API-Überwachung ist die kontinuierliche, automatisierte Praxis der Validierung von API-Endpunkten hinsichtlich Verfügbarkeit, Antwortzeit und Datenkorrektheit – sie bestätigt nicht nur, dass ein Endpunkt antwortet, sondern auch, dass er die richtigen Daten im richtigen Format innerhalb akzeptabler Latenz aus Sicht der Nutzer und abhängiger Systeme zurückliefert.

APIs sind das verbindende Gewebe moderner Software. Jedes Mal, wenn sich ein Nutzer anmeldet, eine Zahlung tätigt oder eine Echtzeit-Benachrichtigung erhält, werden im Hintergrund mehrere API-Aufrufe ausgeführt – oft über Microservices, Cloud-Anbieter und Drittanbieter hinweg. Wenn diese Aufrufe fehlschlagen oder langsamer werden, ist die Auswirkung sofort spürbar: unterbrochene Checkout-Prozesse, ausgesperrte Benutzer und entgangene Einnahmen.
Doch die meisten Teams entdecken API-Ausfälle erst, wenn Kunden diese melden. Ohne proaktive Überwachung liegt die Verzögerung zwischen Ausfall und Untersuchung typischerweise bei mehreren Minuten – lang genug, um echten Umsatz- und SLA-Risiken ausgesetzt zu sein, bevor jemand alarmiert wird.
Dieser Leitfaden erklärt, was API-Überwachung ist, wie sie funktioniert, welche Metriken zu verfolgen sind, wie sie sich von API-Tests und APM unterscheidet und wie sie implementiert wird – mit der Präzision, die DevOps-Ingenieure, SREs und QA-Teams benötigen, um fundierte Entscheidungen im Betrieb zu treffen.
Was ist API-Überwachung?
API-Überwachung deckt drei verschiedene Validierungsebenen in aufsteigender Spezifität ab:
- Verfügbarkeitsüberwachung – Ist der Endpunkt erreichbar? Liefert er eine HTTP-Antwort ohne Timeout?
- Performanceüberwachung – Wie lange dauert die Antwort? Führt TTFB, DNS-Auflösung oder TLS-Handshake zu Latenzen?
- Payload-Validierung – Enthält der Antwortbody die erwartete Datenstruktur? Bestehen JSONPath- oder XPath-Assertions?
Was ist ein API-Endpunkt?
Eine Application Programming Interface (API) ist ein Satz von Protokollen und Definitionen, der es Softwaresystemen erlaubt, zu kommunizieren. Ein API-Endpunkt ist die spezifische URL, an der eine API Anfragen empfängt und Antworten zurückgibt – die Beobachtungseinheit der API-Überwachung. Zum Beispiel:
POST /v2/auth/token– Token-Ausgabe-EndpunktGET /v2/orders/{id}– Bestellabruf-EndpunktPOST /v2/payments/charge– Zahlungsabwicklungs-Endpunkt
Moderne Anwendungen sind gleichzeitig auf dutzende oder hunderte solcher Endpunkte angewiesen – interne Microservices, Drittanbieter-Zahlungsgateways, Identitätsanbieter, Versand-APIs und CRM-Systeme. API-Überwachung erhält die Sichtbarkeit über alle hinweg.
Arten der API-Überwachung
Nicht alle API-Überwachungen sind gleich. Das Verständnis der Kategorien hilft Teams, eine Abdeckung aufzubauen, die sowohl zur Architektur als auch zu den geschäftlichen Anforderungen passt. Die fünf Kernarten gelten für fast jedes Team; spezialisierte Arten sind dann relevant, wenn ihre Bedingungen zutreffen.
Kernarten
| Typ | Was validiert wird | Am besten für |
|---|---|---|
| Uptime-Überwachung | Erreichbarkeit des Endpunkts; HTTP-Antwortcodes; Antwortzeit innerhalb des Timeout-Fensters | Grundlegende Verfügbarkeits-SLAs; sofortige Ausfallerkennung |
| Performance-Überwachung | Antwortzeit, TTFB, DNS-Auflösung, TCP-Handshake, TLS-Dauer, Durchsatz | Latenz-SLAs, P95/P99-Ziele, Kapazitätsplanung |
| Payload- / Validierungsüberwachung | Antwortinhalt via JSONPath/XPath Assertions; Schema-Korrektheit; Feldwerte | Erkennung stiller Ausfälle, bei denen HTTP 200 ≠ korrekte Daten bedeutet |
| Synthetische Überwachung | Simulierte API-Aufrufe von globalen Standorten in geplanten Intervallen, unabhängig vom realen Traffic | Proaktive Erkennung; geographische Abdeckung; Verkehrslose Zeiträume |
| Multi-Step-Transaktionsüberwachung | Verkettete API-Aufrufsequenzen (z. B. Auth → Abfrage → Übermittlung → Bestätigung); Übertragung von Zwischenwerten | E-Commerce-Flows, Login-Journeys, Bestell-Workflows |
Spezialisierte Arten
| Typ | Was validiert wird | Am besten für |
|---|---|---|
| Sicherheitsüberwachung | Auth-Fehler, anomale Anfrage-Muster, Ablauf von Zertifikaten, Missbrauch von Rate-Limits, Token-Wiederverwendung | FinTech, Gesundheitswesen; APIs mit PII/PHI |
| Compliance-Checks | TLS-Version-/Cipher-Validierung, Zertifikatsablauf, Vorhandensein von Sicherheitsheadern, Auth-Tests | Gesundheitswesen, Finanzdienstleistungen, regulierte Branchen |
| Real User Monitoring (RUM) | Reale Nutzer-API-Interaktionen; vollständige Sitzungsübersicht; echte geografische und Gerätevariationen | Verständnis des echten Nutzer-Impacts; Validierung synthetischer Befunde |
| Versions- & Deprecation-Überwachung | API-Versionsannahme, Fehleranstiege nach Versionswechsel, Abwärtskompatibilität | Teams mit paralleler Mehrfachversion-Verwaltung |
| Drittanbieter- / Integrationsüberwachung | Externe API-Abhängigkeiten (Stripe, Okta, Salesforce, Twilio); Trennung externer und interner Fehler | Alle Apps mit kritischen Workflows via Drittanbieter-APIs |
Ein Hinweis zu Compliance-Checks: Diese liefern unterstützende Belege für spezifische technische Kontrollen. Framework-Compliance (HIPAA, PCI DSS, SOC 2) erfordert umfassendere organisatorische Steuerung über das Monitoring hinaus.
