Logiciel automatisé de surveillance synthétique pour applications, APIs et sites web
Le logiciel de surveillance synthétique de Dotcom-Monitor simule le comportement réel des utilisateurs 24h/24 et 7j/7 pour détecter les parcours utilisateurs cassés et les échecs "silencieux" avant qu'ils n'impactent vos clients. Surveillez les sites web, APIs et applications web complexes à travers plus de 30 emplacements mondiaux avec des tests en navigateur réel, des replays vidéo détaillés, des rapports sous forme de graphiques en cascade et des alertes proactives de performance.
Premières alertes
En 10 minutes
Essai de 30 jours
Toutes les fonctionnalités
Support 24/7
Équipe d'experts
- Aucune carte de crédit requise
- Toutes les fonctionnalités premium incluses
10 000+
Organisations dans le monde entier
99,99%
SLA de disponibilité de la plateforme
30+
Emplacements mondiaux de surveillance
Depuis 1998
Leader en surveillance de sites Web
62%
de réduction du MTTR
“Nous avons détecté une régression d’API de paiement en moins de 90 secondes après le déploiement. Avant Dotcom-Monitor, cela aurait été un ticket P1 d’un client trois heures plus tard.”
Michael Reeves
Sr. SRE, plateforme SaaS d'entreprise
140K $
en pertes de temps d'arrêt évitées
“La surveillance synthétique sur notre flux de paiement à elle seule a payé la plateforme dès le premier mois. Nous détectons maintenant les échecs d’authentification avant qu’un seul utilisateur ne soit affecté.”
Sarah Kim
VP Engineering, Fintech B2B
4.5
Capterra
82 avis
