Software de Monitoramento Sintético Automatizado para Aplicações, APIs e Websites
O software de monitoramento sintético do Dotcom-Monitor simula o comportamento real do usuário 24/7 para detectar jornadas de usuário quebradas e falhas "silenciosas" antes que impactem seus clientes. Monitore websites, APIs e aplicações web complexas em mais de 30 localizações globais com testes em navegador real, reproduções detalhadas em vídeo, relatórios em gráfico waterfall e alertas proativos de desempenho.
Primeiros Alertas
Em 10 minutos
Teste de 30 Dias
Todos os recursos
Suporte 24/7
Equipe especialista
- Cartão de crédito não requerido
- Todos os recursos premium incluídos
10.000+
Organizações em todo o mundo
99,99%
SLA de Tempo de Atividade da Plataforma
30+
Localizações Globais de Monitoramento
Desde 1998
Líder em Monitoramento de Websites
62%
redução no MTTR
“Capturamos uma regressão na API de pagamento em 90 segundos após o deployment. Antes do Dotcom-Monitor, isso teria sido um ticket P1 de um cliente três horas depois.”
Michael Reeves
Sr. SRE, Plataforma SaaS Empresarial
$140K
em perdas evitadas por tempo de inatividade
“O monitoramento sintético apenas no nosso fluxo de checkout pagou a plataforma no primeiro mês. Agora detectamos falhas de autenticação antes que um único usuário seja afetado.”
Sarah Kim
VP de Engenharia, Fintech B2B
4.5
Capterra
82 avaliações
4.5
G2 | Mais fácil de usar
Usuários adoram · 2025
4.5
Software Advice
Recomendado
Comece em minutos
Configure seu software de monitoramento sintético em apenas 3 passos
