Escolher a infraestrutura certa e as ferramentas de monitoramento sintético não é mais apenas uma questão de marcar uma caixa de tempo de atividade; trata-se de fechar a lacuna de visibilidade entre a saúde do seu backend e a experiência real do usuário final. Em um ambiente DevOps moderno, uma falha no seu roteamento DNS ou uma API de terceiros latente pode ser tão catastrófica quanto uma queda de servidor, no entanto, esses problemas “de fora para dentro” muitas vezes passam despercebidos pelos monitores internos tradicionais.
Este guia avalia as 12 melhores ferramentas de monitoramento de infraestrutura e sintético, especificamente selecionadas para equipes técnicas que precisam reduzir o MTTR (Tempo Médio de Resolução) e eliminar “pontos cegos” em sua pilha de produção.
Monitoramento Sintético vs. Monitoramento de Infraestrutura
Enquanto o monitoramento sintético valida fluxos funcionais de locais globais, o monitoramento de infraestrutura fornece a telemetria granular necessária para diagnosticar as falhas de hardware e rede que causam a falha desses fluxos.
| Tipo de Monitoramento | O que Faz | Casos de Uso e Vantagens Principais |
| Monitoramento Sintético | Imita ações do usuário, fluxos de trabalho scriptados e chamadas de API agendadas | Captura fluxos quebrados e lentidões. Benchmarking entre locais. Saúde de tempo de atividade/transação |
| Monitoramento de Infraestrutura | Rastreia: servidores, dispositivos de rede, serviços (DNS, TCP/UDP, ping, etc.), e métricas de recursos | Detecta: falhas no backend e nível de protocolo, interrupções de serviço e saturação de recursos |
Comparando as 12 Melhores Ferramentas de Monitoramento de Infraestrutura e Sintético
| Ferramenta | Sintético | Infraestrutura | Destaques | Compensações |
| Dynatrace | ✅ | ✅ | Observabilidade impulsionada por IA, conectando fluxos de usuários e métricas de backend | Complexo. O custo pode escalar rapidamente |
| Dotcom-Monitor | ✅ | ✅ | Monitoramento sintético e de serviço em uma única plataforma | Evita fragmentação de ferramentas. Oferece escalonamento modular |
| New Relic | ✅ | ✅ | Fluxos de trabalho sintéticos scriptados. Forte observabilidade | Caro. Tem uma curva de aprendizado |
| Datadog | ✅ | ✅ | Visão completa da UI, infraestrutura, logs e métricas | Caro em grande escala |
| Site24x7 | ✅ | ✅ | Tudo-em-um: web, servidor, rede, nuvem, cobertura sintética e infra | A profundidade pode ser menor em alguns módulos |
| Pingdom | ✅ | – | Confiável em monitoramento de tempo de atividade, transação e carregamento de página | Falta verificações profundas de infraestrutura e nível de protocolo |
| Checkly | ✅ | – | Scriptagem JS/Playwright para fluxos de trabalho sintéticos | Requer expertise em scriptagem. Sem verificações de infra integradas |
| Zabbix | – | ✅ | Plataforma de alta versatilidade para ambientes híbridos (SNMP, IPMI, JMX e Agentes). | Gerenciamento pesado de UI; escalonamento requer ajuste significativo do banco de dados. |
| Nagios | – | ✅ | Estabilidade lendária para ambientes estáticos/legados com uma enorme biblioteca de plugins. | Alta configuração “toil”; UI datada e falta de gráficos nativos de séries temporais. |
| Prometheus | – | ✅ | O padrão CNCF para métricas nativas de K8s e rotulagem multidimensional. | Requer armazenamento externo (Thanos/Cortex) e ferramentas extras para logs/sintéticos. |
| SolarWinds Network Performance Monitor (NPM) | – | ✅ | Excelente análise de caminho de rede, salto, nível de dispositivo, SNMP, análise de fluxo | Menos foco em monitoramento sintético |
| LogicMonitor, ManageEngine OpManager | – ou Híbrido | ✅ | Monitoramento de infraestrutura, rede, sistemas com alguns recursos sintéticos ou de integração | Monitoramento sintético fraco, complementos são necessários. |
1. Dynatrace

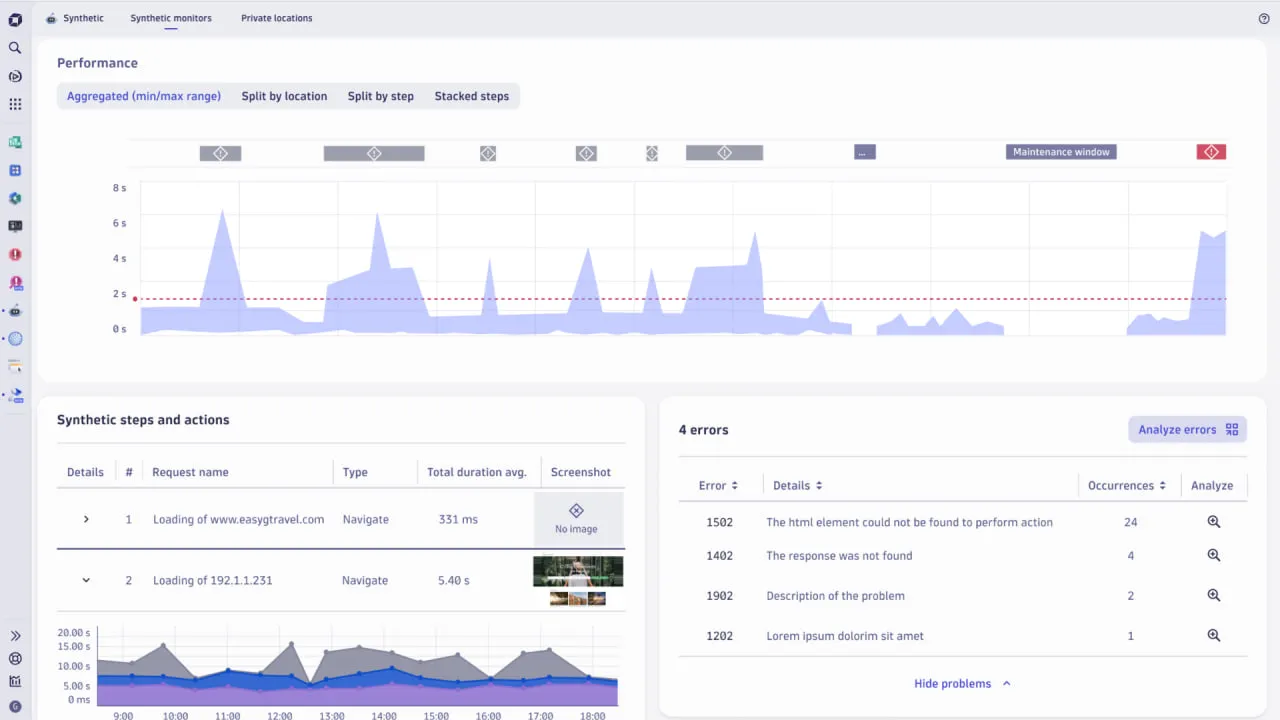
Dynatrace é uma solução que combina recursos como monitoramento sintético, monitoramento de usuários reais, métricas de infraestrutura e aplicação, e análise automática de causa raiz. Sua arquitetura OneAgent coleta análises por meio de análises contextuais, IA e automação.