Synthetische Überwachung vs. Real User Monitoring (RUM)
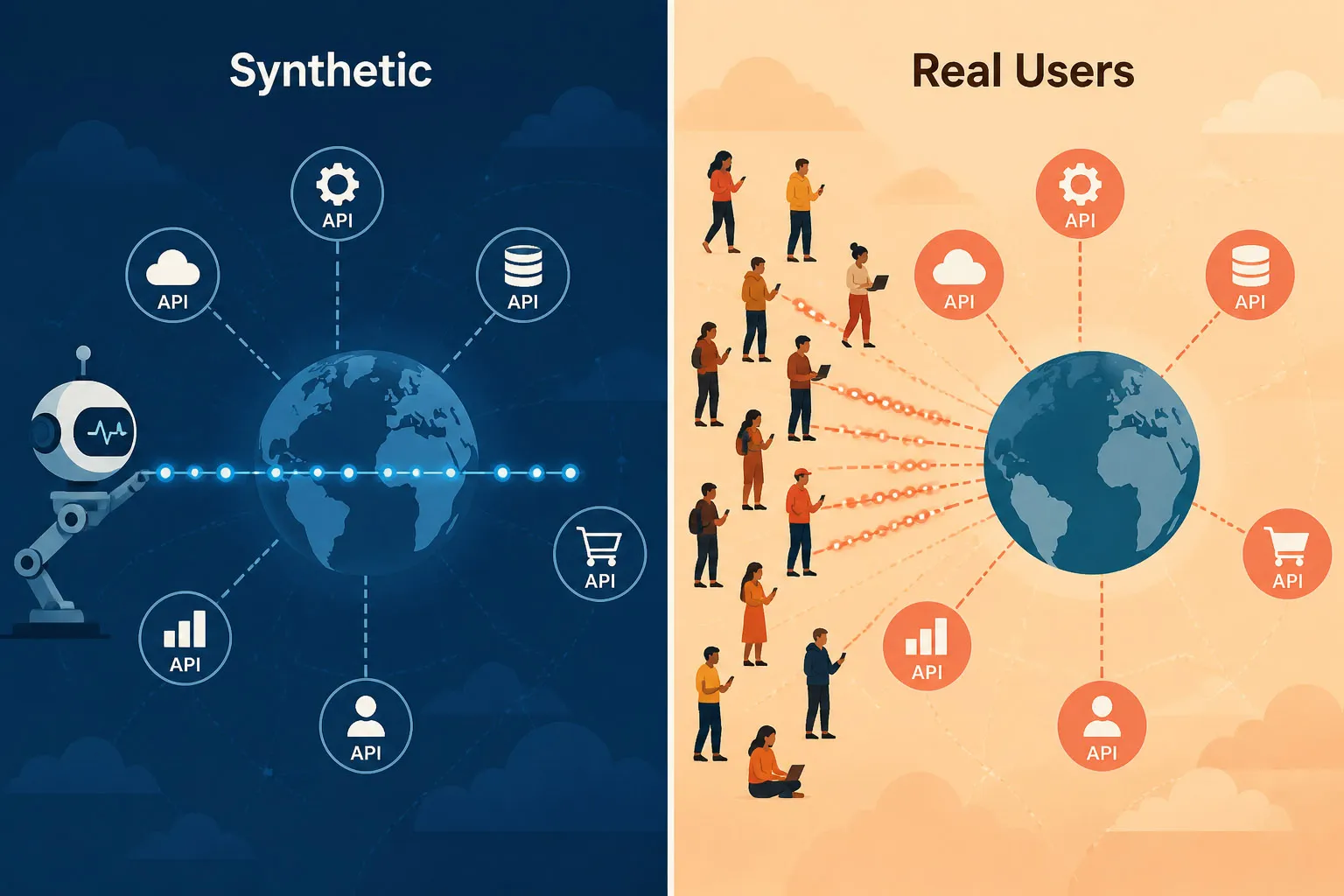
Beide Ansätze liefern API-Performance-Daten, jedoch aus grundverschiedenen Perspektiven:
| Synthetische Überwachung | Real User Monitoring (RUM) | |
|---|---|---|
| Auslöser | Skriptgesteuerte Prüfungen nach Zeitplan (z. B. jede Minute) | Echte Nutzeranfragen in der Produktion |
| Abdeckung | Läuft 24/7 – auch bei null aktiven Nutzern | Generiert Daten nur bei aktiven Nutzeranfragen |
| Erkennung | Proaktiv – erkennt Fehler, bevor Nutzer betroffen sind | Reaktiv – zeigt Probleme, nachdem Nutzer bereits betroffen sind |
| Umfang | Öffentliche und private/interne APIs (über Private Agent) | APIs, die echte Nutzer erreichen – vorwiegend öffentlich, Enterprise-RUM kann auch interne API-Aufrufe erfassen |
| Anwendungsfall | Kontinuierliche Verfügbarkeits- und Performance-Validierung | Verständnis der realen Auswirkungsradius und echten Nutzererfahrung |
Wichtige API-Überwachungsmetriken
Das Verfolgen der richtigen Metriken macht den Unterschied zwischen fundierter Vorfallsreaktion und Alarmmüdigkeit. Im Folgenden die wichtigsten Metriken mit genauen Benchmarks und deren Bedeutung.
| Metrik | Ziel / Benchmark | Was erfasst wird |
|---|---|---|
| Verfügbarkeit (Uptime %) | ≥ 99,9 % (drei Neunen); 99,99 % für besonders kritische APIs | Gesamtausfall, Teilausfall, Timeout |
| Gesamte Antwortzeit | < 200 ms für einfache Endpunkte; < 1s für komplexe Operationen | Server-Verlangsamungen, Überlast, Deployment-Regressionen |
| Time to First Byte (TTFB) | < 100 ms ideal; < 300 ms akzeptabel | Server-Verarbeitungsverzögerung vor Beginn der Antwort |
| P95 / P99 Antwortzeit | Alarm bei 2× dem Basiswert des P95 pro Endpunkt; nach Endpunktverhalten anpassen | Spitzenlatenz, die die langsamsten 1–5 % der Anfragen betrifft |
| Fehlerrate (4xx / 5xx) | < 0,1 % für Produktions-APIs | Auth-Fehler, schlechte Eingabe, Serverfehler |
| DNS-Auflösungszeit | < 50 ms für gleichregionale gecachte Anfragen; regionsübergreifend kann es > 100 ms sein | DNS-Propagation-Probleme, Resolver-Fehler |
| TLS-Handshake-Zeit | < 100 ms | Zertifikatsfehlkonfiguration, TLS-Verhandlungsprobleme |
| Payload-Assertion-Quote | 100 % (Alarm bei jedem Fehler) | Stille Fehler: HTTP-200-Antworten mit falschen oder fehlenden Daten |
| Durchsatz (Anzahl Anfragen/Sekunde) | Vergleich mit historischem Basiswert | Unerwartete Traffic-Abfälle oder ungewöhnliche Spitzen |
| Zertifikatsablauf (verbleibende Tage) | Alarm bei 30 Tagen; kritisch bei 7 Tagen | Baldiges TLS-Zertifikatsablaufdatum |
Antwortzeit-Benchmarks
Wie funktioniert API-Überwachung?
Das Verständnis der technischen Mechanik hilft Teams, das Monitoring korrekt zu konfigurieren und Ergebnisse genau zu interpretieren.
Der Kernüberwachungszyklus
- Planen. Eine synthetische Prüfung wird in konfigurierten Intervallen (z. B. jede Minute) von einem ausgewählten globalen Überwachungsstandort gestartet.