Sem agentes para instalar. Sem mudanças de código. Configure seu primeiro monitoramento sintético e receba alertas antes que seus usuários percebam que algo está errado.
Gravar
Abra o EveryStep Recorder e navegue pelo seu site.
Implantar
Escolha entre mais de 30 checkpoints globais.
Resolver
Receba um aviso no momento em que uma jornada falha - com um vídeo.
Passo 01
Passo 02
Passo 03

Grave Jornadas Reais de Usuários com EveryStep
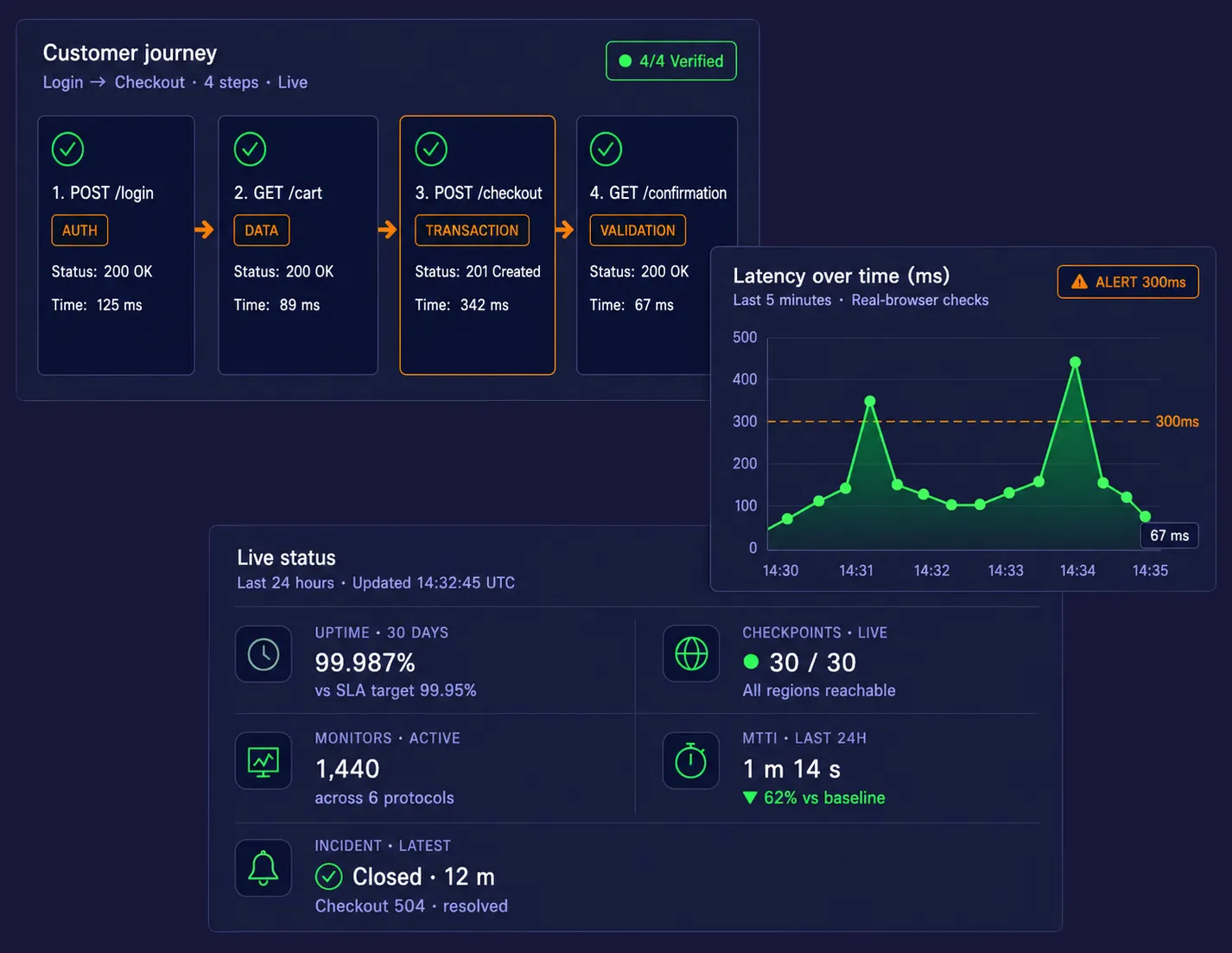
Use o EveryStep Web Recorder para criar scripts de monitoramento sintético simplesmente interagindo com seu site ou aplicação. Grave fluxos de trabalho complexos, como checkout em várias páginas, login SSO, registro de conta, acesso a painéis restritos e ações no carrinho sem necessidade de script manual. Essa abordagem sem código facilita a implementação rápida do monitoramento de aplicações web enquanto protege os caminhos que geram receita e que são mais importantes.
Teste em Navegadores Reais, Não em Simulações Simplificadas
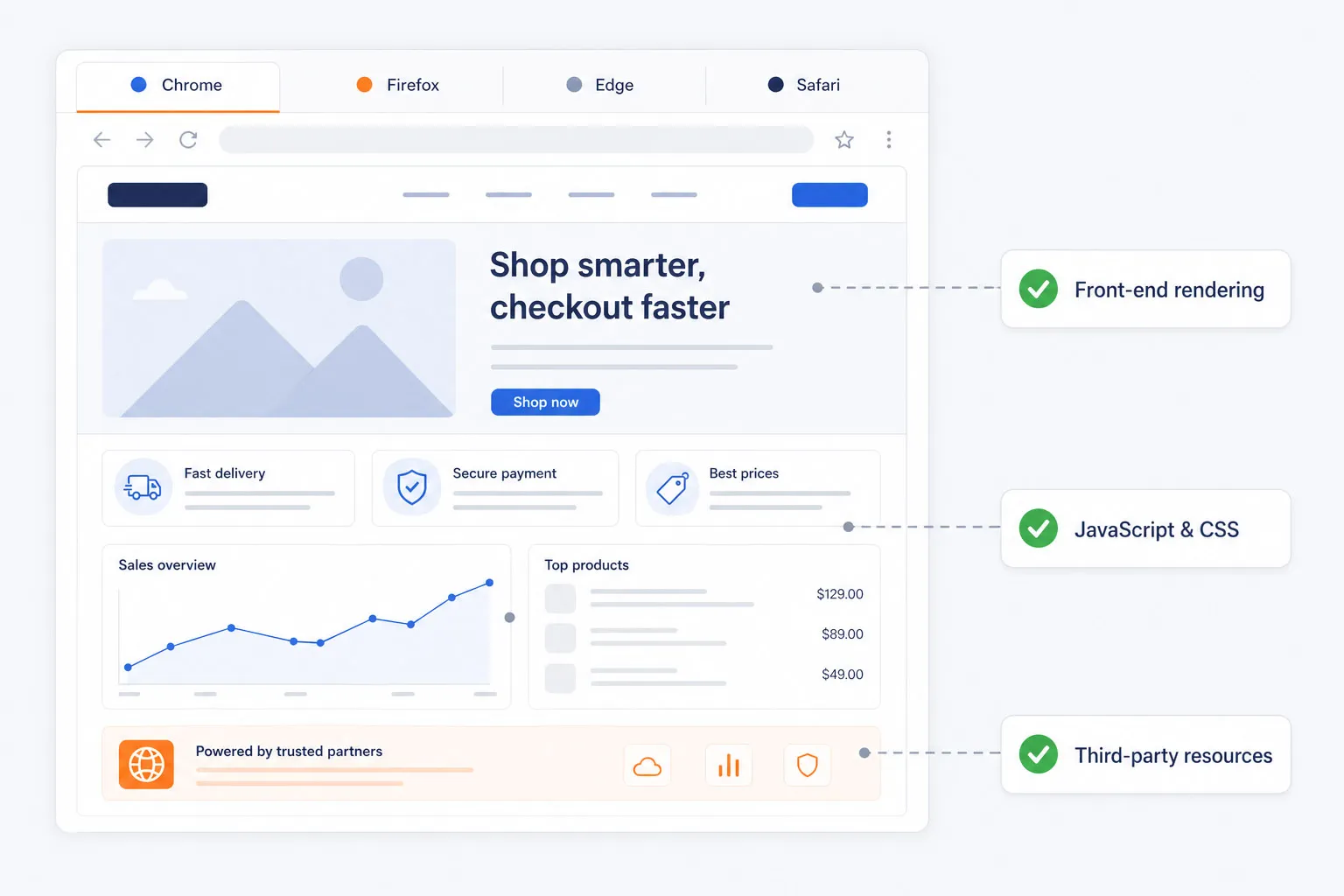
Verificações básicas de disponibilidade não capturam problemas de renderização front-end, erros de JavaScript, problemas de CSS ou recursos lentos de terceiros. O Dotcom-Monitor executa testes sintéticos em navegadores reais Chrome, Firefox, Edge e Safari para que as equipes possam validar desempenho e funcionalidade exatamente como os usuários experimentam.
Isso oferece às equipes de engenharia, QA e digitais uma visão mais precisa da saúde real das aplicações web.