Benefícios Principais
- Detecção e análise de anomalias impulsionadas por IA;
- Correlação de verificações sintéticas com rastros de infraestrutura;
- Cobertura de pilha completa, incluindo monitoramento sintético global;
- Bom para ambientes híbridos, em nuvem e complexos de empresas.
Melhor Para: Complexidade Empresarial Massiva & Causa Raiz Automatizada.
Cenário da Vida Real: Seu banco está migrando um monólito legado para uma arquitetura de microserviços em nuvem híbrida. Um único pedido de “transferir dinheiro” agora toca 50+ serviços em toda a AWS e um data center local.
A Solução: Você implementa o OneAgent. Quando a latência da transação aumenta, a IA do Dynatrace (Davis) mapeia automaticamente a topologia e informa: “O atraso não está no código; é um bloqueio específico do banco de dados no cluster SQL local causando uma cascata.”
2. Dotcom‑Monitor

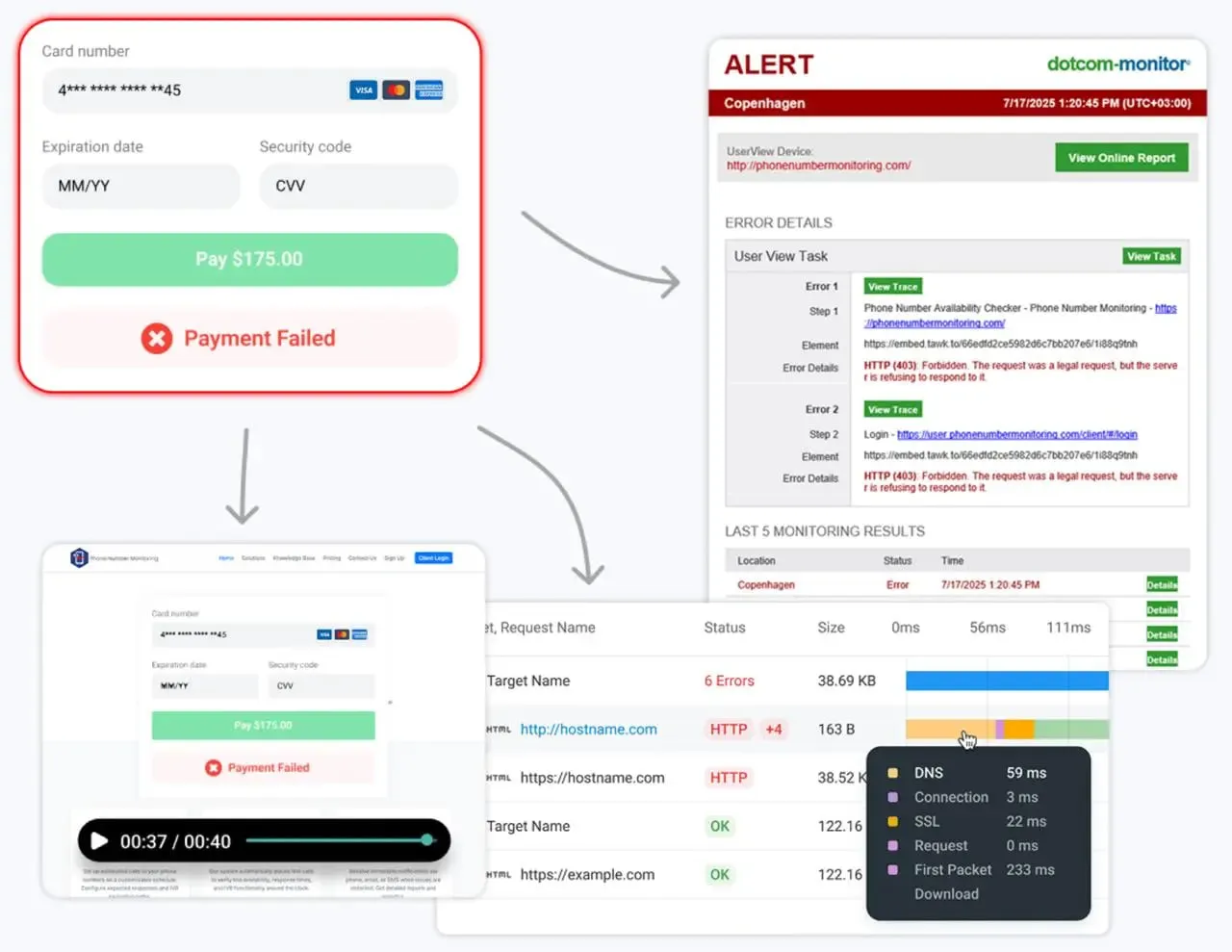
Dotcom-Monitor é uma plataforma unificada que oferece tanto monitoramento sintético (desempenho da web, fluxos scriptados, verificações de API) quanto monitoramento de infraestrutura (DNS, FTP, ICMP, UDP, verificações de porta TCP, VoIP). Também integra monitoramento de servidores e dispositivos por meio de seu módulo ServerView para visibilidade completa com apenas uma interface.
