Choisir la bonne infrastructure et les bons outils de surveillance synthétique ne consiste plus simplement à cocher une case de disponibilité ; il s’agit de combler le fossé de visibilité entre la santé de votre backend et l’expérience réelle de l’utilisateur final. Dans un environnement DevOps moderne, une défaillance dans votre routage DNS ou une API tierce latente peut être tout aussi catastrophique qu’un crash de serveur, et pourtant ces problèmes “de l’extérieur vers l’intérieur” passent souvent inaperçus par les moniteurs internes traditionnels.
Ce guide évalue les 12 meilleurs outils de surveillance d’infrastructure et synthétique, spécialement sélectionnés pour les équipes techniques qui ont besoin de réduire le MTTR (Mean Time to Resolution) et d’éliminer les “zones d’ombre” dans leur pile de production.
Surveillance Synthétique vs. Surveillance d’Infrastructure
Alors que la surveillance synthétique valide les flux fonctionnels depuis des emplacements globaux, la surveillance d’infrastructure fournit la télémétrie granulaire nécessaire pour diagnostiquer les pannes matérielles et réseau qui causent l’échec de ces flux.
| Type de Surveillance | Ce Qu’il Fait | Cas d’Utilisation Clés & Avantages |
| Surveillance Synthétique | Imite les actions des utilisateurs, les flux scriptés et les appels API programmés | Détecte les flux cassés & les ralentissements. Évaluation des performances à travers les emplacements. Santé de disponibilité/transaction |
| Surveillance d’Infrastructure | Suit : serveurs, appareils réseau, services (DNS, TCP/UDP, ping, etc.), & métriques de ressources | Détecte : pannes au niveau du backend & du protocole, pannes de service, et saturation des ressources |
Comparaison des 12 Meilleurs Outils de Surveillance d’Infrastructure et Synthétique
| Outil | Synthétique | Infrastructure | Points Forts | Compromis |
| Dynatrace | ✅ | ✅ | Observabilité pilotée par l’IA, liant les flux utilisateurs et les métriques backend | Complexe. Le coût peut rapidement augmenter |
| Dotcom-Monitor | ✅ | ✅ | Surveillance synthétique et de service sur une seule plateforme | Évite la fragmentation des outils. Offre une mise à l’échelle modulaire |
| New Relic | ✅ | ✅ | Flux synthétiques scriptés. Forte observabilité | Coûteux. A une courbe d’apprentissage |
| Datadog | ✅ | ✅ | Vue complète de l’UI, de l’infrastructure, des journaux, aux métriques | Coûteux à grande échelle |
| Site24x7 | ✅ | ✅ | Tout-en-un : web, serveur, réseau, cloud, couverture synthétique & infra | La profondeur peut être inférieure dans certains modules |
| Pingdom | ✅ | – | Fiable en disponibilité, transaction, & surveillance du temps de chargement des pages | Manque de vérifications approfondies de l’infrastructure & au niveau du protocole |
| Checkly | ✅ | – | Scripting JS/Playwright pour les flux synthétiques | Nécessite une expertise en scripting. Pas de vérifications infra intégrées |
| Zabbix | – | ✅ | Plateforme à haute polyvalence pour des estates hybrides (SNMP, IPMI, JMX, & Agents). | Gestion lourde en UI ; la mise à l’échelle nécessite un réglage significatif de la base de données. |
| Nagios | – | ✅ | Stabilité légendaire pour les environnements statiques/anciens avec une immense bibliothèque de plugins. | Configuration “toil” élevée ; UI datée et manque de graphes de séries temporelles natifs. |
| Prometheus | – | ✅ | La norme CNCF pour les métriques natives K8s et l’étiquetage multidimensionnel. | Nécessite un stockage externe (Thanos/Cortex) et des outils supplémentaires pour les journaux/synthétiques. |
| SolarWinds Network Performance Monitor (NPM) | – | ✅ | Excellente analyse des chemins réseau, des sauts, au niveau des appareils, SNMP, flux | Moins d’accent sur la surveillance synthétique |
| LogicMonitor, ManageEngine OpManager | – ou Hybride | ✅ | Surveillance de l’infrastructure, du réseau, des systèmes avec quelques fonctionnalités synthétiques ou d’intégration | Surveillance synthétique faible, des modules complémentaires sont nécessaires. |
1. Dynatrace

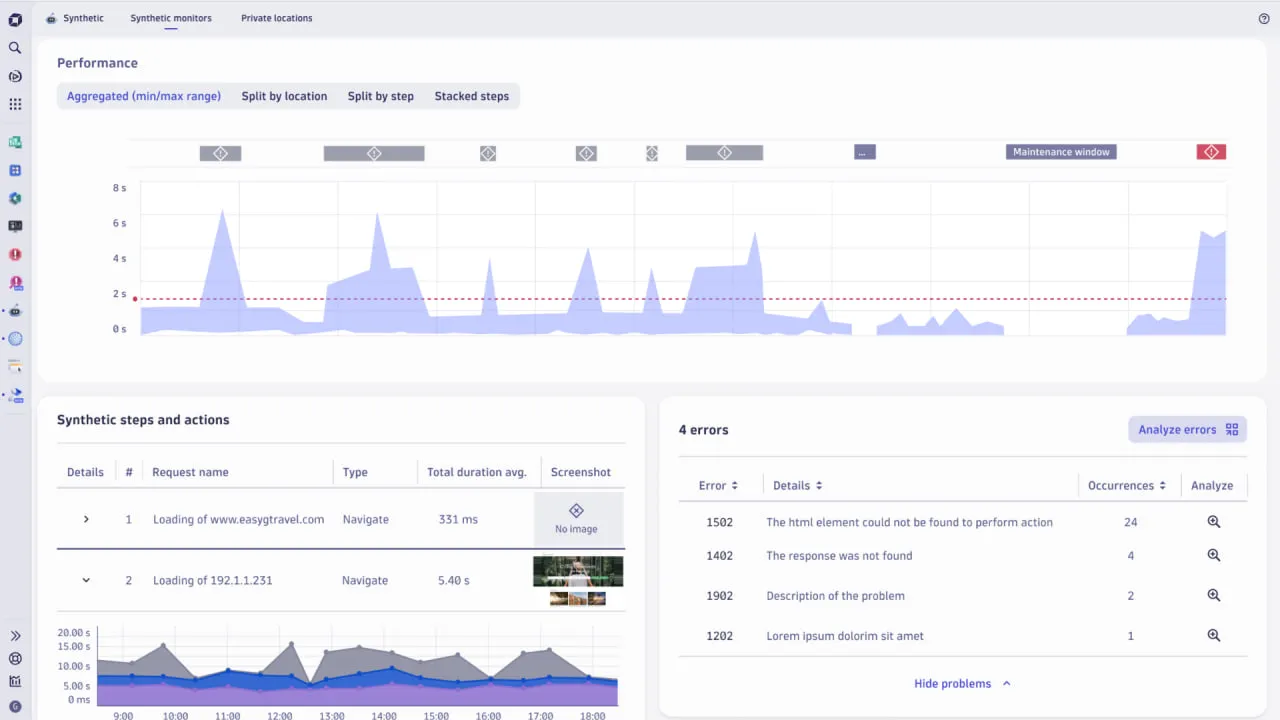
Dynatrace est une solution qui combine des fonctionnalités telles que la surveillance synthétique, la surveillance des utilisateurs réels, les métriques d’infrastructure et d’application, et l’analyse automatique des causes profondes. Son architecture OneAgent collecte des analyses via des analyses contextuelles, l’IA et l’automatisation.