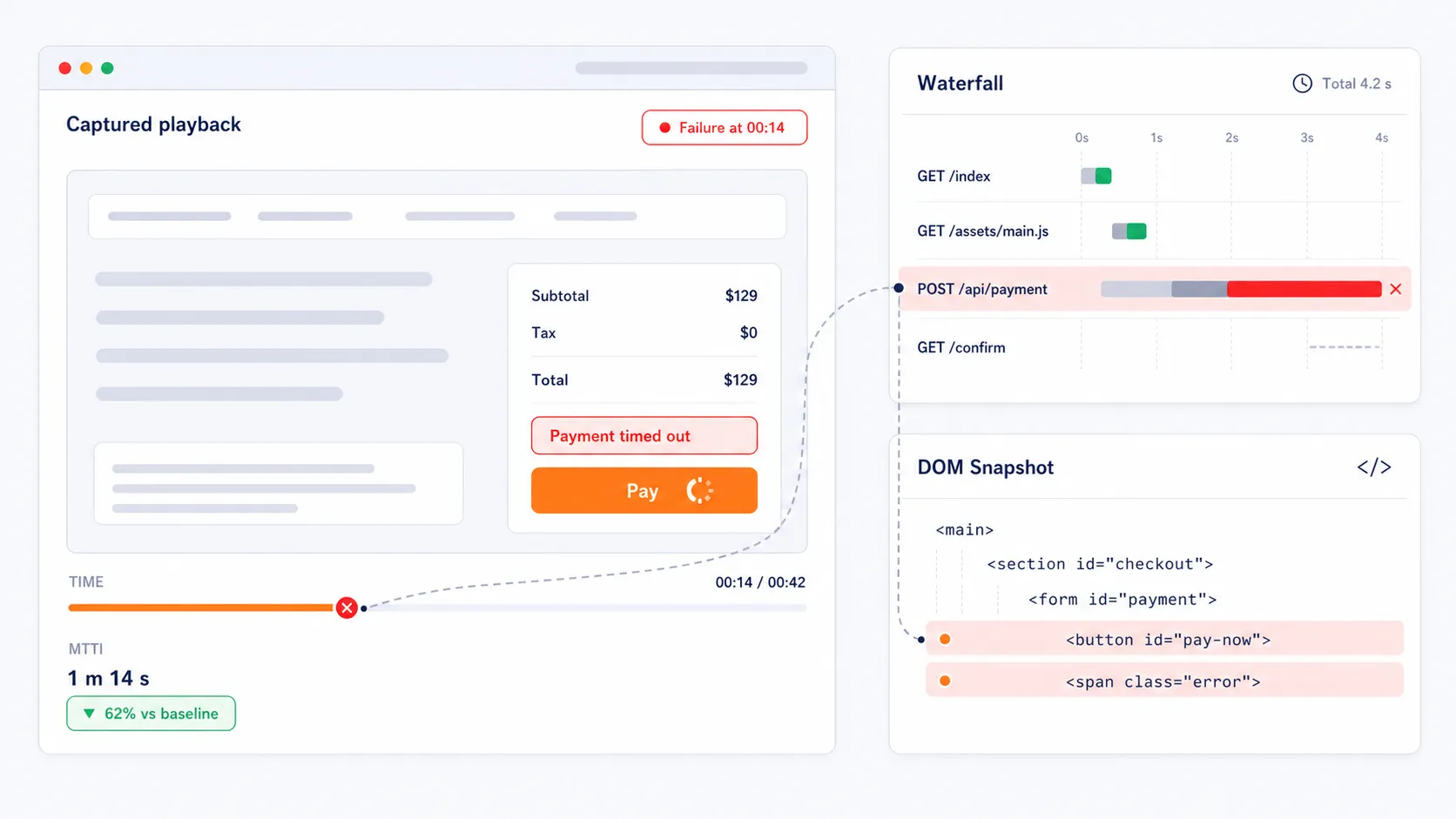
Capture Evidências Visuais para uma Solução de Problemas Mais Rápida
Quando uma transação falha, a plataforma captura reprodução em vídeo da execução do teste que falhou, gráficos em cascata e instantâneos completos do DOM. Esses diagnósticos visuais ajudam as equipes a acelerar a análise da causa raiz, mostrando a chamada exata da API, elemento de página, redirecionamento ou script que causou a falha na jornada. Em vez de adivinhar onde está o problema, as equipes obtêm evidências imediatas que reduzem o Tempo Médio para Identificação.
Detecte Falhas Silenciosas na Conversão Antes que a Receita Seja Perdida
Um site pode parecer disponível enquanto ações críticas como login, checkout, busca ou acesso à conta falham silenciosamente em segundo plano. Essas falhas silenciosas podem diminuir as taxas de conversão, desperdiçar tráfego pago e prejudicar a confiança do cliente. O Dotcom-Monitor ajuda as equipes a detectar esses problemas com verificações sintéticas que podem ser executadas a cada 60 segundos, dando às equipes digitais uma maneira proativa de proteger a experiência do cliente e a receita online.


Implemente com Confiança do Ambiente de Staging para Produção
O monitoramento sintético não é apenas para alertas em produção. As equipes podem direcionar monitores para ambientes de staging ou integrá-los em fluxos de trabalho CI/CD para executar testes básicos nos caminhos críticos antes e depois do lançamento. Isso ajuda a prevenir bugs no Dia 1, protege as jornadas de usuário importantes e dá mais confiança para implementar rapidamente sem quebrar funcionalidades existentes.
