Revu par les ingénieurs de performance de Dotcom-Monitor · Toutes les données des concurrents vérifiées par rapport aux pages de tarification des fournisseurs à la date de publication.

En un coup d’œil — la réponse courte
Si vous avez besoin de profondeur en surveillance synthétique et API : Dotcom-Monitor est la mise à niveau la plus proche et équivalente à Pingdom, avec des workflows API multi-étapes, des parcours utilisateurs scriptés dans des navigateurs réels et une tarification par abonnement prévisible.
Si vous voulez une option gratuite pour des projets personnels : UptimeRobot (50 moniteurs, intervalles de 5 minutes — usage personnel uniquement à partir d’octobre 2024) ou StatusCake (10 moniteurs avec vérifications SSL, DNS et domaine incluses).
Si vous avez besoin d’une observabilité full-stack : Datadog pour la plus grande empreinte d’intégration, ou New Relic pour son palier gratuit perpétuel de 100 Go et ses synthetics performants.
Si vous souhaitez surveillance + gestion des incidents + journaux dans un seul outil : Better Stack — particulièrement adapté aux startups et équipes en croissance.
SolarWinds Pingdom — largement connu simplement sous le nom de Pingdom, suite à son acquisition à 103 millions $ par SolarWinds en 2014 — est une référence dans la surveillance de sites web depuis plus d’une décennie. Il couvre bien les fondamentaux : suivi de disponibilité, tests de vitesse de page, surveillance de transactions et Real User Monitoring (RUM) sur les plans supérieurs. Pour les équipes avec des besoins simples, il reste un outil capable.
Mais ce n’est pas adapté à tout le monde. Certaines équipes le dépassent à mesure que leur infrastructure évolue. D’autres trouvent le modèle de tarification difficile à prévoir, ou souhaitent plus de flexibilité dans la configuration des vérifications de surveillance. Beaucoup préfèrent des plateformes qui regroupent alertes, workflows d’incidents, journaux, et APM en plus de la surveillance — bien qu’il soit important de noter que « observabilité full-stack » dépasse un simple regroupement. Cela dépend d’une instrumentation cohérente à travers métriques, journaux, et traces, avec la propagation du contexte qui permet aux ingénieurs de déboguer des modes de défaillance inconnus, pas seulement de détecter les connus.
Ce guide couvre les meilleures alternatives à Pingdom en 2026, avec une présentation complète des fonctionnalités de chaque outil — pas seulement une dimension de leurs capacités. Que vous ayez besoin de simples vérifications de disponibilité, de surveillance synthétique avancée, d’observabilité full-stack, ou de quelque chose entre les deux, il y a ici un outil adapté.
Comment nous avons évalué ces alternatives à Pingdom
Chaque outil de cette liste a été évalué selon neuf critères identiques. Les chiffres ont été vérifiés directement auprès des pages de tarification, documentation, et annonces produit de chaque fournisseur en mai 2026.
Surveillance de la disponibilité
Types de vérifications supportés, intervalles, emplacements mondiaux de surveillance.
Surveillance synthétique
Tests de transaction, capacités de scripting, simulation dans un navigateur réel.
Real User Monitoring
Visibilité des sessions utilisateurs réelles et performances front-end.
Surveillance API
Tests d’endpoints, validation des réponses, workflows multi-étapes.
Alertes
Canaux supportés, routage d’astreinte, politiques d’escalade.
Intégrations
Couverture des outils DevOps, gestion d’incidents et communication.
Rapports
Tendances, suivi des SLA, rétention historique.
Tarification
Structure des plans, facteurs de coût, évolutivité des coûts.
Simplicité d’utilisation
Complexité d’installation, qualité de l’interface, courbe d’apprentissage.
