適切なインフラストラクチャと合成モニタリングツールを選択することは、単に稼働時間のチェックボックスを確認することだけではなく、バックエンドの健康状態と実際のエンドユーザー体験との間の可視性のギャップを埋めることです。現代のDevOps環境では、DNSルーティングの失敗や遅延したサードパーティAPIは、サーバークラッシュと同じくらい壊滅的な影響を及ぼす可能性がありますが、これらの「外部から内部への」問題は、従来の内部モニターによってしばしば検出されません。
このガイドでは、MTTR(平均修復時間)を短縮し、プロダクションスタックの「盲点」を排除する必要がある技術チーム向けに特別にキュレーションされた12のベストインフラストラクチャおよび合成モニタリングツールを評価します。
合成モニタリングとインフラストラクチャモニタリングの比較
合成モニタリングは、グローバルな場所から機能的なワークフローを検証しますが、インフラストラクチャモニタリングは、これらのワークフローが失敗する原因となるハードウェアやネットワークの障害を診断するために必要な詳細なテレメトリを提供します。
| モニタリングタイプ | 機能 | 主なユースケースと利点 |
| 合成モニタリング | ユーザーアクション、スクリプト化されたワークフロー、スケジュールされたAPIコールを模倣します | 壊れたフローや遅延をキャッチ。場所間のベンチマーク。稼働時間/トランザクションの健康状態 |
| インフラストラクチャモニタリング | サーバー、ネットワークデバイス、サービス(DNS、TCP/UDP、pingなど)、およびリソースメトリックを追跡します | バックエンドおよびプロトコルレベルの障害、サービスの停止、リソースの飽和を検出します |
トップ12のインフラストラクチャおよび合成モニタリングツールの比較
| ツール | 合成 | インフラストラクチャ | ハイライト | トレードオフ |
| Dynatrace | ✅ | ✅ | AI駆動の可視性、ユーザーフローとバックエンドメトリックのリンク | 複雑。コストが急速に増加する可能性があります |
| Dotcom-Monitor | ✅ | ✅ | 合成とサービスモニタリングを1つのプラットフォームで提供 | ツールの断片化を回避。モジュラーなスケーリングを提供 |
| New Relic | ✅ | ✅ | スクリプト化された合成ワークフロー。強力な可視性 | 高価。学習曲線があります |
| Datadog | ✅ | ✅ | UI、インフラストラクチャ、ログ、メトリックの完全なビュー | 大規模では高価 |
| Site24x7 | ✅ | ✅ | オールインワン:ウェブ、サーバー、ネットワーク、クラウド、合成およびインフラのカバレッジ | 一部のモジュールで深さが低い可能性があります |
| Pingdom | ✅ | – | 稼働時間、トランザクション、ページロードのモニタリングに信頼性があります | 深いインフラおよびプロトコルレベルのチェックが不足しています |