- Anfrage senden. Der Monitoring-Agent sendet eine HTTP-Anfrage an den Zielendpunkt – inklusive HTTP-Methode (GET, POST, PUT, PATCH, DELETE), Anfrageheadern, Authentifizierungsdaten und Anfrageinhalt.
- Zeitmessung. Der Agent misst DNS-Auflösungszeit, TCP-Verbindungszeit, TLS-Handshake, Time to First Byte (TTFB) und Gesamtreaktionszeit als einzelne Komponenten.
- Assertion. Die Antwort wird anhand konfigurierte Assertions geprüft – HTTP-Statuscode, Antwortzeitgrenze, Antwortheader und Payload-Inhalt via JSONPath (REST) oder XPath (SOAP).
- Alarm oder Erfolg. Bei Fehlermeldung einer Assertion oder Timeout wird ein Vorfall erzeugt und Benachrichtigungen gemäß konfigurierten Regeln versandt.
- Aufzeichnen. Alle Ergebnisse – Erfolge und Fehler – werden mit Zeitstempeln, Antwortdaten und Assertion-Resultaten für historische Trends und SLA-Berichte gespeichert.
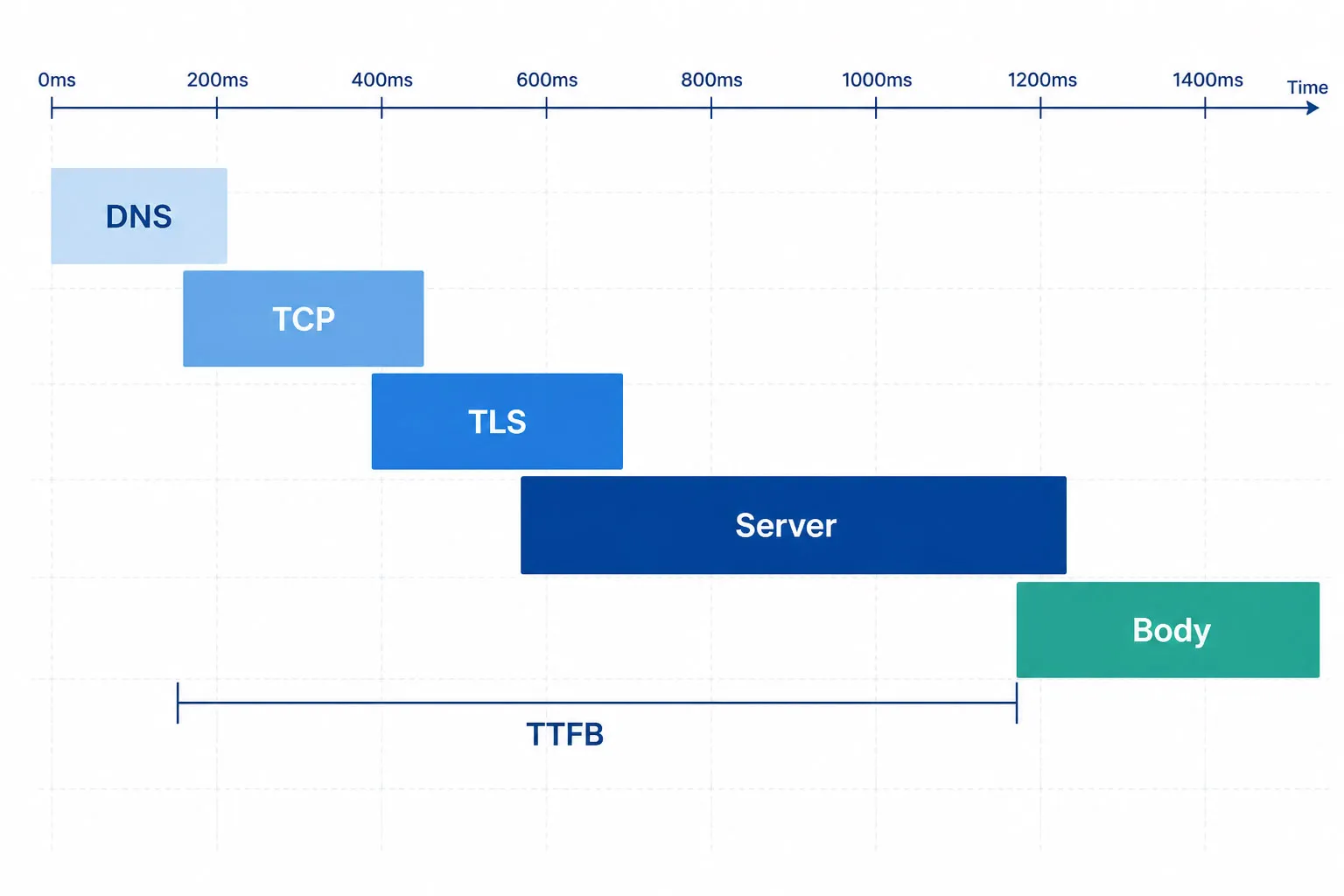
Multi-Step API Transaktionsüberwachung

Ein einzelner Endpunkt-Monitor bestätigt, dass einzelne Endpunkte antworten. Doch reale Nutzerreisen sind verkettete Sequenzen, bei denen jeder Schritt vom vorherigen Output abhängt.
Betrachten Sie einen E-Commerce-Checkout-Flow:
- Schritt 1 –
POST /auth/token: Benutzer authentifizieren;access_tokenaus der Antwort extrahieren - Schritt 2 –
GET /products/{id}: Produktdetails abrufen; Token imAuthorization-Header einfügen - Schritt 3 –
POST /cart/add: Artikel hinzufügen;cart_idaus der Antwort extrahieren - Schritt 4 –
POST /checkout/initiate: Checkout mitcart_idstarten;checkout_session_idextrahieren - Schritt 5 –
POST /payments/charge: Zahlung verarbeiten; assert, dass das Antwortfeldorder_statusgleich'confirmed'ist
Beim Monitoring einzelner Endpunkte bestehen alle fünf Schritte eventuell einzeln; der gesamte Transaktionsfluss kann trotzdem fehlschlagen – weil Sitzungsdaten zwischen den Schritten nicht korrekt übergeben werden, ein Token mitten im Ablauf abläuft oder die Zahlungs-API HTTP-200 mit einem Fehlerfeld in der Payload zurückliefert. Multi-Step-Monitoring führt die gesamte Kette in einem Monitoring-Task aus, validiert jeden Schritt unabhängig und überträgt dynamische Werte (Token, Sitzungs-IDs, Bestell-IDs) automatisch zwischen den Schritten.
Dotcom-Monitor ermöglicht Multi-Step-Transaktionsüberwachung durch Verkettung sequenzieller API-Aufrufe in einem einzigen Monitoring-Task. Variablen-Extraktion und -Injection zwischen Schritten ist automatisch. Jeder Schritt wird individuell überprüft, so dass Fehler genau auf den Schritt zurückgeführt werden können, an dem die Transaktion scheiterte.