Benefícios Principais
- Encontra anomalias subjacentes estimulando interações do usuário;
- Verificações de múltiplas localizações para melhorar a experiência do usuário e a infraestrutura;
- Tudo sob um painel unificado sem alternar ferramentas;
- Aproximação modular—habilite módulos de infraestrutura conforme necessário;
- Reduz a sobrecarga operacional, como gerenciar várias ferramentas.
Melhor Para: Experiência do Usuário Global & Confiabilidade Multi-Protocolo.
Cenário da Vida Real: Você administra uma plataforma de e-commerce de alto tráfego com uma base de clientes global. Você teve vários incidentes em que o site estava “ativo” de acordo com as métricas internas, mas os clientes na Europa não conseguiam concluir as compras devido à latência regional do DNS ou a um gateway de pagamento de terceiros expirando.
A Solução: Você usa o Dotcom-Monitor para executar fluxos sintéticos em navegador real de 30+ locais globais a cada 5 minutos. Quando um ISP regional em Londres tem um problema de roteamento, você recebe um alerta com um gráfico de cascata mostrando o erro exato 404 ou 500 antes que seu helpdesk seja inundado com tickets.
3. New Relic

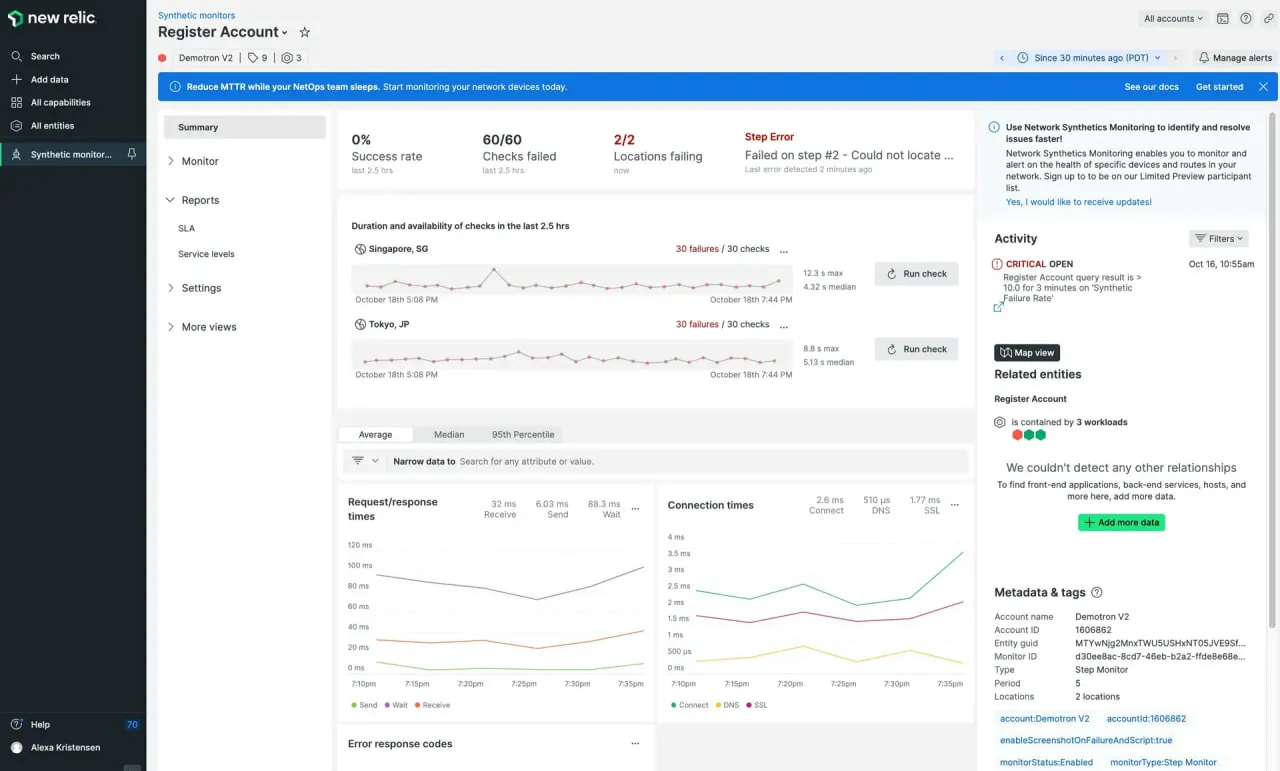
New Relic permite que você escreva scripts de fluxo de trabalho de navegador e API, e depois vincule esses resultados à sua pilha de observabilidade (APM, infraestrutura, logs). É projetado para equipes que desejam tudo em um único ecossistema.