Alternatives à Pingdom en un coup d’œil
| Outil | Disponibilité | Synthétique | RUM | Profondeur API | Journaux | Tarification | Idéal pour |
|---|---|---|---|---|---|---|---|
| Dotcom-MonitorChoix principal | Oui | Oui (profond) | Non | Oui (profond) | Non | Abonnement | Profondeur synthétique & API |
| UptimeRobot | Oui | Non | Non | De base | Non | Gratuit + paliers | Disponibilité économique |
| Datadog | Oui | Oui | Oui | Oui | Oui | À l’usage | Observabilité full-stack |
| New Relic | Oui | Oui | Oui | Oui | Oui | Usage + palier gratuit | APM + télémétrie |
| StatusCake | Oui | Limité | Non | De base | Non | Gratuit + paliers | SSL/DNS + disponibilité |
| Uptrends | Oui | Oui | Oui | Oui | Non | Par paliers | Équilibre Synthétique + RUM |
| Better Stack | Oui | De base | Oui | De base | Oui | Abonnement + gratuit | Disponibilité + incidents + journaux |
Vérifié en mai 2026 par rapport aux pages de tarification et produit de chaque fournisseur. « Profond » indique des workflows multi-étapes, scriptés ou basés sur des assertions ; « De base » indique des vérifications de code d’état ou une seule requête.
1 Dotcom-Monitor
★ Choix de l’éditeur pour la surveillance synthétique & API
Dotcom-Monitor est une plateforme de surveillance dédiée axée sur les tests synthétiques et la validation des performances. Là où beaucoup d’outils partent de l’observabilité infrastructurelle et ajoutent la surveillance comme fonctionnalité, Dotcom-Monitor a été conçu dès le départ pour la surveillance externe — exécutant des vérifications synthétiques contrôlées et répétables en dehors de votre infrastructure afin de valider la disponibilité et les performances pour des parcours utilisateurs spécifiques dans des applications web et workflows API.
Surveillance de la disponibilité et de l’accessibilité
Dotcom-Monitor supporte les vérifications HTTP/HTTPS, DNS, FTP, SFTP/FTPS, SMTP, POP3/IMAP, TCP/UDP, SIP, Media Stream, DNSBL, Trace Route, et PING. Les tests sont réalisés à partir d’un réseau mondial d’emplacements de surveillance, offrant aux équipes une visibilité sur la disponibilité selon les régions. Vous pouvez configurer des seuils d’alerte, définir des fenêtres de maintenance, et recevoir des notifications quand les services sont hors ligne ou dégradés en dessous des repères définis.
Surveillance synthétique
C’est ici que Dotcom-Monitor est le plus performant. La surveillance synthétique va bien au-delà des simples contrôles de disponibilité : les équipes peuvent script des parcours utilisateurs multi-étapes simulant de vraies interactions avec des applications web — soumissions de formulaires, flux de connexion, processus de paiement, chemins de navigation — via des sessions automatisées dans des navigateurs basés sur Chromium qui exécutent JavaScript, rendent les pages, capturent des captures d’écran et mesurent les temps d’étape plus précisément que de simples contrôles HTTP.
Ce niveau de détail détecte des défaillances qu’un contrôle HTTP basique manquerait — problèmes de rendu côté client, interactions cassées, ou workflows échouant seulement dans une région spécifique — en combinant étapes explicites et assertions (clics, vérifications DOM, détection d’erreurs JS, résultats attendus de navigation ou XHR) dans chaque test. Une page qui se charge mais affiche un rendu incorrect, ou un workflow qui échoue uniquement en production, sera détecté là où un contrôle HTTP simple afficherait un code 200 propre.
Surveillance API
Dotcom-Monitor supporte des workflows API multi-étapes, incluant la gestion dynamique de l’authentification (tokens de session, flux OAuth), l’enchaînement de requêtes, la validation des corps de réponse, les vérifications de schéma, et le passage de variables entre requêtes. Cela permet de tester non seulement si un endpoint répond, mais aussi s’il renvoie les bonnes données et se comporte correctement dans un workflow plus large. Pour les équipes gérant des API en production, cette profondeur fait souvent la différence avec des outils plus légers.
Real User Monitoring (RUM)
Dotcom-Monitor n’offre pas actuellement de RUM. Si la visibilité sur les sessions utilisateurs réelles et la performance front-end en production est nécessaire, complétez par un outil dédié RUM. Pour la plupart des équipes, une profondeur synthétique dédiée plus un outil RUM concentré séparé est un signal plus fiable qu’une plateforme unique tentant de faire les deux de manière adéquate.