| Checkly | ✅ | – | 合成ワークフローのためのJS/Playwrightスクリプティング | スクリプトの専門知識が必要です。組み込みのインフラチェックがありません |
| Zabbix | – | ✅ | ハイブリッド環境(SNMP、IPMI、JMX、エージェント)の高い汎用性プラットフォーム。 | UI重視の管理;スケーリングには大規模なデータベースの調整が必要です。 |
| Nagios | – | ✅ | 膨大なプラグインライブラリを持つ静的/レガシー環境の伝説的な安定性。 | 高い設定の「苦労」;古いUIでネイティブの時系列グラフが不足しています。 |
| Prometheus | – | ✅ | K8sネイティブメトリックと多次元ラベリングのCNCF標準。 | 外部ストレージ(Thanos/Cortex)とログ/合成用の追加ツールが必要です。 |
| SolarWinds Network Performance Monitor (NPM) | – | ✅ | 優れたネットワークパス、ホップ、デバイスレベル、SNMP、フロー分析 | 合成モニタリングへの焦点が少ない |
| LogicMonitor, ManageEngine OpManager | –またはハイブリッド | ✅ | インフラストラクチャ、ネットワーク、システムモニタリングにいくつかの合成または統合機能を備えています | 合成モニタリングが弱く、アドオンが必要です。 |
1. Dynatrace

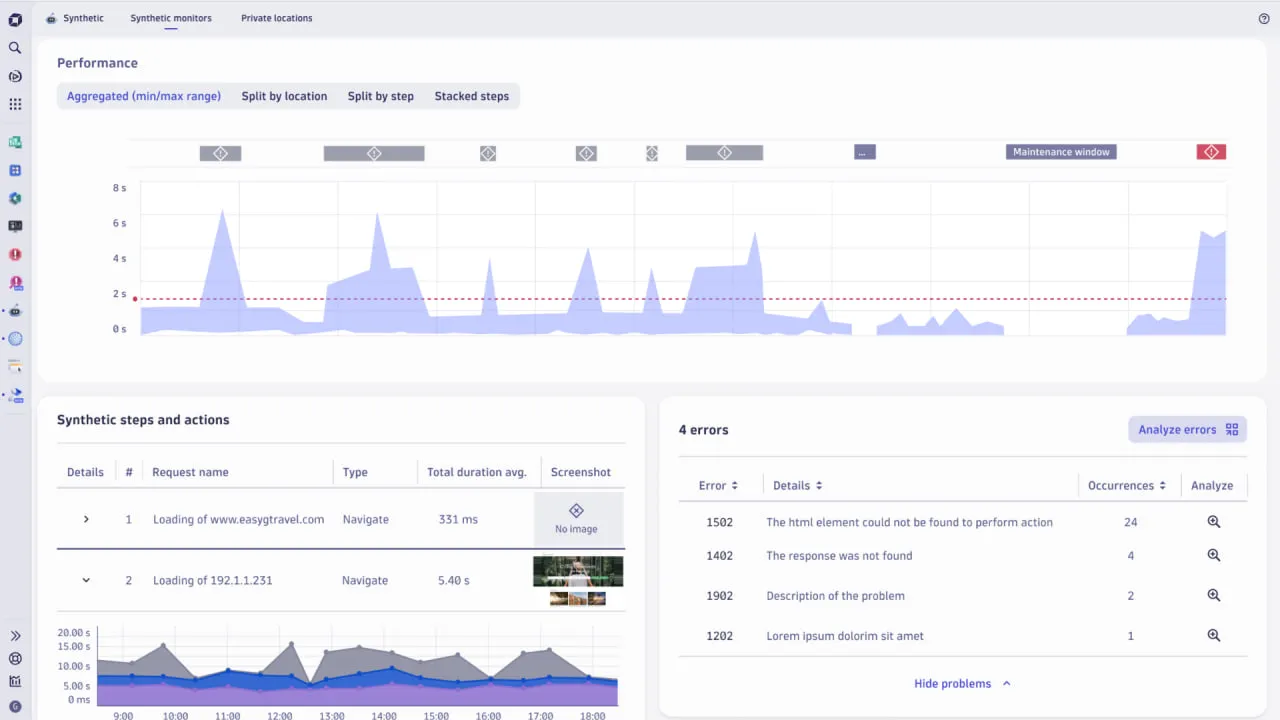
Dynatraceは、合成モニタリング、実ユーザーモニタリング、インフラストラクチャおよびアプリケーションメトリック、自動根本原因分析などの機能を組み合わせたソリューションです。そのOneAgentアーキテクチャは、コンテキスト分析、AI、および自動化を通じて分析を収集します。
主な利点
- AI駆動の異常検出と分析;
- 合成チェックとインフラストラクチャトレースの相関;
- グローバルな合成モニタリングを含むフルスタックカバレッジ;
- ハイブリッド、クラウド、複雑なエンタープライズ環境に適しています。
最適な対象: 大規模なエンタープライズの複雑さと自動根本原因。
実際のシナリオ: あなたの銀行は、レガシーモノリスをハイブリッドクラウドマイクロサービスアーキテクチャに移行しています。「お金を移動する」リクエストは、AWSとオンプレミスのデータセンターにまたがる50以上のサービスに影響を与えます。
解決策: OneAgentを展開します。トランザクションのレイテンシが急増すると、DynatraceのAI(Davis)が自動的にトポロジーをマッピングし、あなたに伝えます:「遅延はコードにない;それはオンプレミスのSQLクラスターでの特定のデータベースロックが原因でカスケードが発生しています。」
2. Dotcom‑Monitor

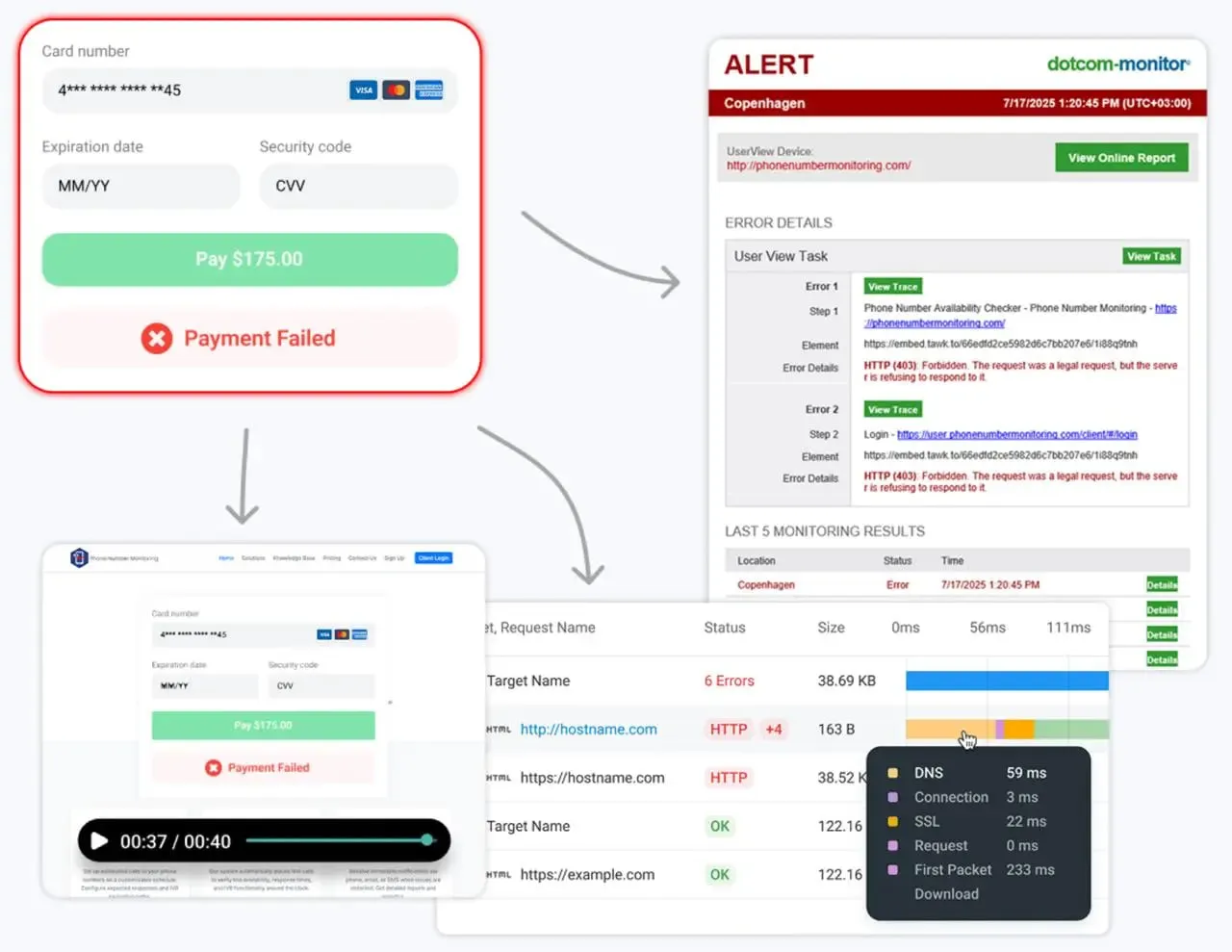
