Automatisierte Synthetic Monitoring Software für Anwendungen, APIs und Websites
Die Synthetic Monitoring Software von Dotcom-Monitor simuliert rund um die Uhr das Verhalten realer Nutzer, um unterbrochene Benutzerpfade und "stille" Fehler zu erkennen, bevor sie Ihre Kunden beeinträchtigen. Überwachen Sie Websites, APIs und komplexe Webanwendungen an mehr als 30 Standorten weltweit mit echter Browser-Testung, detaillierten Video-Wiedergaben, Wasserfalldiagramm-Berichten und proaktiven Performance-Benachrichtigungen.
Erste Benachrichtigungen
In 10 Minuten
30-Tage-Testversion
Alle Funktionen
24/7 Support
Experten-Team
- Keine Kreditkarte erforderlich
- Alle Premium-Funktionen enthalten
10.000+
Organisationen weltweit
99,99%
Plattform-Verfügbarkeitsgarantie SLA
30+
Globale Überwachungsstandorte
Seit 1998
Führend im Website-Monitoring
62%
Reduzierung der MTTR
“Wir haben eine Regression der Payment-API innerhalb von 90 Sekunden nach dem Deployment entdeckt. Vor Dotcom-Monitor wäre das ein P1-Ticket von einem Kunden drei Stunden später gewesen.”
Michael Reeves
Sr. SRE, Enterprise SaaS Platform
140.000 $
an verhinderten Ausfallzeiten-Verlusten
