 多くのチームにとって、API 稼働監視とは、いまだに一つの単純なことを意味しています。それは、エンドポイントが 200 OK を返すかどうかを確認することです。チェックが成功すれば API は「稼働中」と判断され、失敗すればアラートが発報されます。理論上は合理的に聞こえますが、実際には、API 障害がユーザーからの苦情によって初めて気付かれる最も一般的な原因の一つです。
多くのチームにとって、API 稼働監視とは、いまだに一つの単純なことを意味しています。それは、エンドポイントが 200 OK を返すかどうかを確認することです。チェックが成功すれば API は「稼働中」と判断され、失敗すればアラートが発報されます。理論上は合理的に聞こえますが、実際には、API 障害がユーザーからの苦情によって初めて気付かれる最も一般的な原因の一つです。
問題は、現代の API がもはや単純でステートレスなエンドポイントではないという点にあります。API は、次のような複数の可動要素に依存しています。
- 認証および認可フロー
- データベースおよびバックグラウンドジョブ
- サードパーティサービスおよび外部 API
- リージョン別のインフラおよびルーティング
この複雑性のため、API は成功ステータスコードを返していても、実質的には失敗している場合があります。レスポンスに不完全なデータ、古い値、または論理的に誤った結果が含まれていることもあります。監視ダッシュボード上ではすべて正常に見えても、ユーザーの視点では API は事実上ダウンしているのです。
この乖離が、多くのチームが経験する 偽の稼働状態 を生み出します。基本的な稼働チェックは、次のような限定的な技術的質問に答えるのには適しています。
- API 稼働監視 は、API が 到達可能で、高速で、正しい結果を返している ことを確認します。
- 「200 OK」だけでは、サイレント障害(不正なペイロード、認証失敗、部分的なデータ)を隠してしまう可能性があります。
- 本番環境の稼働性には、マルチステップトランザクション と マルチリージョンチェック が含まれるべきです。
そのため、API 稼働監視にはより広い定義が必要です。サーバーが応答できるかどうかだけでなく、ユーザーの視点から見た可用性、正確性、パフォーマンスを考慮する必要があります。