4.5
G2 | Le plus facile à utiliser
Les utilisateurs nous aiment · 2025
4.5
Software Advice
Recommandé
Commencez en quelques minutes
Configurez votre logiciel de surveillance synthétique en seulement 3 étapes
Aucun agent à installer. Aucun changement de code. Configurez votre première surveillance synthétique et soyez alerté avant que vos utilisateurs ne remarquent un problème.
Enregistrer
Ouvrez le EveryStep Recorder et naviguez sur votre site.
Déployer
Choisissez parmi plus de 30 points de contrôle globaux.
Résoudre
Recevez une alerte dès qu'un parcours se brise - avec une vidéo.
Étape 01
Étape 02
Étape 03

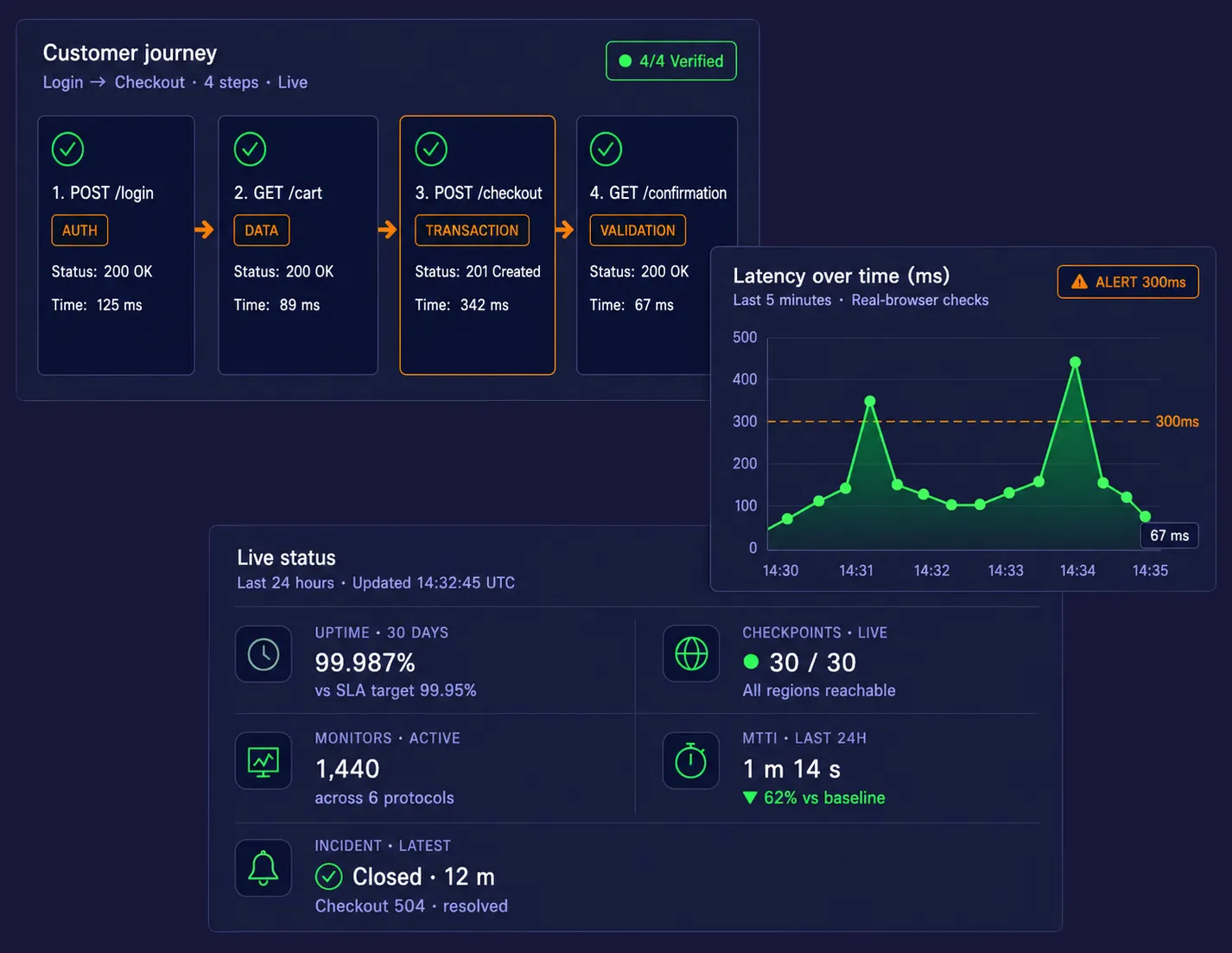
Enregistrez les parcours réels des utilisateurs avec EveryStep
Utilisez le EveryStep Web Recorder pour créer des scripts de surveillance synthétique en interagissant simplement avec votre site ou application. Enregistrez des flux de travail complexes tels que le paiement multi-pages, la connexion SSO, l’enregistrement de compte, l’accès à un tableau de bord protégé et les actions sur le panier sans script manuel. Cette approche sans code facilite le déploiement rapide de la surveillance d’applications Web tout en protégeant les parcours générateurs de revenus qui comptent le plus.
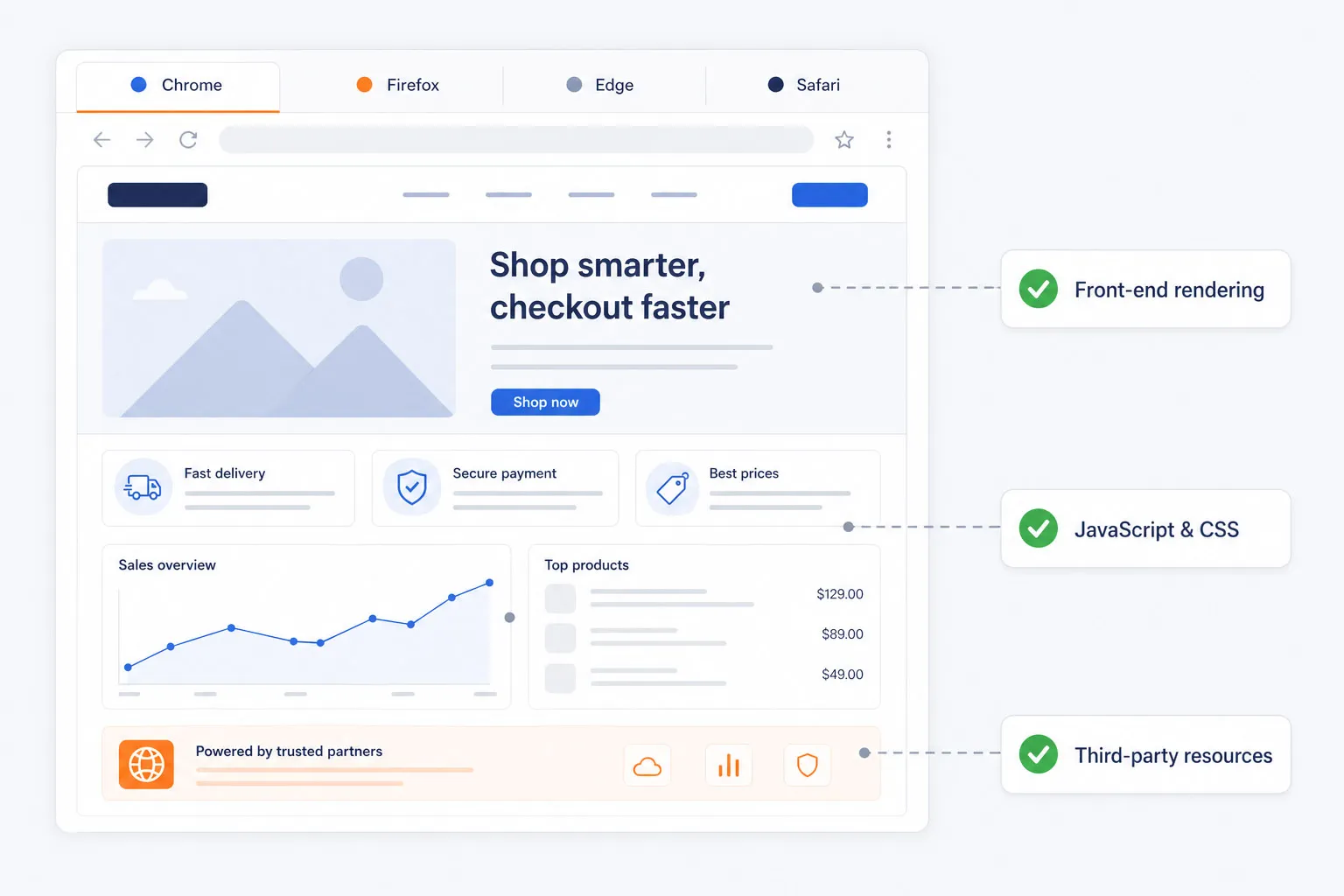
Testez dans de vrais navigateurs, pas dans des simulations simplifiées