„Synthetic Monitoring in unserem Checkout-Prozess hat die Plattform bereits im ersten Monat bezahlt. Wir erkennen Authentifizierungsfehler jetzt, bevor ein einziger Nutzer betroffen ist.“
Sarah Kim
VP Engineering, B2B Fintech
4.5
Capterra
82 Bewertungen
4.5
G2 | Am einfachsten zu verwenden
Benutzer lieben uns · 2025
4.5
Software Advice
Empfohlen
Starten Sie in wenigen Minuten
Richten Sie Ihre Synthetic Monitoring Software in nur 3 Schritten ein
Keine Agenten zur Installation. Keine Codeänderungen. Richten Sie Ihr erstes Synthetic Monitoring ein und erhalten Sie Benachrichtigungen, bevor Ihre Nutzer etwas bemerken.
Aufnehmen
Öffnen Sie den EveryStep Recorder und klicken Sie sich durch Ihre Website.
Bereitstellen
Wählen Sie aus über 30 globalen Prüfstellen.
Problemlösung
Erhalten Sie sofort eine Benachrichtigung, sobald eine Reise unterbrochen wird – mit einem Video.
Schritt 01
Schritt 02
Schritt 03

Zeichnen Sie echte Benutzerreisen mit EveryStep auf
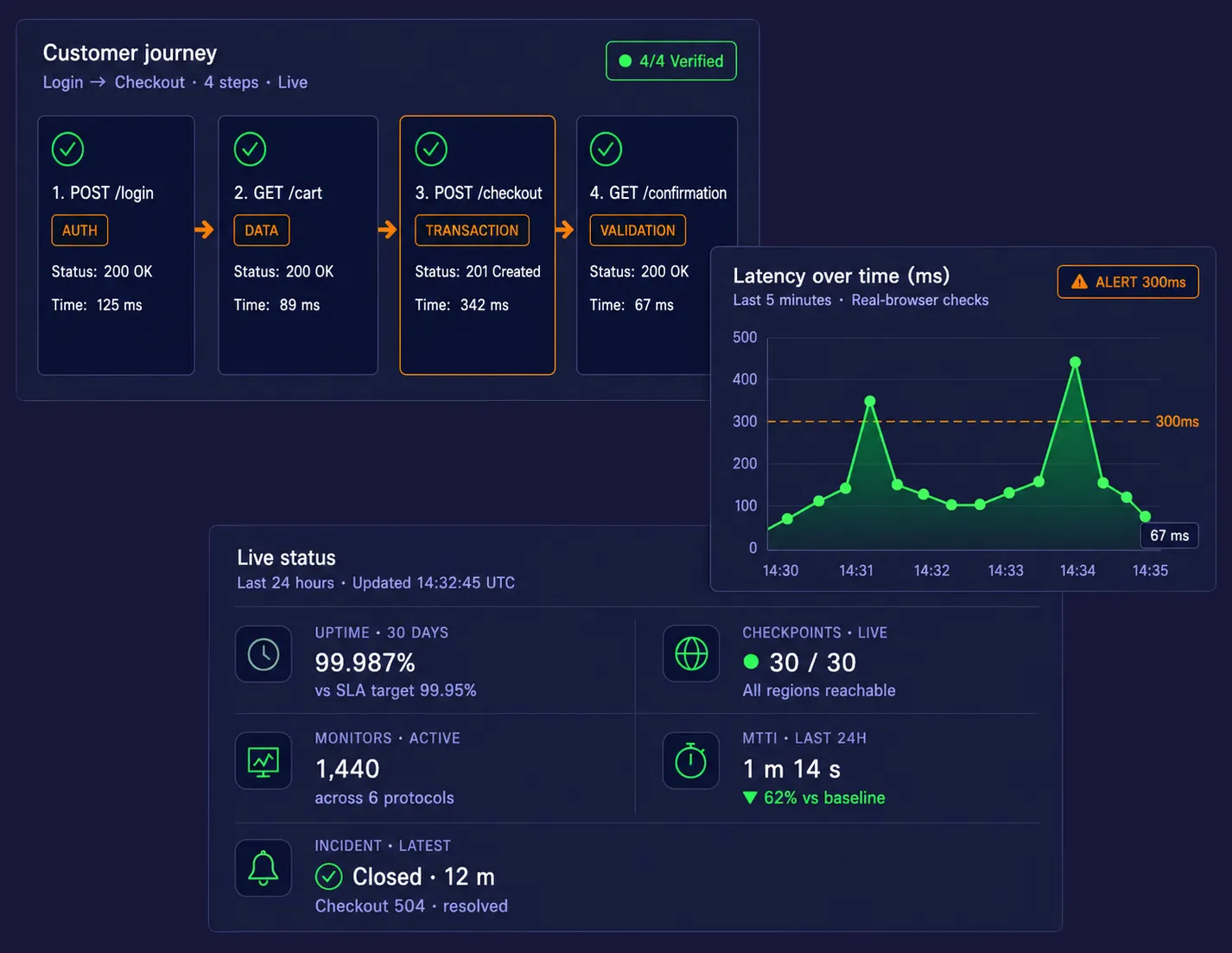
Verwenden Sie den EveryStep Web Recorder, um synthetische Monitoring-Skripte zu erstellen, indem Sie einfach mit Ihrer Website oder Anwendung interagieren. Zeichnen Sie komplexe Workflows wie mehrseitigen Checkout, SSO-Login, Kontoanmeldung, geschützten Dashboard-Zugang