実際のダウンタイムは理論的なものではなく、測定可能な経済的影響をもたらします。Gartner によると、平均的な IT 障害のコストは 1 分あたり約 5,600 ドル、多くの組織では 1 時間あたり約 30 万ドル に達します。また、独立調査では、中規模および大規模企業の 90%以上が 1 時間あたり 30 万ドル以上のダウンタイムコスト を報告しており、41% が 1 時間あたり 100 万ドルを超える と回答しています。これらの損失は、取引機会の損失、生産性の低下、SLA ペナルティ、顧客信頼の損失によって発生し、基本的なチェックでは検出されないことがよくあります。
このガイドでは、今日における API 稼働監視の本当の意味、一般的なアプローチがなぜ不十分なのか、そしてチームが現実の利用状況を反映した監視戦略をどのように設計できるのかを詳しく説明します。つまり、「API が稼働している」とは「API が機能している」ことを意味するのです。
現在における API 稼働監視の本当の意味
本質的に、API 稼働監視は次の単純な質問に答えることを目的としています。今この瞬間、利用者はこの API を信頼できるか? 問題は、多くのチームが依然として「稼働」を狭く定義し、エンドポイントがリクエストに応答するかどうかだけに注目している点にあります。現代のシステムでは、この定義はもはや通用しません。
API は分散アーキテクチャの中心に位置しています。ユーザーを認証し、ワークフローを調整し、複数の内部および外部サービスに依存しています。そのため、稼働性はもはや二値的な概念ではありません。API は到達可能であっても、使用不能な場合があります。
基本的な稼働チェックと最新の API 稼働監視の違いは、実際の監視方法を見るとより明確になります。単一の場所からの ping ではなく、効果的な監視は、複数のリージョンと依存経路から実際のワークフローを検証します。
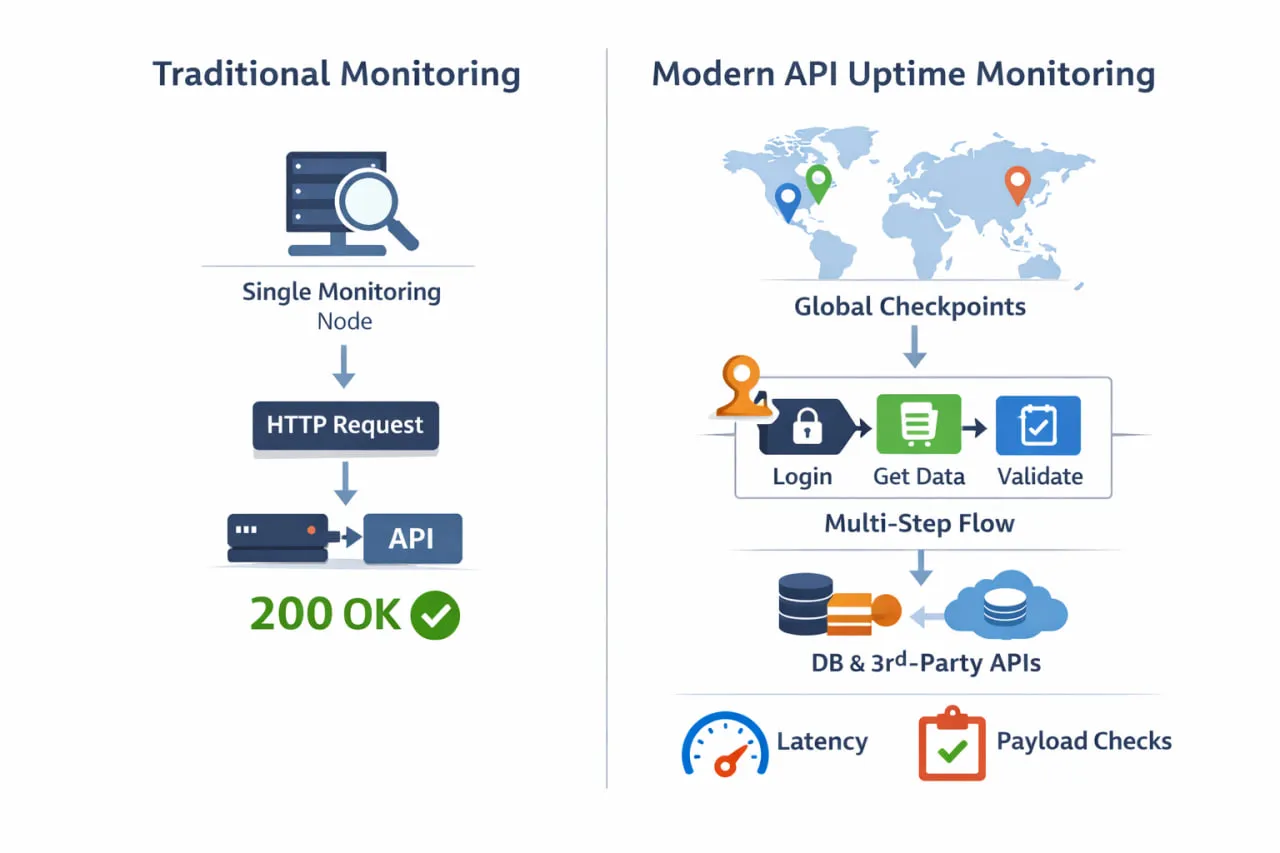
API 稼働のより正確な定義には、次の 3 つの同等に重要な要素が含まれます。
- 可用性 – ユーザーがいる場所から API に到達できるか?
- 正確性 – API は期待されるデータ、構造、値を返しているか?
- 応答性 – API は許容可能なレイテンシ内で応答しているか?
