API 监控 是持续的、自动化的实践,用于验证 API 端点的可用性、响应时间和数据正确性——不仅确认端点有响应,还确认其返回正确格式、正确数据且延迟在可接受范围内,从用户和依赖系统的视角出发。

API 是现代软件的连接组织。每次用户登录、提交支付或接收实时通知时,多个 API 调用会在幕后执行——通常跨越微服务、云供应商和第三方厂商。当这些调用失败或变慢时,影响是立即的:结账流程中断、用户锁定以及收入损失。
然而大多数团队只有在客户报告时才发现 API 故障。没有主动监控,故障与调查之间的延迟通常以十几分钟计——足够暴露真实的收入和 SLA 风险,同时无人接收到警报。
本指南解释了什么是 API 监控、它如何工作、需要跟踪哪些指标、它与 API 测试和 APM 的区别,以及如何实施——为 DevOps 工程师、SRE 和 QA 团队提供精确手段,以便做出明智的生产决策。
什么是 API 监控?
API 监控涵盖三个不同层次的验证,按具体性递增排序:
- 可用性监控 — 端点是否可达?是否返回 HTTP 响应且无超时?
- 性能监控 — 响应时间多长?TTFB、DNS 解析或 TLS 握手是否引入延迟?
- 负载验证 — 响应体是否包含预期的数据结构?JSONPath 或 XPath 断言是否通过?
什么是 API 端点?
应用程序编程接口(API)是一组协议和定义,允许软件系统通信。API 端点是 API 接收请求并返回响应的具体 URL——是 API 监控的观察单位。例如:
POST /v2/auth/token— 令牌发行端点GET /v2/orders/{id}— 订单检索端点POST /v2/payments/charge— 支付处理端点
现代应用同时依赖数十甚至数百个此类端点——内部微服务、第三方支付网关、身份提供商、物流 API 和 CRM 系统。API 监控可保持对所有这些端点的可见性。
API 监控类型
并非所有 API 监控都是相同的。理解类别有助于团队构建符合架构和业务需求的覆盖。五种核心类型适用于几乎所有团队;专业类型在特定条件下尤为重要。
核心类型
| 类型 | 验证内容 | 适用场景 |
|---|---|---|
| 可用性监控 | 端点可达性;HTTP 响应码;是否在超时窗口内响应 | 基础可用性 SLA;立即故障检测 |
| 性能监控 | 响应时间、TTFB、DNS 解析、TCP 握手、TLS 时间、吞吐量 | 延迟 SLA、P95/P99 目标、容量规划 |
| 负载 / 验证监控 | 通过 JSONPath/XPath 断言验证响应体;模式正确性;字段值 | 捕获 HTTP 200 ≠ 正确数据的隐性失败 |
| 合成监控 | 从全球位置定期模拟 API 调用,独立于真实流量 | 主动检测;地理覆盖;无流量期间检测 |
| 多步骤事务监控 | 链式 API 调用序列(例如:认证 → 查询 → 提交 → 确认);步骤间数据传递 | 电子商务流程、登录流程、订单工作流 |
专业类型
| 类型 | 验证内容 | 适用场景 |
|---|---|---|
| 安全监控 | 认证失败、异常请求模式、证书过期、速率限制滥用、令牌重放 | 金融科技、医疗健康;处理 PII/PHI 的 API |
| 合规相关检查 | TLS 版本/密码验证、证书到期、安全头存在、身份验证强制测试 | 医疗健康、金融服务、受监管行业 |
| 真实用户监控(RUM) | 真实用户 API 交互;完整会话可视化;真实地理和设备差异 | 理解真实用户影响;验证合成发现 |
| 版本与弃用监控 | API 版本采纳率;版本变更后错误激增;向后兼容性 | 管理多个 API 版本的团队 |