Dotcom-Monitorは、合成モニタリング(ウェブパフォーマンス、スクリプト化されたフロー、APIチェック)とインフラストラクチャモニタリング(DNS、FTP、ICMP、UDP、TCPポートチェック、VoIP)を提供する統合プラットフォームです。また、ServerViewモジュールを介してサーバーおよびデバイスモニタリングを統合し、1つのインターフェースで完全な可視性を提供します。
主な利点
- ユーザーインタラクションを刺激することで基礎的な異常を発見;
- ユーザー体験とインフラを改善するための多地点チェック;
- ツールを切り替えることなく、統一されたダッシュボードで全てを管理;
- モジュラーアプローチ—必要に応じてインフラモジュールを有効化;
- 複数のツールを管理するような運用オーバーヘッドを削減。
最適な対象: グローバルユーザーエクスペリエンスとマルチプロトコルの信頼性。
実際のシナリオ: あなたは高トラフィックのeコマースプラットフォームを運営しており、グローバルな顧客基盤を持っています。サイトが「稼働中」と内部メトリックで表示されているにもかかわらず、ヨーロッパの顧客が地域のDNS遅延やサードパーティの決済ゲートウェイのタイムアウトのためにチェックアウトを完了できないという複数のインシデントが発生しました。
解決策: Dotcom-Monitorを使用して、30以上のグローバルな場所から5分ごとに実ブラウザ合成フローを実行します。ロンドンの地域ISPでルーティングの問題が発生した場合、あなたはウォーターフォールチャートを使って正確な404または500エラーを示すアラートを受け取ります。これにより、ヘルプデスクがチケットで溢れる前に問題を特定できます。
3. New Relic

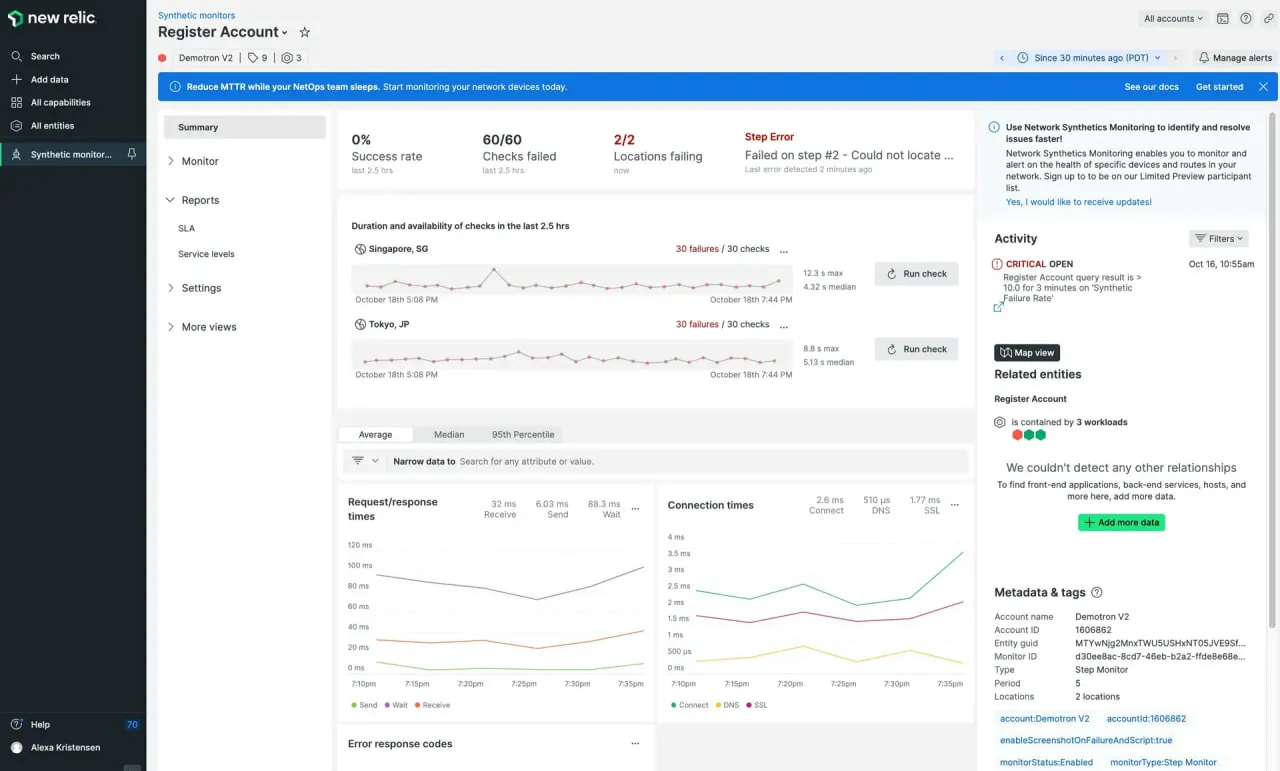
New Relicは、ブラウザおよびAPIワークフロースクリプトを作成し、それらの結果をその可視性スタック(APM、インフラストラクチャ、ログ)に結びつけることができます。これは、すべてを1つのエコシステムで管理したいチーム向けに設計されています。
主な利点
- 複雑なユーザーフローのための豊富なスクリプティングの柔軟性;
- バックエンドメトリックとログとの強力な統合;
- 統一されたダッシュボードとアラートシステム;
- 良好なサポートとエコシステム。
最適な対象: 深いアプリケーションデバッグとコードレベルの最適化。
実際のシナリオ: 大規模な金曜日の午後のデプロイメントの後、あなたのAPIの応答時間が倍増します。ログにはすべてが「OK」と表示されていますが、ユーザーは不満を訴えています。
解決策: New Relic APMを使用して「トランザクショントレース」に掘り下げます。それは、あなたのPythonコントローラーの402行目にある新しい正規表現がCPUスパイクを引き起こしていることを明らかにし、数分以内に特定のコード行を元に戻して修正できるようにします。
4. Datadog