これらのいずれかが失敗すれば、監視ツールが 100% の稼働率を報告していても、ユーザーはダウンタイムを経験します。
ここで、多くの従来型稼働チェックの限界が明らかになります。単一リージョンの HTTP チェックでは、エンドポイントが 200 OK を返していることは確認できますが、認証が失敗していないか、下流依存関係がタイムアウトしていないか、別のリージョンでパフォーマンスが低下していないかまでは分かりません。エンジニアの視点ではすべて正常でも、外部から見れば API は壊れています。
稼働性を正しく理解するためには、API 監視を実際の利用方法に合わせる必要があります。つまり、API を単なるエンドポイントではなく、システムとして観測するということです。また、稼働監視を、ログ、トレーシング、メトリクスといった API オブザーバビリティ の分野で語られる信頼性プラクティスと結びつけることも重要です。オブザーバビリティが内部の深い洞察を提供する一方で、稼働監視は補完的な役割として、外部から実ユーザー体験を検証します。
正しく実施された API 稼働監視は、早期警告システムとして機能します。ユーザーが問題を報告する前に障害を検知し、地域的または条件付きの問題を明らかにし、内部メトリクスだけでは見逃されがちな問題を浮き彫りにします。「サーバーは応答したか?」ではなく、より有用な質問に答えるのです。「API は今、確実に価値を提供しているか?」
この定義の転換が、以降のすべての基盤となります。稼働性を実際の利用可能性として捉え直すことで、基本的なチェックの限界が明確になり、より堅牢な監視戦略の必要性も明らかになります。
なぜ基本的な稼働チェックは現代の API では不十分なのか
基本的な稼働チェックは、アプリケーションが少数の予測可能なエンドポイントを公開しており、成功が単一のレスポンスコードで測定できた時代に設計されました。しかし、現代の API はそのようには動作しません。それでも、多くの監視設定はいまだに同じ時代遅れの前提に依存しています。
基本的な稼働チェックの限界は、最新の本番対応 API 稼働監視と並べて比較すると明確になります。
| 機能 | 従来の稼働チェック | 最新の API 稼働監視 |
| 監視場所 | 単一リージョン | 複数のグローバルリージョン |
| チェック内容 | エンドポイント到達性 | API のエンドツーエンド利用可能性 |
| 認証サポート | ほとんどなし | 完全対応(トークン、ヘッダー、OAuth) |
| レスポンス検証 | ステータスコードのみ | ペイロード、スキーマ、値、ロジック |
| ワークフロー監視 | 非対応 | マルチステップ/トランザクションフロー |
| 依存関係の可視化 | なし | 下流障害を検出 |
| パフォーマンス洞察 | 基本的または平均レイテンシ | トレンド、閾値、劣化検出 |
| サイレント障害検出 | ❌ 見逃される | ✅ 早期に検出 |
| ユーザー体験との整合性 | 低い | 高い |
従来の稼働 ping は、サーバーが技術的に到達可能であることは示しますが、コストの高いサイレント障害からは守ってくれません。一部の業界レポートでは、平均的なダウンタイムコストは 1 分あたり 14,000 ドル近く に達するとされています。これは、API が表面的には「稼働中」であっても、1 時間あたり数十万ドル の損失が発生することを意味します。
最も一般的な障害モードの一つが、「200 OK の錯覚」 です。API は HTTP レベルでは成功して応答していても、ビジネスロジックのレベルでは失敗している可能性があります。例えば、レスポンスが次のような状態になることがあります。
- 空または部分的なペイロードを返す
- 古い、または不正確なデータを含む
- 必須フィールドが欠落している、またはスキーマが破損している
従来の稼働チェックでは成功に見えますが、ユーザーや下流システムにとってはサイレント障害です。
認証も大きな盲点を生み出します。API は多くの場合、期限付きトークン、ローテーションキー、ロールベースアクセスに依存しています。認証フローを完全にシミュレートしない基本的なチェックでは、期限切れの認証情報や権限設定ミスといった問題を検出できません。エンドポイントは到達可能でも、実際の利用者は誰も使用できないのです。
依存関係がこの問題をさらに悪化させます。ほとんどの API は、データベース、メッセージキュー、サードパーティサービスに依存しています。下流依存関係が劣化または断続的に失敗すると、API は応答し続けるものの、レイテンシ増加、部分的な結果、不安定な挙動を示すことがあります。これらは、基本的なチェックが最も検出しにくい問題です。