und Warenkorbaktionen ohne manuelles Skripting auf. Dieser No-Code-Ansatz macht es einfacher, Webanwendungsmonitoring schnell einzusetzen und dabei die umsatzgenerierenden Pfade zu schützen, die am wichtigsten sind.
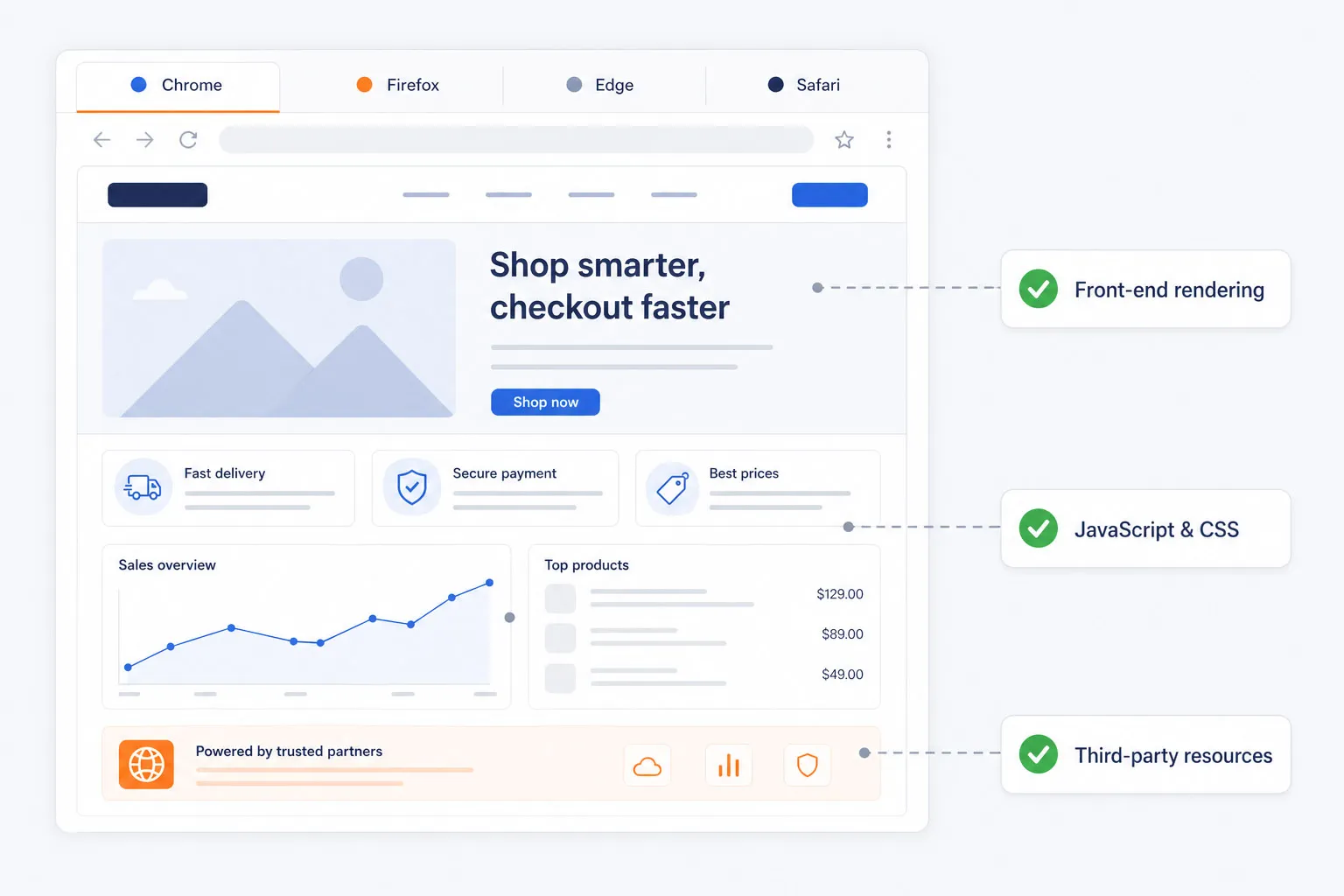
Testen Sie in echten Browsern, nicht in vereinfachten Simulationen
Basis-Uptime-Checks können Frontend-Rendering-Probleme, JavaScript-Fehler, CSS-Probleme oder langsame Drittanbieter-Ressourcen nicht erfassen. Dotcom-Monitor führt synthetische Tests in echten Chrome-, Firefox-, Edge- und Safari-Browsern aus, sodass Teams Leistung und Funktionalität genau so validieren können, wie Benutzer sie erleben.
Das gibt Technik-, QA- und Digitalteams eine realistischere Sicht auf die Gesundheit der Webanwendung im echten Einsatz.
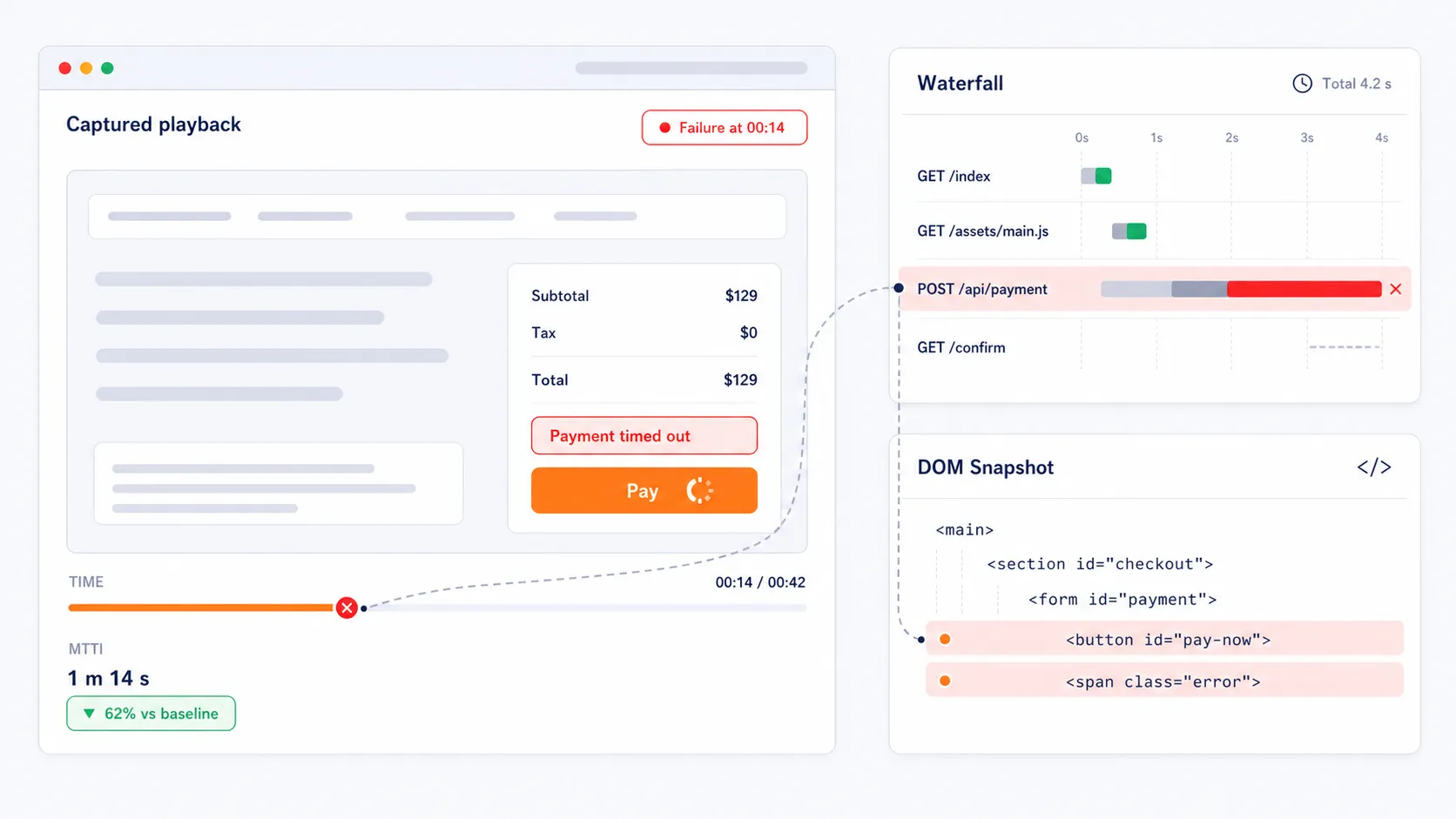
Erfassen Sie visuelle Beweise für schnellere Fehlerbehebung
Wenn eine Transaktion fehlschlägt, erfasst die Plattform Videoaufnahmen des fehlgeschlagenen Testlaufs, Wasserfalldiagramme und vollständige DOM-Snapshots. Diese visuellen Diagnosen helfen Teams, die Ursachenanalyse zu beschleunigen, indem sie den genauen API-Aufruf, Seitenelement, Weiterleitung oder das Skript zeigen, das die Reise unterbrochen hat. Statt zu rätseln, wo das Problem liegt, erhalten Teams sofortige Beweise, die die mittlere Identifikationszeit (Mean Time to Identification) reduzieren.
Erkennen Sie stille Konversionsfehler, bevor Umsatz verloren geht
Eine Seite kann verfügbar erscheinen, während kritische Aktionen wie Login, Checkout, Suche oder Kontozugang im Hintergrund stillschweigend fehlschlagen. Diese stillen Fehler können Konversionsraten verringern, bezahlten Traffic verschwenden und das Kundenvertrauen beschädigen. Dotcom-Monitor hilft Teams, diese Probleme mit synthetischen Checks zu erkennen, die so häufig wie alle 60 Sekunden laufen können, und bietet digitalen Teams einen proaktiven Weg, Kundenerfahrung und Online-Umsatz zu schützen.


Setzen Sie mit Vertrauen von Staging bis Produktion ein
Synthetisches Monitoring ist nicht nur für Produktionsalarme. Teams können Monitore auf Staging-Umgebungen ausrichten oder sie in CI/CD-Workflows integrieren, um Smoke-Tests auf kritischen Pfaden vor und nach Releases auszuführen. Das hilft, Day-1-Fehler zu verhindern, goldene Benutzerreisen zu schützen und gibt Teams mehr Vertrauen, schnell zu veröffentlichen, ohne bestehende Funktionalität zu brechen.