Payload-Validierung: JSONPath- und XPath-Assertions
Payload-Validierung unterscheidet Monitoring von einfachem Verfügbarkeits-Ping. Wie Assertions ausgedrückt werden, hängt vom Tool ab, doch die Logik ist konsistent:
- JSONPath-Feldzugriff (REST): Zugriff auf
$.data.status– assert, dass der zurückgegebene Wert'active'ist - JSONPath-Array-Prüfung: Zugriff auf
$.items– assert, dass die Array-Länge größer als 0 ist - XPath-Assertion (SOAP):
//order/status/text()– assert, dass der Knotenwert'confirmed'ist - Header-Assertion: assert, dass der Wert des
Content-Type-Headers'application/json'ist - Antwortzeit-Assertion: assert, dass die gesamte Antwortzeit unter 500 ms liegt
Authentifizierungsüberwachung
Produktions-APIs benötigen Authentifizierung. Ein Monitoring-Tool muss dieselben Auth-Methoden wie echte API-Clients unterstützen. Zu den Schemen, die eine produktionsreife Monitoring-Plattform abdecken sollte:
| Auth-Methode | Beschreibung | Hinweise |
|---|---|---|
| OAuth 2.0 – Client Credentials | Machine-to-machine; Client tauscht Anmeldedaten direkt gegen ein Token | Am häufigsten bei Server-zu-Server API-Überwachung |
| OAuth 2.0 – Authorization Code | Benutzerauthorisierung, meist mit PKCE für SPAs/Mobile Apps | Monitoring-Tool muss Token-Refresh automatisch handhaben |
| OAuth 2.0 – Resource Owner Password (ROPC) | Direkter Benutzername + Passwort-Austausch – Legacy-Flow | Nur einsetzen, wenn Authorization Code nicht praktikabel ist |
| Bearer Token (JWT) | Statisches oder dynamisch erneuertes Token im Authorization-Header |
Kurzlebige JWTs erfordern automatischen Token-Refresh |
| API-Schlüssel | Statischer Schlüssel im Header, Query-Parameter oder Cookie | Einfachste Methode; auf Rotation achten |
| Basic Authentication | Base64-codiertes username:password im Authorization-Header |
Legacy – immer noch häufig bei Unternehmens- und internen APIs |
| AWS Signature v4 | HMAC-signierte Anfrage mit AWS-Anmeldedaten | Für AWS API Gateway Endpunkte erforderlich |
| mTLS / Client-Zertifikat | Mutual TLS – beide Seiten präsentieren Zertifikate | Zero-Trust-Umgebungen; Monitoring des Zertifikatsablaufs kritisch |
| NTLM / Kerberos | Windows/Active Directory-Integrierte Authentifizierung | Interne Unternehmens-APIs; weniger üblich in cloud-nativen Stacks |
| Custom Headers | Proprietäre Auth-Schemata via benutzerdefinierte Request-Header | Allgemeiner Fall für nicht standardisierte Auth-Implementierungen |
Tokenablauf ist eine Hauptursache für Fehlalarme im Monitoring. OAuth 2.0 Access-Token-Lebensdauern variieren stark je nach Implementierung und Grant-Typ. Benutzergesteuerte Tokens (Authorization Code Flow) haben meist 15 Minuten bis 1 Stunde Gültigkeit. Machine-to-Machine-Tokens (Client Credentials Flow) sind oft für längere Zeitfenster konfiguriert – 1 bis 24 Stunden – um Erneuerungsaufwand zu reduzieren. Hochsichere Umgebungen erzwingen Gültigkeiten von bis zu 5 Minuten. Unabhängig vom Zeitfenster erzeugt ein Monitoring-Tool ohne automatischen Token-Refresh entweder Fehlalarme oder erfordert manuelle Credential-Rotation, was sowohl betrieblichen Aufwand als auch Ausfallrisiko erhöht.
Ein Hinweis zum OAuth 2.0 Implicit Grant: Dieser ist laut aktuellen Security-Best-Practices (RFC 9700) veraltet und sollte in neuen Systemen nicht verwendet werden. Für bestehende APIs mit Implicit Flow wird eine Migration zu Authorization Code + PKCE dringend empfohlen.
Warum API-Überwachung wichtig ist: Geschäftliche Auswirkungen
APIs sind keine Infrastruktur-Abstraktionen – sie sind Umsatzpfade. Bei Ausfällen sind die Folgen finanziell, operativ und vertraglich.
Die Kosten unerkannter API-Ausfälle
Ohne proaktive Überwachung verlassen sich Teams auf Kundenmeldungen zur Fehlererkennung. Branchenumfragen zeigen, dass die MTTD bei Kundenmeldungen oft über 30 Minuten liegt – bis zur Meldung, Untersuchung, Triage und Eskalation ist das Zeitfenster bereits verstrichen. Kontinuierliche synthetische Überwachung mit 1-Minuten-Intervallen reduziert die Erkennungszeit auf unter 60 Sekunden und ermöglicht Ursachenanalyse, bevor das Problem sich verschlimmert.
Die Umsatzformel ist einfach: Bestellungen/Minute × durchschnittlicher Bestellwert × Ausfalldauer in Minuten. Eine Plattform mit 100 Bestellungen/Minute bei $50 durchschnittlichem Bestellwert verliert bei einem 5-minütigen Zahlungsausfall $25.000 potenziellen Umsatz. Setzen Sie Ihre eigenen Durchsatz- und Bestellwerte ein, um Ihre Risiken zu berechnen.
Branchenspezifische Szenarien
- E-Commerce. Ein Checkout-API-Ausfall während Spitzenlast stoppt alle Conversions. Eine Zahlungsautorisierung-API, die HTTP 200 mit abgelehntem Status zurückgibt – aber keinen Alarm auslöst – blockiert still Transactions für Minuten, bevor es jemand bemerkt.
- FinTech. APIs zur Transaktionsverarbeitung müssen Subsekunden-Latenzanforderungen erfüllen. Anhaltende Degradierung über SLA-Grenzen kann Vertragsstrafen und Audit-Feststellungen unter PCI DSS auslösen.
- Gesundheitswesen. EHR-Integrations-APIs und Telemedizin-Endpunkte müssen HIPAA-konformen Datenaustausch gewährleisten. Eine API, die HTTP 200 mit unvollständigen Patientendaten zurückgibt, ist ein Compliance-Vorfall – nicht nur ein Performance-Problem.
- SaaS / API-as-a-Product. Wenn Ihre API ein kostenpflichtiges Produkt ist, führen Ausfallzeiten zu vertraglichen SLA-Strafen und Kundenabwanderung. Monitoring liefert dokumentierte Uptime-Beweise für SLA-Konformitätsberichte.
- Enterprise IT. CRM-, ERP- und HR-API-Integrationen zwischen Abteilungen. Eine Salesforce-API-Degradierung kann stumm Vertriebsworkflows unternehmensweit brechen, ohne dass ein 500-Fehler im Log erscheint.
