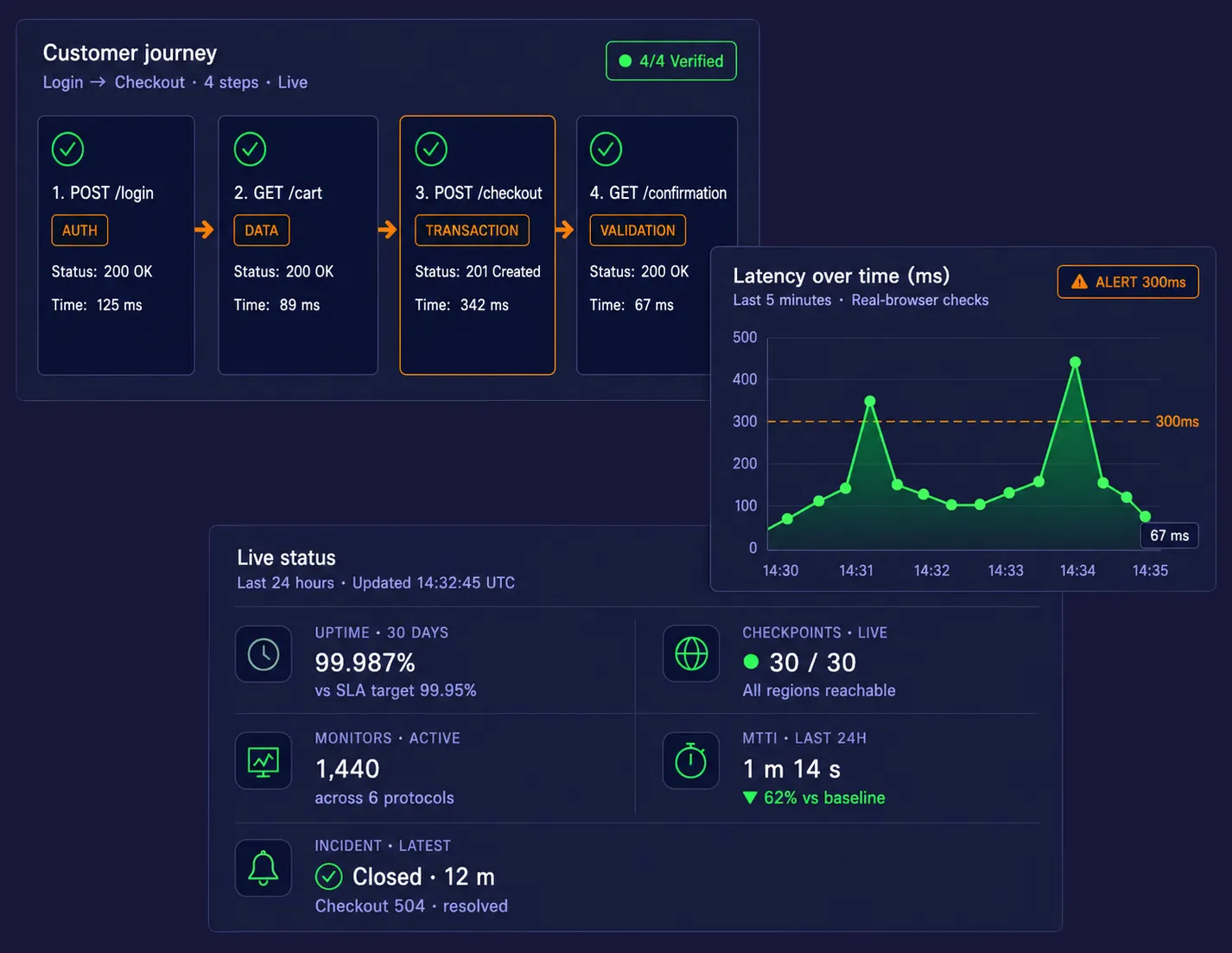
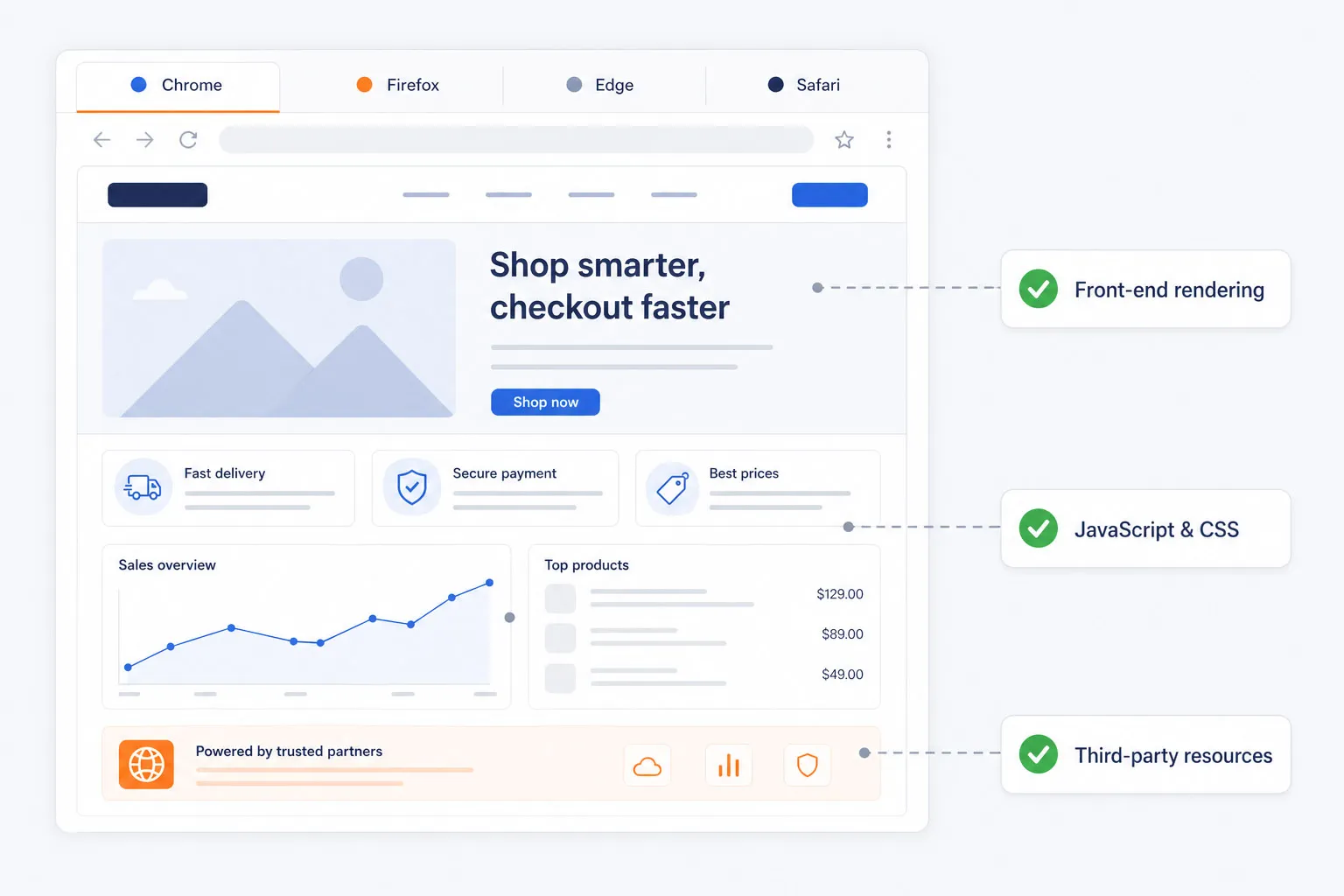
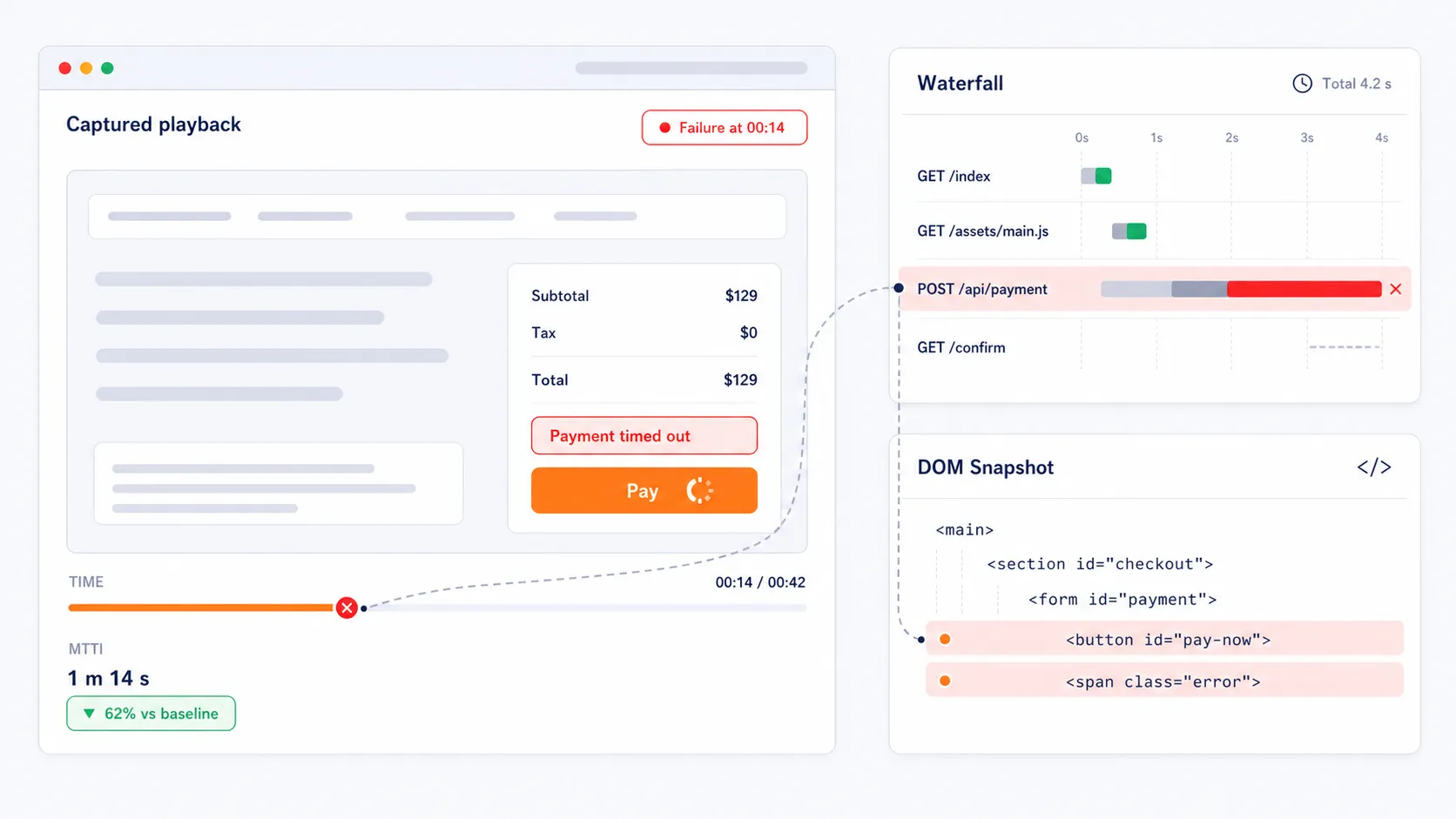
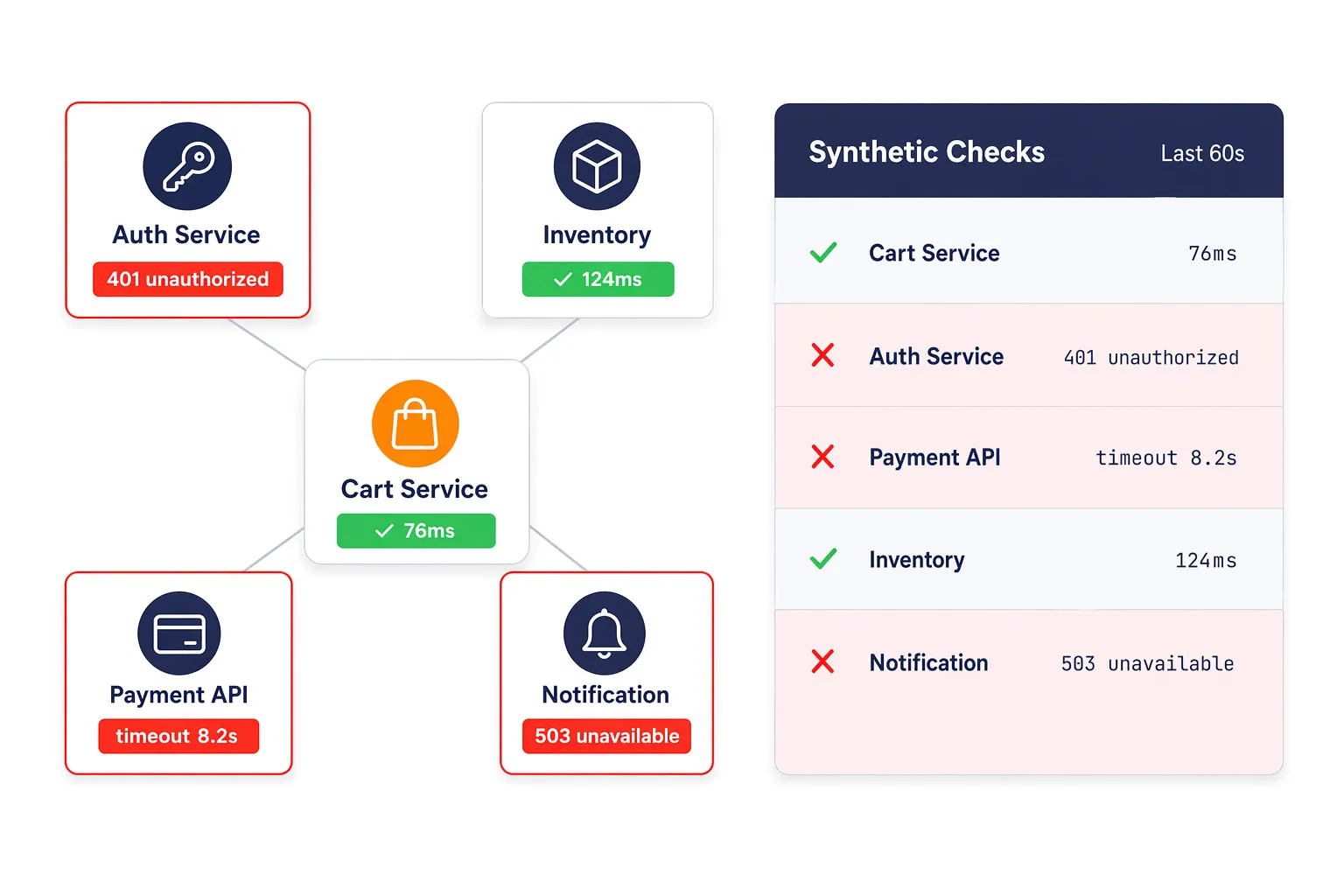
EveryStep Web Recorder を使用して、サイトやアプリケーションとの対話だけで合成監視スクリプトを作成します。マルチページのチェックアウト、SSOログイン、アカウント登録、限定ダッシュボードアクセス、カート操作などの複雑なワークフローを手動スクリプト不要で記録可能。このノーコードアプローチにより、収益に直結する重要な経路を保護しつつ、ウェブアプリケーション監視 を迅速に導入できます。
"I absolutely love the comprehensive monitoring services Dotcom-Monitor provides. The real-time alerts and detailed performance analytics have been a game-changer for our website's uptime and speed. The global monitoring feature ensures that our site is optimized everywhere, and the intuitive dashboard makes it easy to track performance. Their customer support is exceptional — always responsive and efficient."
Tomer C.
Managing Director · Facilities Services
Verified Capterra review · March 2025
"One of Dotcom's best features is the push/pull API capabilities that provide us with network performance data. We use this to monitor for performance issues as well as page loading stats. Dotcom-Monitor allows us to monitor multiple services within one interface and platform. It's allowed us to operate more efficiently."
Gregory S.
Manager · Broadcast Media
Verified Capterra review · May 2020
"I have been thoroughly impressed with the level of detail and comprehensiveness of the reports generated by the software. Moreover, the support team at Dotcom-Monitor has exceeded my expectations. On almost a daily basis, I reach out with various questions and they have consistently demonstrated unwavering patience, providing detailed and insightful answers."
Shirin R.
Software Test Engineer · Computer Software
Verified Capterra review · February 2023
"I'm a network analyst and use Dotcom tools inside the ISP I work, it's a really good and reliable tool for monitoring things along the network, and testing network components, I usually use it to make diagnostics of servers latency, and dns resolve time."