Bewertet von den Performance-Ingenieuren von Dotcom-Monitor · Alle Wettbewerbsdaten wurden am Veröffentlichungstag mit den Preisangaben der Anbieter abgeglichen.

Auf einen Blick — die kurze Antwort
Wenn Sie Tiefe in synthetischer und API-Überwachung benötigen: Dotcom-Monitor ist das nächstliegende Upgrade ähnlich wie Pingdom, mit mehrstufigen API-Workflows, geskripteten Nutzerpfaden in echten Browsern und vorhersehbarer Abonnementpreisgestaltung.
Wenn Sie eine kostenlose Option für persönliche Projekte suchen: UptimeRobot (50 Monitore, 5-Minuten-Intervalle — nur für persönliche Nutzung ab Oktober 2024) oder StatusCake (10 Monitore mit SSL, DNS und Domain-Prüfungen inklusive).
Wenn Sie Full-Stack-Observability brauchen: Datadog für den umfangreichsten Integrationsumfang oder New Relic für die permanente 100-GB-Free-Tier und leistungsfähige synthetische Tests.
Wenn Sie Monitoring + Incident-Management + Logs in einem Tool wollen: Better Stack — besonders geeignet für Startups und wachsende Teams.
SolarWinds Pingdom — weithin bekannt als Pingdom, nach der 103-Millionen-Dollar-Übernahme durch SolarWinds im Jahr 2014 — ist seit mehr als einem Jahrzehnt eine feste Größe im Website-Monitoring. Es deckt die Grundlagen gut ab: Uptime-Tracking, Geschwindigkeitstests, Transaktionsüberwachung und Real User Monitoring (RUM) in höheren Tarifstufen. Für Teams mit einfachen Anforderungen bleibt es ein leistungsfähiges Tool.
Aber es passt nicht für jeden. Manche Teams wachsen über das Tool hinaus, wenn ihre Infrastruktur skaliert. Andere finden das Preismodell schwer vorhersehbar oder wünschen mehr Flexibilität bei der Konfiguration der Monitoring-Checks. Viele bevorzugen Plattformen, die Alerting, Incident-Workflows, Logs und APM neben dem Monitoring bündeln – obwohl „Full-Stack-Observability“ mehr als ein Bündel ist. Es beruht auf konsistenter Instrumentierung über Metriken, Logs und Traces mit Kontext-Propagation, die es Ingenieuren ermöglicht, unbekannte Fehlerzustände zu debuggen, nicht nur bekannte zu erkennen.
Dieser Leitfaden behandelt die besten Pingdom-Alternativen 2026 mit umfassender Darstellung aller Funktionen eines Tools – nicht nur eine Dimension davon. Ob Sie einfache Uptime-Checks, fortgeschrittenes synthetisches Monitoring, Full-Stack-Observability oder etwas dazwischen benötigen, hier gibt es ein passendes Tool.
Wie wir diese Pingdom-Alternativen bewertet haben
Jedes Tool in dieser Liste wurde anhand derselben neun Kriterien bewertet. Zahlen wurden direkt mit den Preisangaben, Dokumentationen und Produkteinführungen der Anbieter bis Mai 2026 verifiziert.
Uptime-Überwachung
Unterstützte Check-Typen, Intervalle, globale Monitoring-Standorte.
Synthetisches Monitoring
Transaktionstests, Skriptfähigkeiten, Simulation im echten Browser.
Real User Monitoring
Einblick in reale Benutzersitzungen und Frontend-Leistung.
API-Monitoring
Endpunkttests, Antwortvalidierung, mehrstufige Workflows.
Alerting
Unterstützte Kanäle, Einsatzplanung, Eskalationsrichtlinien.
Integrationen
Abdeckung von DevOps, Incident Management und Kommunikationstools.
Berichterstattung
Trends, SLA-Tracking, langfristige Speicherung.
Preisgestaltung
Tarifstruktur, Kostentreiber, Skalierbarkeit der Kosten.
Benutzerfreundlichkeit
Einrichtungsaufwand, UI-Qualität, Lernkurve.