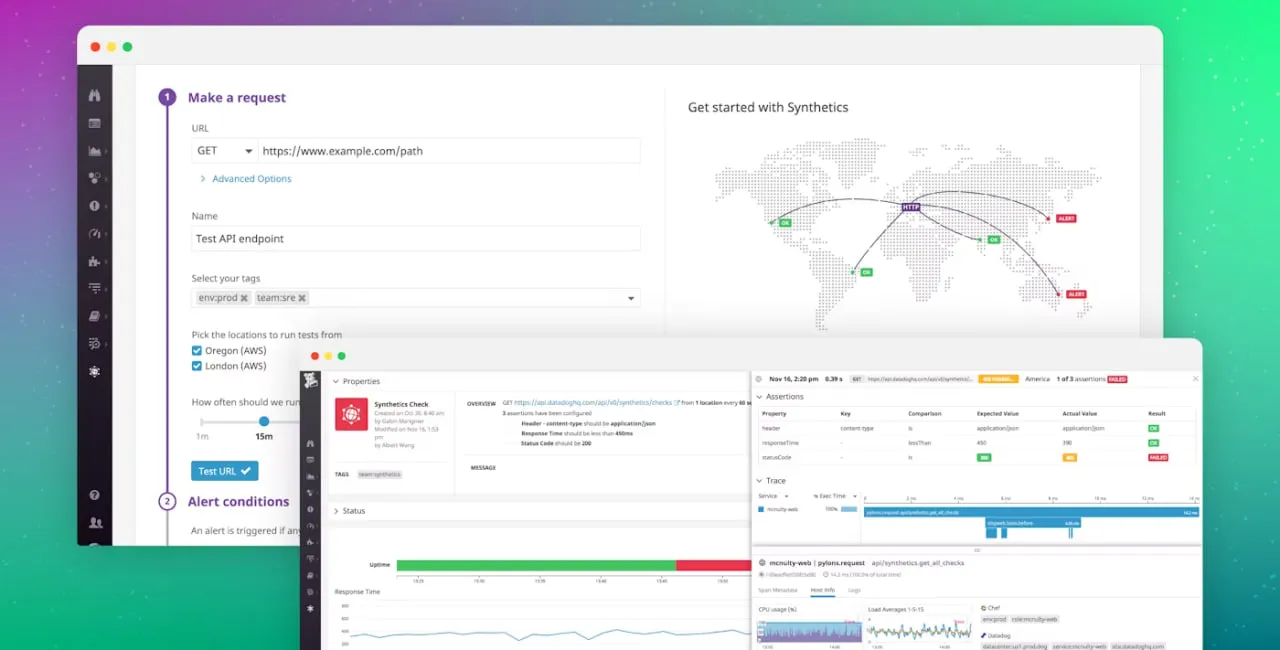
Datadogは、合成モニタリングをメトリック収集、ログ、トレース、インフラストラクチャの健康と統合するアプローチを持っています。これにより、ある意味でオールインワンのソリューションを提供します。
主な利点
- 合成、インフラストラクチャ、ログ全体での統一された相関;
- カスタムダッシュボードとビジュアライゼーション;
- クラウドサービス、コンテナ、データベースなどの広範な統合;
- 大規模システム向けにスケーリング可能。
最適な対象: 高速度のクラウドネイティブチーム。
実際のシナリオ: あなたは500以上のKubernetesマイクロサービスのフリートを管理しており、1日に20回スケールアップおよびスケールダウンしています。特定の「カナリア」デプロイメントが下流のサービスにエラーを引き起こしているかどうかを知る必要があります。
解決策: サービスマップとログ相関を使用します。ポッドがクラッシュすると、ダッシュボードでエラーをクリックし、その特定のコンテナの正確なログとトレースを「バージョン」タグでフィルタリングして即座に確認できます。
5. Site24x7

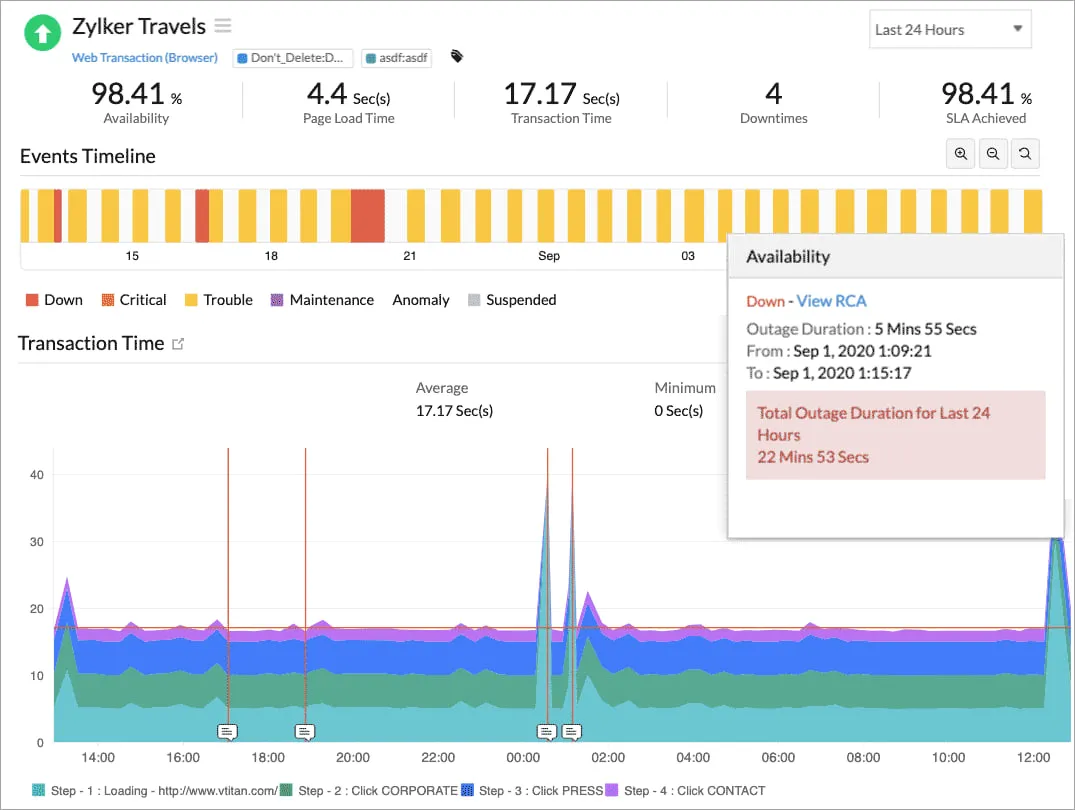
Site24x7は、合成ユーザーフロー、サーバーおよびネットワークモニタリング、クラウドインフラストラクチャ、アプリケーションなどをカバーしています。小規模および中規模のチームにとって、これは完全なカバレッジを提供する良いツールです。
主な利点
- ウェブ、サーバー、ネットワーク、アプリケーションのモニタリング;
- インフラプロトコルのサポート;
- 簡単で段階的な学習;
- 柔軟な価格設定とコストパフォーマンスの良さ。
最適な対象: 予算に敏感なチームが必要とする「オールインワン」基本。
実際のシナリオ: あなたは50人のスタートアップで唯一のDevOpsエンジニアです。限られた予算で、あなたのウェブサイト、オフィスのVPNルーター、AWSの請求書を監視する必要があります。
解決策: Site24x7を使用して基本的な稼働時間のpingとLinuxボックスにサーバーエージェントを設定します。これは「設定して忘れる」ツールで、高価なツールの80%の可視性を20%のコストで提供します。
6. Pingdom

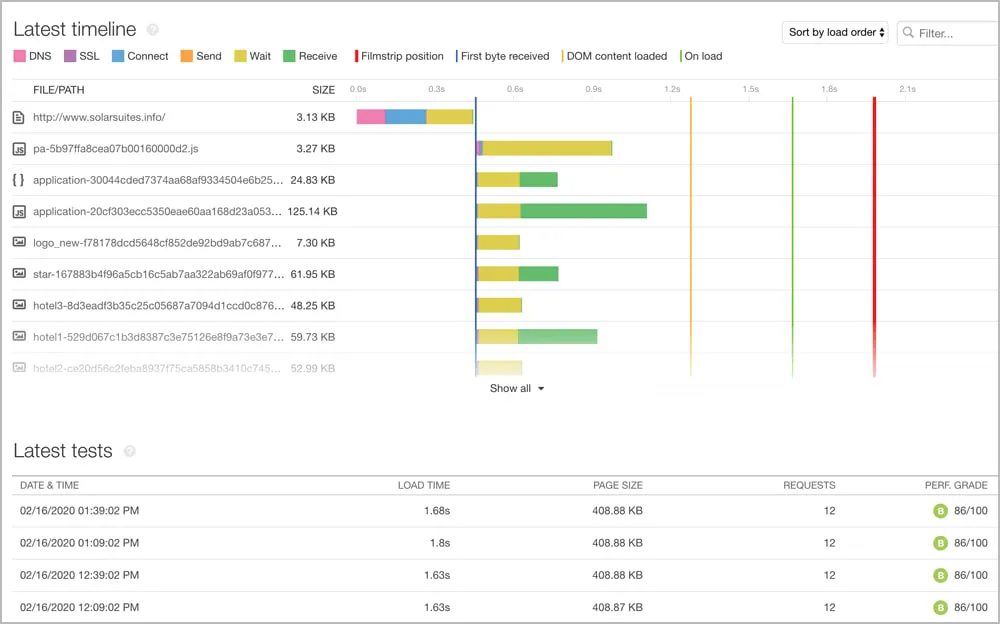
Pingdomは、ウェブベースの合成モニタリングツールです。その機能には、ページロード測定や複数の場所からのユーザー旅のシミュレーションが含まれています。ウェブモニタリングに焦点を当てている人にとっては素晴らしい選択です。
主な利点
- 迅速な設定とデプロイメント;
- 地域の問題検出のための複数の場所チェック;
- マルチステップモニタリングのサポート;
- リアルタイムのアラートとパフォーマンスレポート。
最適な対象: マーケティングおよびビジネス関係者。