| 第三方 / 集成监控 | 外部 API 依赖(Stripe、Okta、Salesforce、Twilio);隔离外部与内部故障 | 任何依赖第三方 API 实现关键工作流的应用 |
关于合规相关检查说明:它们提供特定技术控制的支持证据。框架合规(HIPAA、PCI DSS、SOC 2)需要广泛的组织治理,单靠监控无法完成。
合成监控与真实用户监控(RUM)
两者都提供API 性能数据,但视角根本不同:
| 合成监控 | 真实用户监控(RUM) | |
|---|---|---|
| 触发方式 | 按计划执行的脚本检查(例如每 1 分钟一次) | 生产环境真实用户请求 |
| 覆盖范围 | 24/7 运行——即使无真实用户时也运行 | 仅在用户活跃请求时生成数据 |
| 检测模式 | 主动——在用户受影响前捕获失败 | 被动——用户已受影响后暴露问题 |
| 范围 | 公共和私有/内部 API(通过私有代理) | 真实用户/客户端访问的 API —— 主要是面向公众的,企业级 RUM 也可捕捉带有埋点的应用中的内部 API 调用 |
| 用例 | 持续的可用性和性能验证 | 理解真实影响范围和用户体验 |
API 监控关键指标
跟踪正确的指标,是区分信息豐富的事件响应和警报疲劳的关键。以下是最关键的指标——并附有准确基准及其意义。
| 指标 | 目标 / 基准 | 捕获内容 |
|---|---|---|
| 可用性(正常运行百分比) | ≥ 99.9%(三个九);收入关键 API 99.99% | 完全宕机、部分故障、超时 |
| 总响应时间 | < 200ms(简单端点);< 1秒(复杂操作) | 服务器变慢、过载、部署回滚 |
| 首字节时间(TTFB) | 理想< 100ms;可接受< 300ms | 响应开始前的服务器处理延迟 |
| P95 / P99 响应时间 | 端点基线 P95 的 2 倍触发警报;根据端点行为调优 | 影响最慢的 1–5% 请求的尾部延迟 |
| 错误率(4xx / 5xx) | 生产环境 API < 0.1% | 认证失败、错误输入处理、服务器错误 |
| DNS 解析时间 | 同区域缓存查询< 50ms;跨区域可超 100ms | DNS 传播问题、解析器失败 |
| TLS 握手时间 | < 100ms | 证书配置错误、TLS 版本协商问题 |
| 负载断言通过率 | 100%(任一失败即告警) | 隐性失败:HTTP 200 返回错误或缺失数据 |
| 吞吐量(请求/秒) | 与历史基线比较 | 异常流量下降或峰值 |
| 证书到期(日数剩余) | 30 天告警;7 天关键 | TLS 证书即将过期 |
响应时间基准
API 监控如何工作?
理解技术机制帮助团队正确配置监控并准确解读结果。
核心监控循环
- 安排计划。 合成检查按照设定间隔(如每 1 分钟)从选定的全球监控点运行。
- 发送请求。 监控代理向目标端点发送 HTTP 请求——包括 HTTP 方法(GET、POST、PUT、PATCH、DELETE)、请求头、认证凭证和请求体。
- 时间测量。 代理记录 DNS 解析时间、TCP 连接时间、TLS 握手时间、首字节时间(TTFB)和总响应时间作为独立组成部分。
- 断言。 根据配置的断言评估响应——HTTP 状态码、响应时间阈值、响应头和通过 JSONPath(REST)或 XPath(SOAP)验证的负载内容。
- 报警或通过。 任何断言失败或请求超时时,系统创建事件并根据配置的通知规则发送警报。
- 记录。 所有结果(通过和失败)均存档,包含时间戳、响应数据和断言结果,供历史趋势分析和 SLA 报告使用。