Beginnen Sie mit der Überwachung Ihrer Webanwendungen in weniger als 10 Minuten
Reduzieren Sie Ausfallzeiten, erkennen Sie Probleme, bevor Ihre Kunden es tun, und beweisen Sie Ihre SLA-Einhaltung. Alle Funktionen sind in der Testphase enthalten. Keine Kreditkarte erforderlich. Jederzeit kündbar.
- Keine Kreditkarte erforderlich
- Alle Funktionen enthalten
- Einrichtung in 5 Minuten
- 24x7 Support
Synthetische Monitoring-Software für APIs und Microservices

API-Verfügbarkeit, Genauigkeit und Latenz validieren
Dotcom-Monitor überwacht REST– und SOAP-APIs auf Leistung und Korrektheit, um Teams dabei zu helfen, zu überprüfen, ob Endpunkte die erwarteten Payloads, Statuscodes und Antwortzeiten zurückgeben. Durch kontinuierliche Überprüfung des Serviceverhaltens können Teams Probleme früher erkennen und zuverlässigere Backend-Operationen aufrechterhalten.
Erkennen Sie Timeouts, fehlerhafte Payloads und Authentifizierungsfehler früher
API- und Microservice-Probleme zeigen sich oft zuerst als verschlechterte Funktionalität, langsame Transaktionen oder intermittierende Fehler. Synthetische API-Prüfungen helfen Teams, Timeouts, fehlgeschlagene Authentifizierung, fehlerhafte Antworten und Serviceunterbrechungen zu erkennen, bevor sie zu sichtbaren Kundenproblemen führen.
Dies ist besonders wertvoll in verteilten Architekturen, in denen mehrere Backend-Dienste eine einzelne Nutzerreise beeinflussen.
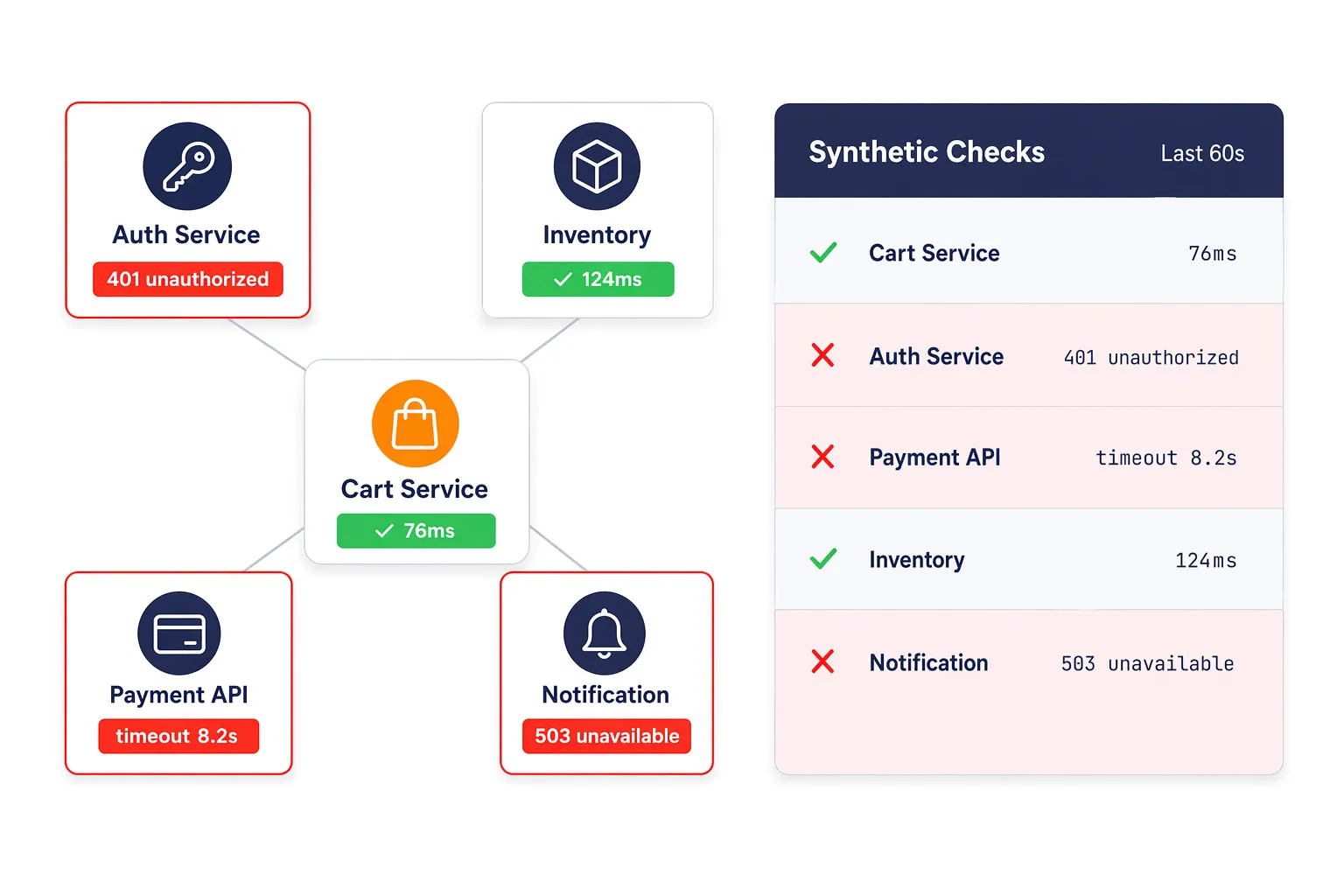

Unterstützen Sie Authentifizierungs- und Service-Level-Validierung
Backend-Zuverlässigkeit beschränkt sich nicht nur auf die Betriebszeit. Teams müssen auch das Authentifizierungsverhalten, den Token-Austausch und geschäftskritische Serviceantworten validieren. Dotcom-Monitor hilft dabei, diese Bedingungen proaktiv zu überprüfen, damit Fehler behoben werden können, bevor sie abhängige Anwendungen oder Kundenabläufe beeinträchtigen.
Beschleunigen Sie die Fehlerursachenanalyse bei Servicevorfällen