実際のシナリオ: あなたのCMOは、サイトが信頼できることを顧客に示すためのシンプルな「公開ステータスページ」を望んでいます。
解決策: シンプルなPingdomチェックを設定します。これは低コストで高信頼性です。サイトがダウンすると、「ステータスページ」の更新がトリガーされ、内部の複雑なSREダッシュボードを公開することなくユーザーに情報を提供します。
7. Checkly

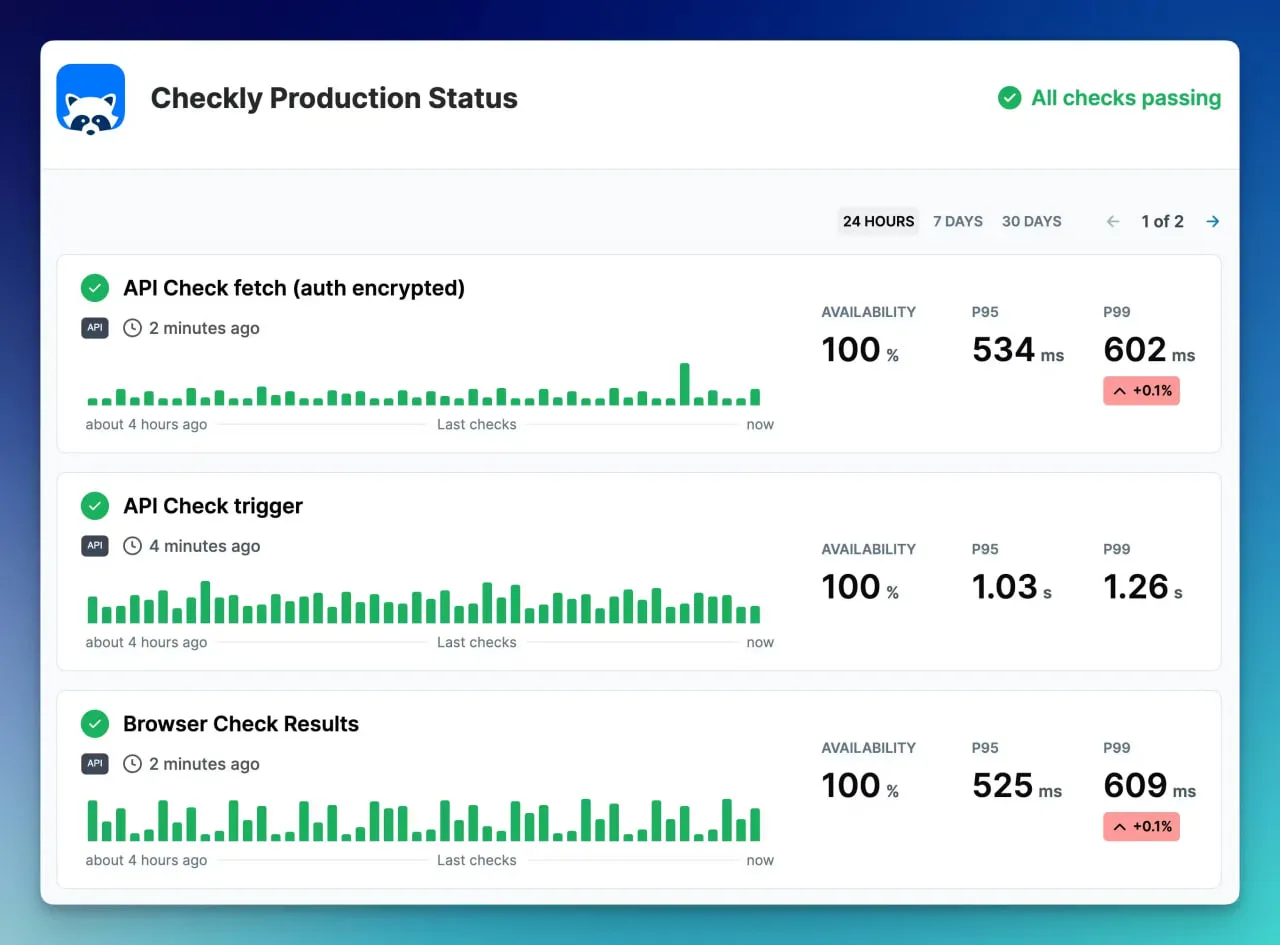
Checklyは、JavaScriptとPlaywrightスクリプティングを強調してチェックを定義するため、開発者向けのツールです。これは、コーディングを知っている人に最適です。
主な利点
- コードを介して高度にカスタマイズ可能な合成チェック;
- CI/CDパイプラインへの簡単な統合;
- APIおよびブラウザベースのモニタリングに適しています;
- 軽量で、現代的なUIと開発者ツールのオリエンテーション。
最適な対象: 現代のフロントエンドおよびQAエンジニアリング(Playwrightファースト)。
実際のシナリオ: あなたのチームは「あなたが構築したものは、あなたが運営する」というモデルに移行しています。あなたの開発者はすでにローカルテストのためにPlaywrightを使用しており、同じスクリプトを使用してプロダクションを監視したいと考えています。
解決策: ChecklyをGitHub Actionsに統合します。PRがマージされるたびに、Checklyは開発者がテストのために書いたのと同じコードを使用してプロダクションの「ハートビート」モニターを自動的に更新します。
8. Prometheus
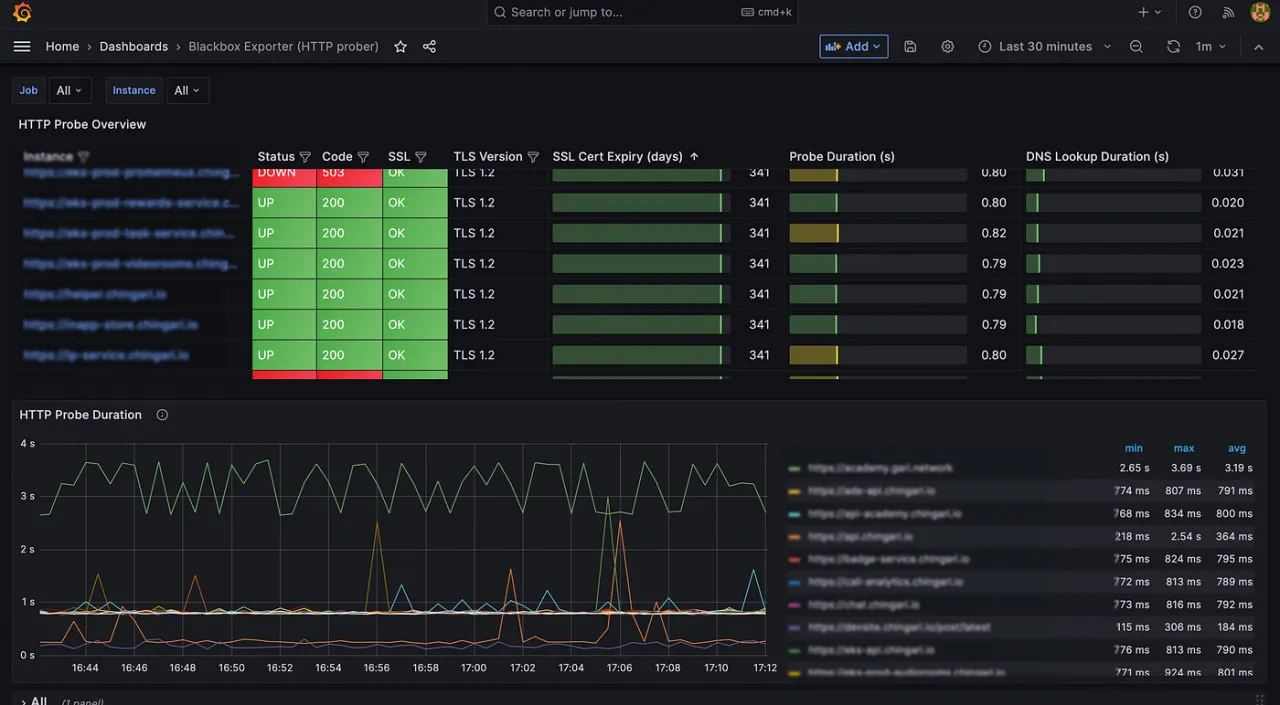
Prometheusは、CNCF卒業の「ゴールドスタンダード」であり、クラウドネイティブモニタリングのためのものです。プルベースのメトリックモデルと多次元ラベルの使用を先駆けており、エフェメラルなKubernetesポッドを追跡するために不可欠です。
主な利点
- Kubernetesサービスとコンテナのシームレスな自動発見。
- 数学的な操作(例:99パーセンタイルのレイテンシを計算する)に設計された強力なクエリ言語。
- 各サーバーは自己完結型で、外部データベースへの依存がないため、停電時にも耐障害性があります。
最適な対象: Kubernetesとマイクロサービスの自動スケーリング。
実際のシナリオ: あなたはEKS(Amazon Kubernetes Service)で小売APIを運営しています。「フラッシュセール」の際に、HPA(水平ポッドオートスケーラー)が200の新しいポッドを起動します。
解決策: PrometheusはKubernetes APIを介してこれらのポッドを自動的に発見し、瞬時にメトリックをスクレイピングし、全体のフリートのp99レイテンシが200msを超えるとアラートを送信します—手動でIPアドレスを設定ファイルに追加することなく。
9. Zabbix