Alertes, rapports & intégrations
Les alertes sont envoyées par e-mail, SMS, appels téléphoniques, PagerDuty, Slack, OpsGenie, xMatters, et webhooks. La logique d’escalade garantit que les bonnes personnes sont notifiées selon la gravité et le temps de réponse. Le reporting SLA et les tableaux de bord de disponibilité fournissent une visibilité historique, et les rapports peuvent être partagés avec les parties prenantes en fonction des objectifs SLA définis.
Tarification
Dotcom-Monitor utilise un modèle par abonnement avec un prix lié aux produits sélectionnés (web performance, surveillance API, tests de charge) et à la fréquence et au volume des vérifications. La tarification est bien plus prévisible que les plateformes d’observabilité à consommation, mais nécessite une planification quand la fréquence ou le nombre de moniteurs augmente. Pas de plan gratuit, mais un essai de 30 jours est disponible.
Facilité d’utilisation
La configuration est simple pour les vérifications basiques. Les tests synthétiques scriptés et workflows API multi-étapes ont une courbe d’apprentissage modérée — les équipes sans expérience préalable en scripting synthétique peuvent nécessiter un ou deux jours pour maîtriser des flux complexes confortablement.
Limites de Dotcom-Monitor
- Pas de Real User Monitoring
- Moins d’intégrations que les plateformes d’observabilité complètes
- Pas de gestion des journaux ni surveillance infrastructurelle
- Non adapté aux équipes souhaitant une plateforme unique couvrant infrastructure, APM et surveillance
Résumé : Dotcom-Monitor est un choix solide pour les équipes nécessitant une surveillance synthétique et API approfondie dans un outil dédié. Il est particulièrement adapté aux équipes QA, ingénieurs centrés sur la performance, et organisations avec des workflows utilisateurs complexes ou dépendances API. Pour les équipes ayant aussi besoin de visibilité infrastructurelle, gestion de logs ou APM, il fonctionne mieux en complément d’autres outils.
2 UptimeRobot
UptimeRobot s’est fait un nom en faisant une chose simplement et bien : vous alerter quand votre site ou service est indisponible. C’est l’un des outils de disponibilité les plus utilisés au monde parce qu’il élimine les barrières au démarrage — le plan gratuit est vraiment utile, pas un leurre.
Surveillance de la disponibilité et accessibilité
UptimeRobot supporte HTTP(S), moniteurs par mot-clé, ping, port et heartbeat. Le moniteur de mot-clé est particulièrement utile pour détecter des pages qui chargent mais affichent une erreur, ou du contenu disparaissant subitement. Le plan gratuit comprend 50 moniteurs avec intervalles de 5 minutes ; les plans payants descendent jusqu’à 30 secondes d’intervalle et augmentent le nombre de moniteurs.
Avertissement important : Depuis octobre 2024, le plan gratuit d’UptimeRobot est limité à un usage personnel non commercial selon leurs conditions d’utilisation. Pour la surveillance commerciale ou générant des revenus, un plan payant est requis.
Surveillance synthétique, RUM et API
UptimeRobot ne propose pas de surveillance de transactions synthétiques ni de RUM. La surveillance API se limite à l’envoi de requêtes HTTP et à la vérification d’un code de réponse réussi — suffisant pour savoir si l’endpoint est accessible mais pas pour valider que l’API retourne des données correctes ou réalise un workflow multi-étapes.
Alertes et tarification
Le plan gratuit ne supporte que les alertes par e-mail. Les plans payants ajoutent SMS, appels vocaux, notifications push, Slack, PagerDuty, Zapier, et webhooks. Les niveaux payants (Solo, Team, Enterprise) évoluent selon le nombre de moniteurs et l’intervalle de vérification, avec une tarification transparente.
Limites d’UptimeRobot
- Pas de surveillance synthétique ni simulation de parcours utilisateurs
- Pas de RUM
- Surveillance API limitée à la disponibilité — pas de validation des flux d’authentification ou de workflow
- Pas de gestion des journaux ni visibilité infrastructurelle
- Le plan gratuit est réservé à un usage personnel — interdit pour surveillance commerciale
- Les alertes SMS sont payantes uniquement
Résumé : Excellent dans son périmètre. Si vous devez savoir quand un site personnel ou un projet annexe tombe à moindre coût, difficile à battre. Les limites sont importantes pour toute équipe gérant des applications de production avec de réelles attentes utilisateurs, dépendances API ou engagements de fiabilité — et la restriction d’usage commercial du palier gratuit pousse de plus en plus les équipes sérieuses vers un plan payant ou un autre outil.