Benefícios Principais
- Flexibilidade de script rica para fluxos de usuários complexos;
- Forte integração com métricas e logs de backend;
- Painéis unificados e sistema de alerta;
- Bom suporte e ecossistema.
Melhor Para: Depuração Profunda de Aplicações & Otimização em Nível de Código.
Cenário da Vida Real: Após uma grande implantação na tarde de sexta-feira, o tempo de resposta da sua API dobra. Os logs mostram que tudo está “OK”, mas os usuários estão reclamando.
A Solução: Você usa New Relic APM para aprofundar-se em um “Rastro de Transação.” Ele revela que uma nova expressão regular na linha 402 do seu controlador Python está causando picos de CPU—permitindo que você reverta e conserte a linha específica de código em minutos.
4. Datadog

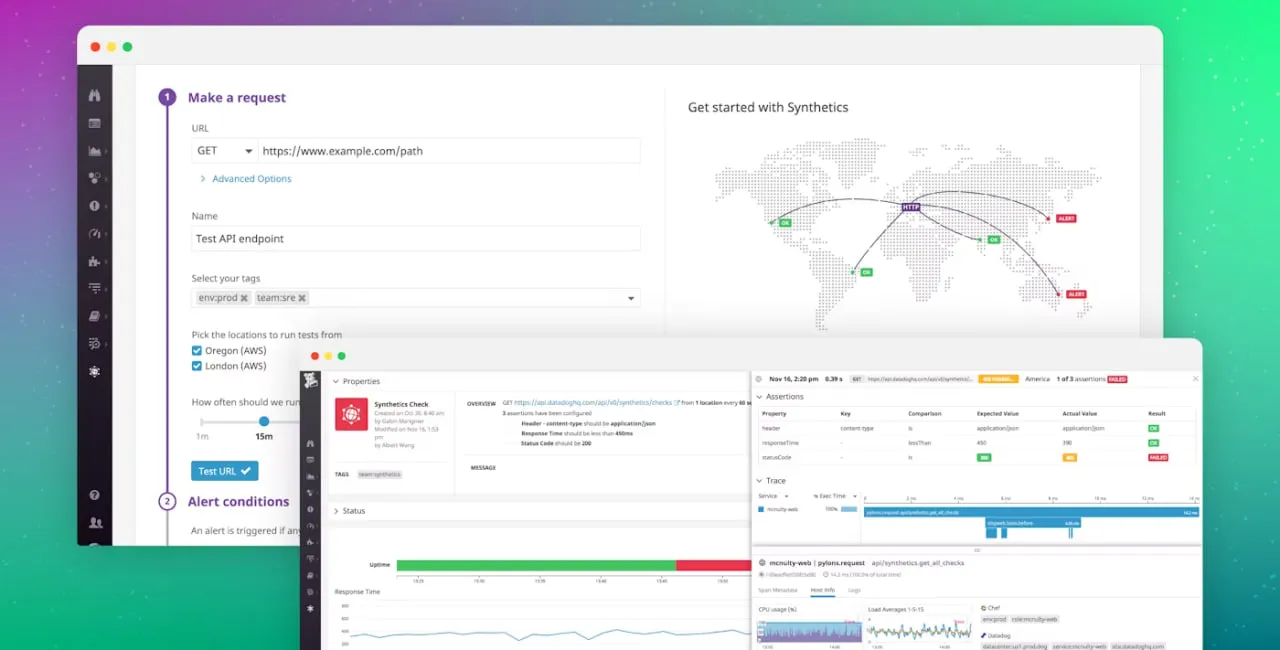
Datadog tem uma abordagem integrativa que combina monitoramento sintético com coleta de métricas, logs, rastreamento e saúde da infraestrutura. Portanto, isso fornece a você uma solução tudo-em-um.
Benefícios Principais
- Correlação unificada entre sintético, infraestrutura e logs;
- Painel e visualizações personalizadas;
- Amplas integrações entre serviços em nuvem, contêineres, bancos de dados, etc.;
- Pode ser escalado para grandes sistemas.
Melhor Para: Equipes Nativas de Nuvem de Alta Velocidade.
Cenário da Vida Real: Você gerencia uma frota de 500+ microserviços Kubernetes que escalam para cima e para baixo 20 vezes por dia. Você precisa saber se uma implantação específica de “Canary” está causando erros em um serviço downstream.
A Solução: Você usa Mapas de Serviço e Correlação de Logs. Quando um pod falha, você clica no erro em seu painel e instantaneamente vê os logs e rastros específicos para aquele contêiner exato, filtrados pela tag “versão”.