地理的要因も、さらに複雑さを加えます。多くの稼働チェックは単一の場所、しかもインフラに近い場所から実行されます。これにより、ルーティング問題、ISP 障害、CDN 設定ミスによる地域的な問題が隠れてしまいます。世界の一部の地域のユーザーがタイムアウトを経験していても、監視ダッシュボードではすべて正常に見えるのです。
これらの制限が、チームが強力な API 稼働監視を実装していると思い込んでいるにもかかわらず、顧客からの報告で初めて問題に気付く理由です。欠けているのは、現実世界での API 挙動に対する可視性です。
そのため、最新の稼働戦略では、到達性チェックに加えて、API レスポンスの正確性を検証 し、API レイテンシトレンドを監視 することで、地域全体にわたる実際のユーザー影響に基づいて問題を検出します。単なるサーバー可用性ではありません。
稼働監視が基本的な到達性チェックを超えない限り、チームは最も重要な問題を見逃し続けることになります。
真の API 稼働を定義するコアメトリクス
「稼働=エンドポイント到達可能」という考え方を超えたとき、次の疑問が生まれます。API 稼働監視は実際に何を測定すべきなのか? 効果的な監視は、紙の上ではなく、現実世界での API 挙動を反映する少数のメトリクスに焦点を当てます。
1. 可用性(到達性)
可用性は最も基本的な問いに答えます。特定の場所から API に到達できるか?
このメトリクスは依然として重要ですが、出発点に過ぎません。リクエストに応答しても他の点で失敗する API は、技術的には利用可能でも、実用的には使用不能です。
2. レイテンシ(応答性)
レイテンシは、API が応答するまでにかかる時間を測定します。リクエストが成功しても、応答が遅ければユーザーにとってはダウンタイムと感じられます。監視では次を追跡する必要があります。
- 定義された閾値に対するレスポンスタイム
- 平均値だけでなく、時間経過に伴うレイテンシトレンド
これにより、段階的なパフォーマンス劣化を障害になる前に検出できます。
3. レスポンスの正確性
ここで多くの稼働戦略が失敗します。正確性は、API が「何かを返したか」ではなく、「何を返したか」に注目します。実際には、レスポンスの正確性はアサーションによって検証されます。
例えば、JSONPath を使用して必須フィールドの存在を確認したり、数値が期待範囲内にあることを検証したり、レスポンススキーマが期待構造と一致しているかを確認します。これらのチェックにより、200 OK が本当に成功を意味していることが保証されます。
レスポンス検証がなければ、監視ダッシュボードは 100% 稼働を示していても、ユーザーは障害を経験します。
4. リージョン一貫性
API はグローバルに利用されますが、障害はしばしば地域限定で発生します。ネットワークルーティング問題、ISP 障害、ローカルインフラ問題は、特定地域にのみ影響することがあります。複数地点からの監視により、稼働性はインフラ近接性ではなく、ユーザー現実を反映します。
5. エラー挙動
すべての障害が同じではありません。エラータイプの追跡は、稼働データに重要な文脈を追加します。
- 401/403 エラーは認証問題を示すことが多い
- 500 系エラーはサーバー側障害を示す
- タイムアウトは下流またはパフォーマンス問題を示す
これらのメトリクスを組み合わせて監視することで、稼働性は意味のある信頼性シグナルとなり、見せかけの数値ではなくなります。
そのため、真の API 稼働監視は自然と API パフォーマンス監視 と重なります。パフォーマンストレンド、正確性チェック、リージョン可視性はすべて、API が本当に利用可能かどうかを理解するために不可欠です。
これらのコアメトリクスに焦点を当てることで、チームは受動的監視から能動的信頼性へと移行し、問題を早期に検出し、誤った安心感を減らし、稼働性を実際のユーザー体験と一致させることができます。
API 稼働を SLO と SLI にマッピングする
API が成熟すると、稼働性は曖昧な割合ではなく、信頼性のコミットメントになります。ここでサービスレベル目標(SLO)とサービスレベル指標(SLI)が重要になります。
「API は稼働しているか?」と問う代わりに、チームはユーザー体験に基づいて稼働性を定義します。
- 可用性 SLI – リクエストは成功しているか?