Les vérifications basiques de disponibilité ne peuvent pas détecter les problèmes de rendu front-end, les erreurs JavaScript, les problèmes CSS ou les ressources tierces lentes. Dotcom-Monitor exécute des tests synthétiques dans de vrais navigateurs Chrome, Firefox, Edge et Safari afin que les équipes puissent valider la performance et les fonctionnalités exactement telles que les utilisateurs les expérimentent.
Cela offre aux équipes d’ingénierie, QA et digitales une vue plus précise de la santé réelle des applications web.
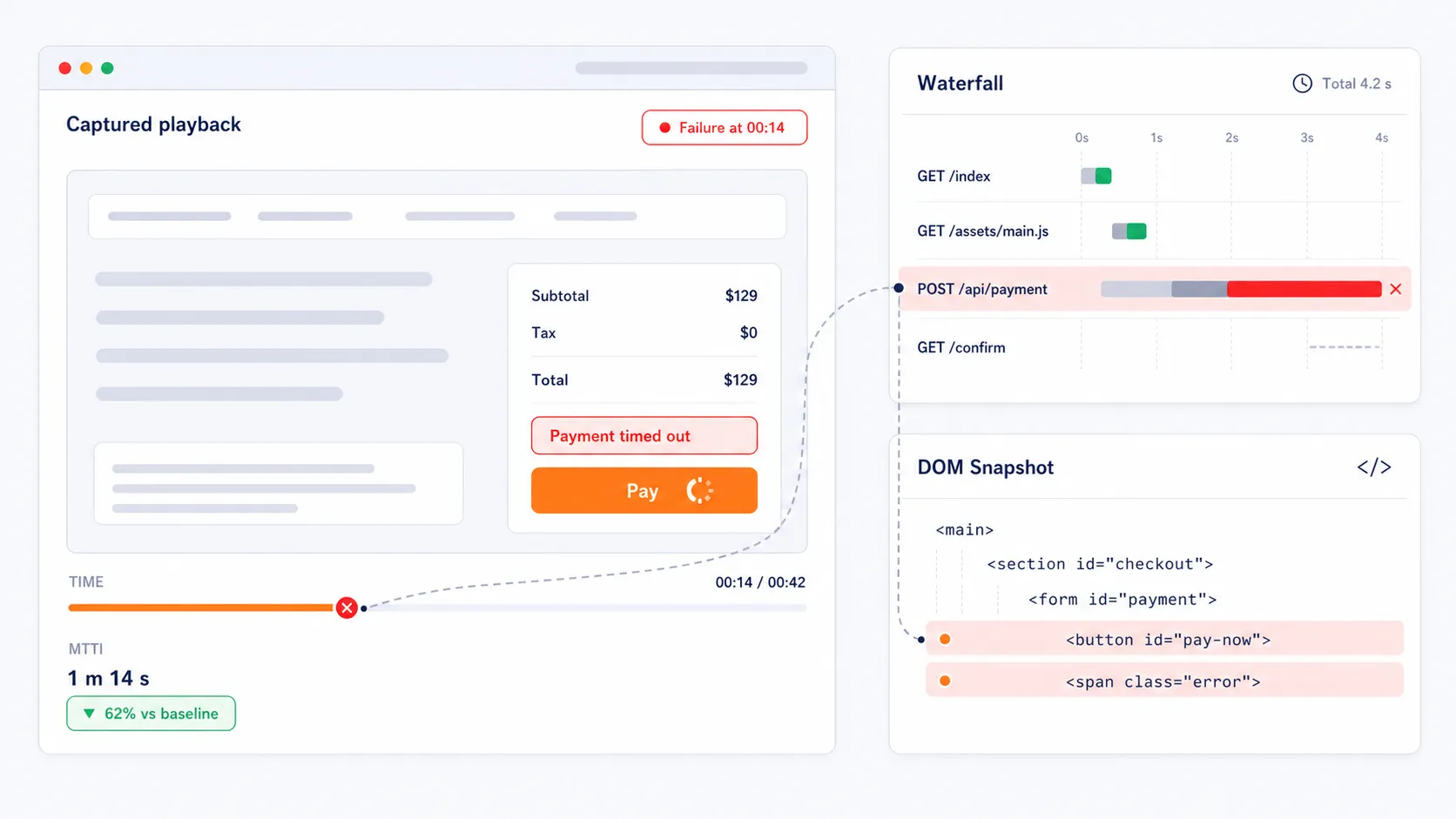
Capturez des preuves visuelles pour un dépannage plus rapide
Lorsqu’une transaction échoue, la plateforme enregistre une vidéo de la session de test échouée, des graphiques en cascade et des instantanés complets du DOM. Ces diagnostics visuels aident les équipes à accélérer l’analyse des causes profondes en montrant l’appel d’API exact, l’élément de la page, la redirection ou le script qui a provoqué la rupture du parcours. Au lieu de deviner où se trouve le problème, les équipes ont immédiatement des preuves qui réduisent le temps moyen d’identification.
Détectez les échecs silencieux de conversion avant la perte de revenus
Un site peut sembler disponible alors que des actions critiques comme la connexion, le paiement, la recherche ou l’accès au compte échouent silencieusement en arrière-plan. Ces échecs silencieux peuvent drainer les taux de conversion, gaspiller le trafic payant et nuire à la confiance des clients. Dotcom-Monitor aide les équipes à détecter ces problèmes grâce à des contrôles synthétiques pouvant s’exécuter aussi fréquemment que toutes les 60 secondes, offrant ainsi aux équipes digitales une méthode proactive pour protéger l’expérience client et les revenus en ligne.