Comece a Monitorar Suas Aplicações Web em Menos de 10 Minutos
Reduza o tempo de indisponibilidade, detecte problemas antes que seus clientes o façam e comprove o cumprimento do seu SLA. Todos os recursos inclusos no teste. Sem cartão de crédito. Cancele a qualquer momento.
- Cartão de crédito não requerido
- Todos os recursos inclusos
- Configuração em 5 minutos
- Suporte 24x7
Software de Monitoramento Sintético para APIs e Microsserviços

Validar Disponibilidade, Precisão e Latência da API
Dotcom-Monitor monitora REST e SOAP APIs para desempenho e correção, ajudando equipes a verificar se os endpoints retornam as cargas úteis esperadas, códigos de status e tempos de resposta. Ao verificar o comportamento do serviço continuamente, as equipes podem detectar problemas mais cedo e manter operações de backend mais confiáveis.
Detectar Timeouts, Cargas Úteis Erradas e Falhas de Autenticação Mais Cedo
Problemas de API e microsserviços frequentemente surgem primeiro como funcionalidades degradadas, transações lentas ou erros intermitentes. Verificações sintéticas de API ajudam as equipes a capturar timeouts, autenticação falhada, respostas ruins e interrupções de serviço antes que eles se tornem problemas visíveis para o cliente.
Isso é especialmente valioso em arquiteturas distribuídas onde múltiplos serviços backend influenciam uma única jornada do usuário.