3 Datadog
Datadog est l’une des plateformes d’observabilité et de surveillance les plus complètes disponibles. Ce n’est pas seulement un outil de surveillance — c’est une plateforme complète d’observabilité qui intègre métriques d’infrastructure, performances applicatives, journaux, tests synthétiques, et données utilisateurs réelles en une vue unifiée. Pour les équipes gérant des systèmes cloud natifs complexes, cette ampleur est sa valeur centrale.
Surveillance synthétique et disponibilité
Datadog supporte les tests de navigateur (enregistrement de script ou codage manuel), tests API avec validation de statut / en-têtes / corps / latence / SSL, et tests API multi-étapes où des variables peuvent être extraites d’une réponse et passées à la suivante. Les tests synthétiques peuvent être déclenchés dans des pipelines CI/CD pour détecter les régressions avant la production.
Real User Monitoring (RUM)
Datadog RUM capture des sessions utilisateurs réelles, incluant temps de chargement, Core Web Vitals, erreurs JavaScript, actions utilisateur et replays de sessions. Il peut corréler événements front-end avec traces backend lorsque le SDK RUM et le traçage backend sont instrumentés et la propagation de contexte trace bien configurée entre passerelles et services. La corrélation fonctionne bien dans des environnements avec instrumentation cohérente de bout en bout, mais peut avoir des lacunes quand les requêtes passent par des load balancers, CDN ou services tiers ne conservant pas le contexte de trace — une réalité fréquente en production.
Infrastructure, APM, journaux et intégrations
La surveillance infrastructurelle de Datadog couvre fournisseurs cloud, conteneurs, Kubernetes, serverless, et bases de données. L’APM fournit traçage distribué, cartes de services, et profilage au niveau du code. La gestion des journaux inclut ingestion, parsing, recherche, alertes, et archivage. Les journaux peuvent être corrélés aux traces et métriques pour une enquête complète d’incidents. Datadog a dépassé les 1 000 intégrations en 2025, l’une des bibliothèques les plus vastes dans le domaine de la surveillance.
Tarification
Datadog utilise un modèle de tarification à l’usage. Les coûts augmentent selon plusieurs dimensions simultanément — hôtes d’infrastructure, volume de journaux, spans APM, sessions RUM, exécutions de tests synthétiques, et plus encore. Cela en fait l’une des plateformes les plus puissantes disponibles, mais aussi une des plus difficiles à budgétiser. Les équipes ne surveillant pas attentivement leur usage peuvent voir les coûts exploser à mesure que leurs systèmes s’étendent. Les paliers gratuits et offres promotionnelles changent fréquemment — vérifiez la disponibilité actuelle de tout plan gratuit ou palier développeur sur la page de tarification Datadog.
Limites de Datadog
- Tarification pouvant escalader rapidement et de façon imprévisible
- Configuration et installation nécessaires pour exploiter pleinement
- Peut paraître excessif pour les équipes ayant seulement besoin de disponibilité ou surveillance synthétique
- L’amplitude des fonctionnalités peut submerger les nouvelles équipes
Résumé : Datadog est le choix adapté pour les équipes souhaitant une plateforme unique couvrant infrastructure, applications, journaux, utilisateurs et tests externes. Si votre équipe gère un environnement cloud natif complexe et a besoin d’une profonde corrélation à chaque couche, Datadog répond — à un coût et une complexité que les petites équipes peuvent avoir du mal à justifier.
4 New Relic
New Relic est une plateforme d’observabilité bien établie, fortement axée sur la performance applicative. Comme Datadog, elle couvre APM, infrastructure, journaux, surveillance navigateur, et synthetics — mais elle est historiquement plus performante en visibilité au niveau du code applicatif et offre un point d’entrée plus accessible via son palier gratuit.