Wenn ein Fehler erkannt wird, können Teams die erforderlichen Diagnosedetails überprüfen, um den fehlerhaften Service schneller zu identifizieren. Dies bietet DevOps-, SRE- und Plattformteams einen besseren Ausgangspunkt für die Behebung und hilft, die Zeit für die Suche nach der Ursache eines Backend-Vorfalls zu reduzieren.

Validieren Sie Ihre APIs, bevor Benutzer den Fehler spüren
- Keine Kreditkarte erforderlich
- REST, SOAP, mehrstufig und Alarmierung enthalten
- 24x7 Support
Synthetische Webüberwachung für Webseiten und öffentliche digitale Erfahrungen

Überwachen Sie die Webseitenverfügbarkeit von über 30 globalen Standorten
Dotcom-Monitor bietet synthetische Überwachung von mehr als 30 globalen Checkpoints, um Teams zu helfen, zu verstehen, wie Webseiten in wichtigen Kundenregionen performen. So lassen sich regionale Latenzen, lokale Ausfälle und blinde Flecken leichter erkennen, die bei Überwachung an nur einem Standort übersehen werden würden.
Mehr als nur Betriebszeit: Sichtbarkeit der Leistung
Die synthetische Webseitenüberwachung sollte nicht nur feststellen, ob eine Seite antwortet. Dotcom-Monitor hilft Teams, Leistungsengpässe mit Wasserfalldiagrammberichten und browserbasierten Diagnosen zu analysieren, die langsame Skripte, schwere Ressourcen und andere Probleme aufdecken, die die Seitengeschwindigkeit und Benutzererfahrung verschlechtern.


Verbessern Sie Core Web Vitals und Sichtbarkeit in Suchmaschinen
Suchmaschinenleistung und digitale Erfahrung hängen eng zusammen. Dotcom-Monitor unterstützt Teams dabei, Bedingungen zu überwachen, die Metriken wie Largest Contentful Paint und Cumulative Layout Shift in kontrollierten Umgebungen beeinflussen. Durch frühzeitiges Erkennen langsam ladender Drittanbieter-Ressourcen und CDN-Leistung können Teams die Stabilität der Website verbessern, die SEO-Leistung schützen und schnellere Erlebnisse bieten.
Verwandeln Sie Zuverlässigkeitsdaten in nützliche Berichte
Für große Unternehmen und Dienstleister muss Zuverlässigkeit oft dokumentiert und nicht nur beobachtet werden. Dotcom-Monitor unterstützt automatisierte Dashboards und SLA-orientierte Berichte, die Teams dabei helfen, Betriebszeit- und Leistungszusagen mit Daten aus einem globalen Überwachungsnetzwerk zu belegen.