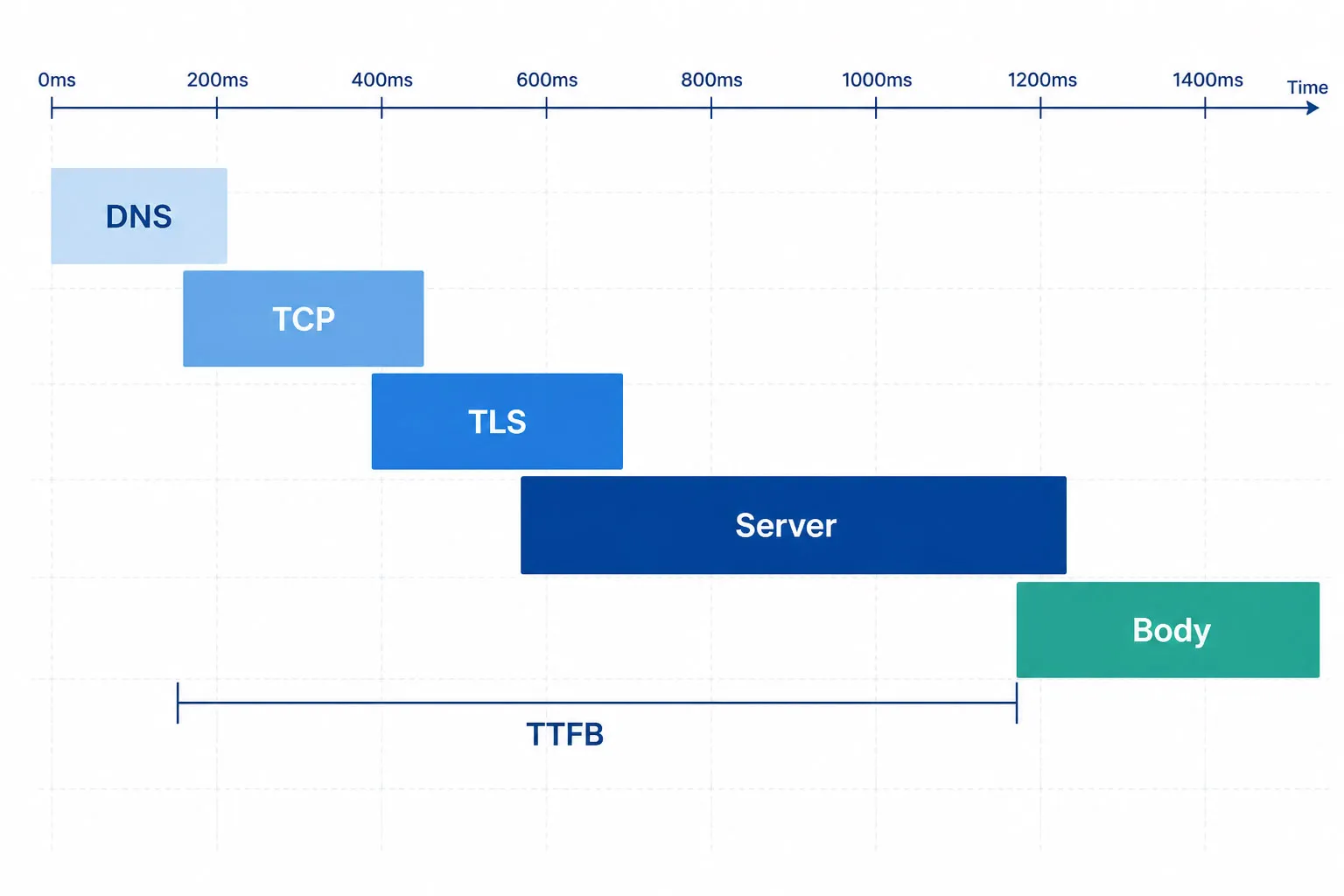 组成 HTTP 请求的各阶段。TTFB 包括 DNS、TCP、TLS 和服务器处理,但不含主体传输。主体传输慢且 TTFB 快多半表示负载较大;TTFB 慢且主体快多半表示服务器处理慢。
组成 HTTP 请求的各阶段。TTFB 包括 DNS、TCP、TLS 和服务器处理,但不含主体传输。主体传输慢且 TTFB 快多半表示负载较大;TTFB 慢且主体快多半表示服务器处理慢。
多步骤 API 事务监控
 实际用户流程很少是单个 API 调用。多步骤监控将调用链串联起来,自动在步骤间传递动态值(令牌、会话 ID、订单 ID)。
实际用户流程很少是单个 API 调用。多步骤监控将调用链串联起来,自动在步骤间传递动态值(令牌、会话 ID、订单 ID)。
单端点监控确认单个端点响应。但真实用户流程是串联的多个步骤,每个步骤依赖上一步输出。
例如电商结账流程:
- 步骤 1 —
POST /auth/token:认证用户;从响应体提取access_token - 步骤 2 —
GET /products/{id}:获取产品详情;在Authorization头中注入令牌 - 步骤 3 —
POST /cart/add:加入商品;从响应中提取cart_id - 步骤 4 —
POST /checkout/initiate:启动结账,使用cart_id;提取checkout_session_id - 步骤 5 —
POST /payments/charge:处理支付;断言响应字段order_status等于'confirmed'
单端点监控可能所有五步均单独通过,但整体事务失败——因为会话数据未正确传递、令牌过期或支付 API 返回 HTTP 200 但负载中含错误字段。多步骤监控将整个链作为一个监控点独立断言每一步,自动在步骤间传递动态值。
Dotcom-Monitor 支持多步骤事务监控,可在单个监控任务中串联顺序 API 调用,自动提取和注入变量,独立断言每步,精准锁定故障步骤。
负载验证:JSONPath 和 XPath 断言
负载验证是区分监控与简单可用性检测的关键。断言表达方式随工具不同,但逻辑统一:
- JSONPath 字段访问(REST): 获取
$.data.status—— 断言返回值等于'active' - JSONPath 数组检查: 获取
$.items—— 断言数组长度大于 0 - XPath 断言(SOAP):
//order/status/text()—— 断言节点值等于'confirmed' - 响应头断言: 断言
Content-Type头值等于'application/json' - 响应时间断言: 断言总响应时间低于 500ms
认证监控
生产环境 API 需要认证。监控工具必须支持与你的真实 API 客户端相同的认证方式。生产级监控平台应支持的认证方案:
| 认证方式 | 说明 | 备注 |
|---|---|---|
| OAuth 2.0 — 客户端凭据 | 机器对机器;客户端直接用凭据交换令牌 | 服务器对服务器 API 监控最常见 |
| OAuth 2.0 — 授权码 | 用户委托授权;通常用于 SPA/移动端结合 PKCE | 监控工具需自动处理令牌刷新 |
| OAuth 2.0 — 资源所有者密码(ROPC) | 直接用户名密码交换——遗留流程 | 仅在授权码不可行时使用 |
| Bearer 令牌(JWT) | 静态或动态刷新令牌,放在Authorization头 |
短期 JWT 需自动令牌刷新 |
| API 密钥 | 静态密钥放在头部、查询参数或 Cookie | 最简单监控;注意密钥轮换事件 |
| 基础认证 | Base64 编码的用户名:密码,放在Authorization头 |
遗留,企业和内部 API 仍常用 |