Pingdom-Alternativen auf einen Blick
| Tool | Uptime | Synthetisch | RUM | API-Tiefe | Logs | Preisgestaltung | Am besten für |
|---|---|---|---|---|---|---|---|
| Dotcom-MonitorTop-Auswahl | Ja | Ja (tief) | Nein | Ja (tief) | Nein | Abonnement | Synthetisch & API-Tiefe |
| UptimeRobot | Ja | Nein | Nein | Grundlegend | Nein | Kostenlos + gestaffelt | Budget-Uptime |
| Datadog | Ja | Ja | Ja | Ja | Ja | Nutzungsbasiert | Full-Stack-Observability |
| New Relic | Ja | Ja | Ja | Ja | Ja | Nutzung + Free Tier | APM + Telemetrie |
| StatusCake | Ja | Begrenzt | Nein | Grundlegend | Nein | Kostenlos + gestaffelt | SSL/DNS + Uptime |
| Uptrends | Ja | Ja | Ja | Ja | Nein | Gestaffelt | Synthetisch + RUM-Balance |
| Better Stack | Ja | Grundlegend | Ja | Grundlegend | Ja | Abonnement + kostenlos | Uptime + Incidents + Logs |
Verifiziert im Mai 2026 an Hand der Preis- und Produktseiten der Anbieter. „Tief“ steht für mehrstufige, geskriptete oder auf Assertionen basierende Workflows; „Grundlegend“ für Status-Code- oder Einzelanfrage-Checks.
1 Dotcom-Monitor
★ Redaktionsempfehlung für synthetische & API-Überwachung
Dotcom-Monitor ist eine dedizierte Monitoring-Plattform, die sich auf synthetische Tests und Leistungsvalidierung spezialisiert hat. Während viele Tools mit Infrastruktur-Observability starten und Monitoring als Funktion hinzufügen, wurde Dotcom-Monitor von Grund auf für externe Überwachung gebaut – es führt kontrollierte, wiederholbare synthetische Checks außerhalb Ihrer Infrastruktur durch, um Verfügbarkeit und Leistung spezifischer Nutzerpfade in Webanwendungen und API-Workflows zu validieren.
Uptime- & Verfügbarkeitsüberwachung
Dotcom-Monitor unterstützt HTTP/HTTPS, DNS, FTP, SFTP/FTPS, SMTP, POP3/IMAP, TCP/UDP, SIP, Media Stream, DNSBL, Trace Route und PING-Checks. Tests laufen von einem globalen Netzwerk aus Monitoring-Standorten, was Teams Sichtbarkeit der Verfügbarkeit über Regionen hinweg gibt. Sie können Alarm-Schwellenwerte konfigurieren, Wartungsfenster setzen und Benachrichtigungen erhalten, wenn Dienste offline gehen oder unter festgelegte Benchmarks fallen.
Synthetisches Monitoring
Hier ist Dotcom-Monitor am stärksten. Synthetisches Monitoring geht weit über einfache Uptime-Checks hinaus: Teams können mehrstufige Nutzerpfade skripten, die reale Interaktionen mit Webanwendungen simulieren – Formularabsendungen, Login-Flows, Checkout-Prozesse, Navigationswege – mit automatisierten Chromium-basierten Browsersessions, die JavaScript ausführen, Seiten rendern, Screenshots machen und Schrittzeiten realistischer messen als reine HTTP-Checks.
Dieses Detailniveau erkennt Fehler, die einfache HTTP-Checks verpassen – clientseitige Rendering-Probleme, gebrochene Interaktionen oder Workflows, die nur in bestimmten Regionen fehlschlagen – durch Kombination expliziter Schritte und Assertionen (Klicks, DOM-Überprüfungen, JS-Fehlererkennung, erwartete Navigation oder XHR-Ergebnisse) in jedem Test. Eine Seite, die lädt, aber fehlerhaft rendert, oder ein Workflow, der ausschließlich in Produktion fehlschlägt, wird erkannt, wo ein einfacher HTTP-Check ein sauberes 200 anzeigen würde.
API-Überwachung
Dotcom-Monitor unterstützt mehrstufige API-Workflows, einschließlich dynamischer Authentifizierungsbehandlung (Session-Tokens, OAuth-Flows), Request-Chaining, Antwortkörpervalidierung, Schemaüberprüfungen und Variablenübergabe zwischen Anfragen. Dadurch kann es nicht nur testen, ob ein Endpunkt antwortet, sondern auch, ob er korrekte Daten liefert und sich als Teil des übergeordneten Workflows korrekt verhält. Für Teams mit produktiver API ist diese Tiefe der entscheidende Faktor gegenüber leichteren Tools.
Real User Monitoring (RUM)
Dotcom-Monitor bietet derzeit kein RUM an. Wenn Einblicke in reale Benutzersitzungen und Frontend-Leistung in Produktion erforderlich sind, empfehlen wir die Ergänzung durch ein dediziertes RUM-Tool. Für die meisten Teams ist die Kombination aus tiefer synthetischer Überwachung plus separatem, fokussiertem RUM-Tool ein zuverlässigeres Signal als eine einzelne Plattform, die beides nur mäßig abdeckt.