Avantages Clés
- Détection et analyse des anomalies pilotées par l’IA ;
- Corrélation des vérifications synthétiques avec les traces d’infrastructure ;
- Couverture full-stack, y compris la surveillance synthétique globale ;
- Bon pour les environnements hybrides, cloud et d’entreprise complexes.
Meilleur Pour : Complexité d’Entreprise Massive & Analyse Automatisée des Causes Profondes.
Scénario Réel : Votre banque migre un monolithe hérité vers une architecture de microservices hybride-cloud. Une seule demande de “transfert d’argent” touche maintenant plus de 50 services à travers AWS et un centre de données sur site.
La Solution : Vous déployez le OneAgent. Lorsque la latence des transactions augmente, l’IA de Dynatrace (Davis) cartographie automatiquement la topologie et vous dit : “Le retard n’est pas dans le code ; c’est un verrou de base de données spécifique dans le cluster SQL sur site qui cause une cascade.”
2. Dotcom‑Monitor

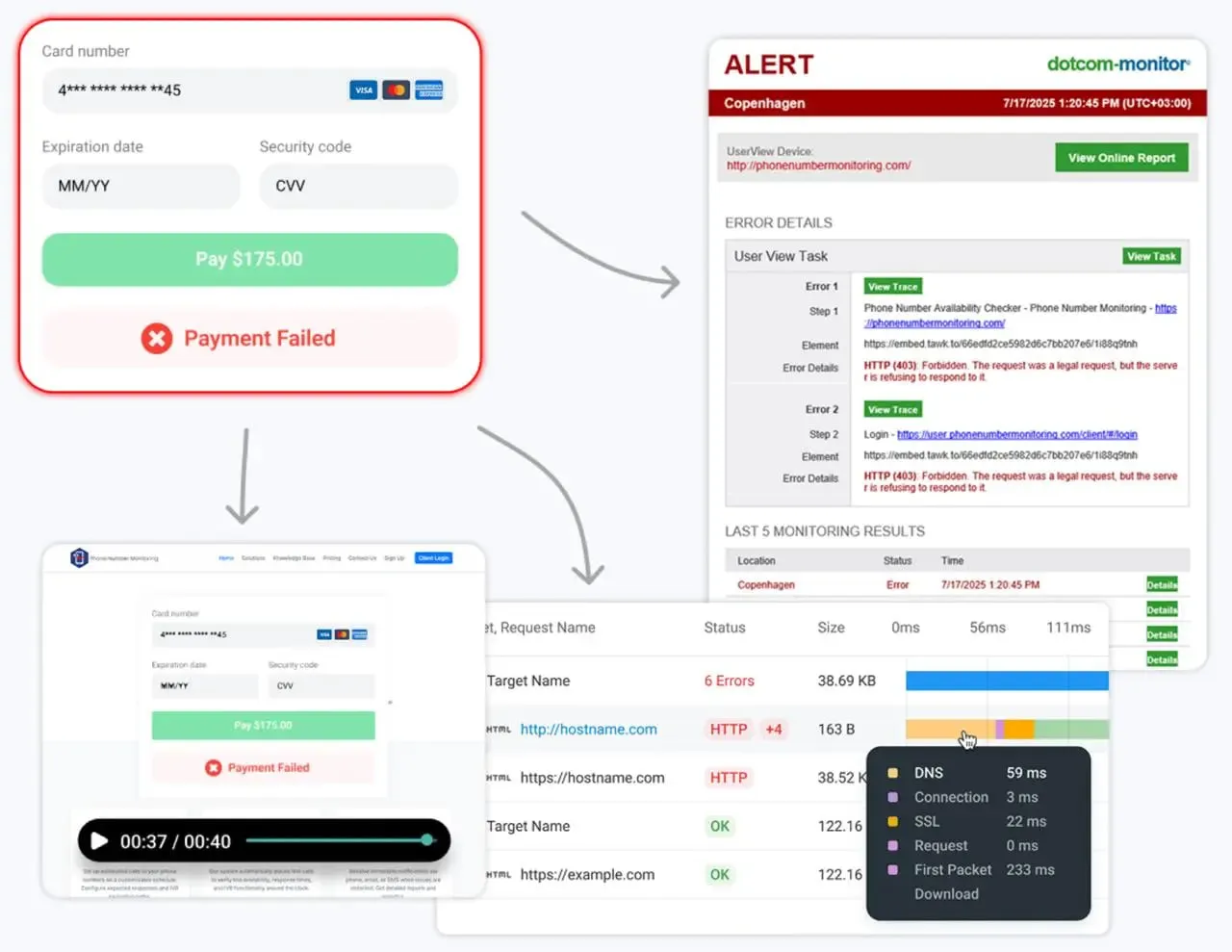
Dotcom-Monitor est une plateforme unifiée offrant à la fois la surveillance synthétique (performance web, flux scriptés, vérifications API) et la surveillance d’infrastructure (DNS, FTP, ICMP, vérifications de port TCP, VoIP). Elle intègre également la surveillance des serveurs et des appareils via son module ServerView pour une visibilité complète avec une seule interface.