| AWS Signature v4 | 使用 AWS 凭据的 HMAC 签名请求 | AWS API Gateway 端点必需 |
| mTLS / 客户端证书 | 双向 TLS —— 双方均需证书 | 零信任环境;证书过期监控关键 |
| NTLM / Kerberos | Windows/Active Directory 集成认证 | 企业内部 API;云原生较少见 |
| 自定义头 | 通过自定义请求头实现专有认证方案 | 适用于非标准认证实现 |
令牌过期是监控误报的主要原因。OAuth 2.0 访问令牌生命周期根据实现和授权类型差异较大。用户委托令牌(授权码流程)通常15分钟到1小时;机器对机器令牌(客户端凭据流程)配置常较长,一般1小时到24小时,以减少刷新开销。高安全环境可执行仅 5 分钟。无论时间窗如何,不支持自动令牌刷新的监控工具都可能产生误报或需人工轮换凭据,增加运维负担与故障风险。
关于 OAuth 2.0 隐式授权:此授权方式在最新 OAuth 2.0 安全最佳实践(RFC 9700)中已被弃用,新系统不应使用。如果现有 API 使用隐式流程,强烈建议迁移到授权码 + PKCE。
API 监控为何重要:业务影响
API 不是基础设施抽象——它们是收入路径。故障带来财务、运营和合约风险。
未被发现的 API 故障成本
无主动监控,团队依赖客户报告故障。行业调查显示客户报告的平均故障检测时间(MTTD)通常超过30分钟——从投诉、调查、分流到升级,时间窗口已过。1分钟间隔的持续合成监控可将检测时间缩短到60秒内,实现问题彻底隔离,防止恶化。
收入计算很直接:订单数/分钟 × 平均订单价值 × 故障持续分钟数。一个每分钟处理100单,平均订单50美元的平台在5分钟支付 API 故障时,潜在损失高达25,000美元。可按实际吞吐与订单价值估算风险。
行业特定场景
- 电商。高峰期结账 API 故障导致全部转化中断。支付授权 API 返回 HTTP 200 但拒绝状态且无警报,数分钟内默默阻塞交易。
- 金融科技。交易处理 API 必须满足亚秒级延迟。持续超越 SLA 阈值降级会导致合同罚款和 PCI DSS 审计问题。
- 医疗健康。EHR 集成和远程医疗端点需保持 HIPAA 合规数据交换。返回 HTTP 200 但数据不完整是合规事件,不仅仅是性能问题。
- SaaS / API 即产品。API 出现宕机触发 SLA 罚款和客户流失。监控提供需记录的可用性证据以满足 SLA 报告。
- 企业 IT。跨部门 CRM、ERP、HR API 集成。Salesforce API 性能降级可能隐性破坏整个销售流程,且日志中无单个 500 错误提示。
第三方 API 风险
现代应用依赖无法控制的外部 API:支付网关(Stripe、PayPal、Braintree)、身份供应商(Okta、Auth0、AWS Cognito)、物流 API 和 CRM 系统。这些服务降级时,即使基础设施正常,用户也会感知为故障。
监控第三方端点使团队能即刻隔离故障是内部还是外部——而无 prior 监控数据,这种区分需要耗费大量调查时间。并提供证据支持要求供应商履行 SLA。
别再从客户那里才知道 API 故障。
Dotcom-Monitor 的合成 API 监控在 60 秒内检测故障,并直接发送警报至 PagerDuty、Slack 或 Microsoft Teams。统一监控支付网关、身份供应商和内部 API。
API 监控 vs. API 测试
两者都验证 API 行为,但在软件生命周期中承担不同职责。混淆会造成覆盖缺失。
| 维度 | API 测试 | API 监控 |
|---|---|---|