Alerting, Berichte & Integrationen
Alarme werden per E-Mail, SMS, Telefonanrufen, PagerDuty, Slack, OpsGenie, xMatters und Webhooks verschickt. Eskalationslogiken sorgen dafür, dass je nach Schwere und Reaktionszeit die richtigen Personen benachrichtigt werden. SLA-Berichte und Uptime-Dashboards bieten historische Übersicht, und Berichte können gemäß SLA-Zielen mit Stakeholdern geteilt werden.
Preisgestaltung
Dotcom-Monitor nutzt ein Abo-Modell mit Preisen, die an die gewählten Produkte (Web-Performance, API-Monitoring, Lasttests) sowie an Frequenz und Anzahl der Checks gebunden sind. Die Preisgestaltung ist deutlich planbarer als bei nutzungsbasierten Observability-Plattformen, erfordert aber Planung, wenn Häufigkeit und Monitoranzahl steigen. Es gibt keinen kostenlosen Plan, aber eine 30-Tage-Testversion.
Benutzerfreundlichkeit
Die Einrichtung ist bei einfachen Checks unkompliziert. Geskriptete synthetische Tests und mehrstufige API-Workflows haben eine moderate Lernkurve – Teams ohne Erfahrung im synthetischen Skripten benötigen meist ein bis zwei Tage, um komplexe Abläufe komfortabel zu erstellen.
Wo Dotcom-Monitor Nachteile hat
- Kein Real User Monitoring
- Weniger Integrationen als Full-Observability-Plattformen
- Keine Log-Verwaltung oder Infrastrukturüberwachung
- Nicht geeignet für Teams, die eine einzige Plattform für Infrastruktur, APM und Monitoring wünschen
Zusammenfassung: Dotcom-Monitor ist eine starke Wahl für Teams, die tiefes synthetisches und API-Monitoring in einem dedizierten Tool benötigen. Besonders geeignet für QA-Teams, performanceorientierte Ingenieure und Organisationen mit komplexen Nutzerpfaden oder API-Abhängigkeiten. Für Teams, die auch Infrastrukturüberwachung, Log-Management oder APM brauchen, funktioniert es am besten in Kombination mit anderen Tools.
2 UptimeRobot
UptimeRobot hat sich einen Namen gemacht, indem es eine Sache einfach und gut macht: Es sagt Ihnen, wenn Ihre Website oder Ihr Dienst ausfällt. Es ist eines der meistgenutzten Uptime-Tools weltweit, weil es den Einstieg einfach macht – der kostenlose Plan ist wirklich nützlich, nicht nur eine Lockvogelversion.
Uptime- & Verfügbarkeitsüberwachung
UptimeRobot unterstützt HTTP(S), Keyword, Ping, Port und Heartbeat-Monitore. Der Keyword-Monitor ist besonders nützlich, um Seiten zu erkennen, die laden, aber einen Fehler anzeigen, oder verschwundene Inhalte. Der kostenlose Plan umfasst 50 Monitore mit 5-Minuten-Intervallen; bezahlte Pläne reduzieren Intervalle bis auf 30 Sekunden und steigern die Monitoranzahl.
Wichtiger Hinweis: Seit Oktober 2024 ist der kostenlose Plan von UptimeRobot nur für die persönliche, nicht-kommerzielle Nutzung laut Nutzungsbedingungen erlaubt. Für geschäftliche oder umsatzgenerierende Überwachung ist ein kostenpflichtiger Plan erforderlich.
Synthetisches, RUM- und API-Monitoring
UptimeRobot bietet keine synthetische Transaktionsüberwachung oder RUM. API-Monitoring beschränkt sich auf das Senden von HTTP-Anfragen und Prüfen des Erfolgscodes – ausreichend für die Frage “Ist der Endpunkt erreichbar?”, aber nicht für Validierung korrekter API-Daten oder mehrstufiger Workflows.
Alerting und Preisgestaltung
Der kostenlose Plan bietet nur E-Mail-Benachrichtigungen. Bezahlte Pläne fügen SMS, Sprachanrufe, Push-Benachrichtigungen, Slack, PagerDuty, Zapier und Webhooks hinzu. Die Bezahlstufen (Solo, Team, Enterprise) skalieren mit Monitoranzahl und Prüfintervall bei transparenter Preisgestaltung.