Déployez en toute confiance du staging à la production
La surveillance synthétique ne sert pas uniquement à l’alerte en production. Les équipes peuvent orienter les moniteurs vers des environnements de staging ou les intégrer aux workflows CI/CD pour réaliser des tests de fumée sur les parcours critiques avant et après le déploiement. Ceci aide à prévenir les bugs du premier jour, protège les parcours utilisateurs clés et donne aux équipes plus de confiance pour déployer rapidement sans casser les fonctionnalités existantes.
Commencez à surveiller vos applications web en moins de 10 minutes
Réduisez les temps d’arrêt, détectez les problèmes avant vos clients et prouvez le respect de vos SLA. Toutes les fonctionnalités incluses dans l’essai. Pas de carte bancaire. Annulez à tout moment.
- Aucune carte de crédit requise
- Toutes les fonctionnalités incluses
- Configuration en 5 minutes
- Support 24h/24 et 7j/7
Logiciel de surveillance synthétique pour APIs et microservices

Valider la disponibilité, la précision et la latence de l'API
Dotcom-Monitor surveille les APIs REST et SOAP pour la performance et la conformité, aidant les équipes à vérifier que les points d’accès renvoient les charges utiles attendues, les codes d’état et les temps de réponse. En vérifiant en continu le comportement du service, les équipes peuvent détecter les problèmes plus tôt et maintenir des opérations backend plus fiables.