Surveillance synthétique
New Relic Synthetics supporte des moniteurs simples de navigateur, moniteurs scriptés (interactions multi-étapes avec assertions personnalisées), tests API (statut, en-têtes, contenu corps), moniteurs d’étapes (constructeur de transactions navigateur sans code), vérifications de certificats, et scan de liens cassés. Le constructeur d’étapes sans code rend les tests synthétiques accessibles sans script.
RUM et APM
New Relic Browser Monitoring capture les données de performance réelles des utilisateurs telles que temps de chargement des pages, Core Web Vitals, erreurs JavaScript, performances Ajax, et traces de sessions — et se connecte aux traces backend APM, permettant aux équipes de remonter depuis un problème front-end jusqu’à un service backend ou requête précise. New Relic APM est l’une de ses forces majeures, instrumentant le code applicatif en Java, .NET, Python, Node.js, Ruby, PHP, et Go avec traçage distribué, traces de transaction, analyse des requêtes de base de données, et profilage code.
Tarification
New Relic utilise un modèle basé sur l’usage, piloté par le volume de données ingérées et le nombre d’utilisateurs plateforme. Le palier gratuit offre 100 Go de données ingérées par mois et un utilisateur complet sans limite de temps — l’un des points d’entrée les plus généreux parmi les plateformes d’observabilité full-stack et un différenciateur significatif pour les petites équipes.
Limites de New Relic
- Le plein potentiel nécessite une instrumentation applicative et un temps de configuration conséquent
- La tarification peut très vite augmenter à forts volumes de données
- Peut paraître excessif pour les équipes aux besoins simples en surveillance
Résumé : Un choix solide pour les équipes d’ingénierie souhaitant une observabilité complète avec un palier gratuit permettant d’explorer les capacités avant engagement. Particulièrement adapté aux équipes développant sur microservices ou architectures distribuées nécessitant de tracer des problèmes à travers les frontières de services.
5 StatusCake
StatusCake est souvent négligé au profit de noms plus connus, mais il offre une bonne gamme de types de surveillance dépassant la simple disponibilité — le rendant plus polyvalent que des outils comme UptimeRobot sans la complexité des plateformes full-stack.
Ce que StatusCake comprend
StatusCake supporte les vérifications HTTP, TCP, DNS, et PING avec intervalles personnalisables et alertes multi-emplacements. Ajouts notables que d’autres outils facturent ou omettent complètement : surveillance intégrée des certificats SSL avec alertes d’expiration, surveillance de l’expiration des domaines avertissant avant qu’une inscription n’expire, surveillance des changements d’enregistrements DNS, et suivi de la vitesse de page. StatusCake propose aussi un scan léger de malwares/listes noires — utile en détection complémentaire, pas en substitut à des outils de sécurité dédiés.
Plan gratuit
Le plan gratuit de StatusCake inclut 10 moniteurs de disponibilité avec intervalles de 5 minutes, 1 moniteur de vitesse de page, 1 moniteur de domaine, et 1 moniteur SSL — une offre gratuite plus complète que beaucoup de concurrents. Les comptes gratuits sont désactivés après 90 jours d’inactivité. Les plans payants (Indie, Business, Agency) ajoutent des moniteurs, des intervalles plus rapides, et des fonctionnalités avancées.
Surveillance synthétique, RUM et API
La surveillance de transactions synthétiques est limitée comparée aux plateformes dédiées — les contrôles de transaction basiques sont supportés mais il manque la profondeur de scripting, la simulation en navigateur réel, et la validation de workflows multi-étapes présents dans des outils comme Dotcom-Monitor ou Uptrends. Pas de RUM. La surveillance API est uniquement au niveau du code d’état — suffisante pour la disponibilité, mais pas adaptée à la validation de workflows API en production.
Limites de StatusCake
- Pas de RUM
- Surveillance synthétique limitée — pas adaptée aux parcours utilisateur complexes
- Pas de gestion des journaux ni surveillance infrastructurelle
- Surveillance API limitée à la disponibilité — pas adaptée à la validation de workflows API en production
Résumé : Un outil bien équilibré pour les équipes souhaitant plus que la disponibilité basique sans s’engager dans une plateforme complexe. SSL, DNS, expiration de domaine, et détection de malwares en plus de la disponibilité offrent une excellente valeur pour les propriétaires de sites et petites équipes de développement. Si votre préoccupation principale est la santé des sites plus que les workflows applicatifs complexes, c’est un choix sérieux.