Zabbixはインフラストラクチャモニタリングの「スイスアーミーナイフ」です。これは、中央集権的でエンタープライズ対応のプラットフォームであり、「混合環境」のモニタリングに優れています—最新のLinuxサーバー、レガシーのWindowsボックス、物理ネットワーク機器の混合があります。
主な利点
- Zabbixは、単一のネイティブウェブインターフェースでダッシュボード、アラート、レポートを含みます。
- 物理ハードウェア(ルーター、スイッチ、サーバールームの温度計)に対する一流のサポート。
- スクリプトを作成できる場合(Python、Bash、Go)、Zabbixはそれを監視できます。
最適な対象: ハイブリッドインフラストラクチャと多様なネットワーク環境。
実際のシナリオ: あなたは大学のネットワークを管理しています。500の仮想マシン、200のCiscoスイッチ、3つの異なるデータセンターの温度を監視する必要があります。
解決策: あなたはVM用にアクティブエージェントとスイッチ用にSNMPを使用してZabbixを利用します。コアスイッチがダウンすると赤くなる「ネットワークマップ」をZabbix UIで構築し、ハードウェア障害によって孤立しているサーバーを正確に確認できます。
10. Nagios (Core & XI)
「モニタリングの祖父」。Nagiosはシンプルな「プラグイン」アーキテクチャに基づいて構築されており、スクリプトを実行し、終了コード(0、1、2)を確認し、それに応じてアラートを送信します。安定性に関しては伝説的ですが、1990年代のインターフェースと設定の摩擦については批判されています。
主な利点
- データセンターに存在するものであれば、過去25年間に誰かがそれに対するNagiosプラグインを作成しています。
- コアエンジンは非常に軽量で、最小限のハードウェアで動作できます。
- シンプルな「チェック→結果→アラート」のフローに従い、トラブルシューティングが容易です。
最適な対象: 安定した、レガシー、または「静的」環境。
実際のシナリオ: あなたは安全な施設にあるミッションクリティカルな「エアギャップ」サーバーのシリーズを管理しています。これらのサーバーは決して変更されず、自動スケールせず、24/7/365稼働し続ける必要があります。
解決策: Nagios Coreを使用します。これは非常に堅牢で、アップデート中に壊れることはありません。シンプルなcheck_diskとcheck_sshプラグインを使用します。ハードウェアRAIDが故障した瞬間に信頼性のある単一のメールを送信し、「SaaS」やクラウドの依存関係は一切ありません。
11. SolarWinds NPM

SolarWinds Network Performance Monitor (NPM)は、ネットワークデバイスおよびパスレベルのモニタリングを専門としています。到達可能性、ホップレイテンシ、デバイスの健康、インターフェイストラフィック、SNMPメトリック、ネットワークトポロジーを追跡します。