Drittanbieter-API-Risiko
Moderne Anwendungen hängen von externen APIs ab, die sie nicht kontrollieren: Zahlungsgateways (Stripe, PayPal, Braintree), Identitätsanbieter (Okta, Auth0, AWS Cognito), Versand-APIs und CRM-Systeme. Wenn diese sich verschlechtern, erscheint Ihre Anwendung für Nutzer defekt, obwohl Ihre Infrastruktur stabil ist.
Die Überwachung von Drittanbieter-Endpunkten ermöglicht Teams, sofort zu isolieren, ob ein Ausfall intern oder extern ist – eine Unterscheidung, die ohne vorherige Überwachungsdaten erheblichen Untersuchungsaufwand erfordert. Sie liefert außerdem dokumentierte Nachweise zur Einforderung von SLA-Verpflichtungen gegenüber Anbietern.
Hören Sie auf, API-Ausfälle erst von Ihren Kunden zu erfahren.
Synthetisches API-Monitoring von Dotcom-Monitor erkennt Ausfälle innerhalb von 60 Sekunden und sendet Alarme direkt an PagerDuty, Slack oder Microsoft Teams. Überwachen Sie Zahlungsgateways, Identitätsanbieter und interne APIs von einer Plattform aus.
API-Überwachung vs. API-Tests
Beide Praktiken validieren API-Verhalten, aber sie dienen unterschiedlichen Zwecken im Software-Lebenszyklus. Eine Vermischung erzeugt Abdeckungslücken.
| Dimension | API-Tests | API-Überwachung |
|---|---|---|
| Wann | Vorbereitend – Entwicklung, QA, CI/CD-Pipeline | Nach Deployment – kontinuierlich in Produktion |
| Umgebung | Entwicklung, Staging, kontrollierte Testumgebung | Echte Produktion, reale Infrastruktur, realer Traffic |
| Auslöser | Code-Commit, Build, manuelle Ausführung, PR-Gate | Geplant (z. B. alle 1 Minute), 24/7 kontinuierlich |
| Ziel | Fehler vor dem Deployment verhindern | Ausfälle und Verschlechterungen in Produktion erkennen |
| Abdeckung | Alle Verhaltensweisen, Randfälle, Fehlerpfade | Kritische Pfade, SLA-Endpunkte, Nutzerreise-Ketten |
| Perspektive | Innen-Außen: testet das Verhalten des Codes | Außen-Innen: validiert aus Sicht des Nutzers |
| Output | Pass/Fail-Bericht; blockiert Deployment bei Fehlern | Echtzeit-Alarme, Uptime-SLA-Aufzeichnungen, Vorfallhistorie |
Die praktische Beziehung: API-Tests sind eine Entwicklungsaktivität. API-Überwachung ist eine Betriebsaktivität. Tests erkennen Fehler vor Deployments; Monitoring erkennt Ausfälle, Regressionen, Performance-Verschlechterungen und Abhängigkeitsprobleme nach Deployments – unter realen Infrastrukturbedingungen, die sich von kontrollierten Testumgebungen unterscheiden.
Ein reifes Engineering-Team nutzt beide – und verwendet Postman Collection-Importe, um die beiden zu verbinden, indem Entwicklungstests in Produktionsmonitore umgewandelt werden, ohne Anfragendefinitionen zu duplizieren.
API-Überwachung vs. APM
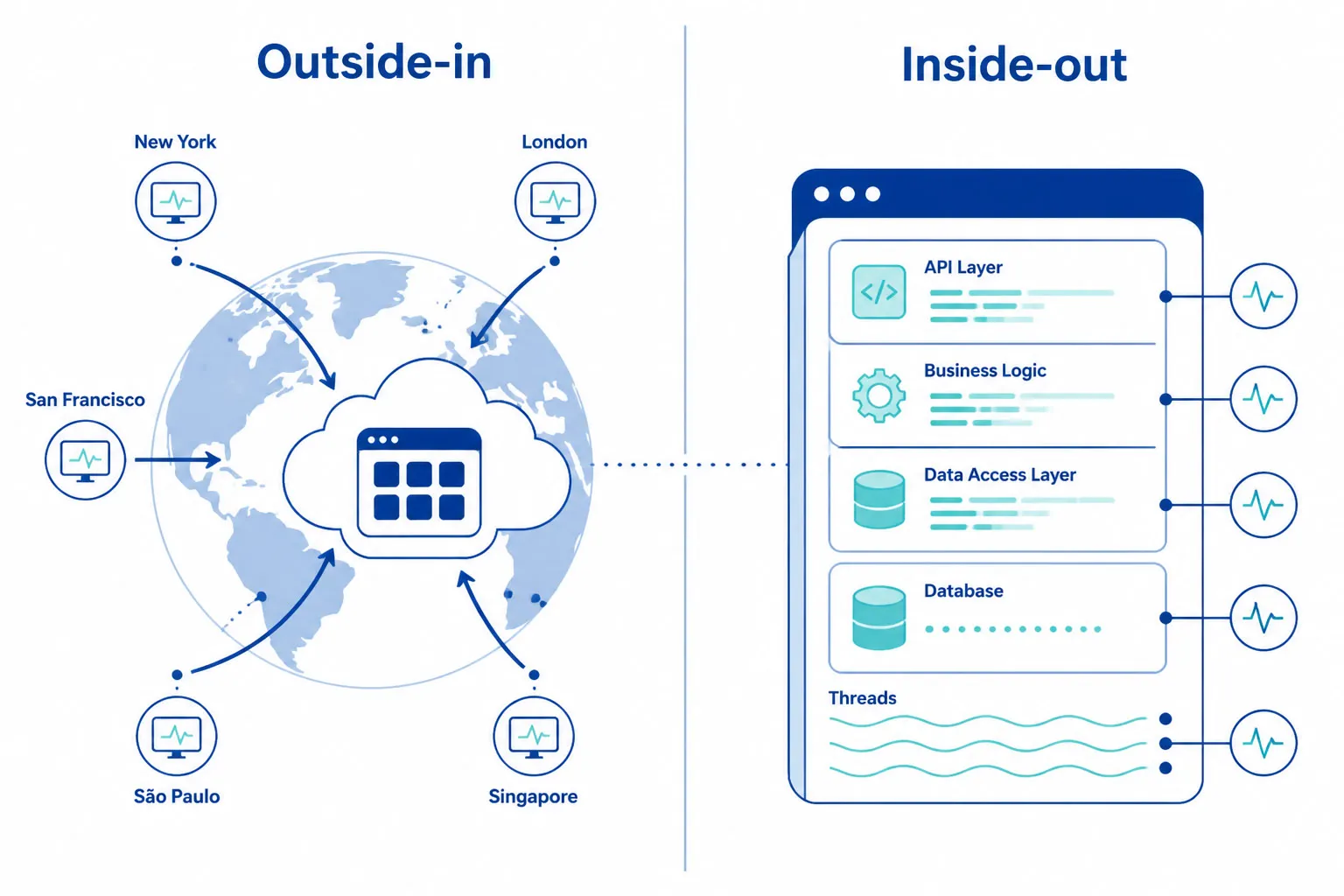
Diese beiden Kategorien werden oft verwechselt. Sie ergänzen sich, sind aber nicht austauschbar.