Détecter plus tôt les délais d'attente, les mauvaises charges utiles, et les échecs d'authentification
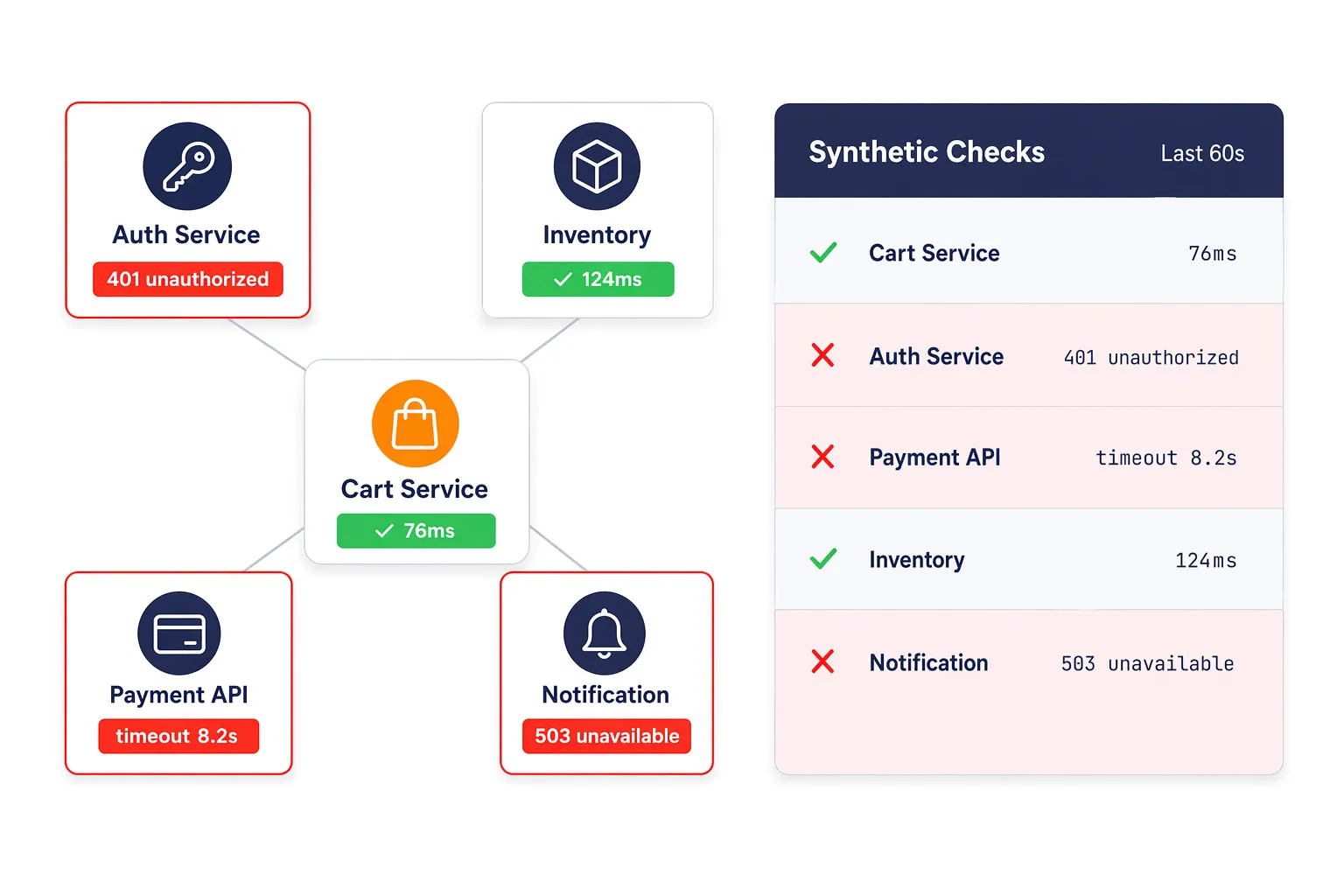
Les problèmes d’API et de microservices apparaissent souvent d’abord sous forme de fonctionnalité dégradée, de transactions lentes, ou d’erreurs intermittentes. Les vérifications synthétiques d’API aident les équipes à détecter les délais d’attente, les authentifications échouées, les mauvaises réponses et les interruptions de service avant qu’ils ne se propagent en problèmes visibles pour les clients.
Cela est particulièrement précieux dans les architectures distribuées où plusieurs services backend influencent un seul parcours utilisateur.

Prendre en charge la validation de l'authentification et du niveau de service
La fiabilité du backend ne se limite pas au temps de disponibilité. Les équipes doivent également valider le comportement d’authentification, les échanges de jetons, et les réponses des services critiques pour l’entreprise. Dotcom-Monitor aide à vérifier ces conditions de manière proactive afin que les défaillances puissent être corrigées avant d’affecter les applications dépendantes ou les flux de travail des clients.
Accélérer l'analyse des causes profondes des incidents de service
Lorsqu’une défaillance est détectée, les équipes peuvent consulter les détails diagnostics nécessaires pour identifier plus rapidement le service en échec. Cela offre aux équipes DevOps, SRE, et plateformes un point de départ plus solide pour la remediation et aide à réduire le temps passé à chercher la source d’un incident backend.