| 时间 | 部署前——开发、QA、CI/CD 流水线 | 部署后——生产环境持续 |
| 环境 | 开发、预发布、受控测试环境 | 实时生产、真实基础设施、实际流量 |
| 触发 | 代码提交、构建、手动运行、拉取请求门控 | 定时(如每 1 分钟),全天候持续 |
| 目标 | 防止缺陷流入生产 | 检测生产故障及性能退化 |
| 覆盖 | 所有行为、边缘情况、错误路径 | 关键路径、SLA 端点、用户流程链 |
| 视角 | 内向外:测试代码行为 | 外向内:从用户角度验证 |
| 输出 | 通过/失败报告;失败阻止部署 | 实时警报、正常运行时间 SLA 记录、事件历史 |
实际关系:API 测试 是开发阶段活动,API 监控是运维活动。测试防止缺陷在部署时出现;监控在部署后捕获故障、回归、性能降级和依赖性问题——均基于与受控测试环境不同的真实基础设施。成熟团队两者兼顾,并利用Postman 集合导入桥接两端,将开发测试转为生产监控,无需重复定义请求。
API 监控 vs. APM
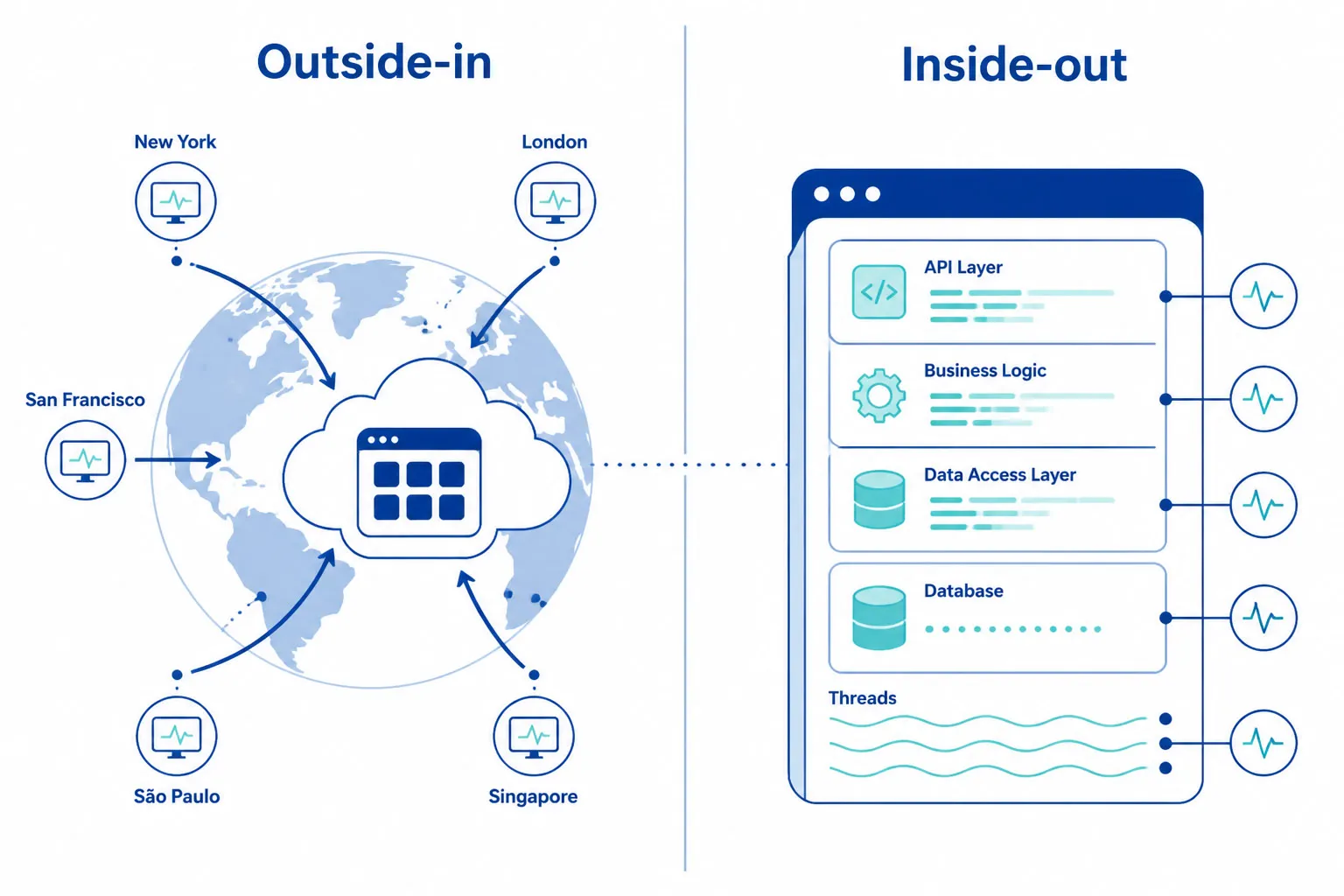 合成监控看到客户视角,APM 看代码运行,两者互补非互换。
合成监控看到客户视角,APM 看代码运行,两者互补非互换。
两者常被混淆,但互补而非替代。
| 合成 API 监控 | APM(应用性能监控) | |
|---|---|---|
| 视角 | 外向内——与用户、合作伙伴相同视点验证 | 内向外——观察内层应用行为 |
| 观察内容 | DNS 失败、网络路由问题、TLS 错误、CDN 错误路由、地理可用性 | 慢查询、内存泄漏、代码异常、函数调用延迟 |
| 运行时间 | 全天候运行——包括无流量时段 | 仅实处理真实请求时 |
| 回答问题 | “客户现在能否调用该 API?” | “请求进入后,应用内部发生了什么?” |
低 MTTR 团队两者并用:APM 用于内因分析,合成 API 监控用于外部验证。日志与追踪回答“代码中出了什么问题?”,合成监控回答“客户现在能否使用该 API?”。
API 协议:REST、SOAP、GraphQL、gRPC 和 WebSocket
每种 API 协议有不同监控要求和失败模式。把所有 API 当 HTTP GET 请求监控将漏失协议特有问题。
REST API 监控
REST 是主流 API 协议。监控验证 HTTP 方法(GET、POST、PUT、PATCH、DELETE)、状态码、响应头和通过 JSONPath 断言的 JSON 响应体。重点需求:断言响应负载字段值——不只状态码;监控所有 HTTP 方法,不仅 GET(POST、PUT、DELETE 引发不同服务端逻辑和故障模式);逐端点单独跟踪响应时间,不以端点集合平均值。
SOAP API 监控
SOAP API 基于 HTTP 交换 XML。监控需求:导入 WSDL 以定义端点和模式;基于 XPath 的 XML 响应元素断言;支持 SOAP 1.1 和 1.2 协议;为企业 SOAP 服务配置 WS-Security 消息级安全。
GraphQL API 监控
GraphQL 的主要监控挑战:多数 GraphQL 服务器实现 即使遇局部错误或查询格式错误仍返回 HTTP 200,状态码非可靠失败信号。必须:
- 发送特定查询负载,断言响应中
data对象 - 检查响应体中的
errors数组——标准 GraphQL 中,每个响应都有可选顶层errors字段,成功时为空或不存在,失败时有值。HTTP 200 且errors[]填值表明请求在 GraphQL 层失败,尽管 HTTP 成功 - 验证查询特定数据不变量:断言