5. Site24x7

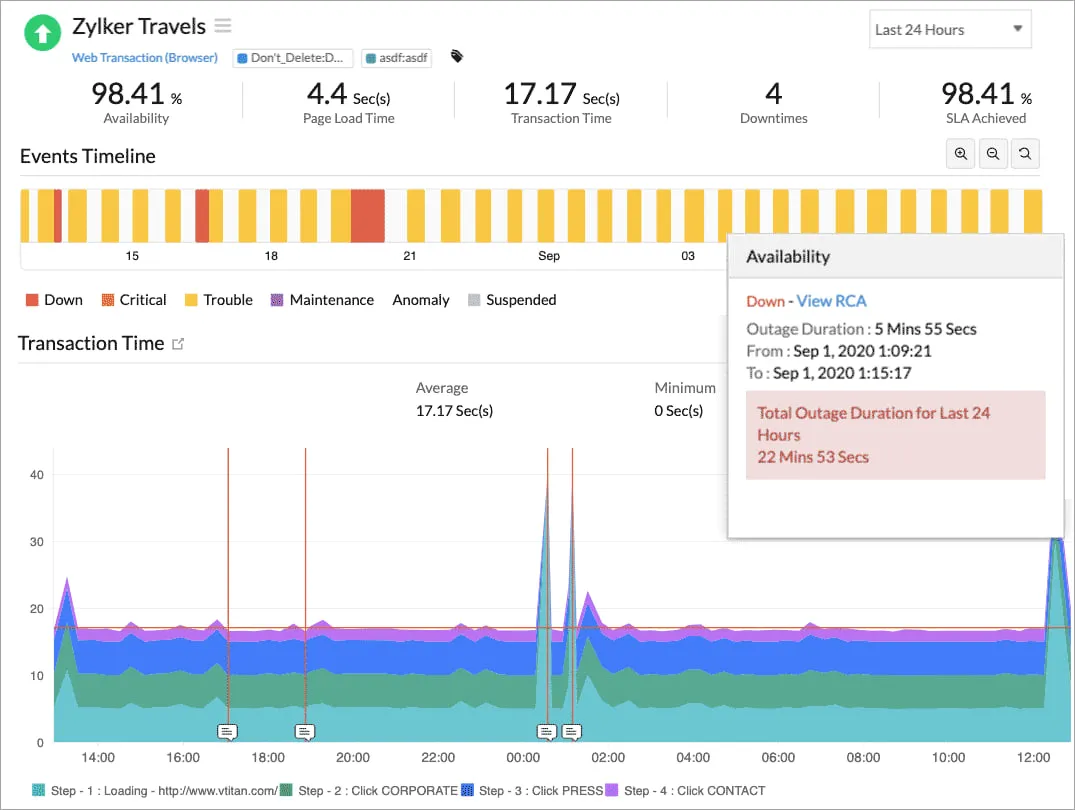
Site24x7 cobre fluxos sintéticos de usuários, monitoramento de servidores e redes, infraestrutura em nuvem, aplicações e mais. Para equipes pequenas e médias, esta é uma boa ferramenta que oferece cobertura total.
Benefícios Principais
- Monitoramento para web, servidor, rede, aplicações;
- Suporte a protocolos de infraestrutura;
- Aprendizado fácil e passo a passo;
- Preços flexíveis e bom custo-benefício.
Melhor Para: Equipes Conscientes de Orçamento que Precisam do Básico “Tudo-em-Um”.
Cenário da Vida Real: Você é o único engenheiro DevOps em uma startup de 50 pessoas. Você precisa monitorar seu site, o roteador VPN do seu escritório e sua conta da AWS com um orçamento limitado.
A Solução: Você usa o Site24x7 para configurar pings básicos de tempo de atividade e um Agente de Servidor em suas máquinas Linux. É uma ferramenta “configure e esqueça” que lhe dá 80% da visibilidade de ferramentas caras a 20% do custo.
6. Pingdom

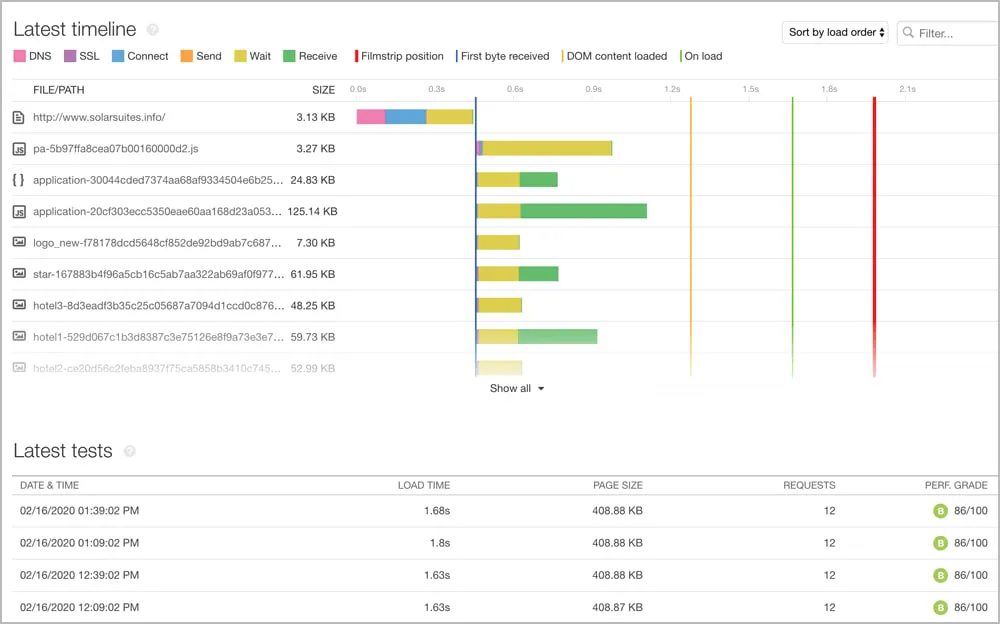
Pingdom é uma ferramenta de monitoramento sintético baseada na web. Seus recursos incluem medições de carregamento de página e simulações de jornada do usuário de múltiplas localizações. É uma ótima escolha para quem tem foco em monitoramento web.
Benefícios Principais
- Configuração e implantação rápidas;
- Verificações de múltiplas localizações para detecção de problemas regionais;
- Suporte a monitoramento de múltiplas etapas;
- Alertas em tempo real e relatórios de desempenho.
Melhor Para: Marketing & Stakeholders de Negócios.
Cenário da Vida Real: Seu CMO quer uma simples “Página de Status Pública” para mostrar aos clientes que o site é confiável.
A Solução: Você configura uma simples Verificação Pingdom. É de baixo custo e alta confiabilidade. Quando o site cai, ele aciona uma atualização da “Página de Status” que mantém seus usuários informados sem expor seus complexos painéis internos de SRE.