6 Uptrends
Uptrends est une plateforme dédiée construite autour de tests synthétiques, surveillance en navigateur réel, et Real User Monitoring. Elle occupe une place intermédiaire utile : plus capable que les outils de disponibilité basiques, mais plus ciblée et accessible que les plateformes d’observabilité complètes comme Datadog ou New Relic.
Contexte de propriété
Uptrends a été acquis par ITRS Group en novembre 2020, où il continue d’opérer comme un produit distinct avec sa propre interface et tarification. ITRS est un groupe logiciel de surveillance soutenu par PE (avec TA Associates) spécialisé dans l’observabilité des marchés financiers et la performance IT. Pertinent pour les acheteurs considérant la stratégie fournisseur à long terme, bien que l’expérience produit au quotidien soit restée stable.
Surveillance synthétique
La surveillance synthétique d’Uptrends est complète : contrôles de pages complètes avec diagrammes en cascade, surveillance transactionnelle multi-étapes scriptée pour flux de connexion / recherche et filtrage / soumissions de formulaires / paiements, tests dans navigateurs Chromium et Firefox réels, plus un enregistreur sans code et une interface de script JavaScript pour interactions complexes.
RUM et surveillance API
Uptrends RUM capture les données de performance réelles des utilisateurs — chargement, Core Web Vitals, segmentation géographique et par appareil, suivi des parcours utilisateurs — réunies avec les données synthétiques dans la même plateforme. La surveillance API supporte les tests d’endpoints avec validation des réponses, séquences de requêtes multi-étapes, et gestion de variables.
Tarification
Uptrends fonctionne sur un modèle d’abonnement par paliers où le tarif augmente avec le nombre de moniteurs, la fréquence des vérifications, et les fonctionnalités activées. Les coûts peuvent croître significativement avec l’extension de la surveillance — notamment en ajoutant la collecte de données RUM ou des tests synthétiques haute fréquence depuis plusieurs emplacements mondiaux. Essai gratuit disponible, pas de plan gratuit permanent.
Limites d’Uptrends
- Pas de gestion des journaux ni surveillance infrastructurelle
- Tarification qui augmente rapidement avec le volume
- Non adapté aux équipes ayant aussi besoin d’APM ou d’observabilité infrastructurelle dans la même plateforme
Résumé : L’une des meilleures plateformes dédiées de surveillance synthétique dans cette liste. La combinaison d’un large réseau mondial de surveillance, de tests transactionnels en navigateur réel, et de RUM dans un produit unique la rend polyvalente pour les équipes focalisées sur la performance qui n’ont pas besoin d’une observabilité complète.
7 Better Stack
Better Stack — plateforme unifiée née de la fusion de Better Uptime (surveillance disponibilité) et Logtail (gestion des journaux) — adopte une approche différente des outils de cette liste. Plutôt que de se concentrer sur la profondeur dans un type de surveillance, il combine surveillance de la disponibilité, gestion des incidents d’astreinte, Real User Monitoring, et gestion des journaux dans une plateforme propre et unifiée conçue pour minimiser la prolifération d’outils.
Surveillance de la disponibilité et synthétique
Better Stack supporte les vérifications HTTP, TCP, ping, DNS, SMTP, et POP3. L’installation est parmi les plus rapides du secteur — les moniteurs basiques peuvent être opérationnels en moins d’une minute. Les capacités synthétiques ont évolué : Better Stack propose désormais des contrôles Playwright basés sur navigateur qui peuvent exécuter des parcours utilisateurs multi-étapes avec exécution complète de JavaScript. Le produit synthétique est encore moins mature que les plateformes dédiées comme Dotcom-Monitor ou Uptrends, mais suffisamment capable pour de nombreux workflows courants.
Real User Monitoring
Better Stack propose un produit RUM complet avec replay de sessions (avec détection de rage-clicks et lecture 2×), suivi Core Web Vitals par URL avec alertes, et corrélation frontend-backend reliant les sessions RUM aux journaux et traces backend. Cette addition relativement récente étend significativement la couverture de Better Stack comparée aux revues antérieures.
