
External Synthetic Monitoring for DORA Operational Resilience
How external synthetic monitoring meets DORA’s detection and availability obligations, mapped requirement by requirement.

How Dotcom-Monitor Resolves DNS in Every Check
Dotcom-Monitor’s DNS resolve modes control caching, failure detection speed, and real-user timing accuracy—learn which mode fits your monitoring checks.
IPv6 Monitoring with Dotcom-Monitor: Find IPv6 Blind Spots
IPv6 protocol checks run once a minute from native nodes, isolating faults your IPv4 monitoring will never catch. Here’s how Dotcom-Monitor does it.
Why You Need Native IPv6 Network Monitoring
Ensure 100% uptime across all routing paths. Learn how native IPv6 network monitoring catches hidden DNS, firewall, and gateway configuration errors.
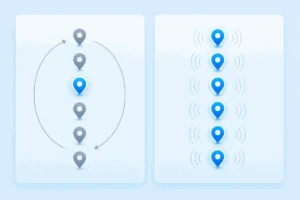
Concurrent vs Round-Robin Monitoring Explained
Round-robin vs concurrent synthetic monitoring: how each schedules checks across locations, the cost trade-off, and when to use which.

Website Monitoring Alerts – Maximize Uptime and Reduce Noise
Updated June 2026 · 11-minute read Ask any on-call engineer about their monitoring and they will tell you the same thing: the alerts are not the problem. The noise is.

What is Application Performance Monitoring (APM)?
What application performance monitoring (APM) is, how instrumentation, collection, and correlation work, which metrics matter, and the best practices that make APM useful in production

Top 8 Application Performance Monitoring Tools (2026 Edition)
Compare the top 8 application performance monitoring tools of 2026 on features, alerting, OpenTelemetry, and real pricing, plus the hidden costs to avoid.

Website Availability Monitoring: A Practical Guide to Staying Online
Learn how to monitor website uptime, compare synthetic vs. real user monitoring, evaluate tools, and audit your setup with a practical checklist.

Best Pingdom Alternatives in 2026: 7 Top Tools Compared
Looking for Pingdom alternatives? Compare top tools like Dotcom-Monitor, UptimeRobot, and Datadog with accurate features, pricing, and API monitoring strengths.

Web Application Performance: Metrics, Process & Best Practices
Web application performance is not just a technical concern – it is a business imperative. Google’s research shows that as page load time increases from one second to five seconds,

Website Monitoring Best Practices Engineers Actually Use
What it is, why it matters, and best practices to choose the best website monitoring service for uptime, performance, and user experience.