- レイテンシ SLI – 応答は十分に速いか?
- 正確性 SLI – レスポンスは正確で完全か?
API 稼働監視は、これらの指標に直接フィードされます。可用性チェックは到達性を確認し、レイテンシ追跡は遅延を明らかにし、レスポンス検証は API が技術的だけでなく機能的にも正しく動作していることを保証します。
SLO は、各指標の許容閾値を定義します。例えば、API は次のような目標を設定できます。
- 99.9% の成功レスポンス
- 95% のリクエストが 300 ms 未満
- 重要エンドポイントでのスキーマまたは検証エラーゼロ
稼働監視が SLO と整合すると、アラートは恣意的なものではなくなります。サーバーが応答しないときではなく、ユーザー向け信頼性がリスクにさらされたときに通知されます。これにより、稼働性は見せかけの指標から、エンジニアリングの優先順位やインシデント対応を導く意思決定ツールへと変わります。
真の API 稼働を計算する方法
真の API 稼働は、単にエンドポイントが応答するかどうかではありません。ユーザー視点で実際に成功したリクエストの割合 に基づいて計算されます。
可用性は次の式で測定されます。
可用性 SLI = 良好なリクエスト数 / 総リクエスト数
良好なリクエスト とは、次の条件を満たすものです。
- 2xx ステータスを返す
- スキーマおよびレスポンスアサーションを通過する
- レイテンシ閾値を満たす
稼働性は、定義された期間(例えば 28 日間のローリングウィンドウ)で測定され、目標 SLO と比較されます。残りの余裕(1 − SLO)がエラーバジェットとなります。
このアプローチにより、稼働性は到達性ではなく、実際の利用可能性を反映します。
効果的な API 稼働監視戦略の設計方法
効果的な API 稼働監視戦略の設計は、チェック数を増やすことではありません。適切な チェックを選び、適切な 結果を検証することです。目的は、ノイズや盲点を作らずに、実際の利用状況をできる限り正確に反映することです。
最も重要な API から始める
すべてのエンドポイントが同じ監視レベルを必要とするわけではありません。まず、ユーザーとビジネスにとって最も重要な API を特定します。通常、次が含まれます。
- 認証および認可エンドポイント
- 中核的なトランザクションまたは収益関連 API
- 外部依存関係を持つ公開またはパートナー向け API
これらの API に集中することで、稼働メトリクスは監視範囲ではなく、実際の影響を反映します。
意図を持って頻度を選ぶ
すべてのエンドポイントを数秒ごとにチェックしたくなりますが、高頻度が必ずしも良い洞察をもたらすわけではありません。監視間隔は次に基づいて決定すべきです。
- 障害をどれだけ早く検出する必要があるか
- ユーザーが短時間の中断をどれだけ許容できるか
- アラート疲れのリスク
高影響 API では高頻度チェックが正当化されますが、低リスクサービスでは長い間隔でも十分なシグナルが得られます。
マルチステップおよびトランザクションフローを監視する
ほとんどの現代 API は単独で動作しません。単一のユーザー操作が、複数の API 呼び出しを連続してトリガーすることが一般的です。個々のエンドポイントのみを監視すると、ステップ間で発生する障害を見逃します。
ここで マルチステップ API 監視 が不可欠になります。エンドポイントを個別にチェックするのではなく、認証、データ作成、取得、検証といった一連のワークフロー全体を単一トランザクションとして監視します。このアプローチにより、単純な稼働チェックでは検出できない問題が明らかになります。
ステータスコード以上を検証する
真の稼働監視では、レスポンスを受信するだけでなく、内容を検証する必要があります。効果的なチェックでは次をアサートします。
- レスポンス構造および必須フィールド
- 成功を示す特定の値
- API が正しく動作していることを確認するビジネスルール
このレベルの検証がなければ、稼働ダッシュボードは 100% 可用性を示していても、ユーザーは機能不全を経験します。
認証済みおよびプライベート API を含める
多くの重要な API は認証やファイアウォールの背後にあります。現実的な稼働戦略では、トークン、ヘッダー、認証情報ローテーションをサポートする必要があります。そうでなければ、チームはシステムの中で最も重要でない部分しか監視しないことになります。
Dotcom-Monitor の Web API Monitoring および REST API 監視 機能は、認証済みおよびプライベートエンドポイントをサポートし、本番環境でアプリケーションが依存する API をそのまま監視できます。
ユーザーがいる場所から監視する
単一地点監視は、誤った信頼感を生み出します。API は、実際のユーザー分布を反映した複数の地理的ロケーションから監視する必要があります。これにより、地域的なレイテンシスパイク、ルーティング問題、ISP 障害を、深刻化する前に発見できます。
稼働性を信頼性目標と整合させる
最後に、稼働監視は SLO と整合する必要があります。「API は稼働しているか?」ではなく、次を問うべきです。
- 可用性目標を満たしているか?