Gestion des incidents — le point fort
C’est ici que Better Stack se distingue vraiment : plannings et rotations d’astreinte avec escalade automatique, routage des alertes par moniteur déclencheur, chronologie d’incidents auto-générée, et pages de statut publiques intégrées qui se mettent à jour automatiquement en fonction de l’état des incidents. Pour les équipes qui gèrent actuellement la surveillance dans un outil et la réponse aux incidents dans un autre (comme PagerDuty), Better Stack offre une consolidation intéressante.
Gestion des journaux
Better Stack inclut la gestion des journaux (anciennement Logtail) dans la même plateforme. Les équipes peuvent ingérer des journaux d’applications, d’infrastructure, et de services, puis les rechercher, suivre en temps réel, et générer des alertes conjointement avec les données de disponibilité — un différenciateur notable que la plupart des outils de disponibilité dédiés n’offrent pas.
Tarification
Better Stack utilise un modèle par abonnement dont la tarification dépend du nombre de moniteurs et des membres de l’équipe. Un plan gratuit utile couvre la surveillance basique (10 moniteurs, 5 000 replays de sessions/mois, 100 000 exceptions/mois, une page de statut, et gestion d’incidents).
Limites de Better Stack
- La surveillance synthétique est encore moins mature que sur les plateformes dédiées
- Surveillance API moins profonde que les outils dédiés (code d’état + validation simple de contenu; pas de workflows API multi-étapes)
- APM limité comparé à Datadog / New Relic
- Plateforme plus récente que les acteurs établis — certaines fonctionnalités entreprise encore en maturation
Résumé : Better Stack tire sa place non pas par la profondeur dans un type de surveillance mais par une intégration intelligente de la disponibilité, l’astreinte, le RUM, et la gestion des journaux dans une plateforme bien conçue. Pour les startups et équipes en croissance voulant réduire la prolifération d’outils et assurer une bonne gestion des incidents dès le départ, c’est une option des plus pratiques. Les équipes avec des besoins complexes en synthétique ou APM devront chercher ailleurs.
Autres alternatives notables à Pingdom
Selon votre environnement et vos exigences, ces outils méritent aussi considération :
- Catchpoint — Surveillance de niveau entreprise axée sur la performance internet, visibilité du dernier kilomètre, et surveillance CDN/DNS. Choix solide quand la performance réseau est critique.
- Grafana Cloud — Idéal pour les équipes utilisant déjà Grafana et Prometheus. Combine métriques, journaux, et traces avec surveillance synthétique intégrée via Grafana k6.
- Checkly — Surveillance synthétique orientée développeur, code-first en JavaScript/TypeScript avec support natif Playwright. Excellent pour les équipes d’ingénierie versionnant leur surveillance avec leur code applicatif.
- Prometheus + Blackbox Exporter — Combinaison open-source pour les équipes voulant un contrôle total sur leur infrastructure de surveillance. Puissant et flexible, mais demande une installation et maintenance conséquentes.
- Site24x7 — Surveillance tout-en-un couvrant sites web, serveurs, applications, et réseaux. Ensemble d’outils large à un prix accessible, notamment pour les prestataires de services managés.
Comment choisir la bonne alternative à Pingdom
Le bon outil de surveillance dépend de trois choses : ce que vous devez surveiller, la complexité que votre équipe peut gérer, et votre budget. L’arbre décisionnel ci-dessous mappe les cas les plus courants vers un point de départ recommandé.