data对象中预期字段存在、非空且类型正确——部分系统在data中编码域失败,而非顶级errors数组 - 监控查询复杂度和深度限制,提前检测性能退化防止超时
gRPC API 监控
gRPC 默认通过 HTTP/2 使用协议缓冲(Protocol Buffers),gRPC-Web 通过代理支持 HTTP/1.1 兼容浏览器客户端。监控需求:导入 proto 文件定义服务和方法;支持协议缓冲消息的序列化/反序列化;使用 gRPC 状态码(OK、UNAVAILABLE、DEADLINE_EXCEEDED 等)验证,不用 HTTP 状态码;支持单次调用、服务器流、客户端流和双向流 RPC 类型。
WebSocket API 监控
WebSocket API 保持持久双向连接,支持实时数据。监控验证连接建立时间和握手成功率、消息传递延迟和负载正确性、连接稳定性及断线后重连行为。
公共 API 监控 vs. 内部 API 监控
 私有代理部署在你网络内部,发起到监控平台的出站连接——无需入站防火墙规则。这使得内部微服务享有与公共 API 同等的监控精度。
私有代理部署在你网络内部,发起到监控平台的出站连接——无需入站防火墙规则。这使得内部微服务享有与公共 API 同等的监控精度。
大多数 API 监控指南专注公共端点。但在微服务架构中,绝大多数关键调用是内部的——服务间调用,未经过公共互联网。
| 公共 API 监控 | 内部 API 监控 | |
|---|---|---|
| 覆盖范围 | 面向客户的端点,合作伙伴 API,第三方集成 | 内部微服务、私有 VPC、预发布环境、防火墙后 API |
| 工作方式 | 外部监控代理从全球位置经公网执行检查 | 部署私有代理于网络内部,发起至监控平台的出站连接 |
| 防火墙需求 | 无——检查来自外部 | 无入站规则,仅出站连接 |
| 捕获内容 | DNS 解析失败、CDN 路由问题、TLS 错误、地理可用性缺陷 | 服务间故障、认证服务延迟、数据库查询 API 降级 |
| 部署情况 | 无安装需求,开箱即用 | 代理安装于本地或私有云(支持 Windows 和 Linux) |
内部微服务 API 是级联故障最常见源头。认证服务降级或数据访问 API 缓慢会引起下游问题,表现为前端失败,使根因定位困难。监控内部 API 帮助团队判断故障是 API 层、下游微服务还是数据库问题。了解更多 防火墙内私有代理监控。
API 监控最佳实践
这些实践可降低平均检测时间(MTTD)、提高警报精度,确保监控覆盖与生产风险匹配。
- 对收入关键端点以 1 分钟间隔监控。支付、认证和核心数据 API,每一分钟未被发现均产生直接业务影响。5 分钟或 15 分钟间隔适用于中低关键级别端点。
- 至少从 5 个地理分布位置运行检查。单点无法检测区域性 DNS 故障、CDN 配置错误或地理路由问题。至少覆盖北美、欧洲和亚太地区。
- 验证负载内容,而非仅状态码。为每个关键端点配置 JSONPath 断言。最昂贵的隐性失败是 HTTP 200 返回不完整、过期或格式错误数据。
- 使用基线派生的警报阈值,而非静态毫秒值。为每端点建立响应时间基线,告警设为 P95 的 2 倍。静态阈值在流量峰值时产生误报。
- 在监控链中包含认证步骤。令牌过期、OAuth 刷新失败、证书轮换是主要 API 宕机原因。认证监控捕捉凭据相关失败,防止故障级联。
- 为每个关键用户流程建立多步骤事务监控。登录流程、结账序列和数据提交工作流是链式 API 调用。单端点监控无法捕获步骤间传递错误或会话问题导致的失败。
- 将第三方 API 依赖作为独立监控。为 Stripe、Okta、Salesforce 等外部依赖建立专门监控。可迅速判定故障是否内部。