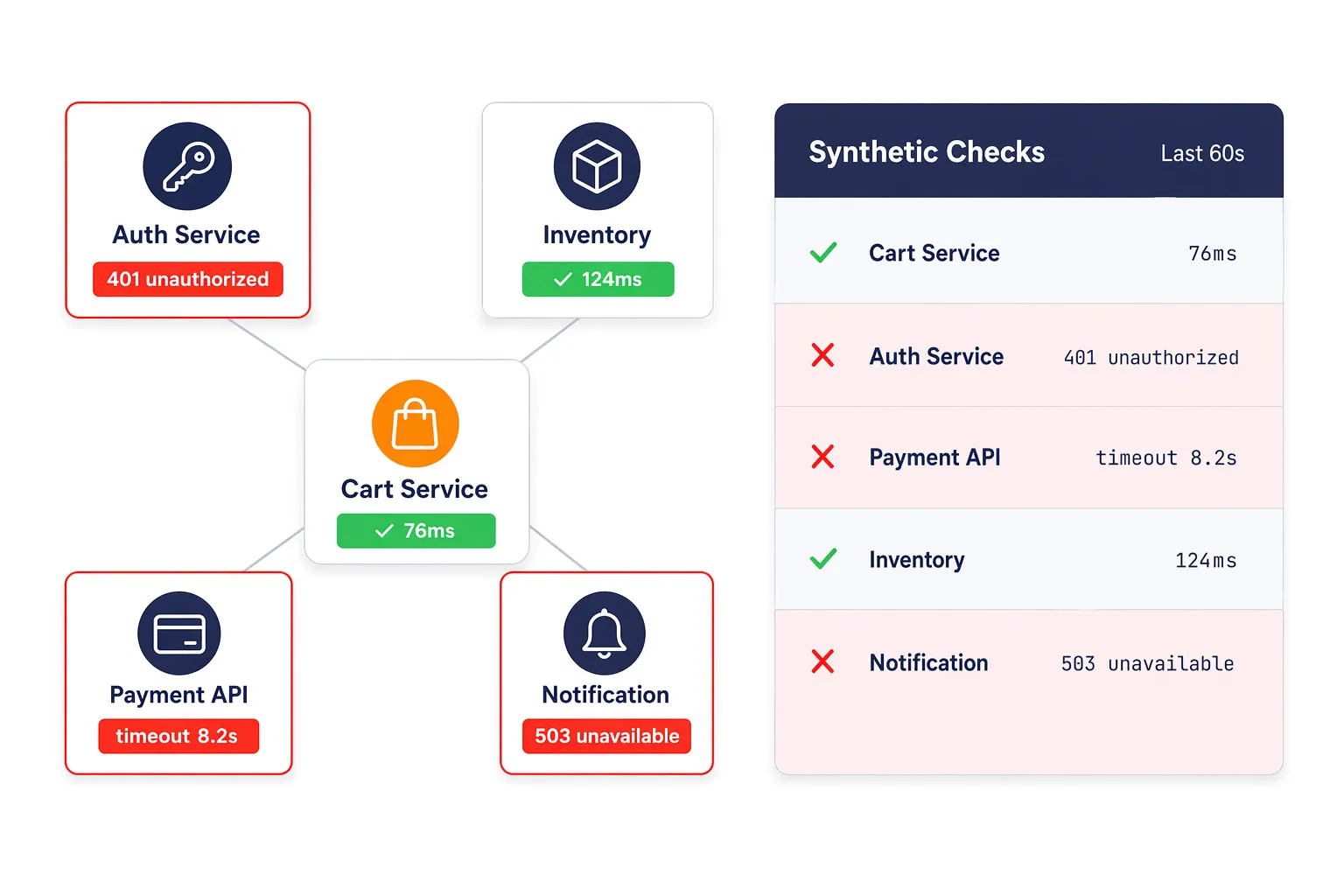

Suportar Validação de Autenticação e Nível de Serviço
A confiabilidade do backend não é apenas sobre tempo de atividade. As equipes também precisam validar o comportamento de autenticação, trocas de token e respostas de serviços críticos para o negócio. Dotcom-Monitor ajuda a verificar essas condições de forma proativa para que falhas possam ser tratadas antes de afetar aplicações dependentes ou fluxos de trabalho do cliente.
Acelere a Análise da Causa Raiz para Incidentes de Serviço
Quando uma falha é detectada, as equipes podem revisar os detalhes diagnósticos necessários para identificar o serviço com problema mais rapidamente. Isso proporciona às equipes de DevOps, SRE e plataformas um ponto de partida mais sólido para remediação e ajuda a reduzir o tempo gasto buscando a origem de um incidente no backend.