Validez vos APIs avant que les utilisateurs ne ressentent la défaillance
- Aucune carte de crédit requise
- REST, SOAP, multi-étapes, et alertes inclus
- Support 24h/24 et 7j/7
Surveillance Web Synthétique pour Sites Web et Expérience Digitale Publique

Surveillez la disponibilité des sites web depuis plus de 30 emplacements mondiaux
Dotcom-Monitor offre une surveillance synthétique depuis plus de 30 points de contrôle mondiaux, aidant les équipes à comprendre comment les sites web fonctionnent à travers les principales régions clientes. Cela facilite l’identification de la latence régionale, des pannes localisées, et des angles morts qui seraient manqués par une surveillance depuis un seul emplacement.
Allez au-delà du temps de disponibilité avec une visibilité sur la performance
La surveillance synthétique d’un site web ne doit pas s’arrêter à savoir si une page répond. Dotcom-Monitor aide les équipes à analyser les goulets d’étranglement de performance avec des rapports en diagramme en cascade et des diagnostics basés sur le navigateur qui révèlent les scripts lents, les ressources lourdes, et d’autres problèmes dégradant la vitesse de la page et l’expérience utilisateur.


Améliorez les Core Web Vitals et la visibilité dans les recherches
La performance de recherche et l’expérience digitale sont étroitement liées. Dotcom-Monitor aide les équipes à surveiller les conditions influençant des métriques telles que le Largest Contentful Paint et le Cumulative Layout Shift dans des environnements contrôlés. En identifiant tôt les ressources tierces lentes à charger et la performance des CDN, les équipes peuvent améliorer la stabilité du site, préserver la performance SEO, et offrir des expériences plus rapides.
Transformez les données de fiabilité en rapports utiles
Pour les organisations d’entreprise et les fournisseurs de services, la fiabilité doit souvent être documentée, pas seulement observée. Dotcom-Monitor prend en charge les tableaux de bord automatisés et rapports orientés SLA qui aident les équipes à démontrer les engagements de disponibilité et de performance avec des données collectées à partir d’un réseau de surveillance global.
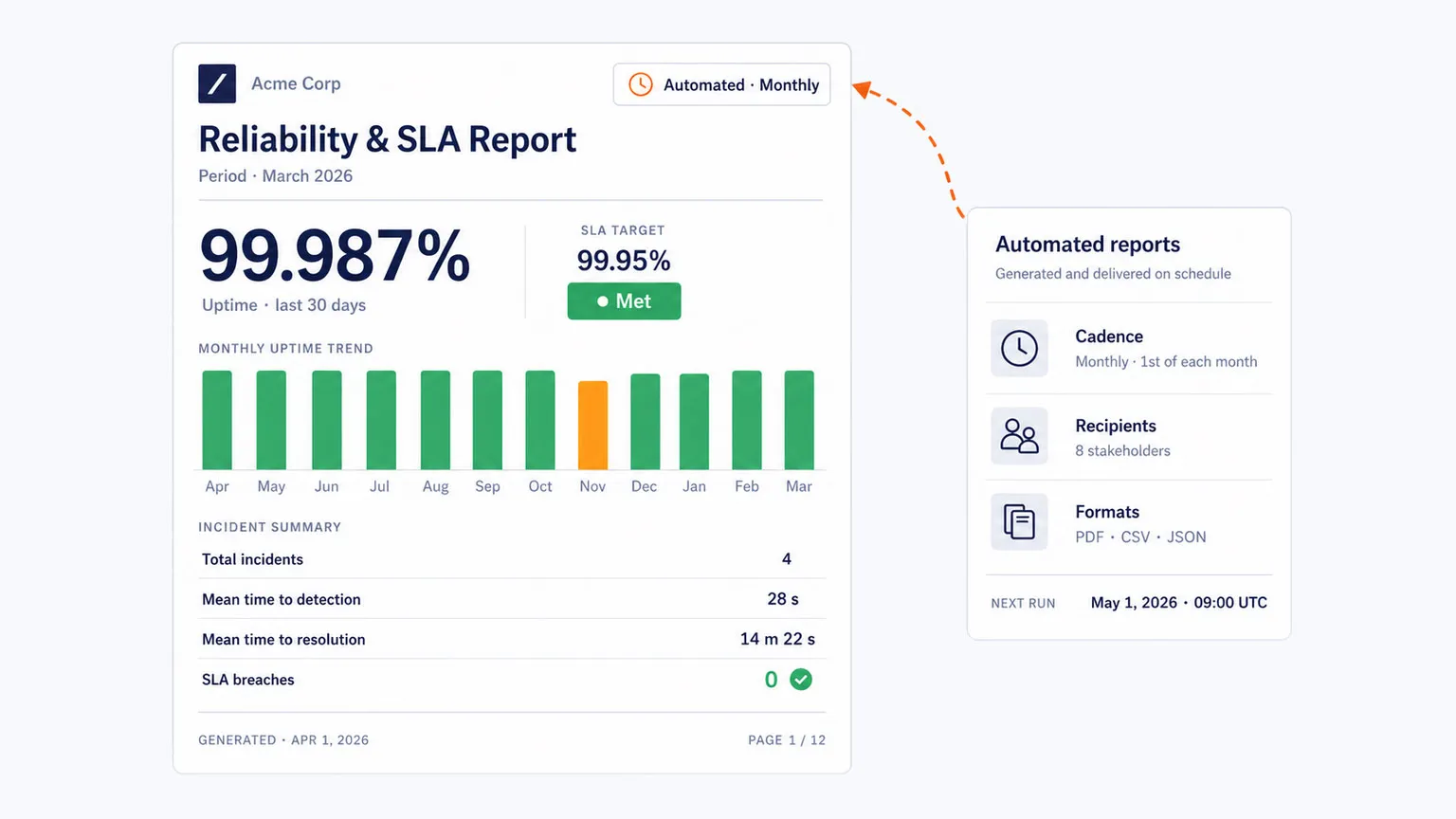
Commencez à surveiller la disponibilité du site Web dans le monde entier
- Aucune carte de crédit requise
- Toutes les fonctionnalités incluses
- Configuration en 5 minutes
- Support 24h/24 et 7j/7
Surveillance synthétique pour l'authentification, les applications internes et les entreprises avancées

Surveillez les flux d'authentification SSO et MFA
Les workflows de Single Sign-On et d’authentification Multi-Factor reposent souvent sur des redirections en chaîne, des fournisseurs d’identité, des échanges de jetons et des sessions protégées qui peuvent échouer de manière difficile à diagnostiquer. Dotcom-Monitor peut simuler ces parcours d’authentification multi-étapes afin que les équipes puissent identifier les échanges défaillants, les problèmes de redirection et les échecs d’accès avant que les utilisateurs ne soient exclus de systèmes critiques.