Wo UptimeRobot Nachteile hat
- Kein synthetisches Monitoring oder Nutzerpfadsimulation
- Kein RUM
- API-Monitoring nur Verfügbarkeit, keine Korrektheit, Auth-Flows oder Workflow-Semantik
- Kein Log-Management oder Infrastruktur-Sichtbarkeit
- Kostenloser Plan nur für persönliche Nutzung erlaubt, nicht für kommerzielle Überwachung
- SMS-Alarmierung nur in Bezahlplänen
Zusammenfassung: Hervorragend im Rahmen seines Anwendungsbereichs. Wenn Sie wissen müssen, wann eine persönliche Website oder ein Nebenprojekt am günstigsten ausfällt, schwer zu überbieten. Die Einschränkungen spielen für Teams mit produktiven Anwendungen mit echten Nutzererwartungen, API-Abhängigkeiten oder Zuverlässigkeitsverpflichtungen eine große Rolle – und die kommerzielle Einschränkung für den Gratisplan drängt ernsthafte Teams zunehmend auf einen bezahlten Plan oder ein anderes Tool.
3 Datadog
Datadog ist eine der umfassendsten Monitoring- und Observability-Plattformen. Es ist nicht nur ein Monitoring-Tool – es ist eine vollständige Observability-Plattform, die Infrastrukturmetriken, Anwendungsleistung, Logs, synthetische Tests und echte Nutzerdaten in einer einzigen Ansicht vereint. Für Teams, die komplexe, cloud-native Systeme verwalten, ist diese Breite der Kernnutzen.
Synthetisches und Uptime-Monitoring
Datadog unterstützt Browser-Tests (skriptaufgezeichnet oder manuell codiert), API-Tests mit Status-/Header-/Body-/Latenz-/SSL-Prüfung und mehrstufige API-Tests, bei denen Variablen aus einer Antwort extrahiert und an die nächste übergeben werden können. Synthetische Tests können in CI/CD-Pipelines ausgelöst werden, um Regressionen zu entdecken, bevor sie in Produktion gelangen.
Real User Monitoring (RUM)
Datadog RUM erfasst echte Nutzersitzungen inklusive Seitenladezeiten, Core Web Vitals, JavaScript-Fehlern, Nutzeraktionen und Sitzungswiederholungen. Es kann Frontend-Ereignisse mit Backend-Traces korrelieren, wenn sowohl das RUM-SDK als auch Backend-Tracing instrumentiert sind und die Trace-Kontext-Propagation über Gateways und Services korrekt konfiguriert ist. Die Korrelation funktioniert gut in Umgebungen mit durchgehender Instrumentierung, kann aber Lücken haben, wenn Anfragen über Load Balancer, CDNs oder Drittanbieter gehen, die Trace-Kontext nicht erhalten – eine gängige Realität in der Produktion.
Infrastruktur, APM, Logs und Integrationen
Datadogs Infrastrukturüberwachung deckt Cloud-Anbieter, Container, Kubernetes, Serverless und Datenbanken ab. APM bietet verteiltes Tracing, Servicemaps und Code-Profilerstellung. Log-Management umfasst Ingestion, Parsing, Suche, Alerting und Archivierung. Logs können mit Traces und Metriken für umfassende Incident-Untersuchungen korreliert werden. Datadog erreichte 2025 über 1.000 Integrationen, eine der breitesten Bibliotheken im Monitoring-Bereich.
Preisgestaltung
Datadog verwendet ein nutzungsbasiertes Preismodell. Kosten steigen simultan über verschiedene Dimensionen – Infrastrukturhosts, Log-Volumen, APM-Spans, RUM-Sessions, synthetische Testruns und mehr. Das macht es zu einer der mächtigsten Plattformen, aber auch zu einer der schwierigsten, um Kosten zu budgetieren. Teams, die ihre Nutzung nicht sorgfältig überwachen, können erhebliche Kostensteigerungen erleben, wenn Systeme wachsen. Gratisstufen und Promotionen ändern sich häufig – prüfen Sie die aktuelle Verfügbarkeit eines kostenlosen Plans oder Entwickler-Tiers auf der Datadog-Preisseite.
Wo Datadog Nachteile hat
- Preise können schnell und unvorhersehbar steigen
- Erheblicher Einrichtungs- und Konfigurationsaufwand für vollen Nutzen
- Kann für Teams mit nur Uptime oder synthetischem Monitoring zu umfangreich wirken
- Funktionsvielfalt kann neue Teams überfordern
Zusammenfassung: Datadog ist die richtige Wahl für Teams, die eine einzige Plattform für Infrastruktur, Anwendungen, Logs, Nutzer und externe Tests wollen. Wenn Ihr Team eine komplexe cloud-native Umgebung verwaltet und tiefe Korrelation über alle Schichten Ihres Stacks benötigt, liefert Datadog – zu Kosten und Komplexität, die kleinere Teams schwer rechtfertigen.
4 New Relic
New Relic ist eine gut etablierte Observability-Plattform mit starkem Fokus auf Anwendungsleistung. Wie Datadog deckt sie APM, Infrastruktur, Logs, Browser-Monitoring und Synthetics ab – war historisch aber stärker in der Code-Level-Anwendungsübersicht und bietet mit der kostenlosen Stufe einen zugänglicheren Einstieg.