- 导入 Postman 或 Insomnia 集合以快速启动监控。将现有 API 定义转换为 24/7 生产监控,无需重建请求配置,消除开发测试与生产监控的差异。
- 集成部署后 API 检查至 CI/CD 流水线。部署后自动执行合成 API 检查,失败可触发自动回滚或流量暂停(蓝绿或金丝雀发布),并通过第二个位置确认警报,减少误报。
- 将警报路由至 PagerDuty、Slack 或 Microsoft Teams,并设定升级策略。仅通过邮件告警存在检测延迟。原生与事件管理工具集成确保警报即时送达正确人员,未响应时按规则升级。
API 监控挑战
即使是设计良好的监控也面临运维难题。预见这些问题,有助于设计规避。
第三方 API 可见性
监控外部依赖能获取可用性和延迟数据,却无法揭示降级内部原因。Stripe 或 Okta 变慢时,可确认并隔离影响范围,但根因分析需依赖供应商状态页和支持渠道。
速率限制
监控代理请求计入 API 速率限制。合成请求量计算公式:位置数 × 每小时检查次数 × 每次监控调用的 API 调用数 × 确认重试次数。单端点监控举例:30 个位置 × 60 次/小时 = 1,800 请求/小时。5 步事务监控同设定为:30 × 60 × 5 = 9,000 请求/小时。需考虑速率预算,尤其内部 API 限制更严格。确保监控供应商 IP 范围被白名单接受。
认证复杂性
使用短期令牌的 API 需支持自动刷新。用户委托的 OAuth 2.0 令牌(授权码流程)通常有效期15分钟至1小时;机器对机器令牌(客户端凭据流程)持续1小时至24小时;高安全环境可能要求仅 5 分钟。基于证书的认证和滚动 API 密钥亦需精心凭据管理。
动态与非确定性响应
返回带时间戳数据、分页结果或随机排序数组的 API 断言难以使用严格匹配。建议使用验证结构、字段存在及类型的 JSONPath 表达式,而非精确字段值。
警报疲劳
过度监控——大量端点以1分钟间隔或阈值设太紧——产生噪声,导致团队对真实警报麻木。建议分层监控:关键路径 1分钟,非关键端点 5–15分钟。用第二地点确认排除瞬态误报再告警。
协议多样性
REST、SOAP、GraphQL、gRPC 和 WebSocket 各需不同断言策略。仅支持 REST 的工具会漏掉 SOAP 服务失败,错误报告 GraphQL 错误为成功因为 HTTP 200。
如何使用 Dotcom-Monitor 设置 API 监控
 检查失败时,告警会路由到你的现有事件响应工具——而非无人关注的独立监控邮箱。
检查失败时,告警会路由到你的现有事件响应工具——而非无人关注的独立监控邮箱。
Dotcom-Monitor 提供强大的合成 API 监控,支持 REST、SOAP 和 GraphQL,覆盖 30 多全球位置,1 分钟检查间隔,多步骤事务支持,原生集成 PagerDuty、Slack 和 Microsoft Teams。
步骤 1 — 定义端点及断言
- 端点 URL: 要监控的 API 端点
- HTTP 方法: GET、POST、PUT、PATCH 或 DELETE
- 请求头:
Content-Type、Authorization及所需自定义头 - 请求体: POST/PUT 请求的 JSON 负载
- 认证: OAuth 2.0、Bearer 令牌、API 密钥、基础认证、mTLS、AWS 签名 v4、NTLM、Kerberos 或自定义头
- 断言: HTTP 状态码、响应时间阈值、头部值、JSONPath/XPath 负载断言
步骤 2 — 从 Postman 或 Insomnia 导入
团队使用 Postman 或 Insomnia 时,完全跳过手动配置端点:
- Postman: 导出 Collection 为 v2.0 或 v2.1 JSON 并导入 Dotcom-Monitor。请求定义、头、体、环境变量和测试断言均保留。
- Insomnia: 导出工作区为 Insomnia v4 JSON 文件并导入 Dotcom-Monitor。请求组、认证配置和环境变量均保留。
二者均将一次性开发测试转换为 24/7 持续运行生产监控,无需重新配置。
已经用 Postman?距 24/7 生产监控仅 5 分钟。
直接导入现有 Postman Collection 至 Dotcom-Monitor。请求定义、头部、环境变量及断言均保留——无需重新配置。
步骤 3 — 配置监控位置和频率
- 检查频率: 设为1、3、5或15分钟间隔——基于端点重要性调整
- 监控位置: 选择覆盖北美、欧洲、亚太及南美的30多个地点
- 私有代理: 针对内部或防火墙后 API——部署代理于本地或私有云(支持 Windows 和 Linux)。代理仅发起出站连接,无需入站防火墙规则。
- 确认重试: 配置二次位置确认检查,避免瞬态网络误报
步骤 4 — 配置告警路由
- PagerDuty: 关键告警直达值班计划,自动创建事件并升级
- Slack / Microsoft Teams: 在运维频道发布带端点详情、错误类型和响应数据的告警消息
- 邮件、短信、电话: 按联系人或团队配置通知偏好
- Webhook: 集成 OpsGenie、ServiceNow 或任意 HTTP 兼容服务
- 阈值配置: 按指标(响应时间、错误率、断言故障率)设定告警条件和严重性等级
步骤 5 — CI/CD 流水线集成
- Dotcom-Monitor REST API: 通过 HTTP API 程序化创建、更新和触发监控任务,兼容任何 CI/CD 系统
- GitHub Actions / Azure DevOps / Jenkins: 添加部署后步骤,触发 Dotcom-Monitor 检查,等待结果,断言失败则使流水线失败
- 预生产验证: 在部署前对预发布环境运行相同合成检查,捕捉回归,防止影响用户
按行业划分的 API 监控用例
| 行业 | 关键监控 API | 关键监控需求 |
|---|---|---|
| 电商 | 结账、支付授权、库存、物流、购物车管理 | 多步骤事务链;1分钟监控间隔;支付确认状态负载断言 |
| 金融科技 / 银行 | 交易处理、KYC/AML 验证、账户余额、外汇汇率、电汇 API | 亚 200ms 延迟 SLA;支持 PCI DSS 证据的合规检查;完整认证流程验证 |
| 医疗健康 | EHR 集成(HL7 FHIR)、保险门户、远程医疗端点、病人排班 | 支持 HIPAA 证据的合规检查;负载数据完整性验证;99.99% 正常运行时间 SLA |
| SaaS | 核心产品 API、Webhook 交付端点、合作伙伴集成 API、认证 API | API 即产品 SLA 遵循;Postman 导入确保开发监控一致性;第三方依赖监控 |
| 企业 IT | CRM、ERP、HRIS、身份提供商、内部工作流自动化 API | 防火墙后私有代理;支持 NTLM/Kerberos 认证;跨部门 API 可见性 |
| 媒体 / 游戏 | CDN 内容交付 API、认证、实时计分、社交功能 API | 地理分布监控;WebSocket 连接监控;流量峰值检测 |
开始监控你的 API。
Dotcom-Monitor 提供来自 30 多全球位置的合成 API 监控,1 分钟检测间隔,多步骤事务支持,原生 PagerDuty、Slack 和 Microsoft Teams 集成。设置耗时不超过 5 分钟。30 天试用,无需信用卡。