Déployez des agents privés derrière le pare-feu
De nombreuses applications d’entreprise, y compris les portails internes des employés, les outils propriétaires, les intranets et les systèmes ERP, se trouvent derrière des pare-feu corporatifs. Dotcom-Monitor prend en charge les agents synthétiques privés, également appelés nœuds privés, qui peuvent être déployés dans votre propre environnement pour surveiller les applications internes depuis un point de vue interne sécurisé.


Isolez l'impact des scripts tiers et l'instabilité du DOM
Les expériences numériques modernes dépendent des balises analytiques, des widgets de chat, des scripts externes et d’autres éléments tiers pouvant bloquer le rendu et provoquer une instabilité de la mise en page. La surveillance synthétique avec navigateur réel aide les équipes à isoler quelle ressource externe ralentit l’expérience ou affecte la stabilité de la page afin d’optimiser la stratégie de chargement et réduire la friction utilisateur.
Reproduisez les pannes intermittentes lors des pics de trafic
Les problèmes intermittents des applications Ecommerce et SaaS peuvent être difficiles à capturer pendant les pics de trafic. La surveillance synthétique aide à reproduire les échecs visibles par l’utilisateur en exécutant à plusieurs reprises toute la logique de transaction, facilitant ainsi la capture des preuves des ralentissements d’API, des erreurs frontend ou des problèmes de performance backend qui n’apparaissent que sous pression.

Assurez-vous que votre infrastructure commerciale fonctionne
- Aucune carte de crédit requise
- Toutes les fonctionnalités incluses
- Configuration en 5 minutes
- Support 24h/24 et 7j/7
Pourquoi les équipes choisissent Dotcom-Monitor pour la surveillance synthétique

Réduire le temps moyen d’identification
Les pannes deviennent plus coûteuses plus les équipes mettent de temps à identifier le problème. Avec des diagnostics visuels, la lecture synchronisée, les données en cascade et les alertes contextuelles, Dotcom-Monitor offre aux équipes un point de départ rapide pour le dépannage.
Surveillance des transactions synthétiques sans code
Les équipes peuvent enregistrer des workflows complexes sans écrire manuellement de scripts, ce qui facilite le lancement rapide de la surveillance et maintient la couverture alignée avec la façon dont un véritable utilisateur navigue sur votre site Web.


Recevez des alertes proactives dans les outils que votre équipe utilise déjà
Dotcom-Monitor intègre des alertes proactives dans les workflows existants via Slack, PagerDuty, Microsoft Teams et ServiceNow, aidant les équipes à réagir plus rapidement lorsque des problèmes de performance ou de disponibilité sont détectés.