7. Checkly

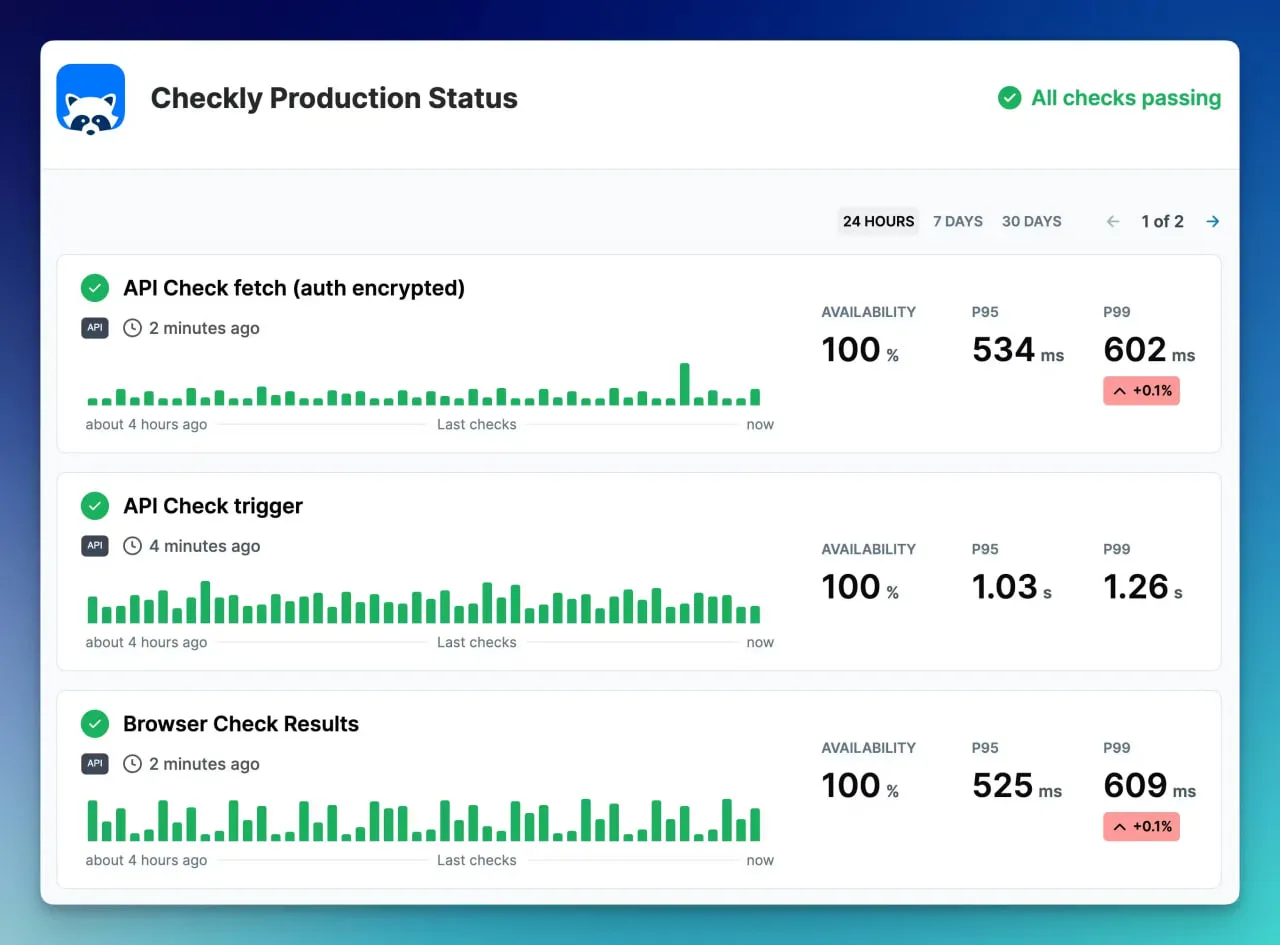
Checkly é para desenvolvedores, pois enfatiza a scriptagem em JavaScript e Playwright para definir verificações. Isso o torna ideal para pessoas que sabem programar.
Benefícios Principais
- Verificações sintéticas altamente personalizáveis via código;
- Integra-se facilmente em pipelines de CI/CD;
- Bom para monitoramento de API e baseado em navegador;
- Interface leve, moderna e orientação para ferramentas de desenvolvedor.
Melhor Para: Frontend Moderno & Engenharia de QA (Prioridade para Playwright).
Cenário da Vida Real: Sua equipe está se movendo em direção a um modelo “Você constrói, você executa”. Seus desenvolvedores já usam Playwright para testes locais e querem usar os mesmos scripts para monitorar a produção.
A Solução: Você integra Checkly em suas Ações do GitHub. Sempre que um PR é mesclado, o Checkly atualiza automaticamente seus monitores de “Heartbeat” de produção usando o mesmo código que seus desenvolvedores escreveram para testes.