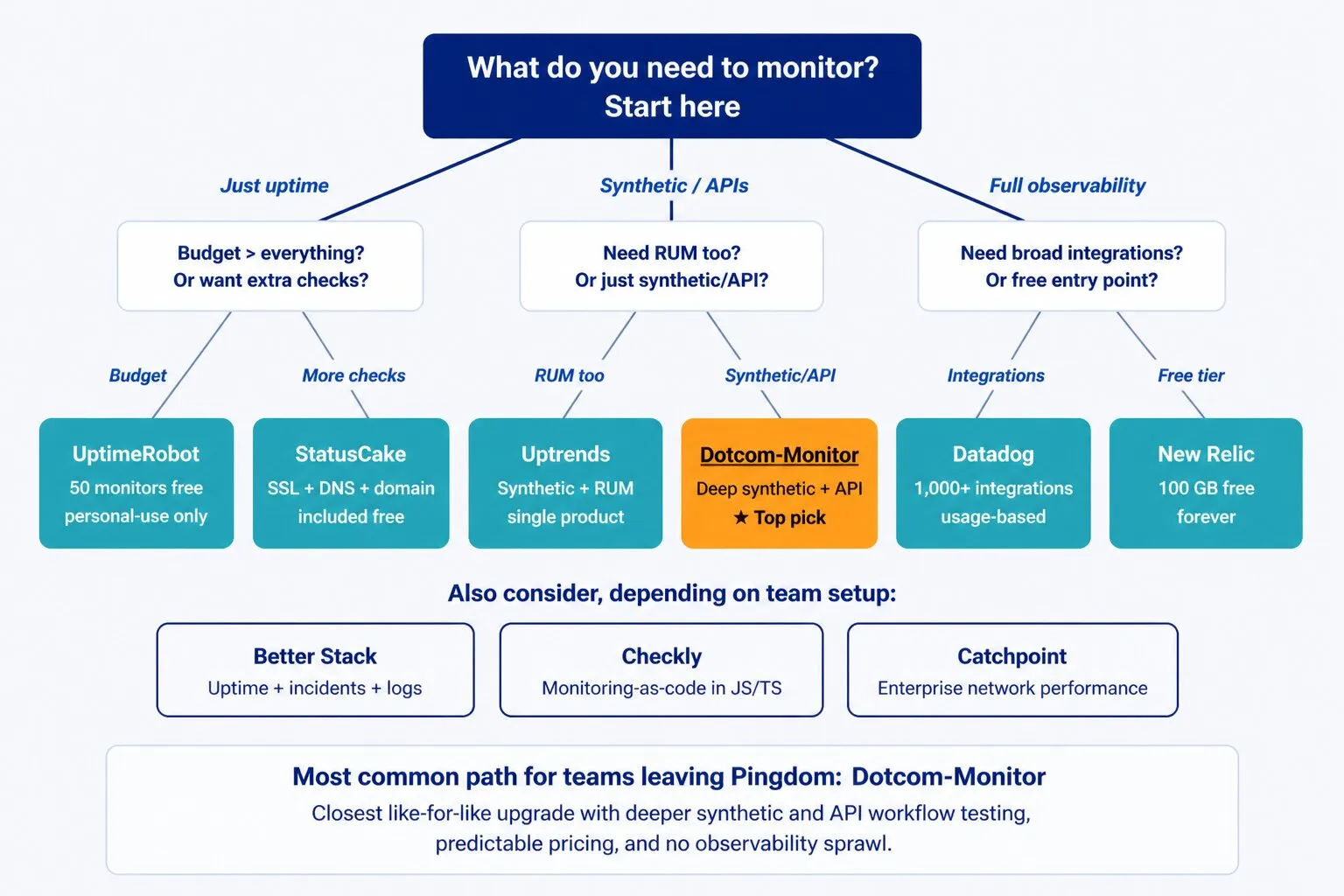
Questions clés à se poser avant de décider
- Avez-vous besoin de surveiller uniquement la disponibilité, ou aussi le comportement et la performance ?
- Votre équipe a-t-elle les ressources pour configurer et maintenir une plateforme complexe ?
- Surveillez-vous principalement depuis l’extérieur (synthétique) ou aussi depuis l’intérieur de l’application (APM) ?
- Avez-vous besoin de RUM pour comprendre ce que les vrais utilisateurs expérimentent ?
- Quelle prévisibilité souhaitez-vous dans le coût de votre surveillance ?
La surveillance consiste en fin de compte à réduire le temps entre une panne et la connaissance qu’en a votre équipe. Le meilleur outil est celui que votre équipe utilisera effectivement et sur lequel elle agira — pas forcément le plus riche en fonctionnalités mal configuré.
Prêt à dépasser Pingdom ?
Dotcom-Monitor vous offre la surveillance synthétique et API la plus profonde dans une plateforme dédiée — avec une tarification prévisible et sans prolifération d’outils d’observabilité. Essayez-le gratuitement pendant 30 jours, sans carte bancaire.