- パフォーマンスは許容範囲内か?
- エラー率は閾値を超えていないか?
稼働メトリクスが信頼性目標と整合すると、監視は情報提供にとどまらず、行動可能なものになります。
これらの戦略を実装するチームにとって、Web API 監視セットアップ や REST Web API タスクの追加/編集(高度な設定オプションは REST Web API タスク設定 で解説)といった Dotcom-Monitor のドキュメントは、基本チェックから本番対応の API 稼働監視へ移行するのを容易にします。
API 稼働性は利用者によって決まる
API 稼働性は一律ではありません。内部 API は短時間の中断を許容できても、ワークフロー維持のために厳格な正確性を必要とします。公開 API は、ユーザー体験とブランド信頼を守るため、安定したグローバル可用性と低レイテンシが求められます。
パートナー向けまたは収益に直結する API は、わずかな劣化でも契約や収益に影響するため、最も高い期待が課されます。効果的な API 稼働監視は、API の実際の利用方法を反映して、エンドポイントの優先順位、検証深度、アラート閾値を調整します。
よくある API 稼働監視のミス(とその回避方法)
成熟した監視スタックを持つチームであっても、同じ API 稼働監視の落とし穴に陥ることがあります。これらのミスは怠慢ではなく、API が本番環境でどのように失敗するかについての単純化された前提に起因します。
1. 稼働性をステータスコードチェックと同一視する
最も一般的なミスは、稼働性を HTTP レスポンスの成功と同一視することです。200 OK はサーバーが応答したことを示すだけで、API が正しく動作したことを保証しません。ペイロード、スキーマ、ビジネスロジックを検証しなければ、チームは 到達性 を測っているだけで、利用可能性 を測っていません。
回避方法:
ステータスコードを超えて、レスポンス内容や期待値を検証する。
2. 単一地点からのみ監視する
インフラに近い単一地点からの稼働チェックは、誤った信頼感を生み出します。地域的なルーティング問題、ISP 障害、DNS 問題は、特定地域にのみ影響し、アラートを発生させないことがあります。
回避方法:
実際のユーザー分布を反映した複数のグローバル地点から API を監視する。
3. 認証済みエンドポイントを無視する
設定が複雑に感じられるため、認証済み API の監視を避けるチームは少なくありません。その結果、最も重要な API が未監視のままになります。
回避方法:
認証、ヘッダー、認証情報ローテーションをサポートする監視ツールを使用する。
4. すべての失敗でアラートを出す
すべての失敗でアラートを出すと、ノイズやアラート疲れが発生し、最終的には通知が無視されます。一時的なネットワーク障害や単一リージョンの問題は、即時エスカレーションを必要としない場合があります。
回避方法:
複数地点や複数チェックで障害を確認してからアラートを発報するロジックを設計する。
5. 稼働性を見せかけの指標として扱う
高い稼働率はレポート上は良く見えますが、実際には根本的な問題を隠すことがあります。API は稼働目標を達成していても、ユーザー体験は劣悪な場合があります。
回避方法:
稼働監視をエラー率、レイテンシ閾値、SLO と結びつける。
これらのミスが、チームが自信を持っているにもかかわらず、ユーザーからの報告で初めて問題に気付く理由です。回避には考え方の転換が必要です。稼働監視は「オンラインであること」を証明するのではなく、「利用可能であること」を証明するためのものです。
ここで、API 監視ツール や API ヘルス監視 といった広範な実践が、基本チェックのギャップを埋め、API 信頼性のより現実的な視点を提供します。
ネイティブまたは開発者専用ツールだけでは不十分になるとき
ネイティブおよび開発者向けツールは、初期段階では有用です。CI/CD チェック、ユニットテスト、プラットフォームレベル監視は、本番前に明白な問題を検出するのに役立ちます。しかし、API がスケールし、顧客向けになるにつれて、これらのツールの限界が明らかになります。