Valide Suas APIs Antes que os Usuários Sintam a Falha
- Cartão de crédito não requerido
- REST, SOAP, múltiplas etapas e alertas incluídos
- Suporte 24x7
Monitoramento Sintético da Web para Sites e Experiência Digital Pública

Monitore a Disponibilidade do Site a partir de mais de 30 Localizações Globais
Dotcom-Monitor oferece monitoramento sintético a partir de mais de 30 pontos globais, ajudando equipes a entender como os sites performam em grandes regiões de clientes. Isso torna mais fácil identificar latência regional, falhas localizadas e pontos cegos que seriam perdidos pelo monitoramento de uma única localização.
Vá Além do Tempo de Atividade com Visibilidade de Desempenho
O monitoramento sintético de sites não deve parar em determinar se uma página responde. Dotcom-Monitor ajuda equipes a analisar gargalos de desempenho com relatórios de gráfico cascata e diagnósticos baseados em navegador que revelam scripts lentos, ativos pesados e outros problemas que degradam a velocidade da página e a experiência do usuário.


Melhore os Core Web Vitals e a Visibilidade nas Buscas
Desempenho em buscas e experiência digital estão intimamente conectados. Dotcom-Monitor auxilia equipes a monitorar condições que influenciam métricas como Largest Contentful Paint e Cumulative Layout Shift em ambientes controlados. Ao identificar recursos de terceiros que carregam lentamente e o desempenho do CDN antecipadamente, as equipes podem melhorar a estabilidade do site, proteger o desempenho de SEO e entregar experiências mais rápidas.
Transforme Dados de Confiabilidade em Relatórios Úteis
Para organizações empresariais e provedores de serviço, confiabilidade muitas vezes precisa ser documentada, não apenas observada. Dotcom-Monitor suporta painéis automatizados e relatórios orientados para SLA que ajudam equipes a demonstrar compromissos de tempo de atividade e desempenho com dados coletados de uma rede global de monitoramento.
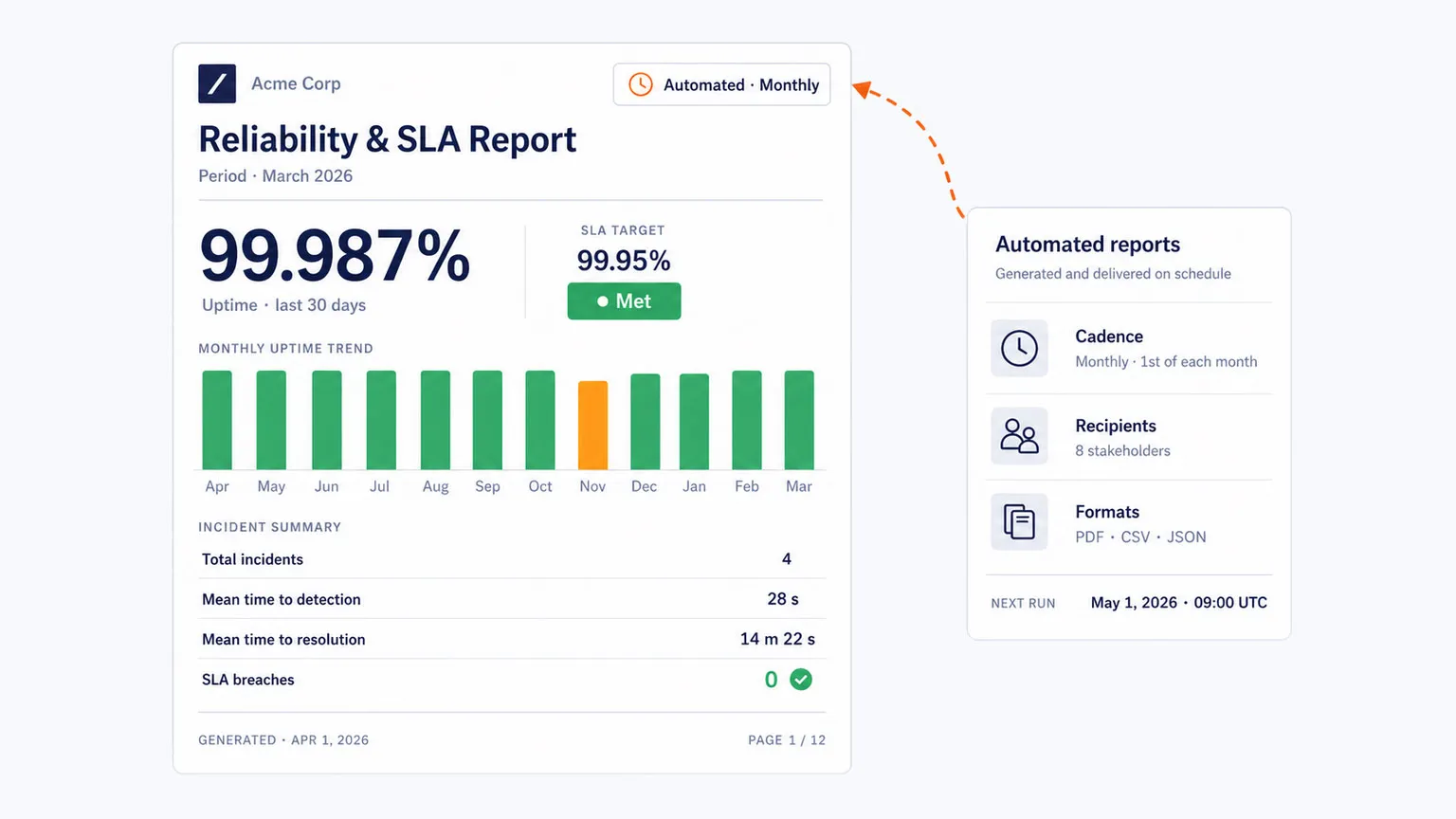
Comece a Monitorar a Disponibilidade do Site Globalmente
- Cartão de crédito não requerido
- Todos os recursos inclusos
- Configuração em 5 minutos
- Suporte 24x7
Monitoramento Sintético para Autenticação, Aplicativos Internos e Empresas Avançadas

Monitore Fluxos de Autenticação SSO e MFA