Beginnen Sie mit der Überwachung der Website-Verfügbarkeit weltweit
- Keine Kreditkarte erforderlich
- Alle Funktionen enthalten
- Einrichtung in 5 Minuten
- 24x7 Support
Synthetische Überwachung für Authentifizierung, interne Apps und fortschrittliche Unternehmen

Überwachen Sie SSO- und MFA-Authentifizierungsabläufe
Single Sign-On- und Multi-Factor-Authentication-Workflows basieren häufig auf verketteten Weiterleitungen, Identitätsanbietern, Token-Austausch und geschützten Sitzungen, die auf schwer diagnostizierbare Weise fehlschlagen können. Dotcom-Monitor kann diese mehrstufigen Authentifizierungsprozesse simulieren, damit Teams fehlerhafte Handshakes, Weiterleitungsprobleme und Zugriffsfehler identifizieren können, bevor Benutzer aus kritischen Systemen ausgesperrt werden.
Private Agenten hinter der Firewall einsetzen
Viele Unternehmensanwendungen, einschließlich interner Mitarbeiterportale, proprietärer Tools, Intranets und ERP-Systeme, befinden sich hinter Unternehmensfirewalls. Dotcom-Monitor unterstützt private synthetische Agenten, auch Private Nodes genannt, die in Ihrer eigenen Umgebung bereitgestellt werden können, um interne Anwendungen aus einer sicheren internen Perspektive zu überwachen.


Isolierung der Auswirkungen von Drittanbieter-Skripten und DOM-Instabilität
Moderne digitale Erlebnisse hängen von Analytic-Tags, Chat-Widgets, externen Skripten und anderen Drittanbieter-Elementen ab, die das Rendering blockieren und Layout-Instabilität verursachen können. Die Überwachung mit realen Browsern hilft Teams herauszufinden, welche externe Ressource das Erlebnis verlangsamt oder die Seitenstabilität beeinträchtigt, sodass sie die Lade-Strategie optimieren und Benutzerhemmnisse reduzieren können.
Reproduzieren Sie intermittierende Fehler während stark frequentierter Ereignisse
Intermittierende E-Commerce– und SaaS-Anwendungsprobleme sind während Spitzenzeiten oft schwer zu erfassen. Die synthetische Überwachung hilft dabei, benutzerseitige Fehler zu reproduzieren, indem die vollständige Transaktionslogik wiederholt ausgeführt wird, sodass Beweise für API-Verlangsamungen, Frontend-Fehler oder Backend-Leistungsprobleme leichter erfasst werden können, die nur unter Last auftreten.

Stellen Sie sicher, dass Ihre Geschäfts-Infrastruktur läuft
- Keine Kreditkarte erforderlich
- Alle Funktionen enthalten
- Einrichtung in 5 Minuten
- 24x7 Support
Warum Teams Dotcom-Monitor für synthetisches Monitoring wählen

Mittlere Erkennungszeit verkürzen
Ausfälle werden umso teurer, je länger Teams benötigen, das Problem zu finden. Mit visueller Diagnose, synchronisierter Wiedergabe, Wasserfalldiagrammdaten und kontextbezogenen Benachrichtigungen bietet Dotcom-Monitor Teams einen schnellen Einstiegspunkt zur Fehlerbehebung.
Code-freies synthetisches Transaktionsmonitoring
Teams können komplexe Workflows aufzeichnen, ohne manuell Skripte schreiben zu müssen, was den schnellen Start des Monitorings erleichtert und die Abdeckung an das tatsächliche Nutzerverhalten auf Ihrer Website anpasst.


Proaktive Benachrichtigungen in den Tools, die Ihr Team bereits nutzt
Dotcom-Monitor integriert proaktive Benachrichtigungen in bestehende Workflows über Slack, PagerDuty, Microsoft Teams und ServiceNow, sodass Teams schneller reagieren können, wenn Leistungs- oder Verfügbarkeitsprobleme erkannt werden.
Frontend-Erfahrung mit Infrastruktur-Signalen korrelieren
Dotcom-Monitor unterstützt die Sichtbarkeit über Websites, Anwendungen, APIs und Infrastruktur-Checks wie DNS, FTP und TCP. Dies hilft Teams, die Gesundheit des Backends und das Netzwerkverhalten mit der tatsächlichen digitalen Nutzererfahrung zu verbinden.

Antworten erhalten
Häufig gestellte Fragen
Kann ich Private Agents hinter der Firewall meines Unternehmens bereitstellen?