Synthetisches Monitoring
New Relic Synthetics unterstützt einfache Browser-Monitore, geskriptete Browser-Monitore (mehrstufige Interaktionen mit benutzerdefinierten Assertionen), API-Testmonitore (Status, Header, Body-Inhalt), Step-Monitore (no-code Browser-Transaktions-Builder), Zertifikatsprüfungen und Broken-Link-Scans. Der No-Code-Step-Builder macht synthetisches Testen ohne Skripte einfach zugänglich.
Real User Monitoring und APM
New Relic Browser Monitoring erfasst echte Nutzerleistungsdaten wie Seitenladezeiten, Core Web Vitals, JavaScript-Fehler, Ajax-Performance und Sitzungs-Traces – und verbindet diese mit Backend-APM-Traces, sodass Teams Frontend-Probleme bis auf einen spezifischen Backend-Dienst oder Query zurückverfolgen können. New Relic APM ist eine der stärksten Funktionen mit Instrumentierung des Anwendungscodes in Java, .NET, Python, Node.js, Ruby, PHP und Go mit verteiltem Tracing, Transaktions-Traces, Datenbank-Analyse und Code-Profilerstellung.
Preisgestaltung
New Relic verwendet ein nutzungsbasiertes Modell, das sich am Dateningest-Volumen und der Anzahl der Plattformbenutzer orientiert. Der Free Tier bietet 100 GB Dateningest pro Monat und einen vollwertigen Benutzer ohne zeitliche Begrenzung – einer der großzügigsten Einstiege bei Full-Stack-Observability-Plattformen und ein entscheidender Vorteil für kleinere Teams.
Wo New Relic Nachteile hat
- Volle Wertschöpfung benötigt Anwendungstracing und erhebliche Einrichtung
- Preise können bei hohem Datenvolumen schnell steigen
- Kann für Teams mit einfachen Monitoring-Anforderungen zu umfangreich sein
Zusammenfassung: Eine starke Wahl für Engineering-Teams, die umfassende Observability mit einem kostenlosen Tarif suchen, der wirklich erlaubt, Fähigkeiten zu erkunden, bevor man sich verpflichtet. Besonders gut geeignet für Teams mit Microservices oder verteilten Architekturen, die Probleme über Service-Grenzen hinweg nachverfolgen müssen.
5 StatusCake
StatusCake wird oft zugunsten bekannterer Namen übersehen, bietet aber eine solide Bandbreite an Monitoring-Typen, die über einfache Uptime hinausgehen – dadurch vielseitiger als Tools wie UptimeRobot, ohne die Komplexität vollständiger Observability-Plattformen.
Was StatusCake bietet
StatusCake unterstützt HTTP, TCP, DNS und PING-Checks mit anpassbaren Intervallen und mehrstandortigem Alerting. Bemerkenswerte Zusätze, die andere Tools berechnen oder ganz weglassen: integrierte SSL-Zertifikatüberwachung mit Ablaufwarnungen, Domain-Ablaufüberwachung vor Registrierungslaufzeitende, DNS-Änderungsüberwachung und Page-Speed-Tracking. StatusCake bietet auch leichtgewichtige Malware-/Blacklist-Scans – nützlich als Ergänzung, nicht Ersatz für dedizierte Sicherheitstools.
Kostenloser Plan
StatusCakes kostenloser Plan umfasst 10 Uptime-Monitore mit 5-Minuten-Intervallen, 1 Page-Speed-Monitor, 1 Domain-Monitor und 1 SSL-Monitor – ein runderes Angebot als viele Wettbewerber. Kostenlose Konten werden bei 90 Tagen Inaktivität deaktiviert. Kostenpflichtige Pläne (Indie, Business, Agency) umfassen mehr Monitore, schnellere Intervalle und fortgeschrittenere Funktionen.
Synthetisches, RUM- und API-Monitoring
Synthetische Transaktionsüberwachung ist begrenzt im Vergleich zu dedizierten Plattformen – einfache Transaktionsprüfungen sind möglich, aber mit weniger Skripttiefe, echter Browsersimulation und mehrstufiger Workflowvalidierung als bei Dotcom-Monitor oder Uptrends. Es gibt kein RUM. API-Monitoring besteht nur aus Status-Code-Prüfungen – geeignet für Verfügbarkeitschecks, aber nicht für Korrektheitsvalidierung oder Workflows.