Corréler l’expérience front-end avec les signaux d’infrastructure
Dotcom-Monitor offre une visibilité sur les sites web, applications, API et contrôles au niveau de l’infrastructure tels que DNS, FTP et TCP. Cela aide les équipes à relier la santé du backend et le comportement du réseau à l’expérience numérique réelle reçue par les utilisateurs.

Obtenez des réponses
Questions fréquemment posées
Puis-je déployer des agents privés derrière le pare-feu de mon entreprise ?
Oui, Dotcom-Monitor vous permet de déployer des agents privés (également appelés nœuds privés) spécifiquement pour surveiller les applications depuis l’intérieur de votre pare-feu d’entreprise. Cette fonctionnalité est essentielle pour suivre la performance et la disponibilité des portails internes pour employés, intranet ou outils RH non accessibles via Internet public.
Qu’est-ce qu’un agent synthétique privé ?
Un agent synthétique privé est une instance logicielle légère installée sur votre propre serveur local ou cloud privé qui sert de point d’observation interne sécurisé. Contrairement aux nœuds de surveillance publics situés dans des centres de données mondiaux, un agent privé simule l’expérience d’un véritable employé ou système interne depuis votre propre infrastructure réseau.
Quelle est la différence entre APM et la surveillance synthétique ?
La principale différence réside dans la direction de l’observation : l’Application Performance Monitoring (APM) est une stratégie “de l’intérieur vers l’extérieur” qui utilise des agents installés sur les serveurs pour suivre l’exécution du code interne, les requêtes de base de données et l’utilisation des ressources matérielles afin d’identifier les goulets d’étranglement du backend. En revanche, la surveillance synthétique est une approche “de l’extérieur vers l’intérieur” qui utilise des scripts pour simuler le comportement des utilisateurs finaux – comme la connexion ou la validation – afin de détecter de manière proactive les défaillances front-end et les temps de chargement lents avant que les utilisateurs réels ne les rencontrent.
Quels sont les différents types de moniteurs synthétiques existants ?
Les moniteurs synthétiques sont catégorisés selon la profondeur technique du contrôle : les moniteurs de disponibilité web gèrent des contrôles protocolaires de base tels que DNS, FTP et expiration de certificats SSL. Les moniteurs Web API valident les fonctionnalités des réponses REST, SOAP et WebSocket. Les moniteurs Web Application (UserView) utilisent un moteur de navigateur complet pour simuler des transactions multi-étapes. Enfin, les moniteurs de streaming média vérifient la disponibilité et la qualité de la lecture audio et vidéo.
Combien de localisations devrais-je surveiller ?
Pour une fiabilité de niveau entreprise, vous devriez surveiller de 3 à 5 emplacements couvrant toutes les principales régions géographiques où résident vos clients. Cette approche multi-nœuds est essentielle car elle permet une logique de “double vérification”, où une panne signalée par un nœud est immédiatement confirmée par d’autres.
Ce que nos clients disent
"I absolutely love the comprehensive monitoring services Dotcom-Monitor provides. The real-time alerts and detailed performance analytics have been a game-changer for our website's uptime and speed. The global monitoring feature ensures that our site is optimized everywhere, and the intuitive dashboard makes it easy to track performance. Their customer support is exceptional — always responsive and efficient."
Tomer C.
Managing Director · Facilities Services
Verified Capterra review · March 2025
"One of Dotcom's best features is the push/pull API capabilities that provide us with network performance data. We use this to monitor for performance issues as well as page loading stats. Dotcom-Monitor allows us to monitor multiple services within one interface and platform. It's allowed us to operate more efficiently."
Gregory S.
Manager · Broadcast Media
Verified Capterra review · May 2020
"I have been thoroughly impressed with the level of detail and comprehensiveness of the reports generated by the software. Moreover, the support team at Dotcom-Monitor has exceeded my expectations. On almost a daily basis, I reach out with various questions and they have consistently demonstrated unwavering patience, providing detailed and insightful answers."
Shirin R.
Software Test Engineer · Computer Software
Verified Capterra review · February 2023
"I'm a network analyst and use Dotcom tools inside the ISP I work, it's a really good and reliable tool for monitoring things along the network, and testing network components, I usually use it to make diagnostics of servers latency, and dns resolve time."
Leonardo J.
IT & Network Infrastructure Analyst Internet
Verified Capterra review · October 2022
Un logiciel de surveillance synthétique | Zéro zone d’ombre
Pas de carte de crédit requise. Toutes les fonctionnalités premium incluses. Support expert 24×7.