主な利点
- 優れたネットワークパス、ホップ、インターフェースの可視性;
- SNMPおよびNetFlowサポート、デバイスレベルのメトリック;
- ネットワークボトルネックやトポロジーの問題に関する洞察;
- ネットワーク関連の障害に対する強力な診断。
最適な対象: ネットワーク管理者と物理インフラ。
実際のシナリオ: ユーザーは「インターネットが遅い」と不満を言っています。あなたはサーバールームのハードウェアの問題やオフィス間の悪いファイバーホップを疑っています。
解決策: NetPathを使用します。これは、ネットワークパスのホップごとのマップを表示します。ダラス支店の特定のCiscoルーターで200msのレイテンシスパイクを確認し、ソフトウェアのバグではなくハードウェアのボトルネックであることを確認します。
12. LogicMonitor / ManageEngine OpManager
 LogicMonitorとManageEngineは、合成モジュールとユーザーエクスペリエンスの統合を特徴とするエンタープライズレベルのインフラストラクチャを監視するためのツールです。これらはデバイス、サーバー、VM、およびアプリのモニタリングに適しています。
LogicMonitorとManageEngineは、合成モジュールとユーザーエクスペリエンスの統合を特徴とするエンタープライズレベルのインフラストラクチャを監視するためのツールです。これらはデバイス、サーバー、VM、およびアプリのモニタリングに適しています。
主な利点
- 広範なサーバー、ネットワーク、およびアプリケーションインフラ;
- 事前構築された統合と自動化の利便性;
- エンタープライズオペレーションに最適なダッシュボード;
- 合成モジュール統合のためのいくつかのオプション。
最適な対象: ハイブリッドITおよびマネージドサービスプロバイダー(MSP)。
実際のシナリオ: あなたは10のグローバルオフィスを持つ会社のITを管理しており、それぞれに独自のローカルサーバー、NetAppストレージ、VMwareクラスタがあり、すべてAzureに接続されています。
解決策: LogicMonitorのコレクターアーキテクチャを使用します。これにより、ネットワーク上の2,000以上のデバイスが自動的に発見され、「エンタープライズダッシュボード」が構築され、物理ストレージ、仮想マシン、クラウドインスタンスの健康状態を1つのビューで表示します。
モニタリングスタックを選択する方法は?
モニタリングスイートを選択することは、「最高のツールを見つける」ことではなく、インシデントとその解決の間のギャップを最小限に抑えることです。現代のDevOpsまたはSREチームにとって、意思決定プロセスは以下を優先する必要があります:
1. カバレッジとツールのスプロールを評価する