Wo StatusCake Nachteile hat
- Kein RUM
- Beschränktes synthetisches Monitoring – nicht geeignet für komplexe Nutzerpfade
- Kein Log-Management oder Infrastrukturüberwachung
- API-Monitoring nur Verfügbarkeit, nicht für Produktion-API-Workflowvalidierung
Zusammenfassung: Ein ausgewogenes Tool für Teams, die mehr als reine Uptime aber keine komplexe Plattform wollen. SSL, DNS, Domain-Ablauf und Malware-Erkennung neben Uptime sind besonders gut für Website-Besitzer und kleine Entwicklerteams. Wenn Ihr Hauptaugenmerk auf Website-Gesundheit statt komplexen Anwendungs-Workflows liegt, verdient es eine ernsthafte Prüfung.
6 Uptrends
Uptrends ist eine dedizierte Monitoring-Plattform, die auf synthetische Tests, echten Browser-Monitoring und Real User Monitoring aufbaut. Es liegt auf einer nützlichen Mittelschiene: leistungsfähiger als einfache Uptime-Tools, aber fokussierter und zugänglicher als vollständige Observability-Plattformen wie Datadog oder New Relic.
Eigentumskontext
Uptrends wurde im November 2020 von der ITRS Group übernommen und arbeitet weiterhin als eigenständiges Produkt mit eigener Oberfläche und Preisgestaltung. ITRS ist eine durch PE finanzierte Monitoring-Softwaregruppe (unterstützt von TA Associates), die sich auf Observability im Kapitalmarkt und IT-Performance fokussiert. Relevant für Käufer, die die langfristige Anbieterstrategie berücksichtigen, dennoch ist das tägliche Produkt stabil geblieben.
Synthetisches Monitoring
Uptrends synthetisches Monitoring ist umfassend: Vollseiten-Checks mit Wasserfalldiagrammen, mehrstufige Transaktionsüberwachung für Login-Flows / Such- und Filterfunktionen / Formularabsendungen / Checkout, echtes Browser testen in Chromium und Firefox, ein No-Code-Rekorder und eine JavaScript-Schnittstelle für komplexe Interaktionen.
RUM und API-Monitoring
Uptrends RUM erfasst reale Nutzerleistungsdaten – Seitenladezeiten, Core Web Vitals, geografische und Geräteauflösungen, Nutzerpfadverfolgung – die im gleichen Tool mit synthetischen Daten kombiniert sind. API-Monitoring umfasst Endpunkttests mit Antwortvalidierung, mehrstufigen Anfragefolgen und Variablenmanagement.
Preisgestaltung
Uptrends arbeitet mit einem gestaffelten Abonnementmodell, bei dem die Preise mit Nummer der Monitore, Prüfintervall und aktivierten Features skalieren. Kosten können stark steigen, wenn das Monitoring ausgeweitet wird, insbesondere bei Zusatz von RUM-Daten und hochfrequenten synthetischen Tests von vielen globalen Standorten. Kostenlose Testversion verfügbar, kein dauerhaft kostenloser Plan.
Wo Uptrends Nachteile hat
- Kein Log-Management oder Infrastrukturüberwachung
- Preise steigen schnell mit Umfang
- Nicht geeignet für Teams, die APM oder Infrastruktur-Observability in ein und derselben Plattform benötigen
Zusammenfassung: Eines der stärkeren dedizierten synthetischen Monitoring-Tools in dieser Liste. Die Kombination eines großen globalen Monitoring-Netzwerks, echte Browser-Transaktionstests und RUM in einem Produkt macht es vielseitig für Performance-orientierte Teams, die keine vollständige Observability benötigen.
7 Better Stack
Better Stack – die einheitliche Plattform aus dem Zusammenschluss von Better Uptime (Uptime-Monitoring) und Logtail (Log-Management) – verfolgt einen anderen Ansatz als die meisten Tools in dieser Liste. Anstatt Tiefe in einer einzigen Monitoring-Art zu fokussieren, kombiniert es Uptime-Überwachung, On-Call-Incident-Management, Real User Monitoring und Log-Management in einer klaren, einheitlichen Plattform, die Tool-Flut minimiert.
Uptime und synthetisches Monitoring
Better Stack unterstützt HTTP, TCP, Ping, DNS, SMTP und POP3-Checks. Die Einrichtung ist eine der schnellsten der Kategorie – einfache Monitore können in unter einer Minute laufen. Die synthetischen Fähigkeiten haben sich verbessert: Better Stack bietet jetzt Playwright-basierte Browser-Checks, die mehrstufige Nutzerpfade mit voller JavaScript-Ausführung durchführen können. Das synthetische Produkt ist noch nicht so ausgereift wie dedizierte Plattformen wie Dotcom-Monitor oder Uptrends, aber für viele gängige Workflows ausreichend.