8. Prometheus
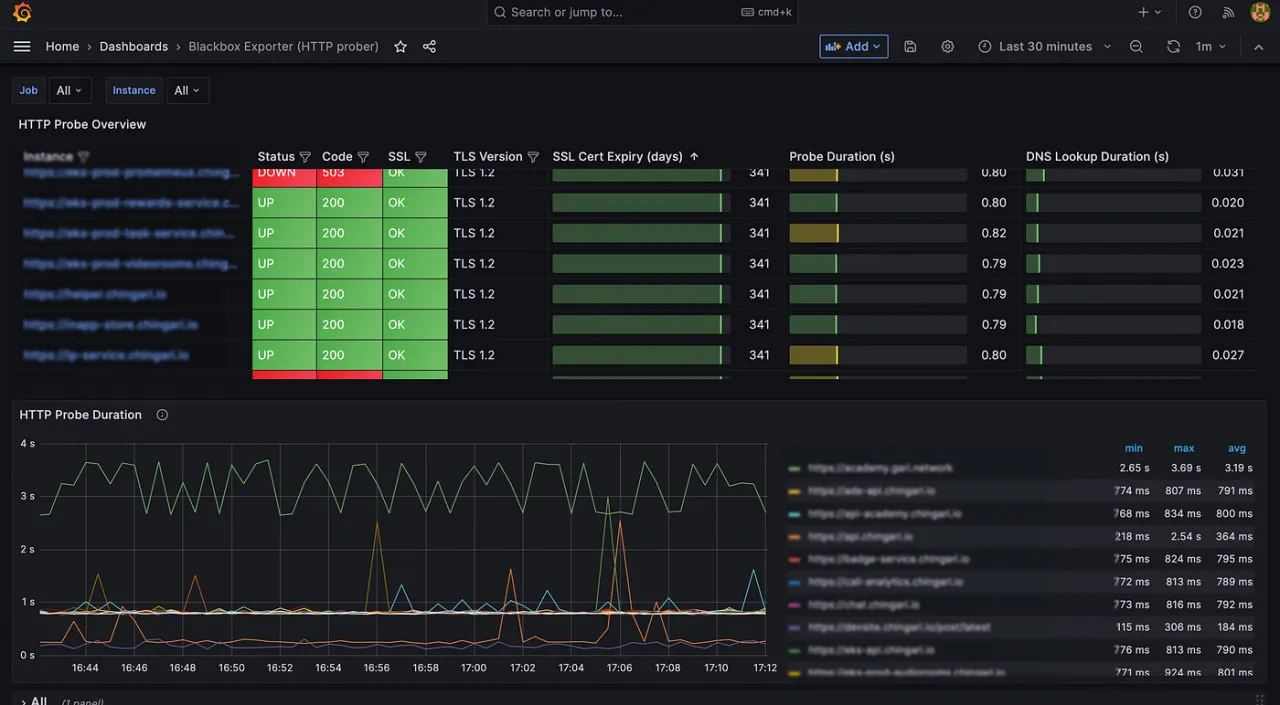
Prometheus é o “padrão de ouro” graduado pelo CNCF para monitoramento nativo em nuvem. Ele pioneirou o modelo de métricas baseado em pull e o uso de rótulos multidimensionais, que são essenciais para rastrear pods efêmeros do Kubernetes.
Benefícios Principais
- Descoberta automática perfeita para serviços e contêineres Kubernetes.
- Uma poderosa linguagem de consulta projetada para operações pesadas em matemática (por exemplo, calcular a latência do 99º percentil).
- Cada servidor é autossuficiente, sem dependência de banco de dados externo, tornando-o resiliente durante interrupções.
Melhor Para: Auto-escalonamento de Kubernetes & Microserviços.
Cenário da Vida Real: Você está executando uma API de varejo no EKS (Amazon Kubernetes Service). Durante uma “Venda Relâmpago”, seu HPA (Horizontal Pod Autoscaler) ativa 200 novos pods.
A Solução: O Prometheus descobre automaticamente esses pods via API do Kubernetes, coleta suas métricas instantaneamente e alerta você se a latência p99 em toda a frota exceder 200ms—sem que você precise adicionar manualmente um único endereço IP a um arquivo de configuração.
9. Zabbix
Zabbix é o “canivete suíço” do monitoramento de infraestrutura. É uma plataforma centralizada, pronta para empresas, que se destaca em monitorar “estados mistos”—onde você tem uma mistura de servidores Linux modernos, máquinas Windows legadas e equipamentos de rede físicos.
Benefícios Principais
- O Zabbix inclui painéis, alertas e relatórios em uma única interface web nativa.
- Suporte de primeira classe para hardware físico (roteadores, switches e até termômetros de sala de servidores).
- Se você pode escrever um script para isso (Python, Bash, Go), o Zabbix pode monitorá-lo.
Melhor Para: Infraestrutura Híbrida & Redes Diversificadas.
Cenário da Vida Real: Você gerencia uma rede universitária. Você precisa monitorar 500 Máquinas Virtuais, 200 Switches Cisco e a temperatura de três diferentes data centers.
A Solução: Você usa o Zabbix com Agentes Ativos para as VMs e SNMP para os switches. Você constrói um “Mapa de Rede” na UI do Zabbix que fica vermelho se um switch central falhar, permitindo que você veja exatamente quais servidores estão isolados pela falha de hardware.
10. Nagios (Core & XI)
O “Avô” do monitoramento. O Nagios é construído em uma simples arquitetura de “Plugin”—ele executa um script, verifica o código de saída (0, 1, 2) e alerta conforme necessário. É lendário por sua estabilidade, mas criticado por sua interface da era de 1990 e fricção de configuração.
Benefícios Principais
- Se existe em um data center, alguém já escreveu um plugin Nagios para isso nos últimos 25 anos.
- O motor central é incrivelmente leve e pode rodar em hardware mínimo.
- Siga um fluxo simples “Verificação -> Resultado -> Alerta” que é fácil de solucionar problemas.
Melhor Para: Ambientes Estáveis, Legados ou “Estáticos”.
Cenário da Vida Real: Você gerencia uma série de servidores “Air-Gapped” críticos em uma instalação segura. Esses servidores nunca mudam, não escalam automaticamente e devem permanecer ativos 24/7/365.
A Solução: Você usa o Nagios Core. É sólido como uma rocha e não falhará durante uma atualização. Você usa um simples plugin check_disk e check_ssh. Ele envia um único e confiável e-mail no momento em que uma falha de hardware RAID ocorre, e faz isso sem dependências de “SaaS” ou nuvem.