チームが「ベストオブブリード」スタック(例:メトリック用のPrometheus、スクリプト用のCheckly、ネットワーク用のSolarWinds)を現実的に管理できるかどうかを尋ねてください。専門的である一方で、これはしばしば「データサイロ」を引き起こします。Dotcom-MonitorやDatadogのような統一プラットフォームは、高圧の障害時に合成の失敗をインフラの健康と直接相関させることにより、コンテキストスイッチングを減少させます。
2. 自動化とIaCサポートを優先する
クラウドネイティブ環境では、手動設定は負担です。選択したツールがTerraform、Pulumi、または包括的なCLIをサポートしていることを確認してください。合成チェックをサービスデプロイメントの一部としてプロビジョニングできない場合、そのツールは最終的にエンジニアリングの速度のボトルネックになります。
3. 信号対雑音比を評価する
SREにとって最大の脅威はアラート疲労です。ツールが「Y地点のX回の失敗」のような高度なアラートロジックを提供して、過渡的なネットワークのブリップをフィルタリングすることを探してください。「一律のサイズ」のしきい値を強制するプラットフォームは、しばしば「狼が来た」となり、通知が無視されることにつながります。
4. 総所有コスト(TCO)を分析する
定価を超えて、運用オーバーヘッドを考慮してください。ZabbixやPrometheusのようなオープンソースソリューションはライセンスが「無料」ですが、メンテナンス、パッチ適用、スケーリングに必要なエンジニアリング時間が高価です。SaaSプラットフォームは、より高いライセンスコストを「苦労」を減らすために取引し、チームがモニタリングサーバーのメンテナンスではなく、サイトの信頼性に集中できるようにします。
多くのチームは、レイヤードスタックを採用するか、Dotcom‑Monitorのような統一プラットフォームに全力を注ぎます。あなたにとって最適なものは、予算、システム、チームのサイズ、チームの専門知識によって異なります。
結論
2026年において、「最高の」ツールは、あなたのDevOps、SRE、QAチーム間のサイロを排除するものです。複雑なクラウドネイティブ環境を管理している場合、DatadogやDynatraceは比類のない相関を提供しますが、プレミアム価格がかかります。「エンタープライズ税」なしで、深いプロトコルチェックとグローバルな合成トランザクションを組み合わせた堅牢で統一されたアプローチを求めるチームには、Dotcom-Monitorが「外部から内部への」および「内部から外部への」可視性の最も実用的なバランスを提供します。
最終的には、モニタリングをコードとして扱うことを目指すべきです。強力なAPIサポートとTerraformプロバイダーを持つツールを優先し、モニタリングがインフラストラクチャと同じ速さで進化するようにします。
Frequently Asked Questions
- 中央システムを介してアラートを使用する
- 重大度レベルとしきい値を賢く使用する
- メンテナンスウィンドウ中は抑制する
- 関連するアラートをグループ化し、重複をフィルタリングする
- 過去の偽陽性に基づいて調整する