Real User Monitoring
Better Stack bietet ein vollständiges RUM-Produkt mit Session-Replay (inkl. Rage-Click-Erkennung und 2× Wiedergabe), Core Web Vitals je URL mit Benachrichtigungen sowie Front-End-zu-Back-End-Korrelation, die RUM-Sessions mit Backend-Logs und Traces verknüpft. Diese vergleichsweise neue Funktion erweitert die Abdeckung deutlich im Vergleich zu früheren Bewertungen.
Incident-Management – das Besondere
Hier differenziert sich Better Stack deutlich: On-Call-Pläne und Rotationen mit automatischer Eskalation, Alarm-Routing nach auslösendem Monitor, automatisch generierte Incident-Timelines und integrierte öffentliche Statusseiten, die sich automatisch mit Incident-Status aktualisieren. Für Teams, die Monitoring in einem Tool und Incident-Response in einem anderen (wie PagerDuty) verwalten, ist Better Stack eine attraktive Konsolidierung.
Log-Management
Better Stack enthält Log-Management (vormals als Logtail verkauft) in der gleichen Plattform. Teams können Logs von Anwendungen, Infrastruktur und Services erfassen, durchsuchen, überwachen und alarmieren – das ist ein bedeutender Unterschied zu den meisten dedizierten Uptime-Tools.
Preisgestaltung
Better Stack nutzt ein Abonnementmodell, das Preise anhand von Monitoren und Teammitgliedern steuert. Ein wirklich nützlicher kostenloser Plan umfasst Basis-Monitoring (10 Monitore, 5.000 Session-Replays/Monat, 100.000 Exceptions/Monat, eine Statusseite und Incident-Management).
Wo Better Stack Nachteile hat
- Synthetisches Monitoring ist noch weniger ausgereift als bei dedizierten synthetischen Plattformen
- API-Monitoring ist flacher als bei dedizierten Tools (Statuscode + Basisinhaltsvalidierung; keine mehrstufigen API-Workflows)
- APM ist begrenzt im Vergleich zu Datadog / New Relic
- Neuere Plattform als etablierte Anbieter – einige Enterprise-Funktionen reifen noch
Zusammenfassung: Better Stack verdient seinen Platz nicht durch Tiefe in einer einzelnen Monitoring-Kategorie, sondern durch intelligente Integration von Uptime, On-Call, RUM und Log-Management in einer durchdachten Plattform. Für Startups und wachsende Teams, die Tool-Flut reduzieren und Incident-Response von Anfang an richtig machen wollen, ist es eine der praktischsten Optionen. Teams mit komplexem synthetischem Monitoring oder APM-Bedarf müssen jedoch woanders suchen.
Weitere bemerkenswerte Pingdom-Alternativen
Je nach Umgebung und Anforderungen sind diese Tools ebenfalls einen Blick wert:
- Catchpoint — Enterprise-Monitoring mit Fokus auf Internet-Performance, Sichtbarkeit der letzten Meile und CDN/DNS-Überwachung. Gute Wahl, wenn Netzwerkperformance kritisch ist.
- Grafana Cloud — Stark für Teams, die bereits Grafana und Prometheus nutzen. Vereint Metriken, Logs und Traces mit eingebautem synthetischem Monitoring via Grafana k6.
- Checkly — Entwicklerorientiertes, code-first synthetisches Monitoring in JavaScript/TypeScript mit nativer Playwright-Unterstützung. Hervorragend für Engineering-Teams, die Monitoring mit Anwendungscode versionieren.
- Prometheus + Blackbox Exporter — Open-Source-Kombination für Teams, die volle Kontrolle über ihre Monitoring-Infrastruktur wünschen. Mächtig und flexibel, aber erfordert erheblichen Setup- und Wartungsaufwand.
- Site24x7 — All-in-One-Monitoring für Websites, Server, Anwendungen und Netzwerke. Umfassendes Toolset zu einem zugänglichen Preis, besonders für Managed Service Provider.
Wie man die richtige Pingdom-Alternative auswählt
Das richtige Monitoring-Tool hängt von drei Dingen ab: Was Sie überwachen müssen, wie viel Komplexität Ihr Team bewältigen kann und was Ihr Budget erlaubt. Der untenstehende Entscheidungsbaum ordnet die häufigsten Fälle einem empfohlenen Startpunkt zu.