11. SolarWinds NPM

O SolarWinds Network Performance Monitor (NPM) se especializa em monitoramento de dispositivos de rede e nível de caminho. Ele rastreia acessibilidade, latência de salto, saúde do dispositivo, tráfego de interface, métricas SNMP e topologia de rede.
Benefícios Principais
- Visibilidade excepcional de caminho de rede, salto e interface;
- Suporte a SNMP e NetFlow, métricas em nível de dispositivo;
- Insights sobre gargalos de rede e problemas de topologia;
- Fortes diagnósticos para interrupções relacionadas à rede.
Melhor Para: Administradores de Rede & Infraestrutura Física.
Cenário da Vida Real: Os usuários estão reclamando que “a internet está lenta.” Você suspeita de um problema de hardware na sala de servidores ou um salto de fibra ruim entre seus escritórios.
A Solução: Você usa NetPath. Ele mostra um mapa de caminho da rede, salto a salto. Você vê um pico de latência de 200ms em um roteador Cisco específico na sua filial em Dallas, confirmando que é um gargalo de hardware, não um bug de software.
12. LogicMonitor / ManageEngine OpManager
 LogicMonitor e ManageEngine são ferramentas para monitoramento de infraestrutura em nível empresarial, apresentando módulos sintéticos e integrações de experiência do usuário. Elas são boas para monitoramento de dispositivos, servidores, VMs e aplicativos.
LogicMonitor e ManageEngine são ferramentas para monitoramento de infraestrutura em nível empresarial, apresentando módulos sintéticos e integrações de experiência do usuário. Elas são boas para monitoramento de dispositivos, servidores, VMs e aplicativos.
Benefícios Principais
- Infraestrutura ampla de servidores, rede e aplicações;
- Conveniência de integração e automação pré-construídas;
- Painel perfeito para operações empresariais;
- Algumas opções para integração de módulos sintéticos.
Melhor Para: TI Híbrida & Provedores de Serviços Gerenciados (MSPs).
Cenário da Vida Real: Você gerencia TI para uma empresa com 10 escritórios globais, cada um com seus próprios servidores locais, armazenamento NetApp e clusters VMware, todos conectados ao Azure.
A Solução: Você usa a arquitetura Collector do LogicMonitor. Ele descobre automaticamente todos os 2.000+ dispositivos em sua rede e constrói um “Painel Empresarial” que mostra a saúde do seu armazenamento físico, máquinas virtuais e instâncias em nuvem em uma única visão.
Como Escolher Sua Pilha de Monitoramento?
Selecionar uma suíte de monitoramento é menos sobre “encontrar a melhor ferramenta” e mais sobre minimizar a lacuna entre um incidente e sua resolução. Para uma equipe moderna de DevOps ou SRE, o processo de tomada de decisão deve priorizar o seguinte:
1. Avaliar Cobertura vs. Fragmentação de Ferramentas
Pergunte-se se sua equipe pode gerenciar realisticamente uma pilha “best-of-breed” (por exemplo, Prometheus para métricas, Checkly para scripts e SolarWinds para rede). Embora especializado, isso muitas vezes leva a “silos de dados.” Plataformas unificadas como Dotcom-Monitor ou Datadog reduzem a troca de contexto durante interrupções de alta pressão, correlacionando falhas sintéticas diretamente com a saúde da infraestrutura.
2. Priorizar Automação e Suporte a IaC
Em um ambiente nativo em nuvem, a configuração manual é uma responsabilidade. Certifique-se de que a ferramenta escolhida suporta Terraform, Pulumi ou um CLI abrangente. Se você não puder provisionar uma verificação sintética como parte de uma implantação de serviço, a ferramenta eventualmente se tornará um gargalo para sua velocidade de engenharia.
3. Avaliar a Relação Sinal-Ruído
A maior ameaça a um SRE é fadiga de alertas. Procure ferramentas que ofereçam lógica de alerta sofisticada—como “X falhas em Y locais”—para filtrar picos de rede transitórios. Evite plataformas que forcem um limite “tamanho único”, que muitas vezes leva a “gritar lobo” e notificações ignoradas.
4. Analisar o Custo Total de Propriedade (TCO)
Além do preço de etiqueta, considere a sobrecarga operacional. Soluções de código aberto como Zabbix ou Prometheus são “gratuitas” em licenciamento, mas caras em horas de engenharia necessárias para manutenção, correção e escalonamento. Plataformas SaaS trocam custos de licenciamento mais altos por “toil” reduzido, permitindo que sua equipe se concentre na confiabilidade do site em vez da manutenção do servidor de monitoramento.
Muitas equipes adotam uma pilha em camadas ou vão com tudo em plataformas unificadas como Dotcom‑Monitor. O que é melhor para você depende do seu orçamento, sistema, tamanho da equipe e expertise da equipe.
Conclusão
Em 2026, a “melhor” ferramenta é aquela que elimina silos entre suas equipes de DevOps, SRE e QA. Se você está gerenciando um ambiente complexo e nativo em nuvem, Datadog ou Dynatrace oferecem correlação incomparável, embora a um preço premium. Para equipes que buscam uma abordagem robusta e unificada que combine verificações profundas de protocolo com transações sintéticas globais sem o “imposto empresarial”, o Dotcom-Monitor oferece o equilíbrio mais pragmático de visibilidade “de fora para dentro” e “de dentro para fora”.
Em última análise, seu objetivo deve ser tratar o Monitoramento como Código. Priorize ferramentas com forte suporte a API e provedores Terraform para que seu monitoramento evolua tão rápido quanto sua infraestrutura.
Frequently Asked Questions
- Use alertas por meio de um sistema central
- Use níveis de severidade e limites com sabedoria
- Suprimir durante janelas de manutenção
- Agrupar alertas relacionados e filtrar duplicatas
- Ajustar com base em falsos positivos históricos