Os fluxos de autenticação Single Sign-On e Multi-Factor Authentication frequentemente dependem de redirecionamentos encadeados, provedores de identidade, trocas de tokens e sessões protegidas que podem falhar de maneiras difíceis de diagnosticar. O Dotcom-Monitor pode simular essas jornadas de autenticação em múltiplas etapas para que as equipes identifiquem falhas, problemas de redirecionamento e erros de acesso antes que os usuários sejam bloqueados em sistemas críticos.
Implante Agentes Privados Atrás do Firewall
Muitas aplicações empresariais, incluindo portais internos para funcionários, ferramentas proprietárias, intranets e sistemas ERP, ficam atrás dos firewalls corporativos. O Dotcom-Monitor suporta agentes sintéticos privados, também chamados de Nós Privados, que podem ser implantados dentro do seu próprio ambiente para monitorar aplicações internas a partir de um ponto de vista seguro e interno.


Isole o Impacto de Scripts de Terceiros e Instabilidade do DOM
Experiências digitais modernas dependem de tags de análise, widgets de chat, scripts externos e outros elementos de terceiros que podem bloquear o carregamento e introduzir instabilidade no layout. O monitoramento sintético com navegador real ajuda as equipes a isolar qual recurso externo está desacelerando a experiência ou afetando a estabilidade da página para que possam otimizar a estratégia de carregamento e reduzir o atrito para o usuário.
Reproduza Falhas Intermitentes Durante Eventos de Alto Tráfego
Problemas intermitentes em E-commerce e SaaS podem ser difíceis de capturar durante períodos de pico de tráfego. O monitoramento sintético ajuda a reproduzir falhas enfrentadas pelo usuário executando repetidamente toda a lógica da transação, facilitando a captura de evidências de lentidão da API, erros no frontend ou problemas de desempenho no backend que só aparecem sob pressão.

Garanta que sua Infraestrutura de Negócios esteja Funcionando
- Cartão de crédito não requerido
- Todos os recursos inclusos
- Configuração em 5 minutos
- Suporte 24x7
Por Que as Equipes Escolhem Dotcom-Monitor para Monitoramento Sintético

Reduza o Tempo Médio para Identificação
As quedas se tornam mais caras quanto mais tempo as equipes gastam para encontrar o problema. Com diagnósticos visuais, reprodução sincronizada, dados de waterfall e alertas contextuais, o Dotcom-Monitor oferece às equipes um ponto de partida rápido para solução de problemas.
Monitoramento de Transações Sintéticas Sem Código
As equipes podem gravar fluxos de trabalho complexos sem escrever scripts manualmente, facilitando o lançamento rápido do monitoramento e mantendo a cobertura alinhada com a forma como um usuário real navega em seu site.