Avantages Clés
- Détecte les anomalies sous-jacentes en stimulant les interactions des utilisateurs ;
- Vérifications multi-emplacements pour améliorer l’expérience utilisateur et l’infrastructure ;
- Tout sous un tableau de bord unifié sans changer d’outils ;
- Approche modulaire—activez les modules d’infrastructure selon les besoins ;
- Réduit les frais généraux opérationnels, comme la gestion de plusieurs outils.
Meilleur Pour : Expérience Utilisateur Globale & Fiabilité Multi-Protocole.
Scénario Réel : Vous gérez une plateforme de commerce électronique à fort trafic avec une clientèle mondiale. Vous avez eu plusieurs incidents où le site était “en ligne” selon les métriques internes, mais les clients en Europe ne pouvaient pas finaliser leurs achats en raison d’une latence DNS régionale ou d’un délai d’attente d’une passerelle de paiement tierce.
La Solution : Vous utilisez Dotcom-Monitor pour exécuter des flux synthétiques en navigateur réel depuis plus de 30 emplacements globaux toutes les 5 minutes. Lorsqu’un FAI régional à Londres a un problème de routage, vous recevez une alerte avec un graphique en cascade montrant l’erreur 404 ou 500 exacte avant que votre service d’assistance ne soit inondé de tickets.
3. New Relic

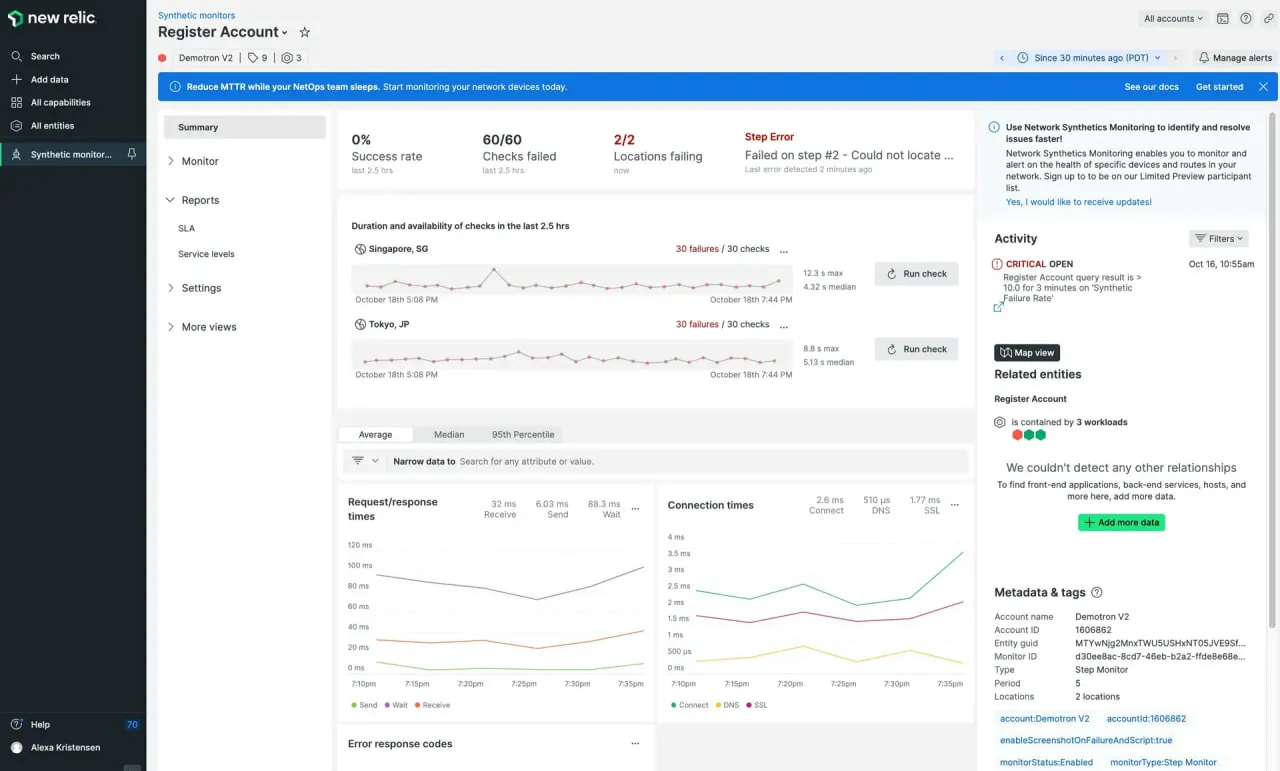
New Relic vous permet d’écrire des scripts de flux de travail pour le navigateur et l’API, puis de lier ces résultats à sa pile d’observabilité (APM, infrastructure, journaux). Il est conçu pour les équipes qui souhaitent tout dans un seul écosystème.
Avantages Clés
- Flexibilité de script riche pour des flux utilisateurs complexes ;
- Forte intégration avec les métriques et journaux backend ;
- Tableaux de bord unifiés et système d’alerte ;
- Bon support et écosystème.
Meilleur Pour : Débogage d’Application Approfondi & Optimisation au Niveau du Code.
Scénario Réel : Après un déploiement majeur un vendredi après-midi, le temps de réponse de votre API double. Les journaux montrent que tout est “OK”, mais les utilisateurs se plaignent.
La Solution : Vous utilisez New Relic APM pour approfondir un “Trace de Transaction”. Cela révèle qu’une nouvelle expression régulière à la ligne 402 de votre contrôleur Python cause des pics de CPU—vous permettant de revenir en arrière et de corriger la ligne de code spécifique en quelques minutes.
4. Datadog

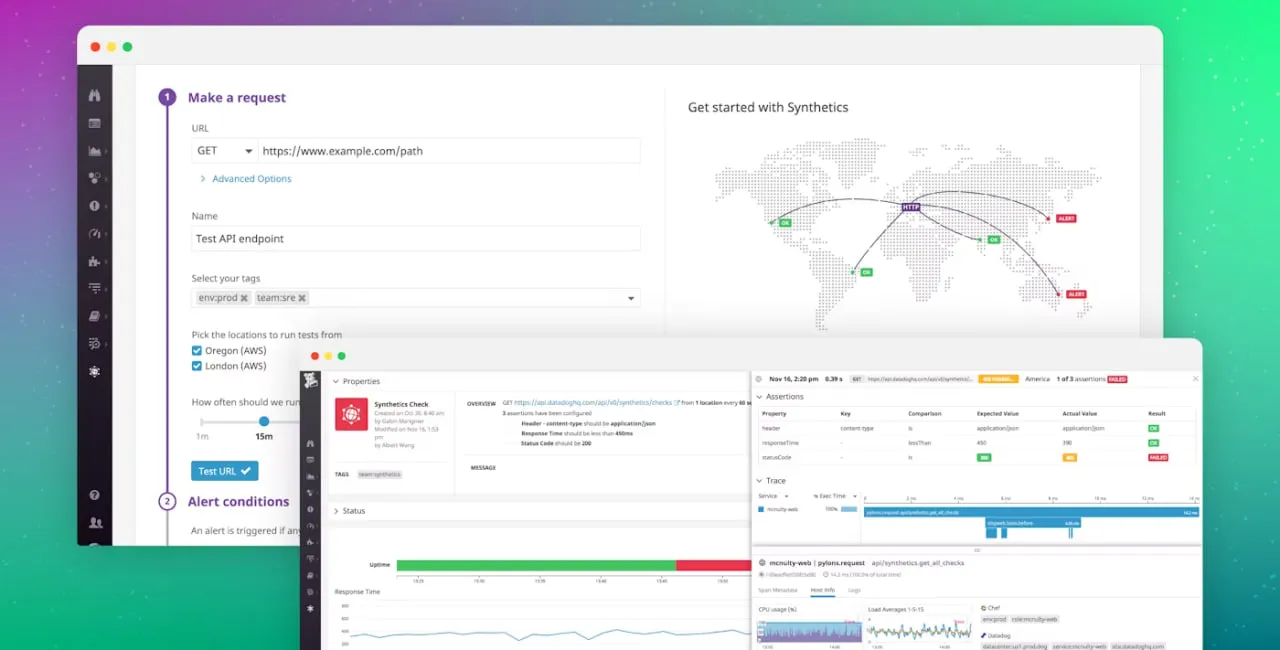
Datadog a une approche intégrative qui combine la surveillance synthétique avec la collecte de métriques, les journaux, le traçage et la santé de l’infrastructure. Cela vous fournit donc une solution tout-en-un.
Avantages Clés
- Corrélation unifiée entre synthétique, infrastructure et journaux ;
- Tableau de bord et visualisations personnalisées ;
- Large intégrations à travers les services cloud, conteneurs, bases de données, etc. ;
- Peut être mis à l’échelle pour de grands systèmes.
Meilleur Pour : Équipes Cloud-Natives à Haute Vélocité.
Scénario Réel : Vous gérez une flotte de plus de 500 microservices Kubernetes qui se mettent à l’échelle 20 fois par jour. Vous devez savoir si un déploiement “Canary” spécifique cause des erreurs dans un service en aval.
La Solution : Vous utilisez Cartes de Service et Corrélation de Journaux. Lorsqu’un pod plante, vous cliquez sur l’erreur dans votre tableau de bord et voyez instantanément les journaux et traces spécifiques pour ce conteneur exact, filtrés par le tag “version”.
5. Site24x7

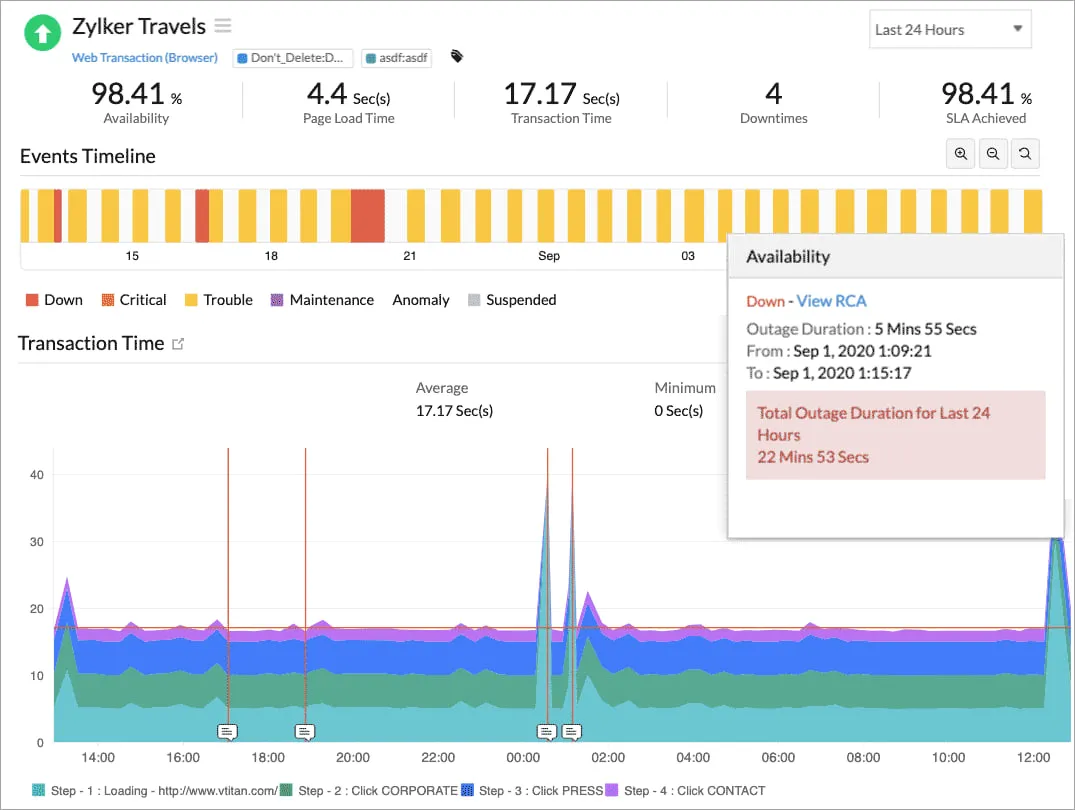
Site24x7 couvre les flux utilisateurs synthétiques, la surveillance des serveurs et des réseaux, l’infrastructure cloud, les applications, et plus encore. Pour les petites et moyennes équipes, c’est un bon outil offrant une couverture complète.
Avantages Clés
- Surveillance pour le web, serveur, réseau, applications ;
- Support des protocoles d’infrastructure ;
- Apprentissage facile et étape par étape ;
- Tarification flexible et bon rapport qualité-prix.
Meilleur Pour : Équipes Soucieuses de Leur Budget Ayant Besoin des “Bases Tout-en-Un”.
Scénario Réel : Vous êtes le seul ingénieur DevOps dans une startup de 50 personnes. Vous devez surveiller votre site web, le routeur VPN de votre bureau, et votre facture AWS avec un budget limité.
La Solution : Vous utilisez Site24x7 pour configurer des pings de disponibilité de base et un Agent Serveur sur vos machines Linux. C’est un outil “à configurer et à oublier” qui vous donne 80 % de la visibilité des outils coûteux à 20 % du coût.
6. Pingdom

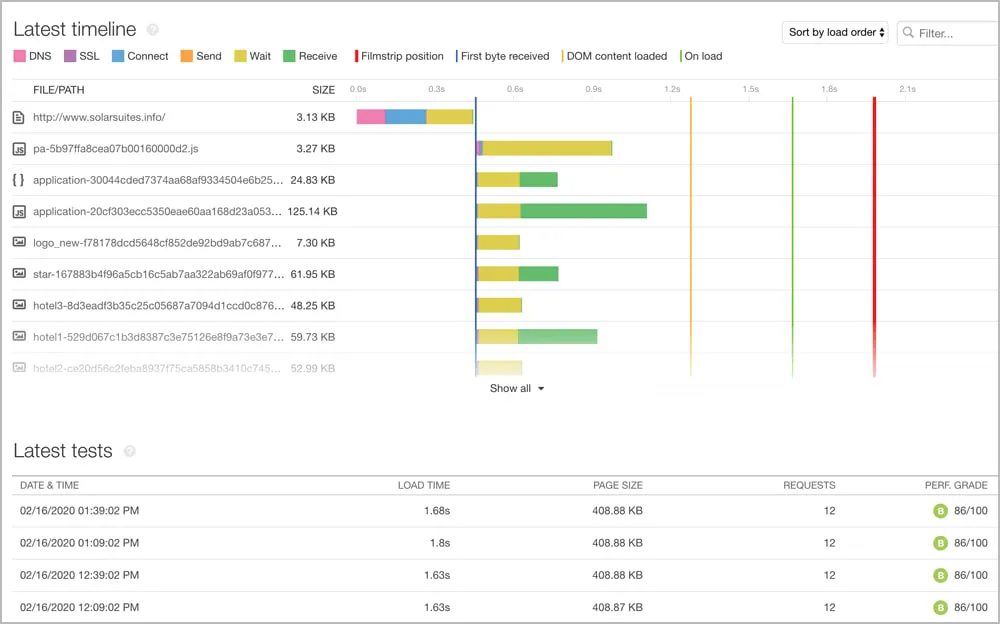
Pingdom est un outil de surveillance synthétique basé sur le web. Ses fonctionnalités incluent des mesures de temps de chargement de page et des simulations de parcours utilisateur depuis plusieurs emplacements. C’est un excellent choix pour quiconque se concentre sur la surveillance web.
Avantages Clés
- Configuration et déploiement rapides ;
- Vérifications multi-emplacements pour la détection de problèmes régionaux ;
- Support de surveillance multi-étapes ;
- Alertes en temps réel et rapports de performance.
Meilleur Pour : Marketing & Parties Prenantes Commerciales.
Scénario Réel : Votre CMO veut une simple “Page de Statut Public” pour montrer aux clients que le site est fiable.
La Solution : Vous configurez une simple Vérification Pingdom. C’est peu coûteux et très fiable. Lorsque le site tombe, cela déclenche une mise à jour de la “Page de Statut” qui informe vos utilisateurs sans exposer vos tableaux de bord SRE internes complexes.
7. Checkly

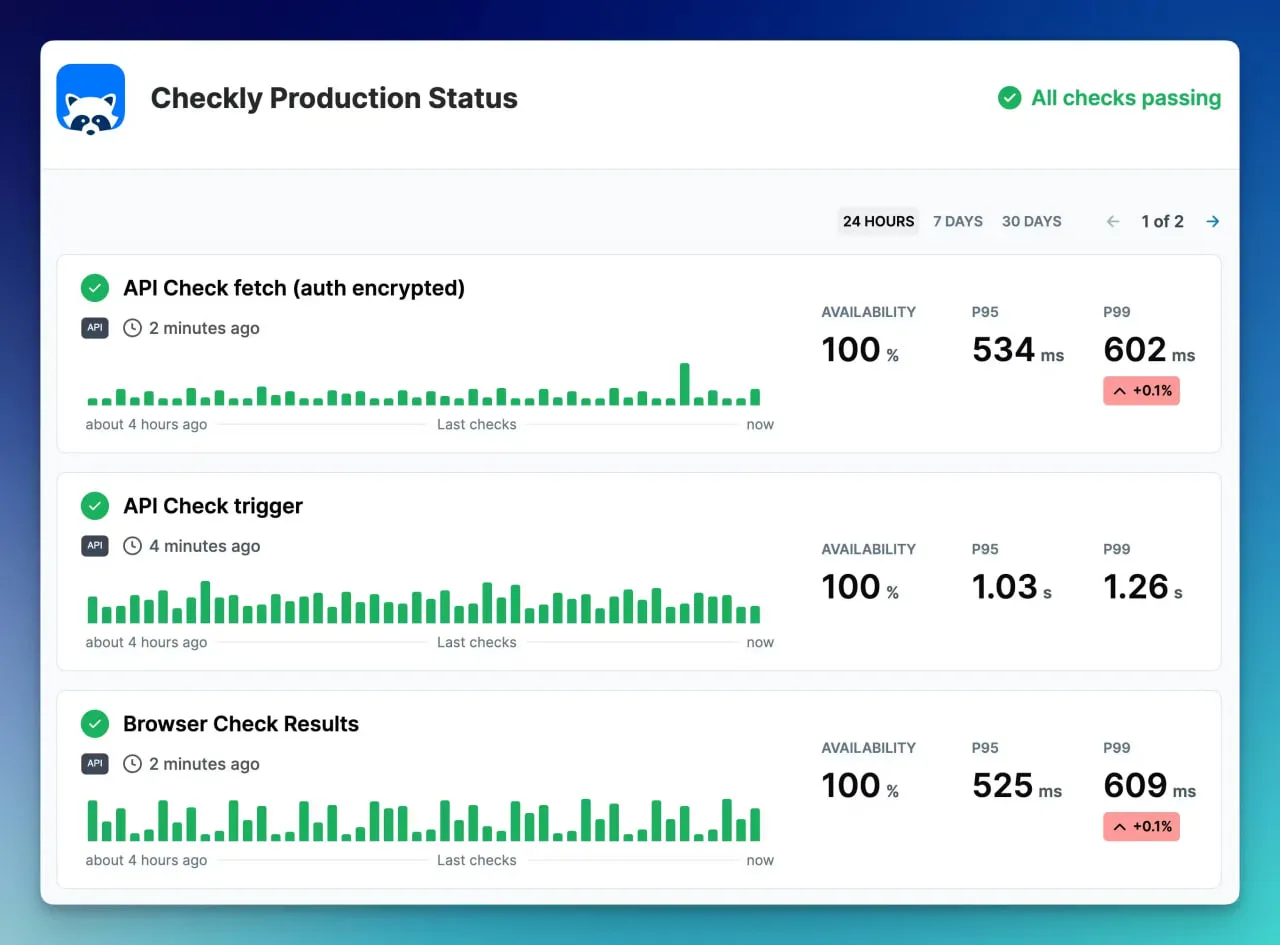
Checkly est destiné aux développeurs car il met l’accent sur le scripting JavaScript et Playwright pour définir des vérifications. Cela le rend idéal pour les personnes qui savent coder.
Avantages Clés
- Vérifications synthétiques hautement personnalisables via le code ;
- S’intègre facilement dans les pipelines CI/CD ;
- Bon pour la surveillance des API et basée sur le navigateur ;
- UI moderne légère et orientation vers les outils pour développeurs.
Meilleur Pour : Ingénierie Frontend Moderne & QA (Playwright-First).
Scénario Réel : Votre équipe évolue vers un modèle “Vous le construisez, vous le gérez”. Vos développeurs utilisent déjà Playwright pour les tests locaux et souhaitent utiliser ces mêmes scripts pour surveiller la production.
La Solution : Vous intégrez Checkly dans vos Actions GitHub. Chaque fois qu’une PR est fusionnée, Checkly met automatiquement à jour vos moniteurs “Heartbeat” de production en utilisant le même code que vos développeurs ont écrit pour les tests.
8. Prometheus
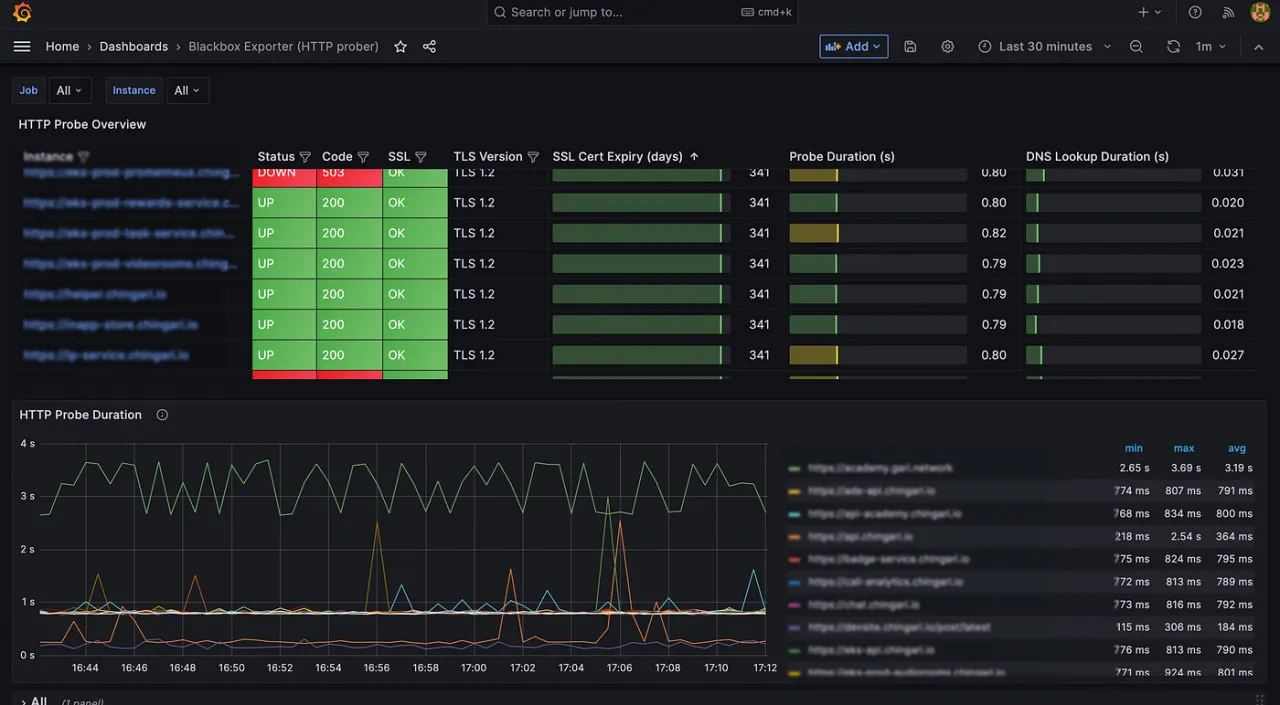
Prometheus est la “norme d’or” pour la surveillance cloud-native, diplômée de la CNCF. Il a été le pionnier du modèle de métriques basé sur le pull et de l’utilisation d’étiquettes multidimensionnelles, qui sont essentielles pour suivre les pods Kubernetes éphémères.
Avantages Clés
- Découverte automatique transparente pour les services et conteneurs Kubernetes.
- Un puissant langage de requête conçu pour des opérations lourdes en mathématiques (par exemple, calculer la latence au 99e percentile).
- Chaque serveur est autonome sans dépendance à une base de données externe, ce qui le rend résilient lors des pannes.
Meilleur Pour : Auto-scaling Kubernetes & Microservices.
Scénario Réel : Vous exécutez une API de vente au détail sur EKS (Amazon Kubernetes Service). Lors d’une “Vente Flash”, votre HPA (Horizontal Pod Autoscaler) fait tourner 200 nouveaux pods.
La Solution : Prometheus découvre automatiquement ces pods via l’API Kubernetes, extrait instantanément leurs métriques, et vous alerte si la latence p99 à travers toute la flotte dépasse 200 ms—sans que vous ayez jamais à ajouter manuellement une seule adresse IP à un fichier de configuration.
9. Zabbix
Zabbix est le “couteau suisse” de la surveillance d’infrastructure. C’est une plateforme centralisée, prête pour l’entreprise, qui excelle dans la surveillance des “estates mixtes”—où vous avez un mélange de serveurs Linux modernes, de machines Windows héritées et d’équipements réseau physiques.
Avantages Clés
- Zabbix inclut des tableaux de bord, des alertes et des rapports dans une seule interface web native.
- Support de premier ordre pour le matériel physique (routeurs, commutateurs, et même thermomètres de salle serveur).
- Si vous pouvez écrire un script pour cela (Python, Bash, Go), Zabbix peut le surveiller.
Meilleur Pour : Infrastructure Hybride & Réseaux Diversifiés.
Scénario Réel : Vous gérez un réseau universitaire. Vous devez surveiller 500 machines virtuelles, 200 commutateurs Cisco, et la température de trois centres de données différents.
La Solution : Vous utilisez Zabbix avec des Agents Actifs pour les VM et SNMP pour les commutateurs. Vous construisez une “Carte Réseau” dans l’UI de Zabbix qui devient rouge si un commutateur central tombe, vous permettant de voir exactement quels serveurs sont isolés par la panne matérielle.
10. Nagios (Core & XI)
Le “Grand-Père” de la surveillance. Nagios est construit sur une simple architecture “Plugin”—il exécute un script, regarde le code de sortie (0, 1, 2), et alerte en conséquence. Il est légendaire pour sa stabilité mais critiqué pour son interface des années 1990 et la friction de configuration.
Avantages Clés
- Si cela existe dans un centre de données, quelqu’un a déjà écrit un plugin Nagios pour cela au cours des 25 dernières années.
- Le moteur principal est incroyablement léger et peut fonctionner sur du matériel minimal.
- Il suit un simple flux “Vérification -> Résultat -> Alerte” qui est facile à dépanner.
Meilleur Pour : Environnements Stables, Hérités ou “Statique”.
Scénario Réel : Vous gérez une série de serveurs “Air-Gapped” critiques dans une installation sécurisée. Ces serveurs ne changent jamais, ils ne s’auto-scalent pas, et ils doivent rester en ligne 24/7/365.
La Solution : Vous utilisez Nagios Core. Il est solide comme un roc et ne se brisera pas lors d’une mise à jour. Vous utilisez un simple plugin check_disk et check_ssh. Il envoie un seul e-mail fiable au moment où un raid matériel échoue, et ce, sans aucune dépendance à “SaaS” ou au cloud.
11. SolarWinds NPM

SolarWinds Network Performance Monitor (NPM) se spécialise dans la surveillance des appareils réseau et des niveaux de chemin. Il suit la disponibilité, la latence des sauts, la santé des appareils, le trafic des interfaces, les métriques SNMP, et la topologie réseau.
Avantages Clés
- Visibilité exceptionnelle des chemins réseau, des sauts, et des interfaces ;
- Support SNMP et NetFlow, métriques au niveau des appareils ;
- Informations sur les goulets d’étranglement réseau et les problèmes de topologie ;
- Diagnostics solides pour les pannes liées au réseau.
Meilleur Pour : Administrateurs Réseau & Infrastructure Physique.
Scénario Réel : Les utilisateurs se plaignent que “l’internet est lent”. Vous soupçonnez un problème matériel dans la salle des serveurs ou un mauvais saut de fibre entre vos bureaux.
La Solution : Vous utilisez NetPath. Cela vous montre une carte étape par étape du chemin réseau. Vous voyez un pic de latence de 200 ms à un routeur Cisco spécifique dans votre succursale de Dallas, confirmant qu’il s’agit d’un goulet d’étranglement matériel, pas d’un bug logiciel.
12. LogicMonitor / ManageEngine OpManager
 LogicMonitor et ManageEngine sont des outils pour surveiller l’infrastructure de niveau entreprise, avec des modules synthétiques et des intégrations d’expérience utilisateur. Ils sont bons pour la surveillance des appareils, des serveurs, des VM et des applications.
LogicMonitor et ManageEngine sont des outils pour surveiller l’infrastructure de niveau entreprise, avec des modules synthétiques et des intégrations d’expérience utilisateur. Ils sont bons pour la surveillance des appareils, des serveurs, des VM et des applications.
Avantages Clés
- Large infrastructure de serveurs, réseau, & applications ;
- Intégration préconstruite et commodité d’automatisation ;
- Tableau de bord parfait pour les opérations d’entreprise ;
- Quelques options pour l’intégration de modules synthétiques.
Meilleur Pour : IT Hybride & Fournisseurs de Services Managés (MSPs).
Scénario Réel : Vous gérez l’IT d’une entreprise avec 10 bureaux mondiaux, chacun avec ses propres serveurs locaux, stockage NetApp, et clusters VMware, tous connectés à Azure.
La Solution : Vous utilisez l’architecture Collector de LogicMonitor. Elle découvre automatiquement tous les 2 000+ appareils sur votre réseau et construit un “Tableau de Bord d’Entreprise” qui montre la santé de votre stockage physique, de vos machines virtuelles, et de vos instances cloud en une seule vue.
Comment Choisir Votre Pile de Surveillance ?
Choisir une suite de surveillance concerne moins “de trouver le meilleur outil” et plus de minimiser l’écart entre un incident et sa résolution. Pour une équipe DevOps ou SRE moderne, le processus de prise de décision doit prioriser les éléments suivants :
1. Évaluer la Couverture vs. la Dispersion des Outils
Demandez-vous si votre équipe peut réellement gérer une pile “best-of-breed” (par exemple, Prometheus pour les métriques, Checkly pour les scripts, et SolarWinds pour le réseau). Bien que spécialisées, cela conduit souvent à des “silos de données”. Des plateformes unifiées comme Dotcom-Monitor ou Datadog réduisent le changement de contexte lors des pannes sous pression en corrélant les échecs synthétiques directement avec la santé de l’infrastructure.
2. Prioriser l’Automatisation et le Support IaC
Dans un environnement cloud-native, la configuration manuelle est une responsabilité. Assurez-vous que l’outil choisi prend en charge Terraform, Pulumi, ou une CLI complète. Si vous ne pouvez pas provisionner une vérification synthétique dans le cadre d’un déploiement de service, l’outil finira par devenir un goulet d’étranglement pour votre vélocité d’ingénierie.
3. Évaluer le Rapport Signal/Bruit
La plus grande menace pour un SRE est la fatigue des alertes. Recherchez des outils qui offrent une logique d’alerte sophistiquée—comme “X échecs sur Y emplacements”—pour filtrer les clignotements réseau transitoires. Évitez les plateformes qui imposent un seuil “taille unique”, ce qui conduit souvent à “crier au loup” et à des notifications ignorées.
4. Analyser le Coût Total de Possession (CTP)
Au-delà du prix d’achat, considérez les frais généraux opérationnels. Les solutions open-source comme Zabbix ou Prometheus sont “gratuites” en licence mais coûteuses en heures d’ingénierie nécessaires pour la maintenance, le patching, et la mise à l’échelle. Les plateformes SaaS échangent des coûts de licence plus élevés contre une réduction du “toil”, permettant à votre équipe de se concentrer sur la fiabilité du site plutôt que sur la maintenance des serveurs de surveillance.
De nombreuses équipes adoptent une pile en couches ou s’engagent pleinement sur des plateformes unifiées comme Dotcom‑Monitor. Ce qui est le mieux pour vous dépend de votre budget, de votre système, de la taille de votre équipe et de l’expertise de votre équipe.
Conclusion
En 2026, le “meilleur” outil est celui qui élimine les silos entre vos équipes DevOps, SRE, et QA. Si vous gérez un environnement complexe et cloud-native, Datadog ou Dynatrace offrent une corrélation inégalée, bien qu’à un prix premium. Pour les équipes cherchant une approche robuste et unifiée qui combine des vérifications de protocole approfondies avec des transactions synthétiques globales sans la “taxe d’entreprise”, Dotcom-Monitor offre le meilleur équilibre pragmatique entre visibilité “de l’extérieur vers l’intérieur” et “de l’intérieur vers l’extérieur”.
En fin de compte, votre objectif devrait être de traiter la surveillance comme du code. Priorisez les outils avec un bon support API et des fournisseurs Terraform afin que votre surveillance évolue aussi rapidement que votre infrastructure.
Frequently Asked Questions
- Utilisez des alertes via un système central
- Utilisez les niveaux de gravité & seuils judicieusement
- Supprimez pendant les fenêtres de maintenance
- Groupez les alertes connexes et filtrez les doublons
- Ajustez en fonction des faux positifs historiques