大きな問題の一つは 環境バイアス です。開発者専用ツールは通常、API と同じクラウド、ネットワーク、パイプライン内で実行されます。これによりデプロイ検証には有効ですが、ルーティング問題や地域的障害など、ユーザーが体験する外部問題の検出には弱くなります。
もう一つの制限は スコープと継続性 です。多くのネイティブチェックは短時間実行を前提としており、継続的監視には向いていません。そのため、次のような時間経過で発生する問題を見逃します。
- 徐々に進行するレイテンシ増加
- 断続的な依存関係障害
- 地域限定のパフォーマンス劣化
さらに アラート信頼性 の問題もあります。自社インフラ内部から発生するアラートは、実際の障害か内部異常か判断が難しく、対応が遅れがちです。
API が成熟するにつれて、ユーザー体験を反映する 独立した視点 を提供する監視が必要になります。外部稼働監視は、その欠けている視点を補い、環境外から可用性とパフォーマンスを検証します。
ここで REST API 監視 が不可欠になります。内部チェックのみに依存するのではなく、複数のグローバル地点から API を継続的に監視し、実際のレスポンスを検証し、障害が広範囲か局所的かを確認できます。
開発者専用ツールからの移行は理論的なものではなく、見逃されたインシデント、遅延アラート、顧客からの先行報告によって促されます。これらの兆候を早期に認識することで、信頼性問題がビジネスリスクに変わる前に監視戦略を進化させることができます。
また、合成稼働監視の限界を理解することも重要です。ユーザー向け可用性と影響を確認する一方で、根本原因分析のためのログ、トレース、メトリクスを置き換えるものではありません。これらは相互補完的に機能します。
Dotcom-Monitor による API 稼働監視のアプローチ
Dotcom-Monitor は、独立したグローバルチェックポイントからの外部合成監視を使用して、ユーザーが体験する可用性、正確性、パフォーマンスを検証します。
このアプローチの中核は 外部合成監視 です。API はインフラ外部から、独立したグローバルチェックポイントを用いてテストされます。これにより内部バイアスが排除され、稼働データは自社システムではなく、ユーザー体験を反映します。
このアプローチを支える主な機能には次が含まれます。
- グローバル監視ロケーション による地域障害およびレイテンシ問題の可視化
- 高度なレスポンス検証 により、200 OK を成功と誤認しない
- マルチステップ API 監視 により、単一呼び出しではなくワークフロー全体を検証
- 認証済みおよびプライベート API のサポート(ヘッダー、トークン、カスタムロジック)
これにより、不正なペイロード、認証フローの破損、部分的な依存関係障害といった、基本的な稼働チェックでは見逃されるサイレント障害を検出できます。
もう一つの重要な要素は アラートの信頼性 です。Dotcom-Monitor は、エラー継続時間や失敗ロケーション数に基づくルールと、誤検知防止チェックによって、誤検知を減らすよう設定できます。アラートはノイズではなく、意味のあるシグナルになります。
監視が継続的に行われるため、チームは時間経過に伴うトレンドも分析できます。レイテンシスパイク、地域的劣化、断続的エラーは、全面的な障害に発展する前に表面化します。これにより、稼働監視は受動的作業から能動的信頼性プラクティスへと変わります。
これらすべては、本番環境向けに設計された Dotcom-Monitor の Web API Monitoring によって提供されます。チェックしやすいものではなく、最も重要なもの、すなわちユーザー体験としての可用性、正確性、パフォーマンスに焦点を当てています。
基本的なチェックを超えたいチームは、本番対応の Web API 監視ツール をご覧ください。