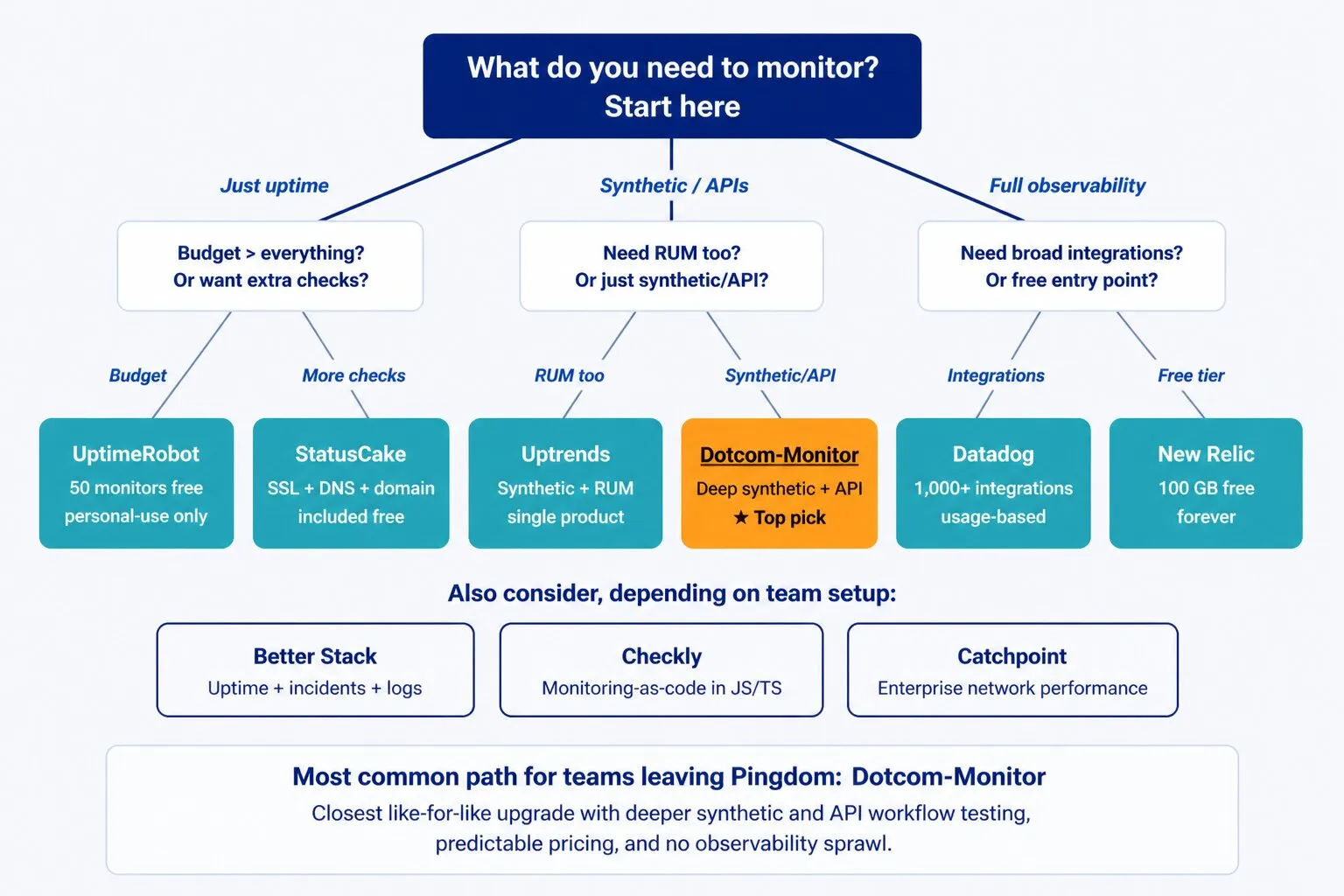
Wichtige Fragen vor der Entscheidung
- Müssen Sie nur Verfügbarkeit überwachen oder auch Verhalten und Leistung?
- Hat Ihr Team die Ressourcen, eine komplexe Plattform zu konfigurieren und zu betreiben?
- Überwachen Sie primär von außen (synthetisch) oder auch von innerhalb der Anwendung (APM)?
- Benötigen Sie RUM, um zu verstehen, was echte Nutzer erleben?
- Wie vorhersehbar muss Ihre Monitoring-Kostenstruktur sein?
Monitoring bedeutet letztlich, die Zeitspanne zu verkürzen, bis ein Fehler bemerkt wird. Das beste Tool ist das, das Ihr Team tatsächlich nutzt und auf das es reagiert – nicht das feature-reichste, das falsch konfiguriert bliebt.
Bereit, über Pingdom hinauszugehen?
Dotcom-Monitor bietet Ihnen die tiefste synthetische und API-Überwachung in einer dedizierten Plattform — mit vorhersehbaren Preisen und ohne Observability-Flut. Testen Sie es 30 Tage lang kostenlos, keine Kreditkarte erforderlich.