Ja, Dotcom-Monitor ermöglicht die Bereitstellung von Private Agents (auch Private Nodes genannt), um Anwendungen speziell hinter Ihrer Unternehmensfirewall zu überwachen. Diese Funktion ist entscheidend, um die Leistung und Verfügbarkeit interner Mitarbeiterportale, Intranets oder HR-Tools zu verfolgen, die nicht über das öffentliche Internet zugänglich sind.
Was ist ein privater synthetischer Agent?
Ein privater synthetischer Agent ist eine leichte Softwareinstanz, die auf Ihrem eigenen lokalen Server oder privaten Cloud installiert wird und als sicherer interner Standort fungiert. Im Gegensatz zu öffentlichen Überwachungsknoten, die in globalen Rechenzentren betrieben werden, simuliert ein privater Agent die Erfahrung eines tatsächlichen Mitarbeiters oder internen Systems innerhalb Ihrer eigenen Netzwerk-Infrastruktur.
Was ist der Unterschied zwischen APM und synthetischem Monitoring?
Der Hauptunterschied liegt in der Beobachtungsrichtung: Application Performance Monitoring (APM) ist eine “Inside-Out”-Strategie, die Agenten auf Servern verwendet, um interne Codeausführung, Datenbankabfragen und Hardware-Ressourcennutzung zu verfolgen und Backend-Engpässe zu identifizieren. Im Gegensatz dazu ist das synthetische Monitoring eine “Outside-In”-Methode, die Skripte verwendet, um das Verhalten von Endbenutzern zu simulieren – wie Einloggen oder Checkout – und proaktiv Frontend-Ausfälle und langsame Ladezeiten erkennt, bevor reale Nutzer sie erleben.
Welche verschiedenen Arten von synthetischen Monitoren gibt es?
Synthetische Monitore werden nach der technischen Tiefe der Überprüfung kategorisiert: Web-Uptime-Monitore führen grundlegende Protokollprüfungen wie DNS, FTP und Ablauf von SSL-Zertifikaten durch. Web-API-Monitore validieren die Funktionalität von REST-, SOAP- und WebSocket-Antworten. Web Application (UserView)-Monitore nutzen eine vollständige Browser-Engine, um mehrstufige Transaktionen zu simulieren. Schließlich überprüfen Media-Streaming-Monitore die Verfügbarkeit und Qualität von Audio- und Videowiedergaben.
Von wie vielen Standorten sollte ich überwachen?
Für Unternehmens-Qualität sollten Sie von 3 bis 5 Standorten aus überwachen, die alle wichtigen geografischen Regionen abdecken, in denen Ihre Kunden ansässig sind. Dieser Multi-Node-Ansatz ist entscheidend, da er eine “Double-Check”-Logik ermöglicht, bei der ein von einem Knoten gemeldeter Fehler sofort von anderen überprüft wird.
Das sagen unsere Kunden
"I absolutely love the comprehensive monitoring services Dotcom-Monitor provides. The real-time alerts and detailed performance analytics have been a game-changer for our website's uptime and speed. The global monitoring feature ensures that our site is optimized everywhere, and the intuitive dashboard makes it easy to track performance. Their customer support is exceptional — always responsive and efficient."
Tomer C.
Managing Director · Facilities Services
Verified Capterra review · March 2025
"One of Dotcom's best features is the push/pull API capabilities that provide us with network performance data. We use this to monitor for performance issues as well as page loading stats. Dotcom-Monitor allows us to monitor multiple services within one interface and platform. It's allowed us to operate more efficiently."
Gregory S.
Manager · Broadcast Media
Verified Capterra review · May 2020
"I have been thoroughly impressed with the level of detail and comprehensiveness of the reports generated by the software. Moreover, the support team at Dotcom-Monitor has exceeded my expectations. On almost a daily basis, I reach out with various questions and they have consistently demonstrated unwavering patience, providing detailed and insightful answers."
Shirin R.
Software Test Engineer · Computer Software
Verified Capterra review · February 2023
"I'm a network analyst and use Dotcom tools inside the ISP I work, it's a really good and reliable tool for monitoring things along the network, and testing network components, I usually use it to make diagnostics of servers latency, and dns resolve time."
Leonardo J.
IT & Network Infrastructure Analyst Internet
Verified Capterra review · October 2022
Eine Software für synthetisches Monitoring | Null blinde Flecken
Keine Kreditkarte erforderlich. Alle Premium-Funktionen enthalten. 24×7 Experten-Support.