| Synthetische API-Überwachung | APM (Application Performance Monitoring) | |
|---|---|---|
| Perspektive | Außen-in – validiert aus der Sicht von Nutzern und Partnern | Innen-aus – beobachtet das interne Anwendungsverhalten |
| Was beobachtet wird | DNS-Fehler, Netzwerk-Routing-Probleme, TLS-Fehler, CDN-Fehlleitungen, geografische Abdeckungslücken | Langsame DB-Abfragen, Speicherlecks, Code-Ausnahmen, langsame Funktionsaufrufe |
| Wann es läuft | 24/7 – auch bei Null-Traffic | Nur bei echten Anfragen in Bearbeitung |
| Frage, die beantwortet wird | „Kann unser Kunde diese API jetzt tatsächlich aufrufen?“ | „Was passiert intern in der Anwendung, wenn eine Anfrage eintrifft?“ |
Teams mit der geringsten MTTR nutzen beide: APM für interne Ursachenanalyse, synthetische API-Überwachung für externe Validierung. Logs und Traces beantworten „Was ist in unserem Code schiefgelaufen?“, synthetische Überwachung beantwortet „Können unsere Kunden diese API jetzt nutzen?“
API-Protokolle: REST, SOAP, GraphQL, gRPC und WebSocket
Jedes API-Protokoll hat eigene Überwachungsanforderungen und Fehlerarten. Ein Tool, das alle APIs nur als einfache HTTP-GET-Anfragen behandelt, übersieht protokollspezifische Probleme.
REST API-Überwachung
REST ist das dominierende API-Protokoll. Monitoring validiert HTTP-Methoden (GET, POST, PUT, PATCH, DELETE), Statuscodes, Antwortheader und JSON-Antwortkörper via JSONPath-Assertions. Wichtig: Assertion auf Payload-Feldwerte, nicht nur Statuscodes; Überwachung aller HTTP-Methoden, nicht nur GET (POST, PUT und DELETE triggern unterschiedliche serverseitige Logik und Fehlerarten); Verfolgung der Antwortzeit pro Endpunkt einzeln, nicht als Durchschnitt über alle Endpunkte.
SOAP API-Überwachung
SOAP-APIs tauschen XML über HTTP aus. Anforderungen: WSDL-Import für Endpunkt- und Schema-Definition; XPath-Assertions auf XML-Antwortelemente; Unterstützung für SOAP 1.1 und 1.2; WS-Security-Konfiguration für Unternehmens-SOAP-Dienste mit Nachrichten-Level-Sicherheit.
GraphQL API-Überwachung
Die Hauptherausforderung bei GraphQL: Die meisten GraphQL-Server-Implementierungen liefern HTTP 200 auch bei Teilfehlern oder fehlerhaften Abfragen. Der HTTP-Statuscode ist kein zuverlässiges Fehlersignal. Sie müssen:
- Konkrete Query-Payloads senden und auf das
data-Objekt der Antwort prüfen - Das
errors-Array im Antwortbody prüfen – Standard-GraphQL hat optional ein obersteserrors-Feld, das bei Erfolg leer oder nicht vorhanden und bei Fehlern gefüllt ist. Eine 200-Antwort mit gefülltemerrors[]bedeutet auf GraphQL-Ebene Fehler trotz HTTP-Erfolg - Query-spezifische Dateninvarianten validieren: assert, dass erwartete Felder vorhanden, nicht null und korrekt typisiert im
data-Objekt sind – manche Systeme kodieren Domänen-Fehler imdata-Objekt statt imerrors-Array - Query-Komplexitäts- und Tiefengrenzen überwachen, um Performance-Degradierung vor Timeouts zu erkennen
gRPC API-Überwachung
gRPC nutzt standardmäßig Protocol Buffers über HTTP/2, obwohl gRPC-Web HTTP/1.1 via Proxy für Browser unterstützt. Anforderungen: Proto-Datei für Service- und Methoden-Definitionen importieren; Binärcodierung/-decodierung von Protobuf-Nachrichten; Statuscode-Validierung mittels gRPC-Statuscodes (OK, UNAVAILABLE, DEADLINE_EXCEEDED etc.) – nicht HTTP-Statuscodes; Unterstützung für Unary, Server-Streaming, Client-Streaming und Bidirektionale Streaming-RPC-Typen.
WebSocket API-Überwachung
WebSocket APIs halten persistente bidirektionale Verbindungen für Echtzeit-Daten. Monitoring validiert Verbindungsaufbauzeit und WebSocket-Handshake-Erfolg, Nachrichten-Übertragungsverzögerung und Payload-Korrektheit, sowie Verbindungsstabilität über Zeit einschließlich Reconnect-Verhalten nach Verbindungsabbrüchen.
Öffentliche API-Überwachung vs. interne API-Überwachung

Die meisten API-Überwachungsleitfäden fokussieren ausschließlich öffentliche Endpunkte. Doch in Microservices-Architekturen sind die meisten kritischen API-Aufrufe intern – Service-zu-Service-Aufrufe, die das öffentliche Internet nie erreichen.
| Öffentliche API-Überwachung | Interne API-Überwachung | |
|---|---|---|
| Was abgedeckt wird | Kundenorientierte Endpunkte, Partner-APIs, Drittanbieter-Integrationen | Interne Microservices, private VPCs, Staging-Umgebungen, APIs hinter Firewalls |
| Wie es funktioniert | Externe Monitoring-Agenten führen Checks von globalen Standorten über das öffentliche Internet durch | Ein im eigenen Netzwerk deployter Private Agent initiiert ausgehende Verbindungen zur Monitoring-Plattform |
| Firewall-Anforderungen | Keine – Prüfungen starten extern | Keine eingehenden Regeln nötig – Agent initiiert nur ausgehende Verbindungen |
| Was erkannt wird | DNS-Ausfälle, CDN-Routing-Probleme, TLS-Fehler, geographische Verfügbarkeitslücken | Inter-Service-Fehler, Authentifizierungs-Microservice-Latenz, Datenbank-API-Degradierung |
| Deployment | Keine Installation – sofort einsatzbereit | Agent on-premises oder private Cloud (Windows und Linux unterstützt) |
Interne Microservice-APIs sind häufig die Quelle für Kaskadeneffekte. Ein degradierter Authentifizierungsdienst oder eine langsame Datenzugriffs-API verursacht nachgelagerte Fehler, die sich als Frontend-Ausfälle zeigen – die Ursache ohne interne Sichtbarkeit schwer lokalisierbar macht. Die Überwachung interner APIs erlaubt es Teams, zu isolieren, ob der Fehler in der API-Schicht, im downstream Microservice oder in der Datenbank liegt. Erfahren Sie mehr über Private Agent Monitoring hinter Ihrer Firewall.
Beste Praktiken für API-Überwachung
Diese Praktiken verkürzen die mittlere Erkennungszeit (MTTD), verbessern Alarmpräzision und stellen sicher, dass die Überwachungsabdeckung zum Produktionsrisiko passt.
- Überwachen Sie umsatzkritische Endpunkte in 1-Minuten-Intervallen. Für Zahlungs-, Authentifizierungs- und Kerndaten-APIs hat jede unerkannte Minute direkten Geschäftseinfluss. Für weniger kritische Endpunkte sind 5- oder 15-Minuten-Intervalle akzeptabel.
- Führen Sie Prüfungen von mindestens 5 geografisch verteilten Standorten durch. Ein einzelner Überwachungsstandort kann regionale DNS-Ausfälle, CDN-Fehlkonfigurationen oder Geo-Routing-Probleme nicht erkennen. Decken Sie mindestens Nordamerika, Europa und Asien-Pazifik ab.
- Validieren Sie Payload-Inhalte, nicht nur Statuscodes. Konfigurieren Sie JSONPath-Assertions für jeden kritischen Endpunkt. Die teuersten stillen Fehler sind APIs, die HTTP 200 mit unvollständigen, veralteten oder fehlerhaften Daten zurückliefern.
- Nutzen Sie alarmbezogene Grenzwerte auf Basis von Baselines statt statische Millisekundenwerte. Etablieren Sie eine Antwortzeit-Baseline pro Endpunkt und konfigurieren Sie Alarme bei 2× dem P95-Wert. Statische Grenzwerte erzeugen Fehlalarme bei normalen Traffic-Spitzen.
- Beziehen Sie Authentifizierung in Ihre Monitoring-Ketten ein. Tokenablauf, OAuth-Refresh-Fehler und Zertifikatswechsel sind Hauptursachen für API-Ausfälle. Monitoring von Auth-Schritten fängt Credential-bezogene Fehler ab, bevor sie sich ausbreiten.
- Erstellen Sie Multi-Step-Transaktionsmonitore für jede kritische Nutzerreise. Login-Flows, Checkout-Sequenzen und Datenübermittlungs-Workflows sind verkettete API-Aufrufe. Einzel-Endpunkt-Monitore können Fehler zwischen Schritten durch falsche Datenübergabe oder Sitzungshandling nicht erfassen.
- Überwachen Sie Drittanbieter-API-Abhängigkeiten als separate Monitore. Erstellen Sie eigene Monitore für Stripe, Okta, Salesforce und andere externe Dienste. Das zeigt sofort, ob ein Fehler intern oder extern liegt.
- Importieren Sie Postman oder Insomnia Collections zur Initialisierung Ihres Monitorings. Wandeln Sie bestehende API-Definitionen ohne Neuerstellung in 24/7-Produktionsmonitore um. So schließen Sie die Lücke zwischen Entwicklungs-Tests und Produktions-Monitoring.
- Integrieren Sie post-deployment API-Checks in CI/CD-Pipelines. Führen Sie synthetische API-Checks als automatisierte Smoke-Tests nach jedem Deployment aus. Schlägt ein Check fehl, ziehen Sie automatisierte Rollbacks oder Traffic-Holds in Betracht – verwenden Sie Bestätigungsprüfungen von einem zweiten Standort zur Vermeidung von Fehlalarmen vor automatischen Aktionen.
- Routen Sie Alarme per PagerDuty, Slack oder Microsoft Teams mit Eskalationsrichtlinien. Nur E-Mail-Benachrichtigungen verzögern die Fehlererkennung. Native Integrationen mit Vorfallmanagement-Tools stellen sicher, dass Alarme sofort die richtigen Personen erreichen, inklusive definierten Eskalationswegen bei fehlender Reaktion.
Herausforderungen bei der API-Überwachung
Selbst gut geplante Monitoring-Setups stehen vor betrieblichen Herausforderungen. Diese frühzeitig zu berücksichtigen hilft bei der Gestaltung.
Sichtbarkeit bei Drittanbieter-APIs
Die Überwachung externer Abhängigkeiten liefert Verfügbarkeits- und Latenzdaten, kann jedoch die interne Ursache von Degradierungen nicht offenlegen. Wenn Stripe oder Okta langsamer werden, können Sie das bestätigen und den Auswirkungsradius isolieren – die Ursachenanalyse hängt jedoch von Anbieterstatusseiten und Support-Eskalationen ab.
Rate Limiting
Monitoring-Agenten zählen zu den API-Rate-Limits. Das gesamte synthetische Anfragevolumen skaliert mit: Standorte × Checks pro Stunde × API-Aufrufe pro Monitor-Lauf × Bestätigungsversuche. Für einen Einzelendpunkt-Monitor: 30 Standorte × 60 Checks/Stunde = 1800 Anfragen/Stunde. Für einen 5-Schritte-Transaktionsmonitor bei gleichen Einstellungen: 30 × 60 × 5 = 9000 Anfragen/Stunde pro Monitor. Berücksichtigen Sie das beim Rate-Limit-Budget, besonders für interne APIs mit strikteren Limits. Stellen Sie sicher, dass IP-Bereiche Ihres Monitoring-Anbieters wo nötig whitelist-geschaltet sind.
Komplexität der Authentifizierung
APIs mit kurzlebigen Tokens benötigen Monitoring-Tools, die automatischen Token-Refresh unterstützen. Benutzergesteuerte OAuth 2.0 Tokens (Authorization Code Flow) laufen typischerweise in 15 Minuten bis 1 Stunde ab; Machine-to-Machine-Client-Credentials-Tokens dauern oft 1 bis 24 Stunden; Hochsicherheitsumgebungen setzen 5-Minuten-Fenster durch. Zertifikatsbasierte Auth und rotierende API-Schlüssel erfordern ebenfalls sorgfältiges Credential-Management.
Dynamische und nicht deterministische Antworten
APIs mit Zeitstempel-Daten, paginierten Ergebnissen oder zufällig sortierten Arrays sind schwer mit exakten Wertvergleichen zu überwachen. Nutzen Sie JSONPath-Ausdrücke, die Struktur, Feldvorkommen und Datentypen validieren – statt exakter Feldwerte, die bei jeder Anfrage variieren.
Alarmmüdigkeit
Überwachung mit zu vielen Endpunkten in 1-Minuten-Intervallen oder zu eng gesetzten Schwellwerten erzeugt Lärm, der Teams für echte Alarme abstumpft. Verwenden Sie abgestuftes Monitoring: 1 Minute für kritische Pfade, 5–15 Minuten für weniger kritische. Bestätigen Sie Alarme von einem zweiten Standort, bevor eine Pagerung erfolgt, um vorübergehende Fehlalarme auszuschließen.
Protokollvielfalt
REST, SOAP, GraphQL, gRPC und WebSocket erfordern unterschiedliche Assertion-Strategien. Ein Tool, das nur REST unterstützt, wird SOAP-Dienstausfälle übersehen und GraphQL-Fehler fälschlich als erfolgreich melden, da sie HTTP 200 zurückgeben.
So richten Sie API-Überwachung mit Dotcom-Monitor ein
 Wenn ein Check fehlschlägt, leiten Alarme an Ihre bestehenden Incident-Response-Tools – nicht an ein eigenes Monitoring-Postfach – weiter, das niemand überwacht.
Wenn ein Check fehlschlägt, leiten Alarme an Ihre bestehenden Incident-Response-Tools – nicht an ein eigenes Monitoring-Postfach – weiter, das niemand überwacht.
Dotcom-Monitor bietet synthetische API-Überwachung für REST, SOAP und GraphQL von über 30 globalen Standorten mit 1-Minuten-Checkintervallen, Multi-Step-Transaktionsunterstützung und nativen Integrationen mit PagerDuty, Slack und Microsoft Teams.
Schritt 1 – Definieren Sie Ihren Endpunkt und Assertions
- Endpunkt-URL: Zu überwachender API-Endpunkt
- HTTP-Methode: GET, POST, PUT, PATCH oder DELETE
- Anfrage-Header:
Content-Type,Authorizationund beliebige erforderliche benutzerdefinierte Header - Anfrage-Body: JSON-Payload für POST/PUT-Anfragen
- Authentifizierung: OAuth 2.0, Bearer Token, API-Schlüssel, Basic Auth, mTLS, AWS Signature v4, NTLM, Kerberos oder benutzerdefinierte Header
- Assertions: HTTP-Statuscode, Antwortzeitgrenzen, Headerwerte, JSONPath/XPath Payload-Assertions
Schritt 2 – Importieren von Postman oder Insomnia
Wenn Ihr Team Postman oder Insomnia verwendet, überspringen Sie die manuelle Endpunktkonfiguration vollständig:
- Postman: Exportieren Sie Ihre Collection als v2.0 oder v2.1 JSON und importieren Sie sie in Dotcom-Monitor. Anforderungsdefinitionen, Header, Body, Umgebungsvariablen und Test-Assertions bleiben erhalten.
- Insomnia: Exportieren Sie Ihren Workspace als Insomnia v4 JSON Datei und importieren Sie sie in Dotcom-Monitor. Anforderungsgruppen, Auth-Konfigurationen und Umgebungsvariablen bleiben erhalten.
Beide Importformate wandeln einmalige Entwicklungstests in kontinuierlich geplante 24/7 Produktionsmonitore ohne Neukonfiguration um.
Nutzen Sie bereits Postman? Dann trennen Sie nur noch 5 Minuten von 24/7-Produktionsmonitoring.
Importieren Sie Ihre bestehende Postman Collection direkt in Dotcom-Monitor. Ihre Anfragendefinitionen, Header, Umgebungsvariablen und Assertions bleiben erhalten – keine Neukonfiguration erforderlich.
Schritt 3 – Konfigurieren Sie Überwachungsstandorte und Frequenz
- Prüffrequenz: Intervalle von 1, 3, 5 oder 15 Minuten – nach Kritikalität pro Endpunkt festlegen
- Monitoring-Standorte: Wählen Sie aus über 30 Standorten in Nordamerika, Europa, Asien-Pazifik und Südamerika
- Private Agent: Für interne oder hinter Firewall liegende APIs – Agent on-premises oder in privater Cloud (Windows und Linux unterstützt). Der Agent initiiert nur ausgehende Verbindungen – keine eingehenden Firewall-Regeln nötig.
- Bestätigungsversuche: Konfigurieren Sie eine Bestätigungsprüfung von einem zweiten Standort vor Alarmierung, um vorübergehende Fehlalarme auszuschließen
Schritt 4 – Konfigurieren Sie Alarm-Routing
- PagerDuty: Leiten Sie kritische Alarme direkt an Rufbereitschaftspläne weiter mit automatischer Vorfallserstellung und Eskalation
- Slack / Microsoft Teams: Veröffentlichen Sie Alarmmeldungen mit Endpunktdetails, Fehlertyp und Antwortdaten in Ops-Kanälen
- E-Mail, SMS, Anruf: Konfigurieren Sie Benachrichtigungseinstellungen pro Kontakt oder Team
- Webhook: Integrieren Sie mit OpsGenie, ServiceNow oder jedem HTTP-kompatiblen Dienst
- Schwellenwert-Konfiguration: Legen Sie Alarmbedingungen pro Metrik fest – Antwortzeit, Fehlerrate, Assertion-Fehlerrate – mit Schweregraden
Schritt 5 – CI/CD-Pipeline Integration
- Dotcom-Monitor REST API: Erstellen, aktualisieren und triggern Sie Monitoring-Aufgaben programmgesteuert via HTTP API aus beliebigen CI/CD-Systemen
- GitHub Actions / Azure DevOps / Jenkins: Fügen Sie einen Post-Deploy-Schritt hinzu, der einen Dotcom-Monitor-Check ausführt, auf Ergebnisse wartet und die Pipeline bei Assertion-Fehlern fehlschlagen lässt
- Validierung vor Produktion: Führen Sie die gleichen synthetischen Checks vor Promotion von Builds in Produktions-Umgebungen durch – erkennen Sie Regressionen, bevor Nutzer betroffen sind
Branchenspezifische API-Überwachungsanwendungsfälle
| Branche | Kritische APIs zum Überwachen | Wichtige Überwachungsanforderungen |
|---|---|---|
| E-Commerce | Checkout, Zahlungsautorisierung, Inventar, Versand, Warenkorbverwaltung | Multi-Step-Transaktionsketten; 1-Minuten-Intervalle; Payload Assertion für Zahlungsbestätigungsstatus |
| FinTech / Banking | Transaktionsverarbeitung, KYC/AML-Verifikation, Kontostand, FX-Kurse, Wire-Transfer-APIs | Sub-200ms Latenz-SLAs; Compliance-Checks zur PCI DSS-Unterstützung; vollständige Auth-Flow-Validierung |
| Gesundheitswesen | EHR-Integrationen (HL7 FHIR), Versicherungsportale, Telemedizin-Endpunkte, Patiententerminplanung | Compliance-Checks zur HIPAA-Unterstützung; Payload-Validierung auf Datenvollständigkeit; 99,99 % Uptime-SLA |
| SaaS | Kernprodukt-APIs, Webhook-Zustellendpunkte, Partner-Integrations-APIs, Authentifizierungs-APIs | API-as-a-Product SLA-Einhaltung; Postman-Import für Dev-to-Monitor-Konsistenz; Drittanbieter-Überwachung |
| Enterprise IT | CRM, ERP, HRIS, Identity Provider, interne Workflow-Automations-APIs | Private Agent für APIs hinter Firewalls; NTLM/Kerberos-Auth; API-Sichtbarkeit abteilungsübergreifend |
| Medien / Gaming | CDN Content Delivery APIs, Authentifizierung, Echtzeit-Scoring, Social-Feature APIs | Geografische Verteilungsüberwachung; WebSocket-Verbindungsmonitoring; Traffic-Spike-Erkennung |
Starten Sie noch heute mit der Überwachung Ihrer APIs.
Dotcom-Monitor bietet synthetische API-Überwachung von über 30 globalen Standorten mit 1-Minuten-Intervallen, Multi-Step-Transaktionsunterstützung und nativen PagerDuty-, Slack- und Microsoft Teams-Integrationen. Die Einrichtung dauert unter 5 Minuten. Keine Kreditkarte für die 30-Tage-Testversion erforderlich.