Receba Alertas Proativos nas Ferramentas Que Sua Equipe Já Usa
O Dotcom-Monitor integra alertas proativos aos fluxos de trabalho existentes por meio do Slack, PagerDuty, Microsoft Teams e ServiceNow, ajudando as equipes a responder mais rápido quando são detectados problemas de desempenho ou disponibilidade.
Correlacione a Experiência do Front-End com Sinais da Infraestrutura
O Dotcom-Monitor oferece visibilidade em websites, aplicações, APIs e verificações em nível de infraestrutura como DNS, FTP e TCP. Isso ajuda as equipes a conectar a saúde do backend e o comportamento da rede com a experiência digital real que os usuários recebem.

Obtenha respostas
Perguntas Frequentes
Posso implantar Agentes Privados atrás do firewall da minha empresa?
Sim, o Dotcom-Monitor permite que você implante Agentes Privados (também conhecidos como Nós Privados) especificamente para monitorar aplicações por trás do firewall corporativo. Essa capacidade é essencial para acompanhar o desempenho e a disponibilidade de portais internos para funcionários, intranets ou ferramentas de RH que não são acessíveis pela internet pública.
O que é um agente sintético privado?
Um agente sintético privado é uma instância de software leve instalada em seu próprio servidor local ou nuvem privada que atua como um ponto de observação interno seguro. Ao contrário dos nós de monitoramento públicos que ficam em data centers globais, um agente privado simula a experiência de um funcionário real ou sistema interno dentro da infraestrutura da sua própria rede.
Qual a diferença entre APM e monitoramento sintético?
A principal diferença está na direção da observação: o Application Performance Monitoring (APM) é uma estratégia “de dentro para fora” que usa agentes instalados em servidores para rastrear a execução interna do código, consultas de banco de dados e uso de recursos de hardware para identificar gargalos no backend. Em contraste, o Monitoramento Sintético é uma abordagem “de fora para dentro” que usa scripts para simular o comportamento do usuário final – como fazer login ou finalizar uma compra – para detectar proativamente falhas no front-end e tempos de carregamento lentos antes que os usuários reais os encontrem.
Quais são os diferentes tipos de monitores sintéticos que existem?
Os monitores sintéticos são categorizados pela profundidade técnica da verificação: monitores de Web Uptime cuidam de checagens básicas de protocolo como DNS, FTP e expiração de certificado SSL. Monitores de Web API validam a funcionalidade de respostas REST, SOAP e WebSocket. Monitores de Aplicações Web (UserView) utilizam um motor de navegador completo para simular transações em vários passos. Por fim, monitores de Media Streaming verificam a disponibilidade e qualidade da reprodução de áudio e vídeo.
De quantos locais devo monitorar?
Para confiabilidade no nível empresarial, você deve monitorar de 3 a 5 locais abrangendo todas as principais regiões geográficas onde seus clientes residem. Essa abordagem multi-nó é crítica porque permite a lógica de “Dupla Verificação”, onde uma falha reportada por um nó é imediatamente verificada por outros.
O Que Nossos Clientes Dizem
"I absolutely love the comprehensive monitoring services Dotcom-Monitor provides. The real-time alerts and detailed performance analytics have been a game-changer for our website's uptime and speed. The global monitoring feature ensures that our site is optimized everywhere, and the intuitive dashboard makes it easy to track performance. Their customer support is exceptional — always responsive and efficient."
Tomer C.
Managing Director · Facilities Services
Verified Capterra review · March 2025
"One of Dotcom's best features is the push/pull API capabilities that provide us with network performance data. We use this to monitor for performance issues as well as page loading stats. Dotcom-Monitor allows us to monitor multiple services within one interface and platform. It's allowed us to operate more efficiently."
Gregory S.
Manager · Broadcast Media
Verified Capterra review · May 2020
"I have been thoroughly impressed with the level of detail and comprehensiveness of the reports generated by the software. Moreover, the support team at Dotcom-Monitor has exceeded my expectations. On almost a daily basis, I reach out with various questions and they have consistently demonstrated unwavering patience, providing detailed and insightful answers."
Shirin R.
Software Test Engineer · Computer Software
Verified Capterra review · February 2023
"I'm a network analyst and use Dotcom tools inside the ISP I work, it's a really good and reliable tool for monitoring things along the network, and testing network components, I usually use it to make diagnostics of servers latency, and dns resolve time."
Leonardo J.
IT & Network Infrastructure Analyst Internet
Verified Capterra review · October 2022
Um Software de Monitoramento Sintético | Zero Pontos Cegos
Não é necessário cartão de crédito. Todos os recursos premium incluídos. Suporte especializado